一种基于层次分割和聚合的大数据流水线任务处理方法
2019-10-11陈天乐朱小杰崔文娟冯伟华周园春
陈天乐,蒲 军,朱小杰,崔文娟,冯伟华,王 锐,杜 一*,周园春
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
3.中国烟草总公司郑州烟草研究院,河南 郑州 450001
引言
随着大数据时代的到来,传统软件无法快速有效地采集与处理大量的数据[3]。在互联网和物联网等领域,个性化服务、数据分析等复杂的业务场景都要求在短时间内返回处理结果。以天文大数据项目为例,该项目需要在15 秒内处理大约 1.3GB 的数据,同时需要实现秒级查询[4];大亚湾反应堆中微子实验中产生了 233TB 的原始数据,需要传送到中国科学院高能物理研究所和美国劳伦斯国家实验室等场所进行进一步的数据分析[5];中国气象局每年新增接近 1PB 的地面观测,卫星,雷达和数据预报产品等数据[6]。随着数据不断地爆发性增长,应用场景也越来越广泛,不同场景往往对数据格式有着不同的要求,如何建立起数据在不同系统和场景之间的关系,自动清理、清洗数据以适配不同系统,这需要使用到大数据流水线工具。
针对这些处理环节复杂的数据处理场景,业界通常采用大数据流水线工具搭建数据处理流程,这些工具存在一些优点:
(1) 配置,监控方便。许多流水线工具都采用XML 或 JSON 的方式进行配置,使业务逻辑的实现与展示分离,方便运行逻辑的备份与移植;用户在流水线搭建过程中能随时开始,停止,修改流水线,并能查看数据在流水线中的变化过程,使得用户能交互地定位错误流程;同时,在流水线运行过程中,能实时查看系统整体运行情况,如占用线程数,数据读写速率及总量,提高了用户对系统运行的感知度。
(2) 扩展性好。企业的数据处理在采集,清洗,集成,建模等环节涉及到的软件很多,如日志收集器,MySQL监控与数据导出工具,批处理,流处理工具,机器学习模型训练器,报表生成工具等,流水线工具支持多种多样的单机,分布式软件,支持一定的动态语言, 避免每次修改运行逻辑后,需要重新打包上传程序和重启组件,支持解析各种各样的 XML,JSON,CSV 格式的数据,还给用户提供API,允许用户扩展系统功能。
(3) 重用性好。流水线工具基于阶段式事件驱动架构[7],数据输入输出格式保持一致,数据经过一个流程处理转换成另一种数据后不再返回原处理流程,处理流程不保存数据状态,降低了各组件的相关性,使得各组件能够独立地开发和修改,增强了组件的重用性,减少了开发人员的工作量。
但是,一些流水线工具存在着任务无法将任务分割为多个子任务并行执行的问题,本文提出了一种基于层次分割和聚合的大数据流水线任务处理方法,主要思想是在流水线工具中添加分割 (split) 和聚合(merge) 两种程序:在分割程序中将流水线中的任务分割为多个子任务并行执行,在合并程序中等待各子任务全部完成,以此获得父任务的完成事件以触发下一个处理流程。实验基于 Apache NiFi[2]流水线工具使用本方法处理 DBLP[1]数据,验证了本文方法的有效性和高效性。实验表明本文方法处理 DBLP 数据的速率是 Apache NiFi 传统处理方法处理速率的 7 倍多。
1 相关工作
