基于空谱融合特征主动学习的高光谱图像分类
2019-10-26刘丽芹沈霞宏史振威
王 琰,刘丽芹,沈霞宏,侯 俊,张 宁,史振威
(1. 上海航天电子技术研究所,上海 201109; 2. 北京航空航天大学 宇航学院,北京 100191)
0 引言
随着成像技术的发展,机载或星载传感器可以获得越来越高的光谱分辨率,高光谱数据以三维形式存储,具有光谱响应范围广、波段宽度窄、图谱合一等特点。高光谱分类的内涵是对每个像素所代表的地物类别进行区分,近年来,我国已成功发射多颗高光谱分辨率的遥感卫星,高光谱图像的分类已经在环境监测、精确农业、智慧城市和信息国防方面得到广泛的应用。尤其是高分五号卫星于2018年5月9日发射成功,更是对提高我国高光谱遥感数据自给率,推动高光谱遥感数据应用有重要作用。
很多基于传统机器学习的算法被应用于高光谱分类,例如支持向量机(support vector machine, SVM)[1]、线性邻域传播(linear neighborhood propagation, LNP)[2]、随机森林(random forest)[3]、极限学习机(extreme learning machine, ELM)[4]和基于稀疏表达的分类(sparse representation-based classifier, SRC)[5]方法,另外还有局部二值模式(local binary pattern, LBP)[6-7]特征提取、Gabor滤波[8]和滚动引导滤波(hierarchical guidance filtering, HGF)[9]等空间域方法。