基于层次结构的生成式自动文摘
2019-10-21吴仁守张宜飞王红玲
吴仁守,张宜飞,王红玲,张 迎
(苏州大学 计算机科学与技术学院, 江苏 苏州 215006)
0 引言
随着互联网的迅猛发展,人们被大量的在线信息和文档所淹没。为了能够从中快速找出需要的信息,获取它们的摘要是一个有效途径。Radev等[1]将摘要定义为“从一个或多个文本生成的,传达了原始文本中重要信息的文本,其长度不超过原始文本的一半,并且通常显著小于原始文本”。但是,面对海量的信息,仅靠人工很难为所有文档创建摘要,而自动文本摘要则能很好地解决此问题。
自动文摘[2]是自然语言处理领域的一个重要研究方向,其目的是通过对原文本进行压缩、提炼,为用户提供一个能够覆盖原文核心意思的简明扼要的文字描述。自动文摘所采用的方法可分为抽取式文摘(extractive summarization)[3]和生成式文摘(abstractive summarization)[4]。传统的自动文摘主要采用抽取式方法,即抽取原文本中的句子组成摘要。相比于抽取式文摘,生成式文摘能够从文档中获取相关信息,创建更加精确、自然的摘要,且生成的摘要具有可读性强、语法正确、连贯性强等优点。同时,随着神经网络模型被广泛应用于自然语言处理任务,例如语言模型[5]和机器翻译[6]等,基于神经网络的生成式自动文摘方法受到了越来越多研究者的关注。
目前主流的神经生成式自动文摘模型主要使用借鉴于神经机器翻译的基于编码器—解码器(encoder-decoder)架构的序列到序列学习模型(sequence-to-sequence learning)。但是常见的基于循环神经网络(recurrent neural network, RNN[7])的编码器尚不能有效地对长文档进行语义编码,并且目前普遍只能学习线性链结构的信息, 忽视了对文档具有的层次结构信息的有效利用。而文档本身的语义表达具备很强的结构性,各语义单元之间存在紧密联系。因此,有效地利用文档层次结构信息有利于自动文摘系统更加准确地判断文档内不同结构单元的语义关系和重要程度。从语言学角度来说,文档的结构可对应为篇章结构,而篇章结构可分为物理结构和语义结构。本文只探索物理结构,即本文中的层次结构: 由字构成句子,句子构成文档。同时,对文档进行层次建模能够缩短上层编码器的输入,缓解基于循环神经网络的编码器对长文档编码的缺陷。
针对上述问题,本文对当前主流的基于编码器—解码器架构的生成式自动文摘模型进行了以下两点改进: (1)根据文档的层次结构对文档进行层次编码。层次编码旨在捕获输入文档结构的两个基本特征。第一,文档具有的层次结构(字、句子、文档)。同样地,我们通过首先利用基于循环神经网络的编码器构建字级语义表示;然后由字级语义表示通过卷积神经网络(convolutional neural networks, CNN)构建句子级语义表示,来获得文档不同层次的语义表示。第二,文档中单词和句子的重要性与上下文高度相关,即相同的单词或句子在不同的上下文中可能具有不同的重要性。层次编码可以较好地对这种现象进行建模。(2)本文提出了一种语义融合单元来对输入文档不同层次的语义表示信息进行融合和筛选,获得包含不同层次语义信息的全局表示,并将其作为最终的文档表示用于解码端生成文本摘要。
