社交网络链路预测的个性化隐私保护方法
2019-06-26孟绪颖张琦佳张瀚文张玉军赵庆林
孟绪颖 张琦佳 张瀚文 张玉军 赵庆林
1(中国科学院计算技术研究所 北京 100190)2(中国科学院大学 北京 100049)3(澳门科技大学 澳门 519020)
链路预测(link prediction)是一种预测节点间关系的重要技术,在社交关系预测[1]、商品推荐[2]等领域得到了学术界和工业界的广泛关注.然而,链路预测过程需要用户社交关系、用户属性等信息,这些信息涉及用户隐私,比如通过用户关注的对象可以分析出用户的宗教信仰等敏感信息.用户为了避免隐私泄露,可能不愿意提供这些信息,这将带来链路预测效果的下降,进一步伤害用户体验.
已有研究提出了在链路预测的过程中为用户提供隐私保护的方法,但目前还存在较多的不足:1)大多数的隐私保护完全依赖于服务商[3].2)有些研究考虑了不可信的服务商,却忽视了不可信的朋友[4].3)为了解决不可信服务商和不可信朋友的问题,部分研究利用加密技术来保证不可信的服务商和朋友不能获取单个用户的个人信息[5].但是,除了加密解密过程带来的计算开销的增加,攻击者仍然可以分析收到的准确计算结果来推断出用户隐私[6].4)社交网络中,用户常常会公开大量非隐私信息,这些信息被攻击者用来反推出用户的隐私信息(即重构攻击[7]),而已有研究都还无法抵御此类攻击.
为了解决现有隐私保护机制的问题和不足,本文设计了一种社交网络链路预测的个性化隐私保护方法,避免不可信的服务商和不可信的朋友对用户敏感链路的推测,并在维持链路预测准确性的前提下提升了隐私保护效果.本文主要的贡献包括3个方面:
1) 提出了一种半集中式的框架.由用户和服务商共同合作完成整个链路预测过程.
2) 提出了一种个性化隐私保护的方法.为了避免不可信服务商和不可信朋友的攻击,将噪声干扰分解为每个用户可独立处理的分量.同时,为敏感信息和非敏感信息添加不同强度的噪声干扰,有效抵御重构攻击的同时保证链路预测的准确度.
3) 从理论上证明我们的个性化的分布式隐私保护机制满足ε-差分隐私,并在真实数据集上验证了其有效性.实验结果表明本文提出的机制实现了隐私保护和链路预测准确性之间的有效平衡.
1 相关工作
本节主要介绍了2类典型的链路预测算法,以及现有的面向链路预测的隐私保护算法.
1.1 链路预测算法
链路预测作为数据挖掘方向的经典问题,在学术界和工业界都受到了广泛关注和重视[1-2].目前链路预测方法主要分为2类:1)基于pointwise的链路预测方法[8].该类方法将训练集中的每对节点作为一个训练数据,将节点间是否建立链路作为分类问题来解决.2)基于pairwise的链路预测方法[1].该类方法的训练数据是2个节点对,通过对这2个节点对的偏序关系来学习一个链路预测模型,使得学习后得到的偏序关系和真实节点间的偏序关系一致.相对于pointwise的方法,基于pairwise的链路预测考虑了节点对之间的相对关系,因而在实际排序中能取得更高的准确性,目前基于pairwise的链路预测方法得到了广泛关注[1,9].
1.2 社交网络中链路预测的隐私保护算法
现有的隐私保护研究都是针对基于pointwise的链路预测的隐私保护方法,包括基于非加密和基于加密2类.1)基于非加密的隐私保护方法主要是由服务商来保护用户的隐私,服务商利用k-匿名[10]等以组为单位进行链路预测,从而使得攻击者无法通过链路预测结果推测目标用户的敏感链路信息.然而,完全依靠服务商存在极大的安全隐患.2)基于加密的隐私保护方法能一定程度上解决不可信服务商的问题,通过设计加密算法对用户的特征信息进行加密,使得服务商无法获知用户的具体隐私信息[5].但这类方法计算开销较大,而且服务商利用获取的最终真实计算值仍然可以推断出用户的隐私信息(即推断攻击[6]).