近年来,深度学习方法在高光谱分类领域得到了广泛应用,最早应用于高光谱分类的深度学习方法是2014年CHEN提出的栈式自动编码器(stacked auto-encoders, SAE)[10],之后卷积神经网络(convolutional neural network, CNN)[11-12]被广泛地用于高光谱分类问题。随着各种深度神经网络的提出,学者们逐渐将它们应用到高光谱分类中,例如CHEN[13]应用深度置信网络(deep belief network, DBN)实现高光谱分类,LI[14]提出了应用深度森林(deep forest)解决高光谱分类问题,ZHONG[15]应用残差网络(deep residual networks, DRN)来解决高光谱图像的分类,MOU)[16]和ZHU[17]分别提出循环神经网络(recurrent neural network, RNN和生成对抗网络(generative adversarial networks, GAN)用于高光谱分类问题。
以上提出的深度学习方法,其应用于高光谱分类的本质都是人为地对每个需要分类的像素点构建一组数据作为特征输入,其实际上还是应用深度网络对浅层特征提取深层表达的过程,因此本文选用像素级分割网络——全卷积网络(fully conventional networks, FCN)[18]直接对构造的三通道图像提取空间特征,再将其与光谱特征结合进行分类。
由于人工标注高光谱样本的成本高,标注困难,造成已知标签的高光谱像素数目是有限的,因此,如何用较少量的样本得到较高的分类精度成为一项亟待解决的问题。主动学习可以充分挖掘数据之间的关系,寻找最具代表性的样本用作训练。因此,近年来也有一系列主动学习算法被应用于高光谱分类[19-20],这些方法取得了一定的效果,但也存在一定的只针对特定问题特定算法的局限性。本文提出一种新的主动学习方法选择训练样本,适应高光谱分类任务,充分保证样本的代表性,使应用一定数目的样本可以获得更高的分类正确率。
