中国城市物流业规模分布的地区差异及动态演进
2020-06-20林双娇
林双娇,王 健
(福州大学 物流研究中心,福建 福州 350108)
一、引言及文献述评
十九大报告指出,中国经济正处于向高质量发展转型的关键时期,物流业作为支撑国民经济发展的重要载体,其高质量发展是中国经济高质量发展的关键一环。物流业高质量发展的核心要义是实现物流产业的均衡协调发展,城市物流业规模分布是物流资源配置的基本体现,可以用于评判物流业发展规模空间布局的合理性。而由于各地区资源禀赋、经济基础等条件差异较大,大型城市物流业发展基础较好,中小城市物流发展相对滞后,物流产业规模分布的区域差异明显,不利于物流业的高质量发展。因此,基于物流规模分布的测算,分析物流规模分布的地区差异及演进趋势,有助于把握城市物流业规模分布的演变规律,优化城市物流规模分布结构,是实现物流产业均衡发展、提升物流业高质量发展水平的关键所在。
有关城市物流产业规模分布的研究,至今鲜有涉及,既有研究多围绕城市规模分布与企业规模分布展开。其中较为公认的观点有两类:一类观点认为城市规模分布具有幂律特性,具有代表性的幂律分布类型包括Pareto分布与Zipf分布。Auerbach(1913)最早指出城市规模分布可以用Pareto分布近似表示[1],苗洪亮(2014)的研究成果表明,中国城市规模服从Pareto分布[2]。而Zipf分布是Pareto分布的特殊形式[3],由Zipf(1949)在幂律定律的基础上发展与完善而成,表明城市位序与人口规模之间的经验关系服从Zipf分布(Bain,1950)[4]。尽管Zipf定律能较好拟合城市规模分布[5],但并不是万能的,例如,Goddard(2014)对美国商业银行与信用合作社规模分布进行估计,研究结果拒绝了服从Zipf分布的假设[6]。另一类观点认为规模分布具有正态分布特性。Luckstead(2014)通过对比中国和印度城市规模分布的正态分布和Pareto分布拟合结果,发现1950-1990年中国城市规模服从正态分布,仅2010年服从Pareto分布[7]。Cortes(2017)基于美国上市企业的运营数据,采用非参数估计方法估计企业规模分布,研究结果同样表明,企业规模服从对数正态分布[8]。
学术界就规模分布测算领域展开多种多样的研究,其中幂律分布由于其数学性质受到广泛关注。目前常用的幂律分布估计方法是对位序—规模法则进行对数处理的普通最小二乘估计(OLS)[9-11],但在小样本的情况下其估计结果是有偏的[12]。为解决由样本量引起的估计偏差问题,Gabaix(2011)改进了OLS估计,对规模位序进行1/2的位移[13],最大限度地减小了OLS估计的偏差。然而,实际情况中,并不是研究对象的所有样本均具有幂律特性,幂律分布往往仅适用于高于某个最小临界值的样本数据。这就意味着,即使样本量足够大,采用简单的OLS或修正的OLS来拟合规模分布也可能会产生较大偏差。为解决OLS估计和改进的OLS估计的偏误问题,Hill(1975)以城市为对象,提出估计Zipf分布的Hill估计方法,该方法满足了最大似然估计(MLE)的有效性,但是容易低估真实标准误与幂指数[14]。Goldstein(2004)及Clau⁃set(2009)进一步对其进行修正,分别采用OLS和MLE估计拟合24类数据的规模分布特征,对比结果表明,MLE拟合的结果最为稳定,验证了企业规模服从幂律分布的结论[15-16]。
