面向问句复述识别的多卷积自交互匹配方法研究
2019-10-21李伟康周夏冰
陈 鑫,李伟康,洪 宇,周夏冰,张 民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
问句复述识别[1],旨在判定两个自然问句是否表达相同的语义,即是否互为语义相同但表述不一的同质异构的问题类语言单位。通常,问句复述识别可被归结为二元分类任务。问句复述识别是自然语言处理领域中一项基本且富有挑战性的任务,不仅是因为其需要识别语句表述上的迥异,且需要在语义表示学习的层面上感知问题的主旨、意图和目标。比如,下例中的问句1与问句2虽具有较为一致的表述方式,但是两者的语义不同,不是复述关系。
问句1:WhatisthestepbystepguidetoinvestinsharemarketinIndia?
(译文: 在印度的股票市场中,什么能够逐步地引导投资?)
问句2:Whatisthestepbystepguidetoinvestinsharemarket?
(译文: 什么能逐步引导股票市场的投资?)
与此相对的是,下例中的问句3与问句4具有完全不同的表述方式,尽管如此,两者之间的语义一致,互为复述关系。
问句3:HowcanIbeagoodgeologist?
(译文: 我怎么能成为一名优秀的地质学家?)
问句4:WhatshouldIdotobeagreatgeologist?
(译文: 我应做什么才能成为一名伟大的地质学家?)
除此之外,问句复述识别与陈述句复述识别[2]不同之处在于,存在一种“问题词不一致但问题含义一致”的语言现象,如上例问句3与问句4所示。这一现象使得问句复述识别任务相较陈述句复述识别具有更高的复杂性。
针对以上问题,前人研究通过构建复杂的深度神经网络模型,或引入大规模外部数据进行模型预训练予以解决。例如,BiMPM[3]等模型对问句进行深度的语义向量编码,再通过融合进行二元分类。虽然上述模型方法在效果上已达到较高水平,但模型复杂度与训练难度都较高。类似地,DECATT[4]模型虽然复杂度与训练难度较低,但其通过引入上千万规模的噪声数据进行预训练,使得该模型预训练难度较高。而同期的MatchPyramid[5]等模型,虽然复杂度低,训练速度快,但性能与BiMPM模型相比,尚有较大提升空间。
本文针对模型复杂度、训练难度与模型性能能否兼得的难题进行了探索,提出了一种多卷积自交互匹配神经网络模型(multi-convolution self-interaction matching neural network,MCSM)。首先,MCSM模型通过融合多种句子特征与预训练的词向量对句子进行词级别向量表示;然后,基于卷积神经网络(convolutional neural network,CNN)[6]构建的多卷积自交互句子编码方法对句子进行多粒度特征向量编码,并在此基础上利用多种池化操作进行特征抽取;最后,将抽取的句子特征进行简单有效的元素融合,用于二元分类输出结果。利用这一模型,本文实现了对两个问句是否互为复述的二元分类任务。经实验验证,该模型与前沿工作在性能上可比,但复杂度和训练难度均显著低于前沿工作。本文的主要贡献可以归纳如下:
① 提出基于CNN的多卷积自交互句子向量编码表示方法,实现对句子在词级与短语级上的多粒度特征融合编码表示。
② 在标准的Quora复述识别语料上进行实验,实验结果表明,该模型在性能上与前沿工作可比的同时,模型复杂度低,且极易训练。
本文组织结构如下,第1节简要回顾前人研究并给出相应分析;第2节具体介绍MCSM模型的架构与具体流程;第3节给出实验及结果,并对比分析方法性能;第4节给出总结与展望。
1 相关工作
早期的复述识别研究是基于特征工程,通过构建有效特征进行分类。这些特征包括:
① 字符串相似度指标,例如: n-gram重叠得分[7]与BLEU得分[8];
