一种稀疏图正则化的非负低秩矩阵分解算法
2020-05-01刘国庆卢桂馥
刘国庆,卢桂馥,张 强
(安徽工程大学 计算机与信息学院,安徽 芜湖 241000)
0 引 言
聚类在特征学习和计算机视觉中是一项非常具有挑战的任务,许多聚类方法[1-3]被提出并在很多领域得到了成功应用,如图像分类[4],图像检索[5],图像分割[6],图像索引[7],图像聚类[8]等。然而对于图像聚类任务,一个非常重要的步骤是找到原始数据的有效低维表示。为此,很多研究者做了大量的工作来挖掘原始数据内在结构中的有用信息,使新的数据表示具有更好的识别能力[9-12]。矩阵分解是一类被广泛使用的数据表示技术,有奇异值分解(singular value decomposition,SVD)[13]、矢量量化(vector quantization,VQ)[14]和非负矩阵分解算法(non-negative matrix factorization,NMF)[15]等,NMF也是一种有效的图像表示工具[16]。1999年Lee和Seung在《Nature》杂志上提出NMF方法,以用人脸识别中的基于局部特征提取,该方法使得分解之后的矩阵中的所有元素都是非负的。NMF在心理学和生理学上的构造依据是其对整体的感知是由组成整体的部分感知所构成的,这恰恰也符合人类大脑对事物的直观理解。NMF在模式识别、信息恢复、神经网络、语音识别等很多领域已被广泛应用,且取得了很好的应用效果。
自NMF被提出以来,便得到学者的广泛关注和重视,并对其进行了深入的研究。为了提高NMF算法的识别率和有效性,人们在NMF算法的基础上提出了许多改进的NMF算法。Cai等[17]在标准NMF的基础上提出了图正则非负矩阵分解算法(graph regularized non-negative matrix factorization for data representation,GNMF),该算法针对流形数据,在矩阵分解过程中考虑了数据所携带的几何信息。Hoyer[18]把稀疏编码和标准NMF算法结合,提出非负稀疏编码算法(non-negative sparse coding,NSC),NSC算法使得矩阵分解后系数矩阵的稀疏性较好,这样可以用更少的有用信息来表达原有信息,在一定程度上提高了运算的效率。Li等[19]在标准的NMF目标函数中引入了局部化约束,提出了局部非负矩阵分解(local non-negative matrix factorization,LNMF)。Serhat等[20]提出了一种增量式非负矩阵分解算法(incremental non-negative matrix factorization,INMF),它避免了新训练样本加入后对基矩阵和系数矩阵的重新计算,从而节省了大量的运算时间。一般给定图像数据的有用信息常常是嵌入在高维欧式空间中的非线性低维流形上[21]。为了能够获得更加有效的低维数据表示,Li等[22]提出了图正则化非负低秩矩阵分解算法(graph regularized non-negative low-rank matrix factorization,GNLMF)。
