基于完备抓取构型和多阶段网络的软体手抓取
2020-06-08刘文海王伟明
刘文海,胡 洁,王伟明
(上海交通大学 机械与动力工程学院, 上海 200240)
机器人抓取是机器人操作的重要组成部分,也一直是机器人研究的重点.传统刚性手爪的抓取已广泛应用于各行各业,用来执行工业场景中重复的、笨重的和较为结构化的任务.而对于外形可变和表面易碎物体的分拣和抓取,软体手显现出了更高的柔顺性[1].同时,这些工作环境往往是非结构化的,相比于固定的工业环境,具有更多不确定性,例如物体种类以及物体表面的柔软程度.因此,如何提高软体手抓取的自主性和智能性便成为一项极为重要的课题.
近年来,随着深度学习的发展,越来越多的研究将深度学习应用在基于视觉的抓取规划中[2].这种方法通过拟合从感知到抓取的直接映射来自动提取预示稳定抓取的特征,对未知物体同样具有良好的泛化性,这一类方法的关键是将抓取规划问题转化成深度学习能解决的分类或者回归问题,同时搜集大量与模型输入输出相对应的有标签数据.Lenz等[3]首次将深度学习应用在二指手的抓取规划中,并开源了其模型对应的抓取数据集.Redmon和Kumra等[4-5]在其开源数据集的基础上分别通过改进网络结构和采用具有更优异分类性能的深度残差基网络(ResNet-50),提高了抓取检测的准确性和速度.Liu等[6]针对散堆多物体的机器人分拣提出用于吸盘的吸附点检测网络.Zeng等[7]则提出了与物体类别无关的全卷积抓取检测网络.以上研究主要针对二指夹手和吸盘等刚性手爪,而将深度学习应用在软体手爪抓取规划的研究则相对较少.多指软体手的抓取大多停留在已知物体位姿抓取或者人工操作的水平[8].这是因为视觉引导的软体手抓取需要视觉提供更多抓取预测量,例如软体手的稳定抓取除了像吸盘需要准确的抓取位置预测.除此之外,还需要考虑软体手的开合角度、抓取深度和宽度的影响,完备的抓取构型是实现软体手抓取的关键.
本文针对视觉引导的4指软体手的自主抓取,提出一种新的基于深度学习的抓取检测方法,利用网络结构VGG16上分别提取彩色图和深度图的卷积特征,并在融合层融合输出多模特征图,以多模特征图为基础设置预测锚点,并级联抓取预测网络,分别输出抓取质量、抓取角度和抓取深度预测.最后,构建软体手抓取数据集,对比分析影响抓取预测准确性的因素,并通过抓取实验验证本方法的有效性.
1 抓取规划问题描述
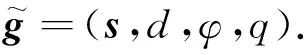
综上,图像空间的抓取表示可通过下式转换到世界坐标系:
(1)
式中:RTC为摄像头坐标系到机器人坐标系的坐标转换,由摄像头外参标定可得;f为2维图像坐标到3维摄像头坐标系的转变,由摄像头内参标定可得.

图1 软体手的4维抓取构型表示Fig.1 4-dimension grasp configuration of soft gripper

2 抓取规划方法
图像空间到抓取指令的映射需要满足稳定抓取准则,这依赖于抓取标签的有效构建,抓取标签的标记过程见下文2.2.这种映射可直接采用深度网络模型进行学习拟合,即Mθ:I→G,其中:Mθ为参数化的网络模型;θ为网络参数矩阵.学习的过程是基于有标签抓取的数据S:IT→GT,以多任务损失函数L作为误差函数的学习映射Mθ(I)=G的参数θ,即
(2)

