一种基于DBN-LR集成学习的异常检测模型
2020-01-14韩家茂阮宏玮
连 超,李 华,2,刘 亚,韩家茂,阮宏玮
1(内蒙古大学 计算机学院,呼和浩特 010021)2(内蒙古大学 图书与信息技术部,呼和浩特 010021)
1 引 言
在日渐成熟的虚拟化等互联网技术的推动下,云数据中心已经成为个人应用或企业级服务将数据处理过程从个人计算机或服务器迁移的必然选择,越来越多的业务系统部署在云上,以实现资源的动态可扩展和综合运维.由于云环境下复杂的资源共享模式和云用户迥然不同的业务形态,云数据中心往往面临随时可能发生的异常所导致的服务不稳定、不安全等问题.为了保证云服务以及部署在云平台上的业务应用的可靠性,服务提供商对于各层面资源往往采取有力的监控,实时获取大量关键性能指标(Key Performance Indicator,KPI)数据.通过对高维时序KPI进行有效综合分析,发现异常,从而达到故障规避,及时止损的目的.
Fabian Huch在文献[1]中将“对正常运行产生或可能产生负面影响的系统的任何非预期状态”定义为异常.而异常检测就是要识别出运维数据中偏离大部分数据或者与数据集中其他大部分数据不服从相同统计分布的小部分异常数据.云环境下,KPI异常检测旨在通过算法分析时序采集数据间的关联性规则,从而自动发现KPI时间序列数据中的异常波动,为后续根因定位、故障预测等提供决策分析.
在实际运维场景中,异常点数据非常稀少,正负样本极度不平衡,少数异常类别样本的直接检测会导致模型将所有样本识别为正常样本,达不到异常检测的目的;由于云环境下的数据监控层面广、监控时间长,导致监控数据实例数量庞大而且种类繁多,这就给数据处理带来了维度灾难问题.现有的一些算法在处理高维空间数据时,计算成本消耗过大,结果却不尽如人意.因此,采用特征提取进行降维是处理高维数据的主要手段.关于建模方法,考虑到真实运维场景下的时效性问题,采用支持流式数据处理模式和复杂度较小的轻量级建模方法才能实现实时在线异常检测;同时,模型应能够适用于处理规模较大的运维数据集;所建立的异常检测模型框架还需具有普适性,能够应用到类似的异常检测场景下.
针对现有的大多数单方面指标的异常检测方法不能全方位实时监测数据异常的弊端,本文提出了一种云环境下业务系统KPI异常检测模型,该模型使用匿名企业软件系统真实运维数据集(覆盖应用系统各个层面KPI)进行模型训练,以适用真实运维环境.
本文的其余部分组织如下:第二节介绍相关工作;第三节介绍了本文提出的异常检测模型的架构;第四节描述了相关算法的原理;第五节介绍了实验以及对模型的评估;第六节总结了本文,并介绍了今后的工作.
2 相关工作
目前异常检测领域已有一些研究成果,同时深度置信网络(Deep Belief Network,DBN)也已经用于异常检测领域,既可以类似于一个自编码机用于无监督学习,进行高维数据的特征提取;也可以用于监督学习,作为分类器使用[2].文献[3]提出一种基于DBN和线性单分类支持向量机(One-Class Support Vector Machine,OCSVM)相结合的高维数据异常检测模型,底层的DBN由两个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)堆叠而成,在OCSVM中,使用无监督算法基于超球面的支持向量描述法进行异常检测.文献[4-6]同样利用支持向量机(Support Vector Machine,SVM)做异常检测分类器,SVM在对少数类样本数据进行异常检测时,效果很好,但是由于其算法的复杂性,不适合处理数量庞大的运维数据.文献[7]提出了一种基于合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)和DBN相结合的入侵检测方法,选择的分类器是softmax,以适应多分类问题.但DBN结构参数是人工随机设定,所以该网络结构不一定是最优,同时SMOTE算法也不适用于解决大规模数据集的样本均衡问题.文献[8]提出了 DBN-KELM 入侵检测算法,采用核极限学习机进行分类的最大特点就是学习速率快、泛化性能好,但是最优核函数的选择比较困难.文献[9]提出了一个OpenStack拓扑异常检测框架,其中包括三个功能组件:图形生成器、统计监视器和异常检测器,图形生成器创建进程之间的关系图,统计监视器收集统计数据并计算与典型统计行为的差异程度,异常检测器接收图表和差异程度,并识别异常进程.文献[10]提出了一种使用DBN和概率神经网络(Probabilistic neural network,PNN)的入侵检测方法,用PNN做分类器,学习速度快,且不易陷入局部最优.文献[11]同样使用softmax作为DBN的分类器,用于在线实时入侵检测,但其所用数据集样本数量较少,不能体现真实运维数据数量庞大的特点.
