有向无环图拓扑的DBN多口音分类方法
2020-01-14肖萌萌徐志京
肖萌萌,徐志京
(上海海事大学 信息工程学院,上海 201306)
1 引 言
近几年来,随着对语音识别研究的日渐深入,相关技术有了明显的提高,但是识别带有口音的语音还是一个难点.带有口音的语言交流给人人、人机沟通造成了极大的麻烦,因此识别和分类带有口音的说话人的语音有着重要的理论价值和现实意义[1].然而在2010年以前口音识别和分类的研究都相对缓慢,口音分类是语音识别算法的主要障碍.
口音分类的关键点之一是进行特征值提取,特征参数要能够反映语音信息.在之前人们对线性预测倒谱系数(Linear Predictive Cepstrum Coefficients,简称LPCC)[2]、线性预测系数(Linear Predictive Coefficients,简称LPC)[3]以及梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,简称MFCC)[4]等进行了深入的研究.MFCC由于更接近人耳的听觉特性以及具有较强的抗噪性等优势被广泛使用.但是标准的MFCC仅仅可以体现出语音参数的静态特性,前人的实验证明把动、静态特征结合起来才能获得更好的识别率.
人工智能近几年迅速发展,经典机器学习算法作为分类器的使用率越来越高.Watanaprakornkul采用MFCC和感知线性预测方法提取特征,使用支持向量机(Support Vector Machine,简称SVM)[5]和高斯混合模型对粤语、印地语和俄语三种外国口音进行了分类.使用SVM和高斯混合模型的准确率分别为41.18%和37.5%.对菲律宾IV-A地区的口音进行分类的文章中[6]作者自行收集该地区不同省份不同城镇的当地居民的语音数据,提取了最小线性预测系数、平均线性预测系数以及MFCC等多种特征,采用多层感知器(Multi-Layer Perception,简称MLP)作为分类器的分类效果为56.12%.在一篇以MFCC为特征,使用深度置信网络作为分类器的文章中[7]作者自己创建了一个包含6个国家口音的数据库,准确率为71.90%.Muhammad Rizwan和David V.Anderson使用基于一对一支持向量机[8]以及极端学习机(Extreme Learning Machine,简称ELM)的加权口音分类算法对TIMIT数据集的口音进行分类,准确率分别为60.58%和77.88%[9].
将MFCC的动静态特征结合作为语音特征意味着特征的维数升高,这必将导致计算复杂度增加.一对一网络结构当分类类别较多时需要较长的测试时间,而有向无环图(Directed Acyclic Graph,简称DAG)[10]的测试时间远远少于一对一.2006年Hinton在受限玻尔兹曼机(Restricted Boltzmann Machine,简称RBM)[11]的基础上提出深度置信网络(Deep Belief Network,简称DBN)[12].该模型通过反向传播网络调整网络参数,最终可以求得全局最优解.本文利用主成分分析(Principal Component Analysis,简称PCA)[13]对MFCC的动静态组合特征进行降维,使用降维后的特征作为特征参数,运用DAG拓扑DBN进行口音分类以达到更好的分类效果.
2 系统模型
使用TIMIT数据集进行多口音分类,标准的MFCC只反映了语音信号的静态特性,MFCC动静态组合特征又导致维数增加.一对多和一对一多分类方法在测试时间和分类精度方面表现的差强人意.为了解决以上问题,建立了基于有向无环图拓扑的DBN多口音分类模型,即使用PCA对MFCC动静态组合特征进行降维,将降维后的特征作为语音特征输入基于有向无环图拓扑结构的深度置信网络(Directed Acyclic Graph Deep Belief Network,简称DAG-DBN)进行训练和测试,通过分类精度和分类速度两个指标对方法进行评价.模型如图1所示.

图1 多口音分类系统模型Fig.1 Multi-accent classification system model
3 特征提取
梅尔频率的提出是根据人类耳朵的听觉特性,根据其与Hz频率的关系得到MFCC,其在说话人识别和语音识别方面得到了广泛的应用.标准的MFCC仅仅可以体现语音信号的静态特性,但是前人的实验表明,在语音特征中加入语音参数的动态特性,将静、动态特征结合起来才能获得更好的识别率.语音信号的动态特性可以通过对MFCC进行差分得到,所以组合MFCC及其一阶、二阶差分作为特征参数.