综上所述,本文提出了一种基于空谱融合特征主动学习的高光谱图像分类算法,通过构造三通道图像,利用全卷积网络提取空间特征,将其与光谱特征相结合,利用主动学习的算法选择训练样本,送入分类器进行训练,并得到分类结果。将高光谱图像构造成更适用于自然图像上训练好的模型的三通道图像,可以更加充分地挖掘高光谱图像中的光谱信息和空间邻域信息,使特征具备更好的表达能力。通过引入主动学习算法,可以选取更有用的训练样本送入分类器训练,从而达到在少量样本下更好的分类效果。算法流程如图1所示。
1 三通道图像构建与空间特征提取
由于高光谱数据量有限,不能用于对全卷积网络的训练,所以我们采用在自然图像上训练好的模型对高光谱图像提取空间特征。
由于自然图像为RGB三波段图像,因此需要从高光谱数据中提取对应的三波段图像,常用的将高光谱图像构造成三波段图像的方式通常是采用主成分分析(principal component analysis, PCA)方法,但考虑到已有模型是基于RGB三个波段的自然图像训练而成,因此其对于RGB对应波段的图像颜色和边缘更敏感,因此需要构造更接近于自然图像的RGB波段图像。
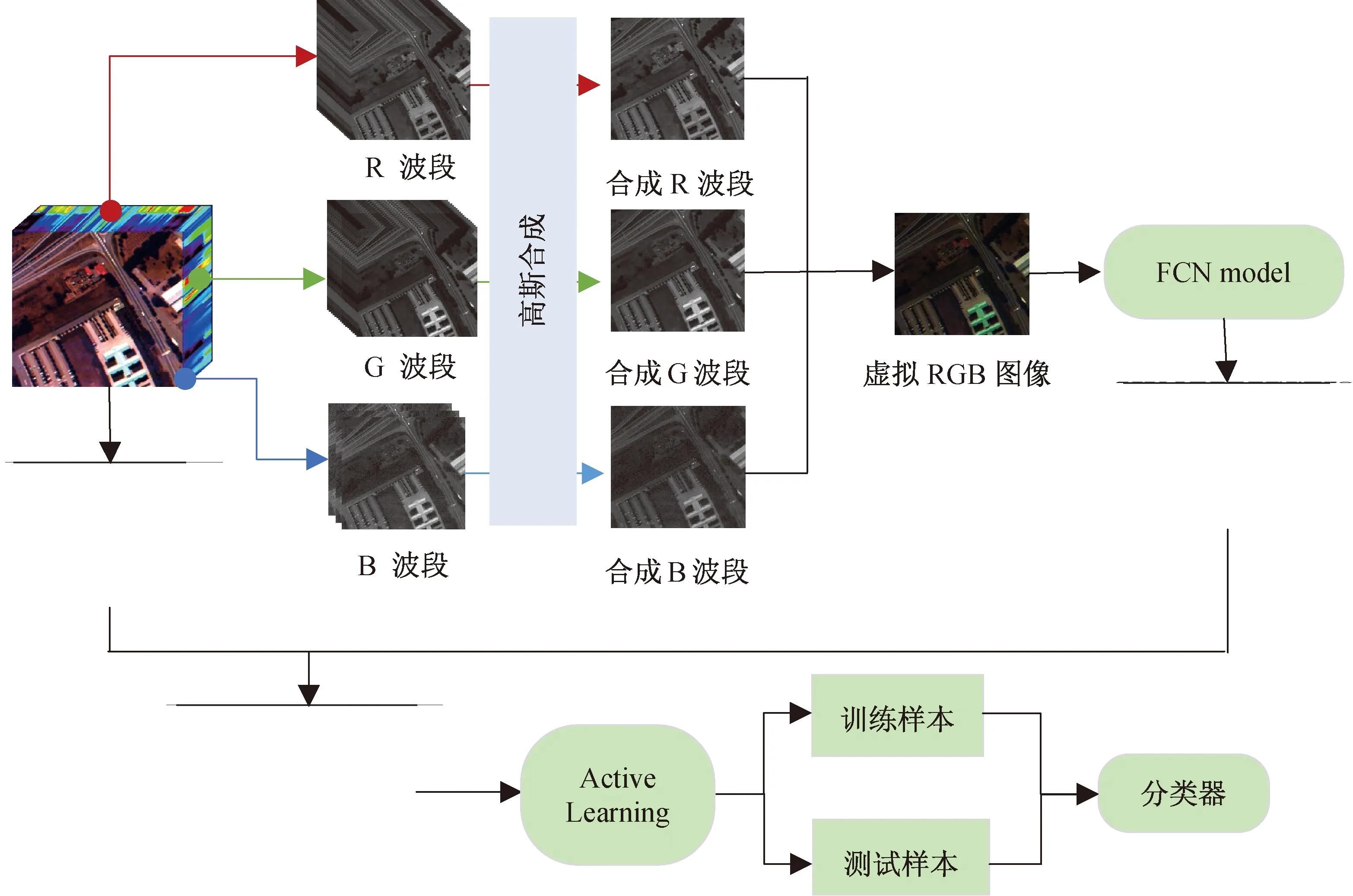
图1 高光谱图像分类算法流程图Fig.1 Flow chart of the hyperspectral image classification method
