基于常规指标的肺癌及胃癌早期诊断模型*
2020-01-06谢冰雪姚荧袁文博郑晓圆姜孙旻刘劝
谢冰雪 姚荧 袁文博 郑晓圆 姜孙旻 刘劝Δ
(1. 江南大学附属医院(无锡市第四人民医院)肿瘤科,江苏 无锡 214000;2. 南京医科大学附属无锡妇幼保健院药学部,江苏 无锡 214000)
恶性肿瘤严重危害人类健康,是当今世界人类的主要致死原因之一[1]。恶性肿瘤的早期诊断、早期治疗是提高其生存期的最重要途径之一[2]。
由于现今诊断方法的局限,大部分患者初诊肿瘤时往往已是中晚期,而大多数恶性肿瘤仅在初期阶段可获得治愈机会。根据2015年国家癌症中心报道,我国肿瘤发病率前两位为肺癌、胃癌,这二种肿瘤也是我国患者因肿瘤死亡的主要原因[3]。将近2/3的肺癌患者发现时已经无法进行手术治疗。对于Ⅰ期肺癌患者,经过手术治疗,5年生存率高达54%,而对于未经治疗的5年生存率只有6%。大多数晚期发现患者都在1到2年内发病身亡[4-5]。胃癌也同样如此,绝大部分胃癌患者初诊时已是中晚期。对于早期胃癌来说,5年生存率>90%,远高于进展期胃癌。早期胃、肺癌诊断率低,部分原因是现有的早期检测手段,如电子计算机断层扫描(Computed tomography,CT),正电子发射计算机断层显像(Positron emission tomography-computed tomography,PET-CT)价格昂贵,且患者依从性差,因此探寻临床上常规、简单有效且具有较高诊断价值的方法至关重要[6-8]。患者血常规以及生化指标是患者入院检查的必检项目,如果能够将其结果通过特定的模型进行计算模拟,找出肿瘤患者和健康人群的区别,或可成为肿瘤早期发现简单易行的手段。
本研究基于血常规以及生化指标结果,采用主成分分析(Principal component analysis,PCA)、正交偏最小二乘判别分析(Orthogonal partial least-squares regression-discriminate anaysis,OPLS-DA)等化学计量学模型[9-10]评估分析肺癌、胃癌患者与健康体检者血常规、生化指标的区别。为肺癌、胃癌早期检查提供数据支持,并力行将评估模型用于临床实践。
1 临床资料与方法
1.1 材料
1.1.1临床资料
标本来源:肿瘤组均为原发恶性肿瘤,标本来源于2014年1月到2015年12月在无锡市第四人民医院住院手术患者,全部病例己经手术和病理确诊。
肺癌组:72例,其中男35例,女37例,34岁~75岁;胃癌组:57例,其中男30例,女27例,38岁~66岁;对照组:对照组随机选取健康体检者50例,其中男25例,女25例,28岁~70岁,见表1。
以上各组均排除糖尿病、肝病、肾病、传染病、血液病等疾病。所有的临床指标均为手术前数据,(若有多次检测结果,取均值),血常规采集于抗凝管中、血生化指标采集于促凝管中用于检测。
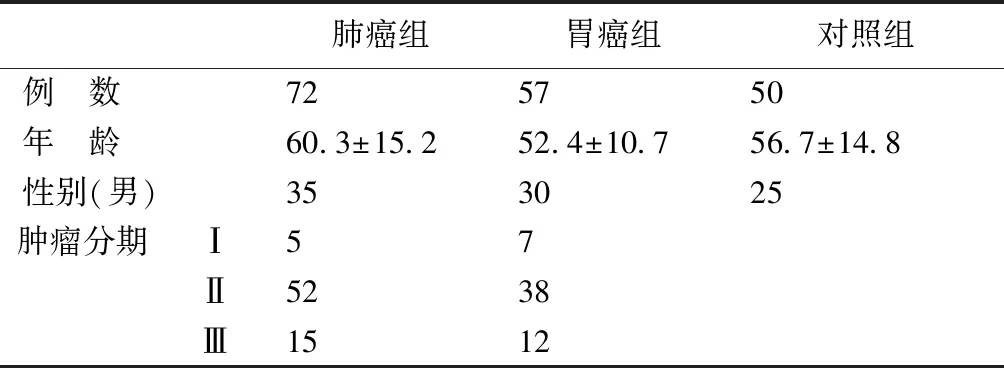
表1 入组人员信息情况表
1.1.2血常规、生化指标检测
血常规项目使用抗凝全血在LH750全自动血液分析仪测定;生化指标均使用静脉血清在P800全自动生化分析仪测定。胃癌组和肺癌组对比指标,见表2:血常规指标20项、生化指标45项;胃癌组和肺癌组与正常患者对比指标,见表3:血常规20项、生化指标16项。

