对现行汉字排检方法的反思和创新研究
2020-05-06罗健
罗 健
任何文字系统都有字的排列和检索顺序问题。英语等语言用的音素文字只有几十个字,从A到Z的顺序很容易被记住,排检也很方便。汉字不同,它是语素文字,是现在通行的世界上最古老的表意体系的文字。成熟的汉字从甲骨文开始,已经使用了三千多年。随着社会的不断发展,汉字的数量在历史上不断增加,字的数量以万计,给学习和使用汉字带来了很多不便。人们在长期的实践中对汉字排检方法做了许多尝试,探索寻找汉字形体和汉语的声音、意义的内在联系和规律,为后人学习汉字提供一种检索方便、功能齐全的汉字工具书,许多汉字工具书应运而生。从周秦时代的历书、字书,到汉代许慎《说文解字》首次使用部首排检法以来,汉字排检逐渐形成了一门学科[1-2],它们的产生为中国文化的传承发展做出了不可磨灭的贡献。
一、汉字排检在中国文化传承和创新中的作用和意义
汉字排检是把一系列汉字按照一定的规律排列成系统,这个系统能够区分每一个汉字的次第,方便检索,它包括排列和检索两个方面,分别叫作排字和检字[2]。排字是检字的手段,检字是排字的目的。汉字排检法除了用于词典、百科全书等工具书的排检之外,还普遍用于索引以及文书、档案中各种名称的排序,在印刷排版、电子计算机汉字信息处理等方面也具有重要的作用。
(一)汉字排检是汉字工具书编辑不可缺少的方法
汉字工具书是指查找汉字的用法的工具书,叫作字典。广义的汉字工具书包括词典或者辞书,就是用来编辑和查找汉字记录的知识信息的文献,它系统地汇集某方面的资料,按照特定的方法加以排检,用来查找使用的书籍。无论是字典还是词典,汉字数量大、字库多,如果不使用一种方法去排检,这些工具书的编辑会出现混乱和无序的局面,给人们学习、使用和传承都带来许多不便。于是,人们利用各种汉字排检方法编辑了不少工具书,它们大都具有查检简单、检字准确和检字速度快等特点。
(二)汉字排检是传承、记录、收集和整理资料的重要工具
随着社会的发展,历史资料和文献的数量越来越庞大,因此,必须运用音序、形序排检的方法进行分类处理。这些资料与每个单位、部门乃至每个人的工作、学习都息息相关。另外,汉字排检法不仅可以为检索各行业不同历史阶段的历史资料提供方便,也可以提高各行业收集和整理日常文件资料的工作效率。
(三)汉字排检是现代计算机汉字输入方法创新的基础
目前,计算机汉字输入不外乎拼音字母、五笔等输入方法,它们都离不开汉字的排检。现代计算机汉字排检是给汉字提供了一种便于计算机识别的代码,使每个汉字能准确地对接相应的一个数字串或符号串,从而把汉字输入计算机系统,形成汉字信息处理方法及汉字编码技术,编码使用的字符集具有扩展性。可以说,没有汉字排检方法,就没有现代计算机汉字输入。
二、汉字排检方法的分类
汉字排检法的研究历史可以追溯到汉代许慎以前。如果从许慎首创部首排检法开始,至今也有一千八百多年的历史。在漫长的岁月中,创造的方法多种多样。
有学者认为,把这些汉字排检法按照汉字的属性来分类,大致可以分成义序、音序和形序3个序列。其中义序排检的辞书有《史籀》《尔雅》等,这种方法排检的字书,不注重字的排列顺序。这种辞书,包括今天的百科全书、分类词典、图书分类目录等都是首先按照词语的意义类型排列[2]。因为这个排检方法顶层排列是根据知识内容分类,同类型的知识词语用的排检方法还是要按照字的音序和形序方法排列,所以严格来说义序不属于汉字排检方法。因此汉字排检方法只有两种:古代的形序和现代新出现的音序。现代音序其实还是形序,就是拼音的形体顺序。可以说,任何文字的排序都只有形序,只是汉语的文字因为是汉字主导和拼音辅助,所以出现语素字的形序和音素字的形序的不同。