本文提出了一种虚拟RGB图像构建方法,主要是利用高光谱传感器每个波段的波长信息,寻找对应于RGB三个波段波长的高光谱波段,然后再将它们合成构成一个虚拟的RGB图像。以ROSIS(reflective optics system imaging spectrometer)成像传感器为例,其对应红光波长的波段有39~66共28个波段,对应绿光波段为13~29共17个高光谱波段,蓝光波段对应2~4共3个波段,将这些波段以类似高斯分布的方式合成。以红光波段为例,将高斯分布的均值定为
标准差σ根据3σ原则确定,即大部分合理波段都在3σ范围内,所以3σ=μ-39=13.5,σ=4.5。三波段图像每个波段的值为对应高光谱波段的值和它对应的高斯权重加权得到。
图2为Pavia University数据集上的结果,其中图2(a)为合成后的虚拟RGB图,图2(b)、图2(c)、图2(d)分别为合成后3个波段的灰度图。

图2 合成三波段图像Fig.2 Composed three-bands image
将提取到的三波段图像送入自然图像上训练好的FCN模型,提取其在Softmax之前的特征层,由于自然图像共20类物体,所以特征图共有21层(20类和背景层)。在Pavia University数据集上提取到的特征如图3所示。

图3 空间特征图Fig.3 Spatial characteristic diagram
2 空谱特征融合
参考JIAO等[21]的做法,将每个像素点的空间和光谱特征进行融合,构成空谱融合特征。假设Xspe为光谱特征,由原始光谱PCA取前s1维主成分得到,Xspa为深层空间特征,其维度为s2,所以可知
Xspe∈Rs1×n,Xspa∈Rs2×n
(1)
式中:n为要融合的像素点数目。首先对Xspe、Xspa进行如下操作
(2)
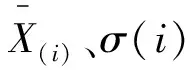
Xf=[f(Xspe);f(Xspa)]
(3)
此处,将原始光谱降维至15维,即s1=15,空间特征维度取所有21层,即s2=21。至此,得到空谱融合特征。
