基于SVM和SRC级联决策融合的SAR图像目标识别方法
2020-06-08吴天宝夏靖波黄玉燕
吴天宝,夏靖波,黄玉燕
(1.厦门大学嘉庚学院 信息科学与技术学院,福建 厦门 361005;2.集美大学 轮机工程学院,福建 厦门 361021)
0 引 言
提高合成孔径雷达(synthetic aperture radar,SAR)图像识别性能对于军事和民用领域均具有重要的意义[1-2]。现阶段,SAR目标识别方法主要是基于传统模式识别思想,采用特征提取和分类决策两级流程。特征提取实现对原始SAR图像中目标特性的抽取以及降低冗余。常见的SAR目标特征包括几何形状特征、电磁散射特征以及变换域等。其中,几何形状包括目标区域[3]、外形轮廓[4]等;电磁散射特征包括散射中心[5]、极化特性[6]等;变换域特征提取方法较为丰富,包括投影法和变化域法等。代表性的投影法有主成分分析(principal component analysis,PCA)[7]、非负矩阵分解(non-negative matrix factorization,NMF)[8]等。变换域法则是将原始图像变换到另一具有稳定性的新空间,如傅里叶变换、小波分解[9]、单演信号分解[10]等。分类器基于既定的特征空间对各类目标进行空间划分,达到正确识别未知样本目标类别的目的。常用于SAR目标识别的分类器有K近邻(K nearest neighbor,KNN)[7]、支持向量机(support vector machine,SVM)[11-13]、稀疏表示分类(sparse representation-based classification,SRC)[13-15]等。文献[11]和[12]分别利用SVM对图像像素分布特征以及小波分解特征进行分类;文献[14]和[15]利用稀疏表示分类设计SAR目标识别方法;文献[13]则是提出基于SVM和SRC决策融合的识别方法,通过综合两种分类器的性能进一步提高了识别性能。近年来,基于深度学习理论的卷积神经网络(convolutional neural network,CNN)[16-22]也在SAR目标识别中得以成功应用并涌现了大量的方法。CNN是将特征学习和分类综合集成与统一的端到端系统,避免了传统的手工特征设计过程。