图2 基于 PCA降维的动静态组合特征提取流程图Fig.2 Dynamic and static feature extraction flow chart based on PCA dimension reduction
动静态组合特征意味着特征向量的维数增加,首先不可避免的造成计算量增加,导致计算复杂度增加.其次维数增加意味着需要大量的计算时间,导致时间复杂度增加.维数增加也意味着需要更大的储存空间来存放这些特征,导致空间复杂度增加.并且MFCC的一阶和二阶差分含有大量的冗余信息会导致分类准确率降低.PCA是一种线性降维方法.通过线性投影,将原本的样本特征空间映射到新空间中,新空间的维数低于原空间.去除不重要的冗余的特征,同时使映射后的数据的方差尽可能大,保留原本高维样本的重要信息,以此来达到降维和去除冗余的目的.使用PCA进行降维以提高分类的准确率.
特征提取的流程如图2所示.
具体步骤如下:
1)预加重.将语音信号通过一个高通滤波器:
H(z)=1-μz-1
(1)
式中0.9≤μ≤1,通常取0.97.
2)分帧加窗.将语音信号处理为包含N个采样点,时间为20~30ms的帧,乘以汉明窗,使帧的左右两端更为连续.
3)快速傅里叶变换:
(2)
4)三角带通滤波器.将上一步得到的频谱与M个滤波器相乘,然后计算输出的对数能量:
(3)
5)离散余弦变换.将对数能量通过下式进行离散余弦变换获取低频信息,最终得到L(12-16)阶的MFCC参数.
(4)
6)求一阶MFCC以及二阶MFCC.对MFCC进行一阶差分,公式如下:
(5)
二阶差分公式如下:
(6)
k为常数,可取1或2.
7)组合MFCC以及一阶、二阶MFCC得到动静态组合特征.去除一阶MFCC、二阶MFCC首尾两帧将MFCC和一阶、二阶MFCC结合得到36维特征参数.
8)PCA降维.首先计算样本的协方差矩阵
(7)

(8)
来确定降维之后的维数即主成分个数.这里的λ表示的是方差,因为特征值对应主成分的方差,当累积贡献率达到80%以上就足够代表所有主成分的信息.确定主成分个数q以后从所有的特征值中选取最大的q个特征值.PCA转换矩阵W=(w1,w2,…,wq)就是由这q个特征值对应的特征向量组成的,W为d×q维.最后求得降维后的样本特征为Y=X·W.
4 有向无环图-深度置信网络
神经网络在解决多类分类问题时,采用一对多的方法,即将原本的分类问题转化为一类对所有类别中剩下的其他类别的二分类问题.在进行训练的时候每一次所有的样本都需要参与,因此需要大量的训练时间.其次,每个分类器需要定义一个类别与所有类别中剩下的其他类别之间的分类面,增加了分类面的复杂度.当分类类别数目较大时,每一类的训练样本的数量和其他类别的训练样本总和的数量相差较大,造成训练样本不均衡,由此大大降低分类精度.
一对一分类方法也是一种多分类方法,但是当有K个分类类别时,其无论是训练还是测试,都需要遍历K(K-1)/2个分类器,使得分类时间大大增加,降低了分类效率.
针对以上问题本文提出有向无环图-深度置信网络,即使用深度置信网络作为二分类器,通过有向无环图完成多分类.
4.1 深度置信网络
DBN是由多个RBM和一层反向传播网络(Back Propagation,简称BP)[14]组成的神经网络.RBM由两层神经元组成,上面一层的神经元组成隐藏层,下面一层的神经元组成可见层.隐藏层和可见层神经元之间全连接,可见层神经元之间以及隐藏层神经元之间都没有连接.DBN的结构图如图3所示.

图3 深度置信网络结构图Fig.3 Deep confidence network structure diagram
4.1.1 基于RBM的无监督预训练
无监督的对每一层神经网络自下而上进行训练.先对第一个RBM进行训练:使用对比散度算法[15]对权值进行初始化工作.随机初始化权重向量和偏置向量,计算隐藏层神经元被开启的概率,根据概率分布进行一步吉布斯抽样.然后计算概率密度,再进行吉布斯抽样来重构显层.最后用重构后的显元计算隐藏层神经元被开启的概率.更新得到新的权重和偏置.将第一个RBM的隐藏层作为第二个RBM的输入层,用同样的方法训练第二个RBM,以此类推.逐步更新得到最终的权重和偏置向量.训练RBM就是为了得到一个分布,使之可以最大概率的得到训练样本.权值决定了这个分布,所以基于RBM的无监督预训练就是为了得到最优权值.
4.1.2 有监督的反向调参
DBN最后一层设置BP网络,首先进行前向传播,使用第一步预训练好的权重和偏置来确定相应隐元是否开启.然后求取所有隐藏层中隐元的激励值.使用下式进行标准化:
(9)
这个式子为sigmoid函数.
