人工智能赋能的查询处理与优化新技术研究综述*
2020-07-10宋雨萌李芳芳
宋雨萌,谷 峪,李芳芳,于 戈
东北大学 计算机科学与工程学院,沈阳110169
1 引言
数据查询一直是计算机领域的一个重要问题。自20世纪70年代起,数据库研究人员对数据库系统优化与数据驱动应用的研究使数据查询处理与优化技术得到了极大的发展。如今,高效的数据管理系统已逐渐成为信息化社会基础设施建设的重要支撑[1]。
近年来,人工智能领域的技术被广泛应用于数据驱动的问题中,取得了良好的效果。受到这些研究成果启发,数据库研究人员将数据查询处理与优化技术与人工智能中机器学习、深度学习技术相融合,力求达到更优的性能。因而,人工智能赋能的查询处理与优化技术正在成为计算机领域的一个重要的热点问题。通过分析查询各阶段中的数据库状态,学习对数据动态、智能的查询处理与优化能力,已经成为产业竞争力的体现。
相比通用的数据查询处理与优化技术,人工智能赋能的查询处理与优化技术在执行效率与性能方面具有明显优势。在执行效率方面,随着硬件的计算能力的巨大提升,越来越多的设备配置了专门用于机器学习的硬件,例如,iphone的“Neural Engine”,谷歌手机的“Visual Core”,谷歌云的云端TPU以及微软开发的BrainWave等[2]。强大的计算能力大大降低了模型训练与运行时间。从当前的发展趋势可以预见,机器学习、深度学习等技术的开销在未来可能忽略不计。因此,人工智能赋能的查询处理与优化新技术将提高数据查询的执行效率,降低时间开销。在性能方面,机器学习方法将自动选择使数据库表现达到最优的查询计划、配置参数或数据索引等,与数据库管理员(database administrator,DBA)的手动调优相比,人工智能方法能够解决有经验的DBA 无法解决的问题,同时避免了大量的手动操作。与复杂的启发式算法相比,人工智能方法将考虑更多的上下文因素,获取更优的优化结果。
如今,大数据管理技术与系统已能够满足各类海量同/异构数据的基本查询需求,但如何利用新一代人工智能技术提高数据查询处理与优化的性能仍然面临着诸多挑战。在近期的相关综述工作中,文献[3]对深度学习与数据库领域的交叉问题进行了总结,分析了部分深度学习模型应用于查询接口、查询计划、众包与知识库、时空数据等数据库应用的可能性。文献[4]总结了人工智能技术在数据库系统的实现方式和存在问题,选取有代表性的研究成果介绍了人工智能在数据库多个方面的研究进展并提出未来研究方向。文献[5]概述了机器学习技术与数据库关键组件中具体问题的结合方式与存在的问题,并分析了现有的问题解决方式,对进一步融合机器学习与数据库关键技术给出展望。文献[6]从存储管理、查询优化、自动化数据库管理系统三方面对数据库系统的机器学习化研究进行归纳,分析已有技术并指出了未来研究方向及可能面临的问题与挑战。
与上述工作相比,本文将侧重于数据管理中的查询处理与优化问题。图1 展示了本文总体内容路线图,以常见数据库管理系统的层次架构为划分依据,有针对性地对人工智能赋能的查询处理与优化技术中数据存取(智能索引)、查询优化(包括代价估计、技术估计、索引选择、连接顺序优化、近似查询优化、联合查询优化等)、系统运维(包括数据配置与调优、查询负载分析与预测)等关键性问题的发展近况进行更全面系统的回顾与分析,剖析不同人工智能技术应用于查询处理与优化各环节的优势与不足,详尽地梳理人工智能赋能的查询处理与优化新技术中的主要挑战与解决方案,并探讨发展方向,为未来的研究工作奠定基础。
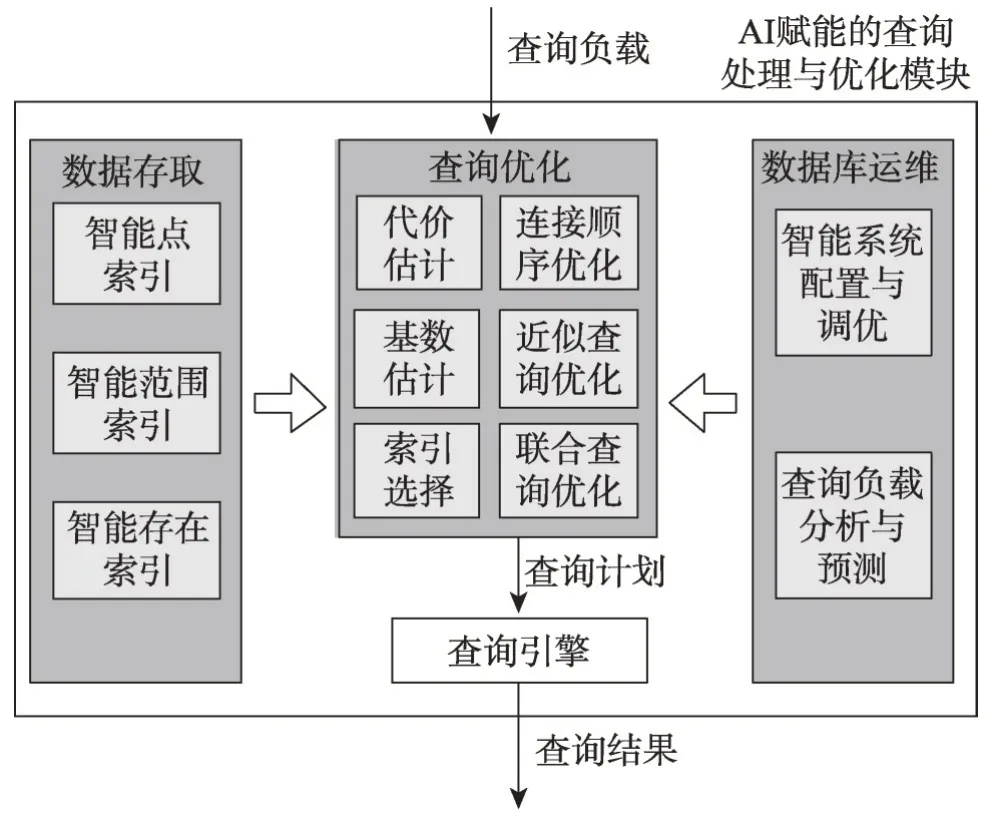
Fig.1 Roadmap of contents of this paper图1 本文内容路线图
2 人工智能技术
人工智能(artificial intelligence,AI)是研究让计算机来模拟人的思维过程和智能行为(比如学习、推理、思考、规划等)的技术科学,主要研究计算机的智能原理、制造类似于人脑的智能计算机,以实现更高层次的计算机应用,例如机器人、语言识别、图像识别、自然语言处理等[7]。机器学习作为人工智能的核心内容,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。与传统的为解决特定任务、硬编码的软件程序不同,机器学习不需要为机器编写专门的业务逻辑代码,由机器通过通用的机制对大量的数据分析学习,用于真实世界中事件的决策和预测。下面对数据库优化管理中几种常用的人工智能技术进行简单介绍。
2.1 神经网络
神经网络是机器学习中重要的技术。神经网络是由具有适应性的简单单元组成的广泛并连的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应[8]。如图2 所示,神经网络通常由一个具有层级结构的加权图表示。图中的每个节点被称为一个神经元,是一个真实神经元的功能抽象。神经网络的每一层由若干个神经网络组成,每层的神经元与下一层神经元全连接。每一层的神经元将前一层神经元的输出值作为输入,并根据权值和函数计算神经元的输出。在现实任务中,神经网络大多使用反向传播算法进行权值训练。