上述文献对规模分布及其测算方法展开了有益探索,为城市物流业规模分布的研究奠定了良好基础。但研究仍存在一定的局限:首先,在规模分布测算方法方面,既有研究多采用OLS估计规模分布的幂指数,未考虑样本量大小对OLS估计有效性的影响;其次,现有文献多从企业或城市视角出发,分析其规模分布特征,介于企业与城市之间的产业层面规模分布研究较为欠缺,尤其是物流产业规模分布的研究更鲜有涉及;最后,既有研究往往仅止步于规模分布的测算,未就城市物流业规模分布的地区差异及其演变规律等后续问题展开深入探讨,易产生对规模分布的演变趋势认知不清、物流规模分布合理化的措施难以奏效等问题。基于此,本文围绕以下三方面内容展开研究:首先,借鉴Gaffeo(2003)做法[17],用城市物流从业人员数量代表物流规模,采用MLE方法测算2001-2017年中国物流业规模分布的幂指数,探讨我国物流规模分布特征;其次,运用Dagum基尼系数及其分解方法,分析物流业规模分布的空间差异及差异来源;最后,采用Markov链转移模型探讨物流业规模分布的动态演变。
二、研究方法
(一)幂律指数估计模型
本文借鉴Clauset(2009)的做法,采用MLE方法估计物流规模分布的幂指数,首先给出城市物流业规模分布的概率密度函数:

其中,P(x)表示物流规模x发生的概率;α表示物流规模分布的幂指数;C为归一化常数。由于x趋于0时,P(x)发散,因此对其施加一个最小临界值xmin,当α>1时(当α≤1时,使用MLE方法估计式(1)没有数学意义),通过计算归一化常数C,将(1)式转化为:

将(3)式对α求导,可得幂指数α的计算公式:
其中,临界值xmin值由K-S检验法确定,基本思想是当X≥xmin时,观测数据的互补累积概率分布和幂律模型拟合的分布越相似,xmin取值效果越好。K-S检验模型设定如下:

其中,C(x)是X≥xmin区间内,实际观测数据的累积概率函数(CDF);P(x)是X ≥ xmin区间内,用MLE方法所拟合的累积概率函数(PDF);D为C(x)和P(x)差距的最大值;xmin的值通过最小化KS统计量D值获取。
与OLS的估计结果不同,MLE估计的幂指数取值一般介于2~3之间(偶有例外),其代表的经济含义也不同。当α=2时,物流规模服从幂律分布[18];1<α<2时,物流产业分布相对均匀,位序低的城市物流业发展较为充分,位序高的城市物流业发展速度较慢,物流业在城市体系中表现为中小城市化趋势,此时α越大,城市物流业规模分布越集聚,反之,物流业规模分布越分散;当2<α<3时,物流产业分布较为集中,位序高的城市物流业发展相对充分,位序低的城市物流产业发展相对滞后,物流产业在城市体系中呈现出大城市化趋势,此时α越大,城市物流规模分布越分散,反之亦然[19-20]。
(二)Dagum基尼系数及其分解方法
相对于传统的基尼系数与泰尔指数而言,Da⁃gum基尼系数可以刻画物流业规模分布的地区差异,并通过其分解解决地区差异的来源问题[21]。本文采用Dagum基尼系数分析物流业规模分布的区域差异及差异来源。首先,计算所有地区的总体基尼系数:
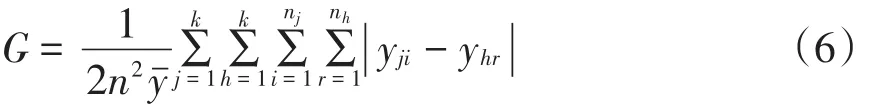
其中,n为省份数目;yˉ为所有地区物流业规模分布幂指数的平均值;k为所划分的地区数;j、h为地区类型;nj(nh)为j(h)地区省份的数目;yji(yhr)为j(h)地区物流业规模分布的幂指数。
其次,按地区对总体基尼系数进行分解。计算各省份物流业规模分布幂指数平均值,并按k个地区分组排序,即yˉh≤ …≤ yˉj≤ …≤ yˉk,将基尼系数G分解为地区内差异对总体的贡献(Gw)、地区间差异净值对总体的贡献(Gnb)以及地区间超变密度对总体的贡献(Gt),三者关系满足G=Gw+Gnb+Gt。计算公式为:

(7)-(11)式中,pj=nj/n,sj=njyˉj/yˉ,j=1,2,3,…,k;Gjj为j地区内基尼系数;Gnb为地区间净值差异;Gjh为j地区和h地区间的基尼系数;Gt为地区间超变密度。Djh为j地区和h地区物流业规模之间的相对影响程度,其计算公式为:

(12)-(14)式中,djh为地区间物流业规模分布的差值,表示j、h地区中所有yji-yhr>0样本值的数学期望;Fh(Fj)为h(j)地区物流业规模分布的累积分布函数;pjh为超变一阶矩,表示j、h地区中所有yhr-yji>0样本值的数学期望。
(三)Markov链方法
Markov链主要用于描述研究对象从一个状态转移至另一个状态的概率,通过概率转移矩阵分析研究对象的动态演变过程。本文采用Markov链方法分析物流业规模分布的动态演进过程,基本模型设定如下:
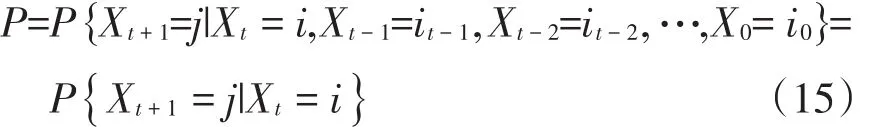
其中,序列{ Xt}为Markov链,可以看出Xt在t+1期的状态仅与其第t期的状态相关。据此,将物流业规模分布分为N种状态,通过Markov链模型,可以测算物流规模分布由t时期i状态转移至t+1时期j状态的概率pij。计算公式为:

其中,nij表示由t时期i状态转移至t+1时期j状态的省份数目;ni表示t时期处于i状态的省份总数。pij构成N×N维的Markov链状态转移概率矩阵,矩阵对角线上的元素表示物流业规模分布稳定在当前状态的概率,概率越大,物流业规模分布的流动性越差;矩阵非对角线上的元素表示物流业规模分布状态转移的概率,概率越大,物流业规模分布的稳定性越差。
(四)数据来源及处理
本文以中国地级行政区及以上城市为研究单元,借鉴Gaffeo(2003)的做法[17],用各城市物流从业人员数表示各城市物流业发展规模,数据来源于《中国城市统计年鉴》,鉴于2001年起,城市物流从业人数数据缺失较少,时间范围界定为2001-2017年。由于海南、西藏、台湾、香港和澳门地区的统计数据缺失严重,不将其纳入研究范围。为进行纵向比较,采用胡定利(2018)的做法[10],将观测数据较少的青海、宁夏和新疆三省(区)合并为一个单位,命名为青宁新单元,将巢湖市的各个区(县)分别并入合肥、马鞍山和芜湖市,将重庆市纳入四川省进行测算,处理后的研究样本由23个省份的288个城市单元构成。估计省际物流规模分布时,忽略北京、上海和天津三个直辖市的观测数据;估计区域及全国物流业规模分布时,补充北京、天津和上海三个直辖市的数据。
三、物流业规模分布估计结果
根据(4)-(5)式估计中国城市物流业规模分布,可以得到临界值xmin与幂指数α,为判定物流业规模分布是否服从幂律分布,借鉴Clauset(2009)的做法[16],采用非参数方法检验幂律拟合效果,p值大于0.1时,物流业规模分布具有幂律特性,p值越大,估计效果越佳。估计结果见表1所列,限于篇幅,仅列出2001年、2006年、2011年、2017年的估计结果。

表1 城市物流业规模分布估计结果
全国层面,从表1可知历年全国城市物流业规模分布的p值均大于0.1,接受我国城市物流业规模服从幂律分布的假设,表明全国物流业规模分布具有幂律特征。图1是历年中国城市物流业规模分布的幂指数趋势图,从图1可知,中国城市物流业规模分布的幂指数从2001年的2.330 8下降到2017年的2.036 9,在长期内呈波动下降趋势,短期内受外部生产率冲击产生偏离。其中,受2008年全球金融危机及2013年全球经济衰退的影响,大量中小型物流企业无法生存,各城市的物流规模分布差距扩大,幂指数出现小幅上升。总体上看,中国城市物流业规模分布的幂指数α值稳定在略高于2的水平,这与Torsten(2016)的结论一致[18],中国企业规模分布遵循幂指数略高于其他国家的分布。样本期内,城市位序越高,其物流业发展越充分,位序靠后的城市,其物流业发展相对滞后。随时间推移,全国幂指数逐步趋近于2,表明全国物流业规模分布的集聚趋势大于分散趋势,位序高的城市物资、人口、技术等资源的集聚使物流规模进一步扩大,其物流业发展处于领先地位。

