无速率编码及其应用综述
2020-01-15黄靖轩费泽松
黄靖轩,费泽松,李 欢
(北京理工大学 信息与电子学院,北京 100091)
0 引言
无速率编码是近十数年间兴起的一种纠错编码方案,其概念首次由J. W. Byers 和M. Luby 等人于1998 年提出[1]。 其最基本的特点是可以对有限长的信源符号进行编码,得到无限长的编码符号;译码时,无论接收到的编码符号是什么,只要编码符号大于一定数量,即可完成译码。 这就好像用一只杯子从喷泉里接水,只要杯子满了就行,而不用在意接了哪一滴水。 因此,无速率编码也被称为喷泉码。第一种可以实际使用的无速率编码由M. Luby 于2002 年提出,按其姓名命名为卢比变换(Luby Transform,LT)码[2]。 随后,A. Shokrollahi 在LT 码的基础上提出了Raptor 码[3],通过低密度奇偶校验(Low Density Parity Check,LDPC)码与LT 码的级联,降低了译码复杂度,并降低了错误平层。 此后,众多学者针对LT 码提出了各种改进方案,改进的手段包括优化LT 码编码过程中的度分布、优化译码算法以及利用反馈信道反馈译码状态调整编码策略等。
近些年来,LT 码的一些改进思想被进一步加以研究和改进,产生了一些新型无速率码。 与Raptor码的级联思想相似,S.Yang 等人将LT 码和网络编码相级联,于2014 年提出了Batched Sparse (BATS) 码[4]。 这种编码保留了无速率码的特性,同时降低了网络编码的复杂度。 A. Shokrollahi 和Y. Cassuto则发展了利用反馈的思想,于2015 年提出了在线喷泉码(Online Fountain Codes,OFC)[5],将利用反馈信道的思想进行了延伸,其在线特性体现在接收端反馈译码状态,发送端根据反馈信息选择最优的编码策略。 OFC 进一步简化了LT 的编译码过程,利用反馈消除了错误平层,并且获得了很好的部分译码能力和实时性。
无速率编码不仅在理论上有了很多改进,更由于其自适应信道质量、编译码复杂度低以及性能优异等特点,在很多场景都有很大的应用潜力。 无速率编码最为适合的应用场景是广播通信,Raptor 码及其改进方案被广泛用于各种广播无线通信协议中。 此外,无速率码低复杂度的特点非常适用于机器类通信和汽车通信等场景。 最后,在无线传感器网络、分布式存储与计算等分布式系统中,由于其节点数量通常较多且不固定,也非常适合使用码率不固定的无速率编码。
1 LT 码与Raptor 码
LT 码是最早出现的可实用的无速率编码,也是被研究最多的一种无速率编码。 Raptor 码的出现时间和LT 码相近,其基本构造是将LT 码与LDPC 码级联,所以编译码方法和LT 码也有很多相似之处,故本节将这2 种无速率编码一起介绍。
1.1 LT 码基本原理及其改进
LT 码最早被设计用来解决二元删除信道(Binary Erasure Channel,BEC)下的数据分发问题,传统的LT 码是一种数据包级别的编码,工作在二元域上。 后文中,我们将编码之前的数据统称为信源符号,编码后的数据称为编码符号。 LT 码的性能主要受其编码时的度分布函数影响,常用的译码算法为置信传播(Belief Propagation,BP)算法。 在此,首先介绍LT 码的编译码算法,然后介绍LT 码的一些改进方案。
1.1.1 LT 码编译码原理
(1) 编码与RSD 分布
LT 码的编码过程比较简单,即每次选择数个信源符号进行模二和运算,计算的结果即为编码符号。进行运算的信源符号数量称为编码符号的度(Degree),用d 表示。 每个编码符号的度是随机产生的,其概率由度分布函数ρ(d) 确定。 假设信源符号的数量为k,那么LT 码的编码过程可详细描述如下:
① 对度分布函数ρ(d) 进行采样,得到d;
② 从k 个信源符号中随机选择d 个信源符号;
③ 将所选的d 个信源符号进行模二和,得到编码符号;
④ 重复步骤①~③,不断生成编码符号,直到接收端完成译码。
在LT 码的编码过程中,编码性能主要由度分布函数确定。 M. Luby 在最早提出LT 码时首先提出了理想孤子度分布(Ideal Soliton Distribution,ISD):
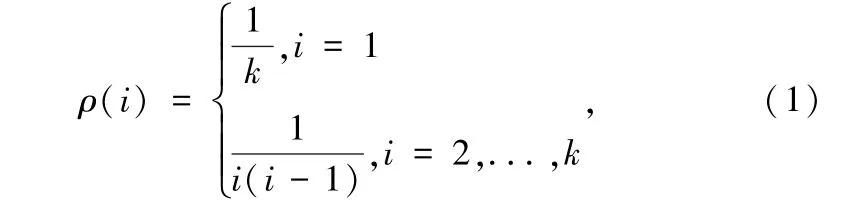
式中,ρ(i) 是度为i 的概率。
