基于逻辑回归与置信传播的数据安全分析算法
2020-07-01李兵
李兵
(河南科技大学应用工程学院,河南 三门峡 472000)
虚拟设备是由多个虚拟机(Virtual Machine,VMs)所组成且大多依赖于软件定义下多事件资源的主机硬件。目前,虚拟设备的普及应用和广泛发展已经成为云计算服务[1-3]的重要保障,同时,虚拟设备也成为网络攻击者进行非法访问攻击的重要目标。网络攻击者利用管理程序源代码中的软件漏洞发起复杂攻击,可突破访客VMs进行底层管理程序的访问;另外,攻击者还可利用操作系统内部的漏洞对虚拟设备发起攻击以获取访客虚拟机的登录细节[4-9],并执行从权限升级到分布式拒绝服务(Distributed Denial of Service,DDoS)的攻击,因此,针对虚拟设备的安全保护至关重要。目前,虚拟设备的安全保护方法主要分为二种,即恶意软件检测[10-11]和安全分析。恶意软件检测过程通常分为二个步骤,一是监视恶意行为在虚拟化设备内的不同行为,二是使用规则更新的攻击签名数据库以确定攻击的存在。恶意软件检测可允许进行实时检测攻击,但使用专用签名数据库会使其易受到零攻击,即无攻击签名,而安全分析方法可以将分析应用于网络内不同点所获得的各种日志以确定攻击的存在。另外,利用由各种安全系统生成的大量日志进行大数据分析,可检测出未通过签名或基于规则的检测方法无法发现的攻击。安全分析通过使用事件关联检测先前未发现的攻击,以消除对签名数据库的需求,但往往无法实时执行,且内在检测无法扩展。
综上所述,本文提出了一种基于逻辑回归与置信传播的数据安全分析(Data Security Analytics,DSA)算法。该方法先通过利用网络日志以及Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)中客户VMs的用户应用日志,以确定基于图形的事件相关性,并从中提取攻击特征;再通过二步有效的机器学习——逻辑回归和置信传播提出DSA算法,以确定攻击的存在。
1 攻击检测模型
在DSA模型中,通过MapReduce解析器所标记的相关图中潜在攻击路径,可检索到不同的攻击特征,进而使用攻击特征分类器通过训练提取出攻击特征。而对于攻击存在的确定,可通过逻辑回归[12]和置信传播[13]完成检测,这是攻击检测模型的关键步骤,更是DSA算法在防御虚拟设备遭受各类网络攻击时至关重要的二个方面。
