基于Voronoi-R*的隐私保护路网k 近邻查询方法∗
2019-10-26倪巍伟李灵奇刘家强
倪巍伟 , 李灵奇 , 刘家强
1(东南大学 计算机科学与工程学院,江苏 南京 211189)
2(计算机网络和信息集成教育部重点实验室(东南大学),江苏 南京 211189)
近年来,随着位置服务(location based service,简称LBS)的普及和人们对个体隐私的日益重视,保护位置隐私近邻查询得到了研究者的持续关注[1−7].路网环境保护位置隐私近邻查询以其贴近真实生活和路网约束的复杂,成为保护位置隐私查询研究的重要方向.基本思想是:通过隐匿机制,将隐藏后查询者位置及查询请求提交LBS服务器,服务器返回候选POI(point of interest)集合,供查询者从中甄选目标查询结果.从隐藏技术角度,这些方法可分为4类:位置干扰(location obstruction)、空间变换(space transformation)、空间混淆(spatial cloaking)和PIR(private information retrieval)技术.
面向路网的保护位置隐私近邻查询主要采用空间混淆技术将查询者位置泛化为混淆区域(公路子网)提交服务器处理,通过扩大搜索空间返回候选解集,实现保护查询者位置隐私的近邻查询.例如:文献[8,9]利用可信第三方服务器对查询者的真实位置进行匿名,并将匿名区域及查询请求提交服务器,服务器扩展边界节点的邻接区域查找匿名区域的k近邻,这种方法具有保护强度可调节、服务器端处理可调控的优点;文献[10]提出利用可信匿名服务器构建路网泰森图,根据路网泰森单元(network voronoi polygon,简称NVP)包含的路段数,采取不同匿名策略对用户真实位置进行匿名保护的方法;文献[11]采用PIR技术,提出了基于全局路网泰森图和KD-Tree的保护位置隐私近邻查询方法.基于 PIR技术可以提供较高的隐私保护强度,但服务器端全局泰森图和KD-Tree索引构建过程复杂,存储消耗大,且k近邻查询时客户端与服务器端需要多轮迭代.服务器端主要采用增量式路网扩张法(incremental network expansion,简称INE)和基于泰森图的近邻查找法实现路网近邻查询.增量式路网扩张法对查询者位置所在路网区域进行广度优先搜索,直到区域中近邻POI的数目满足查询需求;基于泰森图的近邻查询法利用路网泰森图查找最近邻,根据泰森多边形(Voronoi polygon)的邻接多边形查找其k近邻.搜索空间的扩大和复杂路网结构限制,加剧了LBS服务器端查询开销.已有研究大都通过在服务器端构建POI集合关于全局路网的索引结构,提高服务器端处理效率.
已有的基于空间混淆的保护位置隐私路网近邻查询方法主要存在以下问题.
(1) 可信第三方服务器容易成为系统性能和隐私安全的瓶颈.
(2) 路网规模庞大,使得服务器端全局路网索引规模较大,隐私保护需求导致服务器端近邻搜索范围扩大,查找路网索引的代价激增.
(3) 查询目标POI在路网的位置分布不均衡,服务器端对全局路网索引的无差异使用,导致低频访问区域对应的索引结构利用率低,这部分索引结构增加了全局索引的规模,降低了路网高频访问区域查询的性能.
针对上述问题,提出了基于Voronoi-R*索引的保护位置隐私路网k近邻查询方法VRS-PNN(Voronoi-R*based privacy-preservingknearest neighbor query over road networks),主要贡献如下.
(1) 提出了查询客户端与LBS服务器间两次交互的路网隐私保护近邻查询机制,实现不依赖可信第三方的路网位置隐私保护,避免依赖可信第三方导致的隐私泄露威胁.
(2) 提出了基于路网区域查询请求频度的分段式查询处理策略,为频繁请求区域设计了Vor-R*树局部路网索引结构,并定制了查询策略.在降低服务器端索引存储规模的同时,提升了索引利用率,提高了查询处理效率.
(3) 实现了所提保护位置隐私路网近邻查询机制,并设计了实验验证算法的有效性和性能.
本文第1节描述问题并介绍相关概念.第2节介绍VRS-PNN方法的架构和流程.第3节介绍VRS-PNN方法的查询客户端处理方法.第4节介绍VRS-PNN方法服务器端查询处理过程.第5节对VRS-PNN方法的性能进行分析.第6节进行实验分析.最后总结全文,并展望下一步工作.
1 问题描述及相关概念
1.1 问题描述
路网环境保护位置隐私近邻查询的关键问题表现在两个方面:查询者/发起者位置隐私保护效果以及隐私保护近邻查询处理的效率.
