基于深度学习的行人和骑行者目标检测及跟踪算法研究*
2019-07-19胡超超刘军张凯高雪婷
胡超超 刘军 张凯 高雪婷
(江苏大学,镇江 212013)
主题词:YOLO-R网络 卡尔曼滤波 目标检测 深度学习
1 前言
行人、骑行者作为道路交通环境中的弱势群体,其安全问题不容小觑,建立完善的行人和骑行者检测系统已成为研究热点。另外,深度神经网络在机器视觉领域表现出优异的性能,已获得学者们广泛的关注,将深度学习用于驾驶辅助系统正成为发展趋势。本文以车辆前方行人、自行车作为研究对象,开展了基于深度学习的目标检测及跟踪算法的研究。
2 YOLOv2网络改进
YOLO(You Only Look Once)v2网络相比于YOLO网络,在检测率和检测速度上均有大幅提高,为使网络模型更适合检测行人和骑行者目标,本文进一步优化了YOLOv2网络:
a.使用K-means聚类的方法对样本集中标注的目标矩形框进行维度聚类,确定anchor boxes的初始规格和数量。YOLOv2中anchor参数是通过在Pascal VOC数据集中聚类得到的,涉及种类众多,不适合用于训练检测行人和骑行者的模型,因此本文在自制的行人和骑行者样本库中重新聚类,获得anchor参数。
b.YOLOv2网络通过Passthrough层将浅层特征按不同通道数进行重组,再与深层特征结合,得到细粒度特征。但当小目标成群出现时,即使使用了细粒度特征,检测效果仍然不佳[1]。为了解决该问题,在原有YOLOv2网络结构的基础上,去掉Passthrough层,增加残差网络(Residual Network,ResNet),构成YOLO-R网络。修改后的网络结构不仅实现了浅层外观信息与深层语义信息的进一步融合,提高了网络对群簇小目标的检测性能,而且降低了网络的训练难度,防止出现梯度消失现象。
2.1 聚类选取anchor boxes
为了加快收敛速度,提高目标检测的位置精度,YOLOv2中使用K-means方法对样本集中的目标真实框进行聚类分析,得到适合样本集的最优anchor的尺寸和个数。
K-means聚类通常将欧式距离作为评价相似性的准则函数,但本文需对候选框的尺寸进行聚类,如果采用距离评价指标,大框会比小框产生更大的误差,因此改用预测框与真实框的交并比(Intersection Over Union,IOU)来反映两者的差异,IOU越大,两者的相似度越高。聚类的准则函数为:

式中,k、ni分别为聚类数和第i个聚类中心的样本集数;box、centroidi分别为真实框和聚类得到的矩形框;IOU(box,centroidi)为box、centroidi面积的交并比。
聚类数k对聚类效果影响较大,不合理的k值会导致K-means算法最终输出局部最优而非全局最优解。为了解决该问题,本文根据聚类算法中类内相似度最大差异度最小和类间差异度最大相似度最小的基本原则[2],提出了基于IOU的评价函数F。F越小,说明聚类效果越好,其定义为:

同时,k值也影响模型复杂度,其值越大,模型越复杂。因此,k值的选择必须综合考虑模型复杂度S和评价函数F。本文用416像素×416像素的图片需要预测的候选框数目表示模型复杂度S,S=13×13×k。由于这两个评价指标具有不同的量纲,因此先使用minmax标准化方法归一化数据,再作出S、F与k的关系图,结果如图1所示,在平衡了模型复杂度和聚类效果后,本文将k=5的聚类结果作为最终选取的anchor boxes的尺寸。

