面向深度学习训练任务的自适应任务分配方法
2020-01-14陈庆奎
陈 伟,陈庆奎
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
深度学习领域的研究近几年持续升温,并且不断有新的技术成果面世.近期,Google AI 团队的一篇论文提出了一种深度双向 Transformer 模型(BERT)[1],该模型在11个NLP 任务上(包括斯坦福问答(SQUAD)数据集)取得了目前为止最佳的性能.Nvidia的研究团队提出了一种新型的生成模型(GAN)[2],并在视频合成任务中取得惊人的效果.诸如此类的研究成果在深度学习领域如雨后春笋般不断涌现.从7月到现在,机器学习领域论文发表数量的增长率一直维持在每月3.5%左右,每年的增长率达到了50%.众所周知,深度学习的任务训练需要大量的计算资源,而单台普通的机器由于性能原因,很难在短时间内完成大型任务的训练.GPU集群计算正是解决这个问题的首选方案.它既能同时完成多个单机训练任务,也能进行单任务的分布式训练,大大提升了训练效率.Google在2015年年底开源了内部使用的深度学习框架TensorFlow[3,4].它可以运行多个大规模深度学习模型,支持模型生命周期管理、算法实验,并可以高效地利用GPU资源.除此以外,还有Keras、Caffe、Theano、Torch、MXNet等深度学习框架,但从Github上可以看出开发者更倾向于使用TensorFlow,而且它在图形分类、音频处理、推荐系统和自然语言处理等场景下都有相对成熟的应用.
可以看出,深度学习的发展非常迅猛,相应的框架也比较成熟,而随着深度学习网络层数不断增多,对硬件要求越来越高,或者说对训练速度的要求越来越高.近些年国内外专家学者花费大量时间去优化深度学习的各种模型[5,6]以及集群任务的调度与分配策略,目的之一就是为了能够最大程度降低深度学习任务的训练时间.然而这些优化的方法都是在训练过程中实现,也就是说,在训练之前还需要人为设置参数,包括训练方式以及分配资源.这些参数的设置往往依靠经验,但并不能保证任务能够在最短时间内训练完成,也不能使得GPU集群的利用率最高.如何自动有效地选择合适的训练方式,从而最大程度地提高训练效率以及集群的使用率,这是一个很有研究价值的实际问题.
针对上述的问题,本文创新性地提出一种面向深度学习训练任务的自适应任务分配方法.实现本方法首先需要计算出深度学习训练模型的复杂度,同时还需要知道GPU集群的计算能力、网络带宽等状态.前者可以通过已有的研究成果计算得出,后者可以通过查阅官方技术文档并结合Roofline模型计算得到.然后再借鉴组合优化的思想,根据不同训练方式下的理论耗时,最终得出最优的分配方案,即确定训练方式和相应的节点.本文第二部分介绍了一些基本的背景,包括优化深度学习算法和集群任务调度与分配的研究现状法、Tensorflow相关知识、CNN模型复杂度分析方法以及Roofline模型介绍.第三部分介绍自适应任务分配方法的原理和具体实现过程.第四部分通过实验论证本方法的有效性和准确性.最后第五部分对本文进行总结,同时对本方法的下一步研究工作进行展望.
2 背景介绍
2.1 研究现状
为了提高深度学习任务的训练效率以及整个集群系统的性能,目前国内外的研究重点在两个方面:深度学习算法的优化和集群中任务的调度与分配的优化.
Matthew D.Zeiler提出Adadelta算法[7],该方法不需要手动调整学习速率,适用于不同的模型体系结构和数据形式.RMSProp是另一个自适应学习率方法,它最开始由Jeff Hinton在Coursera的课程提出,随后被人们熟知并广泛使用,比如文献[8]中就用它来训练深度神经网络并取得很好的效果.文献[9-11]都实现了SGD算法的并行化,FPSGD[10]通过减少cache-miss和保证共享内存内各个线程的负载均衡来提升矩阵因式分解的效率,而文献[11]则利用环形结构组织GPU实现了卷积神经网络并行算法.Niu Feng等人提出HogWild[12],该方法可以在没有任何锁机制的情况下实现SGD.文献[13]对梯度下降过程中常用的一些优化器(BGD、SGD、MBGD等)做了综合的比较,并对不同优化器的适用场景做出说明.Ioffe等人提出的Batch Normalization[14],把它作为网络结构的一部分,规范化下一层的输入使得训练模型具有饱和的非线性.文献[15]提出在分布式训练中使用混合模式,把同步模式和异步模式的优势都发挥出来,从而实现更快的收敛速度,同时达到接近异步模式的吞吐速率.
