图结构特征挖掘在预测交易风险中的应用
2019-10-11曹俊辉吴开超魏千程
曹俊辉,吴开超,刘 莹,魏千程
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100190
引言
交易风险预测是指在给定部分用户的交易相关信息和用户的风险等级的情况下预测其他用户的风险等级。交易风险预测是互联网金融风险控制中的重要环节,是对抗黑色产业 (羊毛党薅羊毛、银行卡盗刷、信用卡套现等) 的有效手段。目前常用的对抗黑产攻击的方法有传统的基于规则 (黑名单、白名单控制) 的方式,以及基于统计特征的分类模型 (例如逻辑回归)。随着羊毛党行为越发专业化、团队化、地域化,目前的方法不太能满足大数据时代的风控需求。
图是一种经典的数据组织结构,近些年关于图的研究如火如荼。从社交网络到万维网,图结构作为真实世界中信息普遍存在的一种组织方式,通常可用于预测和图节点相关联的缺失信息 (属性、标签),例如:图信息可用于社交网络中预测用户社交圈、网页信息分类等等。图在节点数量大的情况下难以进行复杂计算,需要进行降维。其中,基于图结构特征挖掘的 DeepWalk[1]方法是一种开创性的降维方法,主要思想在于找到一个从图节点到低维矩阵的映方法。
本文针对交易环节中涉及的用户和商户形成的图信息,借鉴 DeepWalk 论文中提出的图结构特征挖掘思路,提出了图结构特征+传机器学习统计特征用于预测节点属性的方法。通过实验对比,验证了该方法比应用传统机器学习方法取得效果更佳,同时在标签数据样本较少的情况下仍然有不错效果。
1 相关背景知识
1.1 图
图(有向图、无向图) 在不考虑节点属性的情况下可以用一个邻接矩阵 V 表示,如图1所示,其中矩阵 V 是一个方阵。图的所有结构信息都蕴含在矩阵 V中,在图节点数量大 (例如:交易中有上亿数量的用户) 的情况下,矩阵 V 是一个高维的方形矩阵,使用矩阵 V 直接进行特征计算会消耗大量的计算资源。考虑到图中任意找俩个节点大概率没有边直接相连的情况下,矩阵 V 是一个稀疏矩阵,若能保留图中大部分的结构信息,矩阵降维成 d 列 (其中 d<<|V|) 后便可以方便的进行特征计算。
1.2 决策树模型
XGBoost和LightGBM是决策树家族最新也是最有威力的模型
(1) XGBoost[8]