图1 评价函数及模型复杂度变化曲线
2.2 结合残差网络搭建YOLO-R网络
残差网络可在网络层数较多时防止梯度消失,减轻深层网络训练的负担,其基本模块如图2所示。假设网络的输入为x,要学习的函数映射为H(x),定义残差映射F(x)为H(x)~x,则原始的函数映射H(x)变为F(x)+x,即H(x)由线性映射x→x和非线性映射F(x)组成。试验证明,学习残差映射F(x)较学习原始映射H(x)容易得多[3]。
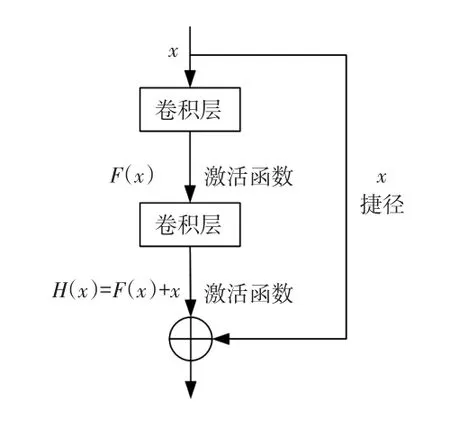
图2 残差网络基本模块
本文在YOLOv2网络结构的基础上,利用残差学习思想,引入跨层捷径,构成了如图3所示的YOLO-R网络结构,其中C层表示卷积层,步长为1,S层表示池化层,方式为最大池化,步长为2。去除YOLOv2网络原有的Passthrough层后,增加了4条捷径。为减少训练过程中的资源空间和计算量,所有捷径的输入都选择原网络中池化操作后的特征图。第1条捷径连接第2个池化层与第5个卷积层后的特征图,第2条连接第3个池化层与第8个卷积层后的特征图,第3条连接第4个池化层与第13个卷积层后的特征图,最后一条连接第5个池化层与第20个卷积层后的特征图。在所有捷径上增加一个1×1的卷积层,使捷径与主径保持相同的维度。捷径与主径汇合使浅层特征与深层特征深入融合,更加充分地利用浅层特征,提高了群簇小目标的检测性能。

图3 YOLO-R网络结构
3 目标检测
3.1 目标检测过程
YOLO网络检测过程如下:
a.将图像及标签信息输入到训练好的网络模型中,图像被划分为13×13个单元格,每个单元格预测5个候选框,共预测13×13×5=845个候选框,然后利用网络前向算法预测每个候选框的相对位置、置信度以及所属类别的后验概率P。
b.对预测的相对位置以及置信度进行映射变换,得到与anchor box更接近的窗口作为检测框。检测框位置预测如图4所示。
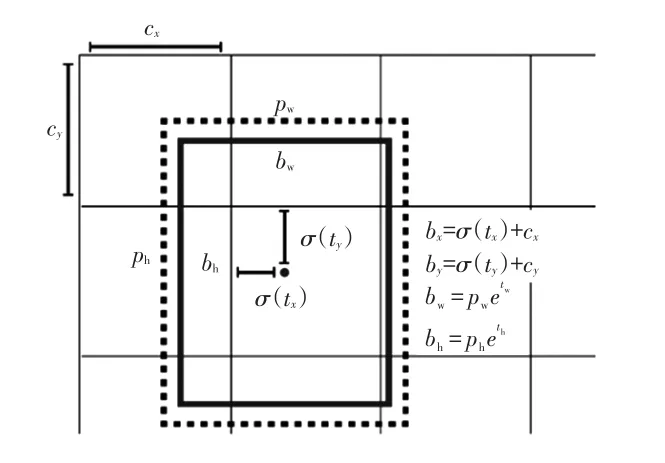
图4 检测框位置预测
c.通过设定阈值T(本文取T=0.25),去除可能性较小的检测框。具体做法是:将σ(t0)与max(p)相乘,得到检测框属于某类别的置信度。如果结果大于阈值T,保留该检测框,否则去除。
d.对每个类别分别进行非极大值抑制[4]处理,去除冗余窗口,具体步骤为:对每个类别的检测框按置信度[5]大小排列;找出置信度最高的检测框,依次与其他框计算IOU,当IOU大于阀值0.4时删除此框,否则保留此框;从未处理的检测框中选出置信度最高的,重复上述步骤,直到所有窗口处理完毕;输出留下的检测框的位置、类别和置信度。
3.2 行人和骑行者分类
图像中的骑行者经过网络模型检测后,会输出行人和自行车2个矩形框。因此本文利用匹配算法对检测算法输出结果进一步融合,完成行人、骑行者分类。
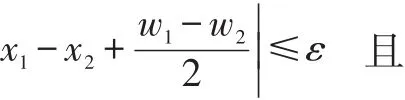