ISD 仅仅是理论上最优的度分布函数,实际使用中性能极易受到影响,因此,M. Luby 提出了实用性更强的鲁棒孤子度分布(Robust Soliton Distribution,RSD)。 首先定义τ(i) :

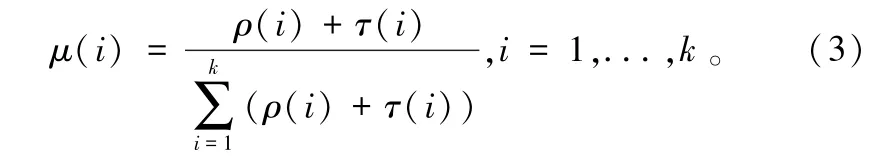
(2) Tanner 图
LT 码本质上是一种低密度生成矩阵(Low Density Generating Matrix,LDGM)码,可以用Tanner 图表示。 Tanner 图又称二分图(Bi-partite Graph),如图1 所示,圆形节点为变量节点(Variable Node),表示信源符号;矩形节点为校验节点(Check Node),表示编码符号。 校验节点和变量节点以边相连,表示该编码符号由对应的信源符号通过模二和运算得到。 以边相连的2 个节点称为相邻节点。
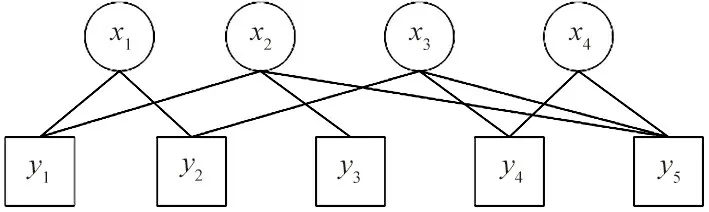
图1 LT 码的Tanner 图Fig.1 Tanner graph of LT codes
(3) BP 译码
译码算法主要有高斯消元法和BP 算法。 其中,高斯消元译码算法的性能较好,但复杂度较高;BP 算法大幅降低了复杂度,而且性能下降并不明显。 在这里,结合Tanner 图,介绍适用于BEC 下的BP 译码算法:
① 译码器查找d = 1 的编码符号,如果找到则译码过程继续进行,否则译码结束。 当译码结束时,如果信源符号未能完全恢复,则译码失败,接收端继续接收编码符号,等待下次迭代译码。
② 译码器任选一个d = 1 的编码符号,将这个编码符号的值赋给对应的信源符号,删去这个编码符号在特纳图上对应的校验节点及其与变量节点相连的边。
③ 将上述信源符号对应的变量节点与所有相邻校验节点对应的编码符号做一次模二和,其结果为相应编码符号的更新值;将所有相邻编码符号的度减1 作为度的更新值。 然后在图上删去这个变量节点和其所有边。
④ 重复上述3 个步骤,直到完成译码或译码失败。
1.1.2 LT 码改进方案
LT 码的性能受度分布函数的影响很大,一个更优化的度分布函数可以带来更好的性能;BP 译码算法以牺牲部分性能为代价降低了复杂度,相应地提升部分复杂度可以获得更好的译码性能。 因此,度分布函数优化和译码算法改进是LT 码改进方案的2 个主要方向。 接收端完成译码时,通常将一个ACK 信号反馈给发送端,通知其结束编码流程,部分方案利用该反馈信道发送更多反馈以提高性能,这是LT 码改进的另一个方向。
(1) 度分布
度分布是影响LT 码性能的关键因素。 传统的度分布设计是针对BP 译码算法进行的。 因为置信传播译码算法从d=1 的编码符号开始,这种编码符号组成的集合称为可译集(Ripple)。 好的度分布首先必须保证BP 译码过程中d = 1 的编码符号产生得足够多。 提高度值较小出现的概率可以增加可译集的大小,然而,如果度值较小出现的概率较大,则需要更多数量的编码符号才能保证全部原始信息符号参与编码。 一种好的度分布使接收端在使用置信传播译码算法时,能以更小的译码开销和更高的概率完成译码。
在ISD 中,可译集大小的期望始终为1,即每次迭代中,从一个d = 1 的编码符号开始译码,成功恢复一个信源符号,同时另一个编码符号的度更新为d = 1。 ISD 理论上可以使译码开销最小化,但是由于d = 1 的编码符号数量太少,译码过程极易失败。RSD 通过增加数值较小的度出现的概率增加了可译集的大小,同时在i = k/R 处引入了一个峰值,以提高所有信源符号都参加编码的概率,从而提高了对抗信道擦除的能力,增强了鲁棒性。
此后,许多研究者对LT 码的度分布做了进一步改进。 J.H. Sorensen[6]等人通过分析得出,可译集大小应该随着译码进程的改变而减小,而非像ISD 与RSD 中一样保持恒定,并且他们设计了相应的度分布。 仿真结果表明,这种拥有不断减小的可译集大小的度分布相比RSD 有更小的译码开销。此后,他们将相应的结论推广到了二元输入AWGN(Binary Input AWGN,BIAWGN)信道[7],并通过仿真证明了这种优化方法在BIAWGN 信道中可以在更小的信噪比下获得更低的误码率。 K. K. Yen[8]等人针对短码长可译集变化较大、可能消失的特点,采取了另一种思路设计度分布函数,即在提高可译集均值的同时降低其方差。 通过这种方法优化得到的LT 码在短码长下需要比RSD 更小的译码开销。