XGBoost 的全称是 eXtreme Gradient Boosting。它实现了梯度下降框架下的机器学习算法。它是一种集成的树学习算法,我们可以通过它建立树模型并用其进行预测。它支持多种目标函数,包括回归、分类以及排名函数,而且还可以很容易地自定义目标函数。XGBoost 有以下几点优势:
速度方面它可以自动在Windows 和 Linux 做并行计算。它通常比经典的 GBM[9]方法快 10 倍。
支持多种输入类型
a) 矩阵 matrix
b) 稀疏矩阵 Matrix::dgCMatrix

图1 图数据结构Fig.1 Graph data structure
c) 本地数据文件
d) xgb.dmatrix:自带的类
稀疏性:它支持稀疏矩阵作为输入,并将其进行了优化。
定制性:它支持自定义目标函数和评价函数。
(2) LightGBM[2]
LigthGBM 是一个快速的、分布式、高性能的基于决策树的 boosting[4]框架,可用于排序、分类、回归以及很多其他机器学习任务中。
1) 与 XGBOOT 的区别
XGBoost 采用的是 level (depth) -wise 生长策略,如图2所示,能够同时分裂同一层的叶子,从而进行多线程优化,不容易过拟合;但不加区分地对待同一层的叶子,带来了很多没必要的开销。LightGBM 采用leaf-wise 生长策略,如图3所示,每次从当前所有叶子中找到分裂增益最大 (一般也是数据量最大) 的一个叶子,然后分裂,如此循环;但会生长出比较深的决策树,容易过拟合的问题这里可以通过设置另一个参数 max-depth 来克服,限制分裂产生的树的最大深度。
2) 优势
与其选用流行的 XGBOOT 模型和其他常见的分类模型相比,选用ligthGBM模型有考虑到以下几点优势:
(a) 训练速度快效率高
使用基于直方图的算法,例如,它将乱序的特征值分桶装箱处理,这使得训练速度变快。
(b) 内存小占用小
使用多个离散箱保存并替换连续值使得内存占用少。
3) 准确率更高
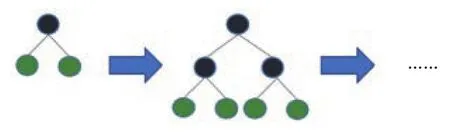
图2 Level-wise 生长策略Fig.2 Level-wise growth strategy
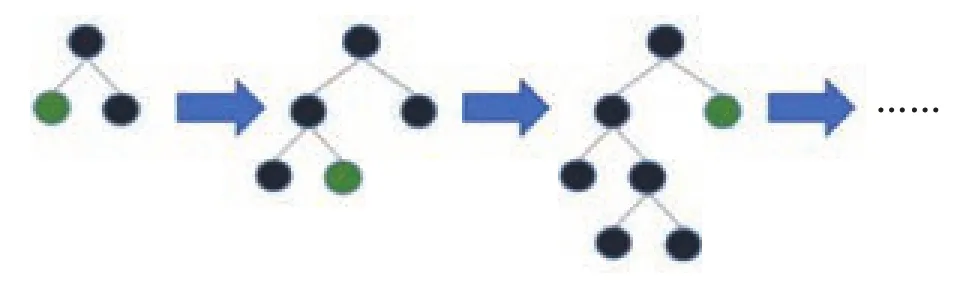