1 相关工作
传统的生成式自动文摘方法主要包括: (1)基于结构的方法,该方法主要通过使用模板[8]、抽取规则[9]和其他结构(如树[10]、本体[11]等)来确定文档中最重要的信息; (2)基于语义的方法,该方法通过自然语言处理工具处理文档,识别名词短语和动词短语等,并将这些语言学信息用于文本摘要生成中。基于语义的方法又包含多模态语义模型[12]、基于信息项的方法[13]和基于语义图的方法[14]。
近年来,深度神经网络模型已被广泛应用于自然语言处理(NLP)任务,例如机器翻译和文本摘要。特别是基于注意力的序列-序列框架与循环神经网络(RNN)在NLP任务中占主导地位。Rush等[15]首次应用编码器—解码器架构进行生成式摘要,首先使用编码器对输入进行编码,然后利用上下文敏感的注意力前馈神经网络生成摘要,在自动文本摘要上取得良好结果。作为这项工作的扩展,Chopra等[16]使用类似的卷积模型作为编码器,而把解码器换成了RNN,在同样的数据集上产生了性能更好的结果。Nallapati等[17]进一步将编码器改为RNN编码器,组成完整的基于RNN的序列到序列学习模型。此外,他们还拓展了传统编码器,增加了词汇和统计特征,如命名实体识别(NER)和词性标注(POS)等,这些特征在传统的基于特征的摘要系统中均发挥了重要作用。
Gu等[18]和Gulceher[19]等提出类似的观点,文摘任务可以从输入文档中复制稀有单词来减少出现未登录词(unk)的情况。Gu等[18]提出CopyNet来对文本生成任务中的复制动作进行建模,这也适用于摘要任务。Gulcehre等[19]提出了一个选择门来控制是从源文档复制单词还是从解码端的词汇表中生成单词。Zeng等[20]在使用复制机制的同时,在GRU与LSTM的门上添加标量权重以完成自动文摘任务。
不同于常见的序列到序列模型,其输入序列编码(encoding)完毕之后才会开始生成(decoding)输出序列,Yu等[21]提出了输入序列输入的同时交替进行编码与解码过程的序列到序列模型。该模型在短文本摘要任务中取得了较好的实验效果。Shen等[22]建议在神经机器翻译中应用最小风险训练(MRT)来直接优化评估指标。Ayana等[23]将MRT应用于生成式自动文摘任务,实验结果表明直接优化ROUGE评价指标可以提高系统测试性能。
