基于Python的学位论文自动排版研究
2020-01-04李秀贤
李秀贤


[摘 要] 针对Word格式的学位论文原文,研究基于Python的论文排版自动化。采用用户数据替换模板范例数据的方法实现自动排版,旨在尽可能地减少论文排版操作,提高工作效率和正确率。
[关 键 词] Python;论文排版;自动排版
[中图分类号] TP391 [文献标志码] A [文章编号] 2096-0603(2020)09-0128-02
一、问题提出
国内学位论文的撰写大多数人采用Microsoft Word文字处理器或Latex的标记式的文本编辑器。虽然这些编辑器能为使用者提供非常强大的字处理功能和文档控制功能,但论文排版依然有许多繁杂的工作需要使用者人工手动完成。
近年来,有部分高校利用Office对象库进行Word的二次开发,为学生提供了毕业论文排版平台,使用者不必再花费大量的时间去学习那些不常用的Word排版操作,而生成正确排版文档。但是,即使使用二次开发的排版工具,也需要人工操作才行,特别是正文部分的章、节、小节的划分需要人工干预。
由于学位论文文档的结构基本上是固定的,通常它由以下部分及顺序组成:封面、声明(诚信或原创性、著作权使用)、中英文摘要、目录、正文、参考文献、致谢、附录等。正文部分是论文的核心,其他部分都是论文的附属部分。论文附属部分都存在固定的特征标志,例如,论文封面通常包括:学校信息(代号、名称)、论文中英文题目、论文作者相关信息(专业、年级、所属系部、姓名、学号和指导教师)、论文完成日期,这些内容前存在若干固定不变的标识字符;每所学校都提供标准声明范文供学生填写;参考文献部分的格式有国家统一的规定,例如,专著、论文集、学位论文、报告的格式是:“[序号]主要责任者.文献题名[文献类型标识].出版地:出版者,出版年.起止页码(可选)”,每段开始有特征“[序号]”,结尾特征为数字等。鉴于这些规律,本文针对Word格式论文原文,研究基于Python的学位论文自动排版。论文自动排版就是按照标准的格式要求,处理未排版论文的内容,并输出完全符合规定格式的论文。从排版的角度来看,在进行文字录入的时候同时应用样式进行排版,效率较高。对于一篇未排版论文,如何模拟人工录入文档内容的方式实现快速排版,这是本文研究的重要内容之一。
二、关键技术
Python本身只能处理text文本,若要在Python程序中操作控制Word文档,可以使用Python win32com组件对象接口或Python docx扩展库。
(一)win32com组件对象接口
使用win32com接口需要先安装pywin32扩展库。该库封装了Python下所有的win32相关操作,它提供了齐全的Windows常量、接口、线程以及COM机制等,是Python调用Windows系统底层功能的最佳接口。其中win32com模块定义了Windows API内的宏,通过win32com接口实现软件的操作本质上跟直接操作软件是一致的。
win32com组件对象接口只对Windows平台有效,对Word文档操作需要本机上有Word应用程序的支持。当在程序内导入这个模块之后,把Word文档、文档中的段落、文本、字体等都当作对象,就可以像VBA一样操作Word。在程序中操作Word文档,其本质就是实例化Word文档对象,使用对象的方法和属性,对对象进行处理就是对Word文档的内容处理。
(二)Python docx扩展库
Office的Docx类型文档采用开放文件格式(Office Open XML),它的基本方法是将文本和格式存储成xml,其他图片等资源存储成独立文件,并将其进行Zip压缩。Docx文档解压后结构如图1所示。
