自然语言生成多表SQL查询语句技术研究*
2020-07-10曹金超吴晓凡
曹金超,黄 滔,陈 刚,3,吴晓凡,陈 珂,3+
1.浙江大学 计算机科学与技术学院,杭州310027
2.浙江邦盛科技有限公司,杭州310012
3.浙江大学 浙江省大数据智能计算重点实验室,杭州310027
4.网易(杭州)网络有限公司,杭州310051
1 引言
随着信息技术的快速变革,如何通过自然语言直接与传统关系数据库交互,也就是如何将人的自然问句转化成数据库可以执行的SQL(structured query language)语句已经成为人工智能领域的研究热点之一。为方便管理,可以利用关系型数据库来存储数据,然而通过关系型数据库来查询数据需要预先学习数据库系统以及数据库查询语句SQL上的专业知识,这对一个普通用户来说显然很难实现。为了解决这个问题,许多研究工作都采用了相似的解决思路,通过实现一个自然语言查询接口(natural language interface,NLI)来完成用户通过日常使用的自然语言与数据库进行交互从而获取想要查询的数据[1]。
如今,自然语言查询接口也产生了很多商业上的应用,例如智能语音助手、智能搜索引擎和对话系统等。同时,该问题亦是新型供电轨道交通系统混合时态大数据个性化运维的最棘手的难点之一。
NLI 最重要的一个部分就是将自然语言查询描述转化为标准的SQL 查询语句(NL2SQL)。针对这个问题,目前有两个不同的解决思路:(1)流水线方法,将自然语言查询转化为一种中间表达,再将其映射为SQL 语句;(2)深度学习方法,使用端到端的神经网络来完成转化[1]。
流水线方法将自然语言转化为中间表达的过程依赖于自然语言查询的规则化描述,因此无法处理一些复杂多变的自然语言描述。而近年来,随着深度学习技术的不断发展,使用神经网络模型来处理NL2SQL 的工作也越发普遍。其优势较前者在于不受自然语言描述多样性的限制,也能从复杂的表达中提取出关注的语义信息。但现有NL2SQL 的深度学习方法存在着一定的局限性,需指定当前自然语言查询对应数据库中的哪一张表,也就忽略了自然语言查询到对应查询表的映射,同时也无法支持如图1中所示例的多表查询。
从这个局限性出发,本文针对自然语言生成多表SQL查询的问题提出了一种解决方法。本文主要的工作和贡献如下:
(1)相比于现有工作基于模板的深度学习模型,本文的深度学习模型能处理更复杂的自然语言查询,因此能生成更为复杂的SQL 语句,包括GROUP BY、ORDER BY等关键词;
(2)利用深度学习模型生成的部分SQL 子句提及的表和数据库模式图,采用了一种全局最优的算法来生成FROM子句中多表的JOIN路径;
(3)通过在一个开放的复杂自然语言生成SQL的数据集Spider上与其他多种模型的对比,本文方法具有更高的准确率。
2 相关工作
尽管自然语言查询接口已经发展了很长一段时间,但要准确地理解自然语言查询中的语义依旧是一个具有挑战性的问题。早期的NL2SQL 需要针对不同的数据库来人工制定相应的语法和语义规则,但此方法缺乏迁移性和扩展性[2]。更倾向于构建与数据库结构和内容无关,能够自适应的NL2SQL接口。
其中一种就是流水线的方法,这种方法通常利用一些中间表达来把自然语言查询转化为SQL。Unger等人[3]在2012年提出了将自然语言查询转化为一种名为SPARQL的查询模板,通过WordNet来填充这个查询模板中的槽。Jagadish 等人[4]在2014 年提出了NaLIR 系统,该系统利用一种“解析树”的中间表达,将其反馈给用户后让用户选择与自己理想查询最匹配的“解析树”,最终通过译码器将用户选择的“解析树”转化为SQL。整个过程需要用户与系统交互才能确定最终的结果,自动化程度不高。上述基于流水线的方法[3-4]需要提前清晰地定义它们语义的覆盖范围,以及对自然语言查询描述也存在一些规则限制,因此不能灵活地处理用户不同方式的提问,具有一定的局限性。
而随着深度学习技术的不断发展,通过应用神经网络模型就能较好地解决自然语言描述复杂多变的问题。早期的研究把NL2SQL 处理成一个序列生成的问题,利用Seq2Seq 模型[5]来完成这个任务。Li等人使用Seq2Seq+Attention模型[6],通过注意力增强的方法来提升SQL 生成的准确率。Wang 等人使用Seq2Seq+Copying 模型[7],通过复制机制定位到输入自然语言描述的其中一部分,将其直接作为输出SQL 语句的对应的部分,复制的部分主要包括自然语言描述中数据表的列名和一些字符串或数值。然而,一般的Seq2Seq模型没有考虑到SQL语句的格式和语法上还存在一定的规则,因此生成的SQL 可能会产生语法上的错误。因此,Xu 等人[8]在2017 年提出了一个SQLNet模型,利用预先定义好SQL查询的模板,如图2 所示,然后对其各个部分进行预测和填充。这种方式相对于Seq2Seq 模型来说能大幅度减少输出SQL查询的语法错误,从而提高准确率。