② 解析结构的句法特征[9];
③ 通过潜在语义分析获得的分布特征[10]。
而随着深度神经网络技术的发展,近期的复述识别的研究工作从特征工程转向利用深度神经网络构建模型进行二元分类,主要模型架构可以分为以下两类。
1.1 基于句子向量表示的模型架构
通过对两个句子进行向量编码表示,将两个句子向量表示进行拼接、逐元素做差取绝对值、元素对应位相乘等聚合操作,然后通过二元分类得出结果。例如Siamese-RNN与Siamese-CNN模型[11],利用相同的循环神经网络(recurrent neural network,RNN)或者卷积神经网络(convolutional neural network,CNN)对句子进行向量编码表示,然后再对两个句子向量处理后进行二元分类。这类模型架构的缺点在于句子之间没有任何交互,可能丢失来自另一个句子的重要信息。所以,一种改进的模型架构被提出,其通过注意力机制让两个句子在编码过程中充分交互影响,得到更好的句子表示。例如,BiMPM模型利用双向长短期记忆网络(bidirectional long short term memory network,Bi-LSTM)分别对句子进行向量编码表示,接着采用4种不同的注意力计算方式对两个句子进行交互,优化句子向量表示,最后再通过聚合操作将两个句子的表示聚合进行二元分类,但此类交互过程繁重复杂。
1.2 基于句子融合向量抽取特征的模型架构
不同于句子向量表示的模型架构主要关注于如何更好地进行句子向量编码表示,该模型架构主要是基于两个句子的融合向量表示进行联合特征抽取,利用抽取的句子联合特征做二元分类,更关注于如何抽取更优的联合特征。例如MatchPyramid模型在利用预训练词向量进行句子向量表示之后,将两个句子向量表示进行元素乘融合,利用CNN与最大池化对句子联合表示进行高维度特征抽取,将抽取的高维特征用于二元分类。这类模型架构更关注于如何更好地抽取句子联合特征,对于句子的向量表示不够充分,有时只是利用预训练的词向量进行简单的表示。
2 多卷积自交互匹配方法(MCSM)
2.1 模型概览
首先,问句复述识别任务定义如下: 给定两个自然问句P和Q,P=(p1,…,pj,…,pm),Q=(q1,…,qi,…,qn),m、n分别表示P与Q的长度,pi、qj分别表示P与Q中第i个与第j个单词,需要识别问句P与Q是否互为复述。对此,本文提出一种多卷积自交互匹配神经网络(multi-convolution self-interaction matching neural network,MCSM),它属于基于句子向量表示的模型框架。模型整体框架如图1所示。

图1 多卷积自交互匹配模型架构
MCSM模型通过词向量层、句子编码层快速高效地对句子进行向量编码表示,通过特征抽取层从句子向量表示中抽取特征,最后经过融合输出层进行二元分类。
词向量层: 该层目标是将句子中的每个单词编码成一个维度为d的向量表示,将句子中的每个单词表示拼接得到词级的句子向量表示。与阅读理解任务中QANet模型[12]利用高速网络(highway network,Highway)[13]对字符向量与词向量融合方法类似,MCSM模型通过构建短语特征(phrase feature,PH)、词共现特征(word exact match feature,EM)、位置特征(position embedding feature,PE)与预训练的300维的GloVe词向量[14]拼接,采用Highway网络快速地进行融合,得到词级句子向量编码表示。这些特征与Highway网络的具体信息将在3.2节详细介绍。
