基于改进YOLOv3网络的遥感目标快速检测方法
2019-10-26方青云王兆魁
方青云,王兆魁
(清华大学 航天航空学院,北京 100084)
0 引言
近年来,伴随着航天遥感技术的快速发展,高分辨率大尺度遥感图像数据不断丰富,实现快速遥感目标检测成为提升天基遥感应用能力的关键。遥感目标检测是指在遥感图像中找到兴趣目标的具体位置并识别其类别,该技术在港口、机场流量监测、交通疏导、寻找丢失船只等民用、军用领域有着重要的作用。然而,基于传统机器学习的遥感目标检测方法往往效果不理想,文献[1]认为相比常规图像,遥感图像背景十分复杂,在数千米的视野半径范围内存在各种复杂背景,这些复杂背景对检测器造成强烈的干扰。普通数据集大多是以与地面水平的视角拍摄的,目标方向相对地面具有一定的垂直方向性,而遥感目标由于是以俯视视角拍摄的,其方向在平面内可以是任意的,因此需要检测器对方向具有鲁棒性。此外,遥感目标大多为稠密的小目标,而提高稠密小目标检测精度正是目前目标检测面临的挑战之一。
传统机器学习效率低,主观性强,严重依赖于数据结构和专业知识,其特征泛化能力差,难以解决上述问题。近年来,深度学习逐渐成为研究热点,它通过对大量数据的学习,自动提取出最有效的特征,并通过建立复杂的网络结构实现精确检测。自2012年KRIZHEVSKY[2]掀起学术界深度学习热潮,深度卷积神经网络凭借其包含的深层语义特征在计算机视觉领域取得了巨大成功,近年来越来越多地被应用到图像的目标检测任务中。目前广泛使用的基于卷积神经网络的目标检测方法主要分为两类:第一类是“两个阶段”方法,该类方法将目标检测分为检测与识别两个阶段,首先由算法或者网络在图像中寻找兴趣目标区域,再对区域内的目标进行识别,如RCNN[3]、Faster-RCNN[4]、Mask-RCNN[5]等;第二类是“一个阶段”方法,该类方法利用回归思想同时完成检测与识别,实现端到端检测与识别,如YOLO[6]、SSD[7]等,它们相对第一类“两个阶段”方法,在速度方面快很多,但检测识别精度相对较低。