一方面,逻辑回归是一种较为快速有效的方法。首先确定测试数据是否投射到两个预定义类中的某一个,其次对训练集的分类进行快速训练,该训练集代表着一系列的特征与类。这二点充分说明逻辑回归适用于计算个别独立属性的攻击条件概率。此外,每当确定攻击存在时,可以使用新识别的攻击特征快速地重新提取逻辑回归分类器(Logistic Regression Classifiers,LRCs),以用于后期的攻击检测。
另一方面,置信传播首先涉及到条件概率的计算,以便进一步获取虚拟环境中攻击存在的置信度。置信传播针对攻击检测是一种较为完整有效的方法,可以保证所获得的置信度准确反映不同特征属性的概率贡献。
可见,攻击检测模型由二个阶段组成,一个是逻辑回归分类器的训练阶段,另一个是基于置信传播的攻击分类阶段,其中,基于训练的逻辑回归分类器可以通过从应用日志中观测到的特征计算出条件概率,但仅使用所获得的个体独立属性的条件概率并不足以获得攻击概率的完整透视图。因此,本文对观测到的所有属性特征加以利用,以检测攻击的存在,而将置信传播用于计算攻击置信度,并且仍有必要考虑所有属性特征的条件概率。
2 数据安全分析方法
DSA算法的二个关键点在于LRCs的训练和基于置信传播的攻击分类,这二个过程均需针对所有属性的特征进行观测、提取和分析,以期获取完整有效的攻击状态。
2.1 逻辑回归分类器
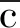
逻辑回归计算特征属性x的攻击概率P,而特征x可采用Logit函数投影到二个预定类的某一个:
(1)
设ω0,ω1,ω2,…,ωn为权系数,则
ζ=ω0+ω1x1+ω2x2+…+ωnxn。
(2)
在DSA算法中,通过式(1)对二个逻辑回归分类器LRapp和LRport进行设置。在训练时需预先在批处理中使用新识别的攻击特征进行重新训练,而后再使用各自相应的Logit函数计算特征属性的条件概率。
为了训练用于端口分析的逻辑分类器,本文收集了一组由不同恶意软件应用程序使用的300个端口号以及由合法应用程序使用的另一组300个端口号作为训练数据集。恶意软件端口号来源于SANS[14-16],而合法应用程序所使用的端口号则源于从因特网分配的编号。为了训练LRCs,所获得的端口首先被分为二组,即合法端口号的系统端口和包含恶意软件端口号的恶意软件端口。每个端口类别用一个数值加以编号,即系统端口分配值为1,恶意软件端口分配值为2,而在LRCs的训练期可将它们表示为特征向量xport。
2.2 基于置信传播的攻击分类
