运用探索性数据分析(EDA)和梯度提升决策树(GBDT)识别人身保险欺诈的方法探讨
2019-12-05王飞跃中国太平洋人寿保险股份有限公司
王飞跃 黄 涛 黄 磊 中国太平洋人寿保险股份有限公司
《反保险欺诈指引》实施以来,要求保险公司建立欺诈风险识别机制,通过欺诈因子筛选、要素分析、风险调查等方法,发现风险因素。如何对欺诈风险进行及时识别,是保险行业实践中亟待探讨解决的问题和挑战。本文通过探讨综合运用探索性数据分析(EDA)和梯度提升决策树(GBDT)方法,在已知问题赔案数据较少的情况下,可以较为有效地识别人身保险领域欺诈案件,为行业和同业公司保险欺诈风险识别提供参考。
一、引言
保险欺诈(Insurance Fraud)是指故意制造保险事故、谎称发生保险事故或夸大索赔以骗取保险金的行为,它以不当得利为目的,严重损害保险公司利益。欺诈导致的额外成本最终将通过后续保费上涨转嫁给诚实投保人,严重侵蚀保险市场赖以运作的公平保费理论。近年来,保险欺诈团伙化、专业化、职业化特点愈发突出,不仅损害诚实守信的保险消费者利益,侵蚀保险公司经营成本,甚至影响保险业的健康稳定发展及社会诚信体系的构建。《反保险欺诈指引》第二十六条明确要求,保险机构应建立欺诈风险识别机制,对关键业务单元面临的欺诈风险进行收集、发现、辨识和描述,形成风险清单。其中包括通过欺诈因子筛选、要素分析、风险调查等方法,发现风险因素。如何对人身保险欺诈领域开展有效的识别和预警,是保险公司保险欺诈研究的核心内容。