上述文献提到的异常检测模型,多数没有同时考虑实际情况下正负样本不平衡、数据维度高以及数据量庞大的问题,不能满足处理真实运维数据的要求.因此,本文提出了基于DBN-LR集成学习的异常检测模型,该模型有效解决了云环境下真实运维数据的KPI异常检测问题.
3 异常检测模型
针对实际运维数据的特点,本文提出的异常检测模型主要考虑三方面内容:
1)用以解决正负样本不平衡的数据预处理算法:考虑到运维数据集规模较大、邻近时间窗口内数据点具有相似性的概率很大以及正常样本数量远高于异常样本数量的特点,可以认定在正常样本中存在大量无用重复特征.因此,正常样本欠采样的方法更适合进行样本平衡.又因为异常类样本一旦出现必定是连续时间段内都为异常,所以类似于文献[12]提出的距离少数类样本平均距离最近的多数类样本采样方法不再适用;而数据清洗技术[13,14]无法控制欠采样的数量,某种程度上都是使用K-邻近法,由于大部分正常类样本附近也都是正常类,因而剔除的正常类样本有限.EasyEnsemble[15]思想是将多数类样本随机划分成N个子集,每个子集的数量等于少数类样本的数量,然后将每个子集与少数类样本结合起来分别训练一个模型,从而放大少数类样本数量,以达到欠采样的目的,最后再将N个模型集成.虽然每个子集的样本少于总体样本,但集成后总信息量并不减少,故本文选用此方法解决KPI数据集中正负样本不平衡的问题.
2)用于特征提取的数据降维算法:高维数据分析中面临的首要难题是“维度灾难”的问题[16].随着数据维度的增高,数据的分布会变的越来越稀疏、数据的组织效果急速下降,从而所需的样本数会呈指数级增长.经典的数据降维算法主成分分析(primary component analysis,PCA)[17,18]和线性判别分析(Linear Discriminant Analysis,LDA)[19]等均属于线性降维算法,不能抽象数据维度间的非线性关系.而DBN通过训练网络结构中的神经元间的权重使得整个神经网络依据最大概率生成训练数据,形成高层抽象特征,从而提升模型的分类性能.DBN最大的特点就是利用其自身非线性的结构进行特征提取,将数据从高维空间映射至低维,这种非线性降维方法可以在最大程度上保留原始数据的特征,并且相比于其他深度算法,学习用时较少;其次,由于深度网络是分层训练的,故可以按照需求选择分类器进行单独训练.因此本文选择DBN进行特征提取.
3)用于异常检测的分类算法:由于可用数据样本数量庞大,所以在分类器的选择上,相对于分类性能,本文更关注于分类速度和易用性.基于伯努利分布建模的逻辑回归(Logistic Regression,LR)分类算法速度较快,简单易用,并且容易吸收新数据更新模型,而当逻辑回归单独处理高维度数据时,又很难获得问题的全局最优解[20],因此本文选择LR作为DBN的输出层对样本数据进行分类.
综上,本文提出的基于DBN-LR集成学习的异常检测模型如图1所示.首先通过采样的方式根据数据比例将正常数据划分多份,分别与异常数据结合训练多个弱分类器,然后运用多数投票集成方法将多个弱分类器集成为一个强分类器.训练步骤如下:
1)样本均衡化.归一化以后的数据通过EasyEnsemble基于无放回随机采样的方式从正常类样本中生成N个子集分别与异常类样本结合进行多个子模型训练.
2)训练DBN进行特征提取.通过多个RBM堆叠形成DBN网络,进行数据的特征提取.采样后得到的新数据逐层通过RBM,分别经一步对比散度RBM学习完成预训练,获得RBM网络预训练参数,再由输出层的分类器模型反向传播误差对模型参数进行微调,训练获取高维数据的较优低维表示.
