基于机器学习的导弹干扰试验效果评估实证研究
2020-04-14闫晓伟曲豫宾
闫晓伟,曲豫宾
(1.海军装备部装备保障大队,北京100036;2.桂林电子科技大学,广西桂林541004)
目前,海战电子对抗愈加激烈,舰船面对导弹袭击始终处于较为被动的局面。反舰导弹的干扰研究是海军舰艇海上防御中必不可少的一环。导弹具有快速突防、破坏力较强的特点,构建复杂的电磁干扰环境是应对反舰导弹威胁极为有效的手段。然而,针对反舰导弹的干扰评估却存在着诸多影响因素,难以有效量化评估。自20世纪60年代以来,信息准则、功率准则、效率准则是用于评估干扰效果的三大准则。同时,以此三大准则为基础衍生了多种应用方法[1-2]。然而这些方法都是从定性的角度对导弹干扰评估角度进行分析[3]。在复杂电磁环境下,影响导弹作战效能有如下因素:导弹干扰的时机;干扰武器与被干扰导弹末端雷达的对准角度;参与干扰设备的功率大小;采用的干扰样式;气象地理环境等客观因素;被干扰导弹的抗干扰措施等[3]。叶厚良等人从简化模型抓住重点特征评估导弹干扰评估角度出发,选择了干扰频率、干扰功率、干扰时机、电磁环境、干扰样式等影响因素,评估导弹实验干扰效果[4];白爽等人从综合分析雷达导引头与红外成像导引头的基本干扰原理出发,对导弹干扰试验效果进行评估[5];牛得清等人从红外对抗角度使用改进后的拉丁超立方采样方法获取评估数据[6];李慎波等从导弹的进入角度等技术参数出发,研究面源红外诱饵干扰效能的影响情况[7]。在以上分析导弹干扰效能的仿真实验中,基于机器学习的模型被广泛使用,多层感知机[4]、随机森林[6]等模型被用于分析仿真实验中的数据集。
然而,基于机器学习对导弹干扰数据进行分析的过程中,却存在典型的样本数量不足与类不平衡问题。试验与评估为武器装备定型的一个非常重要的环节,用于全面考核武器的各项技术指标。武器系统研制周期较长,试验费用较高,一般倾向于把试验与评估放在一起综合评定。在试验与评估过程中,由于受靶场条件、安全性和时间、经费等方面的限制,只能获取小样本的武器测试数据[8]。这些现场试验数据是用于进行武器性能评估的珍贵数据。目前,美军提出的“一体化试验鉴定”概念也是为了解决试验成本高昂等问题,通过数据共享方式来解决数量过少的问题[9]。样本数量不足的问题极大地影响了武器装备的试验评估。继而,武器试验过程中的数据在武器性能未达到指标的演化过程中,必然存在有效试验与无效试验呈现出不平衡的类分布情况。如导弹干扰试验过程中,在干扰功率未能达到有效值情况下,预计会出现导弹干扰失败次数远远大于导弹干扰成功次数的情况。因此,如果不对这些存在类不平衡的数据集进行预处理,必然影响机器学习模型的学习与建立。传统的基于机器学习的对类不平衡数据集的处理方法包括对数据集中多数类欠采样、对数据集中少数类进行过采样和基于代价敏感的分类方法等[10]。对于导弹干扰试验来说,由于本身数据量有限,对多数类欠采样的方式不适合该类试验。基于代价敏感的分类方法等在处理数据量较多的情况下具有优势,如果在真实武器试验数据量较少的情况下,最好采用对数据集进行过采样的方式。过采样的方式中,基于SMOTE等算法虽然可以根据欧式距离等来创建少数类数据集,但这些数据集如果在数据量较少的情况下,其有效性仍待商榷。因此,随机过采样算法被用于导入干扰试验原始数据预处理过程。
基于此,本文提出将随机过采样用于机器学习的分类模型训练过程中,设计了基于随机森林的2 阶段的数据分析框架。首先,采集并对导弹干扰数据进行随机过采样预处理,然后,使用随机森林建立分类模型。使用常见的AUC(Area Under Curve,AUC)指标作为分类性能的评价指标。在开源的导弹干扰试验数据集上进行多次重复试验,对试验结果进行统计分析,证明基于2 阶段的随机森林分类方法能够有效提升导弹干扰评估模型的性能。
1 基于机器学习的导弹干扰试验效果评估
1.1 基于机器学习的2阶段导弹干扰试验效果评估框架
武器装备是严格区分于普通民用产品的高科技产品,具有质量要求极高等特点。在武器装备的生命周期中,需要通过一系列的试验来检验方案是否合理,战术指标是否能够达到要求[8]。其试验流程如图1所示。