3 SVM分类器主动学习
将得到的空谱融合特征送入分类器即可对每个像素所属的地物类别进行区分,由于样本数目限制,此处应用主动学习选择训练样本并与支持向量机(SVM)[22]相结合用于对空谱联合特征进行学习[23-24],实现像素分类。
支持向量机是一种经典的二分类分类器,在将其用于多分类时通常有以下两种做法:一对多(one-versus-rest, OVR) SVMs,即依次将某个类别的样本单独化为一类,其他类别化为另一类,假设共有K类,则会产生K个分类器,对一未知样本分类时,将其送入这K个分类器,选择其中分为某类的概率值最大的那一类作为最终决策;一对一(one-versus-one, OVO) SVMs,在任意两类样本之间均设计分类器,若有K类,则会产生K(K-1)/2个分类器,将未知样本送入左右分类器,并对分成各类的次数进行统计,选择次数最多的那一类作为最终决策。
本文基于一对一分类设计主动学习策略,假设有K类数据,最初选择一部分进行标注,记为DL,其余未标注部分记为DU。每次选择加入训练集的样本数目记为na。用DL训练K(K-1)/2个一对一分类器,对于DU中每个样本,将其送入所有分类器中,获得投票数最多的两个类ω1、ω2,将针对ω1、ω2的分类器的预测值f作为该样本所含信息量的评价指标,该数绝对值越小,证明分类器在决策时把握越小,该样本所含信息将会越多,所以取|f|最小的na个样本进行标注后加入DL,并将其从DU中删除。可重复几次操作,得到选定的训练集DS。SVM分类器主动学习算法流程为:
输入:数据类别数K;标注数据DL;未标注数据DU;每次加入样本数na。
1) 用DL训练K(K-1)/2个一对一分类器;