LRCs通过分析in_connect、out_connect、unknown_exect和port_change四个属性特征确定攻击的存在。由于遭遇攻击的客户VM往往会与远程攻击者建立外部连接,因而可能导致以上属性特征发生变化,因此,由节点表示的各个属性可形成如图1所示的贝叶斯网络。在诸如贝叶斯网络和马尔可夫随机场的图形模型中,置信传播用于计算目标节点的随机分布。不确定理论中的贝叶斯网络可在确定攻击存在时提供不同特征之间的关系表示,在此,若给定贝叶斯网络中的节点v,可利用相邻节点的边界概率计算相应状态下的置信度BEL(v)。由于置信传播可以度量相邻节点在计算节点v时置信度受到的个体影响,因此,本文提出的DSA算法可以使用置信传播用于检测攻击存在。
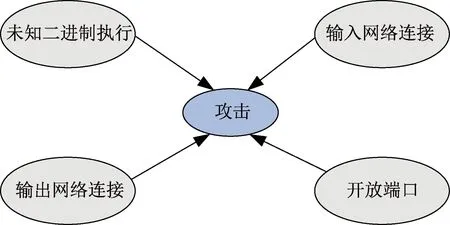
图1 4个属性的贝叶斯网络
给定的属性特征向量如下:
xin_connect=[xport_number,xport_category_value]T,
xout_connect=[xport_number,xport_category_value]T,
xport_change=[xapp_category_value,xuser_id_value,xport]T,
xunknown_exect=[xapp_category_value,xuser_id_value,xport]T,
(3)
本文采用SCIKIT训练端口和应用程序的LRCs(即LRport和LRapp)的输出作为条件概率,从而计算出二个预定义类中的特征概率,具体过程如下:
(4)
其中PAttack表示攻击属性的条件概率,PBenign表示良性属性的条件概率。
若将给定的属性直观地映射到攻击,则攻击概率(PAttack)远高于良性概率(PBenign),反之亦然。关于xin_connect和xout_connect、xunknown_exect和xport_change连接的训练集情况分别如表1、表2所示。

表1 端口与类的训练集
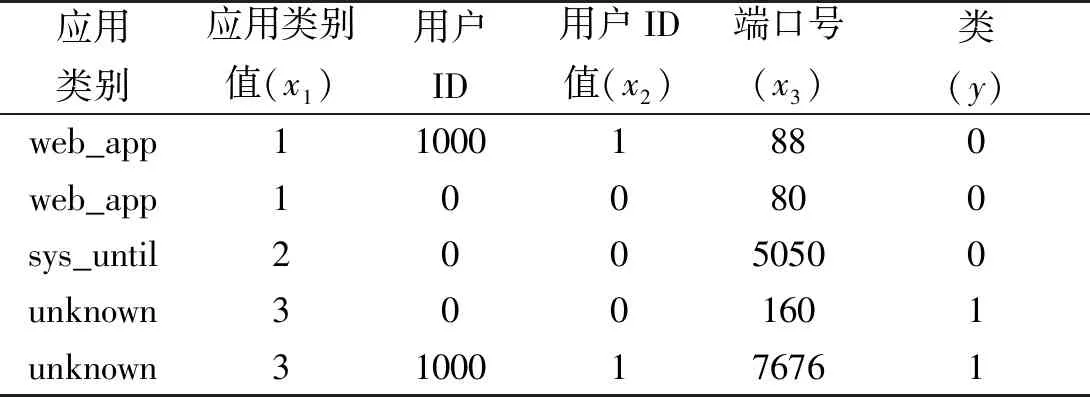
表2 应用程序的训练集
尽管经过训练端口和应用程序的LRCs提供了相对个体属性的条件概率,但却无法提供虚拟环境内的完整攻击状况,因此,当条件概率存在的情况下可将置信传播用于计算攻击的置信度。贝叶斯网络中每个节点包括一个条件概率表(Conditional probability table,CPT),其中覆盖了每个可能状态的边缘概率(即攻击或良性)。贝叶斯网络中每个节点的初始化CPT如表3所示。