(一)形序排检法
狭义的形序排检法是建立在汉字本身的基础上的形序。以字头、词目、条头的形体特征,按设定顺序进行排序和查检的方法。现常用的方法有笔顺和笔画排检、部首排检和笔形号码排检。
1. 笔顺和笔画排检
笔画法和笔顺法一般结合起来使用,其中笔画法是按照汉字笔画数目(笔数)的多少进行排序的排检法,而笔顺法则是按照汉字起笔的笔形顺序进行分类的排检法。 1965年1月30日,文化部和中国文字改革委员会发布的《印刷通用汉字字形表》和1988年3月国家语言文字工作委员会、中华人民共和国新闻出版署发布的《现代汉语通用字表》规定了“一、丨、丿、丶、乛” 五种基本笔画,第11版《新华字典》使用笔顺和笔画排检法。
2. 部首排检
部首排检法自汉代许慎的《说文解字》首次使用以来,一直沿用至今。它是根据汉字字形的结构,把具有相同形旁的汉字归纳成一部,把相同的偏旁放在一部的开头,作为一部的领头字形,再把部首按一定的顺序排列。当今的常用的主要工具书都采用这种办法检索或排列,例如《新华字典》《现代汉字字典》等都使用了这种方法检索;《辞海》《辞源》等则采用这种方法检索和编排正文。
3. 笔形号码排检
它是把汉字的各种笔形变成数字,再按顺序排列汉字的方法,例如四角号码法,现在已经不常用。
(二)音序排检法
广义的形序还包括现在说的“音序检索方法”。音序排检法是用根据语音设计的跟传统汉字不同的字(字母)的习惯顺序排列。有人认为是“以字头、词目、条头的读音为序排检和检索的方法”(《辞书编纂基本术语》)不够准确,因为没有专用字母的时候,除了韵书是无法这样排检的。如果把韵书的排列也考虑进来,汉字音序排检可以分成语音汉字音序排检、注音字母音序排检和汉语拼音字母音序排检3个阶段。
1.语音汉字音序排检
因为当时没有专用的注音符号,所以用汉字兼作表音字母,例如用“帮滂并明……”代表现在的bpmf……按照声母、韵母、声调的配合关系,把每个字记录的语音组织起来的排检方法。因为着重在划分诗歌押韵的韵部,所以又叫作“韵书”,例如《广韵》《中原音韵》《五元方音》等[2]。这种韵书,其实是语音学知识,不是严格意义上的汉字排检方法。
2. 注音字母音序排检
汉字注音字母音序法是1918年由北洋政府教育部公布的,1930年由民国政府改名为“注音符号”,至今仍然在台湾地区沿用。这就是真正的音序排检方法,其实也是注音字母的形序。
3. 汉语拼音字母音序排检
汉语拼音字母音序法是依据1958年2月11日第一届全国人民代表大会第五次会议批准推行的《汉语拼音方案》的规定使用的拉丁字母。《新华字典》《现代汉语词典》一直使用这种排检方法检索汉字和编辑正文。同时,现代计算机也广泛利用拼音字母输入汉字。这是音序方法的改进。
综上所述,现代通行的汉字字典、词典中,主要运用了拼音字母排检、汉字笔画排检和汉字部首排检等3种排检方法,它们各有所长,各有不足。在汉语拼音排检方法的基础上,保留传统的部首排检方法,这无疑是当前最佳的结合方案。其中,检字一般采取拼音字母检字、部首检字、笔画笔顺检字的方法,或者采用拼音字母检字和部首检字相结合的方法,例如《新华字典》等。正文排序有两种情况:一是正文采用部首编排。它们把部首相同的字归纳在一起,顾及了形体、意义的关联,却不能方便读者认识语音,例如《辞海》《辞源》《汉语字典新编》等。二是正文按照拼音字母顺序编排。这个排列方法是按照音序音节把同一音节的汉字排列在一起,读者可以从认识一个字的读音知道一批字的读音,例如《新华字典》《现代汉语词典》等。该方法对读者“认字”无疑是很有好处的,但是它没有顾及汉字的形体和意义的关联。在汉字音、形、义三要素中,读音虽然在第一要素的位置,但是从“用字”的角度来衡量,那么形体和意义两个要素显得更为重要[3]。
