基于卷积循环神经网络的关系抽取
2019-10-21宋睿,陈鑫,洪宇,张民
宋 睿,陈 鑫,洪 宇,张 民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
信息抽取(information extraction,IE)研究如何将非结构化描述的自然文本转化为结构化数据。实体关系抽取(relation extraction,RE)则是该领域的一项重要子课题,其目的是从自然文本中挖掘给定实体对之间的语义关系。如例1所示,句中的实体relics和culture需被判定为Entity-Origin关系类型。主流的关系抽取方法将该任务当作分类问题处理,通过设计分类模型学习关系实例的特性,从而利用训练完备的分类器预测实体间关系类型。
例1Thearchaeologicalsiteyieldsrelicsfromlongforgottenculture.
<译>:考古遗址发掘了被遗忘已久的文化古物。
实体1relics
实体2culture
关系类型:Entity-Origin
传统的关系抽取主要依靠手工特征[1-2]或核函数[3-6]构造分类模型,这类方法不仅难以捕获句子的全部信息,且容易产生误差,从而影响了最终分类器的性能。而深度学习方法不依赖手工构造的特征,因而缓解了传统方法的错误传递问题。但是,深度学习方法无法兼顾局部信息和整体信息。其中,卷积网络主要依靠卷积核抽取局部特征,因此在长句建模中效果不佳,循环网络则依靠序列单元提取序列中的上下文关系,对局部特征关注度不够。因此,本文提出一种兼顾局部与整体信息的卷积循环神经网络(convolutional recurrent neural network,CRNN),旨在更好地表征关系实例。模型主要包括以下三个部分:
① 在卷积层通过多尺度卷积核抽取多粒度局部特征;
② 在聚合层采用三种不同的聚合策略对多粒度特征进行融合;
③ 在循环层通过Bi-LSTM建模局部特征间的上下文依赖,获取全局特征。
本文的研究意义在于,提出了一种融合局部与整体信息的网络架构,并以此对关系实例建模,在SemEval-2010评测数据集[7]上取得了优于主流模型的性能。其贡献主要在于:
① 以紧凑的短语级别表示输入RNN,替代原有松散的词级别输入;
② 利用RNN来处理特征序列,从而弥补CNN在应对序列数据上的不足;
③ 探究了多种聚合策略对信息融合的效果。
本文组织结构如下: 第1节概述相关工作,第2节介绍模型的框架和内部策略,第3节给出实验设置、结果和分析,最后为总结和展望。
1 相关工作
关系抽取是信息抽取领域一个重要研究方向,通常做法是将关系抽取当作分类问题处理。在识别出关系实例中的实体对的基础上,利用分类器来判定关系实例的类型。传统的关系抽取方法主要包括基于特征的方法和基于核函数的方法。近年来随着深度学习的发展,关系抽取也逐渐从传统方法过渡到深度学习方法,下面将具体介绍这几类方法的发展过程。
基于特征的方法通过着重提取文本中的重要特征来描述实体间的关系,如实体类型、依存树[1]和词块[2]特征等,并将其组织成向量形式,利用机器学习算法(如支持向量机、最大熵等)对关系特征进行分类。该方法依赖特征的设计和自然语言处理工具(如命名实体识别、词性标注、短语提取等)的准确率,因此设计耗时且容易造成错误累积,进而影响最终的分类性能。
