一种基于聚类的文章自动摘要方法及实现
2019-10-11唐建权何洪波王闰强
唐建权,何洪波,王闰强
1.中国科学院计算机网络信息中心, 北京 100190
2.中国科学院大学,北京 100049
引言
文章自动摘要即是运用机器学习方法,归纳或者提取出文章主要内容,是自然语言处理领域一个非常重要的部分。目前为止,文章自动摘要主要使用两类方法[1]:一是以抽取文章关键句或者关键词作为摘要的抽取式自动摘要,二是以理解文章后使用相关技术生成新摘要的生成式自动摘要。抽取式自动摘要较为经典的方法有[1–7]:1) 基于统计的方法,即通过统计词频、位置等信息,计算句子权值;2) 基于图模型的方法,即构建拓扑结构图,迭代得到每个句子的权值,例如 TextRank、LexRank等;3) 基于有监督学习的方法,即对句子做特征工程,考虑句子位置、句子关键词个数等众多因素,由机器学习算法确定句子权值,例如SVM、HMM、神经网络等;4) 基于线性规划的方法,即将摘要问题转为线性规划问题,求全局最优解。抽取式自动摘要的主要缺点是句子前后逻辑较差,并且抽取的句子之间相关性较高,一般较长的句子更有可能称为关键句。生成式自动摘要较为经典的方法是基于有监督学习的方法[1-3],目前主要使用的模型是 RNN (循环神经网络) 及其变种模型。生成式自动摘要的主要缺点是需要大量的训练集,一般需要人工标注大量的参考摘要。
针对抽取式自动摘要存在的句子相关性较高的问题,本文提出一种基于聚类的抽取式自动摘要算法,主要是基于自底向上层次聚类算法实现自动摘要。
1 基于聚类的自动摘要方法
1.1 聚类
聚类[8]即是将所有样本划分为多个子集 (称为簇或者类别),使得同一簇中的样本相似性较大,而不同簇中的样本相似性较小。聚类的方法有很多[8],常见的有以 K-means 为代表的基于划分的方法、以DBSCAN 为代表的基于密度的方法、以 AGNES 为代表的基于层次的方法等等。