目前保险公司传统的反欺诈分析依赖相关人员的经验和其能获取数据的程度。受人力、物力所限,保险欺诈案件大多凭借理赔人员和风险监测人员的直觉从大量的案件中抽取出来进行分析。识别规则主要依靠一些固定标准和人员的长期经验筛选可疑案例,调查的质量主要依赖于理赔人员的个人素质以及与业内其他公司、部门的个人关系。在保险业信息化发展的大背景下,客户各种信息的数字化、业务电子商务化、理赔流程系统化、事故现场的影像化,一方面为保险公司积累了大量的数据,另一方面也使传统的以实物为基础的反保险欺诈模式受到极大的挑战,因此迫切需要建立以大数据为基础的反保险欺诈的新模式,提高对保险欺诈风险识别的技术水平。
二、方法及选择
反保险欺诈的大数据分析流程主要包括五个层面的工作流程:风险分析、构建规则模型、筛选可疑数据、进行验证核实、后续优化等,形成完整的、闭环运作的反保险欺诈数据分析体系。关于模型选择目前存在定性分析法、决策树/风险树、评分卡、复制模型、人工智能和知识图谱等方法,但都难以单独解决在已知较小样本基础上准确识别未知欺诈案件。
探索性数据分析(EDA)是指对现有数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构、规律或异常值的一种数据分析方法。梯度提升决策树(GBDT)是一种集成学习的方法,通过集成多个学习器来构建最终预测模型,即对于一个复杂任务来说,将多个学习器(专家)的判断进行适当综合所得出的判断,比其中任何一个学习器(专家)单独做出的判断要好。梯度提升决策树算法经过多轮迭代,每次迭代生成一棵新的决策树,并将新的决策树添加到模型中汇总,不断提升预测模型的精度,并形成最终的模型。本次已知问题赔案数量较少,共28条,待检查的赔案数据为4000条。因此,拟首先运用探索性数据分析(EDA)对已知人身保险欺诈案件特征进行分析;其次运用梯度提升决策树(GBDT)建立大数据分析模型,通过对比各个赔案的评分,分析评分相近的赔案,对比赔案之间的特征,发现疑似案件;最后通过现场复勘评估风险识别的准确性。
三、规则梳理
以赔案号为唯一标识将“问题赔案数据”和“待核实赔案数据”两部分数据进行整合。结合保险欺诈案件的常规特征和本次问题赔案的特点,初步选择出一些典型的字段,并通过分析,明确字段对应的规则。从业务的角度对选取字段和规则的合理性进行初步验证。
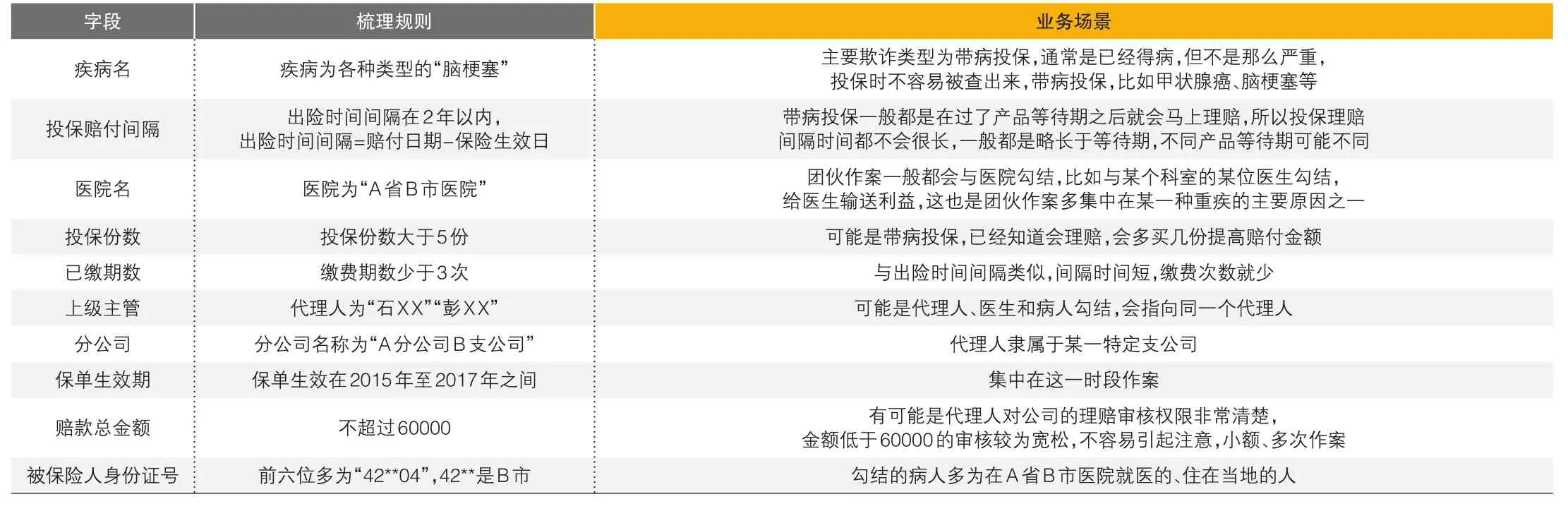
▶表1 字段、规则、业务场景梳理结果
四、探索性数据分析(EDA)