业界针对通用的大数据处理场景提出了各种不同的分布式处理框架。这其中应用最广泛的就是批处理(batch processing) 和流处理 (stream processing),如图1所示。批处理系统如 Map Reduce[8]和 Spark[9],流处理系统如 Yahoo S4[10]和 Twitter Storm[11]。如图1所示,两者对比而言,批处理通常用于处理有限数据,其将整个任务分成多个阶段,上一个阶段处理完才能执行下一个阶段,多个阶段串行执行,吞吐量大,延迟高;而流处理通常用于处理无限数据,其将数据分割成多个部分,一个部分在后一阶段进行处理,另一个部分还在前一个阶段处理,每个阶段并行执行,吞吐量小而延迟低。
1.1 大数据处理主要框架
Map-Reduce 是一种底层的编程模式,Facebook针对这种缺点开发了 Hive[12],能将用户输入的 SQL查询语言编译成 Map-Reduce 任务,在Hadoop 或Spark 上执行,极大地简化了编程工作量。Storm 的发起者之一 Nathan Marz 提出了 Lambda 架构[13],旨在以最低的延迟提供实时的计算结果。如图2所示,Lambda的架构分为三层:批处理层,流处理层,应用层。批处理层会周期性地处理历史数据,生成批处理视图。用户在应用层的每一次查询,都会读取一定时间以前已生成的批处理视图,同时使用流处理层处理增量数据,最终将两者结果合并,呈现给用户。
此外,Summingbird[14]使用 Pig[15]等系统中dataflow 的抽象概念如数据源,数据终点,数据存储进行编程,底层会透明地生成 Hadoop 作业或 Storm拓扑进行运算。这改变了 Lambda 架构中用户必须编写两套查询语言的状态,极大地减少了开发成本。
之后,Jay Kreps 等人提出了如图3所示的 Kappa架构[16],他认为 Lambda 架构采用两种计算模式是导致系统架构复杂的根本原因,提出对延迟不敏感的企业应完全采用批处理架构,对延迟敏感的企业应完全采用流处理架构,当计算逻辑改变时,继续保留旧有的流式处理逻辑并向用户提供视图,同时执行新的流式处理逻辑,直到处理到最新消息时,将视图从原有计算逻辑切换到新计算逻辑上。
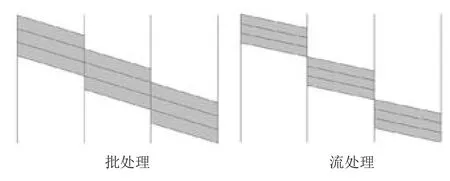
图1 批处理和流处理计算示意图Fig.1 The diagrams of batch and stream processing
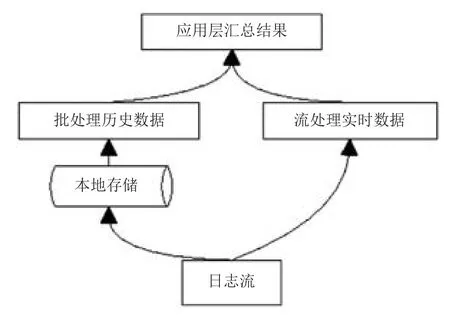
图2 Lambda架构Fig.2 The processing structure of Lambda

图3 Kappa架构Fig.3 The processing structure of Kappa
Google Cloud DataFlow[17]是谷歌公司在其云计算平台上提供的一种批流融合的大数据处理工具,针对批处理和流处理提供了统一的 API,当数据源是cloud storage 时,系统会自动调用批处理模式处理数据,当数据源是 pub/sub 时,系统可根据数据来源自动调用流处理模式处理数据。
1.2 大数据流水线工具