以上研究主要针对编码符号度分布函数,对于信源符号采用随机选择的方式进行选取。 此时,如果定义信源符号的选择次数为信源符号的度,则信源符号的度分布符合泊松分布。 在泊松分布中,d = 0 的概率总是存在的,而对于信源符号来说,d=0 意味着该符号未被选取参与编码。 如果有符号未参与编码,那么在译码时一定无法被恢复出来,因而无论度分布函数如何优化,总有小概率出现信源符号未被选取导致译码失败的情况。 对于这种情况,I.Hussain 和M. Xiao[9]等人记录每个信源符号被选择的次数,并且优先选择被选择次数最少的信源符号参与编码,通过这种方式使LT 码的错误平层得到了改善。 K. F. Hayajneh 等人同样记录每个信源符号的被选择次数以改变信源符号度分布,但是他们选择被选择次数最多的信源符号作为d = 1的编码符号,并通过分析证明这种选取方式降低了接收端的译码复杂度。 Luyao Shang 等人[10]在此基础上又进行了改进,将非均匀选取拓展到了更多编码符号中,进一步降低了接收端的译码复杂度。
(2) 译码
BP 译码算法是一种低复杂度的译码算法,这使得其译码性能有所下降。 最显著的特点是,当d = 1的编码符号消失后,BP 译码将会停止,而只要编码矩阵仍然满秩,此时依然可以用更复杂的译码算法完成译码。 高斯消元译码是一种较为复杂的译码算法,这是一种最大似然译码算法,相当于求解线性方程组。 然而,高斯消元法译码的复杂度太高,不太适合中长码译码。 各种译码方案实际上是在复杂度和性能之间进行权衡。 一种比较直观的改进方法是将BP 算法和高斯消元法结合,在BP 算法停止时使用高斯消元算法求解部分信源符号,使得可译集重新出现,BP 译码算法得以继续。
C.Cao 等人[11]考虑了LT 码作为数据包级别的编码这一特点,设计了一种新的跨层译码算法。LT 码在数据包间编码之后,通常还需要在编码符号(数据包)内进行比特级编码。 在BP 译码停止时,利用已经恢复的数据包,可将比特级译码失败的数据包重新进行最大比合并,从而增加比特级译码成功的数据包数量(即减小信道擦除概率),以期待BP 译码能够继续。 此外,也有学者改进了AWGN信道下的无速率码译码算法。 L.He 等人[12]设计了一种拥有更快收敛速度的贪婪算法。 V. Bioglio[13]简化了高斯译码算法的复杂度,并减小了译码时延。
(3) 反馈
在LT 码编码过程中,接收端通过反馈告知发送端停止发送。 既然反馈信道已经建立,就可以更多地利用反馈信道,反馈更多的译码状态信息,根据译码状态信息调整编码方式。
A.Beimel 等人[14]提出了实时(Real Time,RT)码,这种编码不再根据度分布随机产生编码符号的度值,而是按从小到大的顺序确定编码符号的度值,即先产生d = 1 的编码符号,再产生d = 2 的编码符号,直到d = k。 接收端统计译码情况,计算针对该恢复比例的最优度值,然后通过反馈告知发送端如何改变编码符号的度值。 对于RT 码,接收端收到编码符号后,立刻就能完成译码,而那些不能立刻译码的编码符号会被丢弃,不参与后续译码。 与传统LT 码的“全或无”译码性能不同,通过这种改进,RT码获得了较好的实时性,即恢复出的信源符号数量随着接收到的编码符号数量呈近似线性上升。 但是,RT 码需要更多的译码开销。
A.Hagedorn 等人[15]基于LT 码提出了另一种利用反馈的无速率码方案,称为Shifted LT(SLT)码。 在此方案中,反馈用来告知已经完成恢复的信源符号数量,发送端根据这数量调整LT 码的度分布,即将编码符号度的最小值提高。 通过这种方式,SLT 码不具备RT 码那么好的实时性,但是其译码开销远小于RT,且好于传统LT 码。
D.Jia 等人同样基于LT 码提出了另一种反馈无速率码方案。 这种方案主要基于译码算法进行反馈。 具体的,当BP 译码因为可译集消失而停止时,接收端根据译码情况,通过反馈向发送端请求一个信源符号作为d=1 的编码符号,从而译码过程可以继续。 类似的,在LT-AF(LT Codes with Alternating Feedback)[16]方案中,ISD 中d = 1 的部分被取消了,接收通过反馈选择一个最需要的信源符号作为d = 1 的编码符号,而发送端通过发送这个d = 1 的编码符号作为对接收端反馈的确认信号。 通过这种方式,LT-AF 进一步减小了译码开销。