研究表明,一方面,给定图像的有效信息常隐藏在数据的低秩结构中,数据通常是从嵌入在高维中的低维流形上进行采样的;另一方面,对数据加以稀疏约束可以在一定程度上提高相应算法抗噪声干扰的能力和鲁棒性。为了改善NMF算法的鲁棒性和可解释性,本文将原始数据的有效低秩结构和数据的几何信息引入到NMF中,同时又对基矩阵加以稀疏约束,提出了一种稀疏图正则化非负低秩矩阵分解算法(sparse graph regularized non-negative low-rank matrix factorization,SGNLMF),通过在ORL和YaleB人脸数据库上进行实验,验证了本文所提出的SGNLMF算法比现有的其他算法优异。
1 相关的工作
1.1 非负矩阵分解
目前矩阵分解技术主要有主成分分析、独立成分分析、奇异值分解等方法,这些方法虽然在分解时附加的限制条件不同,但它们都将原始数据矩阵表示为几个矩阵乘积的形式,这在数学上是对的,但在实际应用中往往缺乏直观的物理意义。NMF是一种被广泛应用的矩阵因式分解方法,也是一种有效的图像表示工具,它使得分解后的所有分量均是非负的,此方法使得矩阵元素具有实际的物理意义,为矩阵分解问题提供了一种新的思路。给定一个图像数据的非负矩阵X=[x1,x2,x3,…,xn]∈Rm×n+,它试图找到2个非负矩阵W=[w1,w2,w3,…,wl]∈Rm×l+和H=[h1,h2,h3,…,hn]∈Rl×n+,使其乘积最佳逼近原始矩阵X,即X≈WH,NMF的目标函数为
s.t.W≥0,H≥0
(1)
(1)式中,‖·‖2F表示矩阵的Frobenius范数,矩阵W可以看作是对原始矩阵X进行逼近的一组基,而矩阵H是样本集X在基矩阵W上的非负投影系数矩阵,系数矩阵是原始矩阵降维后的结果。
Lee和Seung在文献[16]中给出的乘性迭代规则为
(2)
(3)
1.2 图正则非负矩阵分解
在现实世界中,许多数据是嵌入在高维欧式空间中非线性低维流行上的,然而,NMF算法和许多改进的NMF算法在对原始数据处理时,没有考虑数据的内蕴几何结构。为了能够发现数据隐藏信息的表示方法,同时又考虑数据内在的几何信息,Cai等[17]通过将图正则化项融入到标准的NMF框架中,提出了图正则非负矩阵分解算法。该算法假设2个数据点在原始数据空间中的几何距离如果是邻近的话,则其在基于新的基向量低维表示中相对应的数据点也应该离得很近。与传统的降维算法相比,流形学习算法能够揭示原始数据内在的几何结构,寻找高维数据在低维空间中的紧致嵌入。GNMF的目标函数为
s.t.W≥0,H≥0
(4)
(4)式中:tr(HLapHT)是图正则项;Lap是图拉普拉斯矩阵,图正则化参数λ>0。
Cai等在文献[17]中给出了如下的迭代规则
(5)
(6)
(5)—(6)式中,Dap是对角矩阵,Lap=Dap-Wap。
1.3 图正则非负低秩矩阵分解
大多数现有的对NMF改进的方法直接将NMF方法应用于高维图像数据集上,来计算原始图像的低维表示。然而,事实上,给定原始图像数据的有用信息常常是嵌入在高维欧式空间中的非线性低维流形上的。为了能够挖掘数据图像中的有效低秩结构部分,Li等[22]提出非负低秩矩阵分解算法(non-negative low-rank matrix factorization,NLMF),并进一步构造出图正则非负低秩矩阵分解算法(GNLMF)。与传统算法相比,该算法将流形结构信息结合到非负低秩矩阵分解的目标函数中,使得其识别率和鲁棒性都有一定的提高。GNLMF算法的目标函数为