图1 中国城市物流业规模分布趋势
为直观展示全国物流业规模分布的时间演变趋势,利用Python软件绘制2001年和2017年中国物流规模分布的MLE拟合图如图2所示。图中纵轴表示累积分布函数(CDF),横轴表示城市物流规模,坐标经对数化处理。从图2可知,2001-2017年,中国物流规模分布拟合效果良好,且随时间推移,物流业规模分布的幂律特性更加凸显,并呈现出明显的厚尾特征,表明北京、上海、广州等大城市已成为物流业的主要集聚地,这进一步证实中国城市物流业规模分布整体服从幂律分布的结论。

图2 中国物流业规模分布拟合
省域层面,除黑龙江、湖北、广西、四川四个省份的个别年份p值小于0.1外,其他省份的p值均大于0.1,表明省域物流业规模基本服从幂律分布。其中,与幂律分布偏离最大的三个省份分别是河南、湖南和甘肃,其城市物流业规模分布的扩散趋势大于集聚趋势,物流产业由大型城市向周边潜力较小的中小城市扩散,这些省份的物流产业迫于大型城市的人力成本、用地租金及环境保护等压力,不断将物流产业向中小城市转移,物流业发展呈现出中小城市化趋势。最接近幂律分布的三个省份分别是广东、四川和贵州,由于大量资本、人才要素向这些省份的大型城市涌入,物流业不断向大型城市集聚,物流业规模分布的集聚趋势大于扩散趋势,物流规模分布的大城市化倾向明显。除贵州及青海、宁夏、新疆单元外,其他省份的幂指数均大于2,表明各省份物流业在大城市地区的发展更具有比较优势,这与陈建军(2011)的观点一致[22],即经济发展水平较高的大型城市,可以通过空间溢出效应引领中小城市的物流业实现空间上的集聚,各省物流业发展呈一定的集聚趋势。
具体到各省城市物流业规模分布的演变趋势,借鉴Duranton(2007)的城市演化理论[23],将中国省域物流业规模分布的演变趋势分为快速上升、快速下降、震荡波动及缓慢演变四种类型。结合表1可以发现,山西、甘肃两省城市物流业规模分布的幂指数呈快速上升趋势,表明其物流业规模分布分散,物流活动主要向中小城市转移;相反,河北、吉林、黑龙江、福建、江西、河南、湖北、湖南、广东和青宁新单元的城市物流业规模分布呈快速下降趋势,幂指数快速向2接近,说明这些省份中小城市的物流业发展迅速,物流规模分布的幂律特性不断凸显,但青宁新单元的城市物流业规模分布与幂律分布仍有一定差距,暗示其中小城市的物流业发展仍然相对不足,与大型城市的物流规模差异有进一步扩大的趋势;内蒙古、江苏、浙江、安徽、山东和贵州的城市物流业规模分布没有明显的规律,在样本期内表现为震荡波动趋势,可能的原因在于这些省份的部分城市物流业发展还不够成熟,物流业发展易受外界环境的冲击;而辽宁、广西、四川、云南、陕西五省的幂指数则呈缓慢演变趋势,表明其城市物流业规模分布基本趋于平稳,特别是辽宁和四川,其物流业发展相对成熟,样本期间维持明显的幂律分布特性。