表3 CPT数值
将边缘概率用CPT加以表示后,攻击结点状态的置信度BEL(v)可用消息传递的方法进行计算;贝叶斯网络中将四个特征属性的边缘概率传递到攻击结点中。在计算攻击置信度BELAttack前先将攻击概率PAttack聚集在攻击节点中,可以表示为:

(5)
贝叶斯网络因子图模拟了因子分解的结构,并针对各结点的条件概率表进行编码。通过给定置信传播的信息传递公式计算边缘概率,也说明CPTs作为因子图允许在算法执行期间更有效地跟踪本地CPT的变化。因子图Fexe、Fin、Fout和Fport表示CPT的单个属性,Fattack表示unknown_exect、in_connect和Attack之间的联合CPT,如表4所示。
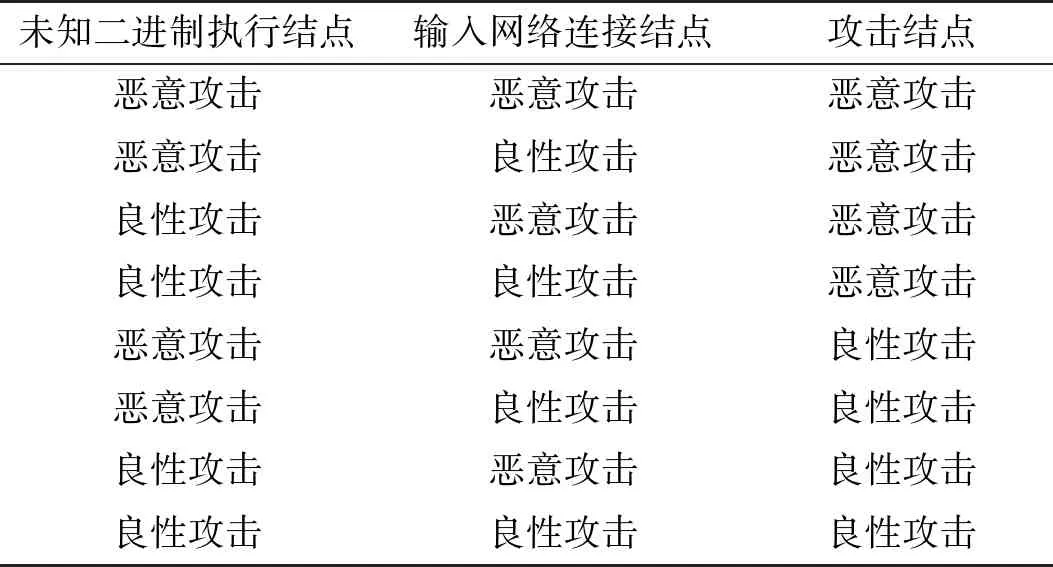
表4 关于未知二进制执行、输入网络连接和攻击的联合CPT
置信传播的信息传递过程具体为:当从逻辑回归分类器接收到边缘概率时,更新贝叶斯网络中的每个结点信息μ以表示其属性是恶意(攻击)或良性(攻击)的概率;然后,传递信息μ到各攻击结点计算其状态置信度BELAttack,并对应于贝叶斯网络中的各结点σ(σ1—unknown_exect,σ2—in_connect,σ3—out_connect,σ4—port_change)。
(6)
端口更新的信息μout、μport可直接进入攻击结点加以计算,信息μexe、μin传递到因子结点Fattack攻击中计算其条件概率分布以反映相互间的关系。在综合所有unknown_exect、in_connect结点的攻击状态前,将Fattack攻击的各项特征数值与μexe、μin相乘生成消息μattack攻击并传递到攻击结点,计算过程如下:
(7)
通过计算out_connect、port_change结点的概率值,置信度BELAttack的计算公式如下:
BELAttack=μport×μFattack×μout。
(8)
DSA中的置信传播阶段的具体步骤如下:
初始化:使用子图创建一个关于攻击特征的贝叶斯网络
输入:Pport_change,Punknown_exect,Pin_connect,Pout_connect;
第1步:设子图Fexe、Fin、Fout、Fport为每个节点CPT的初始值(表3);