基于核函数的方法通过设计核函数计算对象在高维空间的相似度,以获取对象的结构化特征,并以此构建分类模型。Zelenko[3]等通过浅层句法分析设计树核函数;Culotta[4]等通过依存句法捕获对象间的相似性来构造树核函数;Bunescu[5]等将句法最短路径与树核函数融合;Zhang[6]等利用卷积树核探究句法特征的效果。这类方法依赖核函数的设计,且同样受到自然语言处理工具损失的影响,因此通用性不强。
基于神经网络的方法能自动学习文本特征,不需要手动构建特征,因此避免了传统方法带来的损失。神经网络的方法主要包括基于卷积神经网络的方法和基于循环神经网络的方法。其中卷积神经网络的方法主要包括: Zeng[8]等提出利用卷积神经网络对关系实例建模,并引入了位置向量;Nguyen[9]等通过设计不同尺度的卷积核对语义关系进行表征;Santos[10]等提出利用合页损失函数替代原有的交叉熵,以更好地区分不同类型的关系实例; Wang[11]等则在卷积网络中尝试了多层注意力机制,以着重突出句子成分对关系标签的贡献。循环神经网络的方法主要包括: Zhang[12]等提出用RNN替代CNN建模关系实例,并用简单的位置标签替代位置向量;Li[13]等通过循环神经网络对不同的句法结构进行建模;Miwa[14]等利用Tree-LSTM建模关系实例,并考虑不同的句法结构类型; Zhou[15]等则将双向循环神经网络和注意力机制应用于关系抽取任务中;Xiao[16]等将长句切割,并利用两层RNN和注意力机制分别编码。
从建模方法的角度而言,目前神经关系抽取方法主要包括基于卷积神经网络的方法和基于循环神经网络的方法,两类神经网络方法各有优劣。其中,基于卷积神经网络的方法擅长提取关系实例的局部特征,而基于循环神经网络的方法则能够很好地捕获序列的整体特征信息。但是,卷积神经网络过于关注局部特征而忽略整体的序列化信息。相比而言,循环神经网络则侧重考虑序列的整体信息,对局部特征的表示和应用略显欠缺。针对二者在表示学习层面上互为补充的特点,本文提出一种融合局部和整体信息的卷积循环神经网络,通过聚合策略聚合卷积产生的多粒度局部特征,并通过循环神经网络对聚合特征抽取整体信息。
2 基于CRNN的关系抽取
2.1 框架概述

图1 CRNN模型框架
本文的关系抽取模型主要包括三部分: 卷积层抽取多粒度局部特征、聚合层融合多粒度特征和循环层对特征上下文依赖建模。模型的具体框架如图1所示,其中,输入序列表示由dw维的词向量(word embedding)和dp维的位置向量(position embedding)拼接而成。模型首先将序列表示输入卷积层,利用多卷积窗口抽得多粒度的n-gram特征(此处由于卷积操作的平移不变性,使得特征的排列顺序与原始词序列一致,因此不同窗口大小的卷积特征即相当于对应的n-gram特征);然后在聚合层将抽得的特征输入聚合层,将不同粒度的卷积特征进行融合,并将其按时序组织,形成以原词为中心的多粒度融合特征。最后经过循环层,利用LSTM捕获序列长期依赖的能力,对序列特征进行建模,针对高阶的n-gram表示,提取其中的上下文依赖信息。