目前已经有很多学者将深度学习应用于遥感图像领域,并提出很多针对遥感目标检测的网络。2016年ZOU等[8]提出了一种SVDNet,将DCNN和机器学习的SVM相结合,在船只检测中取得了很好效果。2018年YANG等[9]将深度残差网络ResNet和超矢量编码(Super-Vector Coding)相结合,实现对飞机目标的高效检测。2018年XU等[10]将多层特征融合技术应用到全卷积网络(FCN)中,实现了对飞机目标的高精度定位。YAO等[11]提出一种多架构神经网络(MSCNN),每个架构分别针对大中小三类遥感目标进行检测,相比于单一框架网络,该网络在虚警率和召回率上都有较大的提升。
但在火灾监测报警、海上目标搜救和地震、火山、海啸灾害评估等重大紧急任务中,地面离线处理星上传回的图像方法,耗时长久,会耽误抗震救灾、人员搜救的黄金时间,因此星上在线识别处理将成为未来遥感技术的重要发展方向。受卫星本身质量和功耗的限制,其携带的计算单元的内存、算力有限,虽然目前关于利用深度学习方法实现遥感目标检测的论文不在少数,但此类论文提出的网络规模和计算量都较大,难以在星上内存和算力都受限的情况下完成对目标的实时检测。
针对上述问题,本文采用了YOLOv3-MobileNet网络,利用轻量化网络MobileNet[12]替代原先YOLOv3[13]的特征提取网络DarkNet53,在大量减少网络参数的同时显著提升运行速度。在后续对比实验中发现,在两者平均精度均值(mAP)都在76%附近时,YOLOv3-MobileNet检测速度是YOLOv3的3.7倍。此外,本文还提出了一种IoUK-medians算法,对数据集groundtruths进行尺度聚类分析,使得到的先验框更加适合目标检测。使用IoUK-medians算法后,在YOLOv3上的目标检测mAP提升了7.0%,在YOLOv3-MobileNet上提升了2.3%。
1 研究基础
1.1 YOLOv3网络
