中文医学知识图谱CMeKG构建初探
2019-10-21奥德玛杨云飞穗志方代达劢常宝宝李素建昝红英
奥德玛,杨云飞,穗志方,代达劢,常宝宝,李素建,昝红英
(1. 北京大学 计算语言学教育部重点实验室,北京 100871;2. 鹏城实验室,广东 深圳518055;3. 郑州大学 信息工程学院,河南 郑州 450001)
0 引言
2012年,谷歌提出了知识图谱(Knowledge Graph)的概念,为世界知识和领域知识的构建提供了一个可资借鉴的手段[1]。知识图谱的基本组成是由头实体、尾实体和两者之间的关系组成的三元组关系。目前,对知识图谱的研究应用主要包括通用知识图谱和垂直领域知识图谱。典型的通用知识图谱有Google Knowledge Graph[1]、YAGO[2]、DBPedia[3]、CN-DBpedia[4]、XLore[5]等。虽然通用知识图谱收集了大量的领域知识,但是受到概念约束,无法完整描述比较复杂的领域知识。垂直领域知识图谱在领域知识的描述方面优于通用知识图谱,但常采用手工构建方法,因此其构建成本很高。
在知识图谱概念提出之前,众多研究机构已经利用知识库的存储方式构建了大量核心医学资源,如世界卫生组织维护的国际疾病分类代码ICD-10[6]、美国国立医学图书馆的一体化医学语言系统UMLS[7]及其收录的100多种词表和分类体系、国际医疗术语标准开发组织维护的系统化临床医学术语集SNOMED-CT[8]、Linked Open Data(LOD)收集的1 000多种生命科学知识库、BioPortal[9]、Bio2RDF[10]等。上述医学核心资源对医学领域的相关知识进行了专业的描述,这些资源可服务于医学文献检索或医学术语标准化等医学信息化应用,但还不能满足现代智慧医疗对医学知识描述的结构化、精细化和自动化的需求。
鉴于医学知识图谱在知识推理、智能问答、辅助诊断等智能医疗应用中的重要作用,已有一些单位陆续开展了医学知识图谱的构建工作。中国中医科学院中医药信息研究所基于已有的中医药学语言系统[11]构建了中医药知识图谱[12]、上海曙光医院和华东理工大学构建了中医药知识图谱[13]、华东理工大学构建了中文症状库[14]、中国医学科学院医学信息研究所构建了医药卫生知识服务系统知识图谱[15]等。