2.2 局部和整体信息建模
为了同时考虑关系实例的整体和局部信息,本节主要介绍如何综合利用卷积神经网络和循环神经网络对关系实例建模,以建立局部特征和整体特征间的联系,从而更好地获得关系表征。
2.2.1 局部特征抽取
关系实例的重要信息通常体现在序列的局部区域,但粒度却并不绝对。为了使模型能够捕捉不同粒度的局部特征(local feature),本文采用不同尺度的卷积核捕捉文本中不同粒度的n-gram特征,以获取更全面的局部特征信息。
设输入的句子矩阵为C,其中每个词的维度为d(包括dw维的词向量表示和dp维的位置向量)。为了得到输入句子的特征表示,模型初始化窗口大小为k的滤波器用于卷积操作,其宽度与词向量维度一致。卷积操作如式(1)所示。
(1)
其中,“∘”代表点乘,σ表示sigmoid激活函数,C[i:i+k]表示第i到i+k的词向量序列,Hk为宽度为k的卷积核。为了保证不同的卷积核抽取的特征图长度一致,本文采用了SAME的padding策略,以使不同粒度特征图和输入序列长度一致。
2.2.2 局部信息融合
为了更好地建模序列的整体信息,本文通过聚合层对多粒度局部特征进行融合,并将聚合后的特征按时序进行组织,从而得到融合多粒度局部信息的特征矩阵[c1,c2,…,cn]。其中,ci为第i组特征向量,表示以原序列第i个词为中心的多粒度卷积结果的聚合特征。为了探究不同的特征聚合策略,本文将在2.3节详细介绍三种聚合策略。
2.2.3 整体上下文建模
为了更好地捕捉特征序列间的整体信息,本文将循环层置于卷积层之上,旨在通过循环神经网络捕获特征序列的上下文关系。在具体技术环节,本文采用双向长短时记忆网络(bidirectional long short term memory network,BiLSTM)构建循环层。该网络通过前向、后向两组链式网络结构分别对特征序列进行建模,并将两组链式网络最后时刻的输出进行拼接作为序列的整体信息。具体来看,BiLSTM将LSTM 神经元作为基本的处理单元,其内部通过多组门控机制实现对整体序列信息的控制。其借助三组数学公式实现信息的处理与计算,如式(2)~式(4)所示。
其中,ct代表聚合层在t时刻的输出,ht-1代表上一神经单元的输出,σ表示sigmoid激活函数,W为权重矩阵,ft、it和ot分别代表LSTM内部的遗忘门、输入门和输出门。
2.3 融合多粒度n-gram的聚合策略
卷积层获取的n-gram特征,由于卷积核尺寸的不同,其抽取的特征也呈现多粒度的分布。为了更好地组织不同粒度的特征,以适应循环层建模,本文尝试了三种聚合策略将不同粒度特征融合,分别是全拼接策略、逐元素最大池化策略以及自注意力机制策略。下面将具体阐述三种聚合策略。
2.3.1 全拼接策略
采用全拼接策略(full concentrate),对不同粒度的特征直接进行拼接。如图2(a)所示,将特征按序列展开,其中每个时刻的聚合特征由该时刻不同粒度的特征词拼接而得,结果如式(5)所示。
(5)

2.3.2 逐元素最大池化策略
采用逐元素最大池化(element-wise maxpooling)的策略,对不同粒度的特征进行筛选。如图2(b)所示,对多组n-gram特征逐位最大池化,即逐个取特征位上多组特征的最大值,形成向量与原始特征位数一致,具体操作如式(6)~式(7)所示。