StreamSets[18]是一种典型的大数据流水线工具,其支持结构化和半/非结构化数据源,提供了拖拽式的可视化数据流程设计界面。其将处理流程分为数据源 (Origins),执行器 (Executors),处理器(Processors),数据存储 (Destinations) 四类。数据源可以从 Amazon S3,JDBC 等数据源读取数据,执行器可以执行 shell,Spark,Hive 脚本,处理器能在系统内对数据进行过滤,复制,格式校验,数据存储可以将数据存储至文件系统,Google Bigtable,HBase 等数据库中。用户还可以将编辑好的数据管道放入控制中心,方便日后对数据实现定时调度、管理和管道拓扑。
一种更加常见的数据流水线工具是 Apache NiFi[2],是一款由美国国家安全局开发的使用Web界面进行管理的大数据流水线软件,现集成在Hortonworks 公司维护的 Hadoop 框架中。其解决了容错,故障恢复,流量控制,功能扩展等问题,通过 Java ClassLoader 加载用户自定义的 jar 包,实现自定义的处理流程。其原理是一个处理流程从输入队列中读取消息,处理后输出到输出队列,作为下一个流程的输入队列。系统内的每一条消息被称为 flowfile,由 header 和 content两部分组成:header 一般存储于内存中,content 则存储在磁盘中,是运算速度与存储空间的结合。集群中每台主机运行相同的程序,但处理不同的数据,用户对流程的修改会同步到集群的所有节点,Apache Zookeeper 会选择系统内的某台主机作为群集协调器(Coordinator),其余节点定期向此节点发送心跳包,以此跟踪各节点的执行情况。同时,Apache NiFi 还集成了 workflow 的功能,它可以定时,依次执行相应的程序。NiFi 对流模型的主要抽象为 Processor,并且提供了非常丰富的数据源与数据目标的支持。
Apache NiFi 的基本架构如图4所示,集群中的每个节点对数据执行相同的任务,但是每个节点都在不同的数据集上进行操作。Apache ZooKeeper选择单个节点作为群集协调器,故障转移由 Apache ZooKeeper 自动处理。所有群集节点向群集协调器报告心跳和状态信息。集群协调器负责断开连接节点。此外,每个群集都有一个主节点,也由 ZooKeeper 选择。作为 DataFlow 管理器,用户可以通过任何节点的用户界面 (UI) 与Apache NiFi集群进行交互。
2 技术路线
2.1 基于层级划分的思想
本文提出了一种基于层次分割和聚合的大数据流水线任务处理方法,在分割程序中将流水线中的任务分割为多个子任务并行执行,在合并程序中等待各子任务全部完成,以此获得父任务的完成事件,描述如下:
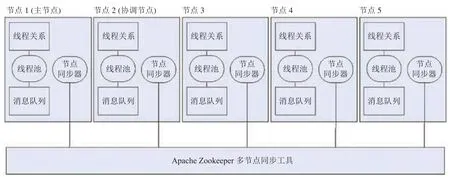
图4 Apache NiFi架构图Fig.4 The structure of Apache NiFi
(1) 在分割程序 (split) 中,将流水线中的任务分割为若干子任务 (以下简称为一级子任务),并使用一种类似于点分十进制的方式对各一级子任务进行编码,若分割的一级子任务数量总数有x个,则将第一个一级子任务编码为 0/x (从 0 开始计数) ,将第二个一级子任务编码为 1/x,...;每个一级子任务还能继续分割成更小的子任务 (以下简称为二级子任务),编码之间以点符串接,若第一个一级子任务分割成 y 个二级子任务,则将第一个二级子任务编码为 0/x.0/y。