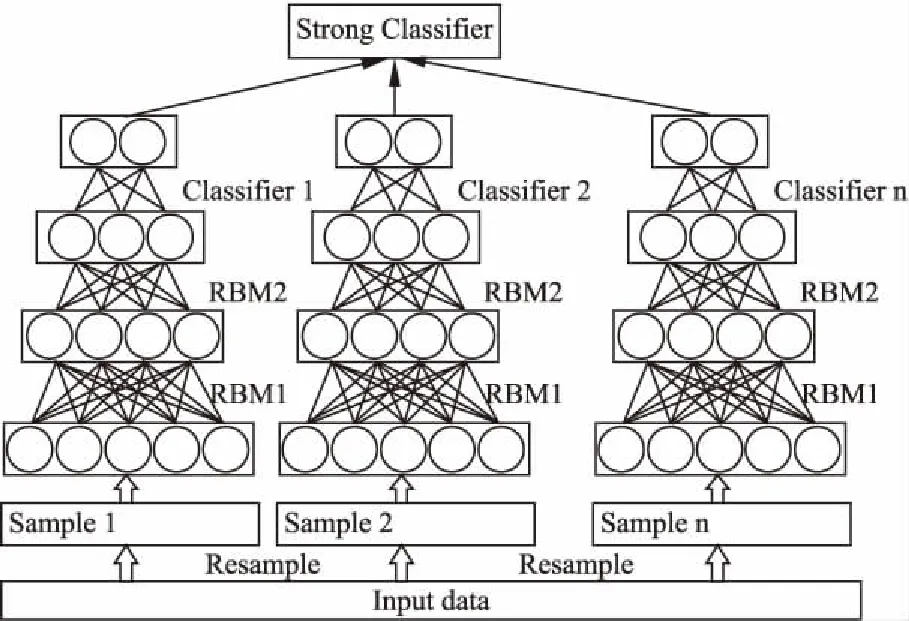
图1 基于DBN-LR集成学习的异常检测模型Fig.1 Anomaly detection model based on DBN-LR integrated learning
3)通过逻辑回归进行二分类.将逻辑回归LR作为DBN的输出层,通过多个RBM得到的低维数据,已经能较好的表示原始数据,再由逻辑回归算法进行样本分类识别异常.
4)多数投票集成弱分类器.经各个数据子集训练得到的弱分类器对测试集预测的结果作为最终的类标,进行多数投票表决,判断样本是否异常.
4 相关算法
本文主要是根据EasyEnsemble思想集成多个深度置信网络和Logistic回归相结合的模型进行运维数据的异常检测.本章简介建模相关算法.
4.1 EasyEnsemble
EasyEnsemble思想是从数据集多数类中进行随机采样生成多个多数类子集,分别与少数类结合训练分类器,生成的多个弱分类器最终结合成一个强分类器,这种方法用到了集成学习的思想.可以将每个弱分类器看成是基于不同训练子集中得到的特征的线性分类器,集成的分类器看成是不同特征的组合.
4.2 深度置信网络
DBN是由多层RBM堆叠而成.RBM通过无监督训练优化特征提取能力,根据能量模型中能量最低原理求得一个最接近训练样本分布的联合概率分布,构建出具有多隐层的非线性网络结构,进而对变量之间的依赖关系进行编码,更抽象地提取训练集特征.
RBM[21,22],本质上是一种自编码网络,是一种基于能量的模型,在能量最小化时网络模型达到理想状态.其网络结构由一层用于数据输入输出的可视层v∈{0,1}m和一层用于数据内在表达的隐藏层h∈{0,1}n构成的层内无连接、层级间全连接的结构,如图2所示.
RBM学习的目标是让RBM网络表示的Gibbs分布最大程度的拟合输入样本,即求出合适的参数θ={W,a,b}来拟合给定的样本数据,其中,W为可视层神经元到隐藏层神经元的权值连接矩阵,向量a和b分别为可视层和隐藏层神经元的乘性偏置.根据相对熵原理,参数是通过最大化RBM在训练集上的对数似然函数学习中得到的.相对熵的计算公式如下:
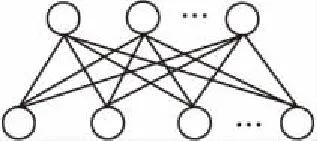
图2 RBM网络结构Fig.2 Network structure of RBM
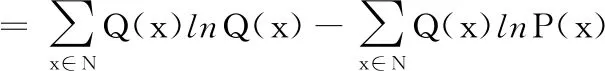
(1)
其中,N表示样本空间,Q代表输入样本的分布,P是RBM网络表示的Gibbs分布的边缘分布.式中第一项则是输入样本的熵,第二项可用:
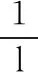
(2)
来估算,其中,l表示训练样本个数,最后要使KL最小,即需要最大化对数似然函数∑x∈NlnP(x).