minL,S‖X-L-S‖2F+αtr(HLapHT)+βtr(WWT)
s.t.L,W,H≥0
(7)
(7)式中,α,β是图正则化参数。
Li等在文献[22]中给出的迭代更新公式为
(8)
(9)
2 稀疏图正则非负低秩矩阵分解
近年来,稀疏优化在图像处理,信息恢复,模式识别等领域都得到了成功的应用。被很多科研人员所重视,研究表明,对数据加以稀疏约束可以在一定程度上提高相应算法的抗噪声干扰能力和鲁棒性。为了提高NMF算法的鲁棒性和可解释性,本文提出一种稀疏图正则化的非负低秩矩阵分解算法(SGNLMF),该算法不仅考虑了原始数据的有效低秩结构和几何信息,还对基矩阵加以稀疏约束。
2.1 SGNLMF的算法模型
一般来说,给定图像的有用信息常常隐藏在它们的低秩结构中,为了挖掘原始数据的有效低秩结构部分,X可以近似表示为L+S的和。其中,L表示原始数据X的低秩部分,S表示稀疏噪声部分,求出低秩部分L之后再对其进行NMF操作,来获得原始数据图像的低维表示。
minL,S‖X-L-S‖2F
s.t.L=WH,L,W,H≥0
rank(L)≤r,card(S)≤s
(10)
(10)式中:W是基矩阵;H是系数矩阵;r表示矩阵L秩的范围集;s表示矩阵S的稀疏范围集;rank(L)表示矩阵L的秩;card(S)表示矩阵S的非零元素个数。
为了确保基矩阵W的的光滑性,对基矩阵W进行Tikhonov正则化处理
(11)
(11)式中,tr(·)表示矩阵的迹,结合(10)式和(11)式,可以得到
minL,S‖X-L-S‖2F+βtr(WWT)
(12)
(12)式中,β是Tikhonov正则化参数。
结合数据的几何结构信息,对(12)式引入图正则化项tr(HLapH),则有
minL,S‖X-L-S‖2F+αtr(HLapHT)+βtr(WWT)
(13)
(13)式中:α是图正则化参数;Lap=Dap-Wap是图拉普拉斯矩阵;Wap是对称权重矩阵;Dap为一个对角矩阵。
稀疏性和低秩性对于数据的表示和分析具有非常重要的意义,将稀疏编码理论和GNLMF算法结合为稀疏图正则化非负低秩矩阵分解算法,该算法可以在给定基向量集的基础上,产生对高维数据的低维近似表示。对于约束项的选择,是约束W的稀疏度,还是约束H的稀疏度,或者是约束两者的稀疏度,取决于具体的应用,由于基矩阵W包含原始数据的特征信息,对W作稀疏约束可以提高基矩阵存储和计算的便利性。为了提高NMF算法的准确率和鲁棒性,本文对基矩阵W加以稀疏约束,将稀疏约束项融入到(13)式中,可以得到SGNLMF算法的最小化目标函数
minL,S‖X-L-S‖2F+αtr(HLapHT)+
βtr(WWT)+γ‖W‖1
s.t.L=WH,L,W,H≥0
rank(L)≤r,card(S)≤s
(14)
(14)式中:γ为基矩阵W的稀疏约束参数;‖·‖1表示L1范数。
2.2 SGNLMF的求解算法
考虑到(14)式关于W和H是非凸的,本文采用交替迭代方法来学习图像数据X低秩结构的低维表示,SGNLMF算法可以通过求解下面的2个子问题来解决:①低秩矩阵的恢复;②NMF的相关子问题。详细过程如下。
1)低秩矩阵的恢复。低秩恢复子问题的目标函数为
minL,S‖X-L-S‖2F
s.t. rank(L)≤r
card(S)≤s
(15)