文献[16]中通过遗传算法进行任务的最优分配,同时结合K均值聚类算法对子集群进行动态重组,但它如果应用于深度学习任务的训练,并没有结合训练方式的差异进行最优任务分配.文献[17]通过分析不同的任务分配方式对整个集群系统的影响,提出一种实现更公平的减速分配方法(FWP),但它只适用于运行时间相对较长的任务调度,对于短时间任务的调度性能比较糟糕.严健康等人结合GPU资源性能及负载情况和协同计算下自适应的流分发决策机制,设计了H-Storm异构集群的任务调度策略,但对于深度学习的部署还需要进一步研究[18].同样,E.Ilavarasan等人提出的高效任务调度算法(PETS)[19],在异构集群环境中有很出色的表现,但是对于深度学习的应用还有待研究.
但是,深度学习算法的优化都是对其内部结构做了相应的调整,针对不同的训练场景需要调整不同的结构才能取得更好的效果,而任务的调度和分配相关的优化方法,也是在确定了深度学习训练方式之后才能发挥作用.如果可以在任务训练之前就能预见不同任务的最佳训练方法和最佳资源配置,而不是单纯依靠经验去手动设置这些参数,这样就能保证每个训练任务可以在最短的时间内完成训练,从而进一步提高训练的效率以及集群的利用率.
2.2 TensorFlow训练策略
2.2.1 并行策略
对于深度学习来说,Tensorflow常用的并行策略主要包括数据并行、模型并行.另外还有模型计算流水线并行,但在实际工程中使用相对较少.
1)数据并行
在这种策略下,训练数据集被分成很多份,不同的计算资源(GPU/CPU等)里有相同的模型副本,每个计算资源上分配不同的训练数据,最终通过同步或者异步的方式处理损失和梯度,并更新模型.
2)模型并行
在分布式环境里,模型并行训练的过程中,不同的计算资源负责网络模型的不同部分,例如神经网络模型的不同网络层被分配到不同的计算资源,或者同一层内部的不同参数被分配到不同计算资源.
2.2.2 分布式训练模式
TensorFlow的分布式训练主要分为单机多GPU和多机多GPU,训练模式分为同步模式和异步模式.对于一个很大的训练任务来说,一般分布式训练的时间比单机训练要短很多,但是如果训练过程中mini-batch的数据量很小或者运算时间很短,可能会出现单机训练时间更短的情况,这是因为Tensorflow分布式训练中存在大量的网络通信开销.
同步模式:每个计算节点计算出各自部分的梯度,然后把这些梯度传给参数服务器PS.PS会等待所有的计算节点都计算完后,一起算出平均梯度,再去更新参数.虽然这样随着获得更精确的梯度估计,可实现更快的收敛,但因为每一次更新都是同步的,其整体训练时间取决于性能最差的那个计算节点.
异步模式:每个计算节点只需要算自己的梯度,然后参数服务器PS根据传过来的梯度异步更新参数,这样不同计算节点之间不存在通信和等待,所以可以有很高的吞吐量.同时,当某些计算节点因故障中途退出,对训练结果影响都不是很大.但是因为每个计算节点之间不相互通信,所以会出现参数抖动的情况.这种方式更适用于数据量大,参数更新次数多的情况.
2.3 计算平台的性能指标
伯克利大学的并行计算实验室提出的Roofline模型[20],它能够很直观的看出由于内存消耗造成的影响和瓶颈.Roofline模型提出,计算平台的主要性能取决于两个指标:
1)计算平台的计算性能上限π(单位:FLOP/s),它表示该平台每秒能够运算的最大浮点数的次数,它比每秒测量指令更精确.
2)计算平台的内存带宽上限β(单位:Byte/s),它表示计算平台的内存每秒能完成的最大交换量.
2.4 CNN模型的复杂度分析
本文研究深度学习模型以CNN模型为例.Roofline模型的计算过程中,还需要提前计算出CNN模型的一些定量:
1)CNN模型的计算量W(单位:FLOPS[21]),它表示模型进行一次完整的前向传播所发生的浮点运算个数,也即模型的时间复杂度.