三、汉字成字部件分析
汉字不是个别字符的随意堆积,它必须形成一个适应汉语词汇意义系统的构形系统,才能全面完成记录汉语的任务[4]。而汉字由部件构成,部件有大有小,它们在汉字形体构成和汉字形序排检中起着主导作用。在第11版《新华字典》部首检字表中的部首目录的基础上,把201个主部首和87个附形部首,按照汉字形体结构和汉字认知规律,把组成汉字的要素分成笔画、构件、偏旁、整字4个部件层次。
(一)笔画。它是由笔画组成的具有组配汉字功能的构字单位。通常是指组成汉字且不间断的各种形状的点和线,是构成汉字字形的最小连笔单位,例如“一、丨、丿、丶、乛”。它是构成汉字部件的第一层次。

(四)整字。它有独立的音义和具有衍生汉字能力的字。包括有衍生能力的独体字,例如“日、月、 山、水、牛”,还包括有衍生能力的合体字,例如“音、香、麻、鹿、鼻、鼓”等。
所有汉字都是由以上部件构成,用以上部件可以组合任何汉字,其结构关系如下:

说明:(1)部件是字的结构要素。构成字的部件根据成字能力大小分成四个级别:笔画、构件、偏旁、整字。(2)构件是没有独体字来源的部件。(3)偏旁在这里特别定义,是有独体字来源但是已经变形的部件。根据从接近独体字的程度不同分成:独体字强变形的偏旁、独体字弱变形的偏旁。(4)这里的整字是具有繁殖新字能力的汉字,包括独体字和合体字。(5)为了整齐体现四种部件的构成字的地位,这里其实牺牲了一些逻辑层次关系:根据是否能够独立做字把①②③ 跟 ④对应分成不成字部件和成字部件;根据笔画多少在不成字部件中把①和②③对应分成笔画部件和笔画组部件。
四、字根字和汉字的造字方法
本研究提出的字根字是指汉字中具有衍生能力的字,这些字大部分是独体字(基础字)和部分合体字。
在汉字造字方面,人们通过对汉字音、义关系和汉字形体结构特点的研究,总结出了汉字造字的“六书”,即象形、指事、会意、形声、假借和转注。其中,转注和假借属于用字的方法,这里不讨论。
(1)象形字。独立的形符,是最接近图画(表达形象的语义理据)的独体字,大部分是字根字。例如“木”是字根字,可以衍生“休、林、森、杏、李、呆”。
(2)指事字。简单复合的形符,是在象形字基础上增加或减少指示性的符号(表达抽象的语义理据)衍生的准独体字。大部分都是字根字,例如“刃”可以衍生“忍、纫、仞、讱、韧”。
(3)会意字。是在象形字的基础上,利用两个或两个以上的独体字的形体与意义所构成的、表示一个新的意义的字[5]。这些独体字在其他造字法中也有较强的衍生能力,属于本课题界定的字根字范畴,因此会意字的结构组成就是字根字加字根字(包括变形的字根字)。例如字根字“人”,通过增加左边变形的“人”字,衍生新的字“从”,再在该字上面加一个字根字“人”,会意成新的字“众”。
(4)形声字。是指具有表示字的意义的形符和具有语音理据的声符组成。形符大部分是独体字变形的偏旁;声符则是指具有衍生能力的汉字,也就是字根字。这种造字方法生成汉字的能力极强,85%左右的汉字是通过该方法创造的。例如字根字“皮”(声符),通过加偏旁(形符)即可衍生“波”“坡”“陂”“破”等字。