与之前的YOLO算法相比,YOLOv3采用了精度更高的DarkNet53作为特征提取网络,设计了目标多尺度检测结构,使用了logistics函数代替传统的softmax函数。DarkNet53借鉴了ResNet[14]残差网络的思路,在一些层之间设置了快捷路径,实验表明:DarkNet53相比于ResNet-152,在精度上接近,但速度更快[13]。此外,YOLOv3对小目标的检测效果有明显的提升,这得益于网络新增的 top-down结构,分别在13×13、26×26、52×52特征图上进行预测,解决了 YOLO算法检测颗粒粗、对小目标检测无力的问题。
1.2 轻量化网络
虽然现在卷积神经网络(如AlexNet[2]、ResNet[14]、GoogLeNet[15]和DenseNet[16]等)的特征提取能力随着网络层数的加深正在不断地提升,但在实际工程中还需要考虑模型尺寸和模型预测速度。深度卷积神经网络包含几十层甚至上百层的网络,有着大量的权重参数,保存这些权重参数对设备内存有很高的要求。此外,在实际应用中往往要求检测速度在几十毫秒甚至更少时间内完成目标检测。
为解决上述问题,通常的方法是对训练好的模型进行压缩,在减少网络参数的同时提升预测速度。轻量化网络则通过更高效的卷积计算方式,使得网络参数和计算量大大减少,且不损失网络性能。MobileNet由2017年Google 团队提出,它采用一种深度可分离卷积的高效卷积方法来提升运算速度。在深度可分离卷积中,一个卷积核负责一部分特征图,且每个特征图只被一个卷积核卷积。深度可分离卷积涉及另外两个超参数:宽度乘法器和分辨率乘法器,这两个超参数用于衡量网络设计的大小和量化模型规模。MobileNet在计算量、存储空间和准确率方面取得了很好的平衡,与VGG16[17]相比,在很小的精度损失情况下,将运算量减小为1/30。
2 网络设计
2.1 YOLOv3-MobileNet网络
图1为YOLOv3-MobileNet网络结构,相比于DarkNet53有53个卷积层,MobileNet只有1个卷积层和13个深度可分离卷积层。