然而,很少有方法在自动文本摘要任务中探索层次编码结构的性能。Tang等[24]首先在情感分类中使用层次结构。他们使用CNN或LSTM来获得句子向量,然后使用双向门控循环神经网络来组成句子向量以获得文档向量。Yang等[25]提出了一种用于文档分类的层次注意力网络。还有一些工作在序列生成[26]和语言建模中使用了层次结构。本文的层次编码器与上述的工作类似,但是又有所创新,本文提出的基于层次结构的生成式摘要模型将文档中每一个句子最后一个字符的语义表示作为句级编码器的输入,并且在字级编码器和句子编码器中混合使用了RNN和CNN,有效结合了两者的优点。另外,增加了语义融合单元,将字级语义表示和句级语义表示进行融合。而上述工作通常直接利用层次结构中的最上级的句级或段级语义表示构成文档表示。
2 基于层次结构的生成式摘要
本节首先给出自动文摘任务的通用定义,并介绍文中使用符号的含义。最后,描述本文提出的基于层次结构的生成式摘要模型。
给定输入文档D,将其表示为句子序列Ds=(s1,s2…,sTs)和单词序列Dw=(w1,w2…,wTw),其中每个单词wi来自固定的词汇表V。自动文摘旨在将文档D作为输入,并生成一个简短的摘要y=(y1,y2,…,yTy),其中T表示序列长度,Tw>Ty。
基于层次结构的生成式摘要模型(后文中使用PHS表示)主要包括: 层次文档阅读器、语义融合单元和配备注意力机制的解码器。其中,层次文档阅读器包括字级编码器和句级编码器,其任务是读取输入文档,并构建字级和句级语义表示。语义融合单元则包含字句对齐模块和全局门控模块。字句对齐模块对获得的字级和句级语义表示进行对齐,并利用全局门控模块进行筛选,将其提供给解码器生成摘要。解码器则负责最终生成摘要。下文将分别详细介绍层次文档阅读器、语义融合单元和解码器的细节及其训练方法。
2.1 层次文档阅读器
层次文档阅读器结构如图1所示,其由两部分组成: (1)使用循环神经网络(RNN)的字级编码器; (2)使用卷积神经网络(CNN)的句级编码器。层次文档阅读器的层次性质反映了文档的层次结构,即文档是由单词、句子,甚至更大的结构单元组合生成的。因此,层次文档阅读器能更好地编码出文档中不同层次结构的信息及其结构关系。

图1 层次文档阅读器结构图
2.1.1 字级编码器
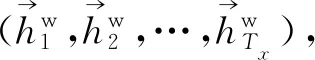
其中,ht∈Rn是t时刻的隐藏层状态,n为隐藏层向量维度。f(·)是一些非线性函数,本文选择了长短期记忆单元(LSTM)。
2.1.2 句级编码器

我们选择卷积神经网络模型作为句级编码器主要有两个原因: (1)训练速度快; (2)卷积核的参数共享,使得模型能够提取某些类型的特征,特别是n元特征。与图像相似,文本中也包含局部相关性,如短语结构、句子的内部相关性。卷积单元可以在句子间提取这些共同特征并指示句子间相关性。
对于卷积网络,我们使用类似于Szegedy等[27]提出的inception的结构,且使用一维卷积来提取句子间的共同特征。和inception初始的设计原则不同,参考Lin等[28]的工作,我们不使用kernel=5的卷积核,而是使用kernel=3的两个卷积核来避免较大的卷积核。具体地,该卷积网络包含3组卷积核: 第一组有一个kernel=1卷积核和两个kernel=3的卷积核;第二组分别有一个kernel=1和kernel=3的卷积核;第三组仅有一个kernel=1的卷积核。我们将每一组的最后一个卷积核的输出进行拼接,作为最终的输出。卷积网络的细节描述如式(5)所示。