M.Hashemi 等人[17]提出了一种新的反馈方案,利用反馈信息调整信源符号的选取方式。 这种方案依然基于LT 码的RSD 度分布,不同的是,发送端利用反馈信息可以估计每个信源符号的恢复情况。 在产生新的编码符号时,发送端选择d-1 个被估计为已恢复的信源符号和1 个被估计为未恢复的信源符号进行编码。 通过这种方式,编码的实时性得到了显著提高,而译码开销随着反馈次数的增加而减小。
1.2 Raptor 码基本原理及其改进
Raptor 码是LT 码的直接改进,因其优异的性能被广泛用于各种商用无线通信协议中,尤其是广播通信协议。 本节简要介绍Raptor 码及其主要后续改进方案。
1.2.1 Raptor 码基本原理
如前所述,LT 码对信源符号的随机选取不能保证所有信源符号都参与译码,因此不论使用何种译码方式,接收端都无法将他们恢复出来。 LT 码通过提高信源符号的平均被选择次数(即泊松分布的均值)来解决这个问题,但一方面,这导致了大部分信源符号被恢复出来之后,还需要一定数量的编码符号才能完成全恢复;另一方面,更高的平均被选择次数意味着更多次的异或运算,从而导致编译码复杂度较高,为O(klog2(k)) 。
为了解决这个问题,A. Shokrollahi 使用了一个高码率的LDPC 码对信源符号进行预编码,预编码的输出称为中间符号,然后使用LT 码对中间符号进行编码,得到编码符号。 在译码时,首先对LT 码进行译码,这时会有少部分中间符号因为未被选择参与LT 码编码,从而未能被恢复;但是,再对恢复出的中间符号进行LDPC 码译码,即便丢失少量中间符号,还是有大概率可以恢复出所有的信源符号。
由于存在一个高码率的预编码,LT 码可以接受少部分中间符号不能恢复,也就无需提高中间符号的平均被选择次数,所以在减少译码开销的同时,译码复杂度降低到了O(k·log2(1/ε)) ,其中ε >0 是一个表示译码开销的常量。
1.2.2 Raptor 码改进方案
(1) 系统化
编码符号包括信源符号的编码方式称为系统码。如果用x1,…,xk表示信源符号,用y1,y2,…表示编码符号,那么系统码满足xi= yi,i = 1,…,k。 将系统码中非信源符号的部分称为修复符号。 系统码在很多应用场景,特别是广播场景中尤为重要。 广播场景中可能存在大量异构接收机,有些配有译码器,有些没有译码器。 如果编码方式不是系统码,那么对这些不配有译码器的接收机来说,就需要额外发送未编码的信息,从而降低系统吞吐量[18]。
系统化Raptor 码的直接方案是先发送信源符号本身,然后发送Raptor 码编码符号作为修复符号[19]。 这种方案的问题是,其性能受到信源符号和修复符号的混合方式影响。 如果信源符号所占比重较大,则性能较好,反之较差。 这与无速率编码“接收到足够数量的编码符号即可完成译码,而不关心接收到了哪些编码符号”的基本思想是相悖的。
另一种方案[19]的主要思想是,假设信源符号本身是某些输入符号通过Raptor 编码得到的输出符号,那么可以首先对信源符号进行译码得到输入符号,再对输入符号进行编码,得到的输出作为修复符号。 在译码时,首先对接收到的编码符号进行译码得到输入符号,再对输入符号重新编码得到信源符号。 这种方案的好处是,信源符号和修复符号是通过同一种Raptor 编码规则得到的,因此信源符号和修复符号的混合方式不影响编码性能。
(2) 失活译码
失活(Inactivation)译码算法[20]是一种结合BP译码和高斯消元译码的译码方式,结合了BP 译码低复杂度和高斯消元译码高可靠度的特点。 其译码分为3 个阶段:第一阶段为试译码,译码器首先寻找可以用BP 译码解出的中间符号,而非实际解出他们;每当BP 译码因可译集消失而停止,那么选择一个中间符号假设其已经被恢复,称之为被失活(Inactivated),BP 译码器可以将其当做可译集而继续下去。 第二阶段为高斯译码阶段,即使用高斯消元算法将被失活的中间符号恢复出来。 第三阶段为BP 译码阶段,在被失活的中间符号恢复之后,BP 译码不会再因可译集消失而停止,可以顺利完成译码。
值得注意的是,虽然这种译码方式首先被设计用来提升Raptor 码的译码性能,并被广泛应用在RaptorQ[21]码中,但是这种译码方式本质上是对Raptor 码中LT 码的部分进行译码,因此也可以直接用来提升LT 码的译码性能[22]。