运用探索性数据分析方法对整合数据进行分析,发现问题赔案的特征变量与待核实赔案有显著差别,包括保费、赔款总额、赔款总额与保费比例、被保险人年龄、被保人身份证所在地区与销售地点等特征变量等,最终确定将保费总额、赔款总额、被保险人年龄、医院、疾病、赔款总额与保费比例、被保人身份证所在地区与销售地点是否一致等作为用于后续测算的特征变量。分析方法如下:
(一)利用关系网络进行分析,发现业务员、上级主管、医院和疾病之间存在关联关系。在图1中,线条的粗细代表关联关系的强弱。在问题赔案中,有多个业务员的上级主管均为“石XX”,而“石XX”和医院“A省B市医院”有非常强的关联关系;医院“A省B市医院”和两种疾病“脑梗塞”和“腔隙性脑梗塞”有较强的关联性(详见图1)。
(二)问题赔案的保费多集中在1000—4000元之间,而待核实赔案的保费主要集中在1400—7000元之间,并且问题赔案的保费普遍较低(详见图2)。
(三)问题赔案的赔款总额多集中在25000—60000元之间,而待核实赔案的赔款总额主要集中在0—35000元之间,并且问题赔案的赔款总额更为集中(详见图3)。
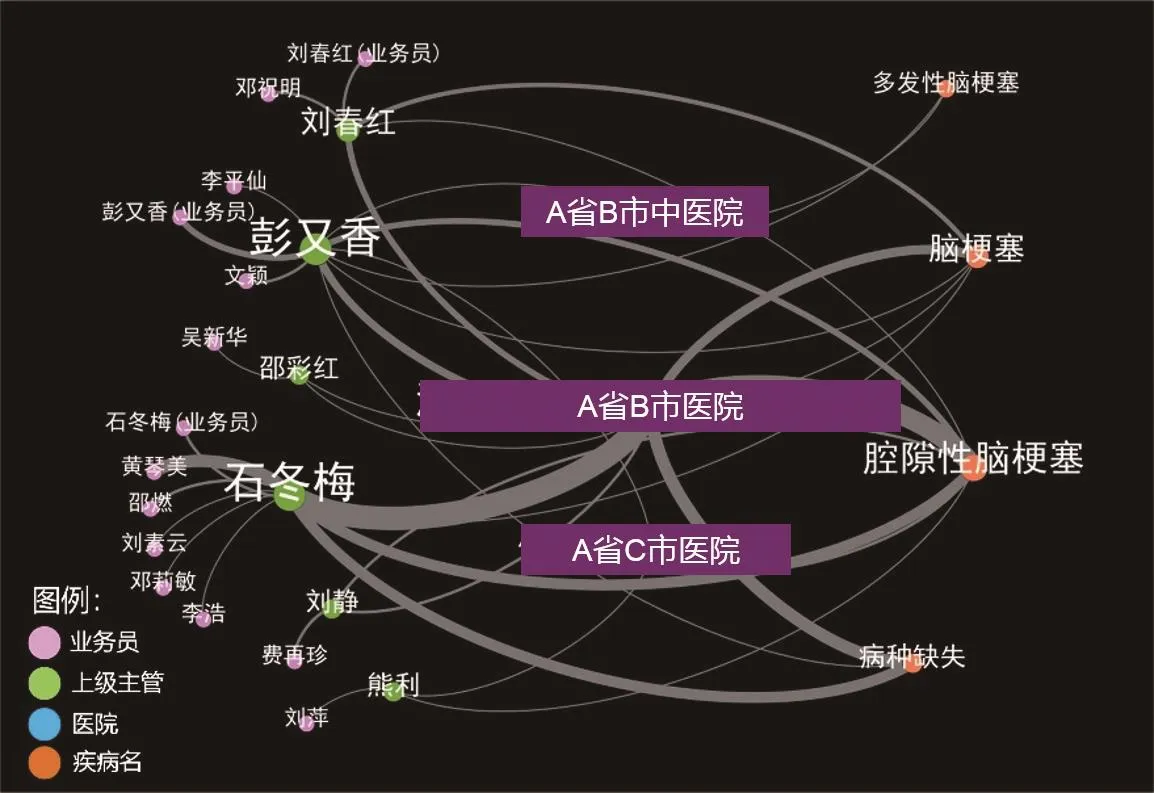
▶图1 业务员、上级主管、医院及疾病的关系网络图