句子编码层: 该层是MCSM模型的核心层,目的是进行高效、快速的多粒度句子特征向量编码表示。句子编码层利用本文提出的多卷积自交互编码方法(multi-convolution self-interaction encoder,MCSE)对句子进行编码,不同于BiMPM等模型利用双向循环神经网络(bidirectional long short term memory network,Bi-LSTM)对句子进行编码表示,MCSE以CNN为基础对句子进行编码。MCSE对句子编码过程可视化过程如图2所示。其中,假设卷积窗口为2,Hp是词级的句子向量表示,将句子中每个词的向量表示与卷积出的短语特征向量表示融合,得到最终的多粒度特征向量表示Emulti_p。本文将在3.3节给出MCSE的具体过程和细节。

图2 MCSE句子编码可视化过程
特征抽取层: 该层目标是从句子向量表示中抽取特征。例如,对于句子P的表示Emulti_p,通过最大池化和平均池化操作,将两者进行拼接获得最终的句子特征向量表示Ef_p,具体计算公式如式(1)所示,其中Maxp与Meanp分别表示最大池化与平均池化操作,[: ]表示拼接操作。
Ef_p=[Maxp(Emulti_p): Meanp(Emulti_p)]
(1)
融合输出层: 该层是MCSM模型的最后一层,在获取句子P、Q的特征向量之后,通过简单的元素乘操作进行融合,最后通过一层全连接层网络并使用softmax激活函数进行二元分类,得到最终的分类结果。
2.2 句子特征
在词向量层,本文通过构建简单有效的句子特征来帮助模型更好地进行句子向量编码表示。MCSM模型是基于CNN对问句进行语义编码,考虑到CNN通过设定的滑动窗口依序对自然问句进行短语向量卷积,本文因此提出短语特征PH,旨在利用该特征将自然问句中的自然短语标识出来,使得模型在利用CNN进行卷积时能够得到更优的句子短语向量表示。此外,通过观测大量语料发现,在两个自然问句中出现的不同单词对两个问句是否互为复述起着较为重要的作用,例如引言中的问句1与问句2中不相同的单词“in India”使得两个问句不互为复述,因此本文提出词共现特征EM来帮助模型更好地对两个问句进行语义编码。同时,因为CNN不能像Bi-LSTM一样捕获句子中单词的相对位置信息,本文通过构建位置特征PE进行弥补。以下是三种特征的具体构造方法。
短语特征PH: 通过spacy标识出句子中的名词短语,利用0-1标签将名词短语的单词对应标签标注为1,其余为0。每个句子能够得到一个对应的短语特征标签PH。通过将PH的0、1标签分别随机初始化成300维的向量,将句子的PH特征映射成特征向量EPH,即PH特征向量。
词共现特征EM: 通过比较两个句子P、Q中的每个单词是否同时出现得到。如果单词同时出现在P、Q中,单词对应的EM标签为0,否则标签为1。得到EM特征之后,通过将0、1标签分别随机初始化成100维向量,得到特征向量EEM,即EM特征向量。EM特征虽然简单,但是在阅读理解任务中的DrQA[15]被验证有效。
位置特征PE: 具体采用学者Vaswani A等[16]提出的位置向量计算公式,进行位置特征向量的构建。具体的计算公式如式(2)、式(3)所示。
其中,pos是指单词在句子中的具体位置,例如句子中的第一个单词,对应的pos为1。C表示一个常数变量,Vaswani A等将其值设为10K。dPE表示的是位置向量的维度。i是指dPE中的具体的序号,PE(pos,2i)与PE(pos,2i+1)分别计算的是位置向量中偶数位、奇数位上的具体数值。实验中,dPE设置为50,则i的取值为0~25。通过式(2)~(3)计算,最终得到位置向量EPE。
在获得以上三种特征向量之后,将这三种特征向量与GloVe词向量进行拼接,通过一层Highway网络对这些特征向量进行简单快速地融合。Highway网络的提出是为了解决深层次网络训练困难的问题,允许信息高速无阻碍的流动。整个过程计算公式如式(4)~(7)所示。
