绿色云计算环境中基于温度感知的虚拟机迁移策略
2020-05-01陈阳,王勇
陈 阳,王 勇
(1.安徽工程大学 现代教育技术中心,安徽 芜湖 241000;2.安徽工程大学 计算机与信息学院,安徽 芜湖 241000)
0 引 言
为了倡导绿色云计算环境,近年来大规模节能的云数据中心的构造与使用成了政府和各大IT企业越来越重视的问题,云数据中心的构造目标是低能量消耗、高服务质量(quality of service,QoS)、节省物理空间和高可靠性等[1-4]。一个数据中心(data center,DC)通常配置有大量的紧密堆积在一起物理节点(physical machines,PM),目的是提高建筑物空间的利用率;虚拟化技术是云数据中心中最关键的技术,虚拟化允许用户对云资源的访问是透明与简单方便的, 它通过虚拟机(virtual machines,VM)的形式将应用程序封装起来,通过虚拟机分配策略将其分配到具体的数据中心的物理节点之中执行。在应用程序执行过程中,利用虚拟机迁移策略来提高云资源的利用效率,节省云服务提供商的能量消耗和成本。针对虚拟机迁移策略,目前大量的文献考虑的迁移因素都关注在物理主机的CPU使用效率,内存大小,空余磁盘空间,网络带宽等方面, 把性能指标关注在违规比率、QoS、系统能量消耗、虚拟机迁移次数等方面[5]。
本文提出了一种绿色云计算环境中基于温度感知的虚拟机迁移策略(TA-VMM),与当前主要的迁移策略不同的是,该策略考虑的主要因素是云数据中心的物理节点的温度情况和能量温度结合情况。建立了虚拟机选择和虚拟机分配过程中物理资源的温度和能量的数学模型;TA-VMM由虚拟机选择算法和虚拟机重分配算法TDR 2个部分组成。最后,在Cloudsim云计算模拟器上实现和测试了TA-VMM的策略。实验结果表明,在TA-VMM节省能量和虚拟机迁移次数方面具有较好的性能,SLA违规方面只有极小的增加。
1 相关工作
目前,学术界为了节省云数据中心的能量消耗,构建绿色云计算环境,进行了大量的研究。第1种是运行冷凝系统保证物理服务器的空间不会过热[6];第2种是通过虚拟机迁移策略和算法,即云服务提供商应用虚拟机迁移与合并策略到公有云、私有云、混合云之中。
第2种又主要分为3类:①早期的单纯的虚拟机迁移策略,没有采用相关智能算法进行优化;②贪心算法、遗传算法等进行优化的虚拟机分配与迁移策略;③Anton Beloglazov博士等为团队开发的以Cloudsim模拟器平台中的迁移策略为主线的虚拟机分配策略的研究。
对于第1类相关研究, 文献[7]提出了云数据中心的绿色计算的思路和减少碳泄露(carbon emission)的方法。它提出的方法都可以支持低能量消耗和减少碳泄露,实验结果显示,可以减少23%的能量消耗和25%的碳泄露;文献[8]提出了虚拟机迁移中一个自适应的低能量消耗方法,使用模糊推理引擎来决定虚拟机的分配与放置,实验结果显示,针对普通的能量管理算法,可以减少18%的能量消耗;文献[9]提出了云数据中心中的虚拟机迁移策略,使用动态的方式使其满足客户端的各种SLA应用程序需求,实验结果显示,该策略可以保证60%的物理服务器中的SLA违规忽略不计,在一定程度上可以保证云数据中心的QoS服务质量;文献[10]在Anton Beloglazov博士的基础上提出SLA违规算法,引入最小能量最大利用率策略,进一步优化虚拟机配置方法。
对于第2类研究,文献[11]从CPU维度对虚拟机的动态配置问题进行建模,并利用改进的蛙跳算法进行求解;文献[12-13]提出了云计算中基于贪心算法的任务调度及改进,把改进任务竞争时间和改进任务执行代价作为主要因素。实验结果表明,贪心算法在串行调度算法的基础上可以改进任务调度的性能,但是它们并没有将贪心算法物理资源低能量消耗相关的算法之中;文献[14-16]都提出了遗传算法优化的云数据中心虚拟机迁移策略,相关实验数据表,其性能要优于贪心算法和无智能优化算法等。