目前,已有研究主要采用空间混淆技术,通过可信匿名服务器对查询用户的位置进行匿名,并将匿名区域发送LBS服务器,可信匿名服务器接收LBS服务器返回的候选集,并将结果反馈查询者.对可信匿名服务器的依赖,源于查询客户端不掌握路网信息,即便客户端获取LBS服务器反馈的包含真实查询目标的候选POI集合,也无法采用非路网环境直接计算查询者位置到各候选POI直线距离的方法甄别目标查询结果.然而可信匿名服务器难以寻找,且匿名服务器容易成为查询性能和隐私安全瓶颈.
在近邻查询处理方面,路网结构的复杂性和位置隐私保护需求使得LBS服务器端处理代价较大,在服务器端构造索引完成近邻查询是常用的方法,已有研究主要采用构造全局索引的方法,LBS服务器端预先计算并存储整个路网区域POI的索引,LBS服务器接收到查询请求时,通过查找索引完成查询.然而整个路网区域POI索引规模较大,且索引的构造未考虑查询目标在路网的实际分布,索引利用率低,导致LBS服务器端近邻查询效率方面的缺陷.
1.2 算法思想
针对前述路网环境位置隐私保护与查询处理依赖可信第三方存在的缺陷,考虑设计空间混淆以及查询处理与反馈机制,实现无需可信第三方介入的位置隐私保护和路网k近邻查询.针对LBS服务器端对全局索引结构无差异利用导致的查询处理效率低的问题,将服务器端全局路网划分为一组基本单元区域,设计区域局部索引结构,实现LBS服务器端兼顾区域查询频度的分段式查询处理,提高查询处理效率.
基本思路:查询客户端向LBS服务器发送区域路网查询请求,根据LBS服务器返回结果对查询者所在路段的节点进行空间混淆,以保护查询者位置隐私.具体方法是将查询者所在路段的节点作为目标对象进行l-路段多样性匿名[12],生成包含查询者所在路段两端节点的一组路段节点序列.
LBS服务器根据查询客户端提交的路段节点序列中节点所在区域选择不同的查询策略:对频繁请求的路网区域,设计Vor-R*索引结构,实现基于Vor-R*局部索引的快速近邻查找;对非频繁请求区域,采用常规INE方法查找近邻,解决全局索引规模大以及索引利用率低带来的查询效率低的缺陷.
1.3 相关概念
本文采用超图路网划分法[13]将LBS服务器端的路网区域划分为若干个基本单元.每个基本单元设置命中率,命中率随查询者对基本单元的请求次数更新.叙述方便起见,引入下述定义.
定义1(基本单元).服务器端采用超图路网划分法将路网划分为n个单元区域,即n个基本单元,单元区域内的所有POI构成该基本单元的POI集合.
定义2(基本单元命中次数).若查询者提交LBS服务器的匿名路网区域落在某基本单元区域内,该基本单元的命中次数加1.
定义3(基本单元命中率).给定时间内,基本单元的命中率为该段时间基本单元的命中次数与LBS服务器接受查询请求总次数的比值.
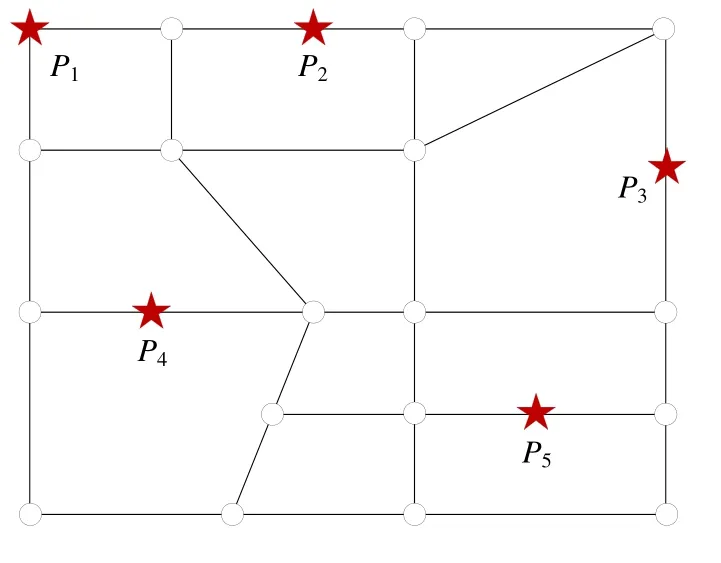
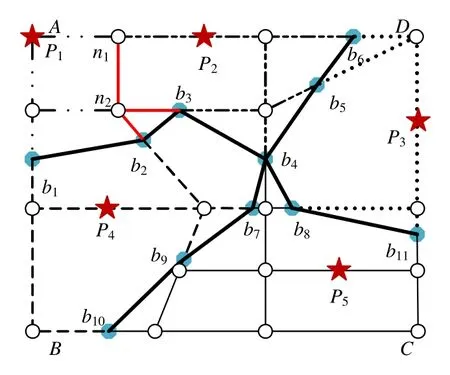
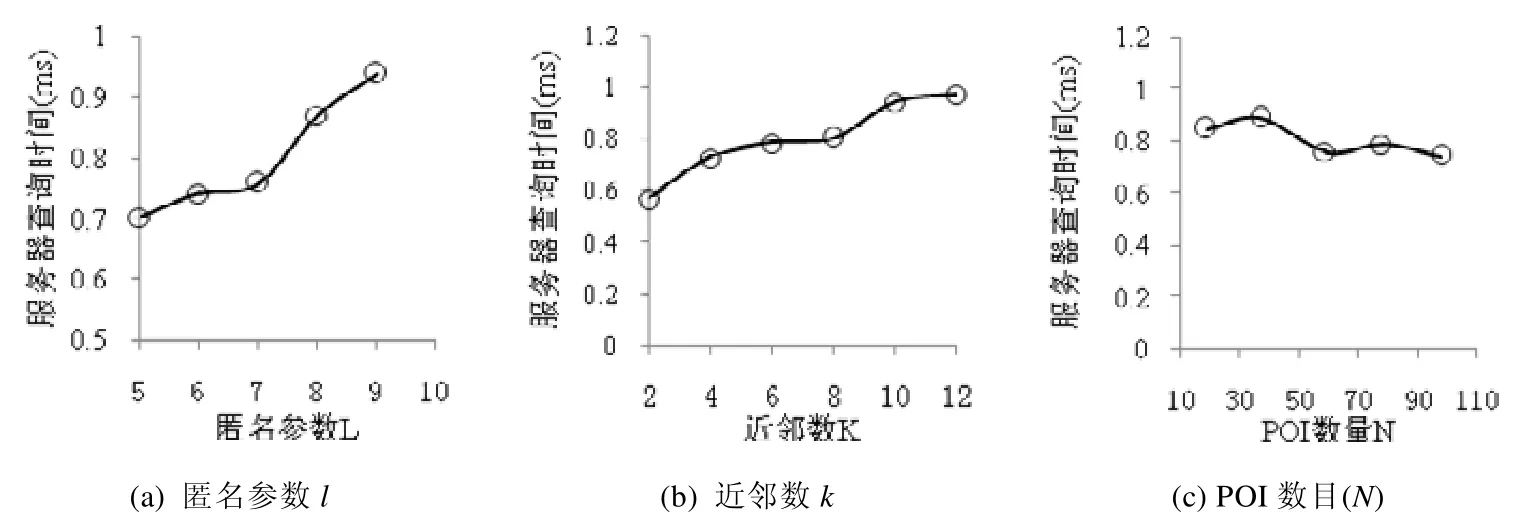
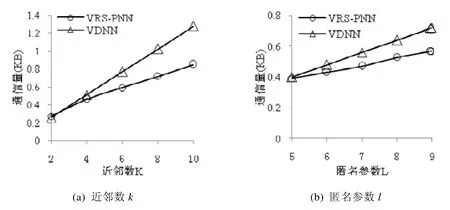
定义 4(路网泰森单元)[14].某基本单元的POI集合为{P1,P2,…,Pm},Pi的路网Voronoi单元的定义如下:NVP(Pi)={q|dist(q,Pi) 定义5(基本单元的路网泰森单元集(networkvoronoidiagram,简称NVD))[14].某基本单元的POI集合为{P1,P2,…,Pm},该基本单元的路网泰森单元集 定义6(邻接NVP[14]).