其中,Ex是拼接三种特征向量表示与词向量表示的句子表示,T是计算得出的门控矩阵,C是线性操作调整后的句子表示,利用式(7)得出最后融合多种句子特征与词向量信息的词级句子表示H。其中,W1、W2、b1、b2是随机初始化的参数,随模型训练进行更新,并且本文三种特征向量也随着模型训练而进行更新。本文在3.3.2节分析三种句子特征对模型的影响。
2.3 多卷积自交互编码方法(MCSE)
目前,传统的句子编码方法主要是基于CNN与LSTM对句子的词向量表示进行编码。其中,基于CNN的句子编码方法主要根据设置的窗口大小n,依次按序对句子中连续n个单词的词向量表示进行卷积操作,得到短语级的向量表示,最终将多个短语级向量表示拼接得到整个句子的向量表示。但是在自然语句中不是所有连续的单词能够组成短语,对于不能构成短语的n个单词,传统的基于CNN句子的编码方法仍然将其作为短语进行向量卷积,得到的短语级向量表示相对于原有n个单词的词向量表示,可能在语义表示上会出现一些错乱。而基于LSTM的句子编码方法,由于LSTM具有时序依赖特性,对句子进行编码时无法像CNN那样进行并行编码,只能串行编码导致效率较低。因此,本文提出一种多卷积自交互编码方法MCSE,能够将基于CNN卷积得到的短语级句子向量与原有的单词级句子向量进行充分融合,得到多粒度句子向量表示,以缓解传统的基于CNN句子编码方法中一些语义向量表示错乱的问题,同时句子编码效率高于基于LSTM的句子编码方法。在3.4.2节将会具体分析对比MCSE与基于CNN、LSTM句子编码方法。
MSCE通过两个参数不共享的CNN对同一句子向量进行短语级特征抽取,将其中一个抽取特征作用于原有词级别特征与另一个短语级特征交互融合的过程中,具体程如图3所示。
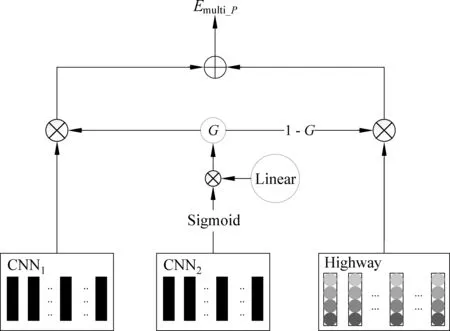
图3 MCSE编码过程
对问句P进行句子编码,词向量层输出的句子表示为Hp,MCSE的具体步骤如下:
① 通过两个参数不共享的CNN,采用相同尺寸的卷积窗口和相同数目的卷积核,同时对句子P的向量表示Hp进行卷积操作,得到短语级卷积特征向量E1cnn_p与E2cnn_p,卷积特征向量具体计算公式如式(8)~(11)所示。
其中,k是卷积核窗口大小,W与b为随机初始化参数,随模型训练进行调整。式(11)是卷积特征向量中每个特征fpi具体计算过程。同时,每个卷积通过自动填充的方式保持卷积结果形状与输入形状一样。
② 将短语级别卷积特征向量E2cnn_p做如式(12)所示计算,得到一个融合门控矩阵G。
G=W·Sigmoid(E2cnn_p)
(12)
其中,对问句P与Q进行MCSE编码时,共享同一个线性操作。这使得问句P与Q之间在计算各自门控矩阵G时有一种直接的交互影响、间接影响得到的多粒度句子向量表示。共享线性操作对MCSM模型性能影响在3.4节具体分析。
③ 利用计算得到的融合门控矩阵G,融合词级别特征向量与短语级别特征向量,得到多粒度句子向量表示Emulti_p,具体计算如式(13)所示。
Emulti_p=HP·(1-G)+G·E1cnn_p
(13)
通过公式(13),能够将词级别上的特征向量HP与短语级别卷积特征向量E1cnn_p通过融合控制矩阵G进行对应融合,得到更好的多粒度特征句子表示Emulti_p。
3 实验设置与结果分析
3.1 实验数据与评价指标
本文采用来自Quora的数据集QQPD(全称为“Quora question paraphrase dataset”),该数据集包含超过400 000的问句对,并且每个问句对都有一个二元标签,标识问句对是否互为复述。本文使用与BiMPM相同的数据集(1)https: //github.com/zhiguowang/BiMPM划分。其中,训练集有384 348条,包含正样本139 360条,负样本245 042条;开发集与测试集各有10 000条,各包含正负样本5 000条。本文采用准确率对性能进行评价。