2 在线喷泉码(OFC)
OFC 是一种新型无速率编码,其特点是接收端可以将实时译码状态反馈给发送端,发送端根据反馈得到的译码状态寻找对应的最优编码策略。 OFC本质上是利用反馈的LT 码,如RT 码和SLT 码的延续,但是整个译码过程更加可监可控,是一种全新的无速率编码。 OFC 是一种具有实时性的编码,同时相较其他具有实时性的编码,其译码开销更小。 本节介绍OFC 的编译码方法和研究现状。
2.1 OFC 中的一部图与编译码方法
OFC 同样是一种面向BEC 的二元域无速率编码,其编码的编译码方法和LT 码基本类似。 编码时,同样随机选择d 个信源符号通过模二和产生编码符号;译码时,同样将编码符号与已恢复的信源符号模二和,得到未恢复的信源符号。 不同的是,OFC的译码算法进行了进一步简化,只接收以下2 种情况的编码符号:
① 编码符号由m-1 个接收端已知的信源符号和1 个接收端未知的信源符号模二和得到;
② 编码符号由m-2 个接收端已知的信源符号和2 个接收端未知的信源符号模二和得到。
其他情况的编码符号将会被直接丢弃,不做处理。
译码器的接收规则决定了只存在最多2 个未知符号进行模二和的情况,因此,OFC 的译码状态可以通过一种简化的译码图来表示,称为一部图(Uni-partite Graph)。 与特纳图不同,一部图中只存在信源节点,不存在校验节点。 如果节点为黑色,表示其在接收端已知;如果为白色,表示其在接收端未知。 节点之间如果以边相连,表示对应的信源符号之间进行过模二和。 所有连接在一起的白色节点组成一个集团(Component),集团中的节点数量称为集团的大小(Size)。 一个不与任何其他节点相连的白色节点本身也是一个大小为1 的集团。 显然,如果集团中的一个节点被接收端恢复出来,与之相连的白色节点就可以通过模二和得到,以此类推,整个集团都可以完成译码。 此时,将该集团中的所有边删去,其中的所有节点变为黑色。

图2 Tanner 图(左)和一部图(右)的对比Fig.2 Uni-partite graph (right) and the corresponding Tanner Graph (left)
传统OFC(Conventional Online Fountain Code,COFC)[23]的编码过程可以分为建立阶段(Build-up Phase)和完成阶段(Completion Phase)。 假设信源符号数量为k,在线喷泉码的编码过程可以详细描述如下:
① 建立阶段:发送端随机选取2 个信源符号进行模二和,产生一个d = 2 的编码符号,直到接收端中最大集团的大小为kβ0,其中0 <β0<1 为一个给定参数。 而后,接收端产生反馈给发送端,发送端改为发送一个随机选取的信源符号作为d = 1 的编码包,直到发送端中最大的集团被恢复出来。
② 完成阶段:发送端通过反馈信息获取接收端已恢复的编码符号占全部编码符号的比例β,根据下式计算当前最优的编码符号度值,并随机选择m^ 个信源符号进行模二和,得到一个d =的编码符号:
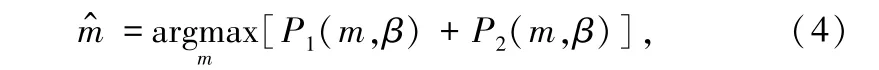
式中,P1(m,β) 是当前恢复比例下度为m 的编码符号符合情况①的概率,P2(m,β) 是度为m 的编码符号符合情况②的概率,可分别用下式表示:
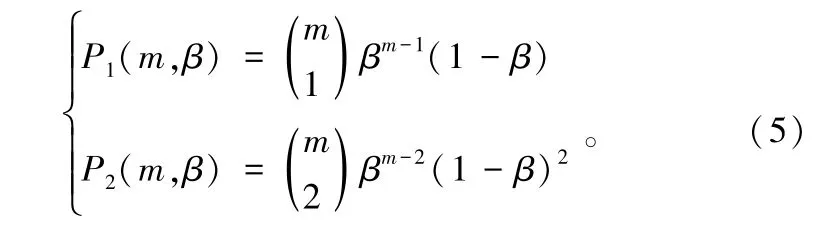
接收端接收符合规则的编码符号并进行处理和统计恢复比例β,在β 值引起m^ 改变时给出反馈通知发送端。
在编码过程中,建立阶段d=2 的编码符号可以在接收端的译码图中增加边,使译码图中建立起数个集团。 根据随机图理论[24],这些集团会逐渐相连,形成一个较大的集团,而其他集团的大小将几乎保持不变。 在完成阶段,虽然所发送的编码符号度值大于2,但是能被接收和处理的编码符号在与所有已恢复的对应信源符号模二和之后,依然是一个信源符号,或2 个未恢复的信源符号异或的结果。如果处理之后,该编码符号包含一个信源符号,那么该符号可以使一个集团恢复出来。 如果是2 个信源符号的异或,那么该符号可以使2 个集团相连变成一个集团。 总之,被接收处理的编码符号可以使译码图中的集团数量减1。