在最大化对数似然函数的过程中,涉及归一化因子的计算,需要遍历可视层单元和隐藏层单元所有可能的组合状态,因此很难获取,只能通过采样的方法求得一个近似值.Hinton在文献[23]中提出一种基于对比散度(contrastive divergence,CD)的RBM学习方法,用训练样本去初始化可视层,通常进行一次采样就能达到很好的拟合效果.基于一步对比散度的的RBM学习流程如图3所示.
将若干个RBM串连起来则组成了一个DBN,其中,上一个RBM的隐层作为下一个RBM的显层,上一个RBM的输出作为下一个RBM的输入.DBN和传统神经网络的训练过程一致,首先充分训练每一层RBM作为预训练权值,然后输出层将误差反向传播对网络各层进行参数微调.
4.3 逻辑回归
逻辑回归常用于处理二分类问题,其实就是将分类问题数学化.它假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数得出分类概率,通过阈值过滤来达到将数据二分类的目的.面对一个二分类问题,逻辑回归的过程是先建立代价函数,然后通过优化方法迭代求解出最优的模型参数,最后验证所求解模型的优劣.
逻辑回归算法基于Sigmoid函数,函数形式为:
(3)
根据Sigmoid函数构造预测函数为:
(4)
其中x为样本输入,hθ(x)为模型输出,即为某一分类的概率大小,而向量θ为分类模型要求的模型参数.由于最终任务是要实现二分类,这里假设分类任务为1和0两类,那么结果为类别1和类别0的概率分别为:
1https://www.kaggle.com/anomalydetectionml/features
P(y=1|x,θ)=hθ(x)
(5)
P(y=0|x,θ)=1-hθ(x)
(6)
将式(5)和式(6)合并为一个式子:
P(y|x,θ)=hθ(x)y(1-hθ(x))1-y
(7)
其中,y的取值只能是0或者1.
不同于线性回归使用模型误差的的平方和定义损失函数,逻辑回归不是连续的,只能通过对数似然函数取反进一步得到损失函数.似然函数的代数表达式为:
(8)
其中,m为样本的个数.
似然函数对数化取反的表达式,即损失函数如下:
(9)
然后对损失函数极小化,即利用梯度下降法对式(9)求解获得使误差函数最小的θ,θ的更新公式为:
(10)
其中,α为梯度下降的学习率.

图3 基于一步对比散度的RBM学习流程图Fig.3 RBM learning flow chart based on one-step contrast divergence
5 实验及分析
本文实验环境是Windows 10 (64位)操作系统,硬件配置为Intel(R)Core(TM)i7-8700 CPU @3.20GHz,16G RBM以及237G固态硬盘,开发语言python3.5,开发框架Tensorflow 1.10.0.
本次实验采用的数据集是某匿名企业真实运维数据1,样本数量达到750万条以上,且正负样本比例极度不平衡,如图4所示,异常样本占比不到整个数据集的2%.该数据集中每一项数据共有231维数据特征和1维数据标签,特征属性包括CPU负载、内存和线程池的利用率以及到不同数据源的连接时间等.数据中的异常既包括对系统正常运行产生致命影响的资源瓶颈,也包括挂起负载在后台对资源的持续消耗等.本次实验按照原数据集比例,随机采样100万条数据进行模型验证.

图4 样本分布比例图Fig.4 Graph of Sample distribution ratio
由于可用数据数量庞大,本次实验按照7∶3的比例进行训练集和测试集的划分,并且测试集保留了原始数据样本比例特点.
实验前先对KPI样本数据集进行归一化处理,使用min-max标准化方法,对原始数据的每一个特征属性作线性变换,将结果映射到[0,1]之间.公式如下:
(11)
其中x为原始数据属性值,min为对应列特征的最小值,max为对应列特征的最大值,x*是归一化以后的数据属性值.
5.1 实验参数设置
在对弱分类器的训练过程中,DBN网络的训练参数以及微调迭代次数都会影响异常检测的结果.本文经过多次重复试验,在平衡耗费时间和分类效果的前提下,设置DBN的参数如表1所示.同时固定参数,验证微调迭代次数对检测结果的影响,损失函数和准确率随迭代次数增加的变化曲线如图5所示.