对P1,P2两个POI,若NVP(P1)与NVP(P2)存在相同的边界点,则称NVP(P1)与NVP(P2)邻接,P1与P2互为1近邻. VRS-PNN算法查询处理流程如图1所示,步骤如下. (1) 查询者向LBS服务器发送包含其位置的匿名区域及参数m(LBS需返回的最小路段数); (2) LBS服务器查找匿名区域所在的基本单元(若匿名区域与多个基本单元存在交集,选取与匿名区域重叠面积最大的基本单元),将该基本单元的命中次数加1(匿名区域通常远小于基本单元,即便匿名区域覆盖超过一个基本单元,也可以进行类似处理,更新相关基本单元命中数); (3) LBS服务器查找匿名区域包含的所有路段,生成并返回路段集合Segs(如果路段数小于m,沿路网边界节点扩展,直到路段数达到m); (4) 查询者从Segs中选取l个路段的节点Pi(i=1,2,…,l),使得查询者所在路段满足l-路段多样性[12](保证查询者所在路段被推断的可能性低于1/l),将查询请求序列Q({P1,P2,…,Pl},k)提交LBS服务器; (5) LBS服务器接收查询序列Q,分析Q中路段节点所在的基本单元,对频繁请求单元,利用预先构建的Vor-R*索引,查询计算路段节点的近邻POI集合;否则,使用路网增量扩张查找方法查询相应路段节点的近邻POI集合; (6) 将Q的近邻查询结果返回查询客户端; (7) 客户端根据查询者真实位置筛选准确路网k近邻. Fig.1 Querying process图1 处理流程 不依赖可信匿名服务器进行查询者位置隐私保护的难点在于查询客户端不掌握查询者所在区域的路网分布信息,而路网信息存储在LBS服务器端,因此查询者需要从服务器端获取局部路网信息,以便完成自身位置的保护. 采取查询客户端向LBS服务器提交两次查询请求的方式完成保护位置隐私近邻查询. · 第1阶段:客户端向LBS服务器提交匿名区域{AR,m},获取局部路网信息,其中,AR为客户端生成的查询者所在匿名区域,m为路段数,LBS服务器查询AR覆盖的路段.若匿名区域AR内路段数不小于m,将AR内的路段信息返回客户端;否则,从匿名区域的边界节点进行路网扩张查询直到获取路段数大于m,将扩充后的路段信息返回查询客户端. · 第2阶段:客户端根据LBS服务器反馈的路段生成包含查询者所在路段节点,且满足l-路段多样性的匿名查询序列,并将查询序列及近邻数k提交LBS服务器. 第1阶段:随机生成的匿名区域如图2所示,Pu为用户真实位置,通过两个随机数r1,r2确定正方形区域的左下端点P1和右上端点P2,正方形匿名区域的大小需满足查询者对位置匿名强度的要求(通过参数R设置). Fig.2 Anonymized area at client side图2 客户端匿名区域 第2阶段:客户端收到LBS服务器返回的路段{seg1,seg2,…segm},将其真实位置所在路段的两个端点加入待查询序列Query中,再随机选取l-2个路段节点加入Query中,生成查询者所在路段满足l-路段多样性的匿名查询序列,具体见算法1. 算法1.用户位置隐匿算法. 输入:路段信息{seg1,seg2,…segm},l; 输出:查询序列Query{P1,P2,…,Pl}. 图3为查询客户端根据服务器返回的区域路网信息生成的查询序列示意,矩形ABCD为客户端向服务器端发送的匿名区域,Pu为查询者真实位置,{ni|i=1,…,7}为客户端生成的查询序列,n1和n2为Pu所在路段的两个端点,ni(3≤i≤7)为客户端在区域路网中随机选取的节点. Fig.3 Node sequence illustration with l-diversity (l=7)图3 l-路段多样性节点序列生成示意图(l=7) 性质1.查询者位置Pu所在路段节点n1和n2包含于向LBS服务器发送的匿名查询序列中,则LBS服务器返回的候选结果集S一定包含Pu的路网k近邻POI. 证明:设n1的路网k近邻POI集为M1,n2的路网k近邻POI集为M2;将Pu的路网k近邻POI集合分为两个子集S1和S2,S1为途经节点n1的路网近邻POI集,S2为途经n2的路网近邻POI集.