文献[16]设计了全卷积神经网络,有效减少了训练过程中的参数;DU K等[17]考虑了SAR目标识别中可能出现的旋转、配置变化等问题,设计了稳健的CNN网络;文献[18]结合了CNN和SVM分类器,通过SVM对CNN的特征进行分类,提升了分类性能;文献[19]和[20]采用数据增强的方式提高了CNN的分类能力;为了克服SAR图像样本的稀缺性,文献[21]和[22]采用迁移学习的方式获得更为稳健的CNN。这些方法均证明了CNN在SAR目标识别中的有效性,然而,需要指出的是,CNN作为典型的数据驱动深度学习算法,对于训练样本的规模要求较高。在训练样本数量少、对测试样本覆盖面有限的条件下,其分类性能往往出现显著下降,这也制约了其在SAR目标识别中的实际应用。
本文提出基于SVM和SRC级联决策融合的SAR目标识别方法。SVM和SRC均为SAR目标识别中常用分类器,其性能也得到了现有文献的广泛验证[11-15]。然而,由于分类原理的不同,两种分类器在SAR目标识别方面优势也不尽相同。研究表明,SVM在标准操作条件(standard operating condition,SOC)下,即测试样本与训练样本相似性较高,可以取得很好的识别性能并且具有很高的效率。然而,它对扩展操作条件(extended operating condition,EOC),即测试样本与训练样本差异较大的,其适应性较差。SRC作为一种压缩感知分类器,对于噪声干扰、部分遮挡等情形具有较强的稳健性[23]。因此,结合两种分类器的优势,有望进一步提高SAR目标识别性能。本文所提方法首先采用SVM对测试样本进行分类,获得其属于各个训练类别的后验概率;其次,通过门限判决方法选取若干具有较大概率的训练类别并采用它们的训练样本构建全局字典,在此基础上,采用SRC对测试样本进行进一步分类并输出各个类别对于它的重构误差;最后,基于线性加权的思想,结合SVM和SRC的决策结果,进而最终确认测试样本的目标类别。SVM预筛选分类可以高效选取测试样本最有可能归属的目标类别。SRC则在这些类别中进一步获得稳健的决策结果。因此,采用级联方法融合两种分类器可以实现识别效率和精度的统一。
1 SVM基本原理
针对两类模式的分类问题,SVM通过最小化结构风险的方式获得最佳的分类界面[24]。对于未知类别的样本x,SVM分类的决策超平面为
wT·φ(x)+b=0,
(1)
式中:w为权重系数矢量,用于描述超平面的相关参数;φ(·)为核函数;b为偏置项。