2) 将DU中每个样本送入K(K-1)/2个分类器,对每个类别进行投票,得到投票数最多的两个类别ω1、ω2;
3) 找出ω1、ω2之间的分类器,将分类器预测值f作为判定该样本是否加入训练集的依据;
4) 找到|f|最小的na个样本进行标注后加入DL,并将其从DU中删除;
5) 循环几次,得最终训练集DS和测试集DU。
输出:最终训练集DS和测试集DU。
4 实验结果及分析
4.1 实验数据集
Pavia University数据集,是由反射光学系统成像光谱仪(reflective optics system imaging spectrometer,ROSIS-3)在意大利帕维亚城拍摄制作,如图4所示。该传感器共有115个光谱通道,覆盖的波段范围为0.43~0.86 μm,去除噪声和水吸收波段后,Pavia University有103个高光谱波段,空间维度为610×340,空间分辨率为1.3 m,共包含42 776个标注的样本,其中包括草地、树木、沥青等共9类地物,其假彩色图和分类真值图分别如图4(a)、图4(b)所示,每类样本数目详见表1。
4.2 实验结果对比
本部分主要验证ALbS2F的效果,将其与随机选取样本进行比较,这里随机选取采用两种方式,一种是每类数目与主动学习相同,另一种是按照总数目相近原则平均或等比例分配给各类别。两种随机方法分别被定义为随机方法A、B。
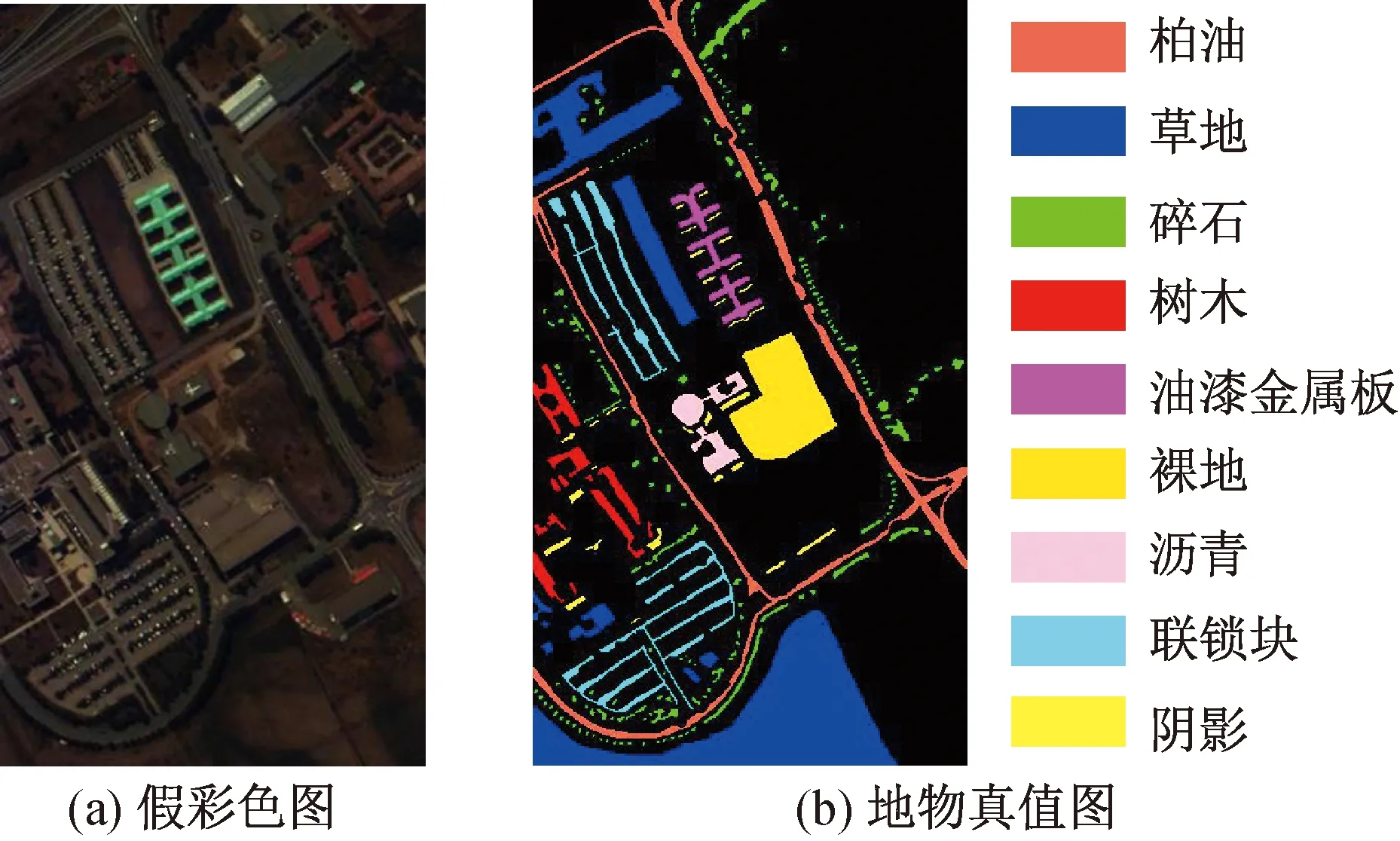
图4 Pavia University数据集Fig.4 Pavia University data
图5(a)、图5(b)、图5(c)为Pavia University数据集上ALbS2F、A、B三种方法分别选取的样本位置图,其中彩色代表选取的训练样本,白色代表测试样本,黑色代表未被考虑的背景,由于选取样本数较少,所以彩色的点不太容易被找到。图5(d)、图5(e)、图5(f)展示了3种方法的分类效果,图5(g)为分类真值图。可以看到应用主动学习后,