假设存在Qk,Qk为Pu的第k近邻,满足Qk∉M1且Qk∉M2.若Qk∈S1,设为M1∪M2中离Pu第k近的POI,则有 查询客户端获取LBS服务器返回的候选结果集后,只需将其所在路段节点的k近邻集合作为候选结果集进行筛选计算.由于客户端缺乏路网信息,无法计算其真实位置到各候选POI的路网距离,因此LBS服务器返回的查询序列Q中添加每个查询位置到其各个近邻POI路径上的第一个路段节点信息,以便客户端计算查询者位置距离候选POI的路网距离(具体见第4.3节),客户端根据LBS服务器返回的信息计算查询者的真实k近邻POI.客户端筛选查询结果的流程见算法2. 算法2.k近邻结果集筛选算法. 输入:用户位置Pu所在路段的两个节点n1和n2的kNN结果集M1和M2; 输出:用户真实位置的k近邻结果集RS. 保护位置隐私路网近邻查询中,LBS服务器处理代价大的重要原因是保护查询者位置隐私导致查询范围扩大.考虑根据各基本单元的命中率,对不同的基本单元采取不同的查询策略:对命中率较高的基本单元,构建基本单元泰森图,并基于R*树[15]构建基本单元内POI关于泰森图的索引结构Vor-R*.由于R*树在插入节点时采取组合策略,使用多个参数作为选择标准,而R树在插入节点时仅考虑面积参数;在分割节点的过程中,R*树采取拓扑分割策略基于周长选择分割轴,最小化空间重叠大小;因此,R*树的空间重叠度相比于R树更小,查询时效率优于R树,可以有效提升频繁查询区域的处理效率.对命中率较低的基本单元,采用INE方法获取查询序列的k近邻. 以基本单元内的所有POI为对象生成基本单元的路网Voronoi图,并对基本单元边界处的NVP予以标记,以图4的路网基本单元为例,{P1,P2,P3,P4,P5}为该单元的POI集合.生成的NVD如图5所示,与计算欧氏距离产生的Voronoi图不同,路网中生成的NVP边界图形存在凹多边形. Fig.4 Road network图4 路网图 Fig.5 Illustration of NVD图5 路网泰森单元集示意 NVP由边界点所围成的区域构成,表1为NVP(Pi)的边界点及邻接POI信息.相邻的两个NVP可能存在重复区域,如图5中的P1和P2:P1的NVP边界为{n1,n2,b3,b2,b1,A},P2的NVP的边界为{n1,n2,b2,b3,b4,b5,b6},两者存在交集区域△b2n2b3,当查询序列Q中的节点位于n2b2或者n2b3时,存在两个最近邻位置P1和P2. Table 1 POI information表1 POI信息 LBS服务器对各个基本单元内的POI进行编号,将编号及其位置信息存储到POI表中(见表2).在构建基本单元NVD的过程中,将所有NVP信息保存到NVD表中(见表3),表中存储POI编号、NVP(Pi)边界点、NVP(Pi)内部路段节点、邻接POI信息,每个POI的NVP边界点按顺时针顺序存储. Table 2 POI table表2 POI表 Table 3 NVD table表3 NVD表 以基本单元内POI的NVP的最小外接矩形为叶子节点构建R*树.Vor-R*树的构造过程如下. (1) 构建基本单元内所有POI的路网泰森图; (2) 创建空R*树; (3) 对所有的NVP,执行下列操作. ①在R*树中查找待插入对象NVPi的合适的叶子节点Leaf; ② 如果叶子节点Leaf存在足够空间,将NVPi添加至节点Leaf,转步骤③;否则分裂此节点,并对Leaf和分裂后的新节点执行操作步骤③、步骤④; ③根据节点向上调整树的结构; ④ 若根节点分裂,插入新的根节点,分裂后的两个节点分别为树的孩子节点. 