(四)问题赔案的赔款总额与保费比例趋势线(红线)呈上升趋势,即问题赔案的赔款总额与保费比例随着赔款总额的上升而上升,主要由于问题赔案的保费较低、缴费次数较少,且不随赔款总额的变化而变化(详见图4)。
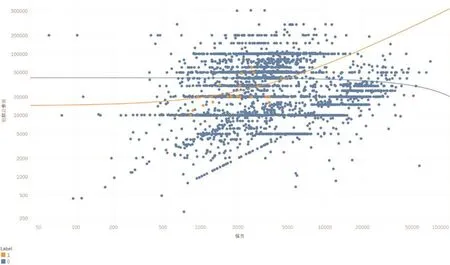
(五)经过分析对比待核实赔案中被保险人身份证所在地区与销售网点所在地区发现,大部分赔案的被保险人的身份证与销售网点在同一地区(黑色直线划出部分),同时也存在被保险人的身份证与销售网点不在同一区域(异地投保)的现象。在异地投保中,有五处较为集中的异地投保区域包括1号区域、2号区域、3号区域、4号区域、5号区域(详见图5)。
(六)从被保险人年龄段来看,35岁—40岁年龄段的问题赔案件数占比最高,50岁—55岁年龄段的问题赔案件数最多。在待核实赔案中,被保险人年龄超过65岁的赔案有376件(详见图6)。
五、梯度提升决策树(GBDT)分析
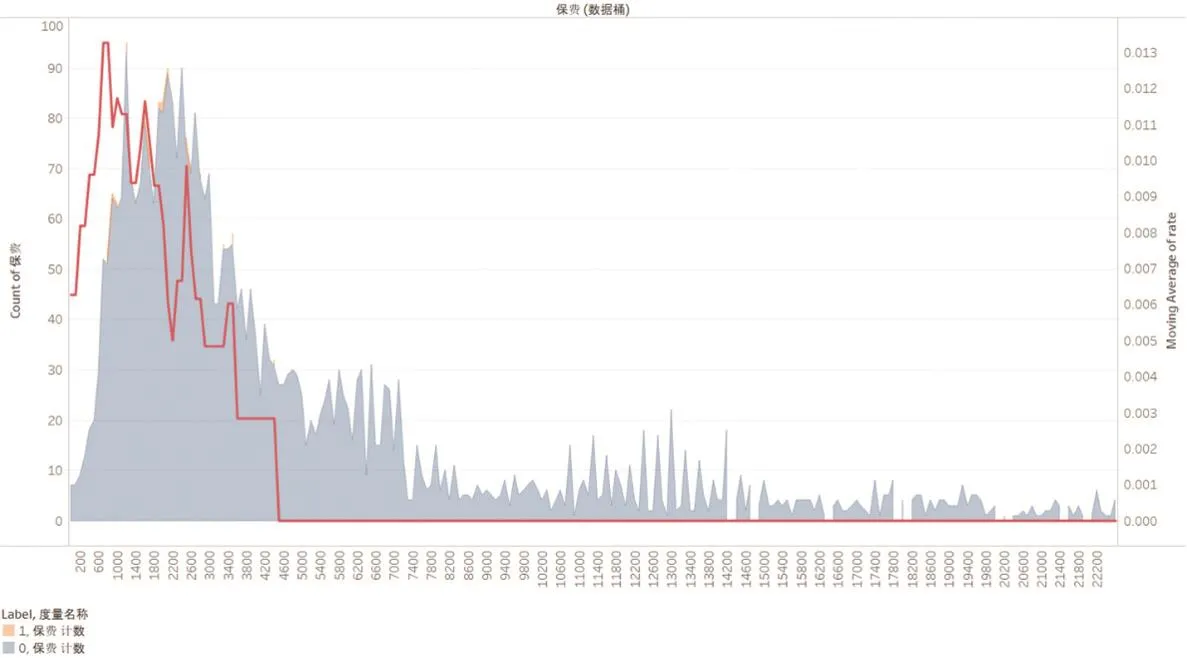
▶图2 保费对比分析
▶图4 赔款总额与保费比例的对比分析
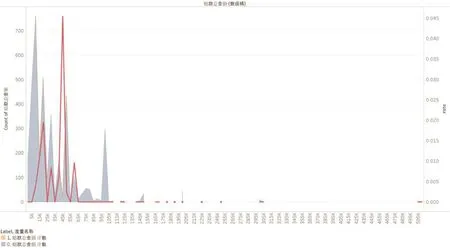
▶图3 赔款总额对比分析
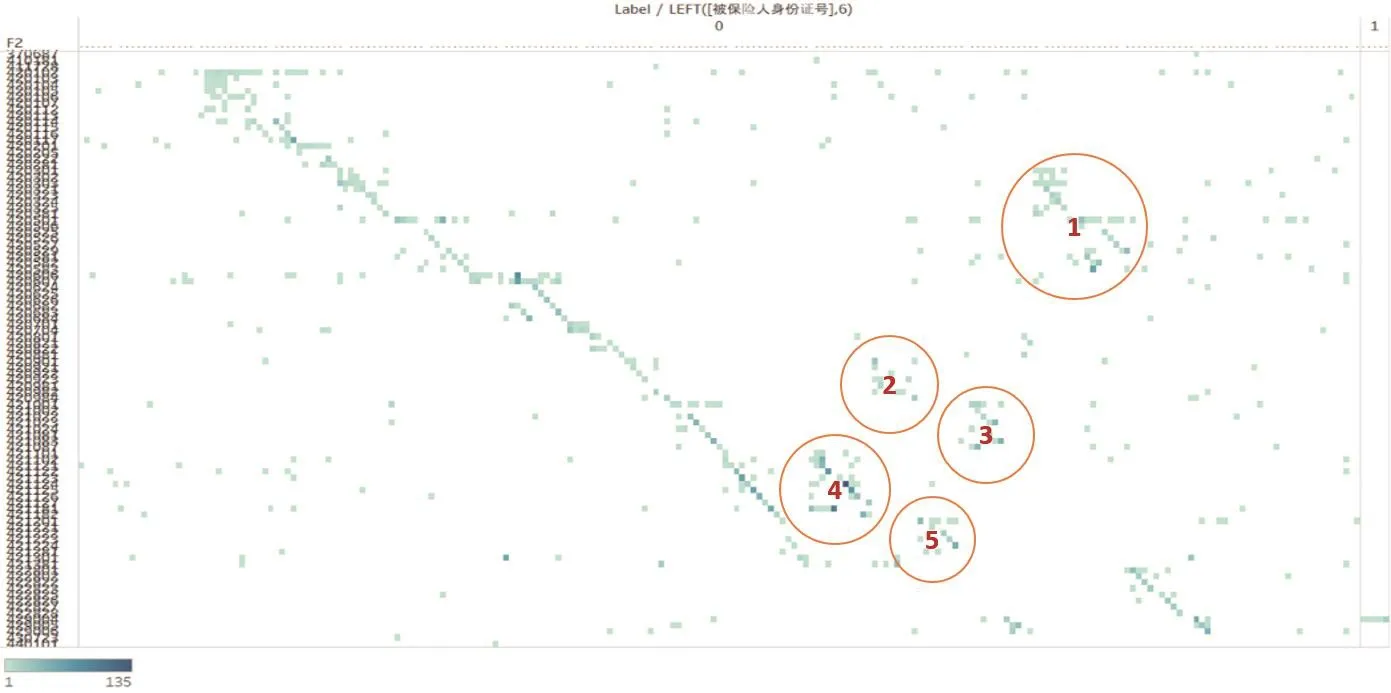
▶图5 被保人身份证所在地区与销售地点对比分析散点图
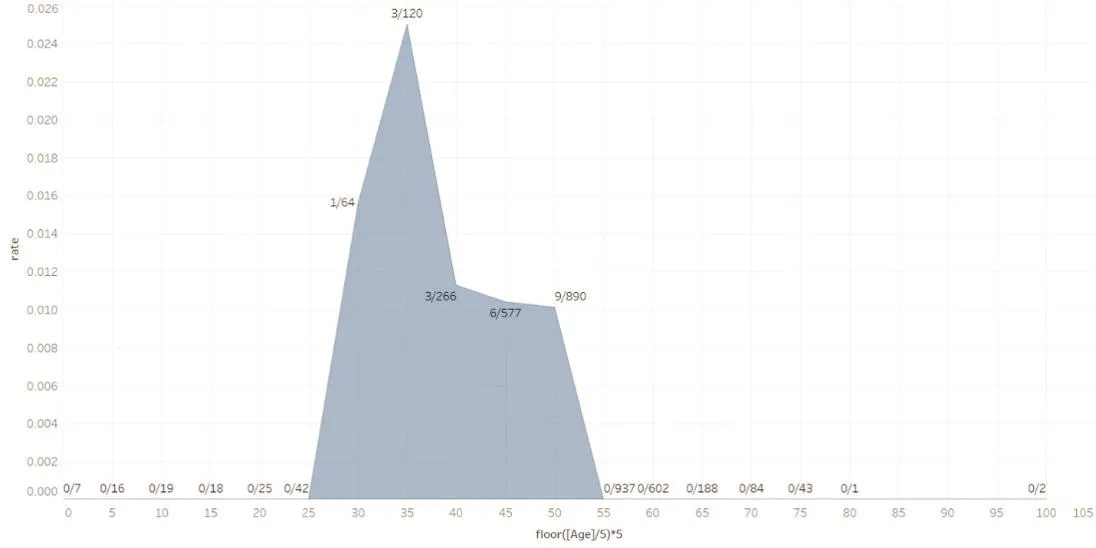