2)CNN模型的内存消耗M(单位:Byte),它表示模型完成一次前向传播过程中所发生的内存交换总量,也即模型的空间复杂度.
3)CNN模型的计算密度I(单位:FLOP/Byte):I=W/M.
2.5 Roofline模型
Roofline模型提出使用计算密度I进行定量分析:当I小于一定值时,整个模型的训练过程将受限于计算平台的内存带宽上限β;当I大于或者等于一定值时,整个模型的训练过程将受限于计算平台的性能上限π.而该值就是π与β之比,也表示为计算密度的上限Imax.具体的Roofline模型如下:
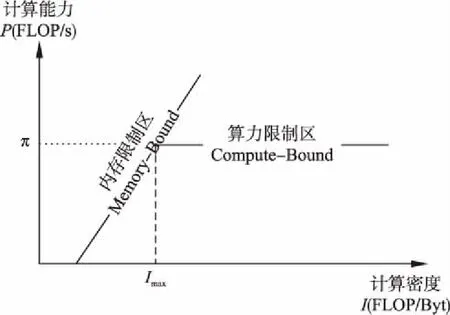
图1 Roofline模型[19]Fig.1 Roofline model[19]
从图1中不难看出,计算平台所能达到的理论最佳计算能力P(FLOP/s)满足下面公式(1):
(1)
3 自适应任务分配方法
通过Roofline模型,我们可以估算出计算平台所能达到的理论最佳计算性能,再根据深度学习模型的计算量和内存消耗,很容易能够估算出对应的计算时间.在此基础上,自适应任务分配方法可以根据GPU集群的中可用资源,再结合深度学习任务的模型复杂度,便能高效准确地确定最佳分配方案,集群基本结构图如图2所示.下面将详细介绍该方法的实现过程,本文结合CNN模型分析.
3.1 集群的基本结构
·主控制节点Head:负责分配训练任务到从节点.当数据服务器有新的数据,服务器组保持和数据服务器和从节点服务器组的通信.
·数据服务器:需要训练的数据预先下载到数据服务器,可以是网络数据.有新的训练数会广播给从节点据来了之后,数据服务器会通知Head.
·从节点服务器组:负责按照Head分配的任务进行训练.各从节点会在空闲的时候从数据服务器下载最新的数据,更新本地数据.各从节点和Head保持通信,定期发送本节点的GPU使用情况.
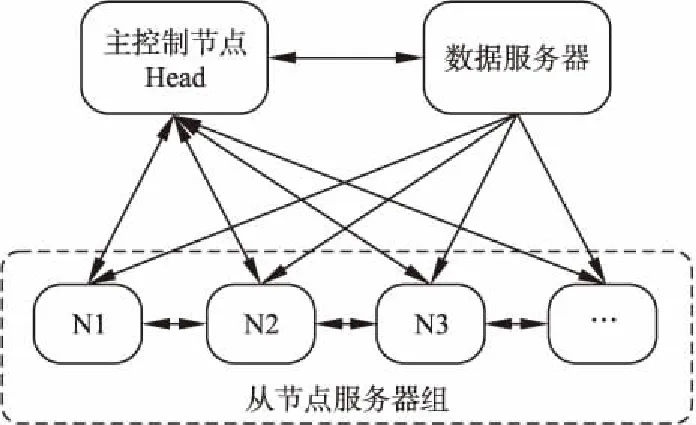
图2 集群基本结构图Fig.2 Basic structure of the cluster
3.2 CNN模型的定量分析
对CNN模型的定量分析主要在两个指标:计算量W和内存消耗M.通常W的单位使用FLOP/s(floating point operations per second)[21],也有用其它度量方式表示如MACC(Multiply-accumulate operation).不管以何种度量标准,它们都是指的矩阵叉乘,如果一次运算中不存在矩阵叉乘,则不可以使用该类指标.M的单位是Byte,一般所有的层都需要考虑到内存消耗.CNN模型中主要的层:卷积层和全连接层[22].当然,还有其他层包括激活层和池化层等,其在整个训练过程中占的时间只是很少的一部分.下面将具体介绍这两个定量的计算过程,以卷积层的一次前向传播过程为例.