对图6所示区域划分,Vor-R*索引树结构如图7所示,中间节点存储所有子节点矩形的轮廓最小外接矩形,叶子节点存储最小外接矩形内部NVP对应的POI编号,并指向NVD表POI编号所在位置.由于R*树的节点之间区域重叠区域较小,服务器端查询路段节点最近邻时可以避免搜索多余的子树,能够快速获得路段节点所在NVP的边界节点信息,根据这些信息,可以计算判定目标位置的准确所在NVP. Fig.6 Region partition illustration of R* tree图6 路网泰森图R*区域划分示意图 Fig.7 Structure illustration of index Vor-R*图7 Vor-R*索引结构图 VRS-PNN算法采用LBS服务器,根据查询请求所在基本单元命中率进行个性化查找的分段处理策略,因此需要动态维护各基本单元的命中率,以便阶段性进行基本单元局部Vor-R*索引的更新. 假设某时间段内,LBS服务器接收查询请求总数为Amt,启动索引更新的查询请求数阈值为A0,频繁请求基本单元的命中率阈值为β.若基本单元的命中率不小于β,该基本单元被标注为频繁请求单元;否则,该基本单元为非频繁请求单元,为每个基本单元设置信号量flag,标注基本单元是否已建立Vor-R*索引. LBS服务器端索引构建策略如下. (1) LBS服务器接收客户端发送的匿名区域AR,并查找AR所在基本单元Reg0(或查找与AR重叠面积最大的基本单元),将Reg0的命中次数加1,同时,Amt=Amt+1; (2) 若Amt (3) 将Amt和所有基本单元的命中次数均设为0,返回步骤(1). LBS服务器阶段性评估最近阶段客户端查询请求涉及基本单元的分布频度,创建或删除相应基本单元的Vor-R*索引,实现路网区域访问频度分布与查询处理策略的动态匹配.同时,通过合理的设置基本单元的Vor-R*索引结构删除策略,提高服务器端索引利用率,降低索引存储与维护的代价. 服务器端接收到客户端的查询序列后,分别查询l个路段节点的最近邻.对每个路段节点,若其位于非频繁请求基本单元,使用INE方法查询其近邻;否则,基于Vor-R*树查询其近邻. 本节主要讨论落在频繁请求基本单元中的路段节点的近邻查询过程.查询Vor-R*树可以得到路段节点所在的NVP最小外接矩形,由于NVP的最小外接矩形存在重叠区域,所以搜索树结构可能会得到多个最近邻POI,而每个POI的NVP的边界点构成(凹/凸)多边形,将NVP内部的路段封装起来,若路段节点在多边形内部,则此多边形内部的POI为其最近邻.主要流程见算法3. 算法3.最近邻查询算法. 输入:路段节点位置Pu(x,y),Vor-R*树; 输出:最近邻POI结果集R. 利用一个点的k近邻一定存在于其k−1近邻的邻接POI集合的性质[16],计算路段节点的k近邻.LBS服务器查找Vor-R*树获得查询序列中路段节点最近邻后,根据上述性质计算路段节点的候选k近邻集合.考虑路段节点的k近邻可能位于不同基本单元.为了计算结果的准确性,在计算k近邻候选集时增加对NVP是否位于基本单元边界的判定.计算路段节点的k近邻候选集流程如下. (1) 利用Vor-R*查询路段节点P的最近邻集合Si(i=1),将Si(i=1)添加至候选集temp_list中; (2) 对Si中所有的POI,执行步骤(3)、步骤(4); (3) 若POI所在NVP已被标记为边界NVP,使用INE方法向另一个基本单元扩张查找此POI的(k−i)近邻集合S′,并保存P到其近邻POI的最短路径距离,将S′添加至候选集temp_list; (4) 若POI所在的NVP未被标记为边界NVP,则将此POI的邻接POI(已存在于temp_list的POI不计入内)分别添加至temp_list和Si+1中; (5) 如果i 在筛选候选集、计算路段节点准确k近邻的过程中,需要计算路段节点到各个候选POI的最短路径距离,然后选取最近的k个POI作为路段节点的准确k近邻.