3.2 实验参数设置
本文利用公开的来自840B Common Crawl语料训练的300维GloVe词向量,对句子单词进行向量表示,对于不在词袋的单词,MCSM将其映射为一个随机初始化的向量。对于短语特征PH、词共现特征EM、位置特征PE,MCSM分别对应初始化300维、100维、50维的特征向量。对于句子编码层中的CNN,卷积窗口大小设置为5,卷积核个数为750。MCSM训练时采用动态dropout,具体公式如式(14)、式(15)所示。
其中衰减率dr为0.997,间隔步长s为10k,W是初始步长,随训练按序增长,sr是计算得到的按训练步长而变化的衰减率,初始衰减率ir为1.0。MCSM分别在词向量层、特征抽取层进行动态dropout。训练时,如果连续5轮迭代开发集数据性能没有提升,就按照表1所示,按顺序进行优化函数与学习率的切换。

表1 优化函数配置
3.3 实验结果分析
本文分别从模型性能、复杂度与序列操作次数、GPU显存开销与训练数据一轮迭代所需时间这3个维度上进行分析。
3.3.1 性能分析
模型在开发集与测试集上的准确率如表2所示。其中前4行数据取自BiMPM的工作;MatchPyramid模型性能是利用MatchZoo[19]复现得到;第6行至第7行的数据取自DECATT[2]的工作,Pt-DECATTword与Pt-DECATTchar是引入外部数据Paralex[20]语料作为噪声数据进行预训练得到。Pt-DECATT将3 600万的Paralex语料做为正样本,构造将近6 400万负样本,整个预训练噪声数据规模将近1亿。
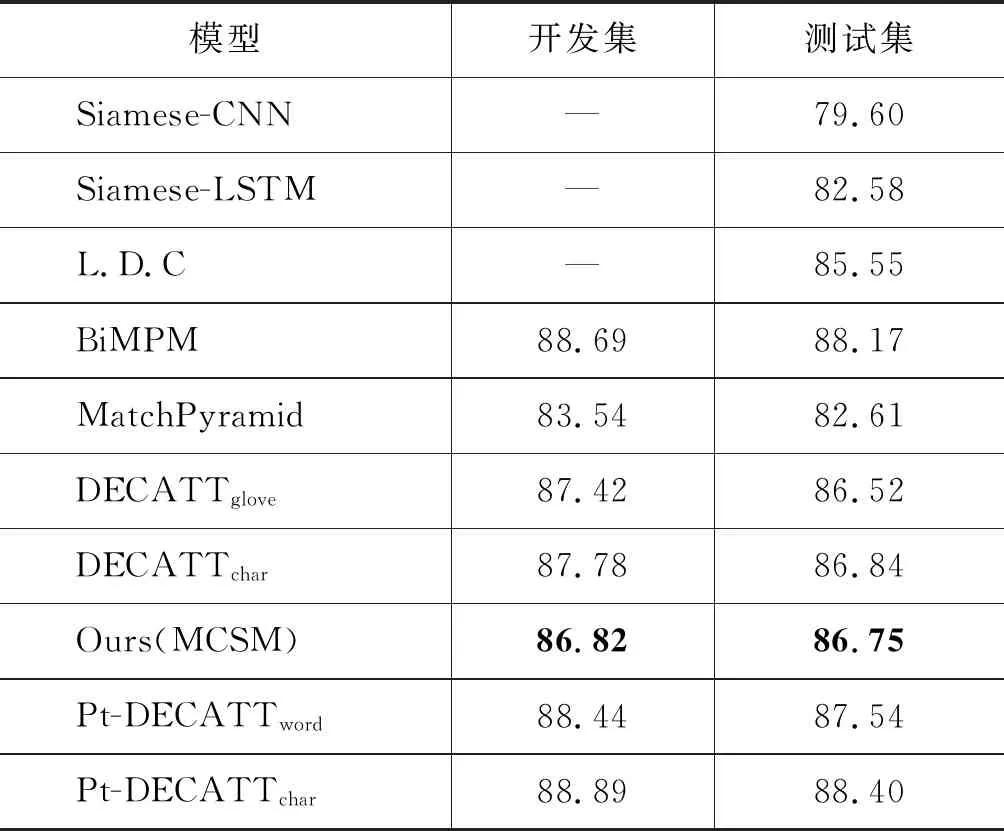
表2 Quora语料上实验结果
(注: “开发集”和“测试集”两列对应的单位为“%”)
从表2结果具体分析,MCSM模型在测试集上性能略低于通过大规模外部数据预训练得到的Pt-DECATTword与Pt-DECATTchar。而在不引入外部数据的条件下,MCSM在测试集上的性能与DECATT相差无几,而与Siamese-CNN、Siamese-LSTM、MatchPyramid相比,MCSM准确率提升4%以上,比L.D.C提升1.2%,MCSM只比BiMPM准确率略低1.42%。综上,在不引入外部数据的情况下,本文所提MCSM模型性能优于大多数模型,且接近前沿模型性能。
3.3.2 模型复杂度分析
本文对基线模型与MCSM模型进行复杂度分析。如表3所示,前3行是学者Vaswani A等[14]给出的单独一层自注意力、RNN、CNN模型复杂度与序列操作次数分析结果,其中n表示序列长度,d表示向量维度,k表示卷积核个数,其中RNN具有时序依赖性无法并行操作,所以序列操作次数是O(n)。因为基线模型与MCSM模型都分别用到注意力、RNN与CNN,所以本节以这三者的复杂度与序列操作次数为基准对各个模型进行复杂度分析。
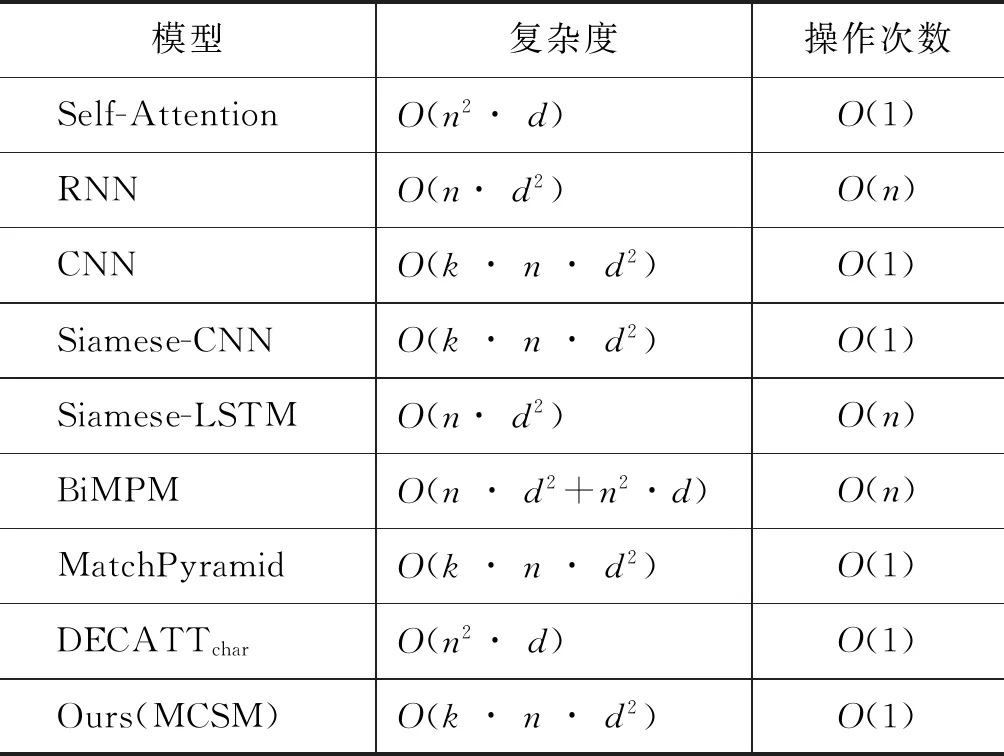
表3 模型复杂度分析
本节选取5种基线系统进行复杂度分析,结果如表3所示。首先,由于RNN无法并行,所以综合复杂度与操作次数比较,RNN要比CNN复杂,而一般而言,n要小于d,所以CNN要比注意力复杂一些,但两者相差不大。同时,BiLSTM是基于RNN的变种,在复杂度上要高于RNN,更远高于CNN与注意力。而BiMPM模型主要架构有2个BiLSTM与4×2个注意力(由于BiMPM中的注意力是双向的);MCSM模型主要架构是4个CNN;同时,Siamese-CNN、MatchPyramid两种模型的主要架构分别是1个CNN与2个CNN,Siamese-LSTM的主要架构是1个BiLSTM,DECATTchar模型主要架构相当于2个注意力。所以,综合表3中复杂度与操作次数两个维度比较,MCSM模型远低于BiMPM;稍微低于Siamese-LSTM;与Siamese-CNN、MatchPyramid相当;比DECATTchar略高。