对于第3类研究,文献[17]分析了虚拟机迁移及其相关的动态虚拟机合并问题,提出了自适应的基于数据历史分析的启发式算法来保证低能量的消耗,实验结果显示,局部规约算法(local regression algorithm)和最近时间迁移(least time migration)方法性能优于其他常见方法;文献[18]提出了能量相关的云计算的体系结构和方法,它的主要思想是基于虚拟机的动态合并,利用Cloudsim[19]来模拟与评测算法的性能,结果显示,针对静态的资源分配方法,它可以很好地降低云数据中心的能量消耗;文献[20]提出了云数据中心考虑资源使用阈值边界的虚拟机分配策略, 可以根据云端当前工作负载的状态来获得资源的使用效率情况,在工作负载高于或者低于设置的阈值上界与阈值下界时,该物理主机上的虚拟机将进行迁移,放置到新的物理主机上,测试结果表明,比Cloudsim中已有的median absolute deviation(MAD)策略,static threshold(ST)策略,local regression(LR)策略,local regression robust(LRR)策略和inter quartile range(IQR)等的性能都要优秀。
上述这些方法的主要目的是应用虚拟机动态迁移技术实现云端服务的负载均衡和容错,节省服务器的能量等,最终是为了改善云端的服务质量QoS,减少SLA违规, 虚拟机在迁移时考虑的物理资源使用情况的维度由早期的单一CPU利用率到现在的多个维度的指标,甚至后面还有硬件因素、软件因素、网络带宽因素、网络设备接口能量消耗等[21]。
TA-VMM也是为了构建绿色云计算环境,针对云端的多种应用服务请求处于动态变化情形下,提出的一种云数据中心的虚拟机动态迁移模型, 可以认为它是针对Cloudsim云计算模拟器进行后续研究的虚拟机迁移策略,在资源申请时考虑的主要因素是温度情况和能量情况,这是其他各类算法考虑较少的地方,它可以避免物理服务器严重的hot-spot 或者cold-spot问题。虽然文献[22-24]在资源分配时也考虑了一些温度因素,但是并没有利用到云端的虚拟机选择与分配之中。
最近这几年又有文献提出采用软件的方法来提高虚拟机分配和虚拟机放置策略的性能,还有文献提出需要在虚拟机迁移过程中考虑网络攻击危险,保证云数据中心的可靠性。例如文献[25]把虚拟机迁移过程划分为物理主机状态检测、虚拟机映射、虚拟机选择、虚拟机放置4个复杂的步骤,其中,虚拟机映射主要通过任务粒度、软件代价等来进行调整;虚拟机放置属于一类经典装相问题,即把大量的VM放置到大量的物理节点之中,它提出要考虑虚拟机映射和虚拟机放置之间的相互联系来改善性能。文献[26] 提出了云数据中心基于安全检测的虚拟机迁移策略。利用隔室技术及SIR(susceptible, infected, recovered)模型在虚拟机迁移过程将有安全威胁的虚拟机隔离出来,保证云数据中心的能量消耗与安全级别的平衡。
2 相关概念描述
2.1 能量消耗模型
在TA-VMM中,物理主机的温度做为重要因素在虚拟机选择和分配过程中予以考虑,其工作场景为一个云数据中心有N个物理服务器节点,云平台上运行着M个虚拟机。云客户端向云数据中心申请资源的时候,存在着虚拟机迁移,虚拟机合并等事件,多个虚拟机也可以被分配到一个单独的物理服务器节点,我们设计了下面的能量消耗数学模型。
物理服务器节点的能量消耗的主要决定因素往往包括主机的CPU使用率、内存大小、磁盘空间大小及网络接口的使用率等。在这些因素之中,CPU往往是物理主机最重要的能量消耗因素,这也是前5~8年的虚拟机迁移策略的论文主要分析的是CPU利用情况的原因所在。后期有相关文献[21]表明,一个空闲的物理服务器大约也要消耗它的峰值能量的70%,所以关闭那些空闲的物理服务器在云数据中心十分重要。
在TA-VMM中,为了计算云端的能源消耗,假设服务器是空闲的,它的能源消耗百分比是k,pfull表示服务器在完全满负载工作时的能源消耗(峰值能量消耗),ui是当前的物理主机i的CPU使用效率。物理主机的能量消耗为整个云服务器端的能源消耗为
Pi=k·pfull+(1-k)pfull·ui
(1)
(2)
2.2 温度模型
在温度的数学模型中,TA-VMM主要参考了文献[27]中的lumped RC物理服务器的温度行为。即在时刻t的情况下,假设一个能量消耗为P的处理器的温度可以描述为