起初,SVM是针对两类模式的识别问题提出的,即以式(1)的超平面进行两个类别的区分;后期,研究人员通过“一对一”、“一对多”等策略将其推广到多类模式的分类。通过大量带标签训练样本的训练可以获得合适的分类决策面。同时,选用合适的核函数能够有效增强SVM的非线性分类能力。在利用SVM进行多类别分类时,输出各个类别的(伪)后验概率来代表当前样本属于某一训练类别的可能性。通过最大后验概率的原则就可以判定测试样本的类别。现阶段,SVM已经在诸如人脸识别、SAR目标识别等模式识别问题中得到极为广泛的应用,其效率和精度也得到了较为充分的验证。然而,这种结构风险最小化的方法对于训练样本的要求很高,即需要覆盖可能出现的测试情形。具体到SAR目标识别中,SVM对于扩展操作条件的适应性不足。
2 SRC基本原理
SRC采用稀疏表示作为基本手段对类别未知的测试样本进行表征,进而根据重构误差的分析判定其类别[14-15,23]。字典构建是SRC的关键环节之一。现有方法多采用所有训练类别的样本构建全局字典A=[A1,A2,…,AC]∈Rd×N,其中Ai∈Rd×Ni(i=1,2,…,C),包含第i类训练类别的所有训练样本(或从中提取的特征、描述)。以此为基础,测试样本y的稀疏重构描述为
(2)
式中:α为需要求解的稀疏表示系数矢量;ε为重构误差门限。

(3)

研究表明,SRC对于噪声干扰以及遮挡等情形具有良好的稳健性[23],这一点可以对SVM进行有效补充。因此,通过合理的手段对SVM和SRC的分类结果进行科学融合,可以进一步提高目标识别算法的综合性能。
3 SVM与SRC级联决策融合
3.1 基于SVM的预筛选
SVM通过参数化的决策面对测试样本的类别进行判断,因而具有很高的效率。根据SVM输出的各个训练类别的后验概率,可以对测试样本可能的类别进行判断。本文采用SVM作为预筛选分类器,采用门限判决法选取若干个具有较大后验概率的训练类别。假设C个训练类别对应的后验概率分别为[P1,P2,…,PC],采用门限T选取测试样本的潜在目标类别,即当Pi>T时,认为第i类为候选类别。
在合适的门限下,基于SVM输出结果选取得到的候选类别能够有效反映当前测试样本的目标类别。与直接采用SVM进行硬决策相比,本文采用的预筛选分类可以有效提高容错率。由于SVM对于扩展操作条件(如噪声干扰、遮挡等)的稳健性较差,此时直接采用SVM进行决策很可能得到错误的决策结果,但真实类别对应的后验概率很可能处于较高的水平。因此,适当的门限判决可以保留测试样本的真实目标类别,从而在后续进一步决策中得到正确的决策。
3.2 线性加权融合
