一种轻量级分布式作业管理系统的设计与实现
2019-10-11张裕牛北方
张裕,牛北方
1.中国科学院大学计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100190
引言
随着大数据、云计算等相关技术的发展,不同学科都面临着海量数据处理的问题,科学研究也在逐步向以数据驱动为主的研究范式转变。单机计算能力明显难以达到工程和科学研究的要求,随着硬件价格的下降以及配套软硬件的成熟,分布式的解决方案正逐渐成为主流[1]。相较于传统的单机系统,分布式系统在一致性、可用性和容错性方面都面临着巨大的挑战,不论是企业级应用还是科研应用,都面临多租户、多任务的要求,如何为用户屏蔽分布式系统底层实现细节,降低用户学习和使用成本,同时合理的调度不同用户的作业都是分布式作业管理系统需要着重考虑的问题[2]。作业管理系统在高性能计算 (High Performance Compute,HPC) 领域已较为成熟,常见的HPC作业管理系统有IBM LSF[3]、Oracle SGE[4]以及Slurm[5]等,而在普通分布式集群中,分布式作业管理系统的研究还较为缺少,大多数应用都与 Hadoop、Spark 等大数据技术紧密结合,使得用户的学习和使用成本较高。
为了充分利用多机性能,合理地调配用户作业,本文设计与实现了一种轻量级的分布式作业管理系统,该系统主要特点体现在以下几个方面:
提供了简洁的命令行接口,屏蔽分布式实现细节,方便用户使用;
采用 HTTP 与 Google Protobuf 作为集群通讯协议,并实现 REST 调用接口,具有较强的功能可扩展性;
用 Master-Slave 模式管理集群,方便集群扩展;
内置 HTTP 服务器并提供 Web 可视化监控界面,提升集群管理和运维效率。
1 相关工作
1.1 IBM LSF
IBM LSF 是 IBM 公司为高性能计算系统研发的一套用来对分布式资源进行管理的工具,它不但可以较好的完成作业管理,同时提供了身份认证、资源管理与调度等功能[6]。IBM LSF 是比较经典的作业管理系统,采用了典型的 Master-Slave 模式,客户端将作业请求发送给管理节点,管理节点根据各执行节点的作业负载将作业分发到不同的计算节点运行。同时,LSF 也针对不同的计算环境提供了不同的作业调度队列,从而满足了不同优先级和类型的作业调度与运行[7]。IBM LSF 不仅在企业中得到了广泛应用,在科研领域中也有突出的表现。IBM LSF 的主要缺点是作为商业软件其源代码并不开放,商业授权费用高昂,对其定制化难度较高,学习和部署都有一定的成本。
1.2 Oracle SGE
SGE (Sun Grid Engine) 原名 CODINE/GRD,是Sun公司的社区网格项目,后被 Oracle 收购后取消开源改为收费项目。SGE 可以通过对集群环境中的工作负载进行有效管理,实现对共享资源的使用控制。SGE 在实现对资源管理的同时也可以对策略进行定制,即一方面可以使系统资源的利用率和系统吞吐率达到最优化,另一方面也可以支持满足作业截止限期、作业优先级等功能[8]。SGE 作业管理系统能够很好地实现批作业管理的功能,并能够很好的监控提交的作业,使得分布式集群的利用率得到了极大的提高,但是其缺乏 checkpoint 机制,容错能力有一定的缺失而且缺少相应的开放调用接口使得可扩展性降低。
2 服务架构和关键技术
2.1 服务架构
为了满足在分布式环境下多机多作业的调度,提高系统的容错性和可扩展性,简化系统的部署和学习成本,本文设计了如下的分布式轻量级作业管理系统。系统的服务架构如图1所示。
该系统主要由 Client、Master 以及 Slave 三种服务组成,Client 节点以命令行接口向 Master 节点提交、查询和终止作业。Master 节点负责维护全局的作业状态信息和 Slave 节点的状态信息,调度作业在各Slave 节点执行。Slave 节点负责具体执行作业,汇报作业状态和资源使用情况。具体的流程描述如下:
1.Master 节点启动后台进程,恢复缓存在磁盘的作业状态表和 Slave 状态表,并在指定端口开启HTTP 监听服务。
2.Slave 节点通过 Master URL 连接到 Master 节点,向 Master 节点发送注册请求,Master 节点收到Slave 节点的注册请求后,登记 Slave 节点信息 (IP 地址、监听端口号等),并为该 Slave 节点分配 SlaveID以及鉴权 token,Slave 节点收到 Master 回复的注册消息后完成注册,维护与 Master 之间的连接状态并定期汇报当前及节点的作业运行状态、CPU 使用率和内存使用率等信息。
3.用户通过 Client 端的命令行接口提交需要运行的作业,并指定作业类型 (二进制作业或者 shell 脚本作业),Client 端将用户作业提交的作业封装为作业消息,悬置 TaskID,发送给 Master 节点。Master 节点收到 Client 端的作业请求后,依据作业调度算法选择执行作业的 Slave 节点并设置 TaskID,登记作业信息,同时将作业消息转发给 Slave 节点执行。Slave 节点在接收到作业消息后,开启后台进程解析和执行作业并向 Master 节点汇报作业状态。Slave 节点完成作业的执行后通过消息接口更新 Master 节点的作业状态信息。