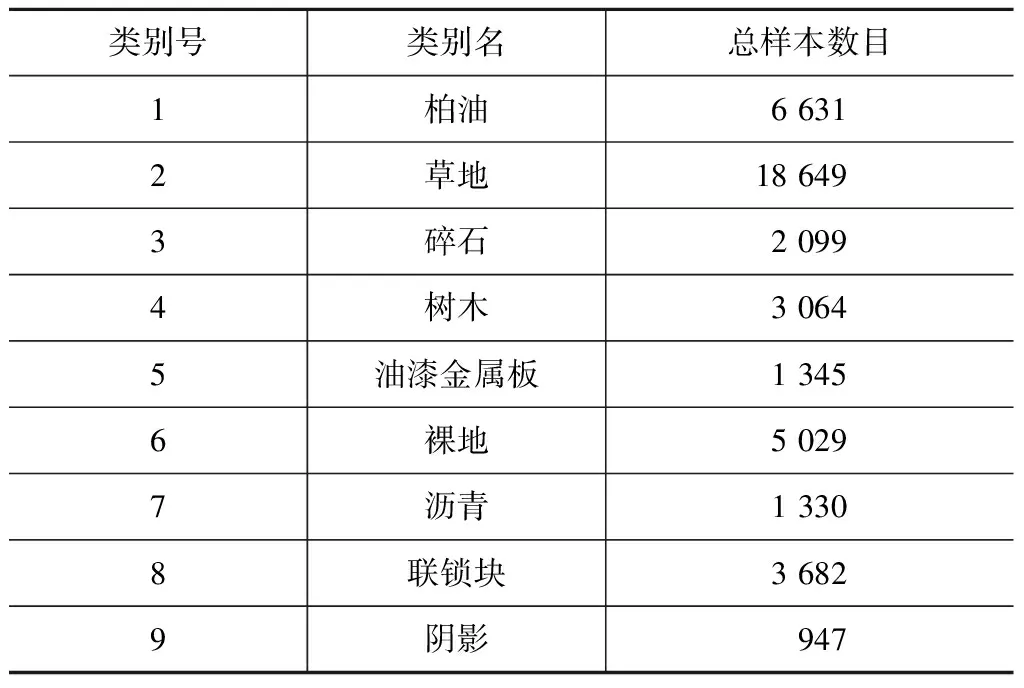
表1 Pavia University数据集地物分布
图5(d)中分类效果几乎接近真值图。表2详细展示了3种方法的每类分类正确率情况,加粗的表示最优的结果,可以看出,主动学习的应用,可使样本数相同或相近的情况下总正确率提高4%左右,效果提升明显。
为验证本文提出的虚拟RGB图像构建方式的有效性,针对PCA取前三维主成分和虚拟RGB图像进行了比较。首先,在运行时间方面,由于只是更改了系统的输入而对其他操作无变化,所以两种方法的耗时是相同的,主要比较其分类性能。在保证两种方法选用的训练样本完全相同的前提下,表3为分类正确率的比较。
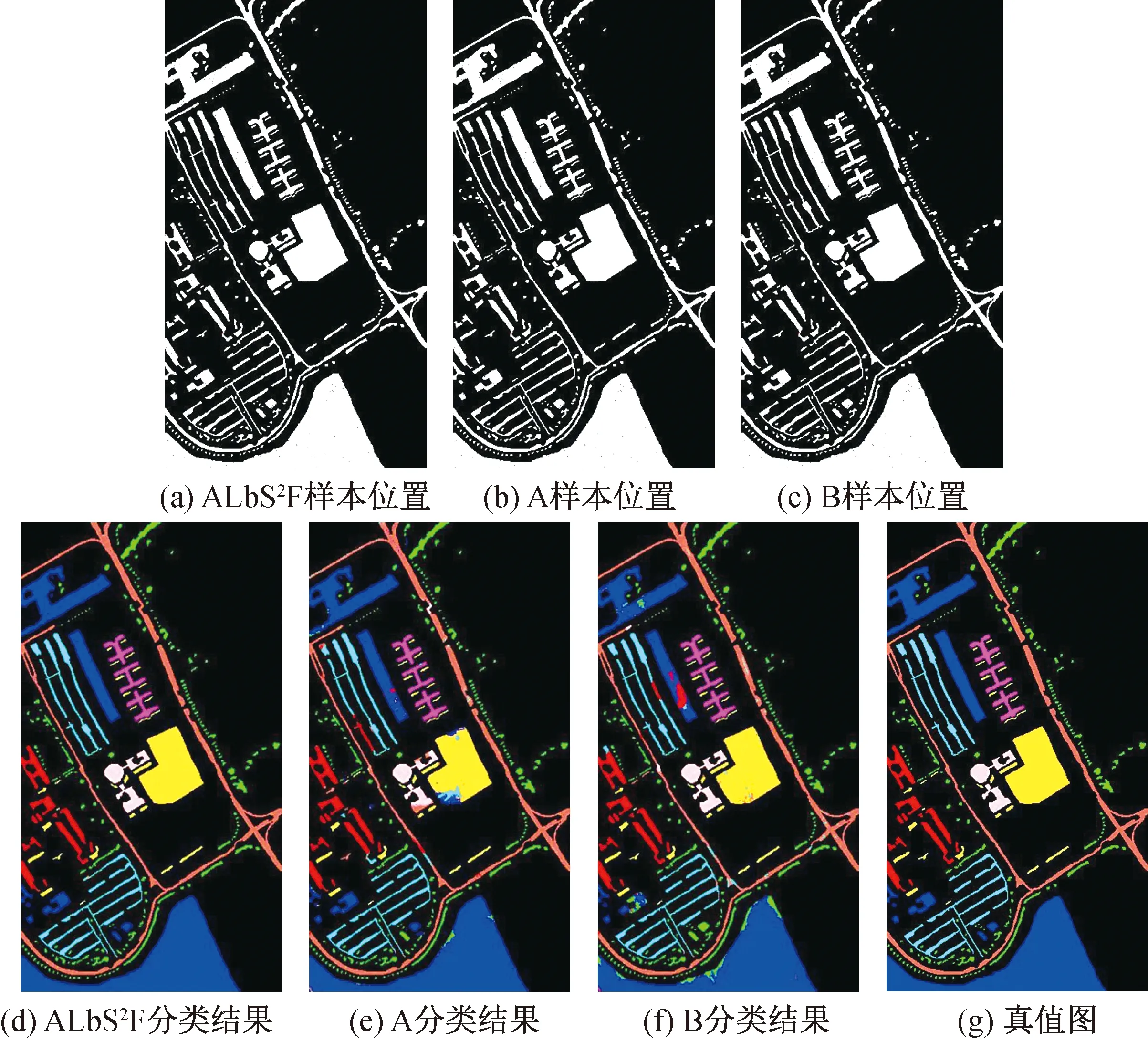
图5 Pavia University 数据集分类结果Fig.5 Pavia University classification results
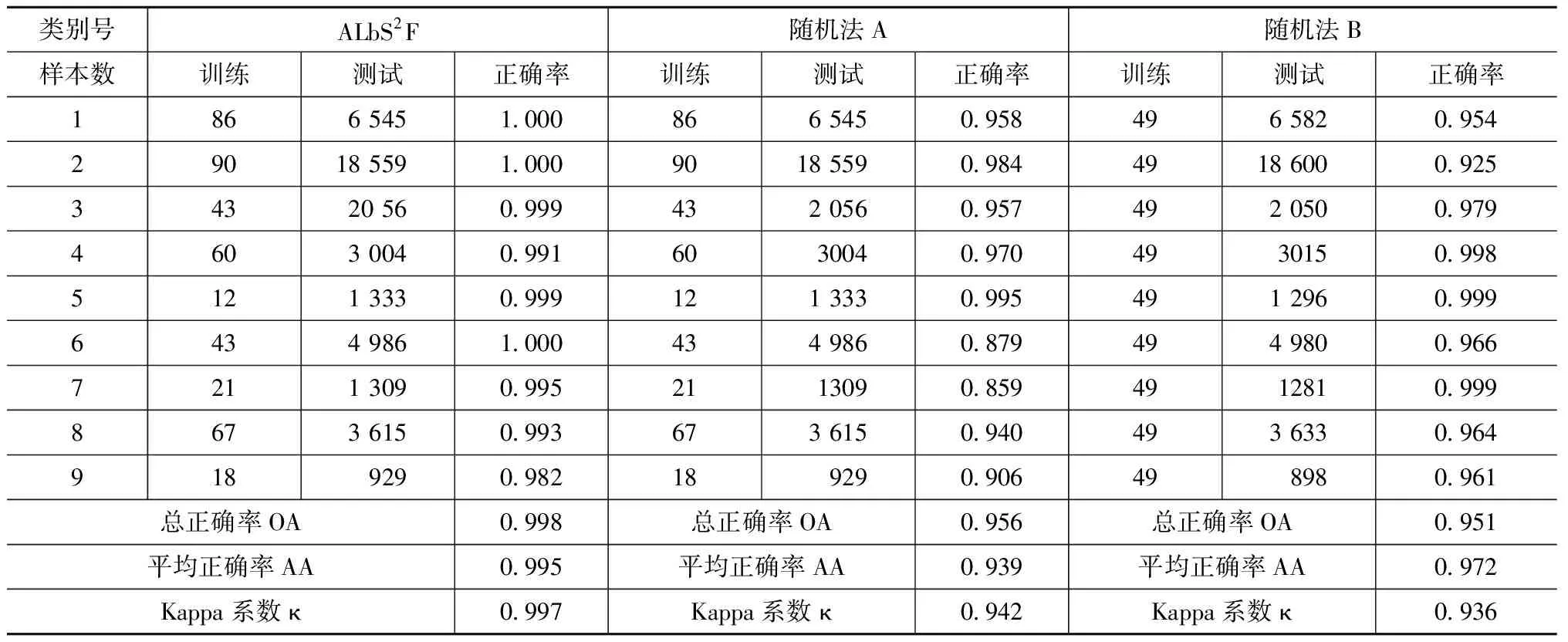
类别号ALbS2F随机法A随机法B样本数训练测试正确率训练测试正确率训练测试正确率1866 5451.000866 5450.958496 5820.95429018 5591.0009018 5590.9844918 6000.92534320 560.999432 0560.957492 0500.9794603 0040.9916030040.9704930150.9985121 3330.999121 3330.995491 