不过,现有医学知识图谱从规模化、规范化、形式化、体系性等方面都仍有很大的提升空间。如何基于高效的知识工程方法、权威的医学数据资源、精准的知识描述体系和先进的文本挖掘技术,构建大规模、高质量的医学知识图谱,仍是极具挑战性的课题。
针对上述挑战,本文利用自然语言处理与文本挖掘技术,以人机结合的方式研发了中文医学知识图谱第一版CMeKG 1.0。本文综述了CMeKG构建过程中的描述体系、关键技术、构建流程以及医学知识描述相关问题。本文组织结构如下: 第1节介绍医学知识图谱相关研究工作,第2节介绍CMeKG构建的总体方案,第3节介绍医学知识描述体系,第4节介绍知识提取技术,第5节介绍医学知识图谱构建的初步结果,第6节为总结与展望。
1 相关工作
医学领域术语和知识资源的收集与构建由来已久,已取得显著的成果。比较典型的包括一些应用广泛的医学术语集,如ICD-10、ATC[16]和MeSH[17]等。
ICD-10是世界卫生组织维护的国际疾病分类代码,它是包含疾病、症状、体征、异常发现、社会环境以及外部原因导致的损伤或疾病的代码。ICD-10编码以树状层级结构描述了22大类的10 000多个概念,通常辅助于公共卫生组织跟踪疾病、保险公司理赔以及医院存储电子病历等任务。ATC是世界卫生组织维护的解剖学、治疗学及化学分类系统,它的本体结构依据的是药物成分对人体解剖学的治疗、药理和化学特征效应,ATC共包含消化道、血液形成器官、心血管等14大类解剖学概念对应的药物成分及其用法用量标准。MeSH是美国国立医学图书馆编制的医学主题词表,它包含15大类所属的18 000多个医学主题词,主要辅助PubMed标引和检索医学文献。
中国中医科学院中医药信息研究所构建的中医药知识图谱包含中医药学语言系统的100余万语义关系,其主要目的是形象地表达概念之间的关系,通过浏览界面提高用户检索领域知识的体验。随后,上海曙光医院也构建了中医药知识图谱,实现了面向临床应用的半自动化知识图谱的构建和知识问答、辅助开药等应用。华东理工大学构建的中文症状库是结合中医和西医知识自动构建的知识图谱。中文症状库涉及10万多个实体及实体之间的20余种语义关系,共包含60多万个三元组关系。中国医学科学院医学信息研究所构建的医药卫生知识服务系统知识图谱基于医学百科的医学知识,以可视化界面展开医学百科知识。