由于基于划分的方法非常容易受到离群点的影响,基于密度的方法无法指定聚类个数并且参数设定非常复杂,因此我们的实现采用 AGNES 这个基于层次的方法 (实验证明该方法的效果也最好)。
AGNES (Agglomerative Nesting)[9]是自底向上的层次聚类算法,首先把每一个样本点当作一个簇,接着不断重复地计算所有不同簇之间的距离并且将其中最近的两个簇进行合并,直到满足迭代终止条件。常见的计算两个簇之间的距离有三种方法[8]:1) 单链,即使用不同两个簇中离得最近的两个点之间的距离;2) 全链,即使用不同两个簇中离得最远的两个点之间的距离;3) 平均链,即使用不同两个簇中所有点对的距离平均值。由于单链和全链容易受到极端值的影响,一般使用平均链来度量两个簇的距离。
1.2 方法思想
我们知道,Word2Vec 模型[10]可以将每个词转换为一个词向量,并且语义相近的两个词,其词向量距离也较近,反之则较远。受到 Word2Vec 模型的启发,两位学者提出 Doc2Vec 模型[11](也称为Paragraph2Vec 或者 Sentence2Vec),可以将每个句子转换为固定长度的句子向量,并且句子语义相近,其向量距离也较近。
显而易见,如果对句子向量进行聚类形成多个簇,每个簇中的句子,其相似性较大,而不同簇中的句子,其相似性较小。从不同簇中挑选出有代表性的句子形成摘要,就能够很好地概括整篇文章的语义,并且句子间相似度较低。
但是在实际应用中,文章可能存在一些和主题非常无关的句子,或者所有内容都围绕主题,如果使用传统方法进行聚类,会导致一些簇中句子向量个数极少,或者极多,这都不利于提取关键句。
因此,为了提升自动摘要的准确率,我们采取三项措施:一是删除句子向量中的离群点;二是聚类时限制每个簇的句子向量个数;三是挑选候选句时忽略句子向量个数极少的簇。
1.3 方法流程
整个自动摘要方法流程主要分为三步:一是生成句子向量,二是对句子向量进行聚类,三是计算得到关键句。
1.3.1 生成句子向量