图5 匹配算法
4 基于Kalman滤波的多目标跟踪
本文基于Kalman滤波设计了多目标跟踪算法,流程如图6所示,该算法包含预测、匹配和更新过程,具体步骤如下:
a.根据前一帧的目标跟踪结果,利用Kalman滤波器预测目标在当前帧的位置,获得目标的预测结果Kt。
b.在当前帧中,根据检测结果和预测结果判断匹配情况。通常将欧氏距离作为损失函数[6],但其无法很好地表达两个矩形框之间的匹配程度,因此本文使用预测框和检测框的IOU来衡量匹配度,定义损失函数为:

利用匈牙利匹配算法[7]将检测结果与预测结果进行最优相似度匹配,匹配过程通过最小化损失函数之和实现。
c.处理匹配结果。对于匹配成功的检测目标,用当前帧的预测及检测结果得到目标位置的最优估计值。
d.显示跟踪结果并进行下一帧的预测。
5 试验验证
5.1 试验平台搭建
系统所用的硬件包括1个前视摄像头、1个视频采集卡、1个GPS模块和1台计算机(英特尔酷睿i7-7700K@3.0 GHz,NVIDIA GTX 1060)如图7所示。
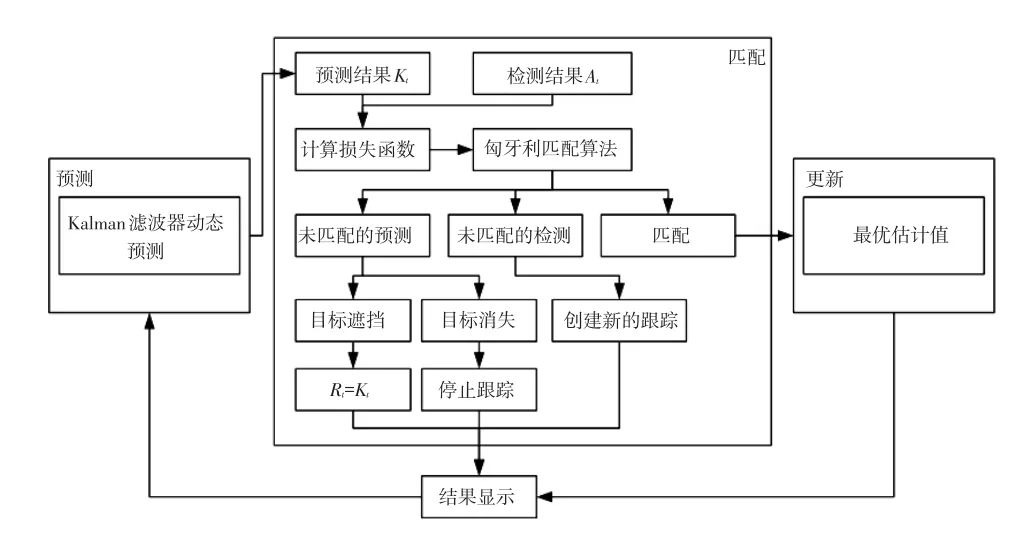
图6 基于Kalman滤波的多目标跟踪流程

图7 硬件安装
在Visual Studio 2015的编程环境下,采用GPU并行计算架构CUDA 8.0、深度学习加速库cuDNN以及OpenCV 2.4.10计算机视觉库实现系统软件编写。并通过微软基础类(Microsoft Foundation Classes,MFC)应用程序进行图形用户界面设计。
5.2 试验结果分析
为了评估本文开发的前方行人和骑行者检测算法的检测性能,在不同背景环境下进行行人和骑行者检测测试,结果如图8所示。从图8可以看出,本文开发的检测算法对不同背景下的目标检测效果良好,并且算法的鲁棒性较好,对于不同姿态以及群簇目标的检测情况,效果也较理想。但当目标与背景颜色过于相近或目标被遮挡严重时,也会出现一些漏检。