综上所述,国外医学信息化领域存在结构化程度较高、规模较大的资源(例如,UMLS等),而中文医学知识目前以非结构化信息为主,缺少大规模结构化的开源资源。目前中文的医学知识图谱在覆盖的知识规模[15]、知识的描述规范体系[14]、知识的开源性[12-13]和形式化等方面还存在诸多不足。因此,我们的研究目标是建立大规模、高质量的中文医学知识图谱,为智慧医疗奠定专业知识基础。
2 中文医学知识图谱CMeKG构建总体方案
目前关于现代医学方面的中文医学知识图谱还比较少。因此本文定位于现代医学中文知识图谱工程构建研究,旨在介绍我们开发的中文医学知识图谱,集中描述其总体构建流程和资源概貌。CMeKG的最终目标是制订层次清晰、高度关联的结构化医学知识描述体系,研发高性能的医学知识图谱构建方法和关键技术;搭建基于自然语言处理技术的知识图谱构建平台,形成知识图谱构建的自动化和规范化工程模式;采集加工多级医疗数据,建立高质量的中文医学知识图谱。作为CMeKG构建的第一阶段,我们搭建了中文医学知识图谱的基础框架,并建立知识图谱第一版。
在CMeKG的构建过程中,我们在语料处理和知识提取时充分利用了中文分词、命名实体识别以及关系提取技术,通过技术手段提升了医学知识图谱构建的自动化程度,扩大了可处理的医学文本的来源和规模,使得知识图谱的信息更充分。同时,作为一个医学知识图谱,不但要保证知识来源的充分性,而且要考虑知识组织和知识内容的权威性。针对后者我们充分利用了医学领域国际标准,如ICD-10、ATC、MeSH来组织和引导知识图谱构建过程,保证我们的医学知识的权威性和系统性。基于以上考虑,中文医学知识图谱CMeKG的构建流程如图1所示。
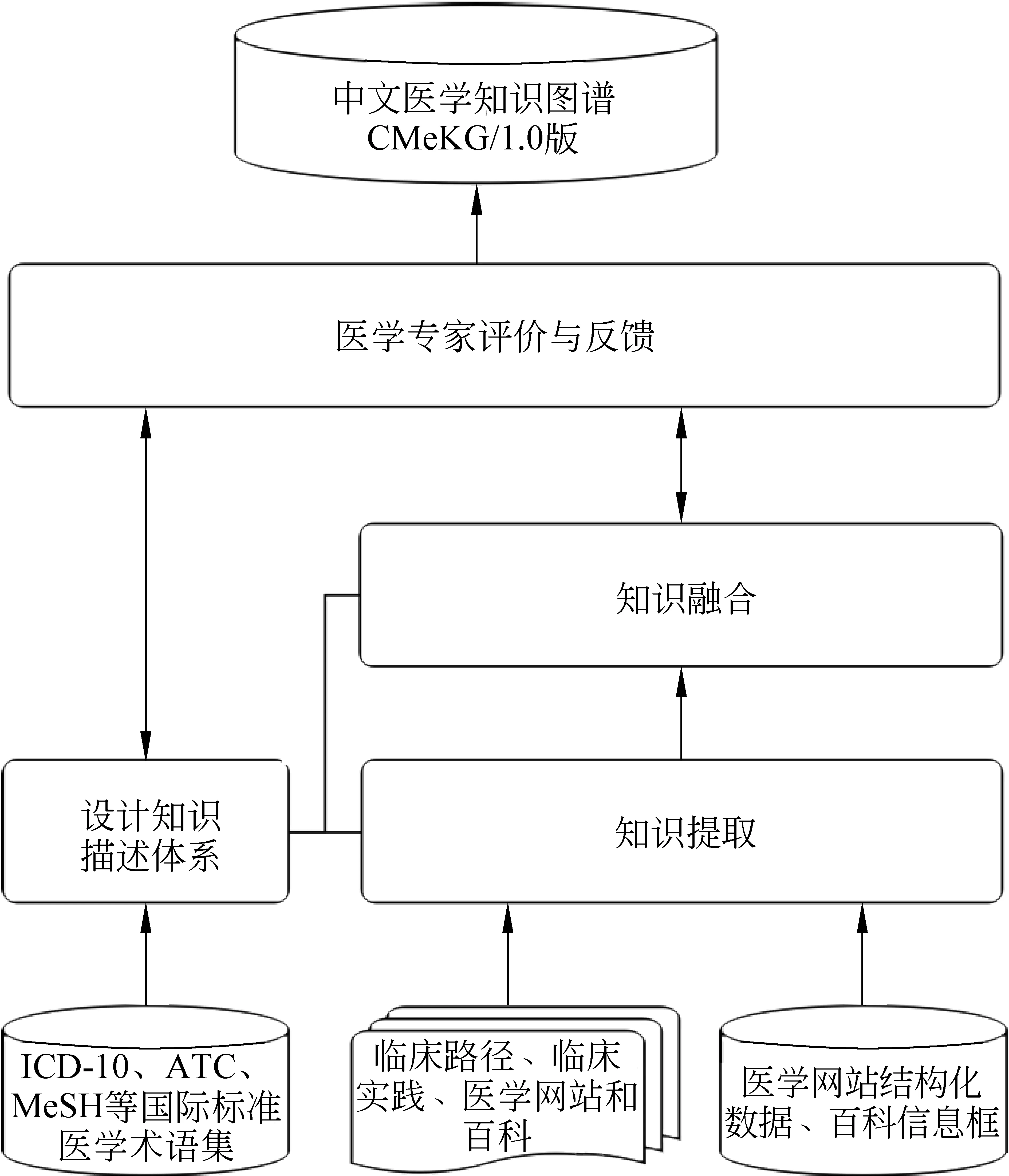
图1 CMeKG构建流程