3.3.3 模型训练难易度分析
本节选择复现Siamese-CNN、Siamese-LSTM、BiMPM、DECATTchar,通过与MCSM在GPU显存使用大小与训练迭代速度上进行对比。以上模型均在英伟达GeForce GTX 1080的实际环境中运行得出的结果,其中,Siamese-CNN、Siamese-LSTM采用MatchZoo以Keras进行复现,MCSM是以Keras实现,BiMPM通过Tensoflow进行复现,DECATTchar采用Pytorch进行复现(2)https: //github.com/Robertren/NeuralParaphraseWithPretrain,虽然模型复现框架有所不同,但是对模型使用GPU内存与迭代一轮训练速度影响不大。最终,模型训练过程需要占用的GPU显存大小和迭代一轮训练语料所需时间如表4所示。
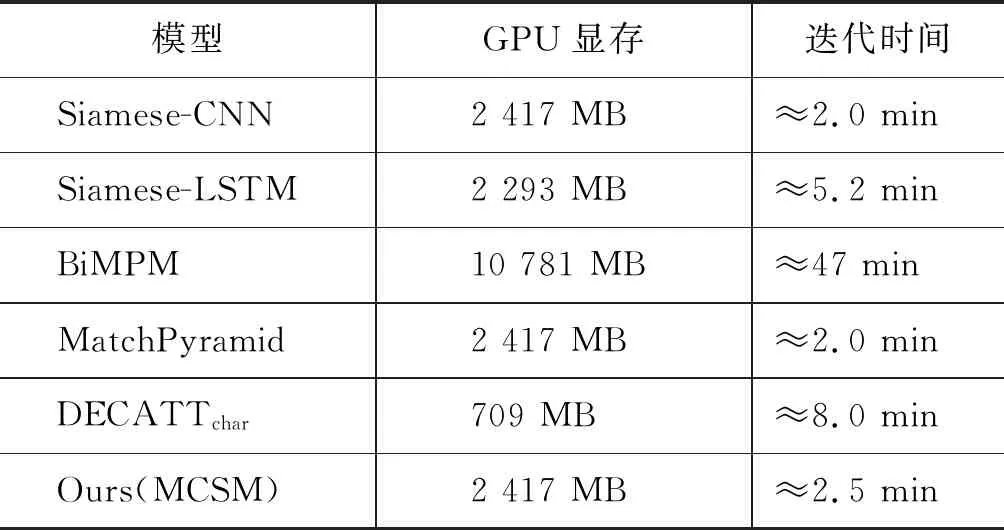
表4 GPU内存与时间开销
从实验结果可以发现,MCSM模型训练速度比BiMPM快将近19倍左右,训练所需的GPU显存比BiMPM下降大约80%。MCSM与DECATTchar相比,虽然训练所需GPU显存更多,但是MCSM训练速度比DECATTchar快3倍多。而Siamese-CNN、Siamese-LSTM与MCSM相比,所需GPU显存使用相差无几,速度上Siamese-CNN最快,其次是MCSM,最慢的是Siamese-LSTM,但是三者间训练数据迭代一轮所需时间差距不大。综上,MCSM模型训练难度低。
3.3.4 综合分析
综合模型性能、复杂度与训练难易度三者进行分析,本文所提MCSM模型在这三者之间达到最优的平衡。训练迭代速度、模型复杂度优于或接近MCSM的基线模型,性能上都低于MCSM,如Siamese-CNN和MatchPyramid;性能上与MCSM接近的基线模型,训练迭代速度比MCSM要慢,如DECATT模型;性能上优于MCSM的基线模型,复杂度与训练难度都远超过MCSM,如BiMPM模型。
3.4 MCSM模型有效性分析对比
本节分别对本文所提句子特征与多卷积自交互句子编码方法MCSE进行有效性实验分析对比。3.4.1节对句子特征进行分析,3.4.2节对MCSE句子编码方法进行分析。通过这两节的分析对比,验证确定本文所提MCSM模型性能提升的内在原因,辅助以后进一步完善模型提升性能。
3.4.1 句子特征分析
针对词向量层中的3种句子特征,本文通过分别去除一种特征进行实验,然后将这三种特征全部去除进行实验对比。最终实验结果如表5所示。

表5 句子特征性能分析
(注: “开发集”和“测试集”对应的单位为“%”)
从实验结果中可以发现句子短语特征对模型性能影响最低,位置特征对模型影响次之,词共现特征对模型影响最大。三种特征全去除,只使用GloVe词向量,整个模型性能下降2.03%。同时,本文基于Siamese-CNN、Siamese-LSTM模型,通过添加3种句子特征进行性能对比,如表6所示,Siamese-CNN与Siamese-LSTM的结果取自BiMPM的工作,而Siamese-CNN+、Siamese-LSTM+表示是添加3种句子特征后复现得到的结果。从表中结果可知,添加3种句子特征之后的模型相较于原有模型在测试集性能上均有所增加,由此,可以得出本文构造的3种句子特征对于其他模型也有效。综上所述,本文构建的三种句子特征简单有效。
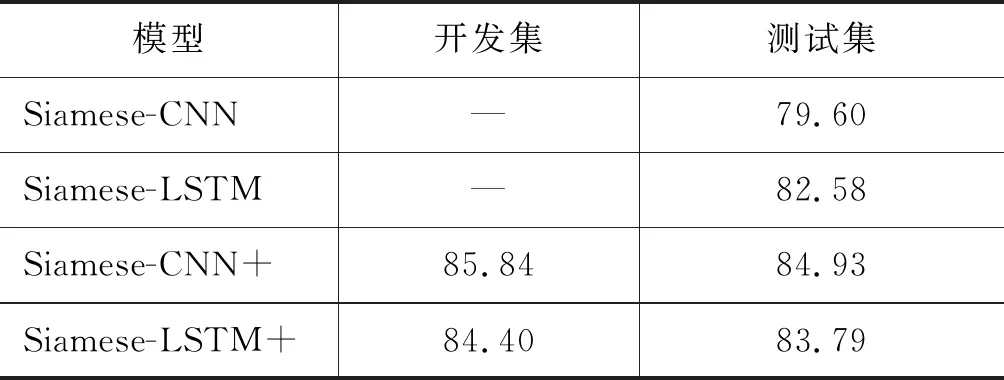
表6 基于基线模型的句子特征实验
(注: “开发集”和“测试集”对应的单位为“%”)
3.4.2 多卷积自交互编码方法有效性分析