在计算路段节点到候选POI的距离时,LBS服务器预计算NVP边界节点间的距离,以降低路段节点到POI的距离计算量. 在查询最近邻POI的基础上,进一步查找某个路段节点k近邻POI的主要流程见算法4. 算法4.KNN查询算法. 输入:路段节点Pu(x,y); 输出:k近邻POI结果集RS. 服务器向客户端返回l×k个POI位置信息,而客户端提交的l个位置在同一匿名区域,它们的k近邻可能存在交集.为了避免重复的近邻POI信息传输,使用第4.1节所定义的POI表结构.服务器端返回结果时,返回各目标位置近邻的Id序列以及Id序列对应的POI信息;同时,服务器端在计算路段节点的k近邻POI时,保存节点到各近邻POI的最短路径距离以及到近邻POI最短路径所经过的第1个路段节点(便于客户端计算准确近邻),与k近邻POI查询结果一起反馈给用户.图8为某基本单元的部分路网结构,n0为客户端所提交的某个路段节点,A为n0的一个近邻POI,n0到A的最短路径为n0n1n2A,则n1为n0到路网近邻点A路经的第1个节点. Fig.8 Road distance illustration between query location and its nearer POI图8 查询点与近邻POI的路网最短路径 表4和表5为服务器反馈查询客户端的查询结果.表4中,每个路段节点的路网k近邻序列由k个三元组组成,元素分别为近邻POI、MinDist为路段节点到此POI的最短路径距离、FirstNode为路段节点到此POI的最短路径中经过的第1个路段节点.表5为表4中各POI和路段节点与实际位置坐标的映射. Table 4 k nearest neighbors of l road nodes in Q (l=4,k=3)表4 Q 中l 个路段节点的路网k 近邻集(l=4,k=3) Table 5 Location of POIs and road nodes (l=4,k=3)表5 POI和路段节点的坐标映射表(l=4,k=3) 本节从LBS服务器端和查询客户端计算复杂度的角度,分析VRS-PNN方法的效率.对LBS服务器端以单个路段节点为查询对象,分别分析频繁请求基本单元和非频繁请求基本单元的处理效率. 对于频繁请求的基本单元,因其索引Vor-R*是预构建好的,每次查询只需查找索引,基于Vor-R*查询路网最近邻的时间复杂度为O(logn),n为基本单元内的POI数目.查询路网k近邻的计算量主要消耗在计算路段端点到候选POI的最短路径距离,如第4.3节所述,通过在LBS服务器预计算NVP各边界节点之间的距离,计算路段节点到其候选POI的最短距离时只需进行简单的求和、比较计算.考虑路网实际情况,每个NVP的边界节点个数为常量,所以计算路段节点到候选POI最短路径距离的时间复杂度为O(C).文献[16]提出,每个NVP的邻接NVP的数目平均不超过6.根据此性质,路段端点的k近邻候选结果集平均大小为6k.本文采用快速排序计算准确路网k近邻,时间复杂度为O(6klogk).综上,计算每个路段端点路网k近邻的复杂度为O(logn+kC+6klogk),即O(logn+klogk).上述过程为路段节点的真实k近邻全都位于路段节点所在基本单元的情形;若路段节点的部分真实k近邻位于其他基本单元,最坏情况为路段节点所在的NVP为边界NVP,此时的计算量包括查询一次Vor-R*树和利用INE方法查找单个路段节点k近邻. 对非频繁请求基本单元,采用INE方法查询k近邻的时间受POI分布密集程度影响[17](用|N|/|S|描述分布密度,|N|为基本单元内POI的个数,|S|对应基本单元内路段数).