融合词预测的半监督老挝语词性标注研究
2020-01-14王兴金周兰江张金鹏郭剑毅
王兴金,周兰江,张金鹏,周 枫,郭剑毅
1(昆明理工大学 信息工程与自动化学院 智能信息处理重点实验室,昆明 650500)2(云南财经大学 信息管理中心,昆明 650221)
1 引 言
词性标注是根据句子上下文信息,为句子中每个词标注正确词性的过程,即要确定句子中每个词是动词、名词或其他词性.词性标注是很多自然语言处理(natural language processing,NLP)任务的预处理步骤之一,它能为句法分析、信息提取、词汇获取等后续研究提供很大帮助.
老挝语和中文同属于孤立性语言,即并非使用词的形态变化来表达语法意义,而是使用虚词与词序来表达.然而老挝语有着自己独特的语法特点:其一,老挝语中有许多针对量词、名词等词性的句法固定搭配.其二,老挝语中的状语和定语在句中的位置比中文更加灵活.对这些语法规则加以总结研究,可以运用于老挝语词性标注中,提高标注精确度.
早期词性标注使用基于规则的方法[1],即由专家总结大量语法规则来指导词性标注.该方法针对特定领域准确率很高,但制定规则非常艰难,由此基于统计的方法得以发展.应用比较广泛的有隐马尔科夫模型(hidden markov model,HMM)、最大熵(maximum entropy,ME)模型[2]和条件随机场(conditional random fields,CRFs)模型[3].ME模型对语料库依赖性强,CRF训练代价大、复杂度高,而HMM不存在这些缺点.因此学者们以HMM为基础,并做出各种改进来利用词与词性信息.文献[4]使用决策树创建HMM的转移概率矩阵,以便在低资源语料下充分利用影响标注的信息;文献[5]使用HMM与规则结合的方法进行词性标注,在有限语料的情况下提高了HMM的准确率;文献[6]提出用三元语言模型构建2阶HMM,TNT算法处理数据平滑,利用词缀信息解决未登录词标注,该方法被广泛应用.这类研究的下述经验值得借鉴:第一,对传统HMM进行了改进,考虑了更多影响词性标注的信息;第二,基于规则与统计的方法结合来进行词性标注,以提高模型准确率和标注速度.但此类研究仍未能解决一个问题:HMM词性标注只能利用当前标注的上文信息,未能利用后文词性信息.此外,未登录词词性标注是所有词性标注研究中的重要问题,因为若未登录词词性标注错误,则会导致误差传递,对后续标注有很大的影响.
目前老挝语词性标注研究较少.从现有发表文献来看,基于HMM的老挝语词性标注最高准确率为89.8%[7],文献中使用半监督学习解决了语料库规模小的问题,训练词缀概率模型解决未登录词标注.综上所述,本文借鉴上述研究经验,对未有效解决的问题做出改进,并研究了未解决的问题,构建融合词预测的半监督隐马尔科夫老挝语词性标注模型.长短期记忆网络(long short-term memory,LSTM)[8]是循环神经网络的变体,适合用于处理时间序列中间隔和延迟相对较长的任务.本文首先基于LSTM建立了词预测模型,并改进维特比(Viterbi)算法,将词预测模型融入HMM中以解决未登录词词性标注问题.其次,研究老挝语语法,制定老挝语法规则集,采用规则和统计相结合的方法来提高HMM标注精度与速度.再有,使用半监督学习方法,以拓展老挝语词性标注语料库,并得到正、反半监督HMM.最后,使用正、反半监督HMM进行词性标注,并考虑后文词性的影响,对标注结果进行优化.
2 未登录词处理
在HMM词性标注过程中,若未登录词词性标注错误,则误差会传递影响后续标注.以往研究采用训练词缀概率模型、统计未登录词分布、同义词替换等方法来处理,但存在未考虑词序影响、受词窗口大小选取限制,近义词查找失败等问题.为有效解决此问题,本文首先基于LSTM建立词预测模型来预测未登录词的预测词集;然后,将预测词集交给改进的Viterbi算法,确定未登录词词性.本节对词预测模型的使用和构建作介绍,Viterbi算法的改进在3.2节介绍.