图3 Leaf-wise 生长策略Fig.3 Leaf-wise growth strategy
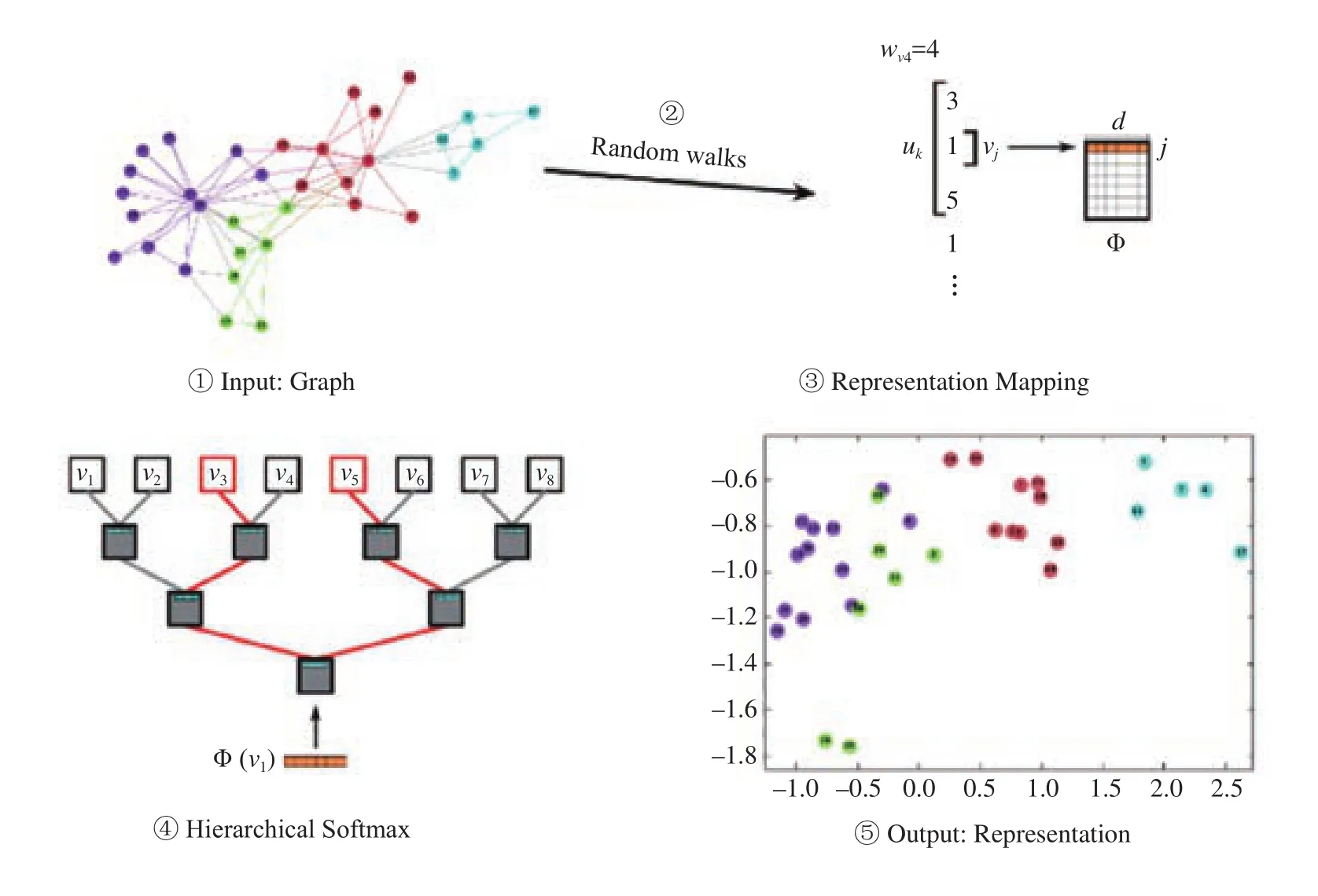
图4 结构特征挖掘步骤示意图Fig.4 Schematic diagram of structural feature mining
通过 leaf-wise 分裂方法产生比 level-wise 分裂方法更复杂的树,这就是实现更高准确率的主要因素。然而,有时候会导致过拟合。因此,可以通过设置max-depth 参数来防止过拟合的发生。
4) 大数据处理能力强
相比于 XGBoost[8],由于 LightBGBM 的在训练时间短,因此具有处理大数据的能力。
2 图结构挖掘算法
DeepWalk 是近些年提出的一个图的表征学习的过程,可以将原本的图邻接矩阵在尽可能保留图结构信息的情况下,降低成一个低维矩阵。根据其中的思想,我们可以将图结构特征挖掘分成以下 5 个步骤,如图4所示:
2.1 步骤介绍
(1) 输入图的结构,输入一个邻接矩阵即可
本文将不同用户商户分别视为图中的一个节点,如图5所示将无向图视为一个上三角矩阵输入。
(2) 随机游走 (Random Walks[3])
每个节点产生γ个随机游走的路径,每个路径长度为t,每次等概论选择当前结点的邻近结点作为下一步,例如:
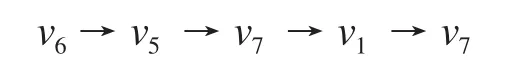
(3) 顶点表征映射 (Representation Mappings)
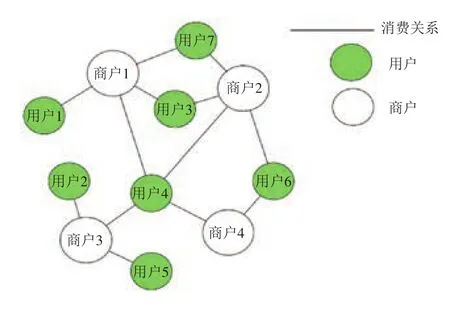
图5 商户用户交易图Fig.5 Merchant-customer relationship graph
将顶点vi映射到该顶点对应的d维向量表示。
定义一个窗口大小为 2w,类似与自然语言模型中的“词长度”,例如,当节点vi上下文是以下
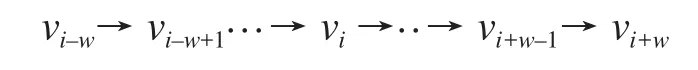
需要最大化表征函数值为Φ(vi) 时,节点上下文为
(vi–w,vi–w+1,…,vi+w–1,vi+w) 的概率,即:
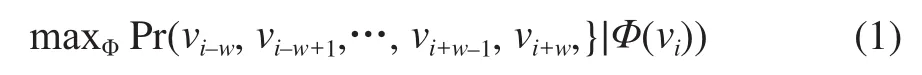
(4) 分层 Softmax (Hierarchical Softmax[5][6])