可以使用两种方法得到句子向量:一是直接使用Doc2Vec 模型将句子转换为句子向量;二是将句子切词,然后使用 Word2Vec 模型将词转换为词向量,再求句子中所有词向量的均值接着添加上句子长度等信息作为句子向量。一般来说,在训练数据足够的情况下,由于训练过程中考虑词序关系,第一种方法效果更好。
为了提升准确率,我们在使用 Doc2Vec 模型时,并不直接使用原始句子,而是参考 TextRank 模型[7],使用下述方法构造的句子:将句子切词并且只保留特定词性 (比如名词、动词、形容词等) 的词,拼接生成句子。
由于每一篇文章都可能存在非常无关的句子,比如作者介绍、版权信息等,我们通过计算句子向量到其他所有句子向量的距离之和,并且删除距离之和较大的句子。这里借用数据挖掘中盒图[8]的思想,将距离之和视为一堆点,距离之和非常大的视为离群点,将所有的点按照值大小排序后,根据公式 (1) 设定阈值 threshold,距离之和超过这个阈值的句子和句子向量将被删除。
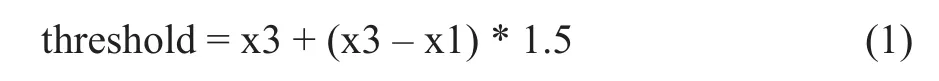
其中,x1表示数据中第 1 个四分位数,x3表示数据中第 3 个四分位数。
1.3.2 句子向量聚类
如果直接使用原始 AGNES 算法对句子向量进行聚类,那么很可能有的簇句子向量个数特别多,甚至可能出现一两个簇占据文章 90% 的句子向量这种情况。因此,我们限定每个簇的句子向量个数,当某个簇句子向量个数超过阈值时,下次迭代计算距离时不再考虑该簇。
那么聚类的流程是:首先根据文章句子数和设定的关键句句子数确定最终簇的数目cluster_num(可以根据文章句子数,设定范围在关键句句子数到两倍关键句句子数之间) 以及每个簇中的最大句子向量个数max_sen_num(可以设定为「文章句子数/关键句句子数」,「x」表示对 x 向上取整),并且将每个句子向量视为一个簇;接着不断重复地使用平均链计算所有不同簇(句子向量个数小于 max_sen_num 的簇) 之间的距离并且将其中距离最近的两个簇进行合并,直到簇的数目等于 cluster_num。