2.1 词预测模型原理
词预测模型使用未登录词周围的已登录词来对未登录词进行预测,用预测词替换未登录词参与词性标注.预测过程考虑了未登录词前后已登录词与词序的信息,因而预测词与未登录词在句子结构中,同一词性的概率很高.但若只预测一个词来替换未登录词,词性标注仍有可能出错.为了进一步提高词性标注的准确率,本文挑选多个预测词(前N个概率最大的词)来组成预测词集,再将预测词集交给改进的Viterbi算法,以选择未登录词的最佳词性.
词预测模型的准则是:利用尽可能多的已登录词对未登录词进行预测.使用词预测模型预测未登录词前,需要找到尽可能多的已登录词:从未登录词位置开始同时向左、右最大匹配已登录词,匹配中遇到其它未登录词或首、尾词则停止,得到左词集(L-Sets)和右词集(R-Sets).接下来,设置词预测模型的预测词数量,将左、右词集输入到词预测模型中,就可以得到预测词集R.为保证预测准确率,虽然对未登录词进行了预测,但在之后其他预测中仍认为它属于未登录词.已登录词匹配时,若左右连接词皆未登录,则认为未登录词的词性唯一且为普通名词.因为经过统计,语料库中普通名词是最多的,占36%的比例.
2.2 词预测模型构建
词预测模型构建是基于LSTM,其专门用来处理长期依赖缺失问题.LSTM的关键在于它的细胞状态,在LSTM结构内,通过门结构来决定细胞状态信息的增加或删除.由于LSTM具有长时记忆特点,词预测模型只要输入足够多的已登录词信息,便能够取得不错的预测效果.LSTM结构如图1所示:
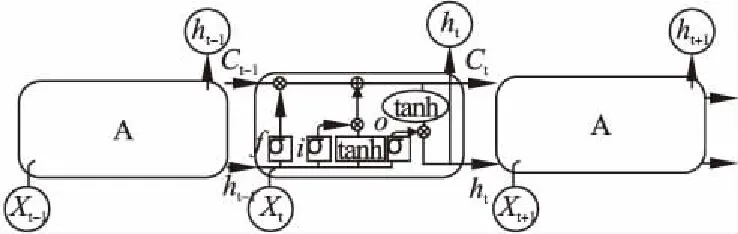
图1 LSTM结构Fig.1 LSTM structure
LSTM结构内部共有3种门:输入门i,遗忘门f和输出门o.输入门控制记忆单元更新的信息量,其决定让多少新的信息加入到单元状态中;遗忘门控制前一个时刻记忆单元信息被利用的量,也就是决定上一个细胞状态中丢弃什么无用信息;输出门控制输出到下一个隐藏状态的信息量.
图2为词预测模型结构图,其包括4层:输入层、隐藏层、全连接层与输出层.输入层接收的数据是老挝词,词在进入隐藏层前需要转换为对应的词向量,因此需要在隐藏层与输入层之间构建一个词向量矩阵(Embeddings).词向量矩阵的行数为词汇表的大小,列数可以根据语料的复杂度来设计.训练开始时,首先将词向量矩阵随机初始化,之后在全连接层到输出层之间作为权值进行训练,直到模型收敛.为了能够更好的拟合老挝词分布规则,模型设计了两个隐藏层,并使用LSTM.为了避免模型陷入过拟合,数据进入LSTM前都会有一个随机Dropout的功能,将数据按比例随机去掉一部分.全连接层使用简单的神经单元,其作用是将隐藏层的两个输出向量进行拼接,并把维度转换为词汇表的大小.输出层使用Softmax函数,用来计算预测词在词汇表上的概率分布.在模型预测时,可以从分布中挑选概率最大的若干个词构成预测词集R.