Fig.2 SQL sketch in SQLNet图2 SQLNet中的SQL模板
然而针对深度学习模型,需要大量的自然语言查询与SQL 查询的配对标注来作为训练数据,而标注数据的获取通常代价昂贵。针对这个问题,一些最新的自然语言处理研究工作提出了使用大规模语料来产生预训练模型的方法,预训练模型在许多自然语言处理(NLP)相关的下游任务中取得了不错的效果,例如BERT[9](bidirectional encoder representation from transformers)、MT-DNN(multi-task deep neural network)[10]。He等人[11]提出了X-SQL模型,该模型利用MT-DNN预训练模型对自然语言查询和数据库模式进行特征提取来提升效果。
现有的深度学习模型[5,8,11]都局限于在数据库的单表中查询,生成结果不包含多表的JOIN路径,适用的范围较窄,无法进行多表SQL 查询生成。本文提出的模型架构能够解决这个问题,从而实现包含JOIN路径的多表SQL查询的生成。
3 问题定义
自然语言查询转化为标准SQL 查询语句,其形式化定义为:

输入:
由n个词语组成的自然语言祈使句或疑问句:

数据库模式集合:

其中,k表示该数据库中表的个数。
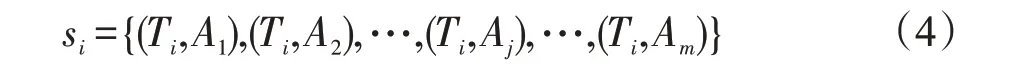
其中,Ti表示当前表的表名,m表示表i列名的个数,Aj表示表i的第j个列名。
数据库模式图(schema graph):