根据字根字在汉字造字结构中的作用和汉字的四种造字方法,可以看出,所有汉字都离不开字根字(部分无字根字除外),所有字根字通过加笔画或者构件或者偏旁或者字根字,可以组合任何汉字,其结构关系如下:

五、提出一种新的汉字形序排检方法
通过对汉字成字部件分析、汉字造字方法与字根字关系的比较以及汉字的认知规律,根据笔画笔顺、部首等形序排检法的优缺点,按照“以根归属,据形定部”的原则,以字根为归属标准,我们提出了一种新的汉字形序排检方法——汉字字根排检方法。
(一)主要概念界定
汉字字根排检方法是对现有汉字字族归类方法的创新,它涉及汉字语言文字学、方法学、心理学、教育学、统计学等学科。下面对本文新涉及的几个主要概念进行界定:
主字根:它是独体字(又叫基础字),是汉字不可撤笔画的最小单位,是构成汉字的最大部件。它是衍生繁殖新字的基础,例如“又”能衍生“叉”“双”“汉”等。主字根大都是象形字。但是,没有衍生能力的独体字不能叫字根,只能叫字,例如“飞”“凸”等字。
副字根:是指通过主字根增加或减少笔画,或是某部分与主字根的结构相近的汉字或构件,或取主字根某结构相同相近的部分。它是主字根的形近字,附在主字根后面。指事字往往属于副字根。
一级字根与一级字:指的是主字根或副字根衍生的汉字。它们部分又能衍生新的汉字,叫一级字根,例如,“又”衍生“皮”,“皮”衍生“波、破”等,“皮”为一级字根;没有衍生汉字能力的叫一级字,例如“破”为一级字。
二级字根与二级字:指的是一级字根衍生的汉字中,部分有衍生能力的汉字叫二级字根,例如“皮”衍生“波”,“波”又衍生了“婆、啵、菠”等,“波”为二级字根;没有衍生能力的汉字叫二级字,例如“婆、啵、菠”为二级字。

(二)整体思路框架
在第11版《新华字典》(商务印书馆)的基础上分析字的结构。该字典收集汉字字头13 000个。其中繁体字和异体字2 000多个,多音字重复占用单字头1 500多个,所以实际收的字是8 500多个。这个数字跟2013年国务院公布的《通用规范汉字表》的8 105个字基本一致,稍微多一点。它是采取拼音字母音节索引和部首检索相结合的方法,正文则采用拼音音序音节的排列方法。
本研究以汉字字根作为分类的标准,把《新华字典》8 500多个汉字(不包括繁体字和异体字)进行了拆字归类。据初步统计,在这些汉字中1个字根字构成的字2 600多个,2个字根字构成的字4 800多个,3个字根字构成的字1 500多个, 4个字根字构成的字230多个,5个字根字构成的字约28个,6个和7个字根字构成的字都只有1个,无法归属字根的字约14个。
在这个基础上,根据汉字字形内在的联系和汉字认知规律,把汉字排序从往往不成字的传统“部首”提升到字根(成字部件)的排列依据。在最高层次用字根字作归部标准,根据与字根形体相近的方式归并部首。然后在字根字下面排列形体不同的具体的部首(字根),再在每个具体字根字后面排列添加其他部件构成的字,最后解释这个字的形体结构,字记录的语素的声音和意义。这样可以使每个字区分,又能够把字根相同的字集中在一起对照查阅和学习。我们使用这个方法编辑出版新的字典。在新字典的检索方法中,有《字根目录》《检字表》《非字根字表》,就方便了解字根和检索字根字典正文的字条。
(三)汉字字根排检的具体方法
1. 检字方法
按照“以根归属、据形定部”的归类原则,字根检字表分别设有《字根目录》《检字表》《无字根字表》。