T(t)=P·Rth+Tamb-
(P·Rth+Tamb-Tinit)·e-t/RthCth
(3)
(3)式中:Rth和Cth分别表示其等效的热电阻和热电容;Tamb表示环境温度;Tinit表示初始温度。
2.3 物理主机过负载检测
由于在虚拟机迁移过程中经常要判断物理主机是否空闲或者超负荷,所以TA-VMM中参考了Cloudsim开发团队中的描述,定义了几种物理主机超负载检测算法。
1)固定阈值(static threshold,THR):资源在使用过程中,采取一个固定的使用效率阈值,例如80%或者20%, 超过或小于这个范围的情况下,虚拟机就要进行迁移。
2)四分差(interquartile range,IQR):设置一个资源使用的上限利用效率阈值,用来调整CPU的使用效率。
3)绝对中位差(median absolute deviation,MAD):设置一个资源使用效率阈值,根据CPU的使用效率的中位来确定是否迁移虚拟机。
4)局部鲁棒性(local regression robust,LRR)规约:寻找一个趋势多项式到最近的CPU使用效率的j个观察值来评测下一个观察值,最后检测其是否满足物理主机超负载的状态。
2.4 虚拟机选择策略
TA-VMM虚拟机迁移策略包括2个过程:虚拟机选择和虚拟机重新分配。TA-VMM中也采用了Cloudsim中的虚拟机迁移方法作为比较性能,这些已有的策略描述如下。
1)最大关联(maximum correlation,MC)选择方法:即选择同一个物理主机上的且与CPU使用效率有最高关联度的虚拟机作为对象。
2)最小迁移时间(minimum migration time,MMT)选择方法:即迁移一个在最短时间内能够完成的虚拟机作为选择对象。
3)最小使用效率(minimum utilization,MU)选择方法:即对一个具有最小使用效率的虚拟机进行迁移。
4)随机选择(random selection,RS)策略:即在物理服务器上随机选择一个虚拟机进行迁移。
3 TA-VMM虚拟机迁移工作机制描述
3.1 主要步骤
TA-VMM虚拟机迁移策略的工作机制包括下面3个步骤:①判断出目标物理主机,即哪个是超负载工作主机或者未超负载的工作主机;②选择一个虚拟机进行迁移,该迁移一般都是从超负载的物理主机上选择;③重新分配虚拟机到那些未超负载的物理主机之上。
在这个过程中,可以采用不同的策略来完成超负载状态的检测,如果一个物理主机的CPU使用率已经超过一个设定的阈值,那么该物理主机上的一个或者多个将必须迁移到另外一个物理主机上,这样的目的是防止产生潜在的SLA违规。在虚拟机迁移结束阶段,那些没有虚拟机运行的物理主机关闭,最终可以节约云数据中心的能量消耗。
3.2 虚拟机选择算法
在TA-VMM中,只要有一个物理主机被检测到处于超负载工作状态,其上的虚拟机将进行迁移,在这个步骤中,本文提出了虚拟机选择算法,该算法的目的是在超负载的物理主机上迁移一个或者多个虚拟机,目的是为了使该物理节点在虚拟机迁移之后获得。 这里值的计算方法为其最优温度和当前温度的距离的绝对值。在这种情况下,如果物理服务器可以控制在根据文献[24]提出的最优温度,那么主机的能量消耗和SLA违规的值都可以保持到相对最低值, 为了最小化,虚拟机选择算法将选择VMj完成迁移,定义为
MTD=|Topt-Ti|
(4)
(4)式中:Ti表示物理主机i的温度;Topt表示物理主机的最优温度。文献[24]中提到,在这个情况下,云平台可以获得能量消耗和SLA违规的相对平衡。
定义这个虚拟机选择算法为MTD, TA-VMM中MTD算法的伪代码如算法1。算法的输入是超负载的物理主机列表,输出是被选择出的虚拟机列表。
Algorithm 1:VM Selection Policy // 虚拟机选择策略
输入 Input: OverUtilizedHosts, vmList //超负载物理主机列表,虚拟机列表
输出 Output:VmsToMigrateList //侯选迁移虚拟机列表