其中,V表示节点,对应于数据库中的表;E表示边,对应表之间的主外键关联关系;w表示边的权重值,默认为1。
输出:
与自然语言查询Q对应的SQL 查询语句R,格式如图3所示。
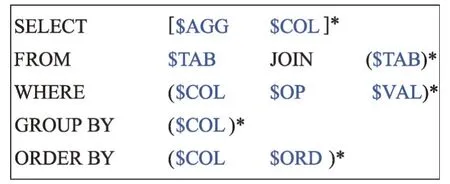
Fig.3 Generated SQL sketch in proposed model图3 本文生成SQL的模板
其中$VAL来自于自然语言查询Q中,本文模型暂不进行预测。$TAB和$COL分别来自数据库模式S的表名和列名。$AGG 的取值集合为{‘NONE’,‘MAX’,‘MIN’,‘COUNT’,‘SUM’,‘AVG’},$OP 的取值集合为{‘=’,‘>’,‘<’,‘>=’,‘<=’,‘!=’},$ORD 的取值集合为{‘DESC’,‘ASC’}。(…)*代表是零个或者多个,若为零个,则括号前对应的SQL 关键词也需省略,[…]*代表至少有一个。
4 方法和模型
为解决自然语言查询生成多表SQL查询语句的问题,本文将分为两个阶段,分别为SQL子句生成和JOIN路径生成。通过充分利用SQL查询语句特定的语法,将SQL 生成结果定义为图3 的格式模板,将序列生成转化为多个分类问题,只需要对带“$”的部分进行填充即可获得标准的SQL查询语句。本文的整体模型架构如图4所示。
4.1 输入编码
输入的编码包括两部分,自然语言查询和数据库模式。本文通过使用处理文本序列常用的双向长短时记忆(bidirectional long short term memory,Bi-LSTM)网络模型[12]来对自然语言查询和数据库模式中的列名进行编码,产生对应的特征向量。
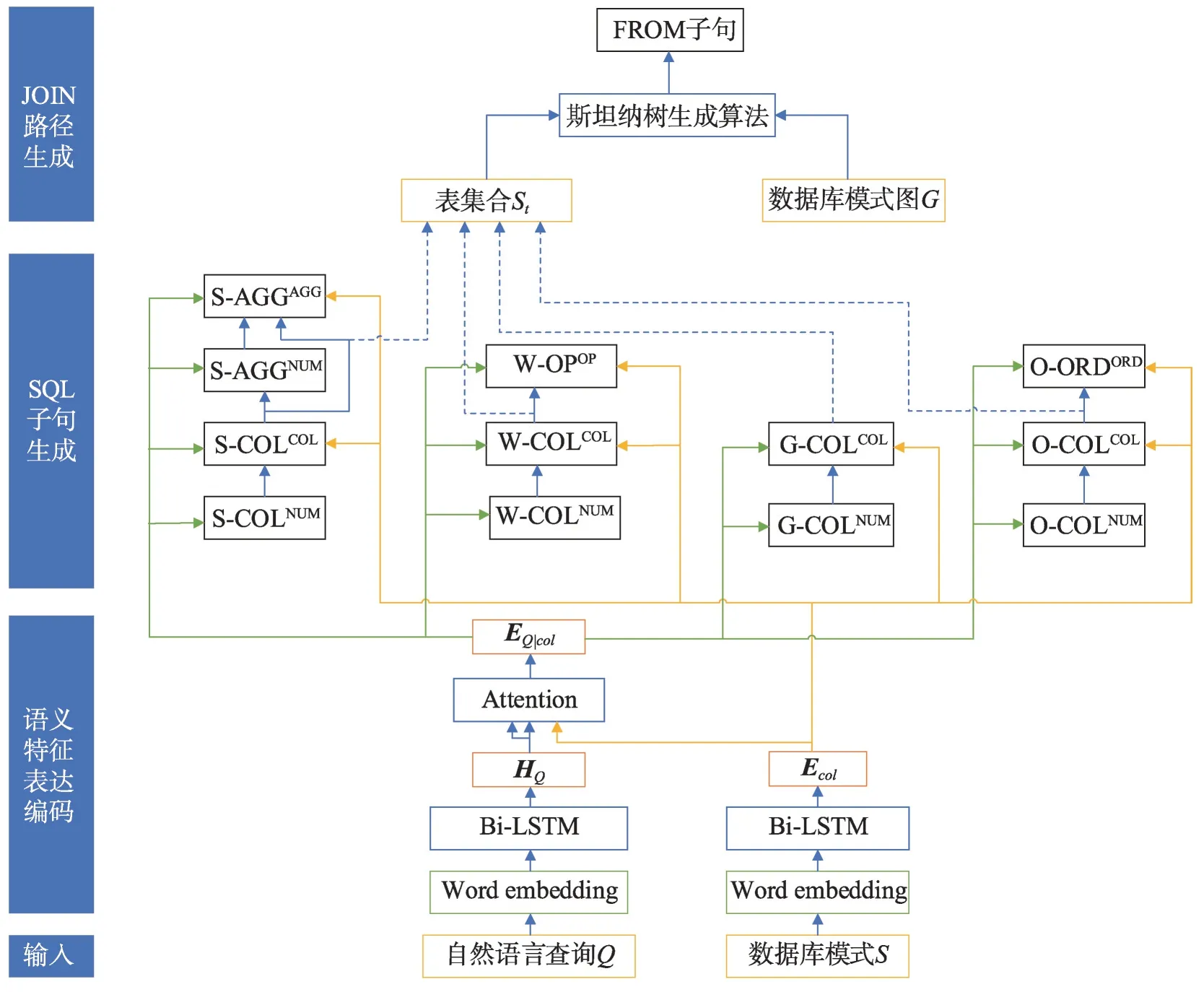
Fig.4 Overall architecture of proposed model图4 本文模型的整体架构
4.1.1 带表名信息的列名特征向量
SQL 子句的构成包含许多数据表中的列名信息,因此通过模型来获取数据库模式信息也是很有必要的。针对相关工作中提到的单表查询,在SQL生成前已经给定当前自然语言查询对应的表,因此不必再将表的信息嵌入到列名的特征向量中。但多表查询没有指定对应的表,查询范围为对应的整个数据库。为了解决这个问题,在做列名信息的特征表达时,同时利用表名和列名的配对来获取列名的特征向量。
具体说来,就是给定一个数据库模式S,首先列出表名和列名的配对作为Bi-LSTM 编码模型的输入。接下来,通过Bi-LSTM模型的编码,选择它最后的隐藏状态来代表当前列名的特征向量Ecol。通过这样编码的方式,获取的列名特征向量Ecol既包含了全局的表名信息,也包含了局部的列名信息,充分地利用了数据库模式的信息,更有利于后续的模型理解自然语言查询中的语义信息。
4.1.2 基于列名的注意力机制
在获取自然语言查询Q的特征表达时,如果只使用Q经过Bi-LSTM 模型编码的最后隐藏状态EQ作为特征向量,那么在预测各个子句所包含的列名信息时,就不能突出不同列名在自然语言查询Q中的重要程度。因此,为凸显不同列名在自然语言查询Q中信息侧重的不同,本文采用了一种基于列名的注意力机制[13],意在提醒之后的模型,在当前的列名Ecol下,应该更加注意自然语言查询Q中的哪些部分,从而获得当前列名对应Q的特征向量EQ|col。
首先,计算针对自然语言查询Q中每个词的权重值ω,从而获得一个长度为句长n的向量:

其中,vi表示向量v的第i维,表示自然语言查询Q的第i个词的编码隐藏状态,取值范围从1到n,n是自然语言查询的长度,W是可训练的参数矩阵,其维度为d×d,d表示编码模型隐藏状态输出的维度。
计算了权重值ω之后,就能将自然语言查询Q中通过Bi-LSTM模型编码的每个词的隐藏状态进行加权乘积后再求和,来获得当前列名对应Q的特征向量:

其中,HQ表示自然语言查询Q中所有词的编码隐藏状态矩阵,其矩阵维度为d×n。
4.2 SQL子句生成
本文将SQL 子句的生成分为4 个子任务,包括SELECT、WHERE、GROUP BY 和ORDER BY 子句的预测,每个子任务都是SQL语句的一个部分,各子句中预测填充部分之间相互依赖关系如图4所示。
4.2.1 模型细节
将模板中各子句中的填充内容处理成多个多分类问题,采用softmax 函数为每个类别计算概率来进行分类。为后续公式表达简洁清晰,先对矩阵M定义概率分布Pc,计算公式为:

其中,V是可训练参数。
在接下来各子句预测模块的公式中,Ecol和EQ|col分别代表了所有列名编码和其做注意力机制后对应自然语言查询Q的矩阵集合,其矩阵维度均为m×d,m表示数据库列名的数量,d为编码隐藏状态输出维度。还有其中所有的W都表示为可训练的模型参数,且各子句预测不共享参数。
(1)SELECT子句
首先预测子句中列名COL 的数量,再预测使用哪些列名,取值范围为对应数据库中所有表名列名配对的集合,公式如下:

在选定使用的列名之后,接下来需要对列名预测其AGG 的数量和具体是集合{‘NONE’,‘MAX’,‘MIN’,‘COUNT’,‘SUM’,‘AVG’}中的哪些聚合操作,假设当前列名的编号为i,那么公式如下:

(2)WHERE子句
同样,首先预测子句中列名COL的数量,再预测使用哪些列名,公式如下:

在选定列名之后,需要对列名预测其OP 操作,取值集合为{‘=’,‘>’,‘<’,‘>=’,‘<=’,‘!=’},假设当前列名的编号为i,公式如下:
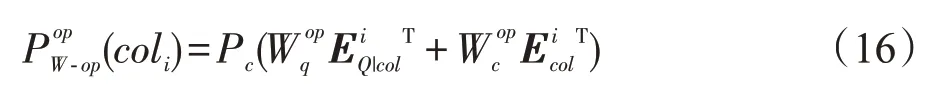
(3)GROUP BY子句
该子句的预测模型相对来说更简单一些,只需预测出子句中列名COL 的数量和对应哪些列名即可,公式如下:
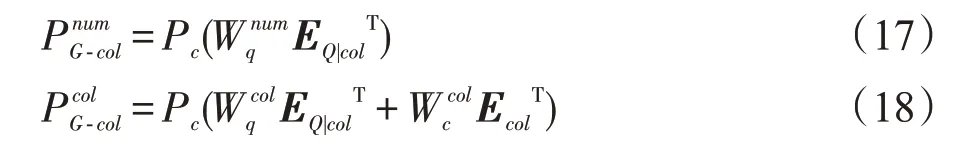
(4)ORDER BY子句
与SELECT子句预测模型结构类似,首先预测子句中列名COL的数量,再预测对应使用的列名,公式如下:
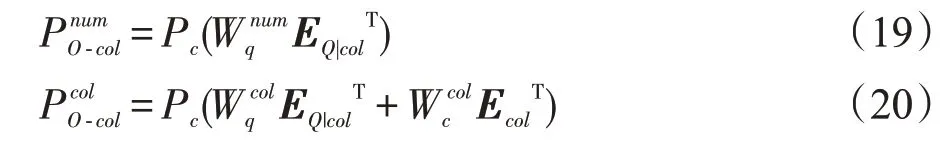
在确定使用的列名之后,就需要对列名的升降序操作ORD进行预测,取值集合为{‘DESC’,‘ASC’},假设当前列名的编号为i,公式如下:
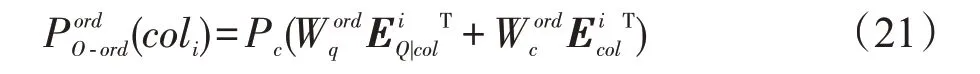
4.2.2 训练和推理
在训练的过程中,其目标函数是所有子任务损失函数的总和,通过最小化目标函数值的方式来进行参数更新。针对各子句中对列名COL 的预测,一个数据库中往往有很多列名,而只有少数几个列名是选中的正例,其他未出现在SQL 语句中的列名即为负例。为解决样本不均衡这个问题,针对各子句列名预测部分Pcol,本文使用带权值的对数似然损失函数来表示其损失(loss),公式如下:
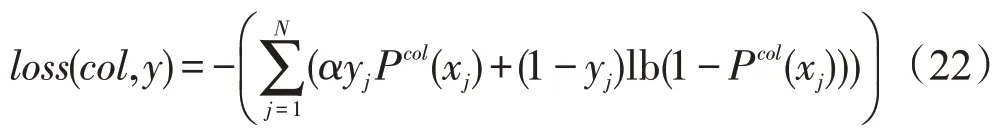
其中,α是用来平衡正负样例的超参数,在本文的实验中根据经验取值为3,N表示样本的数量,x表示训练数据,y表示真值。
其他非列名预测子任务的损失采用传统标准的交叉熵损失函数。在模型的训练过程中,由于已知子句中各部分预测的真实结果,因此各子任务之间互不影响,可并行训练。
但在预测推理阶段,根据图4 所示,以SELECT子句为例,在预测列名COL 对应的操作AGG 之前,需要先预测COL的数量和取值。因此在预测阶段模型是不可并行的,并且在预测推理的过程中,一旦某个部分预测出错,那这个错误一直传递下去,对后续的预测造成影响。
4.3 JOIN路径生成
在4.2节的深度学习模型中,已经完成了SQL语句中除FROM 子句部分的预测。接下来,需要根据之前各子句中生成结果中列名所包含的表,通过选择表与表之间的关系和产生JOIN路径的条件来生成SQL查询语句中的FROM子句。
生成FROM 子句中的JOIN 路径,首先需要获得已生成的SQL其他子句中列名所包含的表集合St和对应数据库的数据库模式图G,数据库模式图描述了数据库中各个表之间的主外键关联关系,图5所示为一个数据库的数据库模式图[1]。
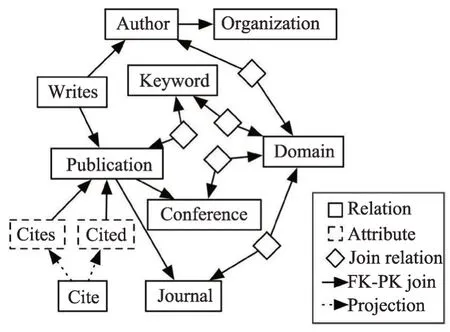
Fig.5 Example of database schema graph图5 一个数据库模式图的例子
目前已有的做法[14]是将St中所有的表,选定其中一个节点为基准点,通过在G上使用广度优先遍历(breadth first search,BFS)算法来获取到其他节点的JOIN 路径。这个算法依赖于基准点的选择,是一种局部最优化的算法,基准点不同会导致最终生成JOIN路径结果的不同。
本文将通过表集合St={tab1,tab2,…,tabm}和数据库模式图G=(V,E,w)来获取最优的JOIN路径的问题建模成斯坦纳树(Steiner tree)问题[15],目标是从图G中寻找一棵包括集合St中所有节点且开销最小的树,同时是JOIN路径的最优解。其中St表示表名集合,m为表的数量。本文采用如下的算法[15]来获取最优的JOIN路径:
算法1斯坦纳树生成算法
输入:表集合St={tab1,tab2,…,tabm}和数据库模式图G=(V,E,w)。
输出:JOIN路径,即斯坦纳树Th。
步骤1由G和St构建一个完全图G1=(V1,E1,w1),其中V1=St;
步骤2由G1获得其最小生成树T1(若有多棵最小生成树,随机选择一棵);
步骤3将T1中的边替换为G中对应的最短路径(若有多条最短路径,随机选择一条),得到G的子图Gs;