1.3.3 关键句提取
聚类得到的簇,有的句子向量个数极少,可以视为离群点进行删除。不过考虑到有的文章本身的句子数较少这种情况,需要保留足够多的簇才能按照下述方法得到足够的关键句。我们计算出每个簇的中心 (簇中句子向量的均值) 到全文的中心 (所有句子向量的均值) 的距离,并且按照簇中句子个数和距离排序,在簇的数目大于关键句句子数的前提下,从前到后删除句子个数小于设定阈值的簇。
这样,当簇中句子向量足够时,每个簇的中心可以很好地表示该簇的语义 (可以称为语义中心点),那么所有的语义中心点的集合能较好地概括整篇文章。由于无法由句子向量直接生成句子,只有从这些簇中选取代表性的句子作为关键句。显然,簇中一个句子向量如果比其他句子向量到语义中心点的距离更近,理论上这个句子向量更能表达该簇的语义。
因此,我们使用公式 (2) 计算簇中句子向量到语义中心点的最终距离,并且选择距离最小的 1 个句子作为候选句子。另外,句子向量数较多的簇可能包含更多的文章语义,当一个簇的句子向量个数大于设定阈值时,可以再从簇中选择距离次小的 1 个句子作为候选句。最后根据距离从小到大从候选句中筛选最终的几个关键句,拼接生成摘要。
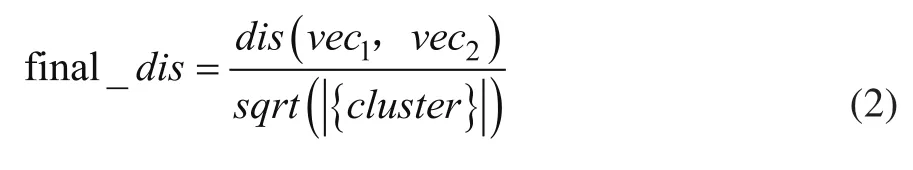
公式中,vec1表示簇中某个句子向量,vec2表示簇的中心 (当簇中句子向量数大于 1 时) 或者全文中心 (簇中句子向量数等于 1 时),|{cluster}| 表示该簇的句子向量个数。
2 方法实现
本文方法的流程图如图1所示。
给定关键句句子数key_sentence_num,该方法提取文章摘要的主要步骤是:
(1) 使用 jieba 分词工具将所有句子进行切词,仅仅保留特定词性 (比如名词、动词、代词、形容词等)的词;