其中,[Content_Types].xml的作用是确定文档中每个唯一类型组件;_rels文件夹存储组件之间的连接;docProps文件夹存储结构化的文档属性;word文件夹存放大部分的内容组件,其中Word的正文内容被保存在word/document.xml中,这就是Word存储文本的方式。操作Docx文档本质就是操作一组复杂的XML文件。
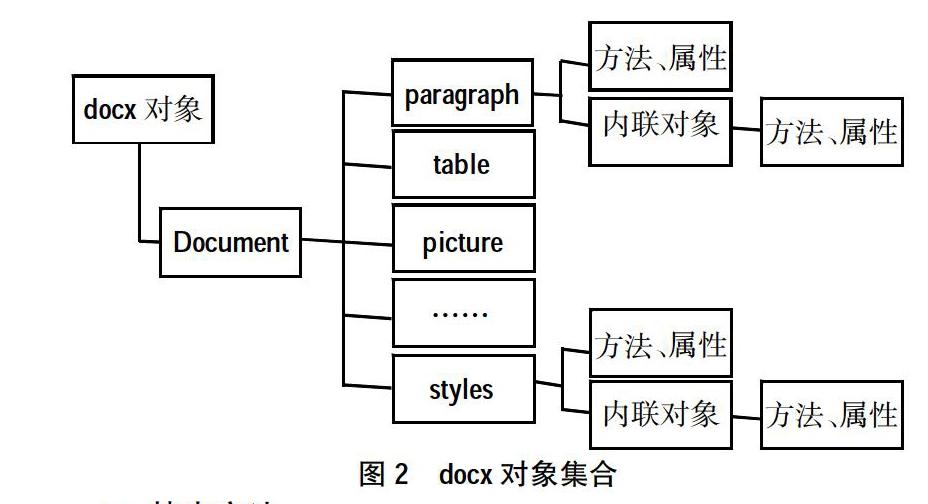
Python docx是一款开源的读写Word文档的组件,不依赖操作系统。该扩展库实际上是对XML操作的封装库,docx对象顶层是Document,代表Word文档;下面是段落(paragraph)、表(table)、图片(inline picture)、节(sections)、标题(heading)、有序列表(numbered lists)、无序列表(bullets lists)、样式(styles)等块级对象(block-level object)。块级对象的属性可指定对象所在的位置,对齐方式、缩进、段间距离、页码等。一个块级对象由一个或多个內联对象(inline-level object)组成。块级对象的所有内容都包含在内联对象中,内联对象的属性指定了字体,例如粗体、斜体、大小等等,run 是常用的内联对象。其关系如图2所示。
三、基本方法
(一)使用论文格式模板配合数据库存放排版参数
学位论文格式智能检测与自动排版需要的格式参数,在本设计中根据学位论文组成结构采用格式模板文件与数据库相结合的方法保存格式参数,论文每一组成部分对应一个模板文件。为了改善处理效率,在论文模板文件中除了设置好各种格式要求(行距、字体、大小、段前、段后、段落缩进、对齐方式、标题等级、页眉页脚、页码等),还要在对应位置写入具有唯一性的范例数据,这样可缩小搜索范围和减少位置的计算量。例如,封面模板文件学号一栏的正确位置上写入12345678,当查找到该字符串,无须计算就能获得位置信息。通过程序将学位论文各个组成部分的格式参数和定位信息导入到数据库,尽可能地减少用户用于自动排版参数的输入工作量。
(二)用替换模板范例数据实现论文附属部分自动排版
由程序按论文结构顺序将各部分的模板组合成一个新文件new.docx,摘要、目录使用罗马数字连续“I、II…”编制页码,正文开始的以后部分都使用阿拉伯数字“1,2,3…”编制页码。为避免各部分页眉、页脚、页码的影响,各部分之间用分节符分隔,如图3所示。此时,new.docx文件排版格式已到位,只是内容暂时未到位。
当需要对未排版论文进行处理时,先清除文内不必要的空行和段首空格,将手动换行符(软回车)替换成段落标记。然后从未排版论文中按定位特征提取相关信息,用纯文本方式替换new.docx文档对应部分的范例数据。由于替换过程只改变文本,新信息就自动继承该位置的格式,达到排版要求。
例如,当处理程序从未排版论文的封面提取到论文作者的学号后,与模板上学号范例数据“12345678”比对字符串长度,若长度不等,在相对短的字符串两侧添加空格,达到平衡,然后用替换命令将论文作者的学号覆盖学号范例数据“12345678”。诚信声明部分的处理更简单,只需要将提取到的论文题目名,替换范例数据“学位论文排版自动化研究”就完成该部分的排版工作。同样,论文摘要只需要提取摘要内容的段落和具体的关键词即可。