图2 网络模型与“锚点”旋转框Fig.2 Network architecture and anchor based rotating block
2.1 “锚点”旋转框与多阶段网络模型
根据上述完备抓取构型,为学习从图像空间到抓取指令的映射,提出一种基于“锚点”旋转框的多阶段抓取检测网络,整体结如图2所示.网络组成包括卷积神经网络(CNN)特征融合层和抓取预测层.特征融合层使用VGG16网络作为特征提取网络.网络分别以480像素×640像素大小的彩色图像和深度图像作为单模态输入网络.其中,彩色图像包含R、G、B3个通道,深度图像扩展为D、D、D3个重复通道.特征提取网络分别生成通道为512、大小为15像素×20像素的单模态特征图,特征图进行通道叠加后衔接3×3卷积层完成特征融合,最终形成512通道的融合特征图.抓取预测层分为2个阶段:第1阶段进行抓取点的二值分类,预先选出可抓取的候选点;第2阶段在候选点进行抓取角度分类和抓取深度回归.受文献[11]的启发,特征融合层与抓取预测层的连接采用基于“锚点”的滑动网络形式,如图2右侧所示.每个“锚点”是融合特征层滑窗的中心点,滑窗大小设置为2像素×2像素.因此,第1阶段在每个“锚点”处判断是否为可抓取点.第2阶段以第1阶段为基础,选出第1阶段预测概率最大的m个“锚点”(此处m取为5)进行角度分类和抓取深度回归,即以“锚点”为中心,以90°/N的角度旋转N次(N为角度旋转次数,此处N取为9)获得N个滑窗.这相当于将R、G、B和深度图分别旋转N次后送入融合卷积层得到N个对应“锚点”位置的特征窗.若抓取角度经过旋转变为0° 或者180°,则此时特征窗的抓取角度类别为可抓取,其他特征窗为非可抓取.抓取预测网络的2个阶段均采用全卷积形式,这种滑动网络相当于依次进行2×2以及 1×1 卷积操作,最后在阶段1输出15×20大小的抓取二值分类c1,阶段2在阶段1的基础上计算m×N个滑窗的角度分类c2和抓取深度d回归.所有的卷积激活函数采用Relu函数,抓取预测分类采用 Sigmoid 激活函数,回归预测采用线性激活函数.
2.2 模型训练与旋转数据增强
由于卷积操作是一种参数共享的模型,可看作是15×20个全卷积小网络的计算.所以其训练过程可看作简化模型的训练,同样分为2个阶段的网络训练,如图3所示.其中:Conv为卷积层;CB为卷积模块.阶段1是二分类,阶段2是角度分类和抓取深度回归,模型输入为64像素×64像素图像块.
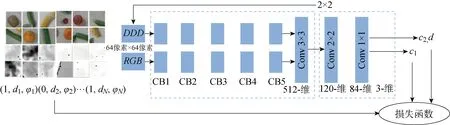
图3 模型简化与训练Fig.3 Model simplification and training
抓取预测层的输入是前层特征图2×2滑窗的卷积,转换到图像空间即是64像素×64像素的图像块.因此,简化模型的输入变为64像素×64像素的图像块.这种转变得益于特殊的抓取网络设计,且有利于进行样本增强,更容易训练.整个多阶段网络模型参数个数为3.44×107.训练采用Adam优化方法,基于Keras框架,训练平台包含2块GTX 1080Ti GPU,整个训练时间为0.5 h,15×20个锚点的整体预测时间为850 ms.
目前,有多个公开抓取数据集可用于抓取检测网络训练,包括Connell二指手抓取数据集[3]和Dexnet系列数据集[12],这些数据集主要用于二指夹手或者吸盘.本文构建了用于软体手抓取的机器人系统.抓取实验以6类水果作为抓取对象,如图4所示.采用 Intel 的RGB-D摄像头D435,视野范围是480像素×640像素.在数据搜集过程中,6类物体被随机放置在桌子上,总共拍摄了18张图片(包括深度图和彩色图,分辨率为480像素×640像素),其中一张图片的密集程度如图5所示.18张图片共894个抓取标记,其中正标记474个,正样本示例如图5(a)所示,负样本示例如图5(b)所示.每个标记以标记位置为中心截取64像素×64像素的图像块作为简化模型的输入,如图5(c)所示.数据集搜集过程可在30 min内完成,可快速应用在其他物体类别,这是该模型的优势.

图5 抓取数据集的建立Fig.5 Establishment of grasp dataset

图4 抓取水果类别Fig.4 Fruit categories for grasping
图5(a)上的红线代表正样本标记,黑点为手爪中心像素点s=(u,v),红线(黑点到青点)的旋转角度为抓取角度φ,考虑到软体手4个手指的对称性,抓取角度范围为[-45°,45°],这是前文选择90°/N的原因.蓝点和黑点的深度差h标记为抓取深度d,若h≥0.8HGri,则d=0.8HGri,HGri为软体手指的高度.图5(b)为负样本标记,负样本的抓取位置标记为青色,主要为水果边缘和桌面.正标记的抓取质量q统一记为1,负样本的抓取质量记为0.
为扩大训练样本,提高样本的利用效率,对采集的数据集进行数据增强.主要采用旋转的方式进行数据增强,如图6所示.一个64像素×64像素的抓取图像块可看作一个训练样本,以抓取位置点为中心,旋转36次可将样本扩大36倍.对于阶段1的训练,即扩大到 32 184 个样本,样本标签不发生改变;阶段2的标签包含两部分,抓取角度的二分类和抓取深度回归,若抓取角度经过旋转变为0°或者180°,则抓取角度预测为1,其他为0,抓取深度标签不变.数据增强后的数据集按1∶4的比例分为训练集和测试集.