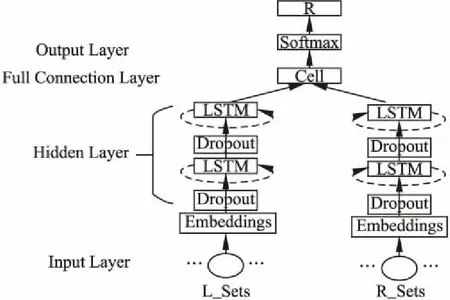
图2 词预测模型结构Fig.2 Word prediction model structure
在模型使用前,需要训练它的参数.训练使用交叉熵损失函数来计算预测值概率分布与真实值概率分布之间的差距,并且使用Adam优化算法来优化模型的参数以减小差距.使用篇章老挝语分词语料库,令模型学习老挝词分布规则.当出现未登录词时,将未登录词的左、右词集输入到输入层中,模型可以利用学习到的分布规则对未登录词进行预测.
3 老挝语词性标注模型
3.1 HMM原理
HMM是用来描述一个含有隐含未知参数的马尔科夫过程,是一种静态马尔科夫模型.本文使用的老挝语词性标注模型是以2阶HMM为基础的,其包括下面5个基本要素:
1)老挝语词性的隐藏状态数N.如果S是词性状态集合,则S={S1,S2,…,SN}.
2)老挝词的观察状态数M.如果V为观测词的集合,则V={O1,O2,…,OM}.
3)老挝词词性的初始概率分布π,分布可以表示为π={πi,1≤i≤N}.其中:πi表示词性Si处于初始状态下的概率.
4)老挝词词性的转移矩阵A={aijk}.其中:aijk=P(Sk|Sj,Si),0 5)观测词概率矩阵B={bij(Om)}.其中:bij(Om)=P(Om|Si,Sj),0 一般的,HMM在数学上可以表示为:λ={A,B,π}.对于转移矩阵A与观测词概率矩阵B存在的数据稀疏问题,本文使用文献[9]提出的TnT算法来解决. HMM词性标注时,使用的是Viterbi算法,该算法利用HMM的5个基本要素,动态规划的为一个老挝语句子搜索最佳标注序列.使用词预测模型可以得到未登录词的预测词集R,如果使用传统Viterbi算法,无法利用预测词集的信息.因此本节对Viterbi算法进行改进,以便利用预测词集确定未登录词位置每种词性的最大概率. 首先在老挝句子o1…om…on的首尾加入o0与on+1,o0与on+1分别对应词性标注′Start′与′End′,计算过程如下: Step 1.初始化: 若o1已登录,使用公式(1)计算δ1: δ1(i,j)=πjbij(o1) (1) 若o1未登录,首先利用词预测模型来预测o1的替换词集R1,然后利用公式(2)进行计算δ1: (2) 计算δ1后,使用公式(3)对Ψ1赋初值: Ψ1(i,j)=0 (3) 这里的i表示o0词性(即:′Start′),j表示o1词性,0 Step 2.对t=2,3,4…n+1进行递推: 若ot已登录,使用公式(4)计算δt: (4) 若ot未登录,首先利用词预测模型来预测ot的替换词集Rt,然后使用公式(5)进行计算δt: (5) 计算δt后,使用公式(6)计算Ψt: (6) 其中,1≤i,j,k≤N. Step 3.停止: (7) (8) Step 4.对t=n-1,…,2进行最优路径回溯: (9) 老挝语有独特的语法规则,本文对其进行详细总结,作为老挝语法规则集来指导词性标注,以提高标注准确率.规则由参考文献[10]及专家指导制定: 1)量词不能重叠.例如:汉语中可以使用“只只”来表达“每一”,但是在老挝语中却不能这样表达. 2)除表达日期外,数词后几乎都是接量词. 3)当修饰年、月、日时间名词或行政单位时,省略量词.如:表达“两个月”时,老挝语为“两月”;‘两个学校’,老挝语为‘两学校’. 4)老挝语时间表达,采用“时间名词+时间数词”形式. 6)利用数词对名词进行修饰时,语法为:“名词+数词+量词”.