由于目前基于pointwise的链路预测的隐私保护机制不能直接应用于基于pointwise的链路预测方法,因此结合现有隐私保护机制的问题和不足,以及用户个性化的需求,针对基于pairwise的链路预测方法,还需要提出新的链路预测隐私保护方法.
2 理论基础
2.1 ε-差分隐私
差分隐私是一种常用的隐私保护方法,具有坚实的理论基础.通过在原始数据集中加入噪声干扰,确保数据集中单个数据的变化不会对最终输出结果产生显著影响,能较好地抵御推断攻击[11].
定义1.ε-差分隐私[11].设有随机算法M,Range(M)为所有可能的输出结果构成的集合,对于任意2个最多只有1个元素不同的数据集D1和D2以及S⊆Range(M),如果算法M满足
P[M(D1)∈S]≤eε×P[M(D2)∈S],
则称算法M满足ε-差分隐私要求,概率P表示隐私泄露的风险,隐私预算ε用于衡量隐私保护强度.
定理1.Laplace机制[11].对于任意一个函数f:D→RK,若算法M的输出结果满足等式M(D)=f(D)+[Lap1(GS(D)ε),Lap2(GS(D)ε),…,LapK(GS(D)ε)],则算法M满足ε-差分隐私.其中Lapi(GS(D)ε),(1≤i≤K)是相互独立的Laplace随机数,且对于任意2个最多只有1个元素不同的数据集D1和
为了利用Laplace机制实现差分隐私,我们结合Laplace分布的性质,将其分解为服从高斯分布和指数分布的2个随机数的计算值.
2.2 推断攻击与重构攻击
推断攻击常常用于推测数据集中是否包含目标用户的某条信息[6],而差分隐私可以通过噪声干扰来降低对目标用户的单条信息对最终结果的影响,因而被广泛应用于抵御推断攻击[5,11].
重构攻击则利用公开的信息来重新构建模型,进而推断出用户的隐私信息[7,12].为了抵御重构攻击,Fredrikson 等人[7]证实可以通过极低隐私预算的差分隐私机制来抵御重构攻击,但是极低的隐私预算将严重影响模型的性能.目前还无法在链路预测中抵御重构攻击的同时保障链路预测的准确度.
3 问题描述
社交网络中包含n个用户,这些用户间的关系构成邻接矩阵X∈Rn×n.将用户对(i,j)的关系表示为Xij∈{1,?},1表示已建立有向社交关系(即用户i已关注用户j),?表示用户间目前还未建立社交关系,这里我们可以把?当作0.令用户对建立链路的预
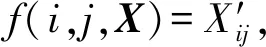
4 社交网络链路预测的个性化隐私保护方法
4.1 基本模型
以目前最常用的贝叶斯个性化排序模型(Bayesian personalized ranking, BPR)[13]作为基本模型,来实现基于pairwise的链路预测:
(1)
这里定义三元集oijk={(i,j,k)|Xij=1∧Xik=0},σ(x)=1(1+e-x)为可将任何值归一化到区间(0,1)的函数,ψ是避免过拟合的正则项,λ为控制正则项范围的超参数.
4.2 社交网络链路预测的隐私保护框架
在学习链路预测模型时,服务器需要根据所有已知链路关系Xij和用户对特征向量fij(包括Xsen,Ysen),来学习、计算出其他变量(即U,V,θ).显然,U,V,θ的整个计算过程都集中在服务器端,这将导致服务商能轻易获取用户的敏感隐私信息.
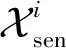
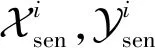
1) 用户对的特征向量fij不仅能够体现用户i的敏感信息,也能反映用户j的敏感信息,所以用户j并不应该将个人敏感信息分享给用户i,这为计算fij,θi带来难题;
2) 由于关注与被关注的链路关系是成对出现的,服务器端V的计算需要U的参与,而每个Ui仅保存在每个用户i本地,所以难以在不伤害用户隐私的前提下完成V的计算;
3) 每个用户的隐私设置不同,用户对相同的关注或特征的敏感与否的判断不同.