1 for each host in OverUtilizedHosts do //针对所有的超负载物理主机中的每一个物理主机。
2 minTD=MAX //变量MAX赋值给最小温度距离变量minTD
3 migratableVM=NULL //可迁移的虚拟机被赋值为空
4 for each vm in vmList do //针对所有的虚拟机列表中的每一个虚拟机。
5 if TD< minTD then //如果温度距离TD小于变量minTD
6 migratableVM=vm //虚拟机被赋值为可迁移的虚拟机
7 minTD=TD 变量TD赋值给最小温度距离变量minTD
8 end if //结束if循环
9 end for //结束For循环
10 VmsToMigrateList.add(migtatableVM) //将虚拟机加入到侯选迁移虚拟机列表
11 end for //结束For循环
12 return VmsToMigrateList //返回侯选迁移虚拟机列表
3.3 虚拟机分配算法
TA-VMM的最后一个步骤是重新分配被选择好的虚拟机到新的合适的物理主机,这种问题可以类比为一种经典装箱问题(bin packing problem) 。每个物理主机上的CPU作为可用资源可以类比为箱的尺寸,货物代表了将要被分配的虚拟机, 价格代表了物理主机的温度距离比率(temperature distance ratio,TDR),即TDR是TA-VMM迁移策略中提出的一个参数,下面详细解释TDR。
当前的CPU都比较先进,处理器都有自动测量芯片温度的功能,如果芯片处于高温的状态,即表明它有高的能量消耗,芯片长期处于功耗大的状态将会出现硬件故障,所以在TA-VMM中,我们期望迁移过来的虚拟机能够使CPU处于低能量消耗状态和低温的状态,TDR定义为
(5)
TDR函数既利用了前面的能量模型,也考虑了温度模型, 所以TA-VMM最后一步为参考TDR的具体值来完成虚拟机的再分配。值得注意的是,在相同CPU使用效率的情况下,一个主机如果有比较高的每秒百万条指令(million instructions per second,MIPS) 值, 那么它消耗的能量也相对要多。在相同情况下,2个物理主机可能容纳不同数量的虚拟机,因此,仅仅通过简单考虑物理主机使用效率或者能量消耗是很难有一个正确的温度控制。所以TDR函数的设计只是将迁移那些最接近最优温度的虚拟机。本文采用一个修改的最佳适应递减算法(best fit decreasing algorithm,BFD)并实现[17],在TA-VMM中称为TDR-BFD。
在TDR-BFD中,被选择好的虚拟机按照CPU使用效率递减的方式排序,那些排序好的虚拟机将被分配到新的合适的物理节点,这样就使TDR值获得最小的增加。
TDR-BFD虚拟机分配算法执行完后,虚拟机将选择到能量和性能最优的物理主机。TDR-BFD算法的伪代码如Algorithm 2。算法的输入为被选择出的虚拟机列表,输出为重新分配好的虚拟机列表。
Algorithm 2: TDR Best Fit Decreasing //最好递减虚拟机分配算法
输入 Input:hostList, VmsToMigrateList //物理主机,侯选迁移虚拟机列表
输出 Output: allocation of Vms //虚拟机分配的结果
1 VmsToMigrateList.sortDecreasingUtilization() //将侯选迁移虚拟机列表中的虚拟机按照资源利用效率排序
2 for each vm in VmsToMigrateList do //针对侯选迁移虚拟机列表中的每一个虚拟机
3 minTDRDiff=MAX //变量MAX赋值给最小温度差异变量minTDRDiff
4 allocatedHost=MULL //可分配的虚拟机被赋值为空
5 fo reach host in hostlist do //针对所有的物理主机列表中的每一个物理主机
6 if host has enough resources forvm then //如果该物理主机有足够的资源容纳虚拟机