第2步:使用条件概率PAttack和PBenign更新子图Fexe、Fin、Fout、Fport;
第3步:计算μexe→Attack、μin→Attack、μout→Attack、μport→Attack;
第4步:基于unkown_exect和in_connect,采用式(7)计算FAttack;
第5步:采用式(8)计算BELAttack;
第6步:若BELAttack 第7步:用新识别的攻击特征更新Cassandra数据库中的表; 第8步:算法结束。 需要说明的是,初始化阶段的初始观测值是关于单个属性先验概率的分配值,但在进入DSA算法阶段后,基于LRCs所更新的值是子节点中所包含的条件概率。 DSA算法的具体步骤如下: 初始化:从Cassandra数据库中选取良性和恶意攻击特征的初始参数 第1步:采用逻辑回归对观测的属性特征进行分类训练; 第2步:从客户虚拟机处收集网络和用户应用日志; 第3步:使用客户VMs的IP地址过滤网络日志条目,并形成相关的应用日志; 第4步:使用相关的应用日志形成相关图G; 第5步:将图G输入MapReduce解析器中识别潜在攻击路径{attack_paths},所有图路径均为图G的子集; 第6步:对于每个攻击路径,i←0; 第7步:针对每个攻击路径的属性特征,计算Pport_change、Punknown_exect、Pin_connect、Pout_connect; 第8步:将Pport_change、Punknown_exect、Pin_connect、Pout_connect输入到Step4; 第9步:算法结束。 DSA算法先从分布式Cassandra数据库中加载所有已知的恶意端口号和良性端口号,然后使用这二种端口类型训练LRCs。显然,该算法在将未知端口信息传递给置信传播模型前即可确定未知端口的恶意攻击概率。经过反复训练的逻辑回归分类器可确定任一特征属性为“恶意攻击”或“良性”,最后将其概率传递给最终的置信传播过程。置信传播过程中使用恶意攻击的所有条件概率的特征属性计算置信度,以确保所获得的最终结果不受任何一个独立条件概率的影响。 本文实验运行环境为Python,操作系统为Ubuntu 14.04,DSA实验台的系统拓扑图如图2所示。