首先,我们参考国际标准,在医学专家的指导下设计医学知识图谱模式层的规范体系。之后,在算法自动提取及人工标注、校对的基础上,整合提取医学概念关系实例,并进行实体对齐和归一化处理。在上述步骤完成后,根据医学专家的评价和反馈,迭代地修正医学知识图谱。最终,形成中文医学知识图谱CMeKG 1.0,并在可视化平台上展示。
3 医学知识描述体系设计
CMeKG主要由疾病、药物和诊疗技术类概念及其关系和属性组成。CMeKG的医学知识抽象描述框架如图2所示,图2中以支气管肺癌为例,描述了对应的主要实体关系和属性。
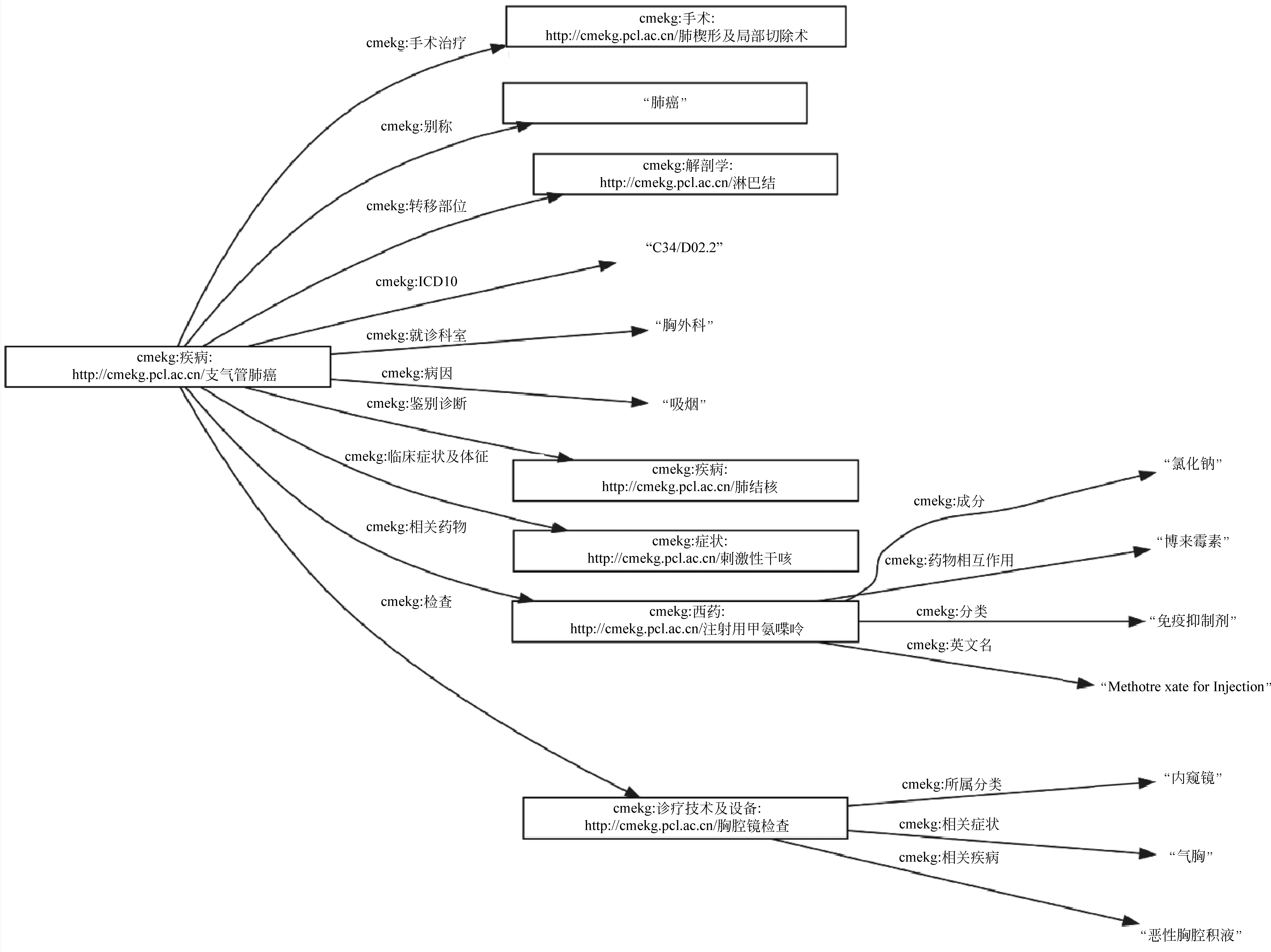
图2 医学知识抽象描述框架
3.1 医学概念分类体系
概念分类体系的专业性和权威性对医学知识图谱的质量具有十分重要的作用,本文参考ICD-10、ATC、MeSH等国际标准医学术语集,将CMeKG的概念层设计为15大类,如表1所示。

表1 概念分类体系规范

续表
3.2 医学概念的关系描述框架
为了更丰富、更精准地描述不同种类的医学知识,基于上述医学概念分类体系,我们针对疾病、药物和诊疗技术及设备等各类医学概念进行细化描述,定义了各类概念的关系描述框架。每个概念的关系描述框架由概念间的关系(概念关系)和概念与属性之间的关系(属性关系)构成。我们共定义了67种概念关系, 例如,<药物类—症状类—适应症>、<疾病类—诊疗技术及设备类—检查>,以及194种属性关系,用来描述某个概念实例的属性值(数字或字符串),如同义词、规格、成分、发病年龄、住院时间等。表2以支气管肺癌为例,展示了疾病类概念的关系描述框架。
对于其他类概念的主要描述信息,简要列举如下:
• 药物类西药子类实体间常见关系: OTC类型、不良反应、分类、商品名、性状、成分、英文名、药品监管分级、药品类型、规格、适应症
• 药物类中草药子类实体间常见关系: 主治、入药部位、分布区域、别称、功效、属、性味、毒性、界、目、种、科、纲、贮藏、采集时间
• 诊疗技术及设备类实体间常见关系: 就诊科室、所属分类、相关疾病、相关症状、英文名
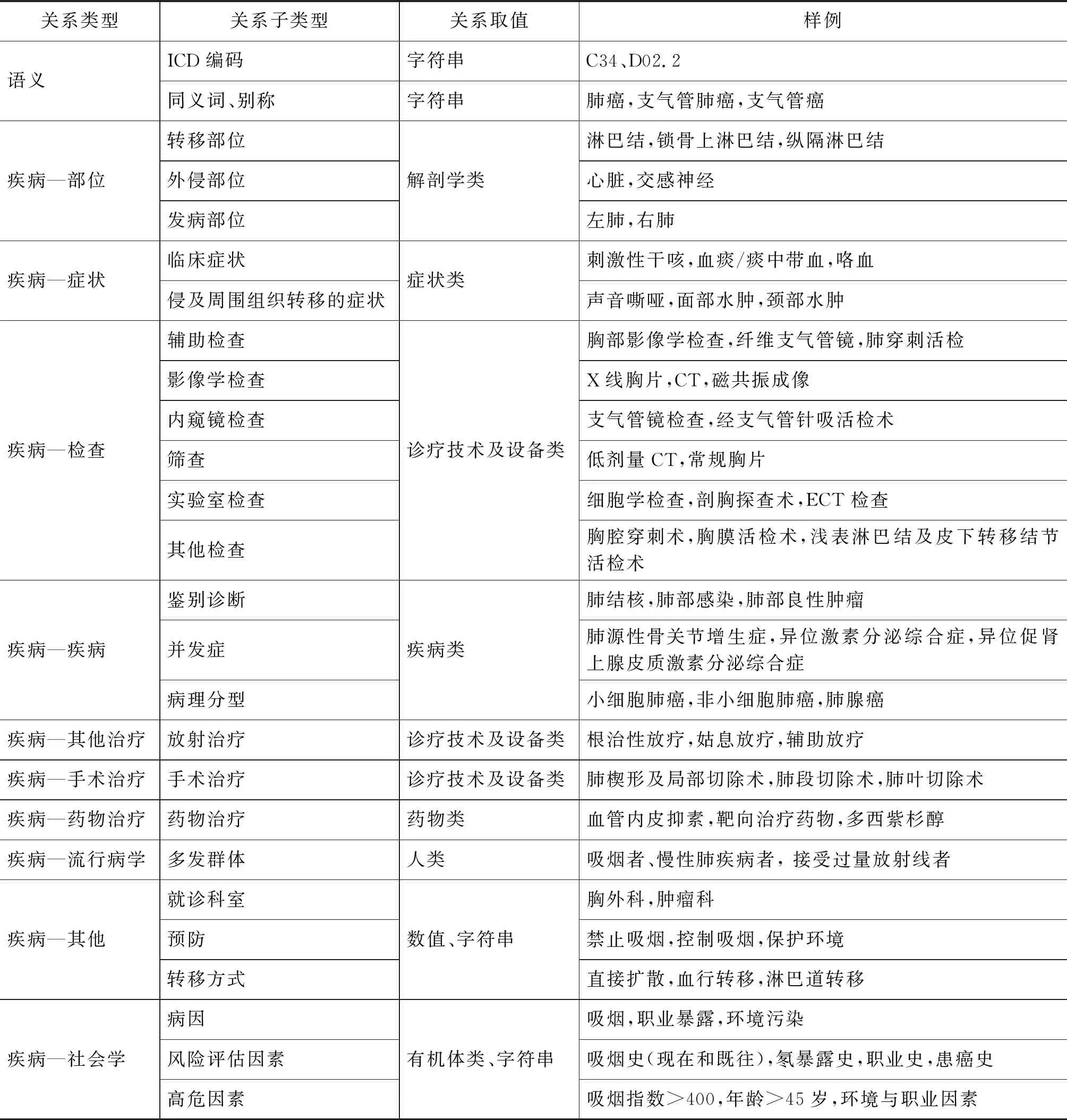
表2 疾病类概念实体的关系描述框架
4 医学知识提取技术
4.1 数据来源