鉴于省域物流业规模分布波动较大,为直观描述省域物流规模分布的时间演变规律,利用Stata软件绘制2001年、2009年、2017年的物流业规模分布核密度图如图3所示。核密度图的位置、形状、两端延展的变化分别反映物流规模分布幂指数的水平高低、状态演变及差距变化。从位置平移角度看,2001-2017年核密度函数整体向左平移,幂指数趋近于2,物流规模分布的幂律特征不断凸显,规模分布由分散变为集中,空间布局优化明显;从形状变化看,核密度图形状整体右偏,符合幂律分布的特性,2017年核密度函数基本保持了2001年和2009年的形状,说明物流业规模分布的状态基本维持平稳。核密度主峰陡峭,幂指数集中分布在2~2.5区间,表明核心城市的物流规模仍然处于主导地位;从两端延展角度看,2001-2017年,两端呈向左收缩趋势,表明物流业规模分布的幂指数有所下降,各省的物流规模分布差距缩小。

图3 物流规模分布核密度
四、物流业规模分布的地区差异及其来源
为进一步掌握物流业规模分布的空间演进过程,获取物流业规模分布的地区差异及差异来源,本文借鉴Dagum(1997)基尼系数分解方法,计算中国物流业规模分布的Dagum基尼系数,由于篇幅有限,仅列出奇数年的计算结果。从表2可以看出,物流业规模分布的总体基尼系数呈波动下降趋势,由2001年的0.132 0下降至2017年的0.105 6,表明中国物流业规模分布的总体差距缩小。
地区内差异方面,东部和中部地区的城市物流基尼系数均表现为波动下降趋势,两个地区的物流业规模分布差异缩小。西部地区的城市物流业基尼系数呈波动上升趋势,其物流业规模分布差距最大,波动最为剧烈,原因在于西部地区各省际物流产业缺乏联动,物流业发展受相邻省份影响较小,各省际物流业规模分布差距较大。其中,地区内差异来源呈两阶段特征,2001-2003年,差异主要来源于中部地区,2004-2017年,西部地区城市物流业规模分布差异不断扩大,上升为造成地区内差异的主要原因。地区间差异方面,三大地区间的基尼系数均波动下降,说明随着时间推移,三大地区间的物流规模差异有所缩小。其中,中、西部地区间的差异最高,是地区间物流业规模差距的主要来源,其可能的原因在于20世纪末西部大开发战略的实施,中、西部地区物流发展水平差距进一步扩大,物流业规模分布差异在21世纪初逐渐凸显。差异贡献率方面,地区内差异贡献率基本维持在29%左右,历年变化幅度不大,表明地区内城市物流业规模分布基本维持稳定。而地区间的规模分布差异对总体的贡献率变动明显,从2001年的50.51%震荡下降至2017年的16.76%,进一步说明样本期内,地区间物流规模分布差异缩小,且缩小幅度较大,超变密度的贡献率则波动上升至2016年,成为中国物流业规模分布地区差异的主要来源。
五、物流业规模分布的动态演进
Dagum基尼系数描绘了物流业规模分布的地区差异特征,但未能体现规模分布的动态演进过程,本文采用Markov链分析方法,进一步分析物流业规模分布在不同状态之间的转移特征,以反映物流业规模分布的动态演进。首先,借鉴张虎(2018)做法[24],根据完备性、不可交叉性原则,对规模分布状态进行区分,考虑规模分布具有幂指数越大越偏离分布的理想状态这一特性,将物流规模分布的幂指数从小到大排序,依次划分为高水平、中高水平、中低水平和低水平四种状态,对应的区间分别为(0,2.19]、(2.19,2.41]、(2.41,2.82]和(2.82,+∞],每区间内幂指数个数占总数的25%。其次,计算状态随机转移的概率矩阵,分析物流规模分布的动态演进过程。