(5)
其中,ReLU为线性整流函数(Rectified Linear Unit),Wc为可训练矩阵参数。
2.2 语义融合单元
语义融合单元结构如图2所示,主要包含两个模块: (1)字句对齐模块; (2)全局门控模块。字句对齐模块获得最终包含全局信息的文档表示gd,全局门控模块对获得的gd进行进一步筛选,去除冗余,挖掘出原文档的核心内容。
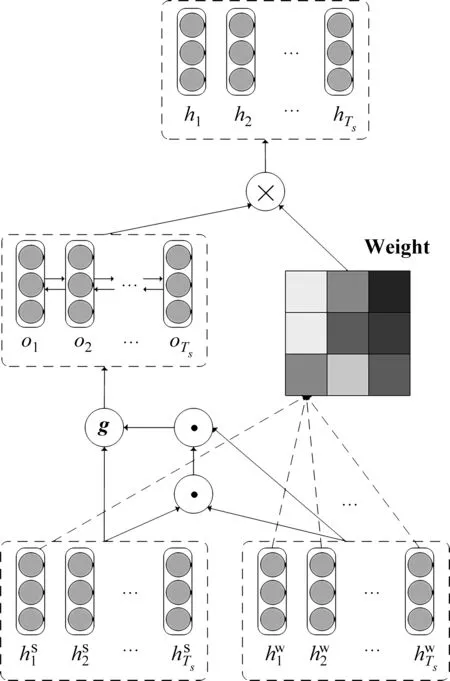
图2 语义融合单元结构图
2.2.1 字句对齐模块


(6)
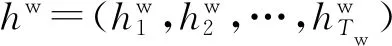
其中,Wo为可训练参数矩阵。

(10)
其中,f(·)为LSTM单元。
2.2.2 全局门控模块
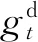
其中,att(·)为注意力计算公式。在此,我们使用Vaswani等[30]提出的缩放点积注意力(Scaled Dot-Product Attention)从整篇文档中有选择地筛选出与当前句子相关的信息并聚焦到这些信息上,如式(14)所示。
(14)
其中,dk为hw的维度。
2.3 配备注意力机制的LSTM解码器
我们利用基于注意力机制的单向LSTM解码器来读取文档表示并逐字生成摘要。在每个时间步骤i,解码器通过获得的词汇表的概率分布生成摘要中的字,直到生成表示句子结尾的标记时结束。具体计算方法如式(15)~式(19)所示。
其中,f(·)为LSTM单元,g(·)是一个非线性、潜在的多层函数,输出y的概率,st为t时刻RNN的隐藏状态,a(·)是一个前馈神经网络。
2.4 训练与推理
给定输入文档x,我们的模型使用随机梯度下降进行端到端训练,通过最小化生成摘要的负对数似然来估计模型参数,形式如式(20)所示。
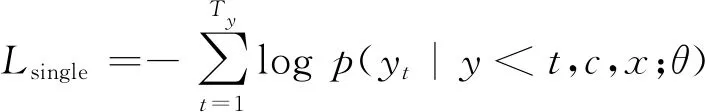
(20)
其中,θ表示可训练的模型参数。
3 实验与评价
在本节中,我们首先介绍实验设置,包括数据集、评价方法、对照实验、文本预处理和超参数设置,然后报告我们的实验结果。
3.1实验设置3.1.1 数据集
本文使用的实验数据集为NLPCC2017 Shared Task3: Single Document Summarization评测任务提供的数据集TTNews[31],该评测任务旨在研究自动生成中文新闻短篇摘要的单文档摘要技术,其提供一个大型数据集,用于评估和比较不同的文本摘要技术。