文献[18]验证了POI分布越密集,INE策略越高效:若|N|/|S|≥1,查询复杂度为O(k);否则,INE方法效率较低,查询复杂度为O(k*|S|/|N|). 上述复杂度分析为单个路段节点的近邻查询复杂度,VRS-PNN服务器端需要对查询序列进行处理,总体时间复杂度受各个路段节点所处基本单元影响.假设频繁请求基本单元的路段节点近邻查询复杂度为O1,非频繁请求单元的路段节点近邻查询复杂度为O2,处理查询序列的最坏时间复杂度为l*max(O1,O2). 客户端计算主要集中在从候选集筛选准确路网k近邻的过程,由于客户端接收查询序列Q的k近邻候选POI集的同时,也获取Q中每个路段节点到其所有k近邻POI的最短路径经过的第一个路段节点,根据算法2,计算时间主要消耗在快速排序过程,时间复杂度为O(klogk).整个查询过程,查询客户端和LBS服务器间发生两轮通信.首先,客户端向LBS服务器发送区域路网信息请求过程中,通信代价为O(1),LBS服务器向查询客户端反馈路网信息的通信消耗为O(m)(m为路段数量参数);随后,查询客户端向LBS服务器发送查询序列的通信代价为O(l)(l为查询序列大小),LBS服务器将候选结果返回给客户端的通信代价为O(lk).综上,VRS-PNN方法中查询客户端和LBS服务器间的总通信代价为O(lk+m). 本节对VRS-PNN的效率进行实验分析,实验数据采用美国加利福尼亚的路网数据(路段节点21 048个,覆盖21 689条道路,http://www.cs.utah.edu/~lifeifei/SpatialDataset.htm),选取包括2 024个路段节点、5 266条道路的路网子区域(内含1 000个POI).实验环境配置如下:Windows7系统,3.4GHz Intel Core i7处理器,内存容量8GB. 首先,设计实验对本文提出的Vor-R*树索引结构与已有基于路网泰森图的R树索引的查询性能进行对比分析,构建基于基本单元的Vor-R*树索引与Vor-R树索引,分别基于两种索引查询目标POI的最近邻,对其进行性能比较.由于R*树相比于R树的空间覆盖和重叠度均比较小,其查询效率更高.如图9所示,伴随着基本单元POI数目的变化,Vor-R*树索引查询性能始终优于Vor-R树索引. Fig.9 Index effectiveness comparsion between Vor-R* and Vor-R图9 Vor-R*与Vor-R索引性能比较图 进一步分析主要参数对VRS-PNN方法性能的影响.图10为VRS-PNN方法中LBS服务器处理效率随参数l、近邻参数k和POI数目N的变化趋势.由图可见,服务器端处理代价随参数l的增长几近呈线性增长,与k也呈线性关系. Fig.10 Server-side querying cost with increasing l,k and number of POI图10 参数l,k,POI数目对服务器端处理效率的影响 图11所示为客户端与服务器间的通信代价受参数l和k影响的变化曲线.由图11可见,其通信代价随l和k缓慢增长. 将VRS-PNN与文献[19]基于路网泰森图的保护位置隐私近邻查询方法VDNN进行性能对比,文献[19]同样采用区域混淆方法,将匿名区域与路网交点的近邻查询结果返回给客户端供其筛选最近邻结果.对两种方法分别顺次串行发起相同的10组查询,取处理时间的均值进行对比,图12为VRS-PNN方法与VDNN方法通信量对比分析图,参数l在VDNN方法中等同于匿名区域与路网中路段的交点数目.不同于VDNN直接返回所有交点的k近邻,VRS-PNN方法生成候选POI集合过程合并查询序列中路段节点的近邻POI,有效规避了重复POI传输,VRS-PNN方法的通信代价低于VDNN. Fig.11 Communication cost with increasing l and k图11 参数l,k 对通信代价的影响 Fig.12 Commubication cost comparing with VDNN algorithm图12 VRS-PNN与VDNN方法的通信量比较 图13为VRS-PNN与VDNN方法服务器端k近邻查找过程性能对比.