从图1中可以看出蓝色的深度可分离卷积模块将卷积操作分成了Depthwise和Pointwise两个步骤。Depthwise对于不同输入通道采取不同的卷积核进行卷积,卷积核和通道是一一对应的,再通过1×1 Pointwise 卷积完成对Depthwise输出特征图的整合,这样就避免了普通卷积层中任意一个卷积核都需要对所有通道进行操作的缺陷。通过Depthwise和Pointwise两个步骤实现卷积层,其参数仅约为普通卷积的1/9,乘法计算量仅为普通卷积的1/c+1/9,其中c为输入通道数。基于这种高效卷积的MobileNet将大大精简整个模型的规模,极大减少计算量。表1为在输入图片尺寸为416×416时YOLOv3-MobileNet与YOLOv3在参数量、计算量方面的比较,在模型规模方面 , YOLOv3-MobileNet参数相比于YOLOv3降低了1.5倍; 在浮点数计算量方面, YOLOv3-MobileNet浮点数计算量相比于YOLOv3降低了3.3倍。

图1 YOLOv3-MobileNet 网络结构Fig.1 YOLOv3-MobileNet architecture
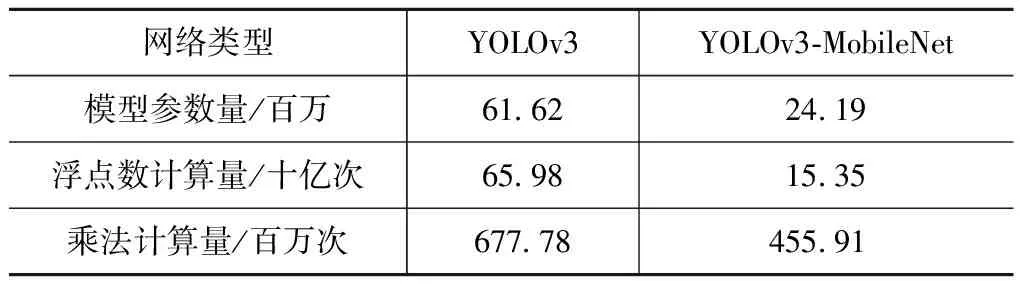
表1 YOLOv3-MobileNet与YOLOv3对比
从图1可看到,YOLOv3-MobileNet未改变YOLOv3 top-down结构,这种结构借鉴了特征金字塔网络[18]的概念,对特定卷积神经网络层数的特征图(YOLOv3-MobileNet中第5、11、13深度可分离卷积层)进行处理,以生成反映此维度信息的特征。top-down结构处理后所生成的特征之间也有关联,上层高维度特征会影响下层低维度特征的表达,最终所有维度的特征一起作为目标检测的输入,如图2所示。不同维度的特征图可以针对不同尺度的目标进行检测;最上面的特征层,特征维度丰富但特征尺度压缩严重,因此比较适合检测大目标;最下面的特征层,特征维度少但特征尺寸大,适合检测小目标;中间特征层居于上、下两层中间,适合检测中等目标。这种多尺度的检测极大地改善了YOLO检测粗糙的问题,特别是对小目标的检测精度有了很大的提升。