(15)式中:r是低秩结构L的秩;s表示矩阵S的稀疏范围集。虽然(15)式对于L和S是非凸的,但是,如果L或S中的一个被固定,则下面的子问题是凸的。
(16)
因此,(16)式中的2个子问题可以通过固定其中的一个更新另一个来解决,直到收敛为止。实际上,在每一次的迭代中,对X-St-1进行奇异值分解是比较耗时的,本文使用了双边随机投影(Bilateral Random Projection,BRP)[23]来求解(15)式。对于给定的矩阵X∈Rm×n,Y1,Y2表示为
Y1=XA1
(17)
Y2=XTA2
(18)
(17)—(18)式中:A1∈Rn×r;A2∈Rm×r都是随机矩阵,则L为
L=Y1(AT2Y1)-1AT2
(19)

(20)
(21)
(22)
通过对Y1和Y2进行QR分解,则L表示为
(23)
在计算出L之后,再对L进行NMF分解以获得图像数据集的低维表示。
2)NMF的相关子问题。图正则化非负低秩矩阵分解,Tikhonov正则化和稀疏约束子问题的目标函数为
minW,H≥0‖L-WH‖2F+αtr(HLapHT)+
βtr(WWT)+γ‖W‖1
(24)
针对稀疏约束子问题,需要进行相应的稀疏优化:对于一个给定的线性系统如:Ax=b,A∈Rm×n,我们知道,当矩阵A中有m 根据上述的稀疏优化相关模型,当想要得出模型的解能够呈现出稀疏的性质时,简单的方法就是在目标函数中直接添加一个稀疏惩罚项,本文中这个惩罚项加在基矩阵W上,为了保持模型的凸性,采用L1范数进行惩罚。则(24)式的表达式可以重写为 F(W,H)=tr((L-WH)(L-WH)T)+ αtr(HLapHT)+βtr(WWT)+γ‖W‖1= tr(LLT-2WHLT+WHHTWT)+αtr(HLapHT)+ βtr(WWT)+γ‖W‖1 (25) Q=tr(LLT-2WHLT+WHHTWT)+ αtr(HLapHT)+βtr(WWT)+tr(ΨWT)+ tr(ΦHT)+γ‖W‖1 (26) 函数Q对W,H求得偏导的结果如下 (27) (28) 根据KKT条件,满足ψilwil=0,φljhlj=0,则可以得到关于wil和hlj的方程如下 -(LHT)ilwil+(WHHT)ilwil+(βW)ilwil+ (29) (WTWH)ljhlj+(αHDap)ljhlj= (WTL)ljhlj+(αHWap)ljhlj (30) 由(29)式和(30)式可以得到wil和hlj的更新规则如下 (31) (32) 问题(24)可以通过梯度下降法来解决[25],相应的更新规则如下 (33) (33)式中,ηil,δlj为迭代步长参数。 为了方便,令δlj=-hlj/2(WTWH+αHDap)lj,则 (-2WTL+2WTWH+2αHLap)lj= (34) 同理,令ηil=-wil/2(WHHT+βW+γI/2)il,则有 (-2LHT+2WHHT+2βW+γI)il= (35) 从上述过程可以看出(31)式和(32)式是梯度下降算法的一个特例,在这些更新规则下可以得出(24)式是非增的,同时可以确保矩阵W和H的非负性。 定义1 设G(w,w′)是F(w)的辅助函数,满足条件:G(w,w′)≥F(h),G(w,w)=F(w)。 