表2 胃癌组和肺癌组对比指标
1.1.3数据处理
所有的临床指标均为手术前数据,(若有多次检测结果,取均值);筛选:每种指标在每组内的缺失比例小于20%,每个样本的指标缺失比例小于20%;以组内均值填补缺失值;组间数据对齐。
原始数据导入SIMCA-P 13.0;所有变量做自动标准化(Unit variance scaling,UV Scaling)处理,消除变量的量级对统计模型的影响;主成分分析(Principal component analysis,PCA):从高维变量中提取出能够表征原始数据的主成分;正交-偏最小二乘回归(Orthogonal partial least-squares regression-discriminate anaysis,OPLS-DA):根据分组信息对原始数据进行提取和压缩;最后利用OPLS-DA模型的变量投影重要性(Variable importance in projection,VIP)参数筛选组间差异指标。

表3 胃癌组和肺癌组与正常患者对比指标
2 结果
2.1 胃癌组-肺癌组的指标差异分析
胃癌组与肺癌组无监督的主成分分析模型不稳定,见图1a,在分组信息未知的情况下,个体差异比较大。有监督的OPLS-DA模型较稳定,见图1 b,根据分组信息构建模型,组间差异较明显。组间差异指标(即VIP>1)主要有补体C3、红细胞分布宽度、胆碱酯酶、补体C4、B-羟基丁酸、嗜酸性粒细胞绝对值、总蛋白、球蛋白、前白蛋白、红细胞压积、血红蛋白、乳酸脱氢酶、视黄醇结合蛋白、淋巴细胞比例、免疫球蛋白M、嗜中性粒细胞比例、G-谷酰胺基转移酶和白细胞,见表4。

图1 胃癌组-肺癌组的指标差异分析注:蓝色:肺癌,红色:胃癌。a:无监督的主成分分析,A:表示主成分分析模型中的主成分的个数;N表示总样本量;R2X表示模型的解释率(即主成分所含有的信息占原始数据的比例);Q2表示模型的稳定性(越接近1表示模型越稳定)。b:有监督的OPLS-DA模型。A表示模型的结构,与分组相关主成分数+正交主成分数+0;N表示总样本量;R2X/R2Y表示模型对原始数据和分组信息的解释率;Q2表示模型的稳定性(R2Y和Q2越接近1表示组间差异越明显)

表4 胃癌组肺癌组间的差异指标
2.2 胃癌组-肺癌组-对照组的指标差异分析
2.2.1 胃癌组-肺癌组-对照组无监督的主成分分析模型不稳定,见图2a,在分组信息未知的情况下,个体差异比较大。有监督的OPLS-DA模型不太稳定,见图2b,三组组间有差异。

图2 胃癌组-肺癌组-对照组指标差异分析注:蓝色:肺癌,红色:胃癌,绿色:对照。a:无监督的主成分分析模型;b:有监督的OPLS-DA模型。
2.2.2 胃癌类-对照组有监督的OPLS-DA模型较稳定,见图3,组间差异明显,主要差异指标有:白蛋白、红细胞、红细胞分布宽度、红细胞压积、血红蛋白、白球蛋白比例、总蛋白、单核细胞比例、单核细胞绝对值和淋巴细胞绝对值,见表5。