Fig.2 Example of neural network图2 神经网络示意图
2.2 强化学习
强化学习是一种针对马尔可夫决策过程(Markov decision process,MDP)的随机优化技术[9],常用的算法包括Q-learning、Policy Gradients 等。强化学习利用试错法使机器能够根据交互环境中的自身行为和经验反馈学习一个策略。如图3所示,机器在时间t收到环境告知的当前状态st,机器根据策略执行动作at,环境将给出这个动作的奖励值rt。接下来环境将给出机器t+1时刻的状态st+1。不断重复这个过程,直到机器完成任务。由此,状态、动作、奖励值构成了机器的经验数据。强化学习的目标则是根据经验数据最大化累计奖励值,学习最优的策略。
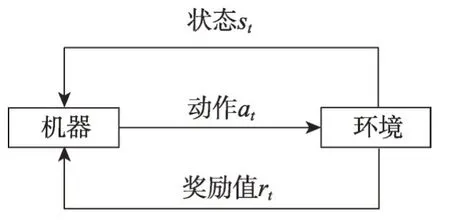
Fig.3 Example of reinforcement learning图3 强化学习示意图
强化算法可以分为基于模型的方法(model-based)与免模型的方法(model-free)。前者主要发展自最优控制领域,通常先通过高斯过程(Gaussian process,GP)或贝叶斯网络(Bayesian network,BN)等工具针对具体问题建立模型,然后通过机器学习或最优控制的方法,如模型预测控制(model predictive control,MPC)、线性二次调节器(linear quadratic control,LQR)、线性二次高斯(linear quadratic Gaussian,LQG)、迭代学习控制(iterative learning control,ICL)等进行求解。而后者更多地发展自机器学习领域,属于数据驱动的方法。通过大量采样估计机器的状态、动作值函数或回报函数,从而优化动作策略。
2.3 卷积神经网络
卷积神经网络(convolutional neural network,CNN)是早期专门针对图像识别问题设计的神经网络。其核心是通过局部操作对特征进行分层采样,利用共享参数提高训练性能。如今,CNN 也被用于自然语言处理中[10]。
CNN 包括3 种层结构,即卷积层、池化层与全连接层。卷积层将输入数据加入一组卷积滤波器,每个滤波器通过卷积计算提取特征。同一层的卷积滤波器共享权值,降低模型复杂度。池化层通过执行非线性采样,减少网络需要学习的参数个数,简化输出。池化方式包括最大池化、加和池化、均值池化、最小值池化和随机池化等。全连接层用于提取数据特征。
CNN的主要优势在于:(1)能够较好地适应图像的结构;(2)同时进行特征提取和分类,使特征提取有助于特征分类;(3)权值共享能够减少网络的训练参数,简化神经网络结构,提高了模型适应性。
2.4 循环神经网络
循环神经网络(recurrent neural network,RNN)是一种根据“人的认知是基于过往的经验和记忆”这一观点提出的特殊神经网络结构。RNN以序列数据作为输入,节点之间按时间顺序连接成一个有向图。RNN具有记忆性、权值共享并且图灵完备,因此能以很高的效率对序列的非线性特征进行学习。如今,RNN已成功地用于自然语言处理中[11]。
RNN 的模型结构如图4 所示,主要包括输入、输出和一个神经网络单元。与普通神经网络不同,RNN 的神经网络单元不仅仅与输入和输出存在联系,其与自身也存在一个回路。这种网络结构使上一个时刻的网络状态信息将会作用于下一个时刻的网络。
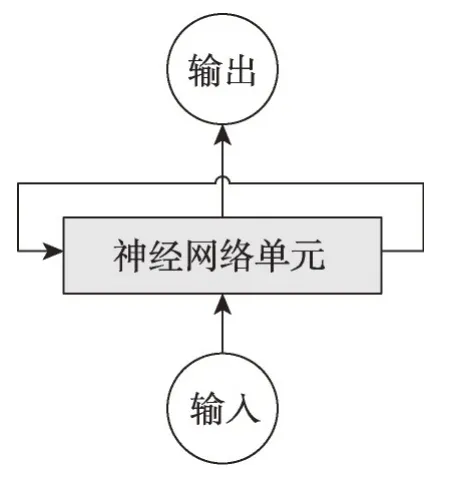
Fig.4 Example of RNN图4 循环神经网络示意图
由于RNN 在实际应用中有梯度消失问题,为解决该问题,研究人员提出带有存储单元的RNN——长短期记忆网络(long short-term memory,LSTM)。LSTM 比标准的RNN 更适合于存储和访问信息[1]。LSTM较RNN增加了输入门、输出门、忘记门三个控制单元。当数据输入模型时,LSTM中的控制单元会对该数据进行判断,符合规则的数据会被留下,不符合的数据则被遗忘,以此解决神经网络中长序列依赖问题。
2.5 数据查询处理与优化任务区别于传统人工智能任务的技术挑战
比起传统的AI 任务,如分类、聚簇等,数据查询处理与优化任务有着特殊的复杂性和多样性。将现有的机器学习算法应用到数据查询的各个阶段,要充分考虑这些特点和挑战,甚至要探索新的定制化机器学习算法来满足这些特殊需求。数据查询处理与优化任务区别于传统AI 任务,主要包括以下四个技术挑战。
(1)面向关键性任务的机器学习算法可解释性。传统AI 任务往往基于预测,具有很大的不确定性。数据查询处理与优化的一些关键性任务(如连接顺序、索引选择等)要求提供确定性的服务,而很多机器学习特别是深度学习算法的有效性内部机理并未完全清楚,缺乏可解释性,对可能出现误差的边界缺乏有效的估计,应用到关键性任务会带来很大的风险甚至严重后果。
(2)面向多样性负载的机器学习算法适配性。传统机器学习任务往往面向单一类型的数据和指定的任务类别,而新一代的大数据管理系统通常要求具备处理多样化数据、工作负载并兼容新硬件环境的适配能力,不同任务的查询分析语义和要处理的数据形态分布都具有巨大的差异,且在任务到达前不可预测。如何提高学习模型的泛化性和自适应性面临巨大的挑战。
(3)面向数据更新的机器学习算法时效性。传统AI 任务往往面向静态的训练数据,但数据查询处理与优化技术需要能够处理频繁的数据更新甚至数据流。数据的动态变化将导致原有的模型失效,预测准确性严重下降。如何针对数据管理任务的数据更新特点,定制有效的增量机器学习和在线机器学习算法,面临巨大的挑战。
(4)机器学习和传统数据查询处理与优化方法的可协作性。当前阶段,机器学习不可能完全替代传统的数据查询处理与优化方法,两类方法需要相互协作,取长补短。当两种方法共存在同一系统时(如传统索引和学习型索引共存),如何使不同类方法充分协助,达到整体性能的最大优化,面临巨大挑战。这需要深入分析不同阶段和不同任务中两类方法的增益边界,探索不同方法之间的交互和数据共享模式,以及自适应的调度和切换策略。
3 人工智能赋能的查询处理与优化技术的相关研究
AI赋能的查询处理与优化新技术将AI与数据查询问题相融合,将AI渗透于数据查询的多个方面,提供更有效的数据查询与优化手段。本文通过调研,将现有相关研究成果分为四类:(1)智能数据存取新技术,即AI用于数据存储组织、压缩和索引。(2)AI赋能的查询优化技术,即AI 替代整体传统查询优化器或部分组件,预测基数、代价,生成查询计划等。(3)智能系统调优技术,即AI用于系统负载的预测及配置的自动调优。(4)AI 赋能的数据库系统/原型系统。本章将对各类研究内容进行详细的整理和比较分析。
3.1 智能数据存取新技术
随着数据量的飞速膨胀,数据存取的性能面临着巨大的挑战。高效的数据存取离不开索引技术,索引技术是提高查询性能的重要方法之一。在过去的几十年中,已提出了多种不同的索引结构[12],例如用于基于硬盘系统的B+树[13],用于内存系统的T-tree[14]及平衡树[15]等。
不同的数据组织特征、用户查询需求及索引策略决定了查询性能的优劣,合理的索引设计必须要建立在对各种查询的分析、预测以及数据组织的特点上。在现有数据库中,通常使用B 树进行范围查询,使用HashMap进行单值查询,使用Bloom过滤器检查值记录是否存在。研究人员专注于索引性能优化的研究,以获得更高的内存、缓存和CPU(central processing unit)效率。然而,目前采用的索引并未利用如数据分布等数据特征,导致在一些情况下数据查询的性能低下。例如,在自动驾车、电子商务网站等应用中产生了大量以时间戳为主键,传感器读数为数值的数据。若数据表中包含多个相同数值但时间戳不同的数据,数据库管理系统将为每一条数据建立索引。随着时间推移,索引的增长将占用大量的存储空间。此外,若使用B 树对以上数据建立索引,查询一条数据的时间开销为O(nlbn),但若根据数据分布计算数据位置,查询开销可降低为O(1)。
针对通用数据索引存在的问题,研究人员提出了多种学习索引,根据数据的分布预测数据的存储位置,降低索引存储空间,提升查询效率,相关研究如表1 所示。索引类型分为基于B 树的混合学习索引与基于深度模型的学习索引,基于B树的混合学习索引混合传统索引算法与学习型索引结构,提升传统索引性能。基于深度模型的学习索引完全摆脱传统索引算法,仅根据训练数据生成的经验概率分布函数估计数据位置。
3.1.1 基于B树的混合型学习索引
Galakatos 等人[16]设计了一种混合树结构与学习算法的近似索引A树,如图5(a)、图5(b)所示。为了利用数据的分布构建更有效的索引,A树提出基于动态规划的分段算法,将数据划分为大小不同的段,每段是一个已排序的连续数组。对于每段中的数据构建线性模型,使用线性插值算法学习数据的分布函数。段中任何点的插入位置与准确位置的误差不超过错误阈值err,DBA 能通过设置err平衡A 树的空间开销与查询性能。数据分段后,A树将段组织到树结构中,如B+树或FAST(fast architecture sensitive tree)等,每个树结构节点仅存储起始关键字、斜率以及具体页面的指针,树结构能够有效地支持插入与查询操作。A 树的查询操作分为两步:第一步为树搜索,根据树结构搜索叶子节点;第二步为段搜索,根据插入位置和错误阈值进行局部搜索(二分搜索等)。A树为每个段设置一个缓存区,将被插入数据加入相应的缓存中,缓存区满时,根据分段算法对段进行更新。

Table 1 Learning indexes classification表1 学习索引研究分类

Fig.5 A tree schematic diagram proposed by Galakatos et al图5 Galakatos等人提出的A树示意图
IFB(interpolation-friendly B-trees)树索引由Hadian等人于文献[17]中提出。如图6(b)所示,与只对叶子节点查询加速的A树相比,IFB树索引利用线性插值方法建立辅助模型,在查询的不同阶段改进经典索引。Hadian等人认为B树查询中,节点内部搜索占用了相当大的时间开销。针对这一缺陷,作者利用辅助模型直接预测查询节点位于下一层节点中的位置,避免了内部搜索,查询过程如图6(a)所示。由于辅助模型并不改变B树的结构,因此IFB树与B树具有一致的理论性能保证。但由于插值算法对于不同的节点的误差不同,若存储多个插值将难以保证B树的效率与开销。为此,IFB 树设置最大错误阈值Δ。建树时,若节点的插值位置的错误阈值小于Δ,则将节点标记为插值友好,使用插值算法查询,对于非插值友好节点,则使用传统方法进行查询。