第i层为卷积层的计算量Wi如公式(2):
(2)
其中,K表示该层每个卷积核(Kernel)的边长;Cini表示该层输入每个卷积核的通道数;Houti和Wouti分别表示该层输出的特征图(Feature Map)的高和宽;Couti表示该层卷积核的个数;即输出通道数.
第i层为卷积层的内存消耗如公式(3):
(3)
由于通常数据的单位为float32,而M的单位为Byte,因此需要乘以4.
CNN模型一次前向传播过程中的总计算量和总内存消耗如公式(4)和公式(5):
(4)
(5)
3.3 训练过程中的时间
深度学习任务的训练过程一般需要利用GPU来提高训练速度.按照GPU的使用情况可以还可以把分布式训练分为单机多GPU和多机多GPU两种情况.为了简化模型,本文提出的集群均采用单机单GPU配置,所涉及的分布式训练均指多机单GPU.
一个训练任务的总耗时会因不同的训练类型而不同.单机训练的情况下,总耗时主要包括理论计算时间和部分因其他因素影响而造成的额外时间开销.分布式训练的情况下,总耗时主要包括理论计算时间、节点间网络通信时间和部分因其他因素影响而造成的额外时间开销.
单机训练情况下:
Ttotal=τ+η
(6)
其中,τ表示本次训练中该从节点的理论计算耗时下限,η表示整个训练过程中因其他因素影响而造成的时间开销影响而造成的时间开销.由Roofline模型可以得到在Memory-Bound区域和Compute-Bound区域中τ的关系,如公式(7):
(7)
分布式训练情况下:
Ttotal=τ+Ttrans+η
(8)
其中,Ttrans表示分布式训练情况下的节点间的网络通信时间:
(9)
其中,B(单位:bit/s)表示网络带宽,而M的单位是Byte,因此要乘以8,一般实际传输时间要大很多.
自适应任务分配方法的目的是找到一种最优的任务分配方案,即确定CNN模型的训练方式以及相关的计算节点.因此,最小化训练总时间为目标函数,如公式(10):
Ttotal=Min{T1,…,Tn}
(10)
单机训练情况下:
把公式(6)带入公式(10)得到公式(11):
Ttotal=Min{τ1+η1,τ2+η2,…,τn+ηn}
(11)
分布式训练情况下:
把公式(8)带入公式(10)得到公式(12):
Ttotal=Min{τ1+Ttrans1+η1,…,τm+Ttransm+ηm}
(12)
其中,m表示第m种分布式训练的组合情况.
接下来进一步分析分布式训练下,第m种组合的具体参数可以表示如下:
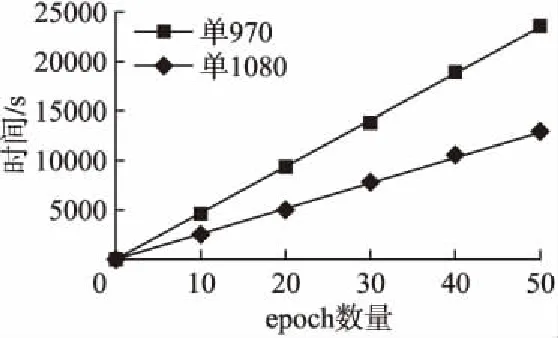
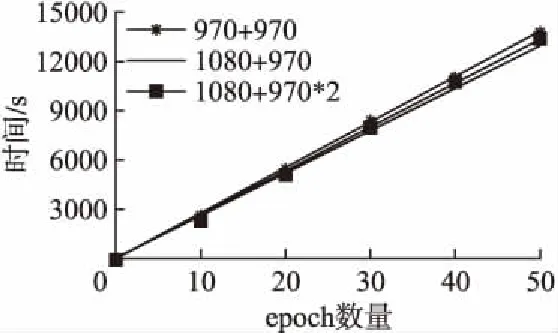
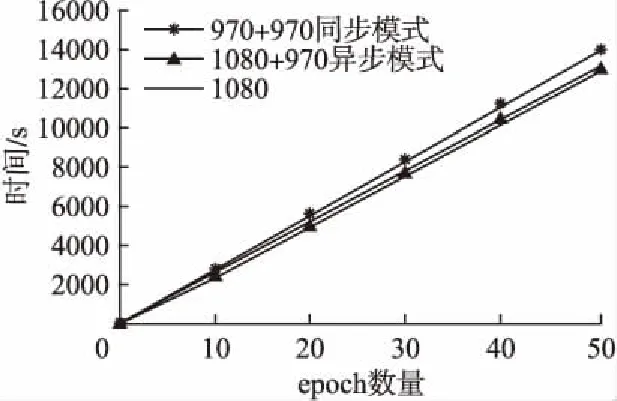
τm={τm1,τm2,…,τmn}(1 (13) Ttransm={Ttransm1,Ttransm2,…,Ttransmn}(1 (14) ηm={ηm1,ηm2,…,ηmn}(1 (15) 其中公式(13)中τmn表示该组合下第n个节点的理论计算时间,公式(14)中的Ttransmn表示该组合下第n个节点的网络通信时间,公式(15)表示该组合下第n个节点因其他因素影响而造成的时间开销.N表示集群中从节点的数. 分布式训练中整体的训练时间由训练最慢的那个节点决定,那么该组合下的整体时间就可以表示为公式(16): Ttotalm=Max{τm1+Ttransm1+ηm1,…,τmn+Ttransmn+ηmn} (1 (16) 这样,我们就可以进一步表示出分布式训练情况下,所有组合中总体时间最小的公式: Ttotal=Min{Max{T11,T12,…,T1n},…,Max{Tm1,Tm2,…,Tmn}} (1 (17) 其中,Tmn表示第m种组合下第n个节点的训练总时间. 把公式(11)和公式(17)整合一下可以得到模型的目标函数: (18) 当集群中的主控制节点收到新的深度学习训练任务指令后,会分析本次任务的深度学习模型,并结合集群中可用的GPU资源,找到最合适的任务分配方案.