图8 前方行人和骑行者检测试验结果
对本文检测算法的检测性能进行定量分析,一般用精度(Precision)和召回率(Recall)评价分类器的性能。精度是指检测结果中正例的数量与检测结果总数的比值,召回率是指检测结果中正例的数量与样本集中标注的目标总数的比值。以精度为纵坐标,以召回率为横坐标,绘制PR曲线后,曲线下的面积即为平均正确率(Average Precision,AP),所有类别AP的均值为(mean Average Precision,mAP):

式中,C为类别数;p为精度;r为召回率。
图9、图10所示为在测试集上分别利用YOLOv2和YOLO-R模型获得的行人和自行车的PR曲线。使用的YOLOv2和YOLO-R网络,除结构及anchor boxes尺寸不同外,训练样本、迭代次数及其他网络参数相同。
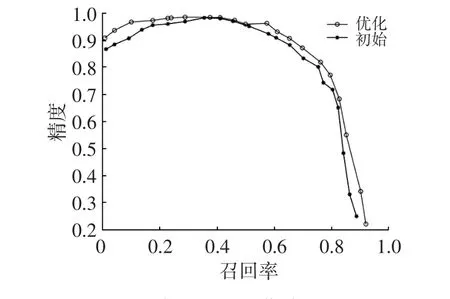
图9 行人的PR曲线对比
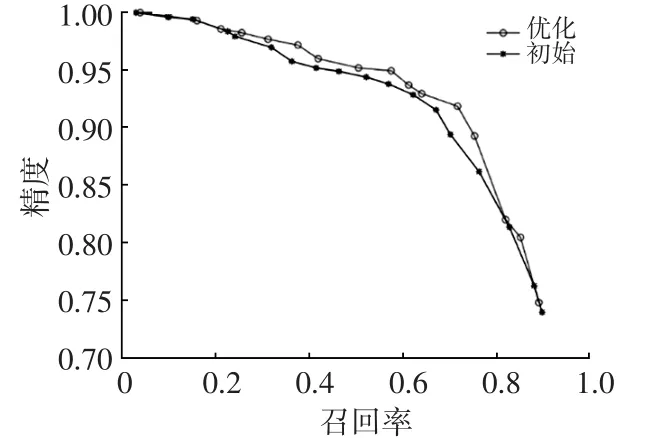
图10 自行车的PR曲线对比
从图9、图10中可以看出,优化后的网络在对行人、自行车的检测上,明显优于原YOLOv2网络。对比原YOLOv2网络和YOLO-R网络的mAP和平均检测时间,结果如表1所示,其中平均检测时间是指网络模型检测测试集中4 500张图片所用时间的平均值。
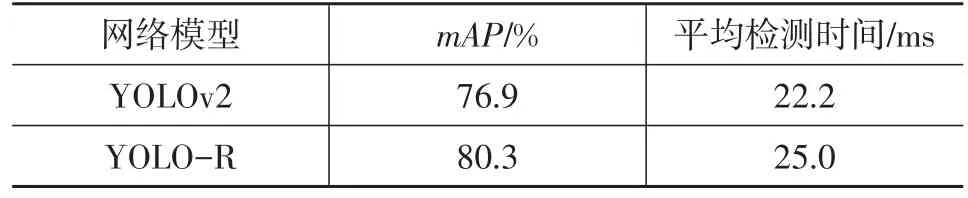
表1 mAP和平均检测时间的比较结果
从表1可以看出:在训练样本、网络参数都相同的情况下,YOLO-R网络的mAP提高了3.4%,这表明YOLO-R网络不仅保留了原YOLOv2网络的优势,其增加的残差网络结构还提升了行人、自行车群簇出现时的目标检测性能;同时,YOLO-R的平均检测时间略高于YOLOv2,主要原因是YOLO-R在结构上比YOLOv2多了4个卷积层,但YOLO-R网络完全可以满足实时性的要求。
6 结束语
本文对YOLOv2结构进行改进,构建了YOLO-R网络,通过训练模型进行目标检测。为了进一步区分行人和骑行者,在目标检测中添加了匹配算法,并利用Kalman滤波完成了对多个目标的跟踪。试验结果表明,与YOLOv2相比,在满足速度要求的前提下,本文构建的YOLO-R网络检测效果更优,YOLO-R网络的mAP提高了3.4%。