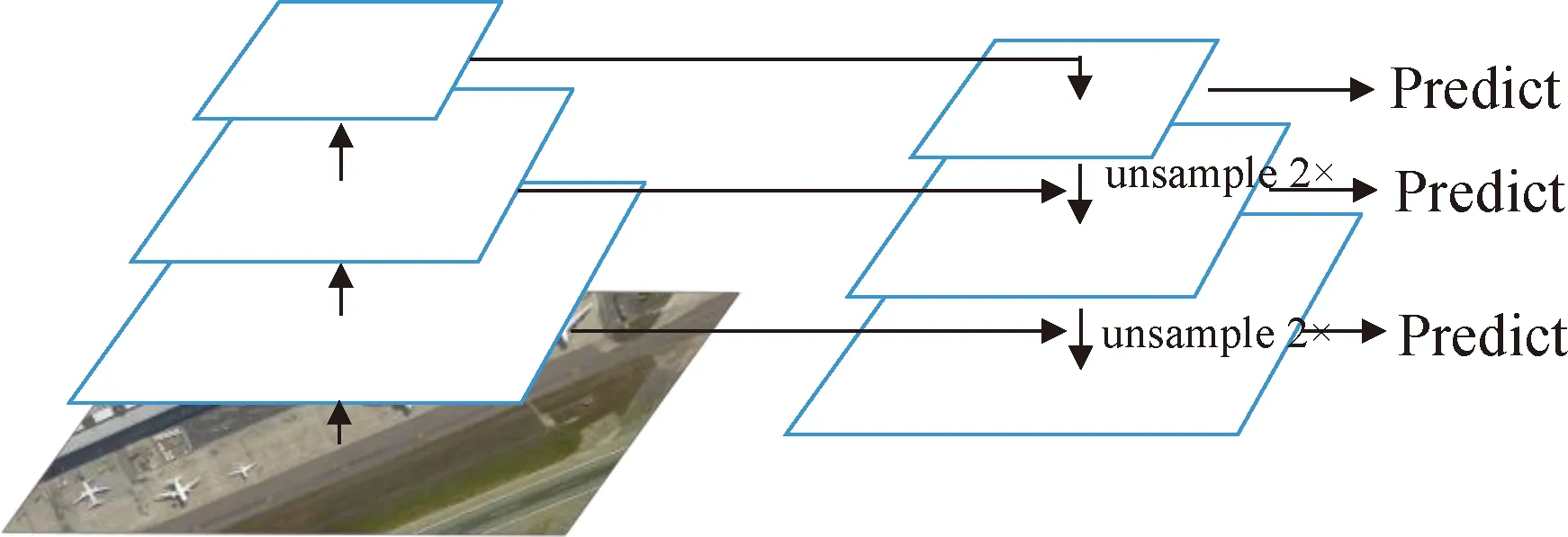
图2 自上向下结构Fig.2 Top-down architecture
2.2 IoU K-medians聚类改进
Faster RCNN和SSD算法中都需要手动挑选先验边界框的尺寸,显然这种方法过于主观。统计学习中的K-means方法通过对训练集中目标的边界框尺寸进行聚类,自动挑选出更精准、更具代表性的边界框尺寸,使得卷积神经网络更容易准确预测目标位置。对于给定的样本集,根据样本间的距离大小,将样本划分为K个簇,通过一系列迭代使得簇内的样本距离尽可能小,而让簇间的距离尽量大,这是K-means的主要思想,其本质上是一种基于最大期望的无监督聚类方法。
K-means算法中通常以欧氏距离、曼哈顿距离、切比雪夫距离或者闵氏距离作为距离度量。设置先验边界框大小的目的是使得预测框与groundtruths 之间的交并比(IoU)结果更好,但使用这些传统的度量往往得不到很好的效果。因此本文使用一种新的距离度量标准,即
d(B,C)=1-IoU(B,C)
(1)
式中:B表示为groundtruths集合;C为边界框的簇中心集合;IoU(B,C)为groundtruths和边界框簇中心的交并比。IoU在目标检测中代表预测框与groundtruths之间的相关度,相关度越高,两者越相近,预测框就越精确,IoU的具体计算式为
(2)
式中:bgti为第i个groundtruth;bpdj为第j个预测框。
K-means算法在簇迭代中采用求取均值后更新的方法,这样会导致其对野值和噪声比较敏感。在遥感图像目标检测中,由于卫星拍摄高度、相机分辨率以及物体本身实际尺寸大小均存在较大差异,会存在少数超大或者超小的目标出现,这些异常目标会对K-means聚类精度造成很大影响。为避免该现象,本文采用一种K-means的改进算法K-medians,将原先K-means簇迭代中求取均值替换为求取中位数。中位数对噪声点或者野值具有很强的抗干扰性,避免了异常目标尺寸的影响,进而提升目标检测精度。