7 TDRDiff=estimateTDRDiff(host,vm) //当前温度差异变量TDRDiff被赋值给estimateTDRDiff函数的结果
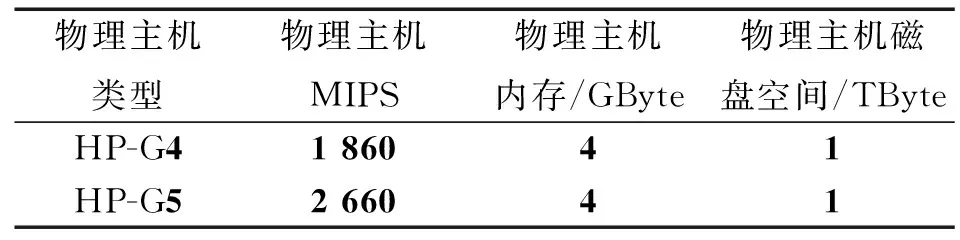
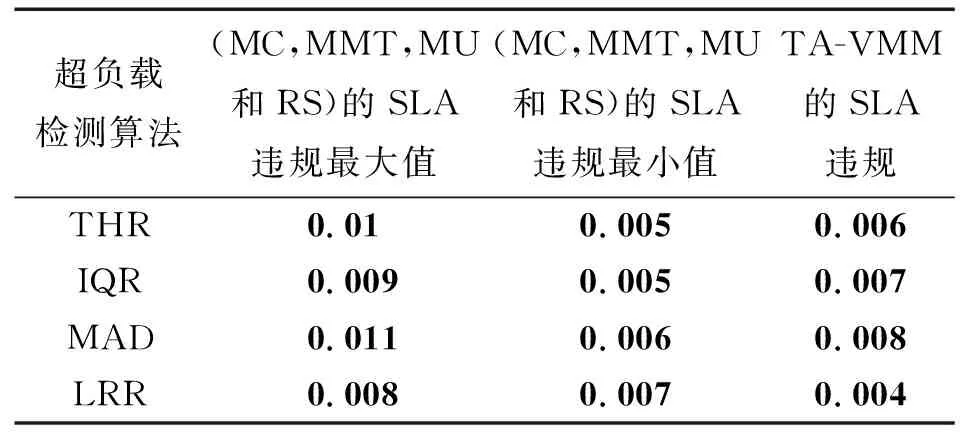
8 IfTDRDiff 9 allocateHost=host //物理主机被赋值为被选中的可分配的物理主机 10 minTDRDiff=TDRDiff //当前的最小温度距离差异值TDRDiff赋值给最小温度差异变量minTDRDiff 11 end if //结束if循环 12 end if //结束if循环 13 end for // 结束For循环 14 if allocatedHost!=NULL then //如果被选中的分配的物理主机列表不为空 15 allcation.add(vm.allocatedHost) // //将物理主机加入到被分配的物理主机列表 16 end if //结束if循环 17 end for //结束For循环 18 return allocation //返回虚拟机分配的结果 Cloudsim[19]工具是Anton Beloglazov博士的研究团队开发的一个最常见的面向云数据中心的模拟器,上面已经实现了一些虚拟机迁移策略,例如已有能量管理策略 (dynamic voltage and frequency scaling,DVFS)和无能量管理的随机策略(no power aware policy,NPA),还有另外的单一阈值(single threshold,ST)迁移策略和最小迁移次数 (minimization of migrations,MM)迁移策略。 DVFS是根据服务器处理器芯片所运行的应用程序对计算能力的不同需要,动态调节芯片的运行频率和电压。 接下来开始设置Cloudsim模拟的云数据中心环境,它包括一大批空闲的HP ProLiant ML110 G4物理服务器与G4数量相同的空闲的HP ProLiant ML110 G5物理服务器,服务器的硬件组成如表1。每个物理节点CPU核心的计算能力相当于1 860 MIPS或者2 660 MIPS。4个模型的虚拟机类型如表2,具有MIPS和内存的具体值,这样可以模拟真实的计算场景。每个虚拟机都具有100 Mbit/s的网络带宽。温度常量参考了lumped RC温度模型中的具体值,如表3。最优温度的阈值设置为343 K, 这个温度可以达到能量消耗和SLA违规之间的平衡。 表1 云数据中心中的物理节点配置Tab.1 Physical machine configuration of cloud data centers 4.2.1 SLA违规 SLA违规值表明在客户有服务请求的时候,CPU并没有分配资源的情况,因此,为了云客户端增加QoS,我们的首要目标是减少SLA违规值。 表2 虚拟机类型配置Tab.2 Configuration of virtual machine type 表3 温度常量的设置Tab.3 Setup of temperature constants 文献[17]中采用了2个方法来评价SLA违规:①单活动主机SLA违规时间(SLA violation time per active host,SLATAH); ②虚拟机迁移后的性能降低(performance degradation due to migrations,PDM)情况。 所以最终SLA违规的具体值可以表示为 SLAV=SLATAH·PDM (6) (6)式中:SLATAH是活动主机的CPU具有100%的使用效率所占的比例;PDM是整个系统因为虚拟机迁移后的性能降低情况。 4.2.2 能量消耗和SLA违规联合指标 本文这里保证能量消耗和QoS之间的平衡来评价整个云数据中心的性能,计算公式为 ESV=E·SLAV (7) (7)式中:E是云数据中心的整体能量消耗;SLAV是(6)式中所表达的SLA违规情况,ESV的值正比于能量消耗E和SLAV,所以ESV越小,云数据中心系统性能越优秀。 