Fig.6 IFB tree schematic diagram proposed by Hadian et al图6 Hadian等人提出的IFB树示意图
3.1.2 基于深度模型的学习索引
Kraska 等人[18]提出了构建学习整体索引的研究思路。作者认为了解数据的分布将高度优化数据库系统中使用的索引。然而在大多数现有的数据库系统中,为每个数据库设计专用的存储方式代价十分高昂。因此,作者提出使用机器学习挖掘数据的模式和相关性,从而以低工程开销自动生成索引结构,称为“学习索引”。学习索引能够提供与传统索引结构相同的语义保证,同时在性能上也能获得极大的提升。在文献中,作者分别以B 树、HashMap、Bloom过滤器为例,提出将学习索引应用于范围索引、点索引及存在索引。
对于范围索引,作者将范围索引视作一个输入关键字预测值记录位置的模型,提出相同语义的递归模型索引(recursive-model index,RMI)。如图7 所示,RMI 利用层次结构缩小问题空间。每层的模型输入关键字,输出下一层的模型选择,直至输出数据记录的位置。RMI 能够在不同层中混合多种模型,如神经网络、ReLU 激活函数或线性回归模型等,以满足每层中搜索子空间的精度。对于点索引,Kraska等人利用底层数据的分布函数训练机器学习模型代替传统的哈希函数,减少冲突。对于存在索引,作者提供了两种思路:其一是将存在索引作为一种二元分类问题,训练分类器区分关键字与非关键字;其二是训练哈希函数,最大化关键字之间的冲突及非关键字之间的冲突,同时最小化关键字与非关键字的冲突。

Fig.7 RMI proposed by Kraska et al图7 Kraska等人提出的RMI模型示意图
文献[18]所提出的学习索引中,假设机器完全学习了关键字的经验分布函数,预测查询关键字在数据存储表页中的位置,降低内存与计算开销。然而,训练后的RMI模型仅适用于只读数据。随着关键字的插入和删除,关键字的经验分布函数与初始经验分布函数将产生显著偏移,使用初始经验分布函数将降低学习索引的性能与精度。基于以上缺陷,Hadian等人[21]提出基于参考点的学习索引更新算法,参考点即已知偏移距离的点。算法利用查询点左侧右侧两个参考点进行插值计算,估计查询点的偏移量。查询时根据查询点的预测位置及偏移量计算查询点的真实位置。学习索引更新算法避免了对模型的重新训练,并确保输出位置在错误窗口之内。
对于文献[18]中学习Bloom过滤器,Mitzenmacher[19]提出了简单的改进方法,提高过滤精度,增强学习Bloom 过滤器的鲁棒性。作者将学习Bloom 过滤器夹在两个小规模Bloom过滤器中,如图8所示。预过滤器首先过滤输入中假阳性的数据,备份过滤器对学习索引中生成的负例进行筛选,获得假阴性的数据。

Fig.8 Improved learning Bloom filter proposed by Mitzenmacher图8 Mitzenmacher提出的改进的学习Bloom过滤器
基于学习索引的启发,Oosterhuis 等人[20]挖掘机器学习用于倒排索引优化的潜力,研究学习索引如何支持倒排索引中常见的基于布尔交集的查询。作者将每个文档作为一个单独的属性集合,使用学习Bloom过滤器,判断文档是否包含某属性。由于这种方法的查询成本与集合中文档的数量成正比,因此作者提出基于两层检索的方法与基于块的方法缩小查询空间,降低查询成本。实验证明,学习索引与当前索引相比提供了空间优势,有巨大的研究潜力。
以上学习索引中,部分模型能够处理数据更新,例如IFB树对传统B树进行优化,对能保证预定义的误差值范围内的节点使用线性插值,但仍维护顶层的B树结构。A树的核心思想与RMI模型相同,但采用线性模型而非深度模型,因此可在较短时间内对模型进行重新训练。A 树与IFB 树使用经典索引结构或简单的模型,限制了通过学习索引可能获得的潜在性能增益。然而,使用复杂模型对数据建模的索引,并不能直接适用于更新数据,需要对数据定期重新训练或使用有效的更新算法,校正索引误差。
基于B 树的混合型学习索引通过机器学习的方法优化B树节点的内部查询速度,并减少硬盘的访问次数,但索引仍采用B 树结构,无法突破B 树的瓶颈。基于深度学习的学习索引使用多个神经网络替换传统的索引结构,通过学习数据的分布构建索引模型,为数据索引提供了新的研究方向。然而,目前基于深度学习的学习索引的研究工作主要围绕Kraska提出的初步研究想法,还存在大量值得研究的问题,如:(1)Kraska 的研究主要针对只读数据库系统,如何在数据更新频繁的场景下进行高效的学习索引训练。(2)针对学习索引中机器学习模型的选择问题,需要进一步实验与分析。(3)学习索引缺乏可解释性,没有理论支持,值得进一步研究。
3.2 AI赋能的查询优化技术
查询处理优化是一个传统的数据库问题。目前大多数数据库系统的查询优化器使用复杂的启发式和代价模型来生成查询计划。但现有的查询优化器在一些情况下可能无法提供最优的查询计划,因此在近期的研究中,研究人员使用机器学习、深度学习算法替代传统查询优化器或其组件,如代价模型、连接计划枚举、基数估计等,以提供更优的查询计划[2,22]。本节对AI赋能的查询优化技术的研究现状进行介绍。
3.2.1 连接顺序优化
连接顺序优化问题已被研究近40年且仍是数据库系统研究中的重要问题之一,对查询性能有很大的影响。连接顺序优化问题的挑战即枚举一组候选连接顺序并选择代价最小的作为查询计划。由于连接顺序优化问题是NP难问题,因此现有研究中经常使用启发式算法缩减查询空间,搜索最优的连接顺序。例如,System R[23]使用动态规划找到代价最低的左深连接树,而PostgreSQL[24]使用贪婪算法选择低开销的关系对,直到构建一个树。许多商业产品(例如SQL Server[25])允许DBA 确定结构约束或在一段时间后结束枚举。然而,当代价模型是非线性时,启发式算法通常会错过良好的执行计划[26]。更重要的是,传统的查询依赖于静态策略,不能从过去的经验中学习,缺乏经验反馈,因此会重复选择次优计划。
针对启发式方法的缺陷,研究人员将不同的强化学习算法应用于连接顺序优化。强化学习不仅从根本上降低了启发式算法的开销,而且能通过过去的经验训练模型,应用于所有工作负载的连接顺序优化问题。人工智能赋能的连接顺序优化方法比较如表2 所示。Marcus 等人提出连接顺序枚举器ReJOIN[26],使用强化学习中策略梯度算法学习连接选择策略。ReJOIN中状态变量为二元连接子树结构和连接/选择谓词的特征表示向量,利用多层神经网络输出当前状态对应的连接动作发生的概率分布以选择下一个连接动作。当所有关系连接完成时,ReJOIN根据优化器的代价模型对连接顺序给出奖励值。Krishnan等人[27]提出一个基于Q-learning算法的DQ(deep Q-learning)优化器。Q-learning是强化学习中基于值的算法,核心为Q(s,a)函数,即在某一时刻的状态s下采取动作a能够获得收益的期望。相较于策略学习的强化学习算法,Q-learning 对任意连接子计划的连接均计算得分而不是直接选择最优连接,能够使用查询计划的多个子计划进行训练,极大地降低训练数据量需求。DQ 优化器由当前表连接结果生成的查询图作为强化学习状态,连接操作作为强化学习动作,使用两层DNN(deep neural network)表示Q函数,训练Q函数的参数。在训练时使用数据库系统代价模型评估动作的奖励,计算Q函数值,在查询时每次选择DNN输出Q值最小的连接计划。
以上两种方法都依赖于大量的训练数据,即从过去的查询计划中学习知识优化下一次的查询。同时,两种方法都使用基于粗粒度数据统计或简化假设(数据独立、均匀分布等)的代价模型作为强化学习的奖励。当模型估计错误时,两种算法的连接计划可能无法达到最优。基于以上考虑,Trummer等人[28]提出一个全新的数据库系统SkinnerDB,不需要任何查询上下文数据及基数估计模型,即可提供可靠的连接顺序选择。SkinnerDB的框架如图9所示。查询时,SkinnerDB的预处理器首先通过一元谓词过滤基表,接着由连接处理器生成查询的连接顺序与执行结果,最后调用后继处理器对结果进行分组、聚合与排序等操作。连接处理器包括4个组件,连接处理器将每个连接操作分为多个时间片,每个时间片首先由学习优化器选择连接顺序,选中的连接顺序由连接执行程序执行,每次执行固定时长,并将执行结果加入结果集中。执行程序可以使用通用的SQL(structured query language)处理器,也可以使用专门的执行引擎。进程跟踪器跟踪被处理的数据,最后由奖励计算器计算连接顺序的得分。当所有数据被连接后,完成连接操作。学习优化器使用强化学习领域的上限置信区间算法[29](upper confidence bound apply to tree,UCT),在每个时间片中根据连接顺序的枚举空间生成搜索树,并选择一条路径。UCT 算法的特点即不依赖任何具体示例的参数设置,能够适用于较大的搜索空间。