通过接收端的反馈,具有较好的实时性,并且OFC 比RT 码、LT 码以及同样具有实时性的Growth码[25]需要更少的译码开销。 同时,由于对接收的编码符号做了限制,OFC 的接收端可以有更低的复杂度。 此外,在文献[5]中,作者利用随机图理论给出了OFC 所需译码开销的上界。
2.2 在线喷泉研究现状
OFC 的提出时间不长,但是依然获得了学者的关注,出现了较多的改进方案。
因为OFC 的编码器同样是随机选取信源符号,所以同样有LT 码中信源符号未参加编码的问题。T.Huang[26]等人着眼于信源符号的选取规则进行改进,并分析了改进方案的译码开销。 与文献[12]类似,改进方案中被选取次数最少的信源符号将在产生下一个编码符号时优先被选取。 通过这种方式,OFC 的译码开销得到进一步减小,但实时性受到了一定的损失。
Y.Zhao 等人[27]针对OFC 译码器较为简单、丢弃大量编码符号这一问题进行了改进,将译码器可以接收并处理的编码符号增加了一种情况,即编码符号由m - 3 个接收端已知的信源符号和3 个接收端未知的信源符号模二和得到。 此外,最优编码符号度的计算方式也做了相应的改变。 通过增加译码复杂度,减小了OFC 的译码开销。 同时注意到由于COFC 中先发送d = 2 的编码包,导致建立阶段结束之前都不会有信源符号被恢复出来,使得译码的实时性很受影响,该方案还通过先发送度为1 的编码符号提高了译码过程的实时性。
在文献[28]中,一个新的理论分析框架被构建起来。 该框架可以较为准确地分析接收到的编码符号个数与恢复出的信源符号个数之间的关系,精确度较文献[5]有很大提高。 分析过程指出,建立阶段中的编码符号有更大概率被接收,因此改进方案通过类似系统化的方法提高了建立阶段中d = 2 的编码符号属于情况①和情况②的比例,减小了完成阶段需要的编码符号数量。 其实时性比COFC 稍差,但好于文献[26]。 其译码开销和反馈数量小于COFC,但稍差于文献[26]。 最后,通过仿真发现,β0的取值最大不应超过0.5。
3 BATS 码
BATS 码是一种新型无速率编码。 与Raptor 码类似,BATS 码也是使用LT 码与其他编码级联的方式提高编码性能。 与Raptor 码不同的是,Raptor 码利用LDPC 码进行预编码,对LDPC 码的输出再进行LT 编码,提高了LT 码的全恢复能力,而BATS 码使用LT 码进行预编码,对LT 码的输出进行随机网络编码(Random Linear Network Coding,RLNC),在保留无速率特性的同时,降低了RLNC 的编译码复杂度。 本节介绍BATS 码的编译码原理和研究现状。
3.1 BATS 码编译码原理
BATS 码的输入称为输入分组,每个分组含有T 个输入符号。 假设有K 个输入分组,则输入分组构成的矩阵表示为S=[S1,S2,…,SK] 。 编码时,首先进行LT 码编码,通过度分布产生度值,然后随机选择输入分组。 与LT 码不同的是,这些输入分组之间不是进行简单的模二和,而是使用一个随机矩阵作为生成矩阵进行编码,得到输出码块。 最后,在LT 码输出码块的内部进行RLNC 编码。 编码流程可详细表述如下:
① 根据度分布函数确定度值di;
② 从S 中随机选取di个输入分组生成矩阵Si;
③ 对S 中的输入分组进行编码,生成第i 个块Ci,即Ci= Sigi,gi是di× M 维的随机矩阵,在接收端已知;
④ 在Ci内部进行RLNC 编码, yi= CiHi=SigiHi,其中Hi是行数为M 的传输矩阵,在接收端已知。
在译码时,同样可以使用高斯消元译码算法和BP 译码算法进行译码。 注意到gi和Hi在接收端已知,如果rank(giHi)=di,那么Si可以被恢复出来,后续译码过程和传统LT 的BP 译码算法或高斯消元译码算法相同。
对于RLNC,编码器的存储开销为K 个数据分组,编码复杂度为O(TK) ;如果译码器采用高斯消元法,恢复出一个输入分组的平均复杂度为O(K2+TK) 。 如果K 很大,那么RLNC 编译码复杂度相当高。 使用LT 码进行预编码之后,RLNC 编译码需要处理的数据仅为某个编码块内部的M 个分组,和K无关,因此降低了编译码复杂度。
3.2 BATS 码研究现状