每次形成一个随机游走节点序列需要最大化公式(1)中的所有节点上下文vj概率,其中最大化一个上下节概率 maxΦPr(vj}|Φ(vi)) 需要更所有 |V| 个节点的概率,这个计算量很大,如果能把顶点放在二叉树叶子上,如图6所示,那么 maxΦPr(v3}|Φ(v1)) 可以等效于

原先更新节点 (v1,v2,...,vN) 概率被替换成更新从根节点到叶子节点路径 (b1,b2,...,blog|N|) 概率,时间复杂度从Ο(ν) 降低到了Ο(log(ν))。
(5) 结果表示
若将图结构信息降低到二维则有类似图4 中 ⑤显示的聚类效果。可以看出,原始图结果 ① 中汇聚的点在降低到二维后仍然有较为明显的聚类效果。本文将 DeepWalk 降维之后的向量用于预测交易风控中的节点的风险属性 (将在第 3 部分重点介绍)。
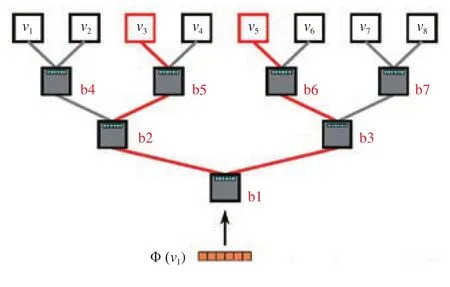
图6 上下文节点概率问题转为树节点概率问题Fig.6 Context node probability transform into tree node probability
2.2 算法分析
如图7所示 DeepWalk 这个算法由两个步骤组成:1.随机游走 2.更新步骤。
算法输入:一个图G(V, E),游走窗口大小w,产生的向量的长度 (顶点表示的维度)d,对于每个点走的次数γ,走的长度t。
算法输出:一个顶点表示矩阵φ,大小为 |V|*d
下面逐行介绍 DeepWalk 算法:
算法 1.DeepWalk
1:初始化表示矩阵φ
2:从节点V中建立一个二叉树 (用于做分层softmax)
3–9:算法核心,外层循环代表了每个顶点产生多少个随机序列,内层循环表示对每个点产生一个wi,并用 SkipGram 进行更新φ
算法 2.SkipGram
3:对随机游走序列中的每个顶点,先把它映射到它的当前表示向量Φ(vj)
4:通过梯度下降法,最大化出现在上下文中所有节点的概率,以此更新向量,其中α为学习率

图7 DeepWalk 算法示意图Fig.7 DeepWalk pseudo code
3 交易风险预测应用
3.1 目的