最后计算出输出层的激励值和输出.
h(l)=W(l)·h(l-1)+b(l)
(10)
(11)
然后进行后向传播调整网络的参数:
可以使用最小均方误差准则算法和梯度下降法两种方法来更新网络的参数,前者的代价函数如下:
(12)
使用梯度下降法则根据下式更新网络参数:
(13)
其中,λ为学习效率.
4.2 有向无环图结构
当有K个分类类别时,所有分类类别两两组合,构成K(K-1)/2个二分类器,训练阶段训练K(K-1)/2个分类器.测试阶段将K(K-1)/2个二分类器组合成一个有向无环图.包括K(K-1)/2个节点和K个叶节点.最上面一层的是根节点,只有一个,最下面的K个节点是叶节点,代表K个类别.除了叶节点以外,其余所有的节点都表示一个二分类器.第i层含有i个节点,其中第j层的第i个节点和第j+1层的第i个和第i+1个节点相连接.分类时从根节点开始,排除最不可能的一类后进入下一层对应的节点,经过K-1次判断后到达某叶节点,该叶节点对应的类别即为样本的类别.
4.3 DAG-DBN分类方法
DAG-DBN的基本思想是使用有向无环图的决策方法将K个类别的多分类问题转换为K(K-1)/2个二分类问题,使用DBN作为二分类器.DAG-DBN结构图如图4所示.
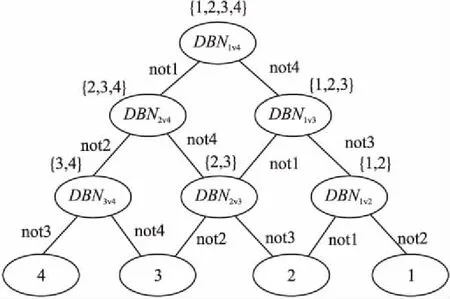
图4 有向无环图深度置信网络结构图Fig.4 Directed acyclic graph depth confidence network structure diagram
有向无环图是针对“一对一”方法提出来的.一对一—深度置信网络(One-Versus-One Deep Belief Network,简称OVO-DBN)当有K个分类类别时,所有分类类别两两组合,构成K(K-1)/2个DBN二分类器,无论是训练阶段还是测试阶段都需要运用K(K-1)/2个分类器,需要较长的测试时间.当二分类器的两个类别之间的差异较小时容易出现错误的判断导致分类出现错误.DAG-DBN训练阶段同OVO-DBN,但是测试的时候只需要K-1个二分类器就可以得到分类结果,测试速度高于OVO-DBN;另外,采用排除法排除掉最不可能的类别来进行分类,分类精度较一般的二叉树方法高.
通过RBM的原理可以知道经过深度RBM的多层提取以后导致RBM丢失了很多特征,所以通过RBM进行训练得到的数据只是基本上收敛到全局最优解的附近,此时在DBN的最后一层设置BP网络.BP网络的缺点是得到的最优解是局部极小值,因为其初始化权值是随机选取的,也因此需要消耗大量的时间进行训练,但是DBN网络将RBM网络训练的权值传给BP网络作为其初始化权值,克服了BP网络的缺点.BP网络在全局最优解的范围内通过反向传播进行微调以找寻全局最优解,因此RBM和BP结合的DBN作为二分类器能够很好的提高分类精度.
5 实验结果与分析
5.1 数据集
实验使用TIMIT数据集[16],是由麻省理工学院(MIT)、德州仪器(TI)和斯坦福研究院(SRI)合作构建的语音库,多年来成为研究语音的标准数据库.TIMIT数据集的语音采样频率为16kHz.包括New England(d1)、Northern(d2)、North Midland(d3)、South Midland(d4)、Southern(d5)、New York City(d6)、Western(d7)以及Army Brat美国8个主要方言地区的口音.从这些地区选取630名说话人每人说出10个句子组成训练集和测试集的6300个句子.本文实验只使用前7个方言地区的数据库,因为Army Brat区域的说话人在童年的时候经常搬家.数据集明确给出了训练样本(大概70%)以及测试样本(大概30%),测试数据包括168个人说的1344个句子.
5.2 不同特征参数的比较
提取MFCC,计算MFCC+ΔMFCC+ΔΔMFCC,分别采用MFCC、MFCC+ΔMFCC+ΔΔMFCC以及使用PCA对MFCC+ΔMFCC+ΔΔMFCC降维以后的特征作为特征参数,利用本文提出的分类方法进行分类实验.实验结果如表1所示.