图1 导弹干扰武器装备试验流程Fig.1 Test process of missile jamming weapon equipment
在试验评估过程中,收集导弹干扰设备的原始数据。试验由于受靶场试验条件、经费等因素的制约,试验次数较少,产生的真实数据也较少。然而这些试验数据却是无可争辩的真实可靠数据,是进行武器系统定型的最终检验考核手段。如何能够深入挖掘有限的数据集,从数据集中建模,以便后续对设备定型进行辅助验证,这是武器装备评估中至关重要的问题。
以试验评估数据集为基础,提出基于机器学习的2阶段导弹干扰试验效果评估框架。该框架首先通过随机过采样对数据集进行预处理,然后,采用随机森林分类方法进行建模分析。该2阶段导弹干扰试验效果评估框架的整体流程如图2所示。
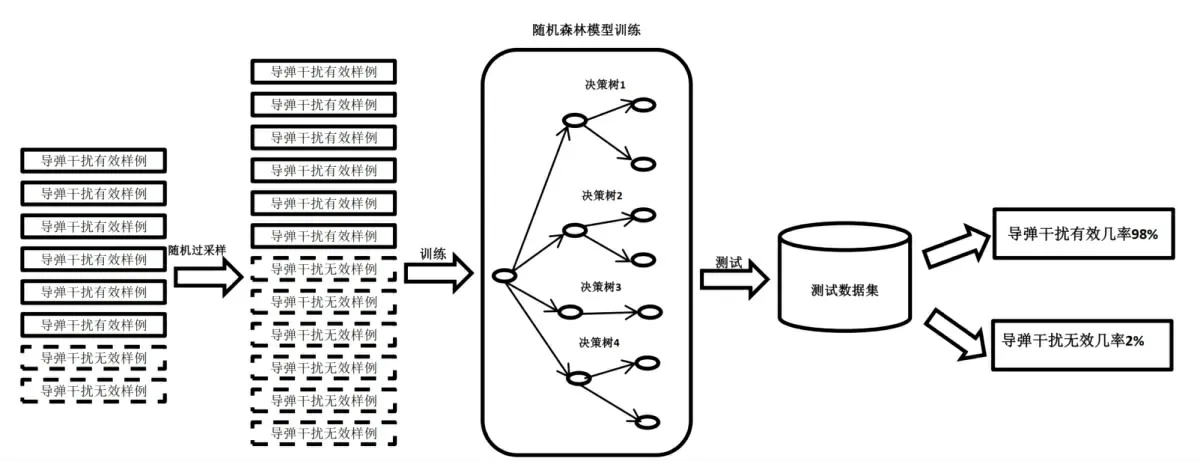
图2 2阶段导弹干扰试验效果评估框架Fig.2 Evaluation framework of two-stage missile jamming test effect
该框架分为原始数据集预处理阶段与随机森林模型训练阶段。训练完成的模型可以用于对测试数据集进行预测。
在原始数据集预处理阶段,如图2所示,导弹干扰有效样例与导弹干扰无效样例之间存在着明显的差异。导弹干扰有效样例数目明显多于导弹干扰无效样例,这个原始数据集中存在着明显的类不平衡现象。如前所述,采用随机过采样方式更加有效可靠。通过引入随机过采样策略,导弹干扰无效样例子数据集的容量达到与导弹干扰有效样例子数据集匹配的数量。将预处理完成的数据集作为第2个阶段随机森林模型的输入数据集。在随机森林模型的训练阶段,通过建立多棵决策树的方式来完成对导弹干扰评估模型的构建。最终,可以将该模型用于测试数据集,完成模型的检验。
1.2 基于小数据样本的随机过采样策略
武器装备经过试验评估阶段产生的原始数据集为小数据样本数据集,定义:

设Smax与Smin数据集间达到的平衡比值为1.0。面向导弹干扰试验评估的随机过采样策略具体步骤如下[11]:
1)随机从Smin中抽取一些少数类样本;
2)复制随机抽取的样本,记为集合Srandom;
3)将新的数据集合Srandom添加到少数类数据集Smin中,扩大数据集得到新的少数类集合Smin-new;
4)重复步骤1)~3),直到Smax与Smin数据集之间达到的平衡比值为1.0时,则终止该算法。
经过随机过采样以后,形成的输出数据集为Smax与Smin-new。这2 个数据集之间达到平衡,可以作为随机森林模型的输入数据集。
1.3 面向导弹干扰试验的随机森林模型
以输入的Smax与Smin-new数据集作为训练数据集,即可以开始训练随机森林模型。针对面向导弹干扰试验评估问题,欲得到泛化能力较强的分类器,则可以通过创建多个独立的具有弱分类效果的决策树来共同决策。定义集合D,D=Smax∪Smin-new,采用自助采样法[12],每次从集合D 中采集一个样本,将其拷贝到集合D′,以该集合D′作为训练数据集构建一棵决策树。样本在m 次采样过程中始终不被采到的概率是1 -m[13],取极限得到:

原始数据集D 中约有36.8%的样本未能出现在采样数据集D′中,不同的采样数据集D′保证了不同决策树的独立性。随机森林是集成学习的一种常用扩展变体[14]。在随机森林中,对基决策树的每个节点,从该节点的属性集合中随机选择一个包含k 个属性的子集,基于该子集选择最优的属性划分。一般推荐k 取值为log2d。假设当前样本集合D′中第n 类样本所占的比例为pn(n=1,2),分别表示导弹干扰无效与导弹干扰有效。则D′的信息熵定义为:

数据集中,离散属性有5个可能的取值,分别为干扰频率、干扰功率、干扰时机、电磁环境、干扰样式。如采用干扰频率来对样本集D′进行划分,每个分支的取值定义为{a1,a2,a3,a4} ,则会产生4 个节点。以不同节点所占的比重不同计算信息增益的公式为:

信息增益越大,意味着以该属性进行划分提升的纯度越高,则可以作为分类属性。多个不同的决策树使用投票机制对样例进行分类。
分类模型没有采用在图像识别领域比较流行的卷积神经网络等深度学习算法,这与数据集数量较少有关[15]。随机梯度算法需要大量的样例才能够对目标函数进行优化[16]。同样,也没有考虑在自然语言处理领域应用较多的循环神经网络结构[17],对词嵌入的训练也需要大量的标注数据集,而目前可用训练数据集较少[18]。
2 试验设计
本节将简要描述试验过程,包括试验数据集、性能评价指标以及试验中用以进行比较的损失函数等。所有试验基于至强E5-2670的CPU与16G内存的工作站完成。试验使用sklearn 作为实现机器学习分类方法的实验平台,各种模型参数均采用默认值。设计如下研究问题来指导试验设计:基于2 阶段的随机森林分类模型与其他基准方法是否存在评估性能差异。
2.1 评测对象
该试验采用的数据来源于根据相关先验数据建立的学习样本集[4],数据集描述见表1。
在评估导弹试验干扰效果的过程中,导弹的距离方位等基本可以确定,因而采用干扰频率、干扰功率、干扰时机、电磁环境、干扰样式5种因素作为评估的重要特征。在专家标注的过程中,针对数据集的具体处理过程如下:若通过5 个干扰因素隶属度计算出的干扰效果数值,经归一化后在[0.67,1]内,则干扰效果评估为“优”;若在[0.33,0.67)内,则干扰效果评估为“中”;若在[0,0.33)内,则干扰效果评估为“差”。原始的数据集并未提供导弹干扰是否有效的标注位,数据的加权处理过程为:将数据样本中干扰效果评估为“优”和“中”的数据样本统一标注为“导弹干扰有效”,标志位记为“1”;其他数据样本标注为“导弹干扰无效”,标志位记为“0”。通过数据集可以看出,该数据集为典型的类不平衡数据集,且样本容量较小。

表1 数据集描述Tab.1 Dataset Description
2.2 试验流程和方法参数设置
为了减少数据的随机性对试验结果的影响,整个试验重复执行多次。试验重复3 遍,每遍重复的次数分别为20 次、30 次、50 次。在试验过程中,对数据进行了分层抽样处理,保证训练数据集和测试数据集的分布一致性,当前试验过程中测试数据集的比例设定为30%。重复过采样过程中,少数类与多数类数量最终达到的比值为1.0。
2.3 评测指标
针对类不平衡数据集的常见评价指标包括召回率(recall)、F1-measure、AUC 等。在本试验中采用的AUC指标,常作为二元分类问题中分析类不平衡的数据集的分类指标。针对二元分类问题的相应的混淆矩阵如表2所示。