为了验证我们提出的在交易风险控制中运用图的结构特征挖掘 +LigthGBM 决策树模比传统的基于规则的控制和基于传统机器学习方式好,我们采用“2018年甜橙金融杯大数据建模大赛”公开的数据集进行实验,给定部分已知风险的用户的训练数据,预测其他未知风险用户是否有风险。
3.2 数据说明
天翼电子商务公司最近主办的 “2018年甜橙金融杯大数据建模大赛” 提供的数据,由用户操作详单数据、用户交易详单脱敏后的数据组成。其中字段包含以下几类:
1) 地理位置信息:ip、经纬度
2)日期信息:交易日期、操作时间
3) 用户设备信息:设备号、操作系统、版本号
4) 金额相关:交易金额、账户余额
5) 用户信息:用户 ID
6) 商户信息:商户 ID
7) 活动信息:营销活动编号
8) 风险标识:0 或 1 (0 为正常用户,1 为风险用户)
3.2 结果对比
为了测试我们提出的“图的结构特征挖掘+传统机器学习”的预测效果,我们使用 4.2 中的数据集,其中包含 3 万个用户的 140 万条操作日志和 2.6 万条交易数据进行分类。其中风险标识为异常的用户占13.7%,以下是我们提出的计算模型和其他几种常用的模型作为 baseline 进行实验对比。
方法对比 :
· DeepWalk+LightGBM (本文方法)
采用图结构特征挖掘得到的 128 维特征 (其中参数设置为:维度d=128,窗口大小w=10,每个节点随机游走的次数γ=10,随机游走的长度t=40),利用128特征和特征工程训练得到的 515 维特征合并用LigthGBM 决策树模型进行二分类训练
· LigthGBM (传统机器学习分类模型)
只使用 LightGBM 对特征衍生 (数值类型、枚举值类型)、特征组合 (和时间序列组合、商户号组合)产生的 515 维特征进行二分类训练
· Neighborhood Average (使用平均值)
利用每个用户节点的二度邻近的节点的风险平均值作为预测的结果
· Black List (基于黑名单规则)
利用传统的风控黑名单规则进行判断,凡是风险用户去过的商户都标记成异常商户,用户和异常商户打交道自身也被判定成异常用户。
评测标准如下:
· ACC
表示风险标识预测的准确率
· AUC
AUC 用于衡量“二分类问题”机器学习算法的性能,ROC 是“受试者工作特征” (Receiver Operating Characteristic) ,ROC曲 线下的面积就是AUC (Area Under the Curve)。