如:“两个苹果”,老挝语为“苹果两个”. 7)老挝语在人名前加称谓.如:“主席+习近平”. 9)老挝语中98%的数词使用阿拉伯数字表示,可以使用正则表达式来辅助数词的标注. 本文准备了50596个词的老挝语分词、标注篇章语料,20006个词的老挝语分词篇章语料.为了拓展老挝语分词、标注语料库,利用Self-training算法,令上述得到的融合词预测与规则的HMM进行半监督学习.使用Self-training算法前,需要设定分类策略:句子标注可靠率在80%以上认定为合格(比较正、逆向标注,标注一致的部分认为可靠,否则不可靠[11];句子标注可靠率=句子中可靠标注个数/句子标注总个数).首先,用正、逆序分词、标注语料训练融合词预测与规则的HMM,得到正、反HMM,用于对老挝句子正、逆向标注.其次,用正、反HMM标注分词语料,并找到标注结果满足分类策略的语料.最后,将这些语料从分词语料中取出,将其及对应标注加入分词、标注语料中,返回第一步再次训练正、反HMM.将上述步骤反复迭代,以得到正、反半监督HMM,两模型将用于3.5节的词性标注及不可靠标注检测. Self-training算法具体过程如下: Step 1.计算分词语料库的大小,作为迭代执行的最大次数,并设置分类策略; Step 2.循环执行以下步骤,达到最大迭代次数为止,以得到正、反半监督HMM; Step 3.使用正、逆序分词、标注语料训练融合词预测与规则的HMM,得到正、反HMM; Step 4.使用正、反HMM对分词语料库进行标注,并且检测每条语料是否满足分类策略; Step 5.从分词语料取出满足策略的语料,将语料及对应标注加入分词、标注语料中,并返回Step 3. 由Viterbi算法可知,HMM在词性标注过程中,未能考虑后续词性对当前标注的影响.例如:二阶HMM对句子“桌上有只笔”进行词性标注,当标注“有”的词性时,能利用的信息有“桌、上”的词性与词“有”,无法利用“只、笔”的词性信息.因此本文对标注结果进行了优化.具体操作如下: Step 1.使用正、反半监督HMM对老挝句子进行正、逆序标注; Step 2.将逆序标注作为参照,查找正序标注中的不可靠标注(标注结果的不一致部分).若正序标注中的不可靠标注左右连接为可靠标注,则使用公式(10)对不可靠标注进行修改,否则保留原标注结果.修改完成后,返回正序标注为最终结果. (10) 其中:L为左可靠词性,R为右可靠词性,J为任意词性,i为不可靠标注的位置.对标注结果里存在的不可靠标注,公式(10)可以使用其上下文词性信息进行修改,此过程有效解决未考虑后续词性对当前标注影响的问题. 表1 语料信息 InformationWords HMM Model -Training Set43006HMM Model -Testing Set7590The Unknown Words of Testing Set213Word Prediction Model-Training Set62012 实验使用的数据有两部分:第一部分是经过分词、标注的老挝语篇章语料,有28种词性、50596个词;第二部分是只被分词的老挝语篇章语料,有20006个词.语料取自老挝网站,并经人工校准.将第一部分语料的85%作为训练集,用于正、反半监督HMM的构建;15%作为测试集,用于标注准确率测试.第二部分及第一部分中的训练集用于训练词预测模型.