表1 实验参数
Table 1 Experimental parameters

实验参数参数值实验参数参数值输入层节点数231预训练迭代次数5第一层隐藏层神经元个数170预训练学习率0.001第二层隐藏层神经元个数50微调学习率0.01输出层节点数10
由图5可知,在第9次迭代后损失函数和准确率曲线趋于平稳,因此在所有子模型的训练过程中微调迭代次数都设置为10.

图5 loss-acc曲线图Fig.5 Graph of loss-acc
5.2 弱分类器训练
根据EasyEsemble思想,本实验采用无放回采样方法对训练集中正常样本进行采样.根据正负样本比例,将正常样本分为50个样本子集,分别和异常样本集合并成一个子训练集,并且每个子训练集中的正常样本数量和异常样本数量相等.把每个训练子集输入DBN-LR网络进行学习.实验结果见表2.
表2 弱分类器分类效果
Table 2 Classification effect of weak classifier
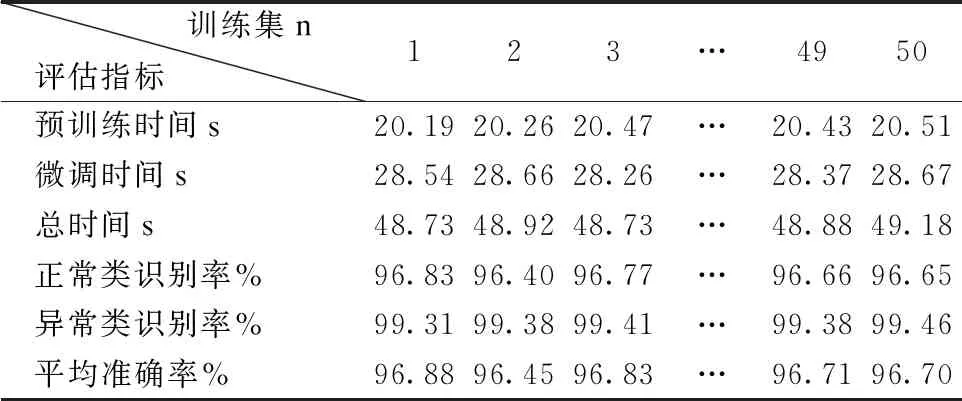
训练集n评估指标 123…4950预训练时间s20.1920.2620.47…20.4320.51微调时间s28.5428.6628.26…28.3728.67总时间s48.7348.9248.73…48.8849.18正常类识别率%96.8396.4096.77…96.6696.65异常类识别率%99.3199.3899.41…99.3899.46平均准确率%96.8896.4596.83…96.7196.70
由表2可知每个弱分类器对异常样本的识别率都在99%以上,而对正常类的识别率和平均准确率都略低.在对弱分类器预测的结果和原测试集标签进行比对中发现,每个弱分类器都存在将正常样本预测为异常的情况.
5.3 集成模型
由表2可知每个子模型对样本预测准确的概率都在96%~97%之间,相差不大,故采用多数投票算法(Majority Vote Algorithm)即少数服从多数的方法进行投票表决来判断一个样本是否为异常.分别由每个子模型预测出测试集对应的标签,然后统计每一条测试集数据的预测结果.对每一条数据预测为1的次数大于等于阈值n/2(其中n的范围就是弱分类器的个数,由数据比例决定),则该条数据的最终预测结果为1,否则为0.结果表明,利用多数投票表决方法集成多个子模型以后,在保证模型异常识别率的基础上,平均准确率相比单个弱分类器提高了一百分点以上,达到了98.35%,提高了整体泛化性.
为了验证集成模型的有效性,本文采用受试者工作特征曲线(Receiver operating characteristic curve,简称ROC曲线)和AUC(Area Under Curve)值对集成以后的强分类器进行性能评估.AUC值即ROC曲线与横轴和纵轴围成的面积,AUC值越接近1,表明当前的分类算法越有可能分类正确,模型的稳健性越好.真正例率(True Positive Rate,TPR)和假正利率(False Positive Rate,FPR)两个指标分别为ROC曲线的横纵坐标.计算公式分别如下:
TPR=TP/(TP+FN)
(12)
FPR=FP/(FP+TN)
(13)
其中,TP(True Positive)为真正例;FP(False Positive)为假正例;TN(True Negative)为真负例;FN(False Negative)为假负例.