步骤4由Gs获得其最小生成树Ts(若有多棵最小生成树,随机选择一棵);
步骤5删除Ts中不必要的节点,得到斯坦纳树Th,其中Th的叶子节点全部来自St。
通过算法1,得到JOIN 路径之后,再根据其路径上的表之间的主外键关联关系产生JOIN 条件,最终生成FROM 子句。相比于BFS 算法,此算法求解的路径是全局最优解,因此理论上生成FROM 子句的准确率会更高。
5 实验
本文的实验环境为一台小型服务器,其操作系统为Ubuntu 16.04.6 LTS,处理器型号为Intel®Xeon®Silver 4110 CPU@2.10 GHz,内存为192 GB,GPU 型号为NVIDIA Quadro P5000,16 GB。本文实验使用的编程语言为Python,所有的模型训练都在深度学习框架PyTorch下进行。
本文使用的数据集是2018年发表的Spider数据集[16],是一个包含复杂SQL查询和跨领域数据库的大规模人工标注英文文本生成SQL数据集。该数据集中包含206 个数据库,在去除一些嵌套的SQL 查询后,获得的训练集3 917条配对数据,测试集数据993条配对数据。
本文对实验结果采用的评价方式是文献[8]的匹配准确率(query-match accuracy),通过将生成的SQL查询和真值转化成一种标准化的表达,再来比较两者之间是否匹配,这种衡量标准能减少因子句中多列名出现顺序不同而导致不匹配的错误。
根据图3 中SQL 语句模板,还有针对单独一个SQL 子句生成结果的评价指标——子句匹配分值(keyword match score),包括了精确率p、召回率r和F1值。以FROM子句为例,FROM$TAB JOIN($TAB)*,其中的TAB 对应的表就是一个需要预测的值单元,若预测结果为表集合pred={pt1,pt2,…,ptm},子句中表的真值为集合gold={gt1,gt2,…,gtn},那么精确率p、召回率r和F1值定义如下:
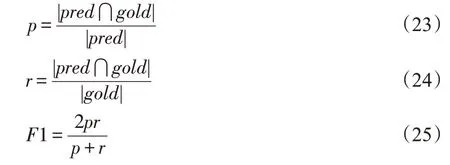
5.1 SQL子句生成实验结果
在实验过程中,本文采用了固定的预训练好的词向量GloVe[17]来对自然语言查询和数据库模式进行特征表达,使用Bi-LSTM模型进行文本特征提取,隐藏层维度设置为100维,使用Adam优化器[18],学习率设置为1E-3,训练迭代次数300 次,批量大小(batch size)为64,每次迭代都随机打乱训练数据的顺序。
表1 中给出了不同模型在测试集上对SQL 中4个子句预测的效果,可以观察到本文模型相较于Seq2Seq 模型以及其改进方法在各个子句上都有明显提升,且Seq2Seq 模型预测WHERE 子句的效果极差。而针对SQLNet模型来说,其定义SQL语句的模板如图2 所示,只能对SELECT 和WHERE 子句进行预测。本文对WHERE子句的预测模型和SQLNet中的相同,因此在实验效果上能保持一致。在SELECT子句预测时,本文模型能预测多个列名,以及一个列名对应的多个聚合操作,SQLNet 模型只支持预测一个列名和其对应的聚合操作,而实验数据中有的SELECT 子句中不止一个列名,因此本文方法在SELECT子句上的预测效果提升较大。
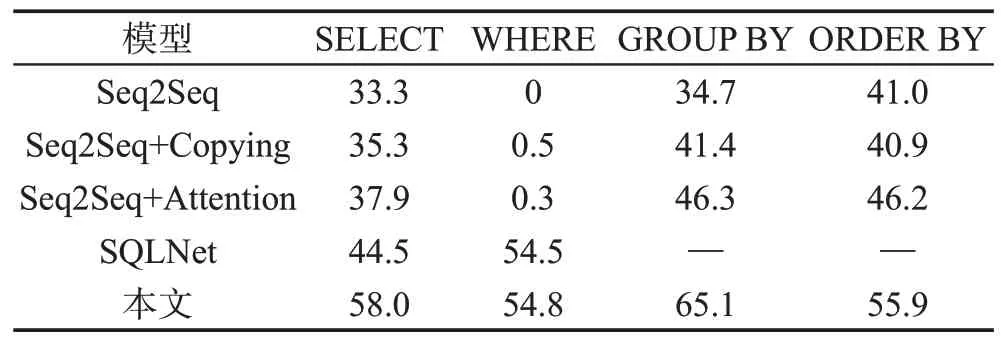
Table 1 F1 of matching 4 clauses in SQL queries on test set表1 测试集上SQL查询中4个子句匹配的F1 值 %
5.2 JOIN路径生成实验结果
为更准确地测试算法1与BFS算法在JOIN路径生成结果的对比,不受SQL 子句生成实验效果的影响,实验将训练集和测试集中除去FROM 子句的SQL 查询中的表名构建出真实的表集合S,以及通过数据库主外键关联关系构建数据库模式图G,两者同时构成JOIN路径生成算法的输入。
通过表2实验结果分析,可以看出算法1在JOIN路径的生成上相比于BFS算法在精确率p和召回率r上都有所提升。因此,利用算法1在5.1节实验结果的基础上生成FROM子句以构成完整的SQL语句更为可靠。