其中,服务器配置为英特尔Xeon四核处理器、Linux内核版本为3.18.18;实验中每个HPC节点上使用基于内核的虚拟机建立虚拟化环境,从而使得多个客户VM可在其上运行并支持跨节点迁移,在服务器节点上安装Apache Hadoop以支持分布式日志存储,并安装Apache Spice以提供实时数据收集和MapReduce解析;此外,安装卡桑德拉柱状数据库系统用以支持识别的恶意应用程序、端口的分布式存储和逻辑回归分类器的实时训练;最后,Python机器学习包安装在节点上以便为DSA算法创建LRCs。在仿真实验中,若置信传播计算的置信值BELAttack低于阈值0.2,则认定该攻击路径为恶意。 DSA算法是通过创建运行CENTOS 6.5的客户VM,并在HPC服务器其一节点上运行Ubuntu 14.04的另二个客户VMs加以评估的,评估内容包括检测用户空间恶意软件、内核级Rootkit攻击能力以及检测访问者VMs内存在攻击的时间。 图2 实验台系统拓扑图 DSA算法检测不同恶意软件攻击的能力是通过执行二个用户空间恶意软件程序,且在客户VMs上的二个内核级Rootkits进行评估的。恶意软件和Rootkit攻击从PacketStorm中加以获取,如表5所示。 表5 恶意软件和Rootkit攻击检测 3.2.1 用户空间恶意软件的检测 用户空间恶意软件也称为应用程序级恶意软件,其运行在客户操作系统的应用程序级别与其他合法应用程序相一致,而采用DSA算法检测用户空间恶意软件是通过在客户VMs上执行上述用户空间恶意软件进行评估的。为了运行用户空间恶意软件,首先建立一个测试场景,即一个访客VM充当攻击者,而另一个访客充当攻击受害者;然后,攻击者VM使用NETCAT监听不同的非标准端口号,进而在受害者VM上运行反向外壳代码。相同的测试场景可用于创建命令和控制僵尸网络,通过在攻击者VM上运行僵尸网络的服务器组件及其客户VM上的客户端组件。在测试过程中,用户空间恶意软件是正在执行的,且硬编码的IP地址和端口编号也是动态的。 3.2.2 内核级Rootkits的攻击检测 当用户空间恶意软件与其他合法应用程序均运行在应用程序级别时,内核级Rootkit则在操作系统的内核中运行。通常情况下,内核级Rootkits分以下二步执行:首先,Rootkit可尝试获得root级别访问操作系统;其次,Rootkits作为可加载内核模块安装到操作系统内核中。由于该访问为特权级,因而使用传统的应用级恶意软件检测方法很难检测到Rootkit。 DSA算法检测内核级Rootkit的性能是通过在客户VMs上执行XingYiQuan和Azazel rootkits进行评估的。