本节通过更改MCSM模型中句子编码层的编码方法,将多卷积自交互句子编码(MCSE)方法替换成Bi-LSTM与CNN,保持模型其他层相同,通过实验结果分析MCSE与其他句子编码方法之间的差异性。具体的实验结果如表7所示,其中“+LSTM”、“+CNN”是指分别以Bi-LSTM、CNN替换MCSE的模型,“MCSE”指没有进行替换的模型。
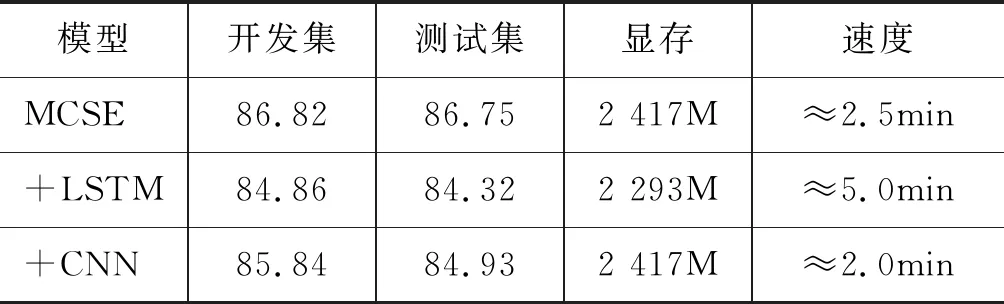
表7 MCSE与Bi-LSTM、CNN对比分析
(注: “开发集”和“测试集”对应的单位为“%”)
从实验结果可以发现,基于MCSE句子编码的模型不仅性能比基于Bi-LSTM句子编码的模型在开发集与测试集上分别高1.96%、2.43%,而且迭代一轮训练数据的速度也比基于Bi-LSTM的模型要快将近2倍;而MCSE与基于CNN的模型相比,由于MCSE复杂度高于CNN,迭代速度上比基于CNN句子编码的模型慢一些,但是在开发集与测试集上分别比基于CNN的模型高0.98%、1.82%。综上,本文所提MCSE句子编码方法实验性能与训练难易度上都优于基于Bi-LSTM的句子编码方法,同时MCSE句子编码方法得到的多粒度句子向量表示比基于CNN得到的短语级句子向量表示更优,最终模型性能高于基于CNN的模型。
在MCSE方法中,两个句子的编码过程共享一个线性操作对各自的交互矩阵G进行影响调节,本文通过实验对共享线性的影响进行探究,实验结果如表8所示,其中“MCSM+”表示拥有共享线性操作的模型,“MCSM-”表示没有共享线性操作的模型。实验结果表明没有共享线性的MCSM-比有共享线性的MCSM+在测试集上性能下降0.36%,虽然性能下降不多,但是仍能表明MCSE通过句子间共享线性操作,对两个句子编码过程实现简单有效的句间交互,得到更好的句子向量编码表示。因此,对于未来相关研究,需要我们探究如何更优地进行两个问句间的交互表示。
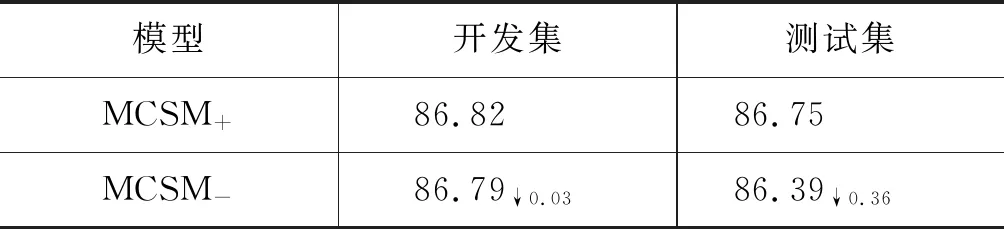
表8 共享线性操作分析
(注: “开发集”和“测试集”对应的单位为“%”)
3.5 测试结果分析
QQPD的测试集数据共有10 000条,我们按照莱文斯坦距离对测试数据集进行划分。其中,莱文斯坦距离是编辑距离的一种,又称Levenshtein距离,在本节主要指一个问句转换成另一个问句所需要的最少编辑单词操作次数。莱文斯坦距离越大,说明两个自然问句之间差异越大,不一样的单词越多。下文的编辑距离都代指莱文斯坦距离。按照编辑距离分布划分测试数据,具体数据分布如图4所示。其中,横坐标是按照编辑距离大小进行划分,纵坐标是标识具体的数据量大小。
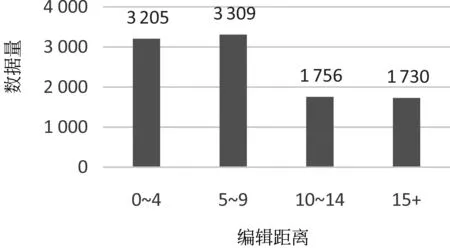
图4 测试集数据分布图
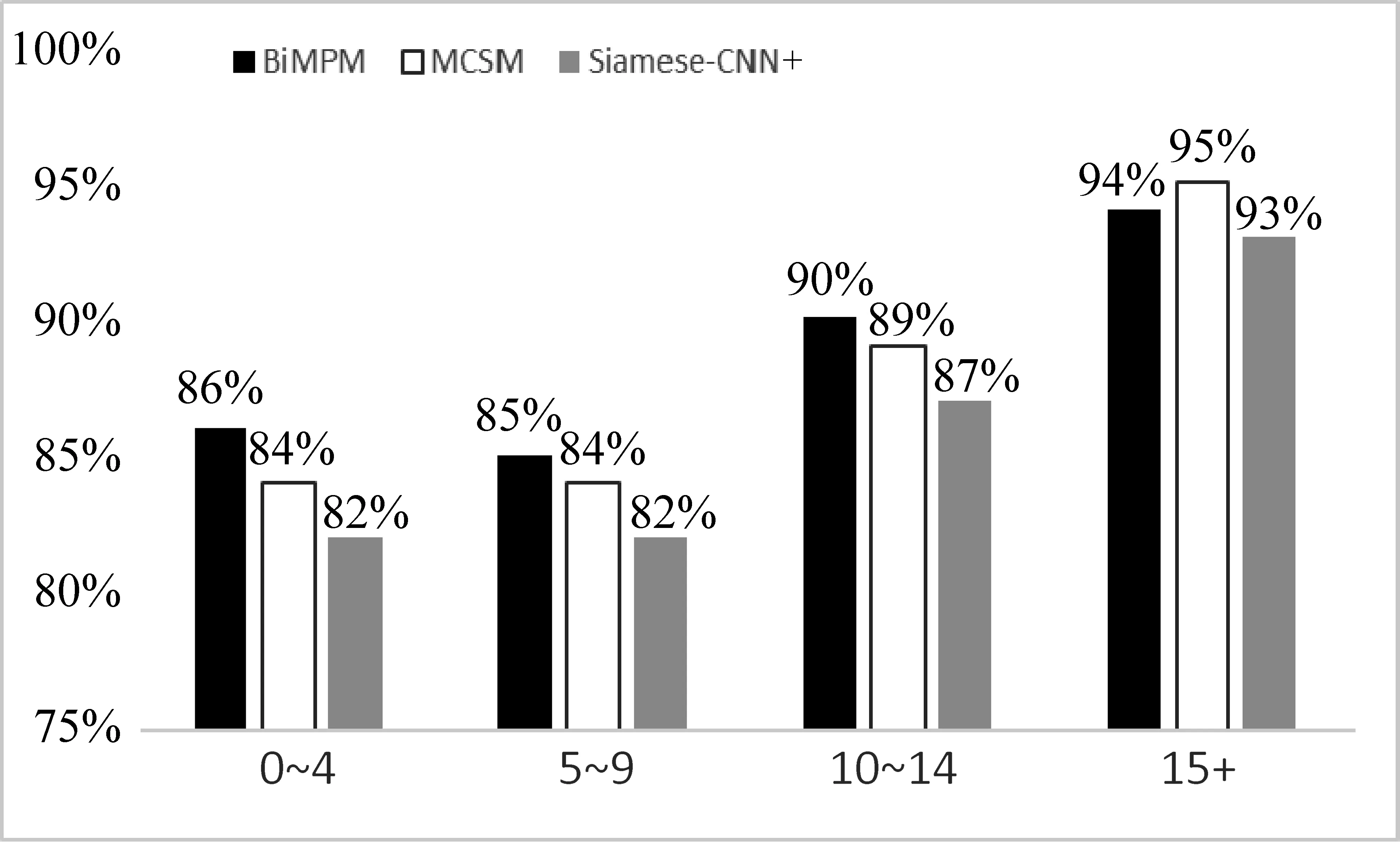
图5 模型正确率分布图
从图4中我们可以发现,编辑距离在10以内的数据约占总数据量的65%以上。本节取基线模型BiMPM、MCSM、Siamese-CNN+的测试结果进行分析对比,其中Siames-CNN+与BiMPM的实验结果是本文复现得到的,并且 Siamese-CNN+是添加3种句子特征的模型,两者在测试集上准确率分别为84.93%、87.78%,MCSM模型在测试集上的准确率为86.75%。将这三种模型在测试集上按照编辑距离进行划分,得出如图5所示的各个编辑距离正确率数据分布图,其中横坐标是编辑距离分布,纵坐标是准确率。从图5数据的分布上,我们可以发现,三种模型分布在编辑距离为10以内的数据上准确率不高,随着编辑距离的增加,模型的准备率逐渐增加。由此可以发现问句复述识别难点在于如何更好地识别较为相似问句之间的复述关系。其次,分别比较三种模型在各个编辑距离分布上的准确率,我们发现BiMPM在编辑距离较小的数据上,准确率都比较高,可能原因在于BiMPM模型虽然复杂度高,但是对两个问句间的交互充分,对于编辑距离小的数据,能够通过充分交互更好地理解句子语义。而MCSM模型对句间交互不够充分,在编辑距离小的数据上准确率略小于BiMPM,但是在编辑距离大的数据上,MCSM模型要更有效些。