基于SVM预筛选得到的候选训练类别构建字典对测试样本进一步进行SRC分类。由于预筛选过程中仅保留了测试样本最可能的类别,因此此时构建的字典规模远小于传统基于所有类别训练样本的字典。假设SVM预筛选后选取了M个训练类别,则SRC得到这些类别对应的重构误差为r(Γ(i)) (i=1,2,…,M),其中Γ(i)为SRC中第i个类别对应原始C类目标中的序号。采用式(4)的归一化方法,将重构误差转换为概率形式,即
(4)
式中:P1(i)为在SRC分类结果中测试样本属于选取的第i类目标(原始类别中的第Γ(i)类)的可能性。
在获得SVM和SRC决策结果的基础上,本文采用经典的线性加权算法对SVM和SRC的分类结果进行融合,即
PF(Γ(i))=w1P(Γ(i))+w2P1(Γ(i)),
(5)
式中,PF(Γ(i))为融合后测试样本属于原始第Γ(i)类目标的可能性。
考虑到本文中SVM中的部分主要是为了预筛选,故在权值上有所弱化,设置w1=0.4,w2=0.6。
图1显示了本文基于SVM和SRC级联决策融合的识别方法的基本流程,根据其实施时序可以归纳为以下步骤。
步骤1 采用PCA对所有训练样本和测试样本进行特征提取。
步骤2 采用SVM对测试样本进行预筛选分类,通过门限T选取候选类别。
步骤3 基于候选类别训练样本构建SRC的字典并对测试样本进行分类。
步骤4 针对选取的候选类别,对它们在SVM和SRC的输出决策值进行线性加权融合。
步骤5 根据融合后的结果,基于最大概率的原则判定测试样本的目标类别。
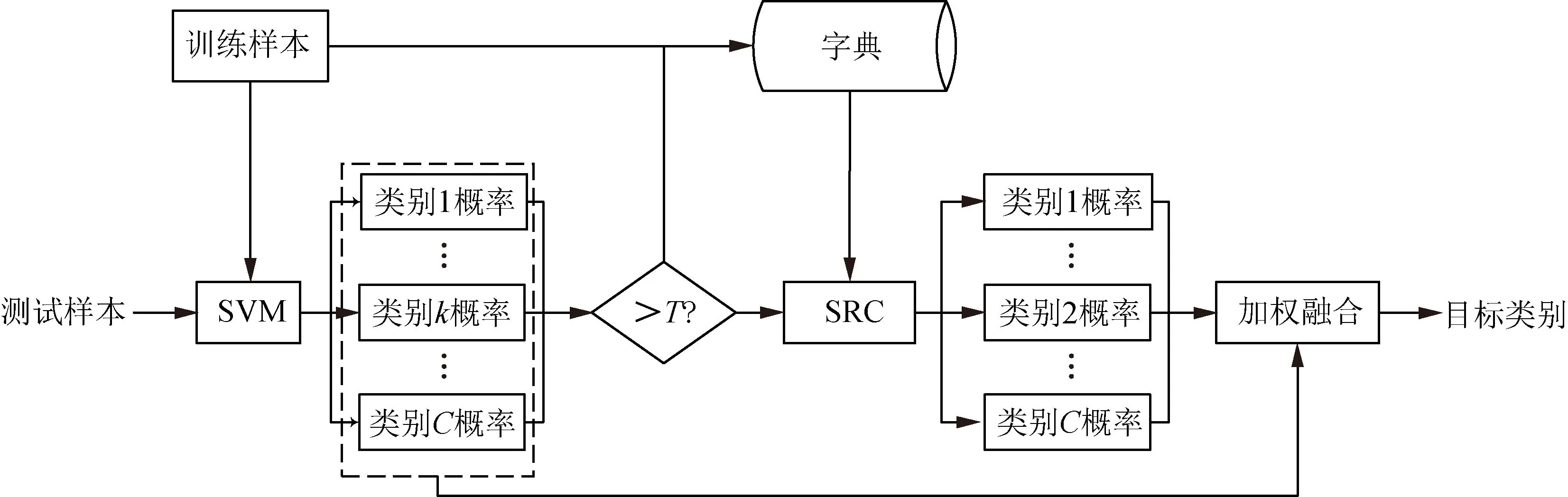
图1 基于SVM和SRC级联决策融合的SAR目标识别方法流程
4 实验与分析
4.1 实验数据集
采用MSTAR公开数据集对本文方法进行测试。数据集中,10类车辆的SAR图像覆盖0°~360°方位角以及若干典型俯仰角(如15°,17°,30°,45°),图像分辨率为0.3 m。在进行本文方法测试的同时,选取了若干方法进行对比实验,包括SVM方法[11]、SRC方法[14]以及基于CNN的方法。本文选用的CNN网络为文献[16]中的全卷积神经网络。该网络包含5个卷积层,前3个卷积层后面均设置最大值池化层次,通过卷积网络的次序迭代,实现输入图像到类别标签的直接映射,具体的网络设计可参见文献[16]。对于本文方法,SVM和SRC均采用现有成熟工具包实现(分别为LibSVM和SparseLab)。其中,SVM采用径向基核函数(RBF),通过LibSVM自带的网格搜索法获得最佳参数。SRC采用OMP算法求解稀疏表示系数,其中算法稀疏度设为13,误差门限设为3×10-5。