Rootkit通过修改基础系统调用表条目且使用NETFLASH内核模块建立外部网络连接从而控制客户VMs,导致应用级防火墙难以检测通信流。而当XingYiQuan重新启动无法持续时,通过客户VM的内核启动Azazel可持续执行。当用户级恶意软件运行Rootkit时,建立了客户端-服务器测试场景,即一个访客VM充当攻击者,而另一个VM充当攻击受害者;在客户端运行Rootkit,攻击者VM使用NETCAT监听连接;二个Rootkit可执行多次,达到5个客户VMs执行次数的3倍,且在所有的情况下采用DSA算法均可检测到所有的Rootkits。通过在根级远程执行NETSTAT命令,DSA算法可检测应用程序以及正在由Rootkit所打开的端口。 测试平均检测时间是对该方法性能的进一步评估与分析。该实验具体为检测访客VMs中的攻击时间,二个用户空间恶意软件程序以及从PacketStorm所获取的二个内核级Rootkit均在客户VMs上执行。本节在三项检测实例中进行了测试,即分别为1个客户VM、2个客户VMs和3个客户VMs。每项测试中,恶意软件程序和Rootkit在客户VMs各自的执行空间中执行,而DSA算法则在HPC主机上运行。当恶意软件程序和Rootkit在客户VMs上执行时,记录每个攻击执行的检测时间。一个测试的检测时间D是在执行恶意软件和Rootkit时记录时间的总和,即 D=Tmalware1+Tmalware2+Trootkit1+Trootkit2,。 (9) 在测试中执行每个恶意软件或rootkit后,需在下次测试重复前等待大约2 min的时间间隔。不仅如此,本节还将待测试的恶意软件和新用户操作安排在客户VM上的不同执行空间,内部测试的等待有助于防止检测时间受到缓存的影响,且客户操作系统可存储频繁触发的指令以便测试更快地执行。 每项测试重复执行10次,且将连续的10次重复实验设置为一轮操作;对1、2、3客户VM的每一种情况,再分别进行5轮测试;每一轮测试后停止大约2 min的攻击,以便从HDFS中移除所收集的日志,然后再次更新到新的一轮操作;在5轮操作中对检测时间进行平均计算以消除测量的不一致性。因此,在第i个实例中的第j次测试实验中,检测时间Dij为 (10) 其中,k为测试实验的次数(k=1,2,3,4,5),i是VMs实验实例的标识(i=1,2,3),j是连续重复实验的次数(j=1,2,…,10),Dij是指将4个恶意软件程序和Rootkit攻击捆绑后作为一个包攻击客户VMs的检测时间。 