表1 不同特征的分类准确率
Table 1 Classification accuracy of different features

特征提取方式分类准确率(%) MFCC83.33% MFCC+ΔMFCC+ΔΔMFCC84.34% PCA降维87.46%
由表1可以看出使用PCA对MFCC+ΔMFCC+ΔΔMFCC进行降维以后,分类准确率得到了提高.因为MFCC的一阶、二阶差分反映了MFCC的动态特性,将MFCC和其一阶、二阶差分结合,同时反映了静态和动态特性,然后使用PCA去掉动态组合特征中的冗余信息,同时尽可能多的保留了原数据信息,由此可以得到较高的分类准确率.
5.3 每种口音的分类精度
采用本文提出的有向无环图—深度信念网络作为分类器测试各个地区的口音分类准确率,图5显示了分类准确率.New York City(d6)地区的分类准确率远低于其他地区,因为来自New York City口音地区的说话人与来自New England口音地区和Northern口音地区的说话人混合.
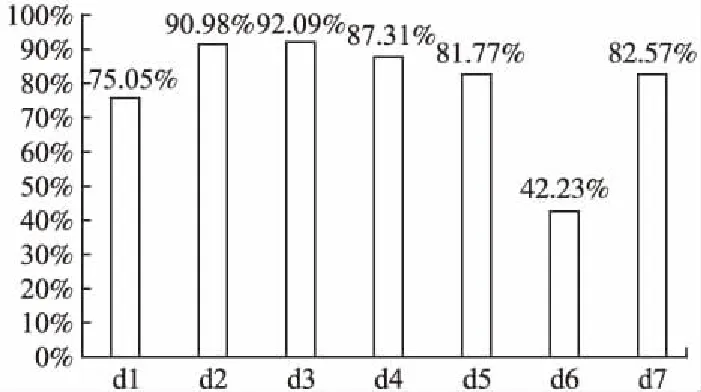
图5 每个方言地区的分类准确率Fig.5 Classification accuracy of each dialect area
5.4 不同方法的比较
口音分类是一个具有挑战性的问题,并且和我们的生活息息相关.无论是哪种品牌的智能设备,在用户使用的时候都会出现无法识别带口音的语音的问题.本文采用一对一—深度信念网络作为分类器进行了对比实验,不同的研究人员在TIMIT数据集上也尝试了不同的方法:对区分元音最多的TIMIT数据集的研究中,准确率为42.52%.Muhammad Rizwan和David V.Anderson使用基于SVM和ELM的加权口音分类算法对TIMIT数据集的口音进行分类,准确率分别为60.58%和77.88%.表2总结了不同方法的分类准确率.
表2 不同方法的分类准确率
Table 2 Classification accuracy of different methods

数据集 方法准确率TIMITProsodic analysis42.52%TIMITSVM60.58%TIMITELM77.88%TIMITOVO-DBN81.90%TIMITDAG-DBN87.46%
5.5 不同方法的训练和测试时间比较
有向无环图-深度置信网络和一对一-深度置信网络在训练阶段类似,K个类别需要训练K(K-1)/2个分类器,因此训练时间相同.但是测试阶段一对一-深度置信网络同训练阶段仍需遍历个K(K-1)/2分类器,然后采取投票的方式得到
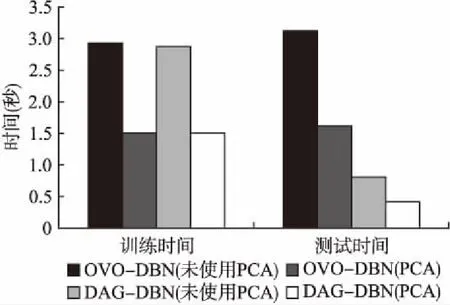
图6 不同方法训练和测试时间比较Fig.6 Comparison of different methods of training and testing time
结果,因此测试时候要多于训练时间.而有向无环图-深度置信网络将所有的分类器构成一个有向无环图,只需要使用K-1个分类器即可得到结果,因此测试时间远少于训练时间.使用PCA对特征参数进行降维,维数的减少降低了时间复杂度.图6显示了时间的差别.
6 结束语
本文提出一种基于有向无环图拓扑结构的深度置信网络多分类方法.提取说话人语音MFCC动静态组合特征,弥补彼此缺失的语言参数特性.使用PCA对动态组合特征降维,解决了因特征维数增加导致的计算复杂度增加的问题.在TIMIT语音库进行实验测试,该多分拓扑结构较一对一—深度置信网络大大缩短了测试时间,分类准确率达到87.46%,和其他多口音分类方法相比,分类准确率得到了显著地提高.鉴于带有口音的语音特征的多样性,如何有效的提取说话人语音的特征参数是一个具有挑战性的问题,未来需要在该领域深入研究以获得更高的分类准确率.