4.2 标准操作条件
设置标准操作条件下的训练和测试样本如表1所示。其中,训练样本来自17°俯仰角,训练样本来自15°俯仰角。通过调整门限T得到本文方法在部分典型预筛选门限下的平均识别率,如表2所示。当门限过小时,SVM的预筛选作用很弱,本文方法近似于SVM和SRC的直接融合。反之,当门限很大时,仅仅有少量的训练类别得以选择,此时SRC的进一步分类作用很小,主要依靠SVM进行判决。值得注意的是,当SVM分类中任一训练类别均达不到预设门限时,则选取概率最大的类别作为候选类别。从表2可见,本文方法在门限0.6时,取得99.21%的高识别率。此时本文方法对这10类目标的识别结果具体展示如图2所示,其中对角线元素记录各类目标的正确识别率。表3对比了各类方法在当前条件下对10类目标的平均识别率以及分类效率。本文方法识别率最高,验证其对于标准操作条件具有最强的适应性。从SVM和SRC的独立识别结果可以看出,两者在标准操作条件下都能以很高的识别率完成识别任务。本文通过它们的级联决策融合进一步提高了决策的稳健性,因此,可以获得更好的识别结果。后续实验中,设定门限为0.6。表3中的时间消耗指的是各类方法识别单幅MSTAR SAR图像的平均时间。所有方法均基于相同的硬件平台进行测试。可以看出,本文方法的效率低于单一的SVM和SRC方法,这是级联两个分类器带来的必然结果。然而,由于在SVM分类阶段进行了门限筛选,因此,效率的下降并不是十分显著。综合考虑识别率以及时间消耗,本文方法的整体识别率性能更优。
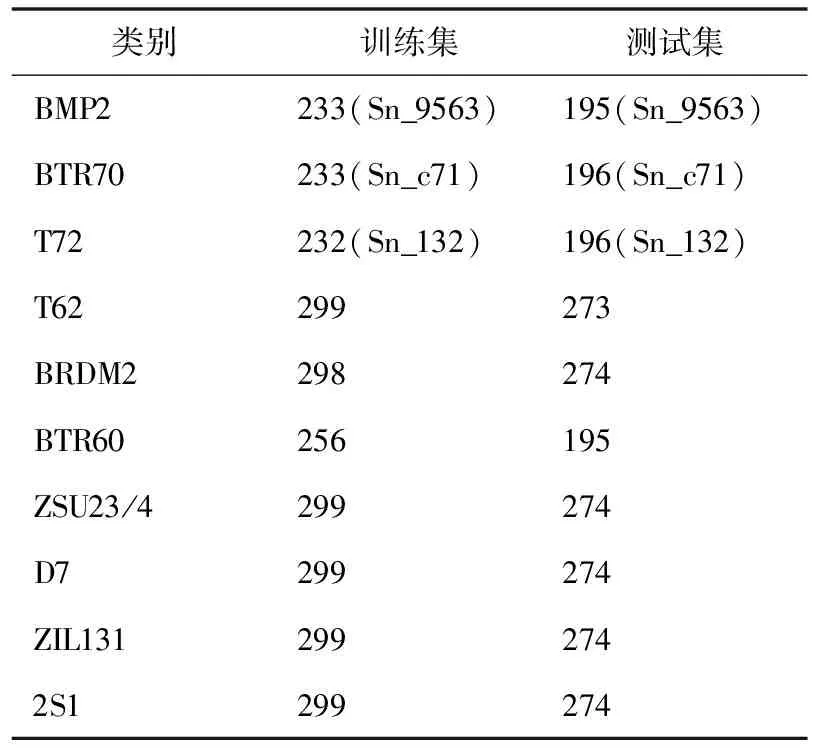
表1 标准操作条件下训练和测试集

表2 本文方法在不同预筛选门限下的平均识别率

图2 本文方法在标准操作条件下的识别结果
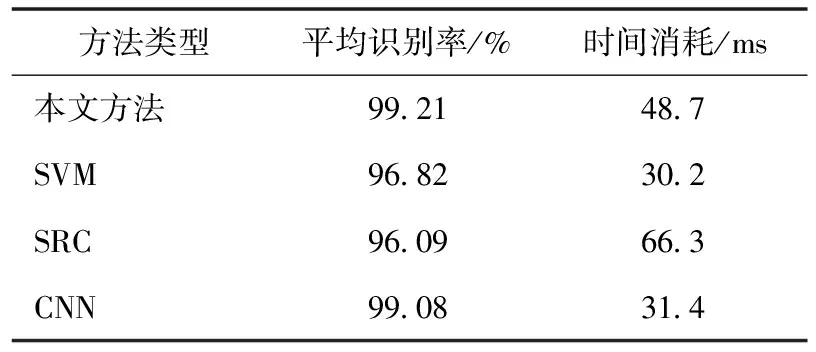
表3 各类方法在标准操作条件下的识别性能对比
4.3 俯仰角差异
俯仰角差异条件下的训练和测试样本如表4所示。其中,训练样本为2S1、BDRM2和ZSU23/4三类目标在17°俯仰角下的图像。测试样本则分别来自30°和45°俯仰角。图3对比了各类方法对在30°和45°两个俯仰角下测试样本的平均识别率。可以看出,由于较大的俯仰角差异,各类方法的平均性能相比标准操作条件均出现了较为明显的下降。对比而言,本文方法在两种情形下均保持了最高的平均识别率,验证其对于俯仰角差异具有最强的稳健性。