为了解决这些难题,我们将介绍求得变量Ui,V,θi最优解的具体算法.
4.3 面向链路预测的隐私保护方法
首先采用梯度下降[9]的方式来学习求得满足式(1)的最优解,迭代更新Ui,Vj,θi直至收敛,在第t次的迭代公式为
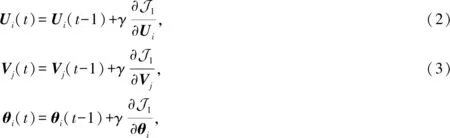
(4)
其中,γ为学习步长(learning rate),目标函数J1关于Ui,Vj,θi的偏导数为
(7)
(8)
此外,我们分别为Pj,Qj赋予不同大小的隐私预算εsen和εnon,其中εsen=βεnon,β∈(0,1),并定义ε=βεnon(1+β).对于不同情况的链路,提供不同幅度的噪声干扰,在涉及敏感链路的计算提供较强的隐私保护,且保证不会大幅削弱整体链路预测效果:
1) 对于某条敏感链路Xij,Vj的偏导数即为
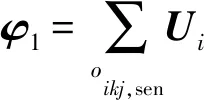
2)对于不敏感链路Xij,Vj的偏导数为
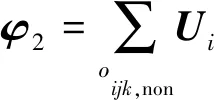
3)对于未知链路Xij=0,Vj的偏导数为
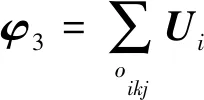
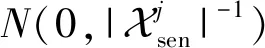
算法1.链路预测隐私保护算法(PrivLP).
输入:隐私预算εsen和εnon、学习步长γ、链路矩阵X、正则项权重λ、敏感矩阵F、用户对的特征f;
输出:U,V,θ.
① 初始化U,V,θ;
② for max iterations
③ forj=1,2,…,n
④ foriwhereFij=1
⑤ 从用户i获取φ1;
⑥ end for
⑦ foriwhereFij=0
⑧ 从用户i获取φ2;
⑨ end for
⑩ foriwhereXij=0
4.4 隐私保护步骤及理论分析
由于每个用户对链路敏感与否的设置是不同的,且服从Laplace分布的随机数之和并不服从Laplace分布,这为满足差分隐私带来了挑战.
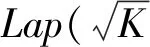
证明. 令εsen=(1+β)ε,εnon=(1+1β)ε.同时,根据高斯分布特征,显然且c服从N(0,1).式(6)涉及到的噪声为
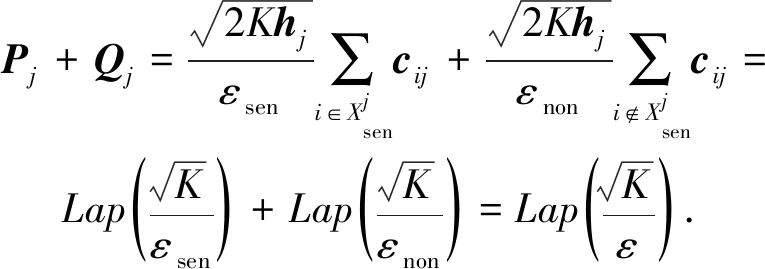
(9)
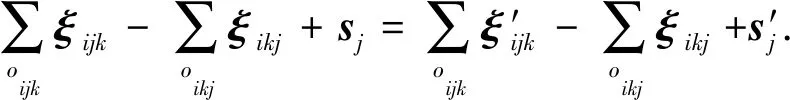
(10)
由于D1,D2只有1个链路不同,假设这是条敏
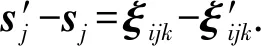
(11)
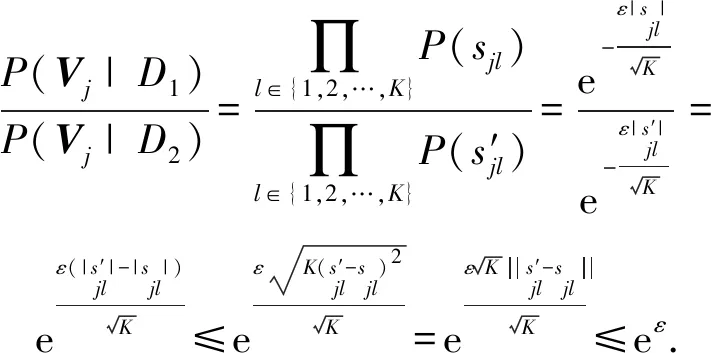
(12)
综上所述,定理3得证.