由此方式产生的排版结果文件不会出现不允许出现的信息,例如,论文封面上不会有页眉、页脚,信息的排列顺序不会发生错误,各部分的页码不会互相影响。
当对导入的学位论文进行检测与排版处理的过程中,如何准确定位到论文的指定部分是至关重要的。由于字符查找通常需要明确查找范围、查找内容等要素,本系统采用特征定位方法,使用论文每一组成部分首尾特征寻找被处理区域,并对定位匹配算法优化。例如,论文摘要区域开始的特征是标题字符“摘要”或“Abstract”,尾部特征字符是“关键字”或“Keywords”。于是程序就可以根据“摘要”和“关键字”,定位到Word文档所在页面。
多模板的使用可缩小标准格式的搜索范围,若使用合成模板文档,通过sections集合,只需要在指定的节内搜索。
(三)用样式处理论文正文的排版
由于研究对象涉及的各个具体学科、选题、研究方法、论证过程、结论表达等可能存在差异,故无法对论文正文主体的内容作统一规定,正文模版只需设置全部标题层次格式及其标题之间分隔段的格式。
论文正文的排版处理首先需要正确地分割章节,在两章之间插入分页符,使用多重循环,依段落为单位,利用add_paragraph将获得的内容插入new.docx文档正文部分,并指定对应的style即可实现格式设置。
论文正文章节分割,可通过定位章节标题来完成。但是待排版的论文无法预知标题名,这可借助章节标题隐含的特征来判断,章节标题隐含特征包括:A.论文标题层次一般采用3级制,可以是阿拉伯数字体的层进制或汉字体的章节制;B.层次标题都比较精短,长度一般小于20,结尾无句号,标题段落应该为单行;C.与标题相邻的2~3个段落不会出现同级标题。
根据标题格式使用正则表达式快速定位到指定段落,当查找到对应的段落后,再检测该段落是否符合这些特征,以便于确定是否是正文标题。例如,按正则模式“^[0-9]”定位后,若相邻同样是数字开始的段落,且前导数字与定位到的段落数字差1,说明所定位的区域是正文中的数字列表,若与该行比较接近的位置若存在节标号段落,则可认定这是章的标题。
当正文排版完成后,使用Document.Tables Of Contents属性,就可以自动生成目录。
(四)定位准确率的优化
Word对象模型提供了Find对象和Replacement对象,可同时进行多个查找与替换,支持通配符和正则表达式,还可以结合格式进行准确查找。
Python提供了强大的查找替换功能,可以使用字符串类型提供的find( )或者index( )方法查找指定的字符,也可以引用fnmatch库实现使用通配符来查找字符串,减少定位的出错率。当需要查找比较复杂的字符规则,可直接调用内嵌集成的re模块,来实现正则匹配。re模块中有findall、finditer、match、search四个方法用于匹配字符串,可根据不同要求采用其中的一种方法,sub函数通过正则表达式,实现比普通字符串的replace更加強大的替换功能,可替换所有的匹配项。
四、结论
本研究尝试不直接对原始论文调整其格式,模拟人工填写文档内容的方式,提取未排版的原始论文数据替换模板范例数据的方法实现自动排版。充分利用模板上已有的格式,减少对论文具体的排版操作,这样事半功倍,其优点明显。
参考文献:
[1]季金奎.浅谈学生毕业论文格式排版的问题与对策[J].福建电脑,2016(8):155,159.
[2]胡海英.基于Word VBA技术的试卷自动排版系统的设计[J].电子技术与软件工程,2014(3):64.
[3]马吉权.毕业论文自动排版系统的设计与实现[J].中国科教创新导刊,2013(26):189-190.
◎编辑 张 俐