BATS 码最早于2014 年由S.Yang 等人提出,此后得到了广大学者的广泛关注。 S. Yang 等人在2016 年又提出了BATS 码的树分析方法[29]。 X.Xu等人[30]研究了BATS 码度分布与信道条件不匹配时的性能损失问题,提出了一种普适度分布,并提出了准普适BATS(Quasi-universal BATS,QU-BATS)码,可以更好地适应信道状态变化或未知的情况。H.Zhao[31]和S.Yang[32]等人随后研究了BATS 码在有限码长下的性能分析问题。
4 无速率编码的应用
无速率码最初的设计目标是应用在广播和数据分发场景中,最广泛的应用也是在广播场景中。 除了广播之外,无速率编码因为其编译码复杂度低、码率可灵活调整等特点,在深空通信、水中通信、认知无线电网络、汽车通信、无线传感器网络、存储和计算等应用中都有较大的应用潜力。 本节介绍无速率编码在广播系统中的应用,以及将无速率编码应用在汽车通信、无线传感器网络、存储和分布式计算场景中的研究。
4.1 广播通信与不等差保护
在广播场景中,LT 码的无速率特性只要求所有接收端在完成译码后反馈一个ACK 信号,没有完成译码的接收机可以继续接收更多的编码符号,数量足够时总能完成译码;发送端在所有接收机反馈ACK 信号后停止广播。 通过这种方式,LT 码避免了在广播系统中使用ARQ/HARQ 可能存在的复杂反馈。
Raptor 码及其改进方案作为性能更好的无速率编码,被广泛应用在各种广播通信的商用标准中,如蜂窝移动通信中的多媒体广播与多播(Multimedia Broadcast Multicast Service,MBMS)[33]以及数字视频广播(Digital Video Broadcasting,DVB)系列标准中的手持设备标准DVB-H[34]。 Y.Suh 等人[35]研究了一种特殊场景下的广播方案。 此场景关注第2 次广播的情况,即接收端通过第1 次广播已经收到了一定数量的编码符号,但是限于信道条件等因素不能完全恢复出全部的信源符号。 文中将这种接收端称为中间状态用户(Intermediate-State Users)。 中间状态用户可以在第2 次广播前通过反馈,将其状态信息告知发送端。 该文针对这种情况设计了2 种度分布,获得了比传统LT 码更好的恢复性能。 S. S.Borkotoky 等人[36]研究了无速率编码在多跳无线网络数据分发中的应用。
在广播场景,特别是多媒体广播中,通常不同的信源符号有不同的优先级。 如H.264 格式中,信源符号分为基本层和增强层,信道条件较差的用户可以先恢复出基本层,播放分辨率较低的视频,而信道条件较好的用户可以同时恢复出基本层和增强层,播放分辨率较高的视频。 这就需要纠错编码对信源符号进行不等差保护(Unequal Error Protection,UEP)。
对于LT 码,最经典的UEP 方法有权重选择法[37]和扩展窗法[38]。 权重选择法将不同优先级的信源符号赋予不同权重,在选择信源符号进行模二和产生编码符号时,权重越高的信源符号更有可能被选择。 扩展窗法将信源符号划分为存在嵌套的窗。 以信源符号分为高优先级和低优先级2 层为例,扩展窗法将产生2 个窗:小窗对应高优先级信源,大窗对应全部信源。 产生编码符号时,首先确定在哪个窗内进行选择,然后再从该窗内随机选择信源符号进行编码。 此时,即使选择2 个窗的概率相同,高优先级的信源符号也有更高的概率被选择参与编码。 S. Ahmad 等人[39]提出了一种基于信源符号扩展的不等差保护方法,高优先级的信源符号将被扩展更高的倍数,以提高其被选择的概率。 此外,扩展窗法和权重选择法也被应用于OFC[40-41]和BATS 码[42]进行UEP。
4.2 汽车通信
汽车通信场景一方面对时延要求较高,而使用ARQ/HARQ 等传统纠错模式会使通信时延增加,而无速率码可以部分代替ARQ/HARQ 机制,从而降低时延。 另一方面,汽车通信中的高移动性会使信道状态不断变化,获取准确的信道状态信息较为困难,而无速率码可以自适应不同的信道状态,从而更好地应对信道状态不断变化的情况。 因此,无速率编码在汽车通信场景中有较好的应用潜力。
在文献[43]中,LT 码被应用在车载自组织网络(Vehicular Ad-hoc NETworks,VANETs)中,以应对VANETs 中网络拓扑结构变化较大、失联情况时有发生的问题。 在文献[44]中,作者用大量的仿真证实了在汽车通信场景中使用Raptor 码比使用IEEE 802.11p 标准中的ARQ 机制性能更加优异,可以大幅提升系统吞吐量,减少译码时延。 Y. Gao等人[45]将BATS 码应用在汽车通信中的数据分发中,并提出了一个新的系统模型。 在该模型中,首先由路边单元(Roadside Unit,RSU)通过无速率编码将数据分发给车辆,随后车辆内部进行汽车间通信,通过网络编码的方式完成数据分发,从而降低传输时延。