Fig.9 Framework of SkinnerDB proposed by Trummer et al图9 Trummer等人提出的SkinnerDB框架图
表3是3种连接顺序优化算法的实验结果对比分析。对于相同的查询负载数据JOB(join order benchmark)[30],3 种算法分别集成于不同执行引擎以达到最低的查询计划执行时间。在对查询计划执行时间的改进方面,与PostgreSQL 相比,3 种算法能够在不同程度上提升连接顺序优化的效率,降低查询计划执行时间,其中SkinnerDB 最高能将查询计划执行时间降低74.7%,但必须依赖于特定的执行引擎。在学习收敛性方面,虽然ReJOIN 与DQ 使用相似的强化学习模型,但在训练中,DQ 仅需要80 次迭代即可超越PostgreSQL 的执行时间,而使用ReJOIN需要约8 000 次迭代才能达到PostgreSQL 的查询开销。这是由于DQ 优化器使用了off-policy gradient的Q-learning方法,将训练数据的利用率提升了两个数量级。

Table 2 Comparison of join order optimization methods表2 连接顺序优化方法比较

Table 3 Experimental comparison of join order optimization methods表3 连接顺序优化实验结果比较
3.2.2 查询性能预测与学习代价模型
查询性能预测用于预测查询延迟,是多种数据管理任务的重要基础,如访问控制、资源管理和维护SLA(service-level agreement)等。影响查询延迟的因素包括查询计划、基层数据分布等。虽然传统的查询优化器能够对候选查询计划的开销进行准确的估计,但随着数据库管理系统的更新和发展,新的操作符或物理组件将引入新的交互,而某些难以建模的交互将无法准确预测查询计划的执行延迟。下面对人工智能赋能的查询性能预测与学习代价模型研究展开介绍,相关文献比较如表4所示。
Akdere 等人[31]提出基于机器学习的性能预测技术,分别在不同粒度对查询性能建模。粗粒度的计划级模型利用支持向量机(support vector machine,SVM)、核典型相关分析(kernel canonical correlation analysis,CCA),根据查询计划中手动选择的特征向量,估计执行计划的延迟。细粒度的操作符级模型对每类操作符建立两个独立的预测模型:启动时间模型与运行时间模型。启动时间模型对应于操作符自身运行时间,运行时间模型对应于多次嵌套循环等情况下的总执行时间。操作符级模型利用多元线性回归模型(multiple linear regression,MLR),将单个操作符模型以分层的方式组合,通过特征选择算法选择后的操作符特征向量计算任意查询的延迟时间。然而,两种粒度的模型对查询性能预测都具有缺陷。计划级模型仅对与训练数据具有类似查询计划的场景具有较好的性能,而操作符级模型由于分层结构可能将底层的模型估计错误传播至上层,因此作者提出两种粒度混合建模方法,适用于普遍的查询性能预测问题。
与上述方法类似,现有研究已包含多个利用机器学习和统计方法的性能预测工作,但解决方法主要集中于手工设计的指标、基于计划级信息的训练模型、基于关系运算符的数学模型等[35]。这些方法通常需要人工专家进行大量工作,且随着数据库管理系统的复杂性的增加,算法的可扩展性很差。除此之外,由于查询延迟与查询计划结构、中间结果的特征和操作符相关,而查询计划结构并不固定,因此传统的静态模型,如DNN等,无法对多种基于树结构的查询计划建模。基于以上两点考虑,研究者们近期提出了基于树结构的学习模型用于代价估计与预测。Marcus 等人[32]提出与查询树结构完全相同的DNN模型,如图10(a)、图10(b)所示。模型为每个逻辑操作符建立一个神经网络单元,计算该操作符用于基数估计的数据向量与用于代价估计的延迟向量。叶子节点输入自身的操作符类型、结果基数估计、I/O需求估计的向量,中间节点接收左右子节点输出的数据向量与延迟向量,并根据自身操作符的特征向量计算结果。根节点神经网络单元的延迟预测作为查询计划的延迟。
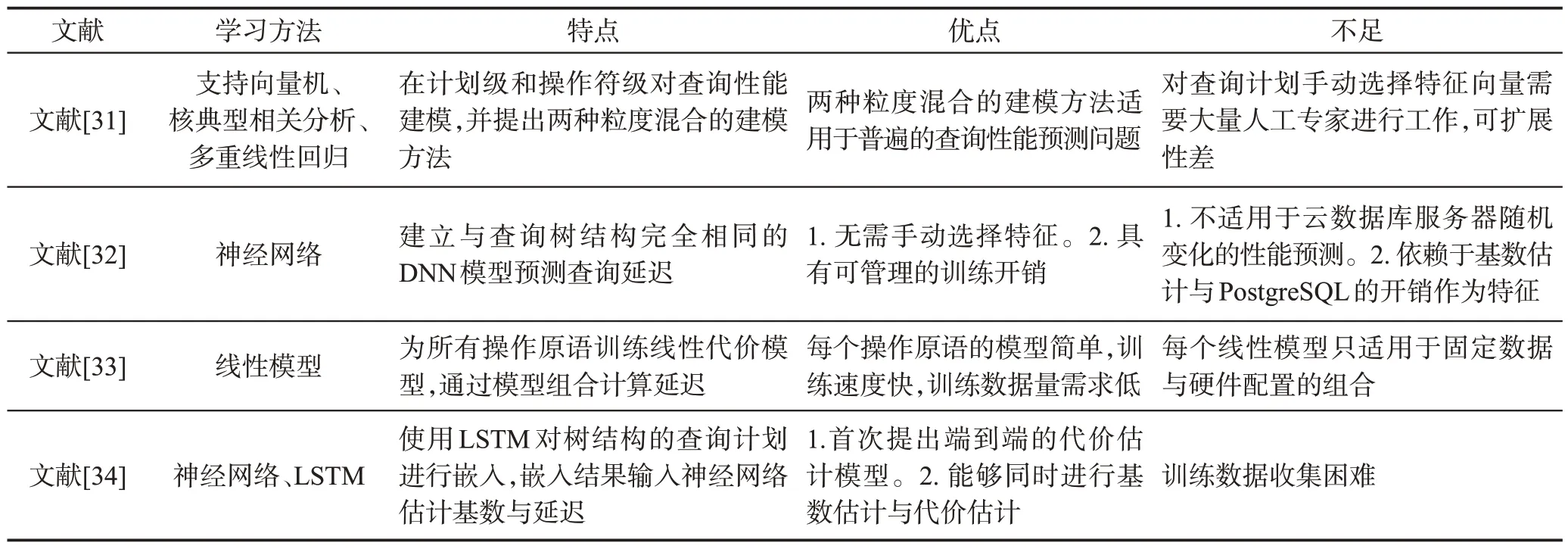
Table 4 Comparison of query performance prediction methods and learning-based cost models表4 查询性能预测方法与学习代价模型比较

Fig.10 Plan-structured DNN proposed by Marcus et al图10 Marcus等人提出的查询计划结构DNN
表5为两种查询性能预测方法的实验结果比较,其中SVM 为文献[31]提出的方法,DNN 为文献[32]提出的方法。在TPC-H 工作负载下,DNN 的预测查询延迟与实际查询延迟的相对误差率与平均绝对误差较SVM分别降低了24个百分点与15 min,证明了手动特征选择难以获取操作符之间的复杂关系。在模型收敛性方面,DNN需要大于1 000次的迭代才能达到收敛,耗时超过28 h,但当迭代次数超过250 次时,DNN的平均绝对误差即可超过SVM的性能。