▶图6 在不同被保险人年龄段的问题赔案在待核实赔案中的件数占比
首先,运用梯度提升决策树方法对特征变量进行测算分析并得到对每一个赔案的评分,发现医院和疾病是两个具有显著影响的特征变量,对本次评分起到决定性作用,赔款总额与保费的比例、被保人身份证所在地区与销售地点是否一致、保费总额、赔款总额和被保险人年龄等特征变量均会对评分,发现医院和疾病是两个具有显著影响的特征变量,对本次评分起到决定性作用,赔款总额与保费比例、被保人身份证所在地区与销售地点是否一致、保费总额、赔款总额和被保险人年龄等特征变量均会对评分产生影响。
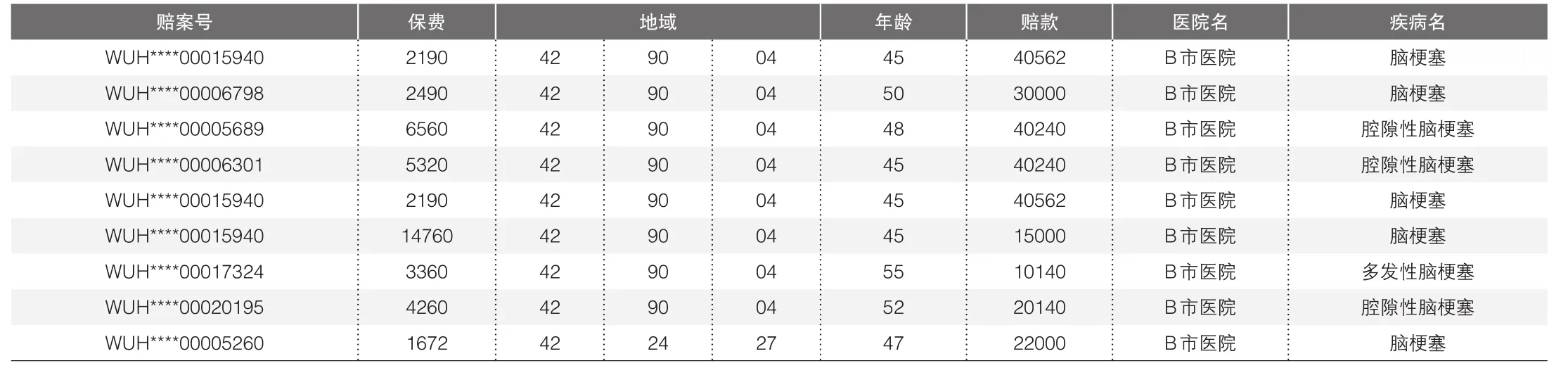
其次,根据评分对待核实赔案进行分组,评分结果相近的分在一组,在每组内通过对比问题赔案和待核实赔案的特征,分析出在待核实赔案中的疑似问题赔案。通过对比待核实赔案信息(特征)和问题赔案信息(特征)之间的相似程度,从医院、疾病、地域、保费、赔付金额等角度进行分析,发现以下赔案与问题赔案高度相似(后称此类赔案为“疑似问题赔案”)。通过对比各个赔案的评分,分析评分相近的赔案,对比赔案之间的特征,发现疑似案件:WUH****00015940、WUH****00015940、 WUH****00015940、WUH****00006798、 