表2 混淆矩阵Tab.2 Confusion Matrix
在所有真实值为阴性的样本中,伪阳性率被定义为错误地判断为阳性之比率:

在所有真实值为阳性的样本中,真阳性率被定义为被正确地判断为阳性之比率:

以不同的阈值对所有样本计算相应的坐标点(TPR,FPR),得到的相应曲线下的面积值即为AUC值。AUC 值越高,表示模型分类性能越好,其取值区间为(0,1)。
2.4 基准方法
为了比较不同的分类模型对导弹试验干扰评估数据集的影响,实现了多个常见的分类模型,在同等条件下进行对比试验。试验中用到的5个分类模型如下:
1)多层感知机模型,该模型是叶厚良等在分析数据集中使用到的模型[3],未考虑类不平衡问题,在试验中作为baseline,记为mlp;
2)随机森林模型,未考虑类不平衡问题,记为rf;
3)支持向量机,未考虑类不平衡问题,记为svm;
4)朴素贝叶斯模型,未考虑类不平衡问题,记为nb;
5)基于2 阶段的随机森林模型,通过随机过采样方式解决类不平衡问题,以随机森林作为分类模型,记为rf_imb。
3 结果分析
试验中,前4 个分类模型都是针对存在类不平衡问题的数据集进行处理的,提出的2 阶段的随机森林分类模型处理的是经过随机过采样的数据集。图3展示的是重复运行次数为50次情况下,不同分类模型的AUC盒图。从图3可以看出,在中位数上,rf_imb分类器获得了最佳的分类性能,而且其中位数比基方法有近60%的提升。同时,前4个分类模型都表现出了较大的一致性,一方面是中位数值均在0.5左右,另外一方面是分类性能都出现了明显的较大波动。这个分类性能的表现充分说明类不平衡对导弹试验干扰评估数据集有明显的副作用。rf分类器和rf_imb分类器相比,rf_imb分类器考虑了类不平衡问题,而大量的中位数在0.5左右也说明rf分类器并没有表现出实用的分类性能。因此,建议在后续的试验中,不采用未做类不平衡处理的分类器。

图3 采用不同分类模型使用AUC指标对比的盒图(重复次数50次)Fig.3 Box plots of different models on the AUC indicator(repeat 50 times)
由图4 与图5 的AUC 盒图结果可以看出,在不同试验不同重复次数的情况下,在中位数上,rf_imb分类器都获得了最佳的分类性能。而且其他未进行类不平衡处理的分类器同样都表现较差,其中位数都在0.5左右,这说明这些分类器缺乏实用的可操作性。因此,可以认为rf_imb分类器具有较好的泛化性能与分类性能。

图4 采用不同分类模型使用AUC指标对比的盒图(重复次数30次)Fig.4 Box plots of different models on the AUC indicator(repeat 30 times)
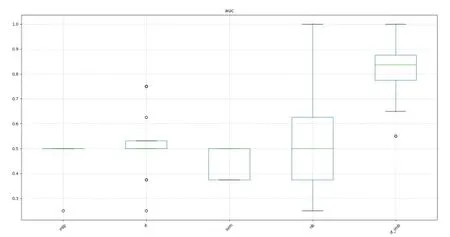
图5 采用不同分类模型使用AUC指标对比的盒图(重复次数20次)Fig.5 Box plots of different models on the AUC indicator(repeat 20 times)
4 总结与展望
随着反舰/反潜武器更新换代和性能的多样化,舰船面临着越来越大的毁伤威胁,如何在舰船设计阶段考虑舰艇武器装备针对来袭导弹的干扰效果就显得十分重要。针对复杂电磁环境下导弹干扰试验影响因素众多且难以量化、试验数据采集困难以及试验数据中普遍存在类不平衡等问题,基于机器学习创建导弹试验干扰效果评估模型,采用随机森林、支持向量机、朴素贝叶斯、多层感知机等常见模型对导弹试验干扰效果进行评估。特别针对小数据样本中的类不平衡问题提出2 阶段分类模型,采用过采样方式解决类不平衡问题并采用随机森林进行分类。基于开源的导弹干扰效果评估数据,通过实证研究说明,基于过采样的随机森林模型在干扰效果评估问题中具有较强的泛化能力和鲁棒性,在AUC 指标上,该模型比多层感知机模型在中位数上最多提高60%,建议在后续的试验中采用该模型进行导弹干扰效果评估。从试验中可以看出,类不平衡问题对分类器性能有着较大的影响,在后续的试验过程中,须处理类不平衡问题。