具体的计算步骤如下: 1)主控制节点Head通过广播,检测集群中可用的从节点资源,得到数组Array.Array是可用节点的集合,其中每个节点还包含编号、GPU的算力(capability)以及GPU的最大带宽(bandwidth)等属性.如果Array为空,则继续执行步骤1;否则执行下一步; 2)为了更快确定最优分配方案,需要对Array先根据Roofline模型计算出理论计算能力(公式(2)),然后按照该值排序(参考算法1).其中计算总量W和内存消耗M这两个定量需要根据CNN模型结构提前计算得到(公式(4)、公式(5));而计算平台的计算性能上限π和内存带宽上限β可以通过技术文档获取; 3)接下来分情况讨论:独立训练Independent和分布式训练Distributed.如果只有1个可用节点,则选择独立训练方式,执行步骤8;否则执行下一步; 4)根据公式(11)计算出独立训练方式下,理论的最短总时间Tmin_I和对应的分配节点UsedNodes_I,其中其他时间开销ηn等于每个节点的历史额外开销的均值,初始值为0; 5)根据公式(12)计算出分布式训练方式下预计的最短总时间Tmin_D和对应的分配节点组UsedNodes_D.根据集群中使用的网络带宽B和训练模型的M计算得出网络通信时间Ttrans(公式(9)); 6)再根据公式(18),比较两种方式下的最短总时间,确定最终方案.如果选择独立训练,则执行步骤8;否则执行下一步;(步骤3~6可参考算法2) 7)比较分配方案UsedNodes_D中各节点的计算能力差异,一般通过比较它们的方差大小来进一步决定使用同步模式还是异步模式; 8)配置训练脚本,开始训练. 算法1.求出计算节点实际的最大计算能力,并排序 Input:anArrayof all available nodes,the number of operationsWand the number of bytes of memory trafficM Output:anArraysorted by attainable compute 1.functionSortByCompute(Array,W,M) 2.I←W/M// operational intensity 3.fori=0→Array.length()-1do 4.π←Array[i].[′capability′]//node′s compute capability 5.β←Array[i].[′bandwidth]//node′s memory bandwidth 6.ifπ/β>Ithen 7.Array[i].[′compute′] ←β*I 8.else 9.Array[i].[′compute′] ←π 10.endif 11. end for 12. Quicksort(Array,0,Array.length()-1)// sorted by attainable compute 13.returnArray 14.endfunction 15.function Quicksort(Array,left,right) 16.ifleft 17.p← Partition(Array,left,right) 18. Quicksort(Array,left,p-1) 19. Quicksort(Array,p+1,right) 20.endif 21.end function 22.function Partition(Array,left,right) 23.pivot←Array[right].[′compute′] 24.i←left 25.forj=left→right-1do 26. ifA[j].[′compute′] <=pivotthen 27.swap(A[j].[′compute′],A[i].[′compute′]) 28.i←i+1 29.endif 30. end for 31.swap(A[right].