(2) 对于每一个句子,使用 Doc2Vec 模型将拼接的词转换为句子向量或者使用 Word2Vec 模型生成每个词的向量并计算均值后再添加长度信息等作为句子向量;
(3) 计算句子向量到其他句子向量的距离之和,排序后根据公式①设定阈值,删除所有距离之和大于阈值的句子和句子向量;
(4) 将每个句子向量都视为一个簇,设定簇的个数cluster_num以及簇中最大句子向量数max_sen_num;
(5) 使用平均链计算每两个簇 (簇中句子向量数大于max_sen_num则不再考虑) 之间的距离,并将距离最近的两个簇进行合并;
(6) 重复进行第 5) 步,直到簇的个数等于设定阈值cluster_num;
(7) 计算每个簇的中心及全文中心,并且计算每个簇的中心到全文中心的距离;
(8) 按照簇中句子向量个数、第 7) 步计算的距离进行排序,在簇个数大于key_sentence_num的前提下,从前到后删除句子向量个数小于设定阈值的簇;
(9) 对于每个簇,根据公式②计算所有句子向量到语义中心点的最终距离,选择最终距离最小的句子作为候选句子;若句子向量个数大于设定阈值时,再选择一个最终距离次小的句子作为候选句子;
(10) 对于所有候选句子,按照最终距离从小到大选择key_sentence_num个句子作为关键句,合并后作为最后的文章摘要。
3 实验
我们实现了算法,并且利用实验室平台优势,随机挑选中国科普博览的 500 篇科普文章进行摘要提取,和 TextRank 算法和词频统计方法进行比较后,验证了该方法的可行性和可用性。
3.1 测试样本简介
中国科普博览[12](www.kepu.net.cn) 是由中国科学院计算机网络信息中心运营的大型综合性科普网站,具有很高的社会影响力和品牌知名度,依托中国科学院的科学资源,向公众提供丰富多彩的科普信息服务,内容包括天、地、生、数、理、化等各个学科。
我们随机挑选的 500 篇科普文章就来源于中国科普博览,文章内容覆盖范围广,不仅包括航天、3D打印、无人驾驶、量子通信等前沿知识,也包括生活科普、讲座总结、演讲实录等,具有很好的代表性。