Table 5 Experimental comparison of query performance prediction methods表5 查询性能预测方法实验结果比较
在近期学习代价模型的相关研究中,Idreos等人[33]将所有操作划分为细粒度的原语,并为所有操作训练一个简单的代价模型,通过原语的组合计算任意复杂操作的延迟代价。Sun等人[34]使用LSTM对查询树进行嵌入,从叶子节点递归地训练查询计划的向量表示。LSTM输入操作符左右子节点的表示向量,输出当前节点的表示向量。最后将查询计划的嵌入输入一个两层全连接神经网络估计基数与延迟。
对于两种学习代价模型,虽然文献[33]未对单独的代价模型组件性能进行实验评估,但通过对整个引擎的数据存取预测延迟与真实延迟的对比实验,可间接证明学习代价模型能够降低预测误差。文献[34]在多个数据集下对比完整模型与不同变体的准确性,验证了模型设计的合理性。
3.2.3 基数估计
在基于代价的查询优化技术中,基数估计是评价查询计划的重要手段,其任务是估计查询执行计划中的每个操作符返回的元组数量[35]。基数估计的质量将直接影响查询计划的选择与查询优化器的性能。因此,高精度的基数估计十分重要。然而,大多数传统的估计方法都是基于如数据一致性与独立性等假设的统计模型,在真实数据集中,数据经常不满足假设,导致基数估计出现较大的错误[30,36-37],使优化器生成次优的查询计划。为了克服传统方法的限制,Lakshmi 等人[38]第一个提出基于神经网络的用户自定义函数谓词基数估计算法,将自定义函数谓词转化为数值输入神经网络,预测谓词返回的元组数量。Malik等人[39]根据查询结构(连接条件、谓词属性等)利用决策树对查询分类,并对每类查询训练不同的回归模型进行基数估计。受到以上两个研究的启发,以及人工智能技术在其他查询优化问题的优秀表现,研究人员开始探索人工智能在基数估计问题上的潜力,相关文献比较如表6所示。
Liu等人[40]提出了针对选择谓词基数估计的增强神经网络框架,学习范围查询谓词的上下界与谓词选择率之间的映射函数,选择率即衡量谓词降低基数能力的指标。但选择率函数是不连续的,为了使神经网络能够学习非连续的选择率函数,如图11 所示,作者改进了传统神经网络结构,将隐藏层中的数据单元根据跳转函数进行分组,在使用时根据输入选择隐藏层中的不同单元。Hasan等人[41]认为非监督学习与监督学习算法皆可适用于选择谓词基数估计问题。非监督学习算法利用传统的抽样基数估计思想,将谓词选择率估计建模为一个密度估计问题,使用自回归模型将数据的联合分布按照链式法则分解为多个条件分布,利用屏蔽自编码器[45](masked autoencoder for distribution estimation,MADE)学习多个自回归条件分布。监督学习算法将编码后的查询输入两层的神经网络,估计正则化的选择率。
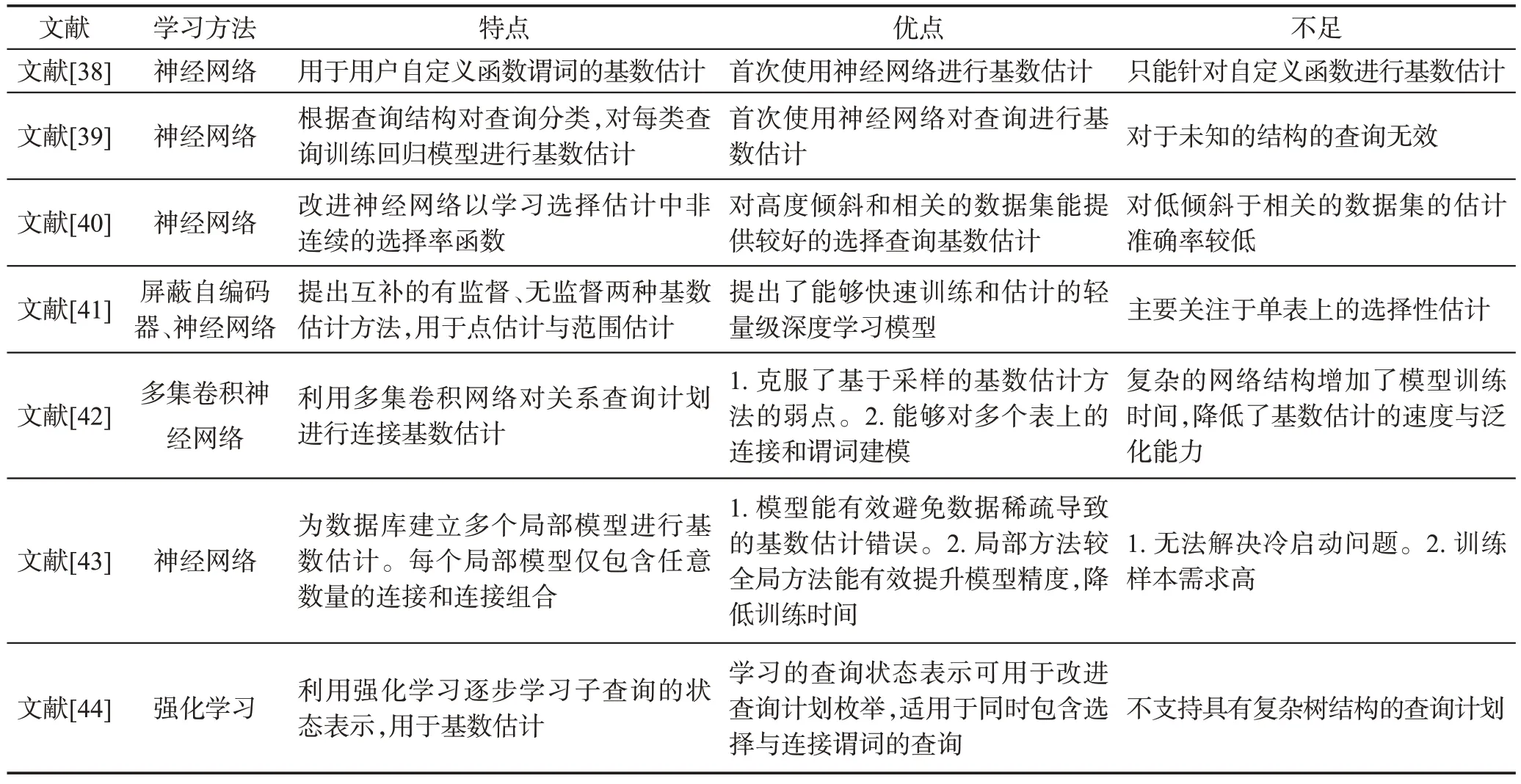
Table 6 Comparison of cardinality estimation methods表6 基数估计方法比较

Fig.11 Structure of enhanced NN proposed by Liu et al图11 Liu等人提出的增强神经网络结构图
文献[40]中的增强神经网络模型、文献[41]中的两种基数估计算法在实验中均能够超越传统基数估计算法。其中,在高相关与倾斜的数据下,对于等式谓词与范围谓词的查询基数估计,增强神经网络模型较DB2在Q-error[41]值上分别降低了98.7%与65.0%,但在低相关与倾斜的数据中,增强神经网络模型基数估计的准确度可能降至个位数。文献[42]提出的两种基数估计模型在Census 数据集中,平均估计准确度是贝叶斯网络算法2倍,最低准确度达到贝叶斯网络算法的100倍,且训练时间降低了93.75%。
Kipf等人[42]发现查询的基数独立于查询计划,因此使用多集卷积神经网络(multi-set convolutional network,MSCN)模型,有监督地估计连接查询基数。模型框架如图12所示,首先对表、连接与选择谓词三个集合分别训练单独的模型,再对三个集合的输出进行连接,输入到最终的DNN 中估计查询基数。上层的DNN将获取集合与基数估计值之间的相关性。训练时,除了用于训练的查询语句外,算法还将符合条件的基表的样本信息特征化,生成表示每个基表符合条件的位图,将位图作为深度学习模型的额外输入训练模型参数。

Fig.12 MSCN model proposed by Kipf et al图12 Kipf等人使用的MSCN模型图
MSCN 算法对整个数据库视图创建一个全局学习模型,但是全局学习模型在训练时容易出现训练数据稀疏的问题。为了克服这一问题,Woltmann 等人[43]提出一种面向局部的建模方法,为数据库建立多个局部模型。每个局部模型对应任意数量的连接和连接组合,输入操作符和数值的表示向量,利用DNN进行基数估计。
Ortiz 等人[44]提出使用强化学习算法的基数估计方法,能用于同时具有选择与连接操作的查询。算法将基数作为奖励,学习数据库执行查询计划的一个操作后新的状态向量的函数NNST以及状态向量与基数的映射函数NNobserved。如图13所示,在执行时,按照查询计划依次利用NNST与NNobserved计算查询计划返回的条目数量。
与PostgreSQL 相比,训练后的MSCN 与局部建模方法(LOCAL NN)对基数估计的准确性与执行速度上均有很大程度的提升,如表7所示。实验数据证明,MSCN复杂的网络结构需要较长的训练时间与执行时间。此外,局部建模方法较MSCN的全局学习方法能够获取精确的数据相关性,提升估计的准确性。
3.2.4 近似查询处理引擎
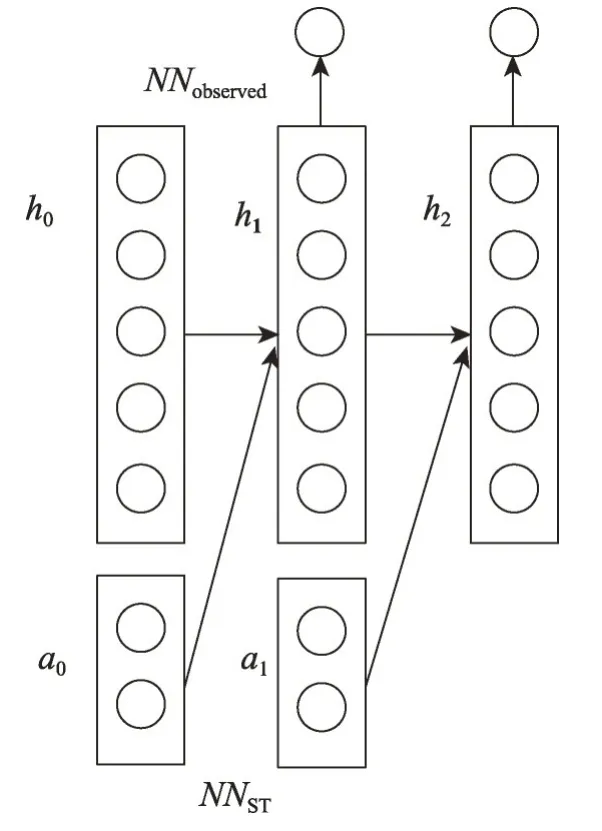
Fig.13 Reinforcement learning model proposed by Ortiz et al图13 Ortiz等人提出的强化学习模型图

Table 7 Experimental comparison of cardinality estimation methods表7 基数估计方法实验结果对比
在大数据时代,数据驱动的决策已成为超越竞争对手的主要手段,但计算准确的大规模数据库查询结果的开销极其昂贵。因此,能够有效进行近似计算且具有高准确性的查询方法具有很高的研究价值。传统的近似查询处理研究大多基于采样方法,在查询执行过程中对数据进行动态采样,以回答近似问题,或根据查询负载预测,对表和列进行线下采样,保存在内存中,处理查询任务。虽然传统的近似查询处理算法能基本处理近似查询问题,但存在以下三个明显缺陷:第一,错误率高、内存开销大;第二,算法无法支持许多重要的数据分析任务;第三,较低的查询响应时间,传统的算法要求在大型数据分析集群上执行并行查询,但集群的获取和使用的成本很高。针对以上问题,近期人工智能赋能的近似查询处理引擎研究相关文献比较如表8所示。
Ma等人[46]提出了一种基于机器学习模型的DBEst近似查询引擎,引擎保证了对部分数据的聚集函数(例如,COUNT、SUM)进行高精度和高效近似查询。DBEst的框架如图14所示,DBEst首先离线对部分底层数据库表和属性采样,根据样本训练密度估计器和回归模型。DBEst 使用核密度估计[48]方法作为密度估计器,核密度估计能够对任意维度的数据提供较高精度和较高效率的建模。回归模型采用增强的回归树模型[49-52],模型能够从小样本中构建有效的数据模型。在查询时,DBEst首先判断是否存在模型支持近似查询,对于模型能够支持的查询,DBEst利用密度估计器和回归模型建立的数据分布推断近似查询结果。