图3展示了以欧几里得距离为度量的K-means、以 IoU为度量的K-means和K-medians三种方法在数据集上的平均 IoU随聚类中心个数K的曲线图。图3验证了使用普通的距离度量往往得不到一个理想的结果,甚至随着簇中心个数K的增加,以欧氏距离为度量的K-means效果在有些情况下反而变差了。原因是在使用欧氏距离为度量时,尺寸大的预测框比尺寸小的预测框更容易产生损失误差,这必然会导致K-means生成的预测框偏大,从而使得最后得到的平均IoU偏低。而直接以IoU为度量的聚类方法避免了预测框大小造成损失不平衡的情况,得到的IoU更好,且结果与预测框的尺寸无关。此外,本文提出的基于IoUK-medians方法相比其他两者的平均IoU更高,得到的先验框更精确也更具代表性。

图3 不同聚类方法的平均IoU比较Fig.3 Average IoU for different methods
3 实验对比分析
3.1 数据集介绍
实验使用的数据集是对NWPU-VHR10数据集的扩充,数据集原有650张图像,扩充398张图像,包含飞机、舰船、储油罐、棒球场、网球场、篮球场、操场、港口、桥梁和车辆10类目标,总计6 686个目标。选取数据集中70%的图像作为训练样本,其余30%作为测试样本。
3.2 检测指标
实验结果指标采用国际PASCAL VOC 目标检测挑战赛的度量,即精度(Precision)、召回率(Recall)、平均精度(AP)和平均精度均值(mAP)。精度P是正确预测的实例占预测总数的百分比,可表示为
P=NTP/(NTP+NFP)
(3)
式中:NTP为正阳性实例;NFP为假阳性实例。NTP和NFP相加就是总预测数。召回率R是正确预测的实例占实例总数的百分比,可表示为
R=NTP/(NTP+NFN)
(4)
式中:NFN为假阴性实例。NFN和NTP相加就是实例总数。对于每一种类别,平均精度是精度随召回率变化(PR)曲线的积分,以图4中飞机目标为例,其平均精度是其PR曲线的积分,即图中淡蓝色区域的面积。mAP表示所有类别平均精度的均值。