3.2 摘要结果对比
我们使用 TextRank 算法、词频统计方法以及本文方法分别进行文章自动摘要,依次设定关键句句子数为 2 和 3,分别选取两例摘要结果进行对比,如表1 和表2所示。
可以看出,本文方法提取的摘要长度一般比词频统计方法要短,并且和标题的相似度更高。
3.3 实验效果对比
文章自动摘要常用的评价指标[2]是精确率(Precision)、召回率 (Recall) 和F值,其定义分别为:
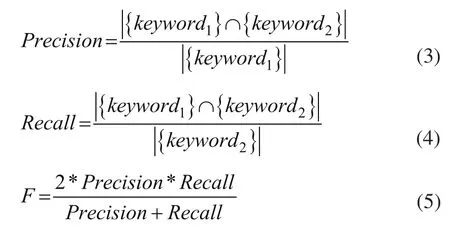
其中,keyword1是指算法生成的摘要结果 (生成摘要),keyword2是指人工指定的摘要结果 (参考摘要),{keyword} 表示句子中所有关键词集合,|{keyword}| 表示句子中关键词的个数,{keyword1}∩{keyword2} 表示两个句子共有关键词的集合。
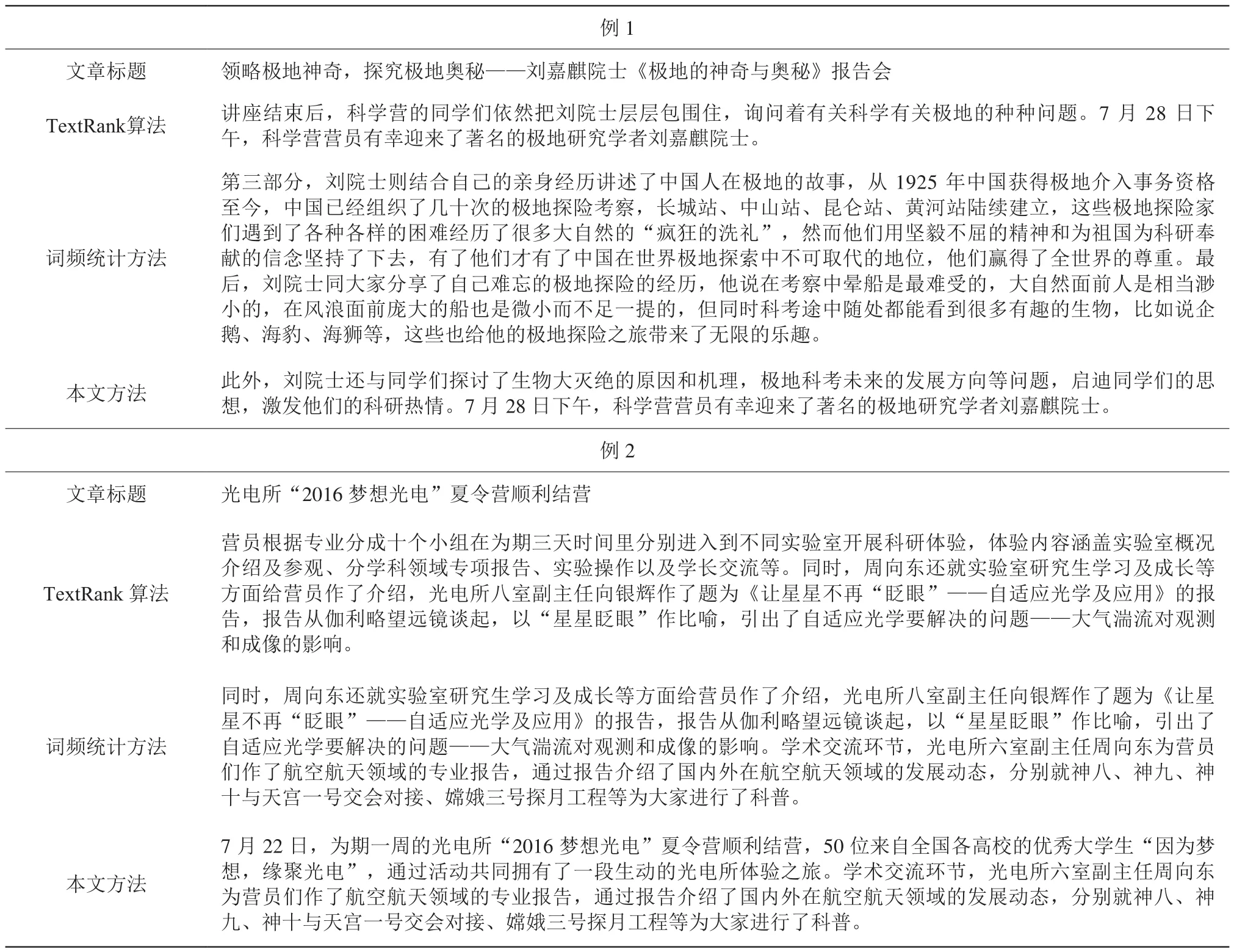
表1 两句话摘要结果对比Table 1 Comparison of two-sentences summary
我们使用 ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 这个在业界被广泛应用的评估自动摘要的一组指标,其主要思想是,计算精确率、召回率和 F 值时两个句子的关键词使用 n 元词,而不是单个的词。
本文使用 Rouge-1、Rouge-2 这两组评价指标,计算时两个句子的关键词分别使用 1 元词和 2 元词。本文还将使用 Rouge-l 这组评价指标,计算时考虑最长公共子序列,精确率和召回率的公式分别为:
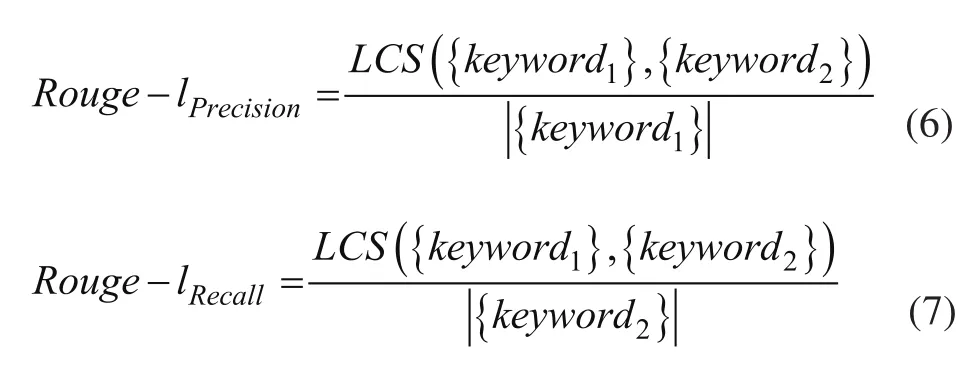
其中,LCS({keyword1},{keyword2}) 表示自动生成摘要和候选摘要的最长公共子序列的长度。