因此,1、2、3客户VM执行时都需进行50次时间检测的实验,10次检测时间Dij的实验结果如图3所示。 图3 DSA算法的时间检测 由图3可知: (1)随着客户VMs数量的增多,本文提出的DSA算法对应的检测时间仅出现小幅度的增加。当使用单个VM测试时,箱形图中的中值检测时间约为0.06 ms,随着第2个VM的引入,检测时间增加到0.07 ms,其中,2个客户VMs运行不同的操作系统,分别为Ubuntu 14.04和CentOS 6.5。由于客户OS处理远程命令执行的差异,可从VMs获得客户进程列表的延迟时间。虽然2个客户OS均可处理相同的远程命令,CentOS客户OS作为其访问控制模块使用SeLinux,而Ubuntu客户OS中使用的是更为灵活的AppArmor访问控制模块。SeLinux往往会对远程命令执行更为严格的检查,且允许其在客户VM上执行,从而致使延迟时间的增加。 (2)在二个客户机VMs的情况下,定期重置内置机制以防止DDoS,二个离群点检测时间源于客户SSH服务器在一定数量的连接(此种情况下为1000)。当在Ubuntu 14.04系统上引入第3个VM运行时,中位数检测时间增加到0.066 ms,与前二个客户VMs的情况基本一致。由于2个客户OS运行了更灵活的AppArmor访问控制模块,远程客户VMs可在客户VMs上执行并得到更快的结果。然而,离群点检测次数亦从2增加至4,表明在第3客户VM中运行的访客SSH服务器正在周期性地重置自身以防止DDoS攻击。 本文针对云计算的攻击检测模型及虚拟设备的安全分析方法进行了研究,得到以下结论: (1)本文建立了虚拟设备的攻击检测模型,确定该模型的二个重要阶段——反复训练逻辑回归分类器和基于置信传播的攻击分类。 (2)针对所有属性特征分别给出了逻辑回归分类器的训练过程、边缘概率有效转换为条件概率的过程和生成贝叶斯网络因子图的过程,并提出了基于逻辑回归与置信传播的DSA算法。 (3)在保证性能的前提下,本文提出的DSA算法的平均检测时间对VM数量的增加并不敏感,具有良好的应用前景。2.3 DSA算法
3 实验结果与分析
3.1 实验设置
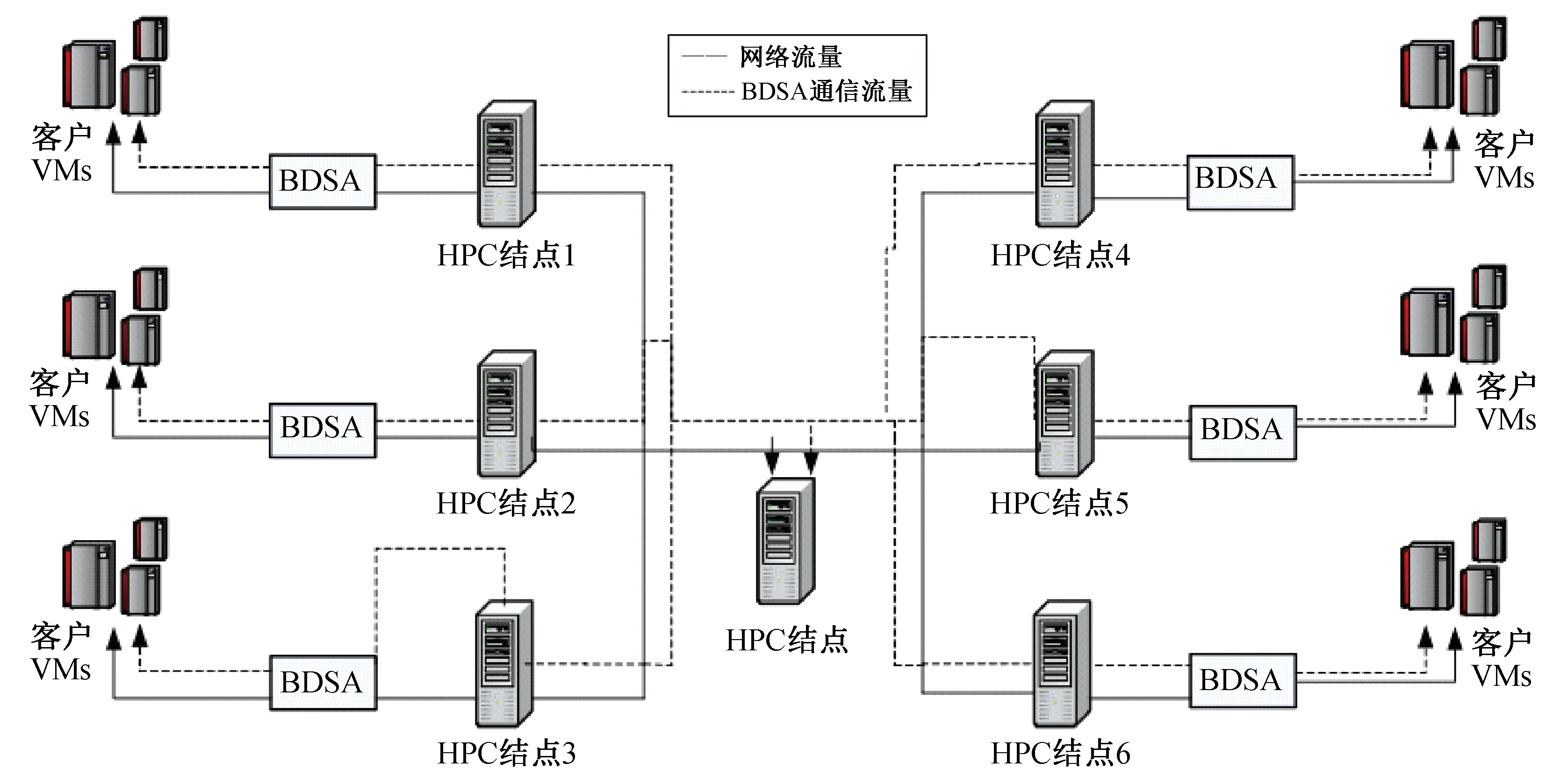
3.2 用户空间恶意软件和内核级Rootkits的攻击检测

3.3 平均检测时间的测试分析
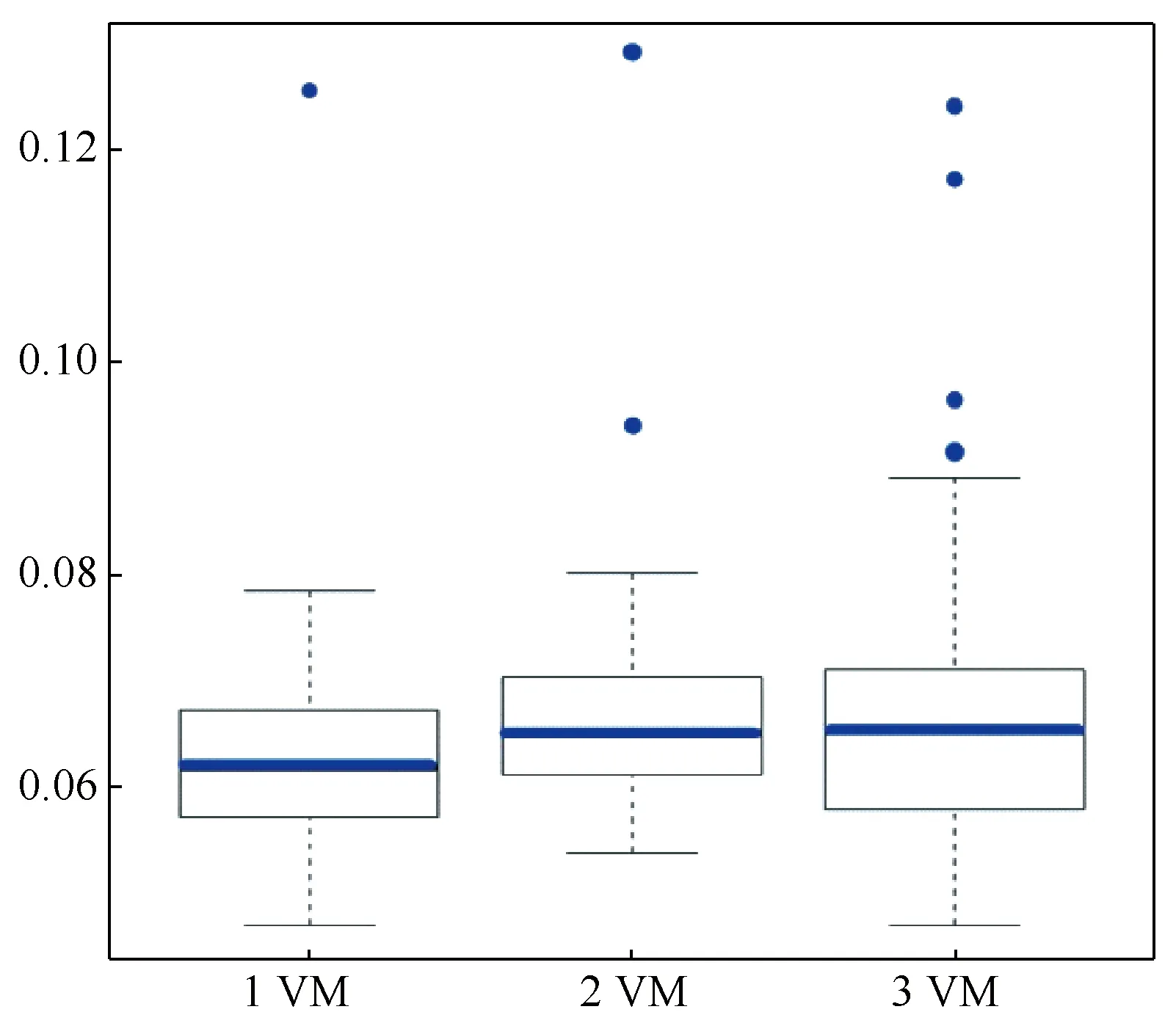
4 结论