[′compute′],A[i].[′compute′]) 32.returni 33.endfunction 算法2.确定最佳的分配方案,包括训练方式和相关的计算节点 Input:anArrayof ranked available nodes Output:theTrepresents the training method and the UsedNodesrepresents related nodes 1.Combination← […] 2.functionAdaptiveAllocation(Array)//W,M,π, 3.T←NULL 4.ifArray.length()=1then 5.T← ′Independent′ 6.Tmin,UsedNodes←M/Array[0].[′compute′]+Array[0].[′extracost′] 7.else 8.Tmin_I,UsedNodes_I← Min(M/Array[0…j].[′compute′]+Array[0…j].[′extracost′]) 9. Combination(Array,0,NULL) 10. SortByNumber(Combination) 11.Tmin_D,UsedNodes_D← Min(M/Combination[0…j].[′compute′]+Combination[0…j].[′extracost′]) 12.ifTmin_I 13.T← ′Independent′ 14.UsedNodes←UsedNodes_I 15.else 16.T← ′Distributed 17.UsedNodes←UsedNodes_D 18.endif 19. end if 20. returnT,UsedNodes 21.endfunction 22.function Combination(Array,i,name)//namerepresents the number of each node 23.ifi=Array.length()then 24.ifname!=NULLandname.length() > 1then 25.Combination.append(name) 26.return 27. end if 28. end if 29. Combination(Array,i+1,name) 30. Combination(Array,i+1,name+Array[i]) 31.endfunction 本次实验采用局域网小型集群,包括1台主控制节点Head、1台数据服务器和3台从节点服务器.所有节点的系统均为Ubuntu16.04.10.其中,Head的CPU为8核Intel(R)Core(TM)i7-7700 CPU @ 3.60GHz.另外3台从节点服务器内存均为32G,1台服务器GPU为GeForce GTX1080,显存8G;2台服务器GPU为GeForce GTX970,显存4G.局域网的网络带宽为100Mbit/s. 本次实验训练采用经典的手写数字数据集MNIST.开发环境中使用Python3.6,Tensorflow-gpu版本为1.3.0.选取的CNN模型为Alexnet网络[23],具体参数可参考表1. 表1 Alexnet网络具体参数 LayerTypeKernelSizeKernelMemOutputSizeOutMemFLOPSInputLayer00(28,28,1)7840Conv1(11,11,1,96)11616(28,28,96)752649106944Relu00(28,28,96)752640LRN100(28,28,96)752640Maxpool100(14,14,96)188160Conv2(5,5,96,256)614400(14,14,256)50176120422400Relu00(14,14,256)501760LRN200(14,14,256)501760Maxpool200(7,7,256)125440Conv3(3,3,256,384)884736(7,7,384)1881643352064Conv4(3,3,384,384)1327104(7,7,384)1881665028096Conv5(3,3,384,256)884736(7,7,256)1254443352064Dense1(12544,4096)51380224(4096,)409651380224Relu00(4096,)40960Dense2(4096,4096)16777216(4096,)40961677216Relu00(4096,)40960Dense3(4096,10)40960(10,)1040960 由表1可以计算出该Alexnet网络的一次前向传播的计算量约为334MFLOPS,内存消耗约为289MB,故计算密度约为1.16FLOP/Byte.通过查阅英伟达官网技术文档,得知GeForce GTX1080的π为6.1TFOLP/s,β为352GB/s,其最大计算密度Imax为17.33FLOP/Byte;GeForce GTX970的π为5.2TFOLP/s,β为232GB/s,其最大计算密度Imax为22.41FLOP/Byte.显而易见,该Alexnet网络计算过程在Roofline模型的Memory-Bound 区域,对应GeForce GTX1080和GeForce GTX970的理论计算能力分别为408.32GFLOP/s、269.12GFLOP/s. 在本实验中,首先利用自适应任务分配算法根据当前的情况确定分配方案,即理论最优方案;然后通过对比实验分别比较单机训练情况下和分布式训练情况下各种组合所消耗的时间,找出实际耗时最短的方案,即实际最优方案;最后通过对比理论最优方案和实际最优方案是否一致,从而判断本次实验中自适应任务分配方法是否准确. 针对当前实验环境,运行自适应任务分配算法最终给出的结果:单机训练,节点选择Node1(即GPU为GTX1080的节点). 接下来需要做多组实验,找出当前资源下,训练该Alexnet网络耗时最短的情况.经过预训练可以发现,该模型在训练50个epoch后,损失率达到最小.所以下面的实验主要比较训练前50个epoch所用时间. 4.2.1 单机训练情况 由图3可以看出,单机训练情况下,GTX1080训练同等数量epoch所消耗时间明显小于GTX970训练耗时.上文已经计算出该实验环境下GTX1080和GTX970的理论计算能力分别为408.32GFLOP/s、269.12GFLOP/s,前者是后者的1.52倍,而时间消耗上前者比后者降低了54.5%.因此,图3的实际结果与理论预期基本上相符合. 图3 单机训练情况下的时间比较Fig.3 Comparison of time in different stand-alone training situations 4.2.2 分布式训练情况 Tensorflow下的分布式训练主要分为同步模式和异步模式.本实验为多机单GPU的情况,假设分布式训练过程中每个GPU显存的占用率为100%.所有的分布式训练组合一共有三种: a)GTX1080+GTX970 b)GTX1080+GTX970+GTX970 c)GTX970+GTX970 训练过程中的参数服务器(PS)均设置在计算能力较强的那个节点上.具体训练情况如图4和图5. 由图4可以看出,GTX970+GTX970的组合耗时明显低于其他两种情况,耗时约为其它两种情况的59.3%.而GTX1080+GTX970+GTX970和GTX1080+GTX970这两种情况的耗时较大且基本相同,其实这并没有问题,因为上文介绍过在同步模型下,整体的性能取决于计算速度最慢的那个节点服务器.所以同时包含GTX970和GTX1080的组合耗时还是由GTX970来决定,因此耗时相对较大.而GTX970+GTX970的组合耗时较小的原因是,两个计算节点的计算能力相同,可以更快地实现收敛,从而提高整体的计算速度.