例如:如果一个任务共分为 10 个一级子任务,则将第一个一级子任务编码为 0/10,第二个一级子任务编码为 1/10;假设第一个一级子任务分为 400 个二级子任务,则将一级子任务 0/10 中的第一个二级子任务编码为 0/10.0/400,第二个二级子任务编码为0/10.1/400,以此类推。
(2) 在合并程序 (merge) 中等待本级子任务全部完成,以此获得父任务的完成事件。将子任务依次组装为父任务,直到组装完毕才触发下游处理程序。
例如:下游循环收集并组装子任务 0/10 的二级子任务结果碎片,当收集到所有二级子任务0/10.0/400,0/10.1/400,…,0/10.399/400 的执行结果时,将其合并为子任务 0/10 的执行结果,触发下游事件。
2.2 方法示例
本文处理流程示例如图5所示。在如图所示的源XML 数据的解析中,第一级分割将XML分割成可并行执行的编码为 0/3,1/3,2/3 的三个一级子任务,分别解析 classA,classB,classC,其中 3 代表本级分割中子任务的划分个数。
第二级分割将编码为 0/3,1/3,2/3 的三个一级子任务再分别分割为编码为 0/3.0/1; 1/3.0/2,1/3.1/2; 2/3.0/3,2/3.1/3,2/3.2/3 的二级子任务,分别解析 item1,item2,item3,item4,item5,item6;流处理将以上数据处理分别生成 data1,data2,data3,data4,data5,data6,任务编码不变,第二级合并循环等待上游二级子任务执行完毕,如二级子任务 0/3.0/1 结束后合并为一级子任务 0/3,二级子任务 1/3.0/2 和 1/3.1/2 结束后合并为一级子任务 1/3,二级子任务 2/3.0/3,2/3.1/3 和 2/3.2/3 结束合并为一级子任务 2/3。
由于 Hive 数据库底层基于 MapReduce 实现,数据分多次存入的效率远低于整体一次存入的效率,因此第二级合并提高了写入 Hive 数据库的速度,同时,因每个子任务处理的数据量不同,完成时间不同,使得各任务在不同时间将数据写入 Hive 数据库,避免相互抢占 Hive 资源。而第一级合并循环等待一级子任务 0/3,1/3,2/3 全部执行完毕,触发结束事件。
3 实验和结果分析
DBLP 是德国特里尔大学 (University of Trier) 和德国信息学会 (Schloss Dagstuhl) 维护的计算机领域期刊、会议和图书等信息数据库。截至 2019年1月,DBLP 包含 6511005 条数据,分为article (A),inproceedings (IP),proceedings (P),book (B),incollection (IC),phdthesis (PT),mastersthesis (MT),www (W) 八类数据,各类数据数据量如错误!未找到引用源。所示。
Apache NiFi 提供了很多针对数据获取、数据清洗的基本通用组件,同时允许加载用户自定义 jar包,扩展性强,极大地减少了开发人员的工作量。
为避免网络传输对性能测试的影响,本实验使用单机 Apache NiFi 平台,开发并使用本文提出的分割和合并程序,解析 DBLP 数据,将数据集 (XML 格式) 中的每类数据分别解析处理后存入Hive 数据库,并与 Apache NiFi 传统处理方法进行了比较。