TTNews数据集是目前最大的中文单文档摘要语料库,包含一个训练集和一个测试集。训练集包含50 000篇用于头条应用程序上推送和浏览的新闻文章和相应的人工摘要。此外,为了进一步促进半监督自动文摘技术的研究,它还包含50 000篇没有人工摘要的新闻文章。测试集只包含2 000篇新闻文章,其来源多种多样,内容也各不相同,包括体育、食品、娱乐、政治、科技、金融等。TTNews 数据集具体统计信息如表1所示。本文仅使用包含相应人工摘要的50 000篇新闻,随机抽取其中2 000篇作为验证集,剩余48 000篇作为训练集。
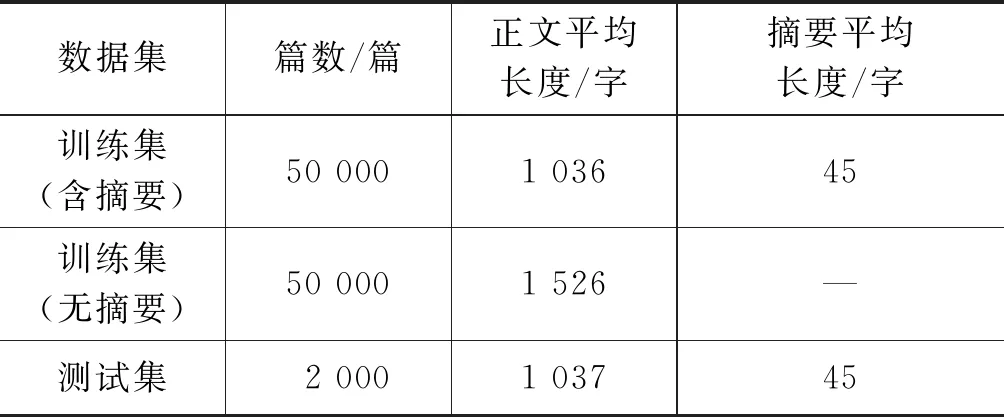
表1 TTNews数据集统计信息
3.1.2 评价方法
ROUGE[32]是Chin-Yew Lin在2004年提出的一种自动摘要评价方法,被广泛应用于NIST组织的自动摘要评测任务中。ROUGE基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。基本思想为由多个专家分别生成人工摘要,构成标准摘要集,将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过与标准人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为自动评价技术的通用标准之一。
本文采用ROUGE中的ROUGE-2,ROUGE-4和ROUGE-SU4以及NLPCC2017 Shared Task3: Single Document Summarization评测任务给定overall score对生成的摘要进行评价,其中overall score为ROUGE1,ROUGE-2,ROUGE-3,ROUGE-4,ROUGE-L,ROUGE-SU4,ROUGE-W-1.2的平均值。另外,该任务中每个摘要的长度限制为60个中文字符,当生成的摘要长度大于60个中文字符时,我们将其截断至60个中文字符。
3.1.3 对照实验
为了评估本文提出的PHS模型在自动摘要任务中的表现,我们将本文提出的模型与NLPCC2017 Shared Task3: Single Document Summarization评测任务中最终提交结果中的模型进行比较。我们直接使用各个模型在该评测任务中最终提交的实验结果。其中,LEAD为该评测任务给出的基线模型。下面我们简要介绍一些具有代表性的系统。
LEAD[31]: 抽取式自动文摘基线系统将文档中的前60个字符作为摘要。由于新闻文本通常是总分总的写作结构,开篇的句子往往包含文章大意,因此该基线系统具有较好的性能。
ccnuSYS[31]: 生成式自动文摘模型,使用配备注意力机制的基于编码器—解码器架构的序列到序列学习模型,它使用文章作为输入序列,将摘要作为输出序列。
NLP_ONE[31]: 生成式自动文摘模型,针对传统基于注意力机制的编码器—解码器模型的不足,提出在输出序列上增加一种新的注意力机制,并采用子字(subword)方法,实验结果得到改进。