Table 8 Comparison of approximate query processing engines表8 近似查询处理引擎比较
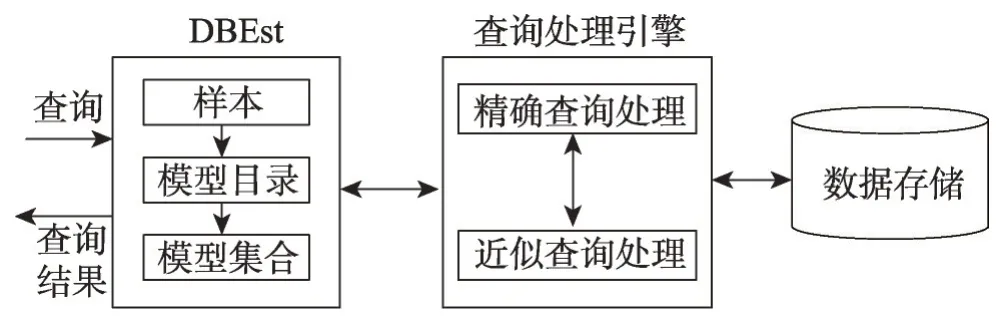
Fig.14 Framework of DBEst proposed by Ma et al图14 Ma等人提出的DBEst框架图
Thirumuruganathan 等人[47]利用深度生成模型进行近似查询处理,通过变分自编码器(variational autoencoder,VAE)对整个数据库或对多个不相交的子数据库建模。在查询时,DBMS(database management system)不需要访问底层数据集,而根据深度生成模型生成大量查询相关的数据样本,并使用现有的近似查询处理技术[53-54]计算查询结果。由于生成模型不能准确地学习底层分布,生成的样本将会产生误差。为解决这一问题,作者提出一种基于拒绝抽样的方法[55]缩小模型与真实数据的分布偏差,提升近似查询的准确性。
通过分析两种近似处理引擎的实验数据,两种近似处理引擎较当今最先进的近似查询处理引擎在查询准确率、查询速度、查询空间开销方面皆存在较大的提升。其中,DBEst 即使只有较少的采样数据,对部分聚集查询的相对误差不超过10%,说明模型泛化能力强,能够从非常小的样本构建模型。同时DBEst的空间开销比近似查询处理引擎VerdictDB[56]低1~2个数量级,证明了模型的紧凑性。但对于复杂的查询,文献[52]提出的VAE模型的准确性更高。这是由于VAE 模型能够生成任意数量的样本,实现较低的查询误差。
3.2.5 索引选择
索引选择问题是查询优化问题的一部分,为特定数据集与查询计划确定最合适的索引方法。现有的索引选择器[57-61]根据查询优化器的代价模型,搜索具有最低执行代价的索引配置。但由于优化器的限制,在很多情况下,索引选择器推荐的索引配置将提高查询的执行代价。
针对以上索引选择存在的问题,研究人员引入机器学习方法用于索引选择。近期人工智能赋能的索引选择方法比较如表9 所示。Ding 等人[62]对索引选择过程中面临的关键问题,如何比较基于不同索引配置的两个计划的执行代价进行研究。研究者将问题作为三元分类任务,对给定的两个查询计划,首先提出一种编码方式将查询计划编码为维度相等的向量,然后利用分类器将代价较高的计划标记为“退化”,将代价较低的计划标记为“改进”,其他情况标记为“不确定”。Vu[63]提出使用深度神经网络建立索引选择系统。首先计算数据集的直方图矩阵并将其转化为一个向量,然后将向量输入深度神经网络模型中,模型根据索引性能预测最优的数据索引。索引的性能指标使用基于抽样的索引方法作为训练数据。Qiu等人[64]针对基于代价模型的索引选择方法无法准确估计索引的优化效果和维护代价的问题,以及无法利用数据分布的缺陷提出了一个面向关系数据库的智能索引选择系统。系统由查询分析、候选索引生成与索引选择三部分组成。其中索引选择模块使用机器学习对索引优化效果建模,计算每个候选索引的实用值,并设计递归算法选择最优索引。

Table 9 Comparison of index selection methods表9 索引选择方法比较
3.2.6 学习查询优化器
以上基于人工智能的查询优化算法都是针对查询优化器的特定组件的研究,如查询表示、基数估计、代价模型、连接枚举器等,但研究大多都依赖于使用启发式的优化器估计基数、物理操作符选择和执行代价。文献[65]提出了一个端到端的基于深度学习的查询优化引擎,利用多种深度学习模型替代传统优化器的多个组件,但以上研究并没有接近于学习整个优化器的方法。虽然这些研究较传统方法的性能得到大幅度的提高,但并没有证明以上的查询优化技术能够达到最先进的性能。因此,学习整个优化器具有较高的研究价值。若训练后的查询优化器能与商业系统具有旗鼓相当的优化性能,将大大降低查询优化器所需的开发与维护时间。
Marcus 等人[66]首次提出用于整个查询优化的端到端学习方法——神经优化器(Neo),包括连接排序、索引选择以及物理操作符选择。Neo的框架如图15 所示,在Neo 运行之前,Neo 首先利用专家查询优化器(例如Selinger PostgreSQL)生成负载样例中每个查询的查询计划和查询延迟,查询计划与查询延迟加入经验数据集合中,用于训练和更新查询优化器值模型。值模型是一个DNN 模型,模型的框架如图16所示。值模型分别将独立于查询计划的查询特征与查询计划进行编码和压缩,合并成扩充树,利用树卷积方法[67]预测查询计划的最终执行时间。在运行时,Neo 根据用户的查询请求与训练后的值模型,通过最佳优先搜索算法[68]在查询计划空间中迭代地搜索最低开销的执行计划。从强化学习的角度看来,Neo 利用值模型的搜索过程其实是一种值迭代技术[69],循环地评估值函数,并使用值函数改进策略。最后,将计划搜索的结果输入数据库执行引擎中,并将查询的真实延迟记录加入经验数据,改进值模型的参数。