集成模型ROC曲线如图6所示.
由图6可知,集成模型的AUC值为0.9825,由此证明该模型的异常识别效果较好,且稳健性较强.
5.4 对比实验
1)对比实验1
本文集成多个DBN-LR弱分类器的目的是为了在样本极度不平衡且维度较高的运维数据中检测出异常,由于支持向量机(SVM)算法对少数类样本数据的异常检测效果好,且应用广泛,所以本实验使用SVM算法,在相同数据集上进行对比实验,结果如表3所示.

图6 集成模型ROC曲线图Fig.6 ROC graph of integrated model

表3 与SVM对比实验结果Table 3 Comparison of experimental result with SVM
由表3可知,两种方法在预测平均准确率方面,SVM方法要略高于本文方法,但是在异常识别率方面,SVM方法远远低于本文方法,在分类器模型的训练时间上,本文提出的异常检测方法中,多个弱分类器模型的训练总时间少于2500秒,而SVM的训练时间在32000秒以上,因此在时效性方面,本文提出的异常检测模型表现更好.综合来看,本文方法更适合用于异常检测.
2)对比实验2
本文DBN模型由三个RBM堆叠而成,未必是最优结构,所以本次实验在相同子数据集下,对比了不同DBN结构对弱分类器结果的影响,表4记录了同一个子数据集在不同结构的DBN模型下,训练得到的弱分类器的异常识别率、平均准确率以及训练耗时.
表4 不同DBN结构对比实验结果
Table 4 Comparison of experimental results of different DBN structures

RBM个数异常识别率平均准确率训练耗时s399.38%96.71%48.88499.17%97.01%71.55599.08%97.37%78.326098.07%89.76
由表4可知,当RBM的个数为3~5时,弱分类器的异常识别率略微有所下降,而平均准确率略微有所提升,但是从耗时来看,4~5个RBM的结构下,耗时远高于3个RBM结构所用的时间.所以,在3~5之间选择RBM的个数构造DBN模型,结果不会产生太大浮动,而从时效性方面考虑,3个RBM结构还是可选的.当RBM的个数为6时,弱分类器准确率达到98.07%,但是异常识别率为0表明模型已经不识别异常,这也证明了当DBN隐藏层数和神经元个数达到一定峰值后,再增加并不会带来识别性能的提升[24-26].
3)对比实验3
由于本文提出的模型用到了集成学习的思想,目前比较常用的集成算法有Adaboost集成算法、Bagging集成算法,所以本次实验在相同数据集上对比了Adaboost集成逻辑回归以及Bagging集成逻辑回归和本文模型进行了对比,结果如表5所示.
表5 集成学习对比实验结果
Table 5 Integrated learning comparison experiment results
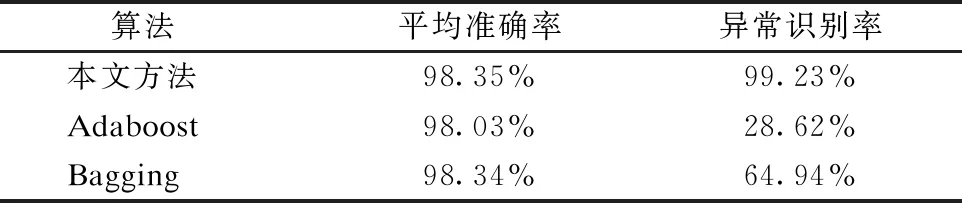
算法 平均准确率异常识别率本文方法98.35%99.23%Adaboost98.03%28.62%Bagging98.34%64.94%
由表5可知,在平均准确率方面,Adaboost方法和Bagging方法都和本文方法相差不大,但是在异常识别率方面,Adaboost方法和Bagging方法都远远低于本文方法,所以综合来看,本文方法更适合于异常检测.
6 结论与展望
本文提出了一种基于DBN-LR集成学习的异常检测方法,有效解决了企业运维数据的KPI异常检测问题,通过EasyEsemble集成学习的思想,对正负样本不平衡数据进行样本均衡化,解决了分类器倾向于将少数类异常样本识别为正常数据的问题,同时将LR作为DBN网络的输出层,既达到了高效特征提取的目的,又实现了快速准确的异常识别,而且在处理百万级运维数据时,耗时较少.
本文在进行数据处理时,没有考虑数据的时序性关系,所以下一步工作将对运维数据进行时序异常检测.