(1)《字根目录》,设有主字根和副字根。主副字根之间一般为形近字,它们具有形体结构相近或者形体某部分特征相近的关系(见表1)。
表1汉字字根目录(部分)

①在《字根目录》中选择了170个具有代表性的基础字作为主字根,将它们按笔画笔顺排列。主字根是汉字的最小单元,也是构成汉字的最大部件。考虑到部分字根所覆盖的汉字较多,为了检索方便,把部分具有代表性的合体字单列在《字根目录》主字根中,例如“口”根中的“古”“可”“石”“豆”“高”等字。
②在《字根目录》中确定副字根有257个,其确认方法有以下几种情况:第一,与主字根字形相同相近的字,例如“人”与“入”、 “七”与“匕”、“日”与“曰”等字;第二,是由主字根加减笔画以后衍生的新的字,例如“乂”与“义、父、交”、“也”与“乜”、“七”与“匕、比”等字;第三,取主字根的具有在不同字中重复出现的特征部位作字根归属标准,形成该字根的系列汉字,例如“走”与“疋、足、是、定”、“立”与“产、辛、幸、帝、商”等字。
(2)《检字表》。根据字根排检原则,在参照《字根目录》中主字根、副字根归类的基础上,把8 500多个汉字分布在《检字表》中(见表2)。
表2汉字字根检字表(部分)

①排序方法。该表按照《字根目录》中的主、副字根的顺序进行排列。主、副字根所衍生的汉字按照笔画由少到多的顺序排列。笔画数量相同的,根据起笔笔形按照“横(一)、竖(丨)、撇(丿)、点(丶)、折(乛)”的顺序排列。第一笔相同的,按照第二笔,依次类推。个别字为了学习使用方便则没有按照笔画笔顺排序,例如“旮、旯”等字。
②多字根字的排序。按照“先上后下、先左后右、先内后外”的取根原则排序。有的形近字为了区别使用,在选择字根时则没有按照上述原则排列,例如“贷、货”“要、耍”等字。
③多字根字的检字。《检字表》中对2个以上多字根的字,采取“多开门”的方法,可通过该字的任意字根查到该字,例如“赢”字可分成“亡”“口”“月”“贝”“凡”5个字根,在检字表中5个字根都能够查到“赢”字。
④该表不涉及繁体字的检索。简体字有繁体字的,在正文中加括号把繁体字附在简体字的后面。
(3)《无字根字表》。部分独体汉字,不可拆分字根,无法归类,为了便于检字查询,设有《无字根字表》。例如丌、彳、冇、书、凸、纠、年、祁、卣、钊、 事、芈、寒等。
当然,按照九年义务教育的要求,我们还会配套有常规的拼音检索和部首检索的方法。
2.正文排序
本排检方法的正文排序就是根据前面说的《字根目录》和《检字表》的顺序进行排列。《字根目录》中的主字根和副字根大都是形体相近或者主要特征一致的字。这个方法排列的正文,方便读者从形声字、形近字、会意字、多音字、生僻字的角度进行分析比较。
(1)形声字:基本按照声符集中排列。这样即使字的声符读音不同,也把它们归类在一起,方便对比记忆。对多字根的形声字,就按照字形先上后下、先左后右、先内后外的原则(部分汉字为了便于对照比较,没有按照这个原则)有限归属到那个字根下。
(2)形近字:按照主字根与副字根要求排列在一起。形近字中有的字单独不能记录有意义的语素,必须用多个字记录,例如“旯旮”“耄耋”等就没有按照笔画笔顺要求归类。
(3)会意字:一般是多字根字,按照先上后下、先左后右、先内后外的原则确定字根排序,部分字取其主要结构归属。
(4)多音字:字根排检可以把多音字的各种不同的读音归并在一个字头下。
(5)生僻字:字根排检使许多生僻字跟形体相似的常用字归并在一起,方便接触了解。