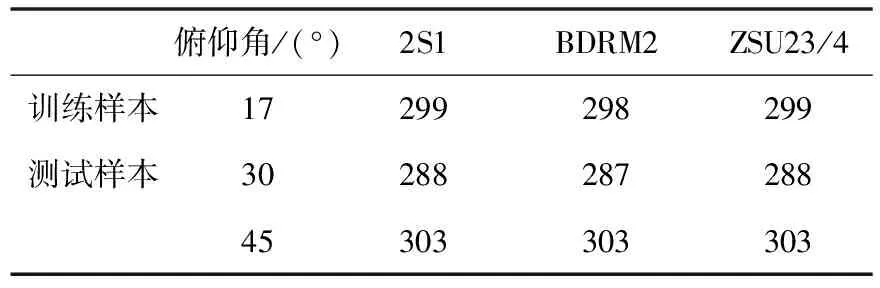
表4 俯仰角差异下的训练和测试集
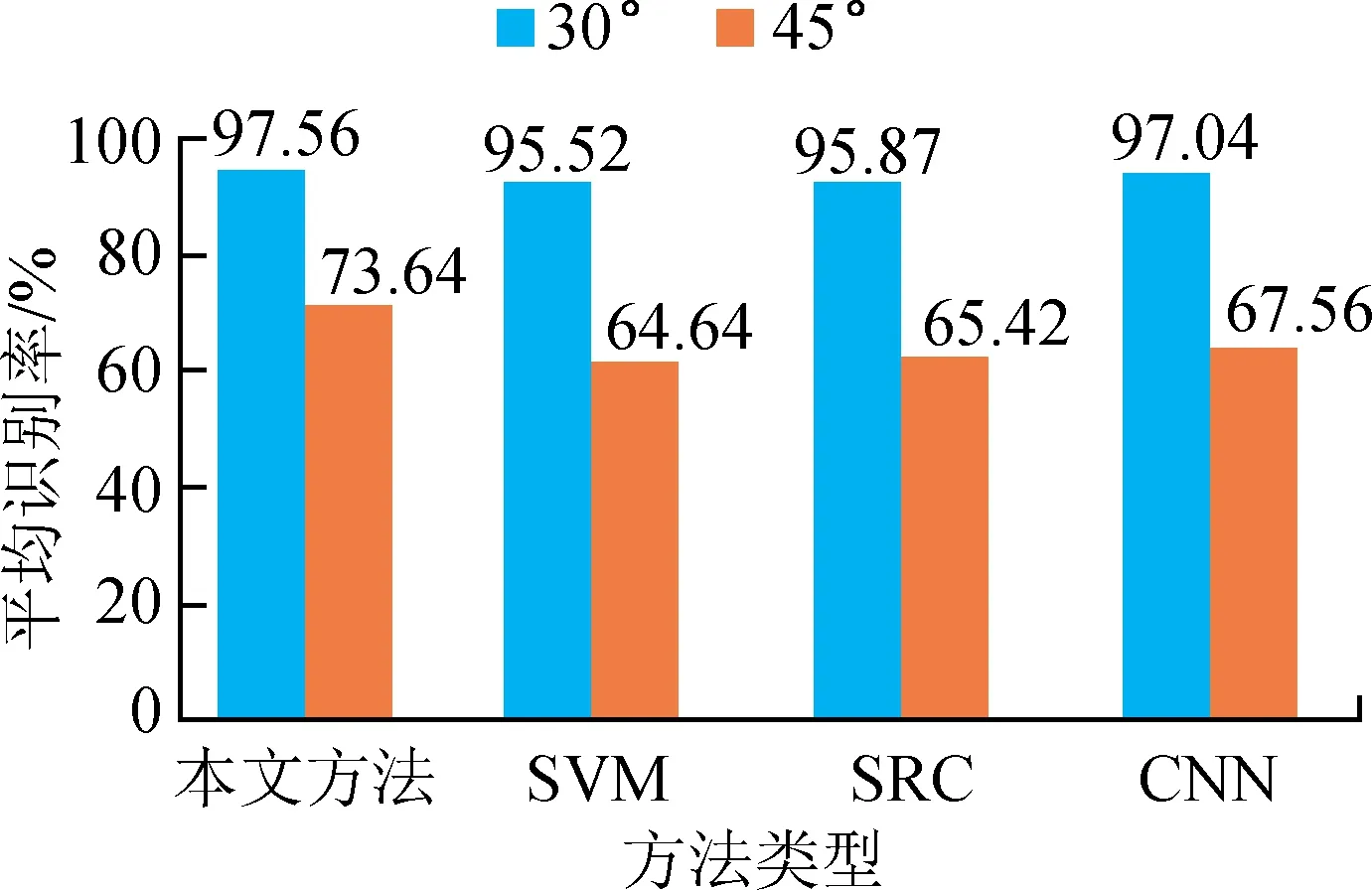
图3 各类方法在不同俯仰角下的识别性能
4.4 噪声干扰
作为SAR图像中的一种典型现象,噪声干扰存在于数据采集、传输的每一个阶段。提高SAR目标识别算法对于噪声干扰的稳健性十分必要。实验首先向表1中10类目标的测试样本添加不同程度的高斯白噪声[5],进而测试不同方法对于噪声样本的分类能力。图4绘制了各类方法的平均识别率随信噪比(SNR)变化的性能曲线。本文提出的方法在各个信噪比下均可取得最高的识别率,表明其对于噪声干扰的稳健性。观察SVM和SRC的独立识别结果,不难发现SVM对于噪声干扰较为敏感,而SRC则具有更强的稳健性。本文采用级联决策融合的思路,进一步提高了融合后决策的稳健性,有利于提高识别算法的噪声稳健性。
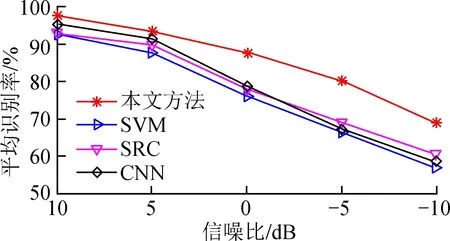
图4 各类方法在噪声干扰下的识别性能曲线
4.5 遮挡
遮挡是地面目标图像获取过程中时常发生的状况。文献[5]和[25]均针对SAR目标识别中的遮挡问题进行研究。本次实验中,首先基于文献[4]的SAR目标遮挡模型构造10类目标的部分遮挡测试样本;其次,测试不同方法在遮挡条件下的平均识别率,如图5所示。随着遮挡比例的不断提高,各类方法的识别性能均有较为显著的下降。对比而言,本文提出的方法在各个遮挡比例下均取得了最高的平均识别率,表明其对于遮挡具有更强的稳健性。与噪声干扰的情形类似,SRC对于遮挡具有较强的适应性。最终,通过分级的决策融合,本文提出的方法可以取得更强的遮挡稳健性。

图5 各类方法在遮挡下的识别性能曲线
5 结 论
(1)提出基于SVM和SRC级联决策融合的SAR目标识别方法。通过SVM进行预筛选决策,获得测试样本潜在的目标类别。
(2)在潜在类别构建的字典上,使用SRC对测试样本进行进一步分类,最后,采用线性加权的策略结合SVM和SRC的决策值,获得更为稳健的识别结果。
(3)基于MSTAR数据集对本文方法进行了测试,结果表明,本文提出的方法提升了SAR目标识别的整体性能。
(4)门限值的选取在本文提出的方法中具有重要地位,随着可用的SAR目标图像样本的不断增多,可通过大量样本的学习、测试,获得通用性更强的门限设置方法。