图3 胃癌类-对照组有监督的OPLS-DA模型

表5 胃癌类-对照组组间差异指标
2.2.3 肺癌类-对照组有监督的OPLS-DA模型较稳定,见图4,组间差异明显,主要差异指标有:白球蛋白比例、白蛋白、淋巴细胞比例、单核细胞绝对值、红细胞、球蛋白、红细胞压积、血红蛋白、碱性磷酸酶、G-谷酰胺基转移酶、单核细胞比例、嗜中性粒细胞比例、淋巴细胞绝对值和葡萄糖,见表6。
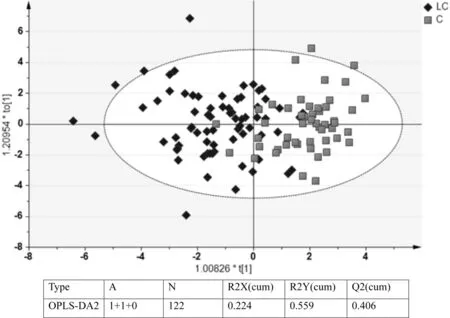
图4 肺癌类-对照组有监督的OPLS-DA模型

表6 肺癌类-对照组组间差异指标
3 讨论
癌症患者伴有血液常规、生化常规等指标的不同程度的变化,这种变化可能具有肿瘤特征模式。有效癌症治疗的前提在于早期诊断,肿瘤诊断从已形成了影像诊断,内镜诊断、化学诊断、组织诊断、细胞诊断等一系列的诊断方法。但至今仍未发现敏感度和特异性均十分理想的早期诊断方法[11],因此合适的肿瘤早期诊断方法是达到普筛目的的首要前提[12]。
偏最小二乘回归法(Partial least-squares regression,PLS)是采用信息综合与筛选技术的多元回归建模方法[8]。正交偏最小二乘判别分析(Orthogonal partial least-squares regression-discriminate anaysis,OPLS-DA)是在PLS-DA基础上发展起来的,由于过滤了X中与Y不相关的信息噪声,因此OPLS-DA方法比PLS-DA能提高模型的预测效果。OPLS-DA方法不仅可以提高癌症的诊断效果,而且可以避免过度诊断,通过常规的血液学以及生化指标结合化学计量学模型即可达到早期诊断的目的[13]。
胃癌和肺癌的许多患者在诊断时已是晚期,失去了最佳治疗时机[14-15]。目前,在我国早期胃癌的诊断率仍在10%左右,而在一些先进国家如日本,其早期胃癌诊断率可高达50%-70%[16]。内镜技术对早期胃癌病变的诊断有一定的价值和意义[17],然而内镜属于侵入性检查,费用较高且患者依从性差,不适于胃癌大规模筛查和胃癌的早期诊断。在肺癌筛查方法中,痰细胞学检测是进行早期肺癌筛查最传统的方法[18-19],但易受取材、保存、制片、染色等诸多因素的影响。而影像学筛查费用过高,患者依从性差[20]。本研究拟通过对常规的血液学以及生化指标结合化学计量学模型即可达到早期诊断的目的。
4 结论
从主成分分析结果可见,尽管胃癌组与肺癌组模型不稳定,但在分组信息未知的情况下,个体差异比较大。有监督的OPLS-DA模型较稳定,根据分组信息构建模型,组间差异较明显。对于肺癌组和对照组以及胃癌和对照组有监督的OPLS-DA模型均较稳定(Q2 0.406),组间差异均较明显。因此,通过有监督的OPLS-DA模型可为胃癌和肺癌的诊断以及鉴别提供数据支持,为肿瘤早期诊断提供理论基础。