该正文排序如能达到以上效果,它将是一本多功能的汉字工具书。在普通工具书的基础上,它具备《错别字字典》《形声字字典》《形近字字典》《多音字字典》等字典的功能。
六、汉字字根排检与其他排检方法的分析比较
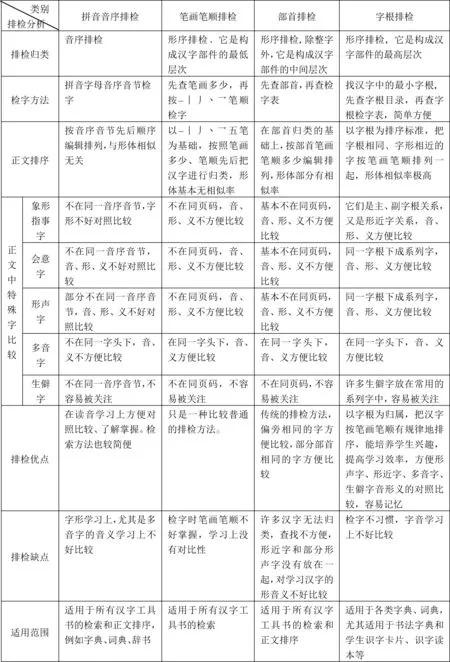
在目前常用的汉字排检中,最常见的是汉语拼音字母、部首、笔画笔顺三种排检方法,四角号码检字复杂不常用,而且不能用于正文排序,所以不进行比较和讨论。下面把拼音字母、笔画笔顺、部首三种排检方法与字根排检方法进行比较。
(一)汉语拼音排检
汉语拼音方案的写法与排列依据都是拉丁字母。优点是检字很方便,排序有规律。正文排序在识字认字上很有优势,在相同音节中能读一个字,就能够认识音节相同的所有字。缺点是减少了字形和意义学习上的关联,大部分汉字在字与字之间没有可比性,在字形上没有规律。多音字在不同页码,不好比较学习。
(二)笔画笔顺排检
这是形序排检上最简单的排检方法。但是笔画笔顺很容易弄错,要反复尝试,耽误时间。这种方法排列的字在形体、声音和意义上都失去了联系。因此这个方法一般只用于汉字工具书检字,正文排序很少采用,在学习功能使用上没有多大优势。
(三)部首排检
部首排检比笔画笔顺排检稍微复杂,在排检上有一定规律,尤其是形声字。但是通过我们的研究,还发现这种方法存在以下缺点:
(1)许多部首归属不明,人为地造成了检字的不便。许多汉字与人们的认识存在差异,例如主、广、出、所、平、上、芈、乡、齑等字。许多字形相同、相近的字,例如尤龙尨、可哥歌、竞竟赣戆等,形体相同或相近,但归属完全不同。
(2)部分部首利用率不高。在第11版《新华字典》201个主部首中,部分部首仅代表部首这个字,例如飞、无、长、阜、毋、龟等,部首后面2~3个字的也有不少。在87个附形部首中,部首后面仅一个字的也有不少,例如镸、尣、已等附形部首。而与这些部首相关的汉字并非只有一个,因为按部首排检将它们归属到了其他部首。例如,与主字根“无”字相关的芜、抚、呒、妩、庑等字没有归属在一起。这样既占用了有限的部首资源,学习使用时又不好比较汉字音、形、义的关系。
(3)具有递归结构关系的字被肢解了。这种方法使具有多级衍生能力的声旁为主的字根构成的字串支离破碎,不成体系,每个汉字显得很孤单。例如,“支”部,在部首排检中许多带“支”的字,如“伎”“芰”“技”“吱”“岐”“妓”“枝”“肢”等不在“支”的部首里,分散在其他部首中,还有“又”“青”等部首也是如此。这样排序造成了正文中字形相似率较低,给学习带来了诸多不便。
(4)形体相似率高的字被分离。部首排检法中的形声字,把形符作归属标准,但大部分形声字的形符在字的构成空间中,比例只占有1/3或1/4,它只能辅助声符构成字。例如“氵”构成的汊、沣、汪、沅、沸、沅,“扌”构成的捐、损、挫、换、描等字,只有字形中的部首相同。这种排检方法所排序的汉字,字与字之间相似率较低。
(5)整字部首。尽管它们有独立的音、义,但它们组字后大部分按声符读音,与形符无关。例如皮、身、羽、革、鬼、香、骨、鹿等整字部首。其中“皮”部,它既可以作形符,例如皱、皲、皴、颇等,又可以作声符,例如披、疲、彼、陂等。还有部分字既没有起到形符作用也没有起到声符的作用,例如波、玻、坡等字。这样的检索方法给学习带来了不便。