2.3.3 自注意力机制策略
采用自注意力机制[17](self-attention),综合考虑不同粒度特征的信息。如图2(c)所示,通过计算不同粒度n-gram特征之间的相关性,将不同粒度特征相互关联,从而赋予不同粒度特征相应的权重,通过加权求和获取其表征。具体计算如式(8)~式(10)所示。

本文将以上三种聚合策略都作用于多粒度的n-gram特征,并且将聚合的结果[c1,c2,…cn]按时间步t输入循环层,以建模多粒度短语之间的上下文依赖。
2.4 模型训练
本节主要介绍模型的训练过程。在循环层获取关系表征之后,模型设置Softmax作为分类器,用于接收隐层的输出,并据此生成每个关系类别的概率分布,然后最小化这一概率分布与关系实例的实际类别的交叉熵来训练模型。
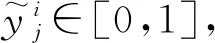
(11)
其中,l为指示函数,当yi=j为真时l=1,否则为0。
在学习参数的过程中,深度学习模型往往会由于参数过多而导致过拟合现象,为了防止过拟合现象的发生,本文尝试两种不同策略来解决这一问题:
① Dropout策略是通过在训练过程中忽略某些节点,即不让数据经过部分神经元。这种随机丢弃的策略相当于组合了多个网络模型,且模型参数数量都较原先模型少,因此有更好的泛化能力。本节在模型的输入层和RNN之后都添加了dropout策略。
② 正则化则是给模型的代价函数添加罚项,以降低模型本身的复杂度。本文使用L2正则化项来约束模型参数,如式(12)所示。
(12)
其中,L为总代价函数,L0代表原始的代价函数,w代表所有的模型参数,n为训练集大小,λ则为正则项系数,用于权衡正则项和原始代价函数的比重。
3 实验与分析
为了评估提出的CRNN模型在关系抽取任务上的有效性,本文在关系抽取的基准数据集上进行了实验,旨在验证:
① 融合局部和整体信息的CRNN模型在关系抽取任务上是否较主流模型有明显优势;
② 不同的聚合策略对模型会产生哪些影响。
下面,首先在3.1节介绍实验数据集及其划分,然后在3.2节介绍具体评价指标及参数设置,最后详细阐述模型的实验性能以及与其他方法的对比。
3.1 实验数据及划分
对于关系抽取的实验,本文采用语义评测会议SemEval的关系抽取数据集SemEval-2010 Task 8[7],该语料集包含8 000个训练样本和2 717个测试样本,其中共9大类关系和一个其他类型,关系类型具体如表1所示。
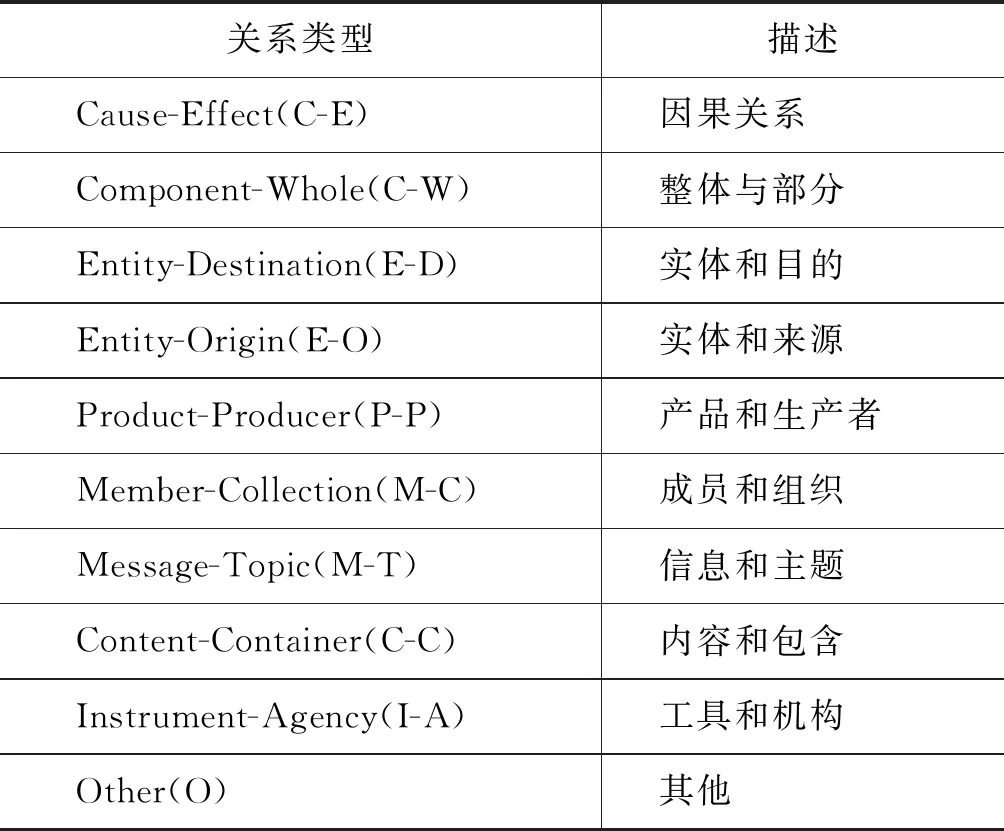
表1 SemEval-2010 Task 8数据集关系类型
此外,依据测试样本的分布,本文从训练集中抽取了1 600个样例充当开发集,用于调整参数及选择模型,其各个类别的语料分布如图3所示。
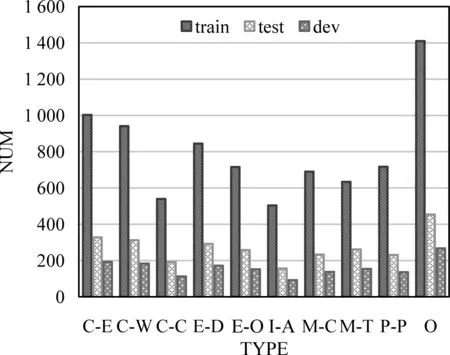
图3 实验语料集分布
3.2 实验设置及评价指标