2960.9996434 9861.000434 9860.879494 9800.9667211 3090.9952113090.8594912810.9998673 6150.993673 6150.940493 6330.9649189290.982189290.906498980.961总正确率OA0.998总正确率OA0.956总正确率OA0.951平均正确率AA0.995平均正确率AA0.939平均正确率AA0.972Kappa系数κ0.997Kappa系数κ0.942Kappa系数κ0.936
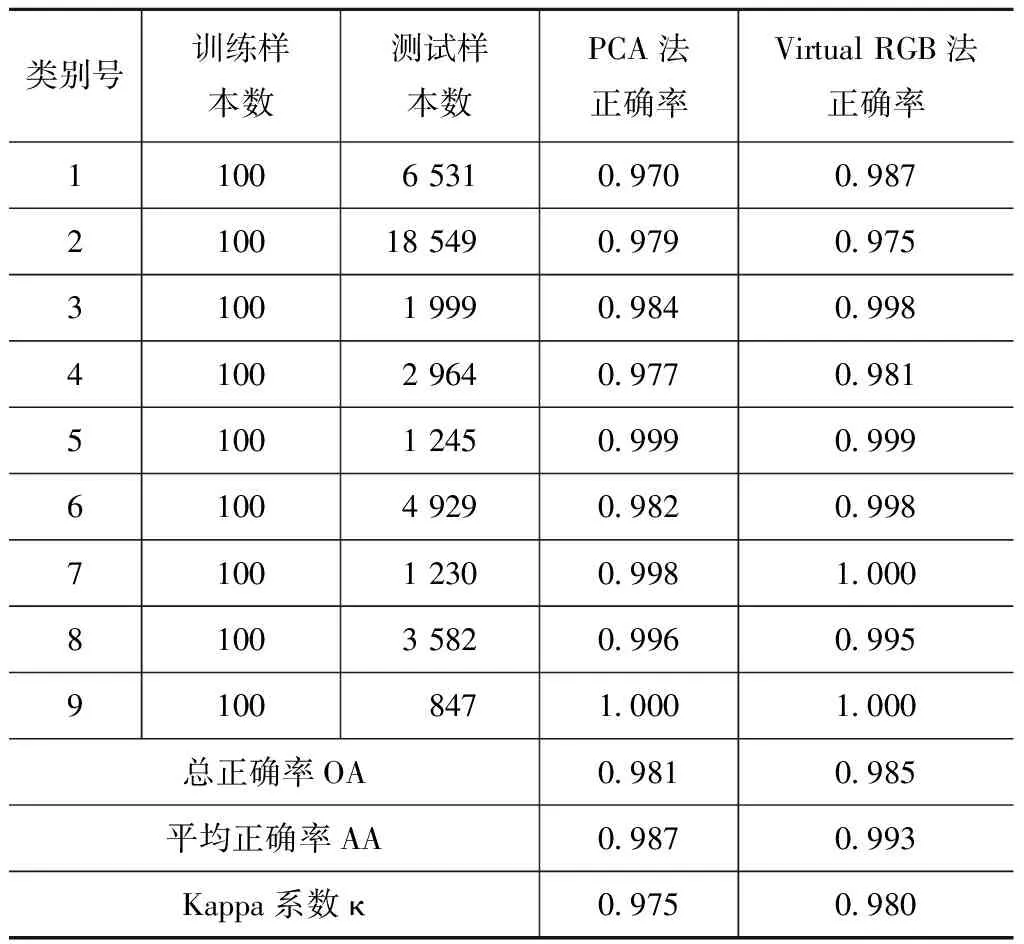
表3 两种三通道图像构造方式正确率
两种方法中,性能较优越的数据被加粗标出,可以看出Virtual RGB方法相对于PCA方法有较明显的优势,可以使分类总正确率提高0.4%左右,效果如图6所示,其中图6(a)为PCA构造法的分类效果图,图 6(b)为Virtual RGB方法的分类效果,图 6(c)为标注的真值图,即GroundTruth。可以看出,图 6(a)图中有很多细微的错分现象在图6(b)中得到了改善。
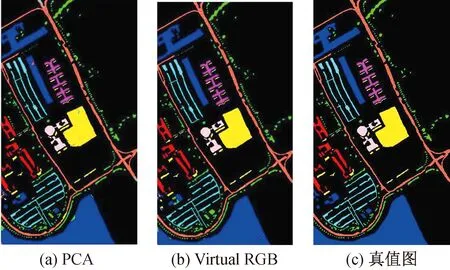
图6 两种三通道图像构建方式分类效果Fig.6 Comparison between two three-channel images
5 结束语
本文通过提出一种基于全卷积空间特征和光谱特征融合,基于主动学习方式选择训练样本的高光谱图像分类算法,实现了在一定数量样本的情况下较高的分类精度,并提出了一种新的RGB图像构造方式。实验表明:该方式相比于主成分分析等方法更加适合用于自然图像上训练好的网络来提取空间特征。