我们在知识提取的过程中根据知识来源的权威性排序,分为: 国际/国家医学标准术语集、医学教材、临床路径指南、临床实践文件和医学百科。CMeKG构建过程中使用了200余个权威的临床路径文档、900余个临床实践文件以及百科类网络资源等多源异构的医学文本数据。
医学标准术语集和医学教材通常是国际或国家级机构统一规定的资源,其优点是权威性高、数据公开可靠。临床路径是针对某一种疾病建立的一套标准化治疗模式与治疗程序,是一个有关临床治疗的综合模式,以循证医学证据和指南为指导来促进治疗组织和疾病管理的方法。临床路径通常包含医院处理某一疾病时的标准指导和流程,具有专业性和权威性。临床实践是面向临床医生和患者提供特定临床情况处理和指导的临床决策支持工具。它将最新的研究成果、诊断步骤、治疗步骤、指南、证据、专家意见整合在一起,为实际临床工作及疑难情况提供可靠的信息。
4.2 自动构建技术
不同的医学文本具有不同的形式特点。基于文本特点,分别使用了基于规则和基于深度学习的两种方法对多来源医学文本信息进行知识提取,本文主要涉及提取医学概念关系三元组信息。自动提取技术框架如图3所示,其中利用基于规则的方法提取临床路径、医学网站和医学百科中的医学知识,利用基于深度学习的方法来提取临床实践中的医学知识。
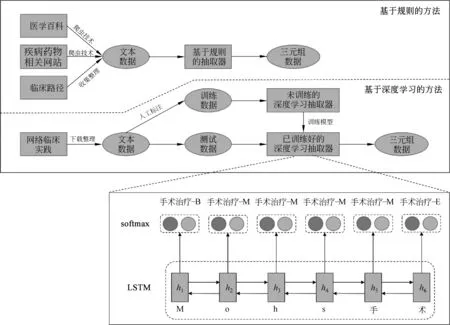
图3 自动提取技术框架
基于规则的知识提取对于临床路径、医学网站和医学百科文本,我们缺乏标注数据,所以难以运用监督学习的方法来从中自动提取三元组。但是,这些数据并非是纯粹的文本,我们在从网络上爬取它们的过程中,同时也获取了它们的半结构化信息,例如,段落层级、标题和小标题信息等。实践发现,在这些半结构化信息的帮助下可以构建一个基于规则的自动提取系统,针对不同来源文本的不同特征,构造出多样化的规则来对其进行概念关系的提取。我们对医学百科数据构造了38类规则,对医学网站数据构造了28类规则,对临床路径数据构造了17类规则,每一类规则由数条更具体的规则所组成,最后在包含了83类、数百条规则的规则系统下,我们从临床路径、医学网站和医学百科文本中提取出了百万量级的概念关系三元组。通过抽样的人工评测,评估了基于规则的知识提取的精确率,对于从临床路径、医学网站和医学百科中提取出来的三元组,其精确率分别达到了97%、96%和94%。