证毕.
5 实验与结果
为了验证社交网络链路预测的个性化隐私保护算法的链路预测和隐私保护效果,本文选择购物网站Ciao的数据集验证本文提出的PrivLP算法的链路预测和隐私保护效果.Ciao数据集[14]中,一共包括18 998个用户及145 826条有向社交关系,用户-用户链路矩阵的稀疏度为99.96%,适用于基于矩阵分解的方法.我们为每个用户随机抽取了80%的数据加入作为训练集Dtrain,剩余20%加入测试集Dtest,即训练集中,在服务器端学习V、在用户端学习Ui,θi,然后根据学习到的变量计算出用户对间的链路预测值,并在测试集中检验链路预测及隐私保护效果.在这个过程中,用户敏感特征Ysen不需要参与服务器端V的计算,仅参与用户本地的θi的计算.另外,由于每个用户的个性化隐私设置数据难以获取,而对于某些用户的关注更可能被设置敏感链路,所以我们随机抽取用户,对这些用户的被关注链路(即这些用户在链路中是被关注用户)中80%为敏感链路,不断抽取用户直至训练集Dtrain和测试集Dtest中敏感链路的比例为x%,这里x∈{10,30,50}.
我们采取了曲线下面积[13](area under curve, AUC)来衡量链路预测和隐私保护效果,并将基于AUC的衡量指标LAUC定义为
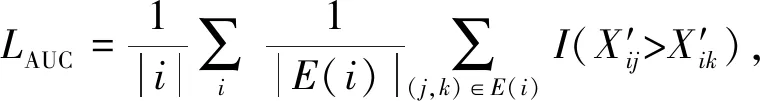
(13)
其中,E(i)={(j,k)|(i,j)∈Dtest∧(i,k)∉(Dtest∪Dtrain)}.对链路预测而言,较高的LAUC意味较好的链路预测效果;对隐私保护而言,较低的LAUC表示提供了较高的隐私保护.
我们选择了目前最具代表性的链路预测隐私保护方法PPLR[4]以及基本模型BPR[13]作为对比.为了简化实验过程,为每个用户统一选择了3个特征用于PrivLP:用户i的好友个数、用户j的好友个数、用户i和j的共同好友个数.ε=0.1,β=0.1.
5.1 链路预测效果对比
由于BPR没有提供隐私保护,所以我们没有将Dtrain中的Xsen加入链路预测的训练中.
随着敏感链路比例的变化,与PPLR及BPR的实验对比结果如图1所示.由于我们是基于BPR的模型,所以在敏感链路较少时噪声干扰导致我们链路预测效果明显低于BPR,这说明噪声干扰和隐私保护确实存在着博弈关系.而随着敏感链路的增加,由于隐私保护机制激励用户将更多的敏感链路加入链路预测的过程,所以链路预测效果反而超过了没有噪声干扰的BPR.总的来说,随着敏感链路数目的增长,虽然我们为每个用户都添加了较大的噪声,我们仍然能够维持较高的链路预测准确度.