4.3 无线传感器网络
在无线传感器网络中,多个分布式数据源通过一个或多个中继将数据发送给接收端。 由于每个数据源的码长较短,如果在每个数据源内部进行单独编码,无速率码的随机性会导致编码性能较差。 为解决这个问题,S. Puducheri 等人提出了分布式LT(Distributed LT,DLT)码[46]。 DLT 通过将RSD 去卷积的方式使LT 码分解,每个分布式信源通过DLT码编码后,编码符号在中继处再通过模二和组合起来,最终产生的编码符号和对所有信源符号统一使用RSD 分布编码得到的编码符号相同,从而使编码性能获得提升。 在分布式信源数量较少的情况下,编码符号的最大度值受到节点数量的限制,从而使性能受到影响。 I. Hussain 等人[47]利用缓存存储部分之前接收到的符号参与当前编码,从而部分减轻了这种限制,并且在文献[48]中分析并改善DLT 码的错误平层。
此外,L.Sun 等人[49]利用无速率编码实现了无线传感器网络中的安全协作传输。 H.U.Yildiz 在水下无线传感器网络中利用无速率编码代替传统ARQ 机制,从而减少了能量消耗,提高了传感器的使用寿命,并且文章通过大量的仿真比较了单纯使用无速率编码方案和使用无速率编码-ARQ 混合方案的性能。 B.Yi 等人[50]将OFC 应用在了无线传感器网络中进行数据收集。
4.4 存储
由于其复杂度低、可以任意调整冗余数量的特点,无速率码在存储系统中也有较大的应用潜力。C.Anglano 等人[51]考虑了LT 码在云存储系统中的应用,发现基于LT 码的云存储系统在可靠性、安全性等方面相比传统云存储系统都存在较大优势。H.Lu 等人[52]研究了在基于LT 码的存储系统中如何优化检索方式以降低时延。 T.Okpotse 等人[53]研究了将系统LT 码应用在分布式存储系统中的情况,并提出了一个截断泊松分布作为LT 码编码符号的度分布,从而使用较低的译码开销保证了低复杂度译码。
4.5 分布式计算
分布式计算系统中通常使用MapReduce 结构[54],这种结构分为3 个阶段:映射(Map)、数据交换(Data Shuffling)和缩减(Reduce)。 在映射阶段,分布式结算节点处理计算任务,并根据其映射函数产生中间值。 在数据交换阶段,不同计算节点之间交换中间值。 最后,在缩减阶段,通过缩减函数对中间值进行计算得到最终输出结果。 分布式计算中的编码策略可以分为2 种:① 最小时延编码(Minimum latency codes),通常使用纠错编码,通过引入冗余的计算节点,使得计算网络对部分节点丢失不敏感,只要一定数量的节点完成了计算任务,就可以得到最终计算结果,从而增强了网络的可靠性,降低了时延;② 最小带宽编码(Minimum bandwidth codes),通常使用网络编码,通过在每个节点引入冗余计算量,减小每个节点在数据交换阶段需要进行通信的数据量。
BATS 码本身就是LT 码(纠错码的一种)和网络编码的级联,因此非常适合分布式计算系统。J.Yue 等人将BATS 码应用在分布式计算系统中,并用于工业控制[55],同时减小了冗余计算量、通信数据量和计算时延。 A.Severinson 等人将使用失活译码器的LT 码应用在分布式计算系统中[56],以增加通信数据量为代价减小了计算时延,在计算时延存在限制的场景中获得了良好的性能。
5 结束语
本文介绍了无速率编码的编码方案和发展过程,梳理了无速率编码的发展脉络,并介绍了无速率编码在不同场景中的应用。 无速率编码是一类编译码复杂度低、码率灵活且性能优异的纠错编码。 从LT 码被提出后,广大学者从级联、度分布优化、译码改进以及利用反馈4 个方面对其进行改进,并从级联改进中衍生出Raptor 码和BATS 码,从反馈改进中衍生出OFC。 无速率编码被广泛应用于广播通信等经典场景,并在车联网、存储系统、分布式计算网络等新兴应用场景中有较大的应用潜力。 随着BATS 码和OFC 两种新型无速率编码的发展,无速率编码将会在更广泛的场景中发挥更大的作用。