基于深度学习的知识提取随着基于规则提取的三元组数据和人工标注的临床实践数据的积累,我们拥有了足够丰富的资源,已在临床实践数据上实施基于深度学习的医学知识提取。从文本中抽取三元组是一个被研究已久的任务,目前已经存在许多三元组抽取的方法,主要分为两类: 一类是先进行实体识别再进行关系分类的pipeline方法;另一类是同时进行实体和关系抽取的联合抽取方法。但无论是哪种方法,在现有数据集上的实验结果都达不到令人满意的效果,作为医学知识图谱中使用的三元组数据,其精确度一定要有较高程度的保障,否则可能会引来许多问题。我们的任务是从一篇文档中抽取三元组,不同于以往的三元组抽取,其特殊性在于,数据中的一篇文档总是围绕着一个疾病实体来展开的,所以本质上只需要抽取另一个实体以及两个实体之间的关系。如图4所示,对于围绕“皮肤鳞状细胞癌”疾病的文档,我们只需要抽取“Mohs手术”实体以及“手术治疗”的关系即可。

图4 关系提取任务图示
考虑到这样的特殊性,我们提出了一套新的基于标注的三元组抽取方法。我们采取“关系名+BMES”的标注方式,如果某个实体与文档描述的疾病之间存在关系R,则用“R-B”来标注该实体的第一个字,“R-E”标注该实体的最后一个字,“R-M”标注该实体中间的字。如果该实体本身只有一个字,则用“R-S”来标注该实体。其他无关的字我们用“O”来标注。标注方式的示例如图5所示。

图5 “关系名+BMES”标注方式图例
在这样的标注方式下,我们采用了BiLSTM + softmax分类模型来预测每个字的标签,先用双向LSTM得到每个字的隐向量,然后将该隐向量通过MLP和Softmax层,使其变为一个c维的概率向量,其中c为标签种类数。训练时,我们首先按照“关系名+BMES”的标注方法将训练集中的数据进行标注,然后将其送入模型进行学习。测试时,我们首先预测出每个字的标签,然后对标签进行匹配,即每找到一个配对同一关系R的完整的“BMES”集合,我们便取出这个集合对应的实体E,形成一个(疾病名,R,实体E)的三元组。我们的模型结构如图3下方展开的方框部分所示。