值得注意的是,GTX1080+GTX970+GTX970的组合由于PS在GTX1080的服务器节点,所以它和两个GTX970服务器节点需要消耗大量的通信时间,而GTX970+GTX970两个节点之间的通信时间相对较小,因此后者的耗时比前者耗时小. 图4 同步模式情况下的时间比较Fig.4 Time comparison in synchronous mode 由图5可以看出,包含GTX1080的两个组合训练时间相差不大,GTX970+GTX970的组合耗时相对较大,比前两个组合增加了约6.2%.上文介绍过,异步模式可以提高吞吐量,每个节点训练完当前mini-batch后立即更新参数,这样就可以发挥计算能力较强的节点的优势.在本实验中,比较GTX970+GTX970和GTX1080+GTX970两种训练情况,就可以看出后者消耗时间小于前者,就是因为两者通信时间差不多但后者的GTX1080计算能力相对较大.再比较GTX1080+GTX970和GTX1080+GTX970+GTX970这两种情况,可以看出耗时基本相同,原因就是后者的通信时间相对较大,所以最终的耗时和前者基本相同. 图5 异步模式情况下的时间比较Fig.5 Time comparison in asynchronous mode 4.2.3 综合比较分析 通过对比图3、图4和图5中的最短耗时情况得到图6,可以看出,GTX1080服务器节点进行单机训练耗时比GTX970+GTX970同步模式情况下降低了8.1%,比GTX1080+GTX970异步模式情况下降低了2.3%.GTX1080单机训练时间和GTX1080+GTX970组合的分布式训练耗时相差并不是很大,这是因为节点间的通信消耗了大量的时间,而且该时间成本已经大于节点的计算时间.也就是说,通过多组实验表明,在当前的GPU集群资源下,使用GTX1080服务器节点进行单独训练Alexnet网络是最佳选择.这一结果和自适应任务分配算法计算出来的理论最优分配方案一致,说明本次实验有效地论证了该方法的合理性和有效性. 在同样的实验环境下,进行1000组相同的实验,大部分实验结果都表明自适应任务分配算法计算出来的理论最优分配方案和实际最优分配方案一致,得到91.6%的高准确率(结果一致的次数/实验的总次数).但是,有部分实验结果出现了理论最优分配方案与实际最优分配方案不符的情况,经研究发现,可能是网络的不稳定或者GPU长时间工作导致性能下降等原因.综上所述,本文所提出的自适应任务分配方法,可以有效地、高准确率地实现最优任务分配,从而在很大程度上提高了任务的训练效率以及集群的使用率. 图6 不同情况下的最短时间对比Fig.6 Shortest time comparison in different modes 本文提出的面向深度学习训练的自适应任务分配方法,可以根据当前GPU集群的可用资源,同时结合训练模型的复杂度,高效准确地找到耗时最短的分配方案,从而确定训练方式和具体的计算节点.本方法解决了人为配置训练方式以及分配资源而不能保证训练耗时最短的问题,提高了整体的训练效率和集群的利用率.本方法有别于传统的深度学习的优化算法,而是结合深度学习的特点和集群任务分配的特点,从组合优化的角度去确定最优分配方案,所以具有一定的创新性和简单高效且易于实现的优点.在异构GPU集群中训练Alexnet网络,可以得到91.6%的高准确率.除此以外,它还具有广泛的适用性,能够应用于同构或者异构的集群环境,以及部署了其他深度学习框架的集群中.后续的研究工作中,还需进一步提高本方法的健壮性,比如网络出现不稳定或者动态分配任务的情况下,如何继续保证整体耗时最短.3.4 算法描述
4 实验结果和分析
4.1 实验环境
Table 1 Specific parameters of Alexnet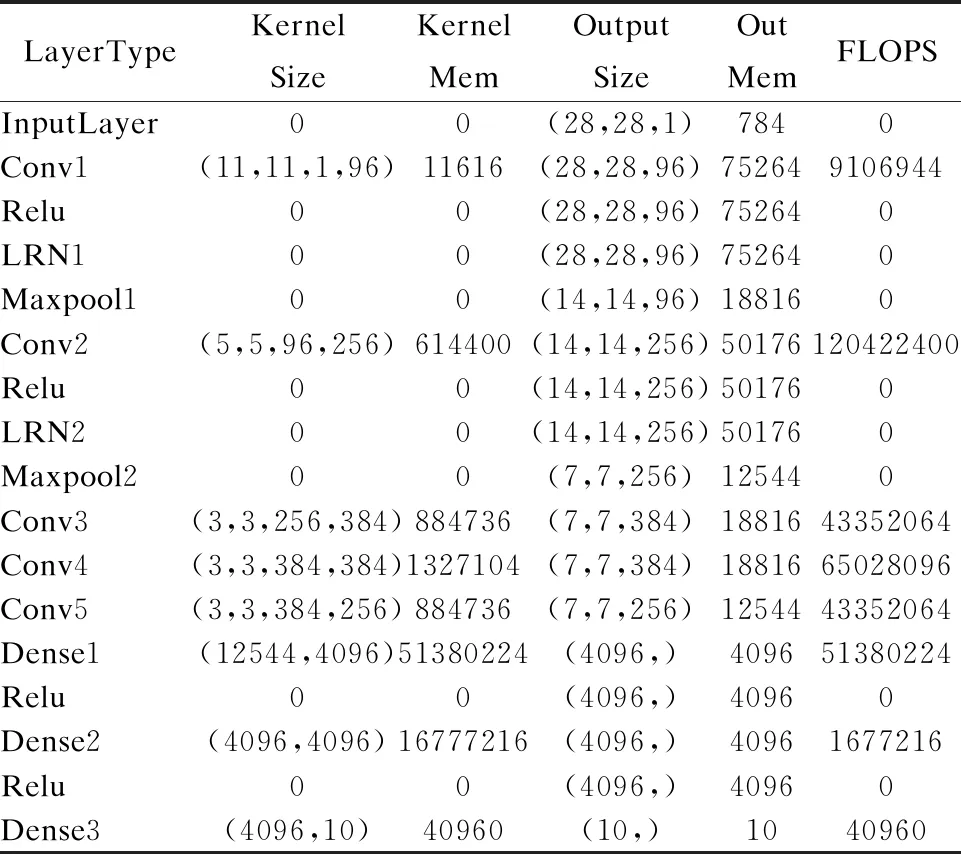
4.2 实验分析

5 总 结