由于Vor-R*树查询性能优于Vor-R树,且VRS-PNN方法仅对频繁查询区域构建局部Vor-R*索引,而VDNN方法在服务器端构建全局路网R树索引,因而VRS-PNN方法相较VDNN方法能够充分降低频繁检索区域的路网近邻POI查询消耗.由图易见,VRS-PNN在服务器端查询性能优于VDNN方法. Fig.13 Querying workload comparing with VDNN algorithm图13 VRS-PNN与VDNN方法的服务器查询性能比较 对LBS服务器端分段式查询处理策略的效果进行分析,采用客户端向服务器端同时随机发送100次不同位置的近邻查询的方式,对比VRS-PNN方法和VDNN方法的服务器端处理效率.VRS-PNN方法的频繁请求阈值设为0.6,统计得出这些查询共涉及服务器端20个基本单元,实验结果如图14所示,VRS-PNN方法的服务器端查询处理效率显著优于VDNN方法.原因在于:LBS服务器接收到大量查询时,不同于VDNN对所有查询请求基于全局路网索引的无差异检索处理,VRS-PNN方法区分频繁路网区域和非频繁路网区域,并动态维持各个频繁基本单元的Vor-R*索引,对涉及频繁基本单元的大量查询,利用各基本单元的局部Vor-R*索引进行查找,避免了对大量查询无差别采用基于全局索引的近邻查找导致的查询代价激增. Fig.14 Server side batch query performance comparison between VRS-PNN and VDNN图14 VRS-PNN方法与VDNN方法服务器端批量查询效率对比 最后,对VRS-PNN方法的客户端处理性能进行实验分析.VRS-PNN方法客户端主要开销是对候选结果集的筛选,图15为客户端处理效率随参数k、POI数目N的变化趋势.由图可知:客户端处理时间随近邻数k的增长缓慢上升,维持在数十微秒级别,且处理时间受POI数目N的影响不显著.所提方法适用于目前手机、导航仪等客户端设备. Fig.15 Client-site cost with increasing k and the number of POIs图15 参数k、POI数目对客户端处理效率的影响 本文提出了基于局部索引机制的保护位置隐私路网k近邻查询方法VRS-PNN,查询客户端通过与LBS服务器的一轮通信,获取局部路网信息,生成查询位置所在路段满足l-路段多样性的匿名查询序列,并将匿名查询序列提交LBS服务器,从而避免保护位置隐私查询对可信第三方服务器的依赖.在LBS服务器端,提出基于路网基本单元划分的分段式近邻查询处理策略,对频繁查询请求路网基本单元,构建基于路网泰森多边形和R*树的局部Vor-R*索引结构,实现基于索引的快速查找.对非频繁请求路网基本单元,采用常规路网扩张查询处理.有效降低了索引存储规模和基于全局索引进行无差异近邻查询的访问代价,在保证查询结果正确的同时,提高了LBS服务器端k近邻查询处理效率.下一步,将对所提索引策略及查询处理方法在保护位置隐私连续路网近邻查询中的应用进行研究.2 VRS-PNN算法处理流程

3 VRS-PNN算法客户端处理方法



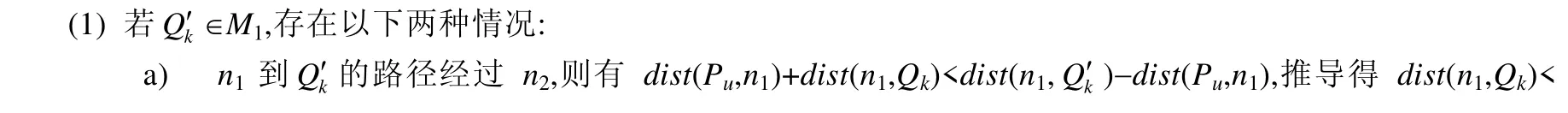


4 VRS-PNN服务器端处理方法
4.1 Vor-R*索引结构





4.2 服务器端局部Vor-R*索引更新
4.3 基于查询序列的近邻查询






5 算法性能分析
6 实验分析





7 结 论