引理1 如果G(w,wt)是F(w)的辅助函数,则F(w)在下面迭代更新规则下是非增的 wt+1=argminwG(w,wt) 证明:由上述可以得出结论:当w=wt+1时函数G(w,wt)取最小值,根据定义1,G(wt+1,wt)大于等于F(wt+1),可以用不等式表示为 可以注意到,F(wt+1)=F(wt)只有当wt为G(w,wt)的局部极小点时才成立。如果函数F的导数存在且在wt的一个极小领域内连续,则微分F(wt)=0。通过引理1可以得到一列收敛到局部极小点wmin=argminwF(w)的序列 F(wmin)≤…≤F(wt+1)≤ F(wt)≤…≤F(w1)≤F(w0) 可以看到,通过定义辅助函数G(w,wt),对于目标函数(24)式,其相应的迭代规则可以满足wt+1=argminwG(w,wt)。 输入:数据矩阵X∈Rm×n+,参数p,α,β,γ。 输出:最优稀疏基矩阵W和数据的低维表示矩阵H。 1)对X进行BRP操作,求出Y1和Y2; 2)对Y1和Y2进行QR分解,计算出矩阵X的低秩结构L; 3)对矩阵L进行NMF分解; 4)计算 5)求得最优稀疏基矩阵W和数据的低维表示矩阵H。 为了对本文所提出的稀疏图正则非负低秩矩阵分解算法的有效性进行评估,分别在ORL和YaleB 2个人脸数据库上进行实验。 ORL人脸库是由剑桥大学实验室所创建,是在不同的光照条件下图像包括了表情,姿态和面部表情的变化。它由40个人共400张面部图像组成,每个人有10张灰度图像,由于照片拍摄于不同的时期,人脸和面部表情有着不同程度的变化,深度旋转和平面旋转可达20°,在本文的实验中,图像的大小为32×32,图1是用于实验的ORL人脸库中的部分图像。 YaleB人脸数据库由38个人组成,每个人大约有64张在不同光照条件下的灰度图像,在本文的实验中,图像的大小为32×32,图2是用于实验的部分YaleB人脸图像。 为了验证SGNLMF算法的优越性,将它与K-means,PCA,NMF,GNMF,GNLMF等算法进行了比较,详细算法如下。 1)K-means:在原始数据集上进行,而不使用样本中包含的任何信息; 2)PCA:能够有效地提取原始数据集中的主要成分; 3)NMF:试图找出2个非负低维矩阵,其乘积近似为原始矩阵; 4)GNMF:试图通过构造一个简单的图来包含数据中的内在几何结构信息。最近邻数p设置5,图正则化参数设置为100; 5)GNLMF:最近邻数设置为5,图正则化参数设置100,Tikhonov正则化参数也设置为0.000 1。 6)SGNLMF:考虑原始数据的低秩结构和几何信息,并对基矩阵加以稀疏约束,最近邻数设置为5,图正则化参数设置为100,Tikhonov正则化参数设置为0.000 1, 稀疏约束参数设置为2。 聚类性能的评价通过原始样本的类别信息和使用算法所得结果的对应程度进行评价,本文采用正确率(accuracy,AC)和归一化互信息(normalized mutual information,NMI)2种常用准则来评价聚类性能。AC的定义如下 (36) (36)式中:n为整个数据集的规模大小;gndi是数据集提供的实际标签;如果a=b,则δ(a,b)=1,否则,δ(a,b)=0;zi是使用本文的算法所得出的样本X的标签;map(zi)是将本文的算法得出的标签映射到数据集提供的实际标签的最优置换函数。 