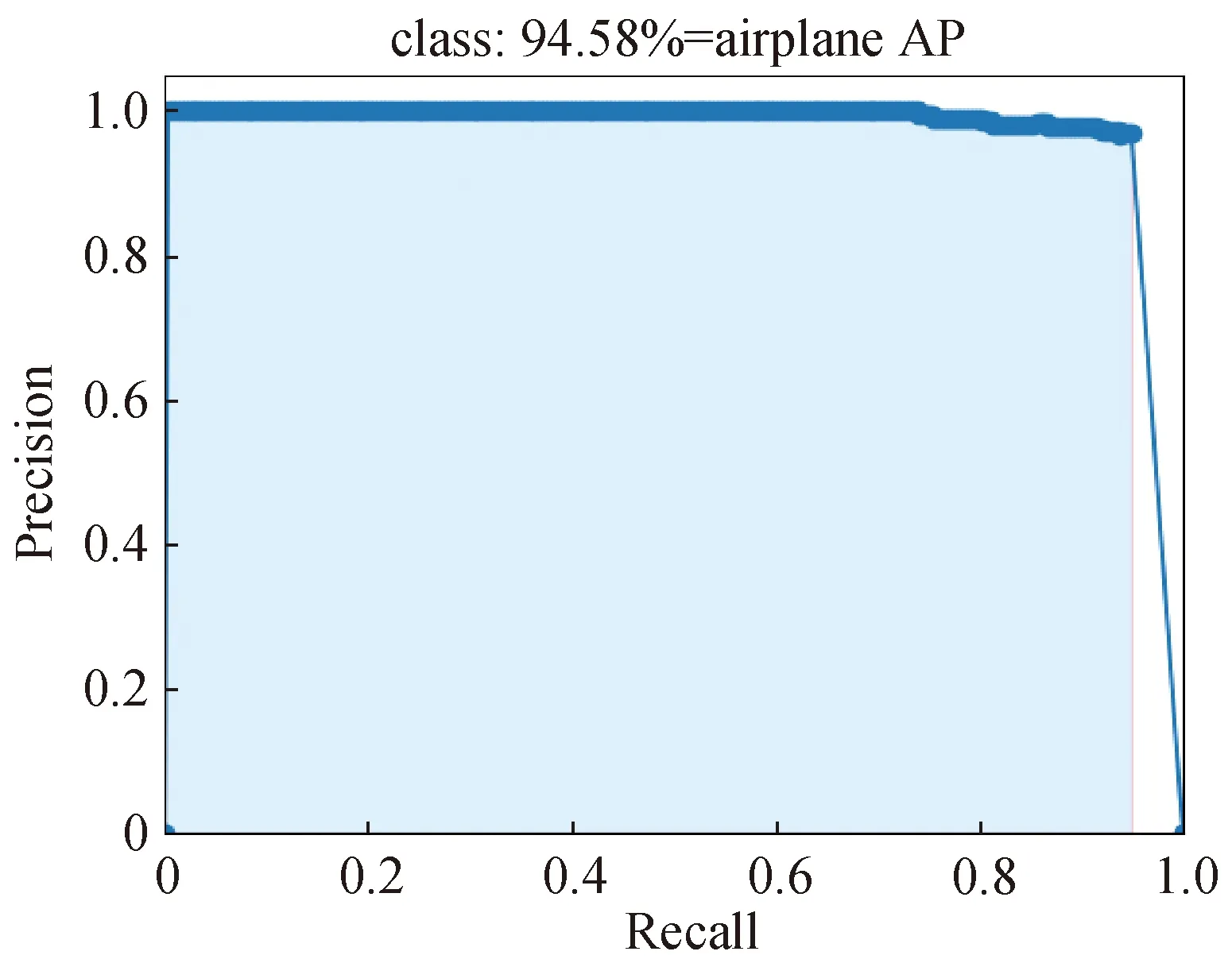
图4 飞机目标平均精度Fig.4 AP of airplane
3.3 实验分析
实验采用的软硬件平台配置如下。CPU:Intel(R) Core(TM) i9-7900X @ 3.30 GHz; GPU: NVIDIA Titan xp; 操作系统: ubuntu 16. 04LTS; 深度学习框架: Keras。
表2是YOLOv3和YOLOv3-MobileNet使用和不使用IoUK-medians算法的对比。通过对比可以发现:使用IoUK-medians算法能产生很好的效果,在YOLOv3上的mAP提升了7%,在YOLOv3-MobileNet上则提升了2.3%。检测平台界面如图5所示。图6是YOLOv3-MobileNet的部分检测结果,最右侧小图中棒球场目标在图像中只占很小一部分,但也能被正确检测,侧面反映了YOLOv3-MobileNet具有强大的学习能力。

表2 IoU K-medians效果
图7中,YOLOv3-MobileNet相比于YOLOv3在检测速度方面有很大的优势,其检测速度为GPU耗时的倒数,YOLOv3-MobileNet最快能达到101 frame/s,满足实时检测的需求。当YOLOv3-MobileNet和YOLOv3 两者的mAP都在76%附近时,YOLOv3-MobileNet的检测速度为78 frame/s,而YOLOv3的检测速度只有21 frame/s,前者是后者的3.7倍。当YOLOv3-MobileNet的mAP达到82.2%时,其检测速度仍能达到33 frame/s,是YOLOv3最快速度(21 frame/s)的1.6倍,并且比YOLOv3的mAP高6%。

图5 遥感目标检测系统界面Fig.5 System interface of remote sensing target detection