4.当用户通过 Client 端的命令行接口查询作业信息时,Client 端向 Master 节点发送消息请求并获得作业的执行情况。同时,用户也可以通过 Client 端的命令行接口终止运行中的作业,Master 收到 Client 端提交的终止请求后查询作业运行的 Slave 节点并转发终止请求到 Slave 节点完成作业的终止。
2.2 关键技术
(1) 采用 HTTP 协议并结合 JSON (JavaScript Object Notation,JSON) 以及 Google Protobuf 序列化方法进行消息传递
为了减少各节点之间的状态维护成本,本文采用 HTTP 协议作为各节点之间消息传递的载体。与基于 TCP 长连接的消息传递方式相比,采用 HTTP协议可以降低 Master 节点和 Slave 节点的状态维护成本同时提高集群的可扩展性并易于实现 REST(Representational State Transfer, REST) 调用接口。为了支持二进制类型和 shell 类型的作业,本文采用Google Protobuf 作为作业消息的序列化方法,与传统的 JSON 序列化方法相比,Google Protobuf 不仅可以自定义数据类型,构造丰富的消息格式,同时对字节数据流有更好的支持,方便将二进制、文本数据等打包到消息体内进行流转。同时,Google Protobuf 序列化后的字节占用数较少,可以有效的减少网络传输的压力,本文定义的作业消息 Protobuf 格式如图2所示。在实现过程中,Master 节点的后台进程和 Slave节点的后台进程中都内置了 HTTP 服务并使用 REST接口的方式进行互相调用和消息传递,对于监控数据、作业状态等小规模数据,本文以 JSON 序列化方式进行通信,而对于作业等大规模消息,则使用Google Protobuf 作为序列化方式。
(2) 加入 checkpoint 机制提高系统容错性

图2 作业消息 Protobuf 格式Fig.2 Job message of Protobuf format
在Master-Slave 结构的分布式系统应用中,Master 节点的失活将导致整个服务的不可用。为了使 Master 和 Slave 节点快速从故障中恢复,本文对 Master 和 Slave 节点加入了 checkpoint 机制。在Master 节点运行的进程中,每当作业状态表、Slave状态表变动时或者在容错定时器唤醒时,Master 进程都会开启单独后台线程将作业状态表、Slave 状态表刷写到磁盘文件中。当 Master 进程从故障中恢复时,Master 进程将会首先读取状态表文件并重新将其加到到内存中供 Client 端和 Slave 端进行查询和操作。Slave 节点会定期向 Master 节点汇报自身的资源使用情况和作业执行情况,当 Slave 节点无法连接到Master 节点时,Slave 会将需要汇报的状态信息加入待汇报队列,并在重新连接到 Master 节点时,统一上报缓存状态信息。与 Master 节点类似,为了防止Slave 节点因宕机故障而导致的状态信息丢失,Slave节点也会定期将状态信息刷写到磁盘文件中,从而在故障恢复时重新加载。
(3) 作业调度算法
作业调度算法是分布式作业管理系统的核心,常见的作业调度算法有轮转法、多级反馈队列、短作业优先等算法。本文在实现过程中主要采用了两种作业调度算法,并为作业调度算法规定统一的调用接口,方便实现基于不同算法的作业调度。1) 轮转作业调度算法:轮转作业调度算法通过哈希函数将收到的作业分发到不同的 Slave 节点执行,本文采用的哈希函数为取模函数,即 chosenSlaveID = jobID mod slaveNumber。轮转作业调度算法可以保证每个Slave 节点都能较为均等地分配到需要运行的作业,保证了分配给每个 Slave 节点作业数的负载均衡,但是轮转作业调度算法没有充分考虑到作业的运行时长等属性,可能导致部分 Slave 节点分配过多长时间运行的大作业,从而降低该节点的作业执行效率。2) 最少运行中作业调度算法;为了解决轮转作业调度算法的缺点,本文也实现了最少运行中作业调度算法作为Master 进程的配置选项。最少运行中作业调度算法在收到新的作业请求时,会依次查询各个 Slave 节点当前运行的作业数目,并将新的作业发送给正在运行中的作业数目最少的 Slave 节点执行以避免大作业的长时间占用导致 Slave 节点的性能下降。
3 系统实现
本文提出的轻量级分布式作业管理系统主要由Client 端、Master 端以及 Slave 端组成,下面将分别介绍其实现原理和技术细节。
3.1 Client 端

图3 Client/Master/Slave端命令行接口Fig.3 Client/Master/Slave port connmand line interface