NLP@WUST[33]: 抽取式自动文摘模型,基于特征工程的句子抽取框架来获得抽取摘要。在抽取出摘要之后,增加了一个句子压缩算法,压缩抽取出摘要以得到较短的摘要。
3.1.3 文本预处理
预处理时,我们用正则表达式将原始数据集中的HTML标签、符号以及非法字符等无效字符去除。另外,由于硬件限制,我们只能将编码器输入文本长度上限限制为500个中文字符,对于超出部分进行截断处理。通过实验,我们发现较小的文本长度会降低模型的性能,而文本长度过大则导致内存不足错误。
3.1.4 超参数设置
我们使用PyTorch深度学习框架编写代码并在一块NVIDIA 1080Ti GPU上进行实验。由于按词分割文本导致词表过大,在生成摘要时出现大量未登录词。因此,本文按字分割文本,使用“unk”来表示所有字表外的未登录字。字嵌入矩阵在模型训练开始时随机初始化,并随模型一同训练。另外,我们使用默认设定参数的Adam优化器[30]:lr=0.001,betas=(0.9,0.999),eps=1×10-8。其他具体参数设置如表2所示。
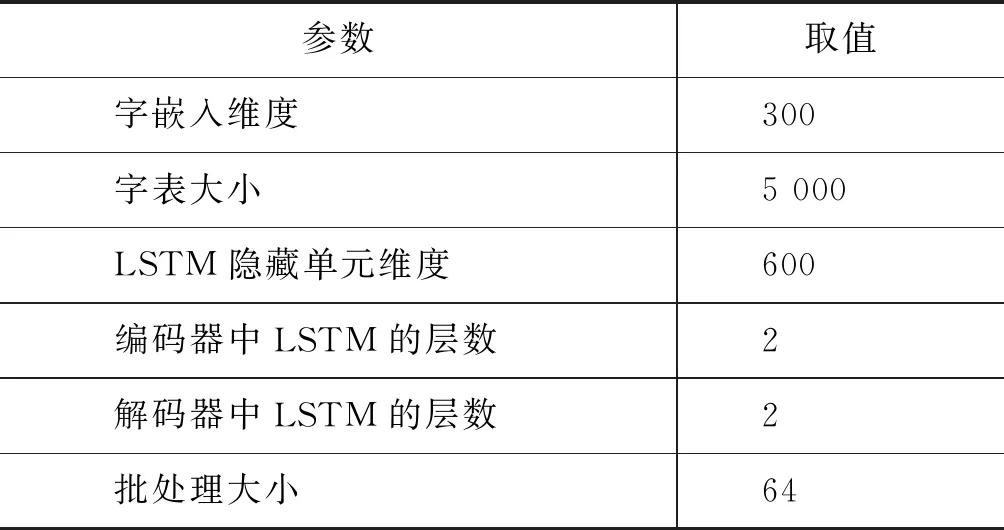
表2 实验参数设置表
所有超参数都使用验证集进行调整,实验结果在测试集上报告。
3.2 实验结果及分析
下面,首先将本文提出的基于层次结构的生成式自动文摘模型与上述的对比系统进行比较,然后分析本文模型中不同组件对模型的贡献。
(1) 与对比系统比较
实验结果如表3所示,其中PHS为本文提出的基于层次结构的生成式自动文摘模型。
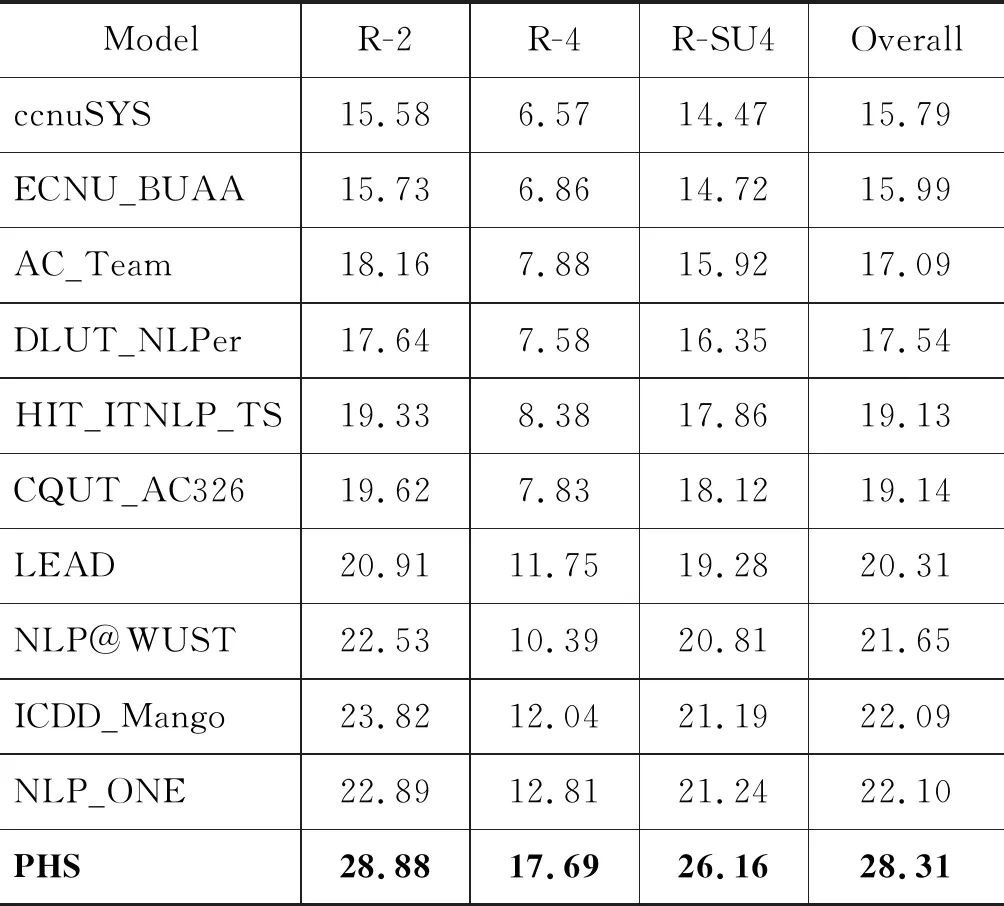
表3 在TTNews数据集上的实验结果
注: 其中R-2,R-4,R-SU4和Overall分别为ROUGE-1,ROUGE-2,ROUGE-SU4和Overall Score的缩写。
分析表3中的实验结果可以看出: 本文提出的基于层次结构的生成式自动文摘模型(PHS)的实验结果超过了所有对比模型,在ROUGE评价指标上性能得到了显著提升,达到了最好的实验效果。并且,与NLPCC2017 Shared Task 3: Single Document Summarization评测任务中排名第一的NLP_ONE模型相比,本文模型在ROUGE-2,ROUGE-4,ROUGE-SU4和Overall Score上分别提高了5.99,4.88,4.92和6.21个百分点。这充分说明了本文提出的模型是有效的,可以生成更高质量的文本摘要。
(2) 模型中不同组件的贡献
为了分析模型中不同组件对模型的贡献程度,我们在传统基于注意力机制的序列到序列(seq2seq)模型的基础上进行修改,将编码器分别换为字级编码器、句级编码器和层次文档阅读器,并进行比较。