我们用该方法在临床实践数据中提取了20余万条三元组数据,通过抽样的人工评测评估了基于深度学习的知识提取的精确率,其精确率达到了89.2%。这样高精确率的自动提取方法在大幅提升知识库构建效率的同时,能够保证知识库内容的高度可靠性。
5 中文医学知识图谱CMeKG 1.0
我们在医学专家的配合下,制订了医学知识描述体系,收集了多来源的大规模医学文本,通过人工标注和自动提取方法相结合,构建了中文医学知识图谱CMeKG。CMeKG 1.0版包括6 310种疾病、19 853种药物、1 237种诊疗技术及设备,涵盖疾病的临床症状、发病部位、 药物治疗、手术治疗、鉴别诊断、影像学检查、高危因素、传播途径、多发群体、就诊科室等以及药物的成分、适应症、用法用量、有效期、禁忌证等常见关系类型,关联到的医学实体达20余万,CMeKG目前的概念关系实例及属性三元组达100余万。同时,基于以上医学实体和关系三元组,我们开发了CMeKG的展示平台,网址为:http: //cmekg.pcl.ac.cn/。
CMeKG使用百度开源可视化库Echarts[16]展示知识图谱,平台展示内容主要包括树状结构和网状图谱两部分,提供的功能包括实体的搜索、匹配、图谱的链接和遍历。对于每一个实体,选择以该实体为主语的三元组进行显示,连接同一节点的相同颜色节点代表相同的语义关系,整体效果呈现为以查询实体为中心,具有语义关系的相关实体发散至四周的网状结构,如图6所示。
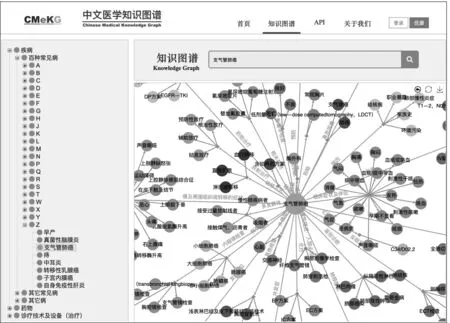
图6 CMeKG结果展示图
6 结束语
我们对医学知识图谱的构建研究才刚刚起步,本文综述了CMeKG 1.0构建过程中的描述体系、关键技术、构建流程以及初步的构建结构。我们认为,未来服务于智慧医疗的知识图谱应该满足以下方面的要求: 知识来源具有权威性、知识组织具有系统性、知识内容具有丰富性、知识描述具有精准性、知识更新具有高效性。因此,医学知识图谱的构建任重而道远,在未来我们将朝着构建大规模、高质量、融合文本、图像与视频等多模态信息的医学知识图谱的方向继续努力。
致谢
感谢郑州大学第一附属医院牛承志老师、郑州大学第三附属医院赵悦淑主任及北京大学医学部詹思延教授给予的指导建议!