接着,我们取出具体样例数据进行分析。首先如问句5与问句6所示,它们真实标签为0,表明两者不互为复述,MCSM模型预测为不是复述,预测正确。问句5与问句6之间最大的语义差异来源于问句5中“thinkofhimself”,这个短语使得问句5的语义与问句6截然不同,很显然MCSM模型通过构建的句子特征与MCSE句子编码方法将这个短语语义捕获,在最后进行分类时得出正确的答案。
问句5:DoesDonaldTrumpthinkofhimselfasacharlatan?
(译文: 唐纳德特朗普认为自己是骗子?)
问句6:IsDonaldTrumpacharlatan?
(译文: 唐纳德特朗普是骗子吗?)
Truth: 0 Prediction: 0
但是,问句7与问句8的真实标签为1,互为复述,MCSM模型预测错误,但BiMPM模型对此预测正确。具体分析问句7与问句8,我们发现两者主要差异在于问句7中“canIget”与问句8中“doyoufind”,BiMPM通过4种不同的注意力对问句7与问句8进行充分的语义向量交互得到更优的语义向量表示,使得BiMPM得出正确的结果。而MCSM模型为得到更简单的复杂度与更快的训练速度,在句间交互上不够充分,在句子向量语义编码中可能受两个不同主语的影响,得出两者不互为复述的结论。
问句7:HowcanIgettheproductnamefromaWalmartreceipt?
(译文: 我如何从沃尔玛收据中获取产品名称?)
问句8:HowdoyoufindproductnamesfromaWalmartreceipt?
(译文: 您如何从沃尔玛收据中找到产品名称?)
Truth: 1 Prediction: 0
综上,未来研究工作一方面需要研究对编辑距离小的问句对进行更好句子语义编码;另一方面,如何在保证模型复杂度不会过高的前提下,更好地进行问句间的语义交互匹配,以此得到更优的句子向量表示,这些需要更为深入的研究。
4 总结与展望
本文针对问句复述识别,提出了一种快速轻巧的多卷积自交互匹配模型MCSM。首先,本文通过构建3种简单有效的句子特征帮助模型更好地进行句子编码;其次,本文提出一种基于卷积神经网络的多卷积自交互句子编码方法,将词级别句子特征与短语级别句子特征进行多粒度融合,得到语义信息更丰富的句子向量表示;最后利用池化操作抽取特征进行二元分类。本文在Quora标准复述识别语料上进行实验,实验结果证明,MCSM模型与基线模型BiMPM在性能上可比的同时,模型复杂度大幅降低,更易训练。具体而言,MCSM训练所需GPU显存比BiMPM下降大约80%,迭代训练速度快19倍左右。
未来工作中,我们一方面将MCSM模型扩展到答案排序和自然语言推理等任务中。另一方面,结合实验结果的错误分析结果,相似问句的复述识别与两个问句编码间的高效交互,也将成为后续的重要研究点,以此保证在模型复杂度不会大幅提高的前提下,通过更好的句间编码交互捕获更优的句子向量表示,进一步提升模型性能。
另外,在中文问句复述识别的研究上,本文提出的词共现特征EM,对应中文复述语料也有作用,识别两个中文问句是否互为复述,两个问句中不一样的汉字也对结果起着更为关键的作用;其次,本文所提的MCSE句子编码方法对于中文句子的编码表示也有一定启发意义; 最后,考虑到中文的词语比英文蕴含更丰富多样的含义,例如存在一词多义或者不同语境下相同词语的语义不一致等现象。因此中文问句复述识别的研究中,问句间的语义交互匹配的作用应该会显得更为关键,如何对中文问句进行更为有效的句子交互可能是需要研究的重点问题之一。