Table 2 Experiment result comparison of FROM clause generation表2 FROM子句生成的实验结果对比 %
5.3 完整流程实验结果及分析
为生成结构如图3所示的SQL查询语句,实验过程分为两个阶段,第一阶段使用5.1节中的SQL子句生成结果,第二阶段需要将SQL 子句中除FROM 子句的表名构成JOIN路径生成的表名集合输入St,然后将算法的输出转化为FROM 子句,最终生成SQL查询的结果。本文的实验中第二阶段的JOIN路径生成均采用算法1。
从表3 中的实验结果可以得出,Seq2Seq 模型在表1 中WHERE 子句结果不理想的情况下,在完整SQL 语句的查询匹配准确率还能达到19%~23%之间,说明数据中一部分的SQL 查询语句中不包含WHERE 子句。SQLNet 模型由于其局限性,不能用于生成多表查询SQL,因此无法统计其实验效果。结果表明使用本文两个阶段的模型和算法在多表SQL查询语句生成上能有效地提升准确率。

Table 3 Query-match accuracy comparison of full pipeline表3 完整流程的查询匹配准确率对比
6 结束语
本文针对自然语言生成多表SQL 查询问题,提出了SQL 子句生成和JOIN 路径生成两个阶段的改进模型和方法。在SQL子句生成阶段使用深度学习模型对SQL 语句模板进行填充,将序列生成处理为多个多分类问题,在JOIN 路径生成阶段将其建模为斯坦纳树问题求解。实验结果表明,本文方法的实验效果相比于之前的模型和方法上都有明显的提升,但查询匹配的准确率仍然不高。由于本文实验数据集Spider的特性,WHERE子句中的VAL不一定出现在自然语言中,对其预测带来困难,因此本文对VAL暂未进行预测。接下来的工作可以考虑完成对VAL的预测来生成完整的SQL 语句。除此之外,由于缺乏中文自然语言生成SQL 查询语句相关的数据集,因此无法验证本文模型在中文语料上的实验效果。