测试集中的未登录词的数量为213.所有数据在使用前都做了预处理工作:用Number来替换数字、去除所有的标点符号、词频低于三的词用“unk”来替换,以及在句子的首尾加入“Start”、“End”字符来表示开始与结束. 由于词预测模型的输入数据有2766个非重复词,因此词向量矩阵为2766行.词预测模型参数经过多次调整,设置如表2所示. 表2 词预测模型参数 ParametersValueEmbeddings(2766,150)Dropout10%Lstm-dim150Maximum gradient norm5R3 本文对HMM词性标注进行4个方面改进:第一,为解决未登录词标注问题,构建了基于LSTM的词预测模型,并对Viterbi算法进行改进,将词预测模型融入HMM中;第二,制定了老挝语法规则集,并融入HMM中;第三,对HMM使用了半监督学习;第四,对标注结果进行优化. 为了测试改进的效果,实验设计五个模型进行对比分析.模型1是本文所提出,为HMM加入四个改进后得到的老挝语词性标注模型,其他模型在模型1的基础上改变一种改进,与模型1作对比,以测试四种改进的效果.模型2、模型3、模型4和模型5分别用于测试未登录词标注、老挝语法规则集指导、半监督学习和结果优化的词性标注效果.其中,模型2未采用未登录词处理,模型3未采用老挝语法规则集,模型4采用有监督学习的方式,模型5中未采用结果优化.表3给出各模型的词性标注准确率. 表3 对比模型设计 ModelUnknown Word ProcessingLao Rules SetLearning StyleResult OptimizationPrecision(%)1Word Predic-tion ModelSemi-su-pervised92.552✕Semi-su-pervised79.703Word Predic-tion Model✕Semi-su-pervised91.764Word Predic-tion ModelSupervised91.315Word Predic-tion ModelSemi-su-pervised✕91.92 本文提出的模型1表现最佳,标注准确率为92.55%.模型2未处理未登录词,准确率仅为79.70%,较模型1低了12.85%.因为若不处理未登录词,该词及之后词的标注都将失败,标注准确率受到了很大的影响.在老挝语法规则集效果测试中,模型3的准确率为91.76%,比模型一低了0.79%.因为老挝语法规则集指导下,使得满足规则词及该词周围词的标注准确率都得到了提高.此外,老挝语法规则集还可以加快HMM的标注速度.在学习方式测试中,模型4的准确率为91.31%,比模型1低了1.24%.因为半监督学习将分词语料库不断扩充到标注语料库,用于训练HMM.半监督学习结束后,HMM已经被大规模标注语料训练,并得到正、反半监督HMM,可以用于词性标注及结果优化.在结果优化测试中,模型5的准确率为91.92%,较模型1低了0.63%.优化过程采用正、反半监督HMM来检验标注结果,以发现不可靠标注,并对不可靠标注进行优化.优化的过程有效考虑了后续词性的影响,因此提高了模型的标注性能. 本文使用相同测试集,测试了应用于老挝语及其他语言词性标注的代表性HMM方法. 方法1.文献[6]用TNT算法解决数据平滑问题,并用生词的词缀信息和词类型来解决未登录标注. 方法2.文献[7]用整体规划进行半监督学习,并使用词缀信息来解决未登录词标注. 