图6 YOLOv3-MobileNet 检测示例Fig.6 Some examples of YOLOv3-MobileNet detection
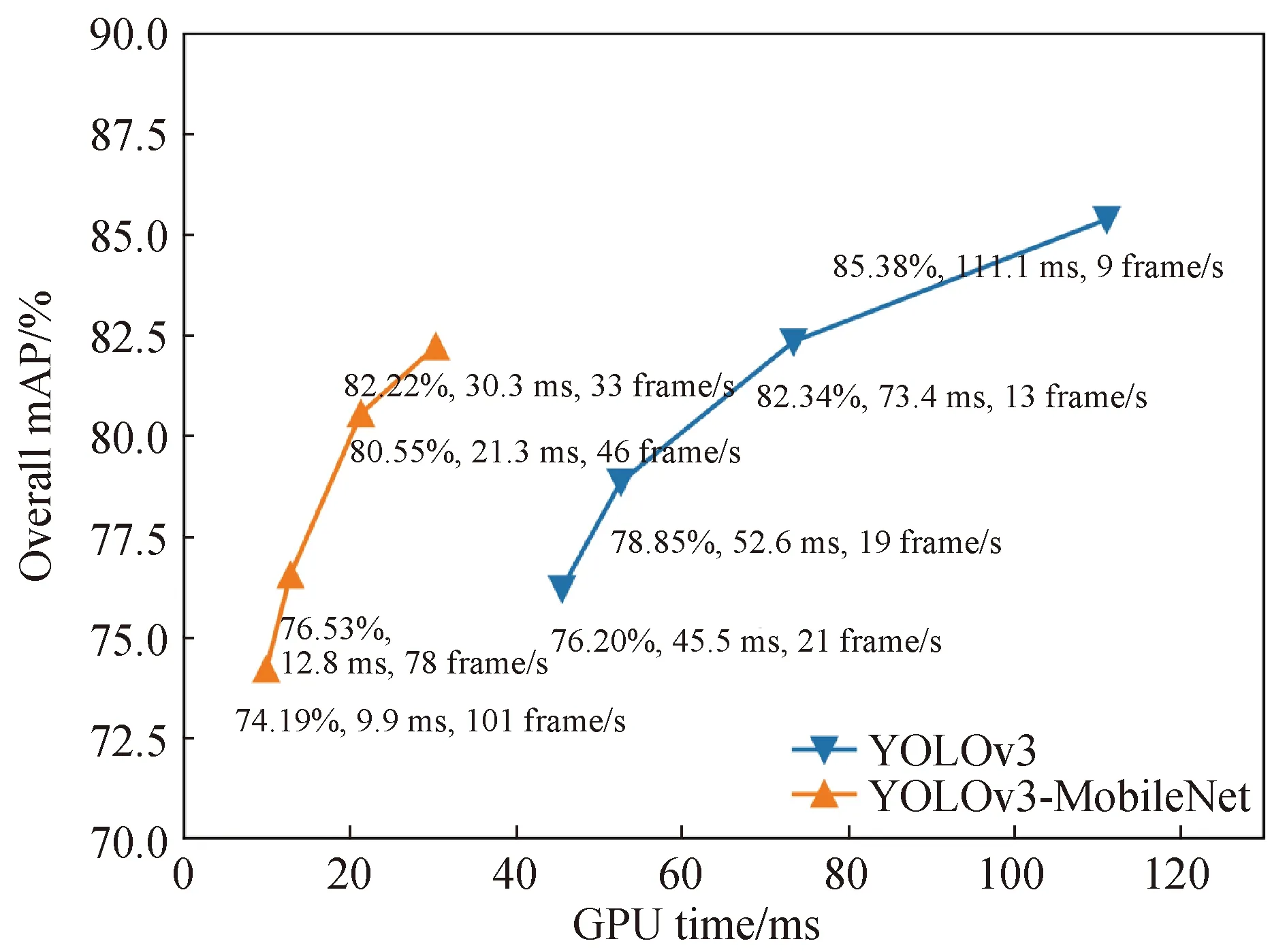
图7 YOLOv3-MobileNet 与YOLOv3的mAP和检测速度对比Fig.7 Comparison of mAP and detection speed between YOLOv3-MobileNet and YOLOv3
不同尺寸的输入图像对YOLOv3-MobileNet结果有很大的影响,总体来说,随着网络输入图像尺寸增大,mAP也在提升,如表3所示。大的输入图像能保留更加丰富的信息,因此其检测精度也相对较高。值得注意的是,对于不同大小的目标,随着输入图像尺度增加,检测精度不一定提高。对于储油罐和汽车这类小尺寸目标,随着输入尺度的增加,精度不断提升;而对于操场、棒球场等超大尺寸的目标,随着输入尺度增加,精度会降低;对于飞机这类中等尺寸的目标,随着输入尺度增加,精度基本不变化。对于小目标,在输入尺寸较小时,经过多层的卷积池化后,其大量信息丢失,使得最终特征的维度过低,从而难以区分出来。随着输入尺寸增大,保留下的信息变多,因而小目标检测精度得到提升。大目标正好相反,输入尺寸过大,使得提取特征的维度过高,最终导致精度下降。
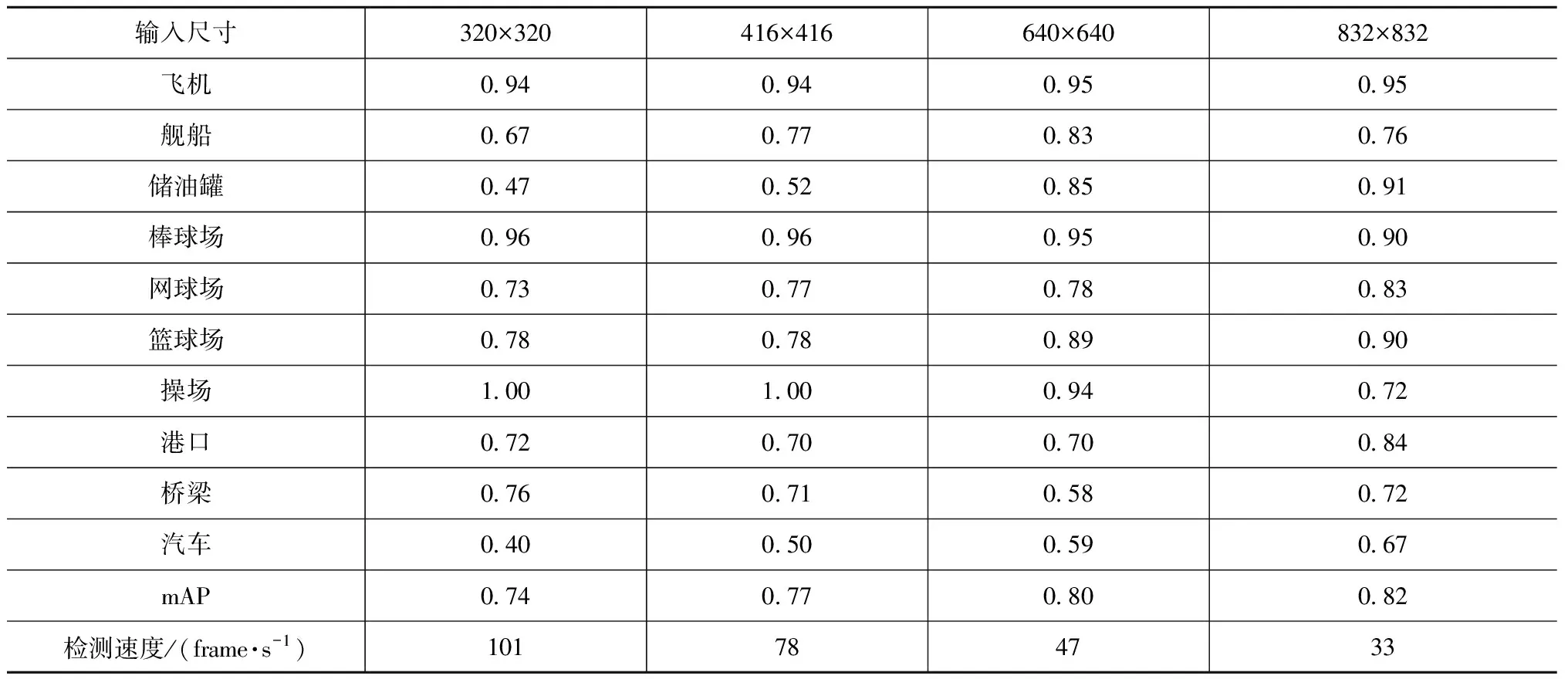
表3 不同输入尺寸YOLOv3-MobileNet各类目标AP检测结果
4 结束语
本文针对将来星上实时检测内存和计算能力都受限的情况,在YOLOv3的基础上进行了改进,利用轻量化网络MobileNet代替了DarkNet53,在保持检测精度相差不多的情况下,极大减小了模型规模和计算量。此外还提出了一种IoUK-medians算法,通过对groundtruths进行聚类分析,得到更精准、更具代表性的先验框,使得YOLOv3-MobileNet更容易预测目标准确位置,并通过实验进行了验证。该实验也为将来在嵌入式平台上对算法进行后续仿真验证奠定了基础。