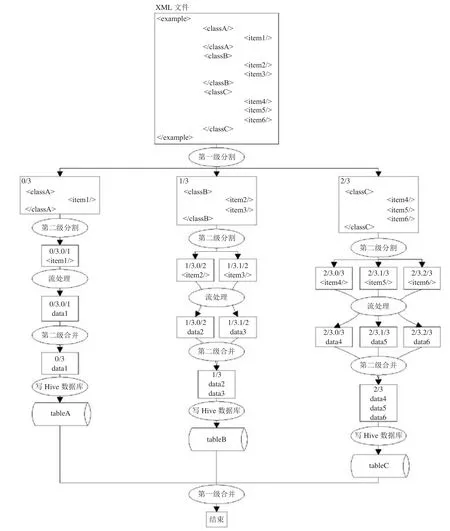
图5 本文方法示意图Fig.5 The example of the proposed method

表1 DBLP数据中各类数据数量Table 1 The amount of data in different types in DBLP
本方法基于 Apache NiFi 的实现如图6所示,以 article 类型的数据处理为例,第一级分割中的 SplitDblpXmlByDDN 程序将 dblp.xml 分割为article, inproceedings,proceedings 等数据,将其中的 article数据编码为 0/8,传入内部分割处理程序中的 article程序;内部分割处理程序将每类数据进一步分割并使用 Apache NiFi 提供的组件进行处理,其中第一条 article 数据编码为 0/8.0/1895917。第二级合并中的 MergeContentByDDN 循环合并上游处理结果,直到全部合并,形成编码为 0/8 的数据文件,传到下游写入 Hive 数据表,第一级合并中的MergeContentByDDN 循环合并上游处理结果,直到八类数据全部处理完毕,触发结束事件。
某次实验结果如错误!未找到引用源。所示,结果表明,在使用本文方法处理数据的过程中,由于P、IC 类型的数据量较少,最先处理完毕并写入 Hive数据库,A、IP 类型的数据量较多,最后处理完毕写入 Hive 数据库,同时任务处理的无序性与并行性导致 P、IC 类型的数据量虽然比 B、MT 类型的数据量多,但比 B、MT 类型的数据先处理完毕。与 Apache NiFi 传统处理方法处理 DBLP 数据相比,传统方法写 Hive 数据库的次数总计 68525 次,本文方法写Hive 数据库的次数总计 8 次,最终导致本文方法处理DBLP 数据的速率是 Apache NiFi 传统处理方法处理速率的 7 倍多。
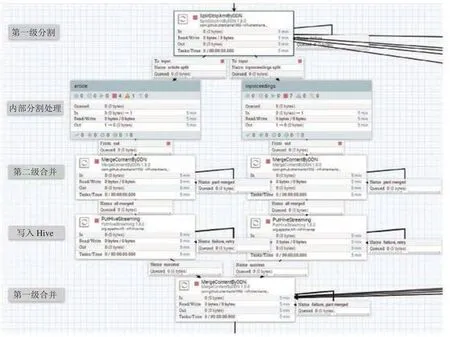
图6 基于Apache NiFi的本文方法实现图Fig.6 The implement of the proposed method based on Apache NiFi
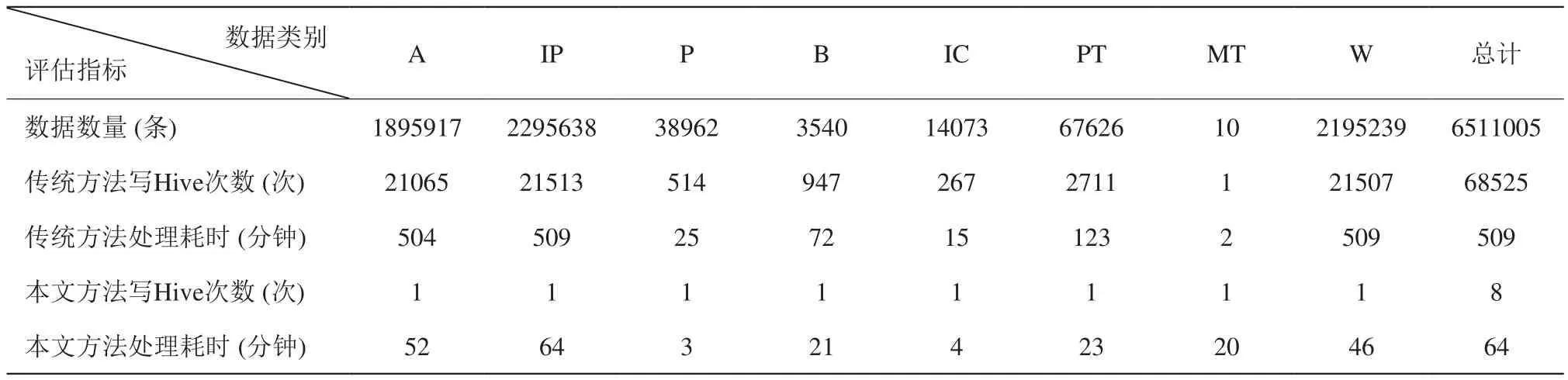
表2 各方法处理 DBLP 数据效率结果Table 2 The results of different methods in processing DBLP data
4 总结
本文提出一种基于层次分割和聚合的大数据流水线任务处理方法,将流水线数据处理任务使用编码的方法分为了划分和聚合两部分,将任务分割为多个子任务并行执行,使得任务更加碎片化,以获得更大的并行加速,同时实现了使用流处理框架处理有限数据的目的。在实证研究中,我们以 DBLP 数据集为例进行了实验,结果表明,由于将写 Hive 数据库的次数从近 7 万次减少到 8 次,本文方法处理 DBLP 数据的速率是 Apache NiFi 传统处理方法处理速率的 7 倍多,同时本文方法以其层级划分的特性提高了 Apache NiFi 组件的重用性。