NMI是另一种被广泛用于评价聚类结果的方法,NMI是C和C′相似性的度量,在这里C为由已知的类提供的真实值,C′是由本文的算法所获得的类。互信息(mutual information,MI)可以看成是一个随机变量中包含的关于另一个随机变量的信息量,则C和C′的互信息可定义为 (37) (37)式中:p(ci)和p(c′j)分别是任意选择的样本X属于C和C′的概率;p(ci,c′j)是样本X既属于C类又属于C′类的概率,NMI的定义为 (38) (38)式中:H(C)是类C的熵;H(C′)是C′的熵;NMI是C和C′相似性的度量。 通过在ORL和YaleB数据库上进行实验来验证本文所提出的SGNLMF算法的优异性。 在实验中,当本文提出的SGNLMF算法其最近邻数p设置为5,图正则化参数设置为100,Tikhonov正则化参数设置为0.000 1,稀疏约束参数设置为2时,其图像识别率和归一化互信息比设置其他参数表现要好。表1~表4和图3~图6给出了在选取不同的类别数K时,6种算法在ORL人脸数据库和YaleB人脸数据库上的识别率和归一化互信息。本文在进行实验时,随机选取数据样本,并重复20次,最终实验结果为20次实验结果的平均值。从上述的实验结果中我们发现,在类别数K取不同的数值时,本文所提出的SGNLMF算法因其考虑了原始数据的低秩结构,利用了数据内部的几何信息,同时又对基矩阵加以稀疏约束,使得它比其他算法的聚类性能要优异。 表1 不同算法在ORL数据库上的聚类结果ACTab.1 Clustering results of different methods on ORL database AC % 表2 不同算法在ORL数据库上的聚类结果NMITab.2 Clustering results of different methods on ORL database NMI % 表3 不同算法在YaleB数据库上的聚类结果ACTab.3 Clustering results of different methods on YaleB database AC % 表4 不同算法在YaleB数据库上的聚类结果NMITab.4 Clustering results of different methods on YaleB database NMI % 针对现有的NMF算法存在对噪声敏感,鲁棒性差等缺点,为了提高NMF算法的鲁棒性和可解释性,本文提出了SGNLMF算法,通过利用原始数据的的低秩结构,并将数据的几何信息融入到NMF中,同时对基矩阵加以约束,使得该算法在ORL和YaleB数据库上的实验表现出较高的识别率和较好的鲁棒性以及可解释性。下一步我们将调整稀疏惩罚项,使其能够适应更多的问题,得到更好的应用效果。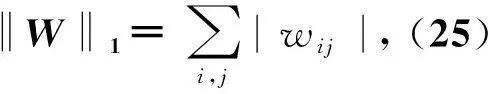
2.3 与梯度下降法之间的联系
2.4 收敛性分析
2.5 稀疏图正则非负低秩矩阵分解算法步骤
3 实验与结果分析
3.1实验使用的数据库
3.2 算法比较
3.3 评价准则
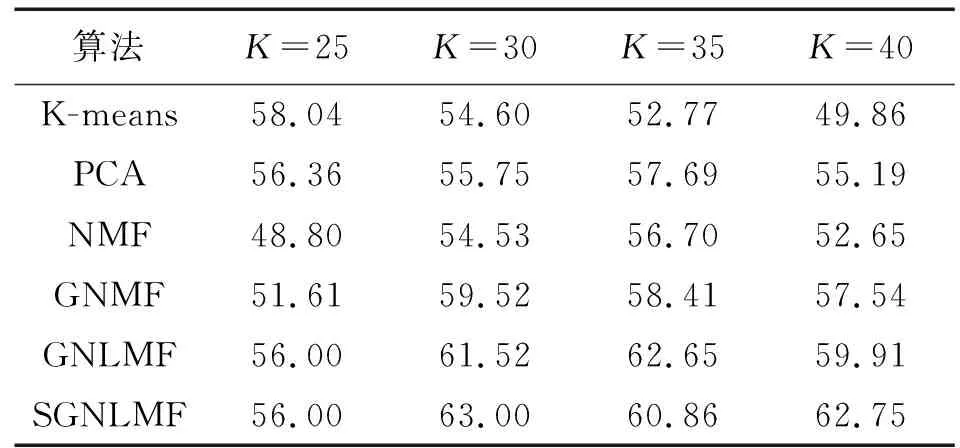
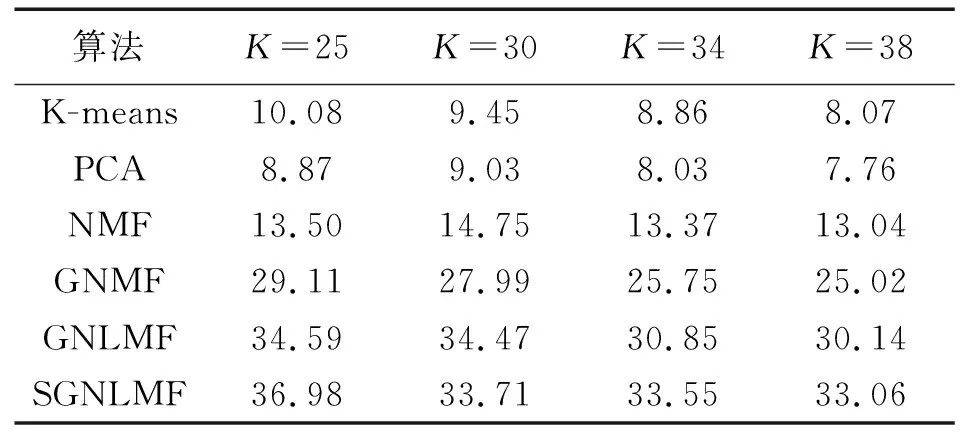
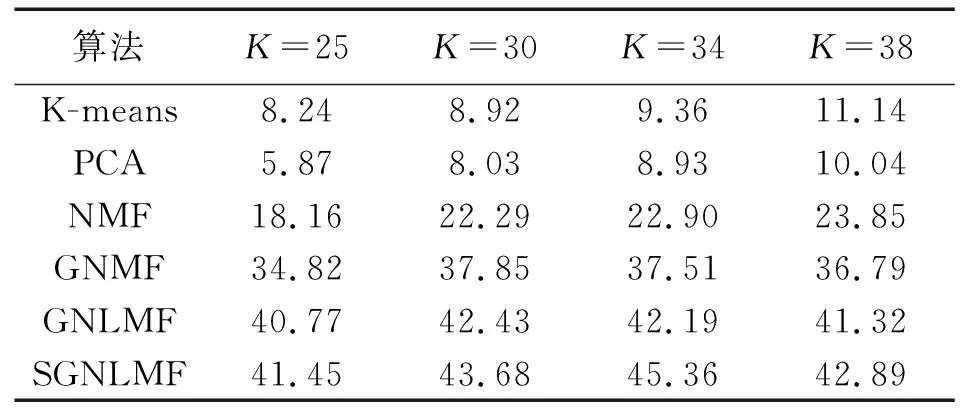
3.4 性能的评价和比较

4 结束语