Fig.15 Framework of Neo proposed by Marcus et al图15 Marcus等人提出的Neo框架图
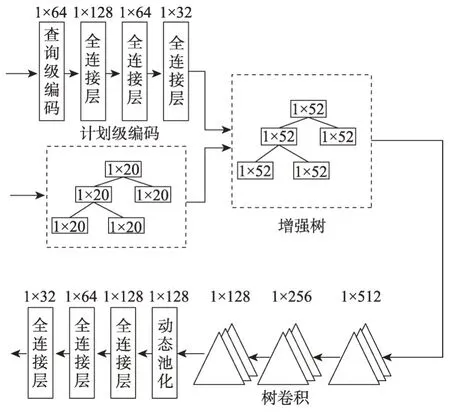
Fig.16 Structure of value model proposed by Marcus et al图16 Marcus等人提出的值模型结构图
3.2.7 联合查询优化
除了以上介绍的查询处理优化新技术外,Xu 等人[70]也将人工智能技术用于优化联合查询。联合查询是在包含第三方数据源的数据库中执行的具有跨数据库连接的查询。与传统查询执行相似,联合查询首先生成查询计划,然后根据查询计划在多个数据库执行。查询计划在由每个数据源执行完成后,数据库选择一个数据源作为联合引擎执行连接等操作。错误的联合引擎选择可能导致需要在数据源之间大量地移动数据,或不恰当地为每个组件分配工作。Xu等人提出基于随机森林回归的动态联合引擎选择,对于每个数据源使用大多数数据库系统都可以提供的EXPLIAN PLAN 数据作为输入,生成计划运行时间,以此选择联合引擎。
现有AI赋能的查询优化技术研究主要集中于查询优化器的三个主要部分,连接顺序优化、代价模型与基数估计。同时也有部分工作对近似查询处理、索引选择、整体查询优化器与联合查询优化进行研究。AI赋能的查询优化器结合机器学习与深度学习算法,根据查询优化经验、查询结果与真实查询性能改善查询优化策略,提高查询基数与代价估计的准确性,在优化性能上被证明接近甚至优于传统方法,并且能够处理传统方法难以优化的复杂查询问题。基于以上研究,对于查询优化器的重要部分仍有许多问题值得进一步研究。
针对连接顺序优化,现有工作的研究思路主要使用强化学习模型学习连接选择策略,基于强化学习的连接顺序优化存在以下问题:(1)模型每次迭代根据查询延迟真实值作为奖励值调整神经网络参数,模型收敛的实际计算开销很大。(2)传统代价模型无法准确估计查询代价,影响依赖于传统代价模型的算法性能。(3)强化学习需要大量的训练数据才能保证模型的性能。因此,无法应用于数据库构建早期或缺乏训练数据的场景。
针对代价模型,现有工作主要根据查询计划建立操作级或树结构的神经网络模型预测查询代价,面临的主要挑战是查询计划的特征选择问题,手动特征表示可扩展性差且低质量的特征表示将降低算法的性能,如何实现对查询计划中多种谓词、逻辑符号、数据类型的自动编码是亟待解决的问题之一。
针对基数估计问题,现有工作打破了传统基数估计方法对数据均匀性、一致性和独立性的假设,实现了更好的基数估计性能,已经对数据库性能产生良好的影响。与代价模型类似,基数估计也存在特征选择的问题。此外,Sun 等人于文献[34]提出的同时估计基数与代价的研究思路也值得进一步的研究。
3.3 智能系统调优技术
如今,数据库与大数据分析系统如Hadoop、Spark等都设有大量的配置参数,用于控制内存分布、I/O优化、并行处理与数据压缩,错误的参数设置可能导致显著的性能下降,并对稳定性造成影响。而依靠有经验的数据管理员(DBA)对功能丰富、结构复杂的数据库系统进行配置、管理、调优会使系统的总体拥有成本(total cost of ownership,TCO)变得很高。因此,为了有效地降低系统的总体拥有成本,数据库自调优是长久以来的研究问题[71]。配置参数调优工作主要分为六类:基于规则的自动调优、基于代价模型的自动调优、基于模拟的自动调优、实验驱动的自动调优、基于机器学习的自动调优和自适应调优[72]。基于机器学习的自动调优的优点在于能够捕捉复杂的系统动态,独立于系统内部和硬件且基于对系统性能的观察数据进行学习。
(1)基于神经网络的调优。Rodd等人[73]与Zheng等人[74]都提出使用神经网络估计工作负载的特定配置。前者利用缓存命中率与数据表大小通过神经网络计算缓存大小与共享内存池大小。后者将数据缓冲区命中率、库缓存命中率与内存排序率输入神经网络,输出缓存大小、共享内存池大小与PGA(process global area)聚合目标的参数数值。
(2)基于多种机器学习方法的调优。Van Aken等人[75]提出一个多步骤的调优工具Otter-Tune,通过学习历史数据中DBA的经验值推荐可能的配置参数设置。Otter-Tune 首先分析对性能指标最有影响力的配置参数,并利用因子分析[76]与K-means[77]聚类将高维DBMS指标数据转换为低维向量。删除冗余指标后,Otter-Tune使用正则化的最小二乘法回归模型Lasso[78]根据与系统性能的相关性对配置参数排序。在自动调优时,Otter-Tune将目标工作负载的指标与已调优的历史负载的指标进行比较,匹配最相近的历史负载,然后利用历史负载训练高斯过程回归[79],推荐配置参数值。
(3)基于强化学习的调优。由于Otter-Tune采用流水线的学习模型,每步之间存在依赖关系,前一步的最优解无法保证为后一步的最优解,因此Zhang等人[80]设计了一种使用强化学习的端到端自动云数据库调优系统CDBTune。CDBTune使用深度确定性策略梯度(deep deterministic policy gradient,DDPG)模型[81]学习参数优化策略,在高维连续空间中搜索最优的配置参数值。在CDBTune中,状态向量包含63个云数据库的性能指标,奖励值为执行配置参数修改后的系统性能差异。在训练中,CDBTune 利用试错策略,避免了传统强化学习模型中对大量训练数据的需求,同时降低了陷入局部最优的可能性。Li 等人[82]提出查询敏感的数据库调优系统QTune,提供查询级、负载级、簇级三种粒度的调优。Li等认为,现有的深度强化学习模型忽略了查询对环境状态的影响,因此提出了双状态深度确定性策略梯度模型(doublestate deep deterministic policy gradient,DS-DDPG)进行查询敏感的配置参数调优。DS-DDPG模型的结构如图17所示,其中实线表示数据输入,虚线表示调优反馈,模型包括5个组件,其中预测器、执行器与评价器都是深度神经网络。对于负载中的每个查询,模型首先将查询转换为向量,输入预测器中。预测器用于预测处理查询前后外部性能指标差异。环境将指标差异与当前指标相加生成新的观察值用于模拟查询执行后的性能指标。执行器根据新的性能指标生成调优动作,环境执行动作并生成奖励值发送给评价器,用于更新评价器参数,评价器为执行器生成的动作计算得分(Q值),更新执行器参数。DS-DDPG通过同时学习Q函数与策略解决连续空间中的最优问题。
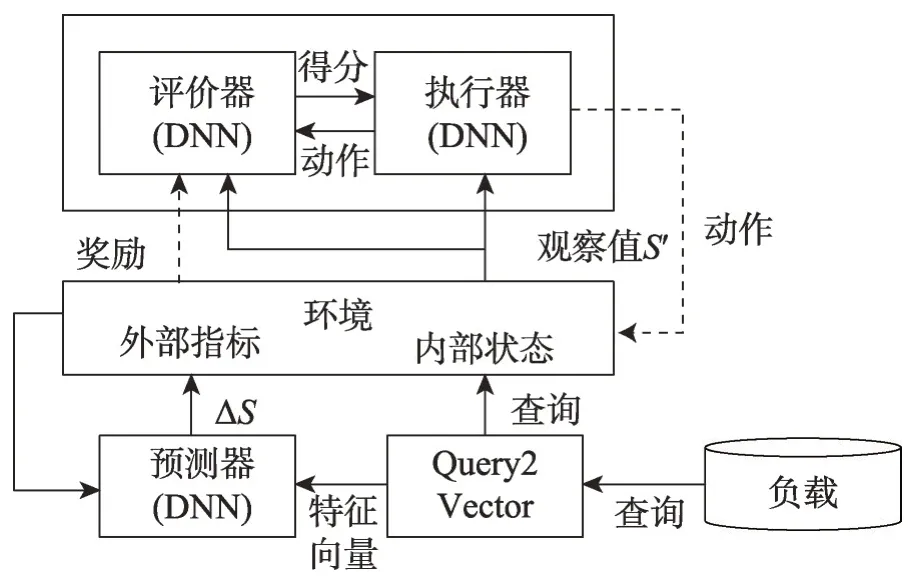
Fig.17 Structure of DS-DDPG proposed by Li et al图17 Li等人提出的DS-DDPG模型结构图
除了有效的自动调优方法外,查询负载预测也能帮助数据库系统提前选择适当的配置参数,适用于不同类型的查询负载。Ma等人[83]提出QueryBot5000框架用于学习历史负载数据预测数据库未来工作负载。框架包括预处理、聚簇器与预测器三部分。预处理将大量查询数据简化为通用模板,聚簇器对模板根据到达率历史进行聚类,预测模型使用核回归与循环神经网络模型预测查询模板聚类到达率模式作为输出结果。
智能系统调优技术能够有效利用历史负载信息与数据库性能表现提高数据库在查询处理与优化等多方面的性能。现有工作提出了适应不同的应用场景的调优模型,无需DBA 参与给出最优的调优推荐结果。对于智能系统调优技术,还存在许多值得研究的问题,如:(1)对于硬件环境、负载和数据库的动态变化,自调优技术需要快速适应并推荐参数配置。(2)模型训练需要大量高质量的样本采集,如何降低训练样本依赖性需要进一步探讨。
3.4 AI赋能的数据库系统/原型系统分析
随着数据库系统的不断革新,数据库系统已逐渐满足大数据时代的应用要求,在多个领域起着举足轻重的作用。但传统数据库仍存在诸多局限性亟待解决,如依赖于DBA 维护、缺乏特殊性等。因此,研究人员将人工智能技术应用于数据库系统中,提出了多种AI 赋能的数据库系统与原型系统,利用人工智能技术优化部分或全部数据库系统的功能或组件,以实现数据库系统的自优化、自配置、自监控等功能[84]。目前,工业界已发布了多个AI 赋能的数据库系统,如Oracle自治云数据库[85]、GaussDB[86]等。
近期AI 赋能的数据库系统/原型系统研究如表10所示。Peloton[87]是第1个自主数据库管理系统,无需DBA 指导,利用3.3 节中介绍的QueryBot5000 框架预测查询负载,逐步优化查询延迟,且在部署期间不会对应用程序造成明显的影响。Oracle 自治云数据库内置机器学习算法支持基于负载特性的自动缓存、自适应索引、高效压缩与云数据加载,提升数据库系统性能。同时,支持自治修补、自治更新、自动安全性管理以保证安全性。GaussDB 采用人工智能技术融入分布式数据库的全生命周期,实现数据库系统自运维、自管理、自调优、故障自诊断、自愈合,其中自调优性能比同类产品提升60%以上。此外,GaussDB还支持异构计算。