方法3.文献[11]利用二次计算进行半监督学习,使用word2vec[12]计算词相似度,用近义词的词性来构成未登录词的词类.实验结果见表4. 表4 不同方法对比 MethodPrecision(%)189.2289.6392.23Ours92.55 表5给出了测试集中,主要词性的个数,标注的准确率、召回率及F值. 表5 主要词性信息 TagTotalPrecision(%)Recall(%)F score(%)CNM20710098.599.2PRA246100100100N119693.395.794.5V73195.597.296.3CLF12286.287.586.8PRE54992.795.494ADJ2658390.586.5REL13293.170.280.0 针对老挝语词性标注问题,构建了融合词预测的半监督老挝语词性标注模型,该模型在HMM的基础上做出四种改进:构建词预测模型,改进Viterbi算法来对未登录词进行词性标注、HMM与老挝语法规则集的结合、半监督学习、标注结果优化.基于LSTM构建了词预测模型,并改进Viterbi算法,将词预测模型融入HMM中,以解决未登录词词性标注问题.词预测模型预测时,在充分考虑未登录词前后已登录词及词序的影响,标注具备普适性的前提下,选择出现概率最大的三个词构成未登录词的预测词集,进而确定未登录词词性,提高了词预测的准确率.在实验中,该方法的词性标注准确率高于对比文献采用方法,老挝语词性标注准确率达到了92.55%.使用规则与统计相结合的方法,较为全面的总结了老挝语法特点,用于制定老挝语法规则集.规则与HMM的结合,不仅提高了标注准确率,而且加快了模型标注速度.实验结果表明,加入规则后模型标注准确率提升了0.79%.为了拓展老挝语词性标注语料库,使用半监督学习方法,提高了老挝语词性标注模型的泛化能力.相比有监督学习,标注准确率提高了1.24%.HMM在词性标注时,未考虑后续词性的影响,因此提出结果优化方法.由半监督学习得到正、反半监督HMM,用于词性标注、查找不可靠标注.对不可靠标注,使用其对应词以及该词的前后可靠词性来进行优化,使得标注准确率提升了0.63%.未来的工作中,将会考虑使用三元HMM,使用更多影响词性的信息,并制定更加详细的老挝语法规则集来提升标注的准确率.3.2 Viterbi算法改进

3.3 老挝语法规则集
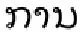
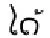
3.4 半监督学习
3.5 词性标注及结果优化
Table 1 Corpus information
4 实验与分析
4.1 数据准备与参数设置
Table 2 Word prediction model parameters
4.2 实验设计与结果分析
Table 3 Contrast model design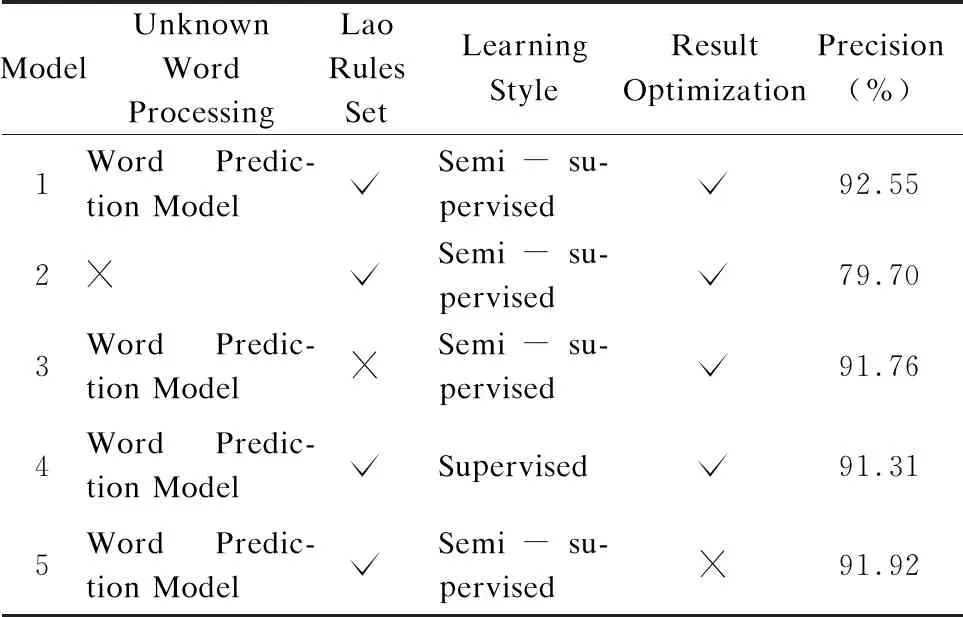
4.3 不同方法对比实验
Table 4 Comparison of different methods
4.4 标注结果具体分析
Table 5 Information of main part-of-speech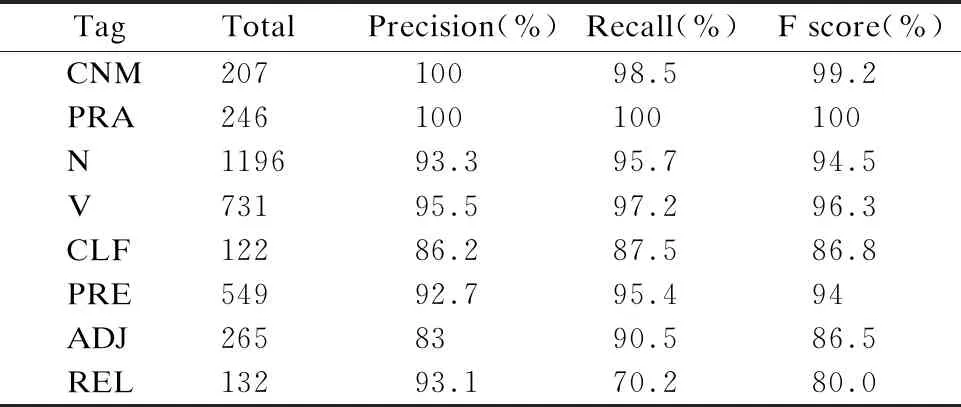
5 结 论