最终的分类效果如表1所示,数据集的训练样本取 5% 到 95% 不等进行四种方法的评测,可见采用DeepWalk+ LightGBM 分类算法取得的准确率最高,其中在给定的训练样本比例较少的时候 (<50%) 得到的准确率也高于其它三中方式。这说明结合图结构的特征挖掘可以在样本标签较少的情况下挖掘到较充分的信息。在训练样本 95% 时,对应的 AUC 有最大值,此时评测方法对应的 ROC 曲线如图8所示,可以看到采用结合了 DeepWalk 图特征挖掘的方式,在交易异常检测中得到的二分类效果好于其他。
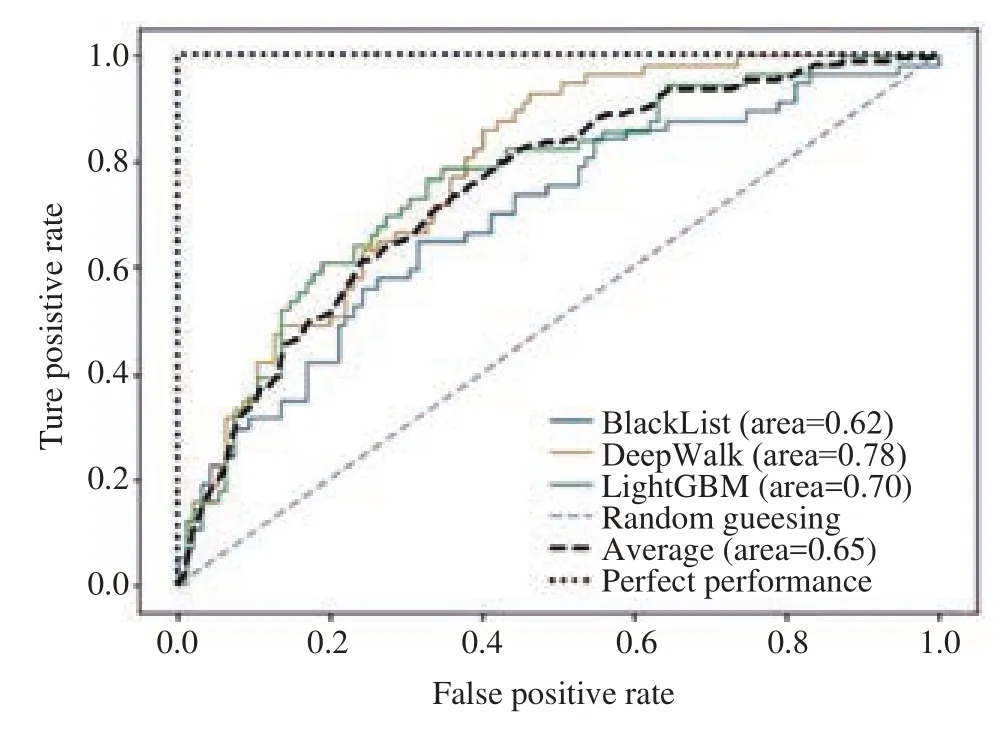
图8 不同的分类方法对应的 ROC 曲线Fig.8 ROC curves of different classification methods
其他几种方式,例如只用 LigthGBM 得到的效果比采用平均值和基于规则方式 (黑名单) 要好,但是没有基于图结构特征挖掘的效果好。这说明单独只是用基于统计特征的机器学习模型挖掘的信息不充分。只用周围节点的平均值作为判定,在样本充分的情况下也能有一定的判别准确率,但是没有利用其它的属性信息,导致能预测的准确率显然有限。最后一种方式,是传统的基于规则的方式判定。利用商户黑名单的方式判定,也能识别出一部分,但是效果远远没有其它等的好,最高的准确率只有 53%。这说明传统的基于规则方式比较落后。
4 结语
本文提出了一种利用图结构特征挖掘和统计机器学习方式预测交易风险的方法。该方法首先将数据以图的形式作为角度考虑,结合流行的 DeepWalk 图特征挖掘,为特征挖掘提供了一种新的思路。从图数据的角度,该方法既用上了图的结构信息,同时也用上了图的属性信息,利用 LightGBM 决策树分类模型将两者的特征联合进行训练,得到最终较好的预测结果。实验表明,使用该方法在预测交易风险时效果显著。而且,在训练样本标签数据较少的情况下,仍然能得到较高的预测准确率。
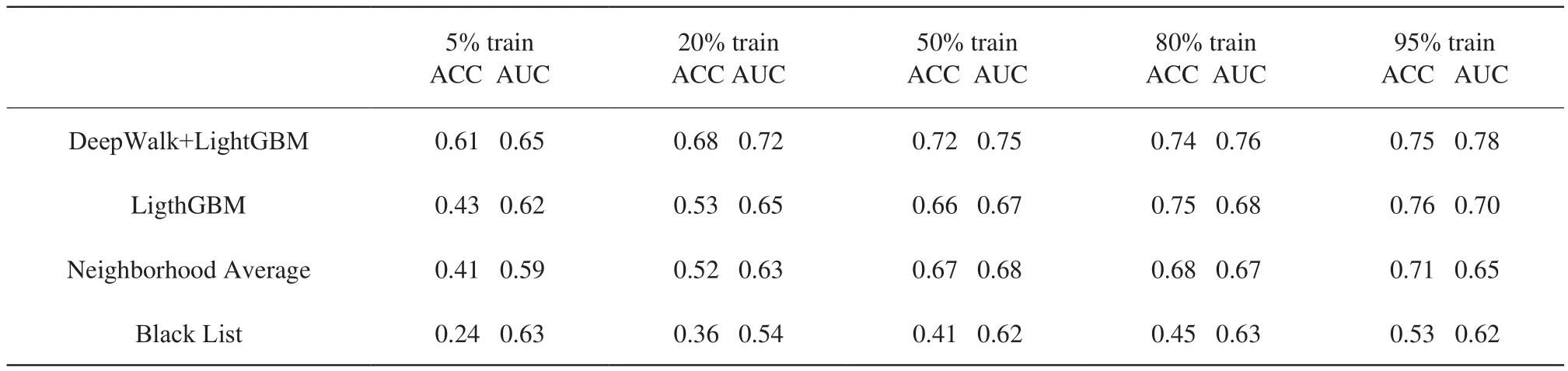
表1 不同分类方法对应的分类效果Table 1 prediction result of different classification methods