图6 数据增强示意图Fig.6 Data augmentation
2.3 多任务损失函数
不同于其他文献采用单一损失函数的方式[13],不同阶段采用不同的损失函数,阶段1采用二元交叉熵,阶段2采用多任务损失函数,角度分类同样采用二元交叉熵,抓取深度回归采用L2函数作为损失函数,对于参数化网络Mθ,定义如下回归损失:
(3)

阶段1抓取分类和阶段2的角度分类,采用二元交叉熵作为损失函数,定义如下:
(4)

(5)
式中:平衡权重α是一个超参数,由实验确定;B为训练批大小.
3 实验
为验证本文所提算法的有效性,通过公开数据集和自建数据集对比验证模型结构性能.公开数据采用Cornell 二指夹手数据集,与文献[13]的单一均方误差损失函数进行对比分析.在自建数据集上对比分析影响抓取检测准确率的因素,同时通过实际机器人进行软体手抓取实验,以验证所提方法的有效性.
3.1 损失函数对比
Cornell抓取数据集885张图片,240个可抓物体,抓取标签为5参数抓取矩形.文献[13]对其中的抓取角度,抓取宽度和抓取质量3个标签进行抓取回归预测,采用的是单一均方误差(MSE)损失函数,抓取构型的输出量与本文预测量相似(抓取角度、抓取深度、抓取质量).作为对比,将其MSE单一损失函数与本文的多任务损失函数进行比较.同样的,将Cornell数据集按4∶1∶1的比例分为训练集、测试集和验证集,在测试数据集对比损失函数的训练效果.为全面衡量网络的学习效果,采用均值平均精度(mAP)值作为网络检测结果的性能评价指标.抓取质量以不同阈值作为抓取成功的标准会有不同的mAP,超参数α也会影响网络最后的mAP,给出了单一损失函数和不同α的多任务损失函数的阈值mAP变化图,如图7所示.其中:δ为阈值;M-L为多任务损失函数;MES-L为均方误差损失函数.由图7可知,多任务损失函数具有更优异的预测性能,抓取质量的判断阈值设置为0.3,超参数α设置为2时,多任务损失函数获得的最好预测结果为91.9,单一MSE损失函数的最好预测结果只有85.7.根据图7,可以选出不同阈值设置下最合适的超参数α,从图7中的曲线也可以看出,在不同阈值设置下,单一损失函数都不是最好的误差函数.以阈值0.5为阈值时的各损失函数的mAP曲线如图8所示.其中:ε为召回率;μ为精准率.由图8可知,从mAP曲线中可具体知道多任务损失函数具有更高的预测精确率和召回率,相比单一MSE损失函数更适合作为多输出抓取构型的损失函数.

图8 多任务和单一损失函数在δ=0.5时的mAP比较Fig.8 Comparison of mAP between multi-task and single loss function at δ=0.5
3.2 单阶段与多阶段网络对比
本文的完备输出包含抓取角度、抓取深度和抓取质量,只有这3项同时预测正确才能实现成功的抓取.本文设计了一个针对多输出的评价指标,即对于预测结果,若抓取质量预测错误,则网络判定为预测错误;若抓取质量预测正确,同时抓取角度与真值相差10° 以内,抓取深度与真值相差10 mm以内,预测结果判定为正确.作为对比,以单阶段模型作为基准模型,即直接以阶段2的模型对抓取进行预测.两种模型在测试集上的对比结果如表1所示.其中:eac为网络整体准确率;eer,a为抓取角度错误率;eer,d为深度预测错误率;eer,m为抓取质量错误率.
由表1可知,本文模型具有82.8%的整体预测准确率,明显高于单阶段模型.深度预测错误率给出了只有深度预测错误的比例,抓取角度错误率给出了阶段2角度分类错误的比例,抓取质量错误率给出了阶段1抓取质量分类的错误率.表1中的结果显示,分为2个阶段进行抓取检测可以获得更好的性能.2个阶段模型的抓取角度错误率明显低于单阶段模型,这说明将抓取预测分为2个阶段可以使角度预测主要集中于阶段2进行,能够获得更好的角度预测.抓取深度回归的错误率小于5%,说明网络对抓取深度学到了相应的映射.