本文实验的词向量采用的是预训练的Glove词向量(1)https: //nlp.stanford.edu/projects/glove/,维度为300维。模型超参设置上,本文尝试了多组模型参数,并通过网格搜索在开发集上选择了最优的模型。其中,最优结果在20~25个迭代轮获取。模型具体参数实验范围和最终设置如表2所示。
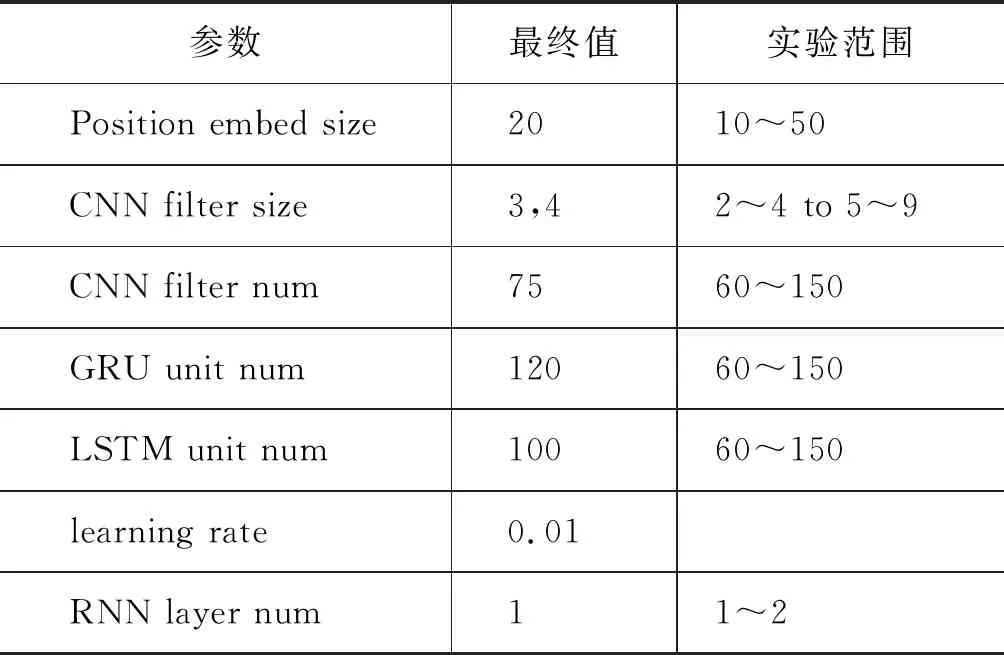
表2 模型超参设置
本文采用准确率P(precision)、召回率R(recall)和F1值作为衡量模型性能的评价指标,首先通过混淆矩阵求得每个类别下的P、R、F1值,然后通过宏平均(Macro-average)求得所有类别的算术平均值作为整体性能的指标。
3.3 实验结果及分析
本文的实验以MultiCNN[9]为基线系统(Baseline),本文复现的该模型在未引入额外知识的前提下,分类性能能够达到82.63%。
3.3.1 局部与整体建模
在第一组实验中,本文在MultiCNN获取的多粒度卷积特征基础上,通过添加循环层捕获序列之间的上下文信息,替代了原先的池化层。得到的实验结果如表3所示,其中聚合层采用直接拼接的策略。

表3 添加循环层的实验结果(实验结果省略%,F1值为宏平均)
从实验结果可以看出,在MultiCNN的基础上添加循环层,提高了模型的整体分类效果。其原因在于,单独的CNN只能关注序列的局部区域,通过循环层能更好地捕捉特征间的联系,从而获取关系实例的整体特征。此外,以LSTM作为基本的处理单元,其遗忘门和记忆门在一定程度上起到了特征选择的作用,效果比简单的池化更优。该实验证明,通过RNN能有效弥补CNN在整体信息建模上的不足,从而提升关系抽取的性能。
3.3.2 聚合策略
在第二组实验中,本文旨在验证三种不同的聚合策略对信息融合的影响。在上节模型的基础上,分别尝试逐元素最大池化和自注意力机制的聚合策略,实验结果图4所示。

图4 聚合策略实验结果
从实验结果可以看出,自注意力机制和直接拼接的聚合策略结果近似,且都优于逐元素最大池化策略。其原因在于:
① 模型选取LSTM Cell作为基本处理单元,其中,遗忘门和记忆门在一定程度上起到了特征选择的作用,因此不需要再利用池化操作对特征进行筛选;
② 自注意力学习到的不同粒度的权重信息,直接拼接也能够获取,不过是将权重学习的负担传递到循环层。
综合以上两组实验结果,本文在基线系统的基础上,组合利用自注意力机制的聚合策略和基于BiLSTM的整体建模思路,在关系抽取语料集上进行实验,并详细比较了基线系统和本文的模型在各个类别下的指标,实验结果如表4所示。从表中可以看出,相比基线系统的多通道CNN,本文的模型在各个类别均有性能优势。其中,召回率提升明显,说明原先被误判为other类别的样本都能被本文的模型正确识别。并且,观测发现,本文的模型在长句预测上的性能要显著优于基线系统。如例2中关系实例,基线系统判定为other类别,而本文的模型则正确标识为Member-Collection类。

表4 最优模型性能结果(实验结果省略%,F1值为宏平均)
例2Skype,afreesoftware,allowsahookupofmultiplecomputeruserstojoininanonlineconferencecallwithoutincurringanytelephonecosts.