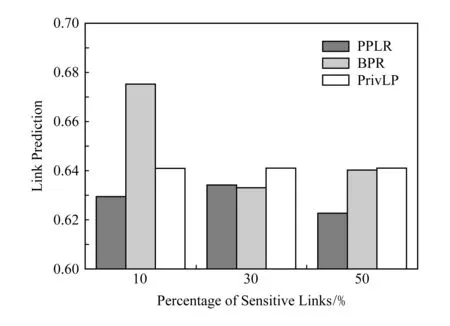
Fig. 1 Link prediction comparison on LAUC with different percentages of sensitive links图1 随着隐私链路数目变化的链路预测LAUC比较
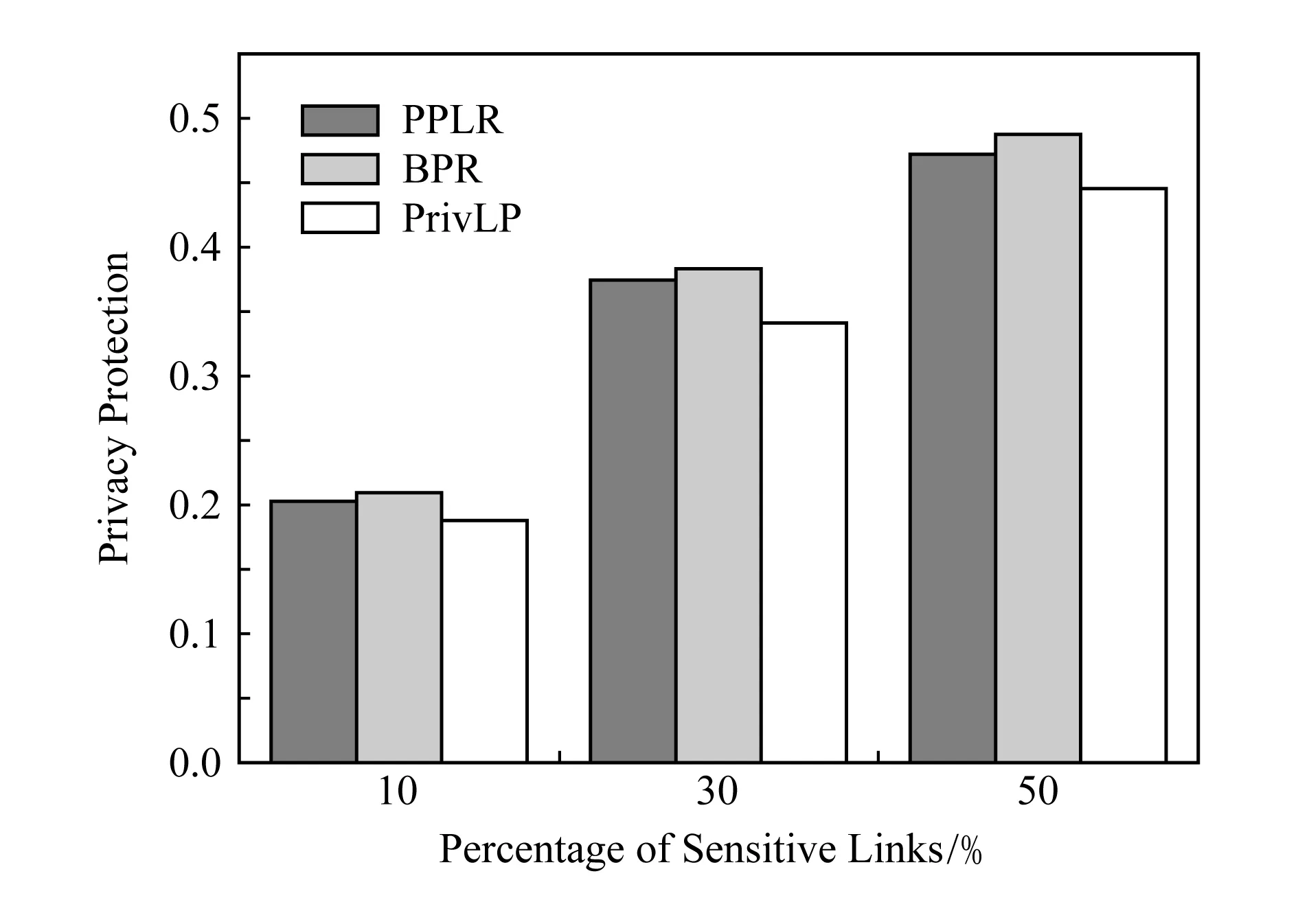