Table 10 Comparison of AI-powered database systems/prototyping systems表10 AI赋能的数据库系统/原型系统比较
Kraska等人在文献[2]中提出了一个全新的数据库原型——学习数据库系统SageDB。SageDB 利用机器学习模型通过程序自动生成数据库系统组件。作者对数据库系统提出了新的展望,如果成功,将产生新一代的大数据处理工具,将更好地利用GPU(graphics processing unit)和TPU(tensor processing unit),且在存储方面具有显著优势。SageDB 与现代数据处理系统重视数据、硬件和负载的特性不同。SageDB 的架构如图18 所示,SageDB 主要分成两部分,分别是机器学习和代码生成。通过机器学习,对数据的分布、工作负载大小以及硬件进行建模,得到数据结构、优化的访问方法和查询计划。代码生成将学习的模型嵌入数据库的各组件中。Kraska 等人分别在数据存取、查询执行、查询优化、先进分析等组件对SageDB进行初步的设计和实验。实验证明,SageDB 能够有效提升数据库性能,具有很高的研究价值。
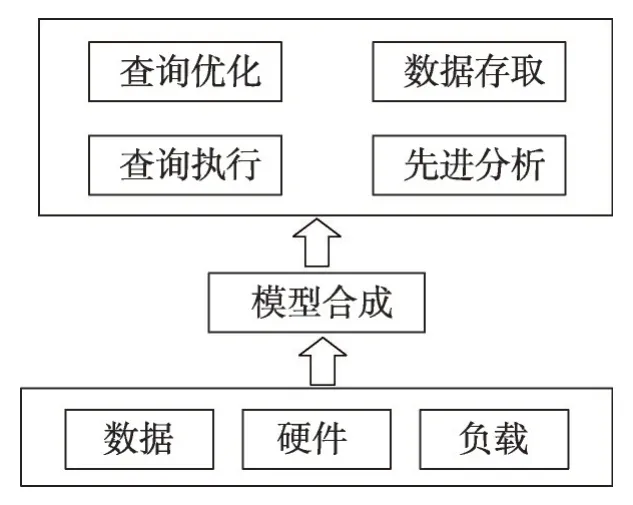
Fig.18 Framework of SageDB proposed by Kraska et al图18 Kraska等人提出的SageDB的架构图
AI 赋能的数据库研究仍然处于早期阶段,现有工作的设计目标主要针对数据库特定方面的优化,且没有考虑模型之间的配合、通信与参数配置等问题。AI赋能的数据库研究未来工作的主要目标是设计并实现具有高效数据存取、查询的自主管理的学习数据库系统。
3.5 小结
当前人工智能驱动的查询处理与优化技术在各方面都取得了一定的进展,但研究大多以对查询优化器中的各组件的优化为主,其他组件仍然依赖于传统数据库系统的优化器,而极少考虑整体优化器的学习技术。虽然Marcus等人提出的Neo能够学习整体优化器,但训练模型需要基于规则或代价的传统优化器提供模型的先验知识,难以实现优化器在不同数据库的泛化。可见,人工智能驱动的查询处理与优化技术有待进一步研究,提高优化器的性能。
4 主要挑战
上述研究成果已在数据查询处理与优化的多方面提出了展望性的想法并进行了初步的实现,取得了一定的研究成果。从现有的研究思路与研究成果可以看出,AI 赋能的查询处理与优化技术研究中主要面临如下挑战。
(1)数据查询处理与优化问题的建模方法。查询处理与优化作为一个传统的数据库问题,当前大多数的数据库系统都使用复杂的启发式算法估计基数,预测代价,生成查询计划。但传统的启发式算法由于无法总结过去的经验,可能导致重复地生成次优的查询计划。因此,研究者们通过一组SQL 查询语句与元数据,构建学习模型,解决查询处理与优化中的相关问题。在上文中总结的AI赋能的查询处理与优化新技术中,研究分别将传统的查询处理与优化问题建模为不同的机器学习或深度学习问题。其中,不同的建模方式为问题的解决方法带来了不同的优势。例如文献[39]中,将选择估计问题转化为对有限样本的联合概率分布的密度估计问题,能够有效支持点查询与范围查询的基数估计,而利用查询语句与真实基数估计值训练的DNN模型则能够在几毫秒内预测查询基数。除此之外,问题的建模也对训练开销及对复杂查询的适应性产生了影响。因此,如何对不同场景中查询处理与优化问题的建模方法是AI赋能的查询处理与优化技术的主要挑战之一。
(2)查询的特征表示方法。神经网络等机器学习模型通常使用数值向量作为输入,查询的特征表示用于将查询语句转化为包含查询信息与数据统计特性的数值特征向量。随着研究的发展,传统依赖于专家的手工特征选择方法逐渐被替代,研究者们提出了多种适用于问题模型的特征提取与编码方式,例如对物理查询操作、查询谓词、元数据和数据进行one-hot 编码,或利用学习模型学习查询谓词语义,生成嵌入向量等。建立语义丰富的向量化查询表示作为模型的输入,能够有效提高模型的泛化能力。在建模过程中,必须要考虑适当的查询特征表示方法,以保证模型的质量。
(3)学习模型的训练问题。在现有的AI 赋能的查询处理与优化技术中,大多数模型必须进行高质量的参数训练,但真实数据库中,大规模的数据、多种查询谓词、聚合函数、数据表连接将导致稀疏的训练数据采样,无法获得高质量的训练数据。例如,一数据库中有6个包含5个属性的数据表,每个属性存在1 000种候选值,数据库仅包含3个谓词{<,=,>},该数据库的采样空间将包含6 048 000条不同的查询语句。更重要的是,尽管现有的研究对所提出的方法在多个评价标准上进行了测试,但训练和测试的场景依然十分有限,无法保证新技术的通用性。目前,在AI 赋能的查询处理与优化新技术中,只有少数研究关注于训练过程,模型的训练问题尚未获得足够的重视。
(4)学习模型的维护。目前的研究一般都假设数据库模式和底层数据都是静态的。虽然所学习的机器学习或深度学习模型能够包容数据分布和相关性的细微变化,但是在某些情况下,学习模型必须进行调整或重新学习。因此,模型维护是当前AI 赋能的查询处理与优化技术的重要挑战。模型维护必须研究的核心问题是是否有可能将知识从一个给定的模型转移到另一个具有不同数据特征的模型中。学习模型的维护是AI赋能的查询处理与优化新技术仍需努力的方向。
5 未来研究方向展望
随着技术的发展,机器学习与深度学习在数据管理领域被越来越多地研究,AI 赋能的查询处理与优化新技术引起了广泛的关注,并且在多个工作中展现了巨大的潜力。但由于研究时间较短,仍有许多关键性问题值得深入探索。本文将对AI赋能的查询处理与优化技术总结为以下5个研究展望。
(1)智能高维数据存取新技术。当前的学习索引研究通过机器学习技术学习数据的分布预测数据所在的存储位置,主要针对低维数据提出设想并进行测试与评估。然而在真实数据库应用中,高维数据已成为数据存储的常态,高维数据的高效访问需求不容小觑。随着机器学习与深度学习算法的不断发展,部分机器学习模型不仅能够学习低维数据分布,还可以有效地捕捉复杂的高维数据关系,为高维数据存取技术提供了新的研究思路。因此,未来可针对高维数据的智能数据存取技术进行深入研究,将学习索引扩展到高维数据中,预测任意属性组合的数据所在位置。
(2)端到端的学习查询优化器。在近期的人工智能研究中,端到端学习正逐渐成为一种热门的学习方法。传统方法通常将问题分解为子问题,例如传统的图像识别问题往往将图像识别问题分解为预处理、特征提取和选择、分类器设计等子问题,然后对子问题分别学习单元模型得到子问题的最优解,但子问题的最优解并不一定是全局问题的最优解。端到端的学习范式则忽略人为的子问题划分,模型直接学习由原始数据到期望输出的映射函数。端到端的学习查询优化器能够避免研究中子问题模型依赖于传统数据库优化器的弊端,并能够根据查询的特征向量生成全局最优的查询计划。在未来的工作中,探索端到端的学习查询优化器可能会为AI 赋能的查询处理与优化问题提供更多的见解。
(3)AI 赋能的时空数据查询处理与优化技术。随着移动计算、全球定位系统、GIS 等相关技术的发展,大量现实世界中带有时空信息的物理对象被存储在数据库中。时空数据作为常见的数据类型,常用于趋势分析、进程建模和预测分析,应用范围遍及交通、气象检测、军事等多个领域。在时空数据库系统中,时空数据存储与查询处理是保证对时空对象有效建模的关键技术,已成为时空数据库研究的焦点。如今,深度学习模型,如CNN 模型与RNN 模型已经能够对空间的内接矩形与时间序列建模,这为智能数据存取技术扩展到时空数据提供了契机;而在现有的研究中,深度学习模型也被用于不同的时空问题中,如车流预测、旅行时间估计与驾驶行为分析等。由此可见,AI 驱动的时空数据查询处理与优化问题是未来具有前景的研究方向之一。
(4)面向图数据库的智能查询处理与优化技术。近年来社交、电商、物联网等行业产生了庞大而复杂的关系网,传统数据库难以处理关系运算,图数据库应运而生。图数据库使用图结构进行语义查询,存储数据含节点、边和属性。图数据库利用图结构相关算法,如最短路径、节点度关系查找等,处理复杂的关系数据。虽然图数据库相比关系数据库能够有效提升数据管理效率,但常见的图算法往往包含大量的针对整个图的迭代计算,不利于查询效率的提升,并增加了计算的开销。近期,基于图嵌入表示技术的图算法研究已经证明了AI技术在图处理问题的巨大潜力,相信AI 技术将为图数据库的存储与管理问题提供更优的解决方案。
(5)面向云数据库的智能查询处理与优化技术。第3 章所述的智能查询处理与优化技术大多数用于处理裸机服务器上执行的查询。但在云数据库服务器中,数据库的软件与硬件能够进行动态扩展,导致数据库服务器的性能随之变化,这种性能变化可以看作是随机变化。为了应对数据库系统的动态变化,未来面向云数据库的智能查询处理与优化技术研究可以通过获取系统相对性能(例如,监视I/O率、CPU周期等),或提出性能波动的检测方法,利用迁移学习等技术降低模型的训练时间,提升模型的自适应性。
6 结束语
人工智能的发展为数据查询处理与优化技术带来新的机遇,AI 赋能的查询处理与优化正在成为数据库领域的一个重要热点问题。近年来,AI 赋能的查询处理与优化新技术取得了众多进展。本文主要围绕AI 的查询处理与优化新技术进行介绍,梳理并分析了新的研究成果,总结了主要挑战和未来研究方向发展。AI 赋能的数据库技术发展前景广阔,期望本文对高性能数据库技术的研究发展有所助益。