<译>: Skype是一款免费软件,允许多个计算机用户连接加入在线电话会议,且不会产生任何电话费用。
实体1hookup
实体2users
关系Member-Collection
3.3.3 与现有方法对比
最后本文选取了当前主流的关系抽取模型与本文提出的CRNN模型进行对比,分别是:
① SVM: 融合多种词法、句法、框架语义等特征;
② Multi-CNN: 利用多尺度卷积核抽取特征+最大池化;
③ CR-CNN: 模型为基本的CNN,损失函数利用合叶损失函数替代交叉熵损失;
④ SDP-LSTM: 利用LSTM建模实体间的最短依存路径;
⑤ BiLSTM+ATT: 融合双向循环神经网络和注意力机制;
⑥ BiLSTM+CNN: 组合BiLSTM和CNN,其中BiLSTM在前,CNN在后。
如表5所示,本文将主流的关系抽取模型分三大类列出: 基于特征的方法、基于CNN的方法和基于RNN的方法。
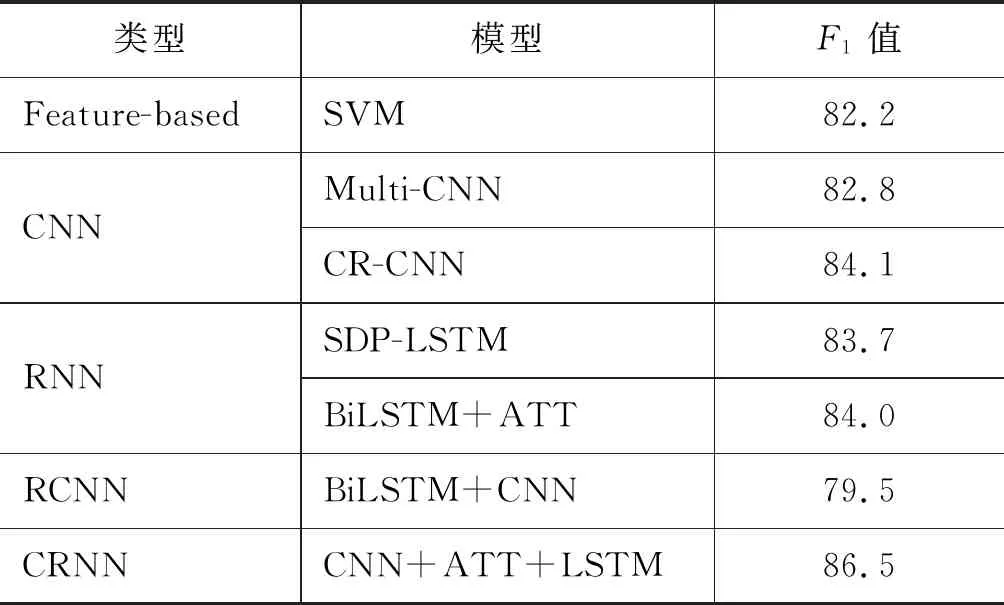
表5 CRNN和其他模型进行对比(实验结果省略%,F1值为宏平均)
从表5中可以看出,相较于传统基于特征的方法以及基于CNN和基于RNN的模型,本文提出的CRNN模型在不依赖外部特征的情况下,取得了优于三类模型的效果。此外,本文还对比了BiLSTM和CNN的另一种结合方法RCNN[18],该方法首先通过BiLSTM对每个词进行编码,然后通过卷积层抽取局部特征。实验显示,本文的CRNN模型要明显优于RCNN模型。原因在于本文提出的CRNN模型通过聚合策略对特征进行融合,该方法在保留词序信息的基础上,起到了融合多粒度局部信息的效果,在结合循环神经网络和卷积神经网络中起到了重要作用。
4 总结与展望
本文针对现有的基于神经网络的关系抽取模型无法融合局部和整体信息的问题,提出了一种融合局部特征和整体序列信息的卷积循环神经网络。该模型通过卷积层抽取多粒度局部特征、聚合层融合多粒度信息、循环层捕获特征之间的上下文联系,从而将关系实例的局部特征和整体信息进行了融合,并在聚合层探究了多种特征融合策略,最终得到了融合局部和整体信息的关系表征。在SemEval-2010 Task8 数据上的实验证明:
① 融合了局部和整体信息的模型架构比单独建模局部特征和序列关系的模型在关系抽取上更有效;
② 自注意力和直接拼接聚合策略在特征融合上效果类似,并且都优于逐元素最大池化策略。
后续工作将在本文的基础上,继续探究如何更好地利用实体词和关系之间的联系,以凸显重要的局部特征,如采用注意力机制捕获不同特征的重要性。