为了体现TA-VMM虚拟机迁移策略的性能改进,把TA-VMM和其他能量感知的虚拟机分配机制进行了比较,包括Cloudsim中4类虚拟机迁移策略(MC, MMT, MU 和RS),同时采取不同的虚拟机超负载检测算法(THR, IQR, MAD 和LRR)。为了方便描述实验结果,只保留了这些迁移策略的最大值和最小值的数据,仿真了真实情况下应用程序访问云数据中心的情况,随机选择24 h来完成工作负载的跟踪。 在仿真过程中,有800个物理主机和1 052个虚拟机。表4~表7是各类虚拟机迁移策略和本文的TA-VMM迁移策略的比较结果。 表4显示了TA-VMM迁移策略与其他迁移方法的比较,能量消耗有大约30%的减少。 表4 TA-VMM与Cloudsim中已有的迁移策略能量消耗比较(持续24 h)Tab.4 Experiment results analysis of energy consumption in TA-VMM and Cloudsim (continue 24 h) KWh 表5 TA-VMM与Cloudsim中已有的迁移策略SLA违规比较(持续24 h)Tab.5 Experiment results analysis of SLA violation in TA-VMM and Cloudsim(continue 24 h) % 表6 TA-VMM与Cloudsim中已有的迁移策略虚拟机迁移次数比较(持续24 h)Tab.6 Experiment results analysis of migration numbers in TA-VMM and Cloudsim(continue 24 h) 表5中显示了SLA违规的仿真结果,从表5中可以看出,所有的虚拟机迁移策略都可以获得小于0.01%的SLAV值。 表6中显示了不同虚拟机迁移策略的虚拟机迁移次数的比较,TA-VMM的迁移次数比其他的2个策略要少50%。 表7显示了本文TA-VMM策略的ESV参数值也小于其他策略的38%~51.2%,当对比活动主机数目的时候,本文基于TDR的温度感知机制比其他能量感知的虚拟机迁移机制也要低,具有比较高的MIPS的物理主机SLATAH比较小。分析原因是TA-VMM迁移策略在能量节省方面更容易使虚拟机到那些低能量消耗的物理主机之上。 表7 TA-VMM与Cloudsim中已有的迁移策略ESV性能比较(持续24 h)Tab.7 Experiment results analysis of ESV in TA-VMM and Cloudsim(continue 24 h) 然而TA-VMM策略的SLA违规值也有了一些轻微的提高,但是TA-VMM迁移策略能够成功地定位被选择的虚拟机到合适的物理节点,可以达到能量消耗、最佳温度及SLA违规之间的平衡。因为每个虚拟机的迁移都可以导致SLA违规,因此,应该在可能的情况下尽量减少虚拟机迁移的数量。 从表6还可以看出,TA-VMM迁移策略的迁移次数比其他策略的要少,通过虚拟机重新分配,它可以保持主机一直工作,同时接近最佳温度。物理主机的CPU整体利用效率可以一直保持在一个与最佳温度相对应的阈值范围之内。整体来说,TA-VMM迁移策略也实现了更好的虚拟机合并,与其他迁移策略比较起来,TA-VMM迁移策略最终在降低虚拟机迁移次数、减少能量消耗、降低SLA违规等方面体现了良好的性能。 本文提出绿色云计算环境下的基于温度感知的虚拟机迁移策略TA-VMM, 它主要考虑物理主机的温度情况作为选择和分配虚拟机的关键因素。采用Cloudsim云计算的模拟器建立了TA-VMM仿真环境,测试结果表明,与Cloudsim中已经有的迁移策略比较起来,TA-VMM可以很好地节省云数据中心的能量消耗,减少SLA违规值(保证云计算的服务质量QoS)和虚拟机迁移次数。TA-VMM模型给构造绿色云数据中心的企业提供了一个新的思路,温度感知和能量感知相结合的虚拟机迁移策略在一定程度上可以更好地降低能量消耗,下一步工作将考虑将云数据中心的迁移策略利用到群智网络或者移动云计算之中[28]。4 仿真与性能分析
4.1 仿真环境
4.2 性能指标


4.3 仿真结果与性能分析



5 结 论