表3报告了物流规模分布的Markov链转移概率,对角线上元素表示从t至t+1期物流业规模分布稳定在既定状态的概率,非对角线上元素表示从t至t+1期物流业规模分布在不同状态之间转移的概率。由表3可知,物流业规模分布的幂指数在对角线上的概率均高于非对角线上的概率,物流业规模分布相对稳定。至当年年初物流规模分布处于高水平状态的省份,当年年末仍稳定在高水平状态的概率高达73.03%,而17.98%的省份则向下转移至中高水平状态;至当年年初物流规模分布位于中高水平状态的省份,当年年末仍维持在中高水平状态的概率是52.17%,而25%的省份向下转移至中低水平,17.39%的省份则向上转移至高水平状态;当年年初物流业规模分布处于中低水平状态的省份,至当年年末有51.06%的省份仍稳定在中低水平状态,有15.96%、22.34%的省份其物流业规模分布分别转移至低水平与中高水平状态;当年年初物流业规模分布处于低水平状态的省份,至当年年末有68.82%的省份仍稳定在低水平状态,仅有22.58%的省份物流规模指数向上转移至中低水平状态。由此可以看出,中国物流业规模分布状态基本稳定在高水平和低水平状态,规模分布之间的流动性较差,区域物流要素流通不畅,物流业规模分布易陷入“高水平垄断”和“低水平陷阱”。
六、结论与政策建议
本文以物流业规模分布为切入点,测算2001-2017年物流业规模分布的幂指数,分析全国及省域层面的物流业规模分布特征,并通过Dugum基尼系数分解和Markov链方法探索物流业规模分布的地区差异及动态演变趋势。主要研究结论如下:一是中国物流业规模分布具有幂律特性,物流业发展的大城市化倾向明显,中小型城市物流业发展不够充分。多数省份的物流业规模分布处于不断自我完善的阶段,物流规模分布演化过程虽然略有波动,但整体优化效果显著,物流业规模分布逐步趋于理想状态。二是样本期内,中国物流业规模分布的总体差距缩小。东、中部地区内物流业规模分布差距缩小,西部地区内物流业规模分布差距扩大,地区内物流业规模分布差距对总体差距的贡献率基本稳定为29%左右的水平。三大地区间的差距均呈缩小趋势,地区间物流规模分布差距对总体的贡献率逐步降低。超变密度对总体差距的贡献率波动上升,成为造成物流业规模分布差距的主要原因。三是中国物流业规模分布固化倾向明显,规模分布状态基本稳定在初始水平,尤其是稳定在高水平和低水平状态,说明中国物流业规模分布易陷入“高水平垄断”和“低水平陷阱”。
基于上述结论,本文提出几点政策建议:
首先,深入探索物流业规模分布规律,提高中小城市物流竞争力。其一,引导中小城市物流企业通过组织创新、服务创新,提高物流服务质量,提升物流运作效率;其二,通过兼并重组、参股控股、协作联盟等方式,实现中小城市物流资源及要素的优化重组及有效对接,发挥规模效应;其三,在中小城市建设产业集聚区,完善产业空间布局,通过财税、金融、用地政策手段的支持,引导物流企业向产业集聚区发展,发挥集聚效应。
其次,建立区域发展协调机制,促进西部地区物流业发展。其一,加强地区之间的资源、市场、要素融合,通过物联网、大数据等技术,促进物流要素从东、中部物流业发展相对饱和地区适度地向西部相对落后地区转移,实现地区间不同城市的融合发展,缩小东、西部和中、西部地区间物流规模分布差距;其二,整合三大地区各级城市的物流发展规划,放宽行政规划对西部地区物流业发展的约束,建立共享式物流发展模式,实现地区内城市间连片发展格局,缩小西部地区与其他地区间的物流发展差距;其三,根据西部地区自身要素禀赋,延伸产业链,积极承接产业转移,提高物流业发展后劲,实现物流业均衡发展。
最后,培育中等水平城市物流新功能,实现物流业规模分布“去固化”。中等城市作为大型城市在区域的补充,承担着要素集聚与产业支撑的作用,其物流规模分布水平在向高水平和低水平转移过程中拥有较大自由度。为避免物流业规模分布固化,应积极从大型城市承接产业转移,优化产业结构,完善交通基础设施建设,提高基础设施承载能力,发展物流新业态,培育物流新功能,激发中等水平城市的物流发展潜能,避免中等城市物流规模分布向低水平状态转移,缩小区域间物流规模分布差异,实现区域物流业协调发展。