WUH****00017324、WUH****00005689、 WUH****00020195、WUH****00006301、WUH****0000526等上述疑似问题赔案的医院名、疾病名与问题赔案完全一致,被保险人身份证所在区域与部分问题赔案的区域相同,符合问题赔案保费金额低并且赔款总金额不高的特征;其余五个赔案与问题赔案的医院名、疾病名、所在地区等特征相似(详见图7)。
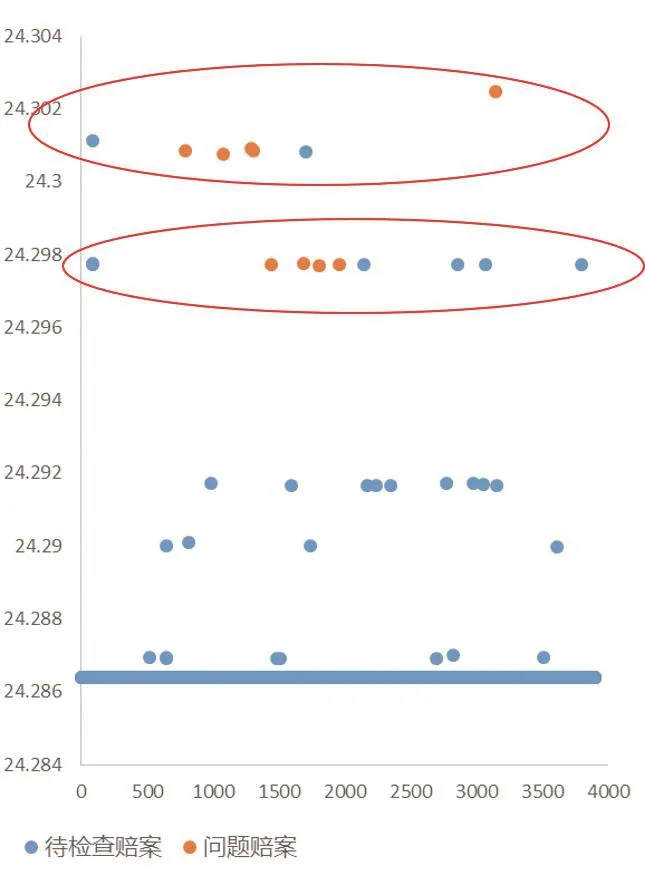
▶图7 疑似问题赔案分析结果
最后,将上述可疑赔案发送至分公司进行复勘。经核实,除赔案号WUH****00005260外,其余8件赔案均确认为欺诈案件,准确率为88.9%。
六、结语
本文探索了在已知问题赔案数据较少的情况下对人身保险领域未知欺诈风险的一种识别方法。首先运用探索性数据分析(EDA)对已知人身保险欺诈案件特征进行分析,其次运用检验梯度提升决策树(GBDT)建立大数据分析模型,通过对比待核实赔案信息(特征)和问题赔案信息(特征)之间的相似程度,从医院、疾病、地域、保费、赔付金额等角度对待核实欺诈数据进行分析,发现可疑赔案,最后针对重点可疑赔案进行复勘确认,得到了较好的识别效果。

▶表2 特征变量对筛选问题赔案的贡献度分析结果
▶表3 疑似问题赔案分析结果