我们使用标题作为文章的参考摘要,依次设定关键句句子数为 2 和 3,分别使用 TextRank 算法、词频统计方法、本文方法在500篇科普文章上进行摘要提取,计算其在Rouge-1、Rouge-2、Rouge-l 三组评价指标上的平均得分,结果如表3、表4、表5所示。
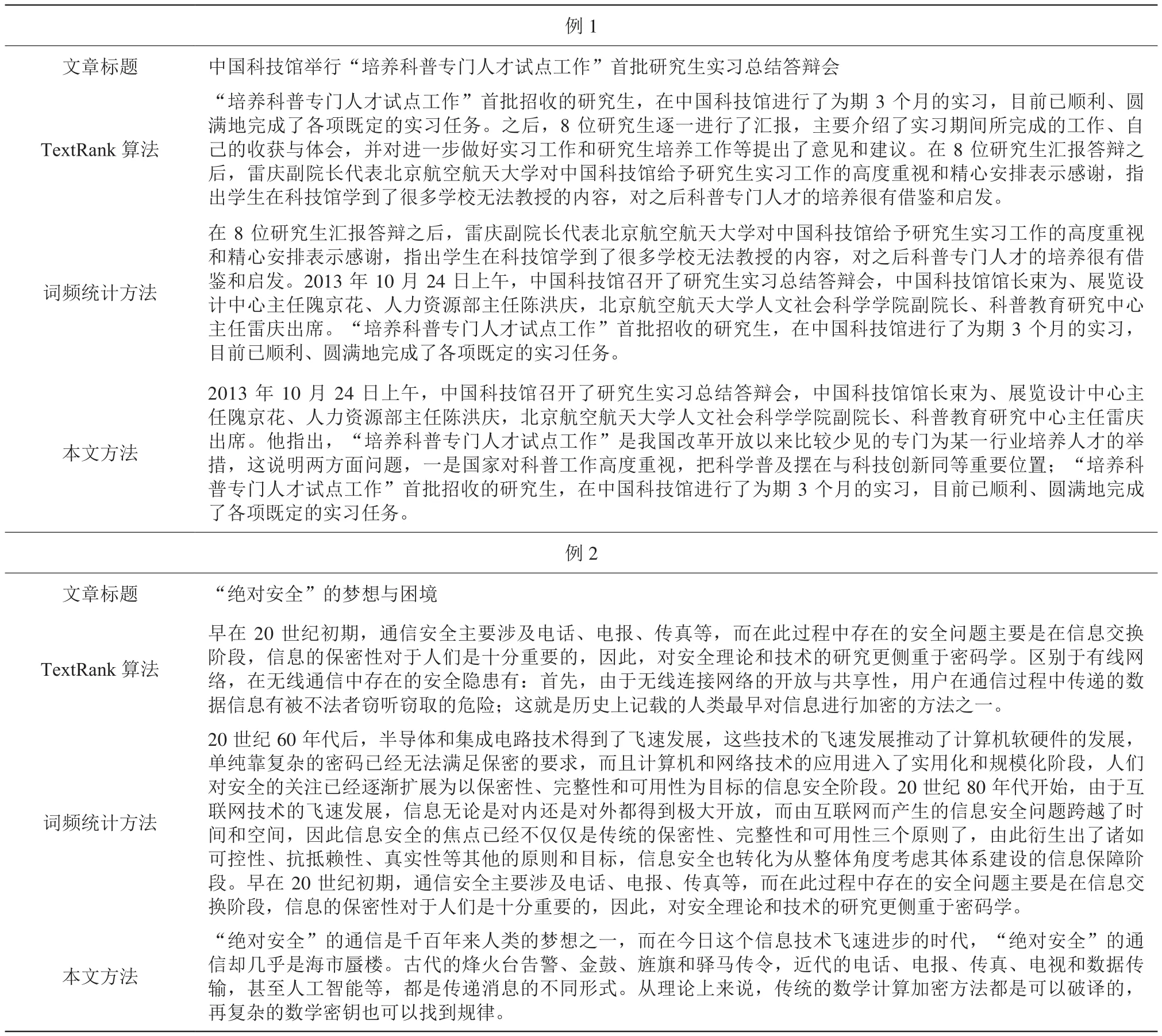
表2 三句话摘要结果对比Table 2 Comparison of three-sentences summary
可以看出,本文方法在各项指标上均优于TextRank 算法和词频统计方法,是一种比较好的文章自动摘要方法。
4 结束语
本文提出一种基于聚类的文章自动摘要方法,主要基于 AGNES 算法将删除离群点后的文章句子向量聚类成几个簇,设定阈值删除句子向量数极少的簇以后,按照句子向量到语义中心的距离,从每个簇中挑选一个或者两个最能代表该簇语义的句子,筛选后形成摘要。本文方法经过实验对比验证,效果较好,是一种实用的自动摘要算法。
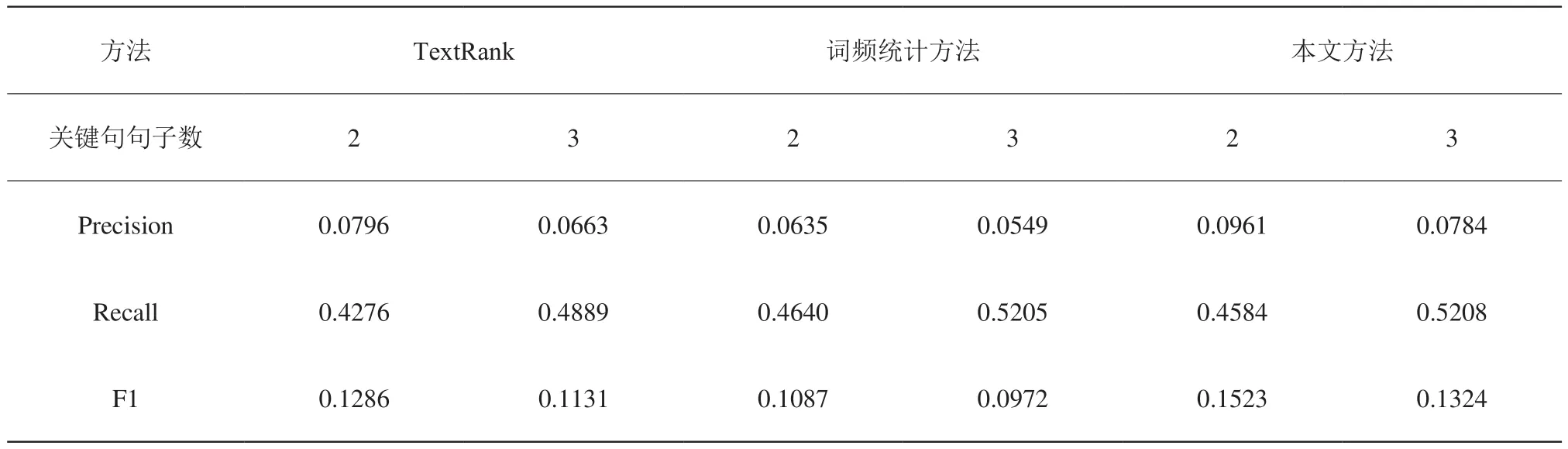
表3 实验效果对比 (Rouge-1评价指标)Table 3 Comparison of results(using evaluation index of Rouge-1 )
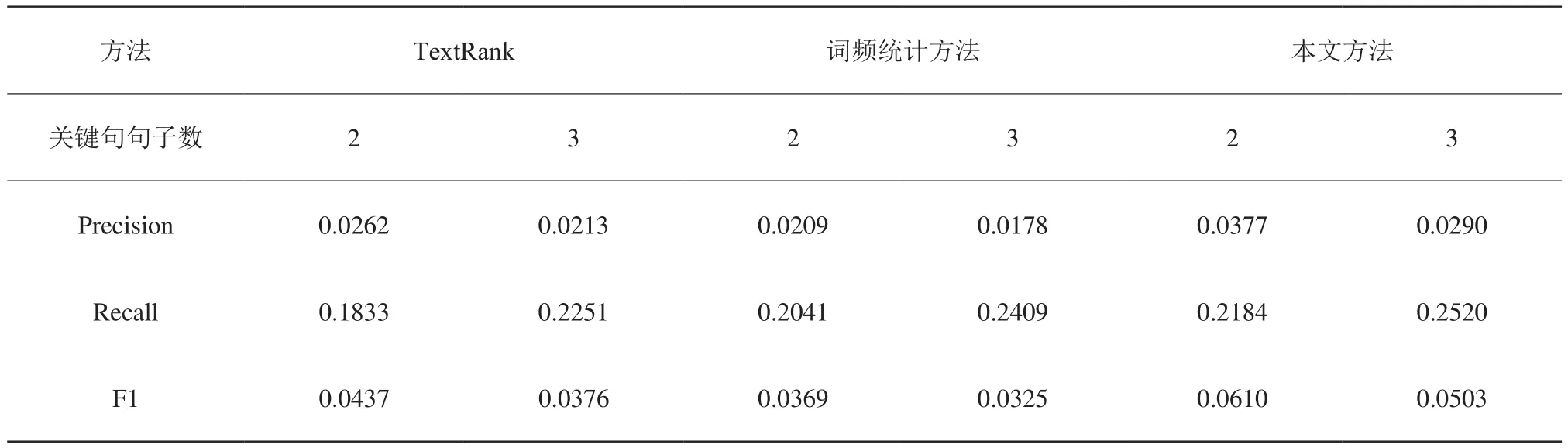
表4 实验效果对比 (Rouge-2评价指标)Table 4 Comparison of results(using evaluation index of Rouge-2 )
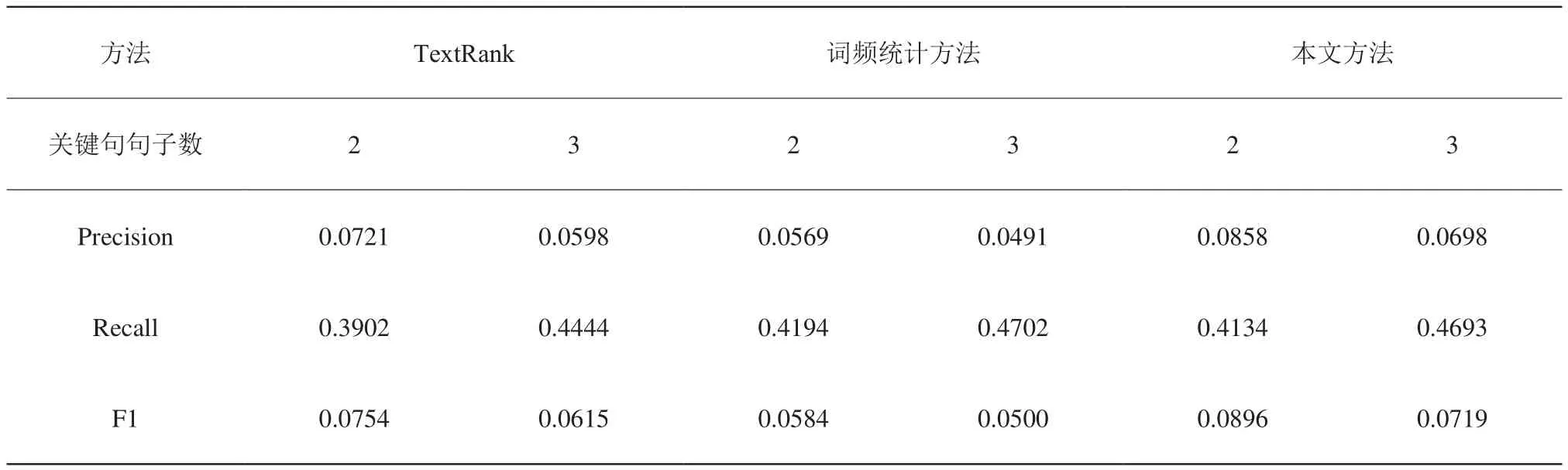
表5 实验效果对比 (Rouge-l评价指标)Table 5 Comparison of results(using evaluation index of Rouge-l)