实验结果如表4所示,其中char_encoder模型为使用字级编码器的模型,具体实现方式为将传统基于注意力机制的seq2seq的编码器替换为本文2.1.1节中的字级编码器;sen_encoder模型为使用句级编码器的模型,具体实现方式为将传统基于注意力机制的seq2seq的编码器替换为本文2.1.2节中的句级编码器。但是,由于没有字级编码器,无法将每个句子的最后一个字符的隐藏层表示作为句嵌入向量。在此,我们简单地将句子中的每个字的字嵌入向量相加求平均作为该句子的句嵌入向量;hier_encoder模型为使用本文提出的层次文档阅读器的模型,具体实现方式为将传统基于注意力机制的seq2seq的编码器替换为本文2.1节中的层次文档阅读器,但是无语义融合单元。

表4 具有不同组件的各自模型的性能
注: 其中R-2,R-4,R-SU4和Overall分别为ROUGE-1,ROUGE-2,ROUGE-SU4和Overall Score的缩写。
对比表4中实验结果可以看出: 模型中不同组件的贡献有所不同。首先,基于字级编码器的char_encoder模型的性能大幅优于基于句级编码器的sen_encoder模型,说明简单地将句子中的每个字的字嵌入向量相加求平均作为该句子的句嵌入向量存在一定的局限性,无法很好地表示句子的语义信息。另外,基于字级编码器的char_encoder模型已经优于该评测任务的第一名NLP_ONE模型,通过分析生成的摘要,我们猜测是由于中文文本按字编码能大量减小词表大小,有效避免了未登录词出现的情况, 提高模型性能。其次,基于层次文档阅读器的hier_encoder模型优于基于字级编码器的char_encoder模型,在ROUGE-2,ROUGE-4,ROUGE-SU4和Overall Score上分别提高了1.58,1.44,1.46和1.48个百分点,说明本文提出的层次文档阅读器是有效的,它可以在字级语义信息的基础上,进一步挖掘出句级语义信息,并利用CNN的共享参数的特点,发现句子之间的关联。最后,本文提出的基于层次结构的生成式自动文摘模型(PHS)实验效果与hier_encoder模型相比,在ROUGE-2,ROUGE-4,ROUGE-SU4和Overall Score上又分别提高了1.95,2.22,0.99和1.94个百分点。PHS模型和hier_encoder模型的不同之处在于PHS模型在hier_encoder模型的基础上增加了本文提出的语义融合单元,这说明本文提出的语义融合单元能有效融合字级语义信息和句级语义信息,并对融合的信息进行进一步筛选,去除冗余信息,挖掘出原文档的核心内容。
4 结束语
自动文摘是自然语言处理领域的一个重要研究方向,近60年持续性的研究已经在部分自动文摘任务上取得了明显进展。本文针对当前主流的基于编码器—解码器架构的序列到序列学习模型进行了改进: 根据文档的层次结构对文档进行层次编码,获得文档不同层次的语义表示,并提出了一种语义融合单元来对输入文档不同层次的表示信息进行融合,用于编码器生成摘要。实验结果表明: 该方法与对比方法相比,在ROUGE值的评测上有较大的提升,说明该方法是有效的。在接下来的工作中,我们将考虑如何利用篇章的语义结构信息(如篇章修辞结构、话题结构等)来辅助摘要生成。