Client 端的程序主要由命令行解析器、格式转化器和消息收发器三部分组成,命令行入口如图3 (a)所示。命令行解析器主要负责解析用户的命令行输入,本文设计的轻量级分布式作业管理系统对于作业的操作主要开放了提交、查询和终止三种操作,因此Client 端的命令行接口依次暴露了 submit/query/kill 三个子命令,如图4所示。同时,submit 子命令也提供了不同的命令行选项用来支持不同类型的作业 (二进制作业或者 shell 脚本作业) 的提交。格式转化器主要负责将用户的命令行输入转换为以 JSON 序列化或者以 Google Protobuf 序列化的内部消息格式从而方便消息在Master 和 Slave 节点的流转和解析。消息收发器主要负责和 Master 节点进行消息传递,与 Master和 Slave 之间的通信方式类似,Client 与 Master 之间也是主要通过 HTTP 协议进行通信,消息收发器将序列化后的字节打包到 HTTP 协议的 Body 中进而调用Master 节点的 REST 接口操作作业。
3.2 Master 端
Master 端的程序主要由消息监听器、作业调度器、状态管理器组成,命令行入口如图3 (b)所示。消息监听器在指定端口开启 HTTP 监听服务并将Master 内部的核心功能抽象为 REST 接口[9](定义见表1),同时接收来自 Client 端和 Slave 端的消息请求并将接收到的请求分发到不同的模块进行处理。作业调度器在收到 Client 端或者 Slave 端的作业操作请求时将根据作业操作类型进行相应的操作。新建作业时,作业调度器将依据作业调度算法为作业分配ID 和 Slave 执行节点,并将作业转发给 Slave 节点执行。查询作业时,作业调度器从状态管理器的作业状态表中获取指定作业的状态信息并返回给 Client 端。终止作业时,作业调度器从状态管理器的作业状态表获取作业状态信息和执行节点,并将终止作业的消息转发给 Slave 执行节点。状态管理器负责管理集群的元信息,主要有作业状态表和 Slave 状态表,每当Master 收到作业消息或 Slave 状态消息时,状态管理器就会对相应的状态表进行登记、更新以及删除等操作。同时,为了提升 Master 节点的容错能力,加快Master 节点的故障恢复速度,状态管理器也会定期开启单独的后台线程将状态表刷写到磁盘文件中。

图4 Client 端 submit/query/kill 操作示例Fig.4 Client port submit/query/kill operation example

表1 REST 接口设计Table 1 REST interface design
3.3 Slave 端
Slave 端的程序主要由消息监听器、作业执行器和资源管理器组成,命令行入口如图3(c)所示。Slave 端的消息监听器同 Master 端类似,主要在指定端口开启 HTTP 监听服务供 Master 节点向 Slave 节点发送消息。作业执行器作为 Slave 端的核心模块在收到 Master 端转发的作业消息后根据消息类型执行对应的操作。作业管理器收到 Master 节点转发的新增作业消息后,解析消息体并在Slave 端登记作业信息同时根据作业类型开启对应的后台进程执行作业,在作业执行完毕后 Slave 端修改自身的作业状态信息并向 Master 节点汇报作业运行情况。当作业管理器收到 Master 节点转发的终止作业消息后,作业执行器将根据自身登记的作业状态信息找到对应的后台进程,终止作业运行并向 Master 节点发送作业状态。资源管理器主要负责对 Slave 节点的主要参数信息 (如CPU 使用率、内存使用率等) 进行监控,维持该节点在Master 节点中的存活状态并定期向 Master 节点上报资源使用情况。
3.3 基于 Web 的可视化监控
为了方便用户查看集群中各节点的作业运行情况以及资源使用率,本文也基于 Master 节点提供的REST 接口结合,采用 Ajax (Asynchronous Javascript And XML,Ajax) 异步轮询模式,结合 MVC 模式的Web 框架开发集群可视化监控页面,具体如图5所示。通过 Web 监控页面,用户无须命令行输入即可查询作业的状态信息并动态获取获取各节点的运行状态[10]。
4 结语
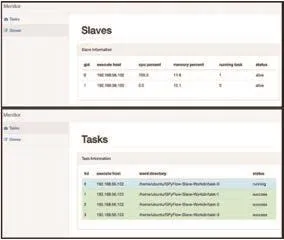
图5 Web 监控界面Fig.5 Web monitoring interfale
本文设计与实现了一种轻量级的分布式作业管理系统,与常见的作业管理系统相比,该系统专注于分布式作业管理的核心功能,易于部署和使用,具有较好的容错能力。目前该系统已部署在3 台 Linux 服务器 (1 台 Master 节点,2 台 Slave 节点) 中,实践效果表明该系统可以对多用户的作业进行有效调度与运行。与此同时,该系统在身份鉴别、作业迁移和调度等方面还有较大的改进空间,加入分布式协同服务以避免 Master 单节点故障以提升高可用性也是将是下一步工作的重点。