表1 单阶段和多阶段模型对比Tab.1 Comparison of single-stage and multi-stage models
3.3 机器人抓取实验
以6自由度UR5机械臂、Intel RGB-D摄像头D435和4指软体手爪构建了机器人自主抓取实验系统,D435固定在机械臂外部,视角朝下垂直桌面高度为800 mm,如图9所示.
抓取检测结果如图10所示,图10(a)为“锚点”步长为18像素的检测结果,图10(b)为“锚点”步长为9像素的检测结果,蓝点为抓取位置,“工字形”红线代表抓取方向.从检测结果来看,虽然步长18像素比9像素具有更稀疏的输出点,但并没有丢失对于水果的检测结果,所以实验采用“锚点”为18像素的步长.

图9 机器人抓取系统Fig.9 Robotic grasping system

图10 “锚点”步长为18和9像素的抓取检测结果Fig.10 Grasp detection results with anchor step 18 and 9 pixels
输入为480像素×640像素的情况下,步长为18像素的整体检测时间为850 ms左右.各个水果的抓取结果如表2所示.由表2可知,整体抓取成功率达到96%.为便于定量分析各个水果抓取成功率的影响因素,在自建数据库上(见表2)还比较了不同水果的网络检测结果.
表2 不同水果抓取成功率和网络检测准确率
Tab.2 Grasp success rate and model accuracy of different fruits

水果抓取总次数成功次数成功率/%预测准确率/%黄瓜 50459081柿子 505010085橘子 505010083香蕉 50388680西红柿505010084猕猴桃505010084
从表2不同水果的抓取成功率来看,圆形水果的抓取成功率普遍比棒状水果的成功率高,这是因为圆形水果对抓取角度分类的结果不敏感,并且对于位置定位误差也具有较高的容差.表2中的抓取成功率普遍高于预测准确率,这是因为软体手对预测结果具有一定容差,即使预测偏离正确值,仍然可以成功抓起水果.此外,数据标记主要根据人的经验进行标注,和实际机器人的抓取略有不同.从预测准确率来看,圆形水果的准确率同样高于棒状水果,和抓取成功率结果吻合.不同水果的抓取结果如图11所示(抓取视频参见https:∥github.com/liuwenhai/softGrasping.git).如图11(a)中的西红柿抓取图,显示了在视觉定位存在误差的情况下西红柿依然可以被抓取.而棒状水果,如黄瓜和香蕉,依赖网络输出正确的抓取角度和视觉定位的精度,只有抓取角度和抓取位置同时满足一定准确度才可以被成功抓取.黄瓜和香蕉的预测准确率差异不大,黄瓜的抓取成功率却明显高于香蕉.这是因为,相较于黄瓜,香蕉的质量较大,抓取香蕉的中心具有更高的抓取成功率,而黄瓜质量较小,即使抓取到黄瓜两侧也能被成功抓取,所以黄瓜成功率比香蕉更高.试验中还发现,对于大小不同的橘子,抓取网络能够输出合适的抓取深度,有助于提高不同大小水果抓取的成功率,如图11(b)所示.
实验中发现,即使对于堆叠的水果皮,网络也可以输出正确的抓取检测结果,并被成功抓取,如图11(c)所示,这说明网络对于水果皮同样具有很好的泛化能力.

图11 不同水果的抓取结果Fig.11 Grasp results for different fruits
4 结语
针对视觉引导的软体手智能抓取,本文提出了基于“锚点”旋转框的多阶段抓取预测网络,设计了针对4指软体手的完备抓取构型,包含抓取质量、抓取角度和抓取深度,并采用多任务损失函数提高了多输出抓取网络的预测准确率.通过开源数据库和自建数据库验证了所提抓取模型的有效性.最后,通过机器人抓取实验验证了所提方法可以有效地实现软体手的智能抓取.实验结果表明,所提方法对不同水果能够达到平均96%的抓取成功率,此外,对于水果皮同样具有很好的泛化效果,进一步提高了所提方法的应用范围.