(6)大批无法归部的汉字,都是通过五个基本笔画 “一、丨、丿、丶、乛” 的起笔检索,这样造成了许多形近字被拆散,例如“从、丛”“史、吏”“或、彧”“日、旧”“及、乃”“川、卅、州”“艮、良”等。这种归部方式在正文中造成了字形相似率很低的现象。
(四)汉字字根排检
1. 在汉字检字索引上具有以下特点
(1)检字简单方便。绝大多数汉字都有字根(极少部分无字根的字外)。检字时,可根据汉字中任意字根查找它的归部。
(2)《字根目录》是主字根和副字根组成,所有汉字都是由它们衍生的。因此,只要掌握好了《字根目录》,就可以直接在正文中查字检字。
(3)在查检多字根汉字的时候,采取“多开门”的方法,先找到汉字中任意最小字根,再在《字根目录》中查找该字根在《检字表》中的页码,找到该字。
(4)为了与国家九年义务教育相适应,该方法编辑的工具书在检字上以部首检字和拼音检字为主。由于正文按照形序字根排检,所以把《新华字典》简单的拼音索引改成详细的拼音检字表,使读者通过拼音检索到每个字的正文页码。
2. 在正文的排序功能上具有以下特点
(1)象形字与指事字大都是主字根和副字根,同时,它们许多又是容易写错的形近字,把它们归类在一起,形成汉字字形的比较概念,可以大幅度地防止写错。对字形一致而笔画和笔顺不同的,找它们之间的共同字根,把它们放在一起,方便学习,例如旮旯、耄耋等字;有的容易混淆的字,找它们之间的共同字根,放在一起比较,例如货贷、灸炙、杳杲、耍要、庠痒、冶治、冮江等。
(2)会意字把字根相同或相近的字编排在一起,方便比较,例如赢、羸、嬴、蠃等。
(3)汉字中形声字占85%左右,在形声字中,声符大部分是字根字,把它们全部按声符归属,形成字串,通过学一字而识一串字,解决了大量容易读错的字(俗话称“白眼字”)。在学习的时候,也可以对照比较它们字形相同而读音不同的地方。这样既提高了学习效率,又培养了学生的好奇心。同时,它们之间又有形近字的关系,把它们串在一起,能有效地提高对汉字字形的辨析能力。
(4)多音字不同的字音和字义放在同一个字头下面,便于比较,防止用错,减少了音序排检在不同页码的麻烦,并且能节省版面。把音序排字的分立条目集中在一起,便于对相同的字进行读音和意义比较,例如差chā、差chà、差chāi,长 cháng和长zhǎng。

综上所述,通过以上几种排检方法的比较,可以看出它们各具特点、各有所长,在汉字的学习、使用和功能方面各有优势(见表3)。
表3字根排检与其他排检方法的比较
总之,汉字字根字是组成汉字最基础、最重要的部件和元素,也是每个汉字最核心的部分。因此,采用字根排检方法,把每个字根相同、字形相近的字排列在一起,使读者在学习汉字的时候,通过查找一个字,能了解与该字字根相同的系列汉字。在学习这个字时,能够举一反三、比较对照、触类旁通地识别一批形体相同或相近的字,防止写错、用错、读错,达到精准学字、识字、用字的效果。该方法还能运用于汉字的各种书法工具书的编辑、少儿课外读本,例如识字卡片、《汉字大家庭》《汉字家族》等课外读本(包括电子产品)。同时,还可以利用该方法开发计算机输入法,在汉语拼音输入比较普及的情况下,开发一种学习简单、操作方便、输入速度较快的形序输入方法,提高人们对汉字字形的认识,防止出现“电脑同音别字”和“提笔忘字”的现象。
这个研究成果具有原创性,它提出了中国汉字排检历史上的一种新的形序排检方法,具有较大的理论价值和应用价值。它排检的汉字工具书对培养学生学习汉字的兴趣、提高学习效益,对使用表音文字[6]的外国人学习汉字和汉字走向世界,对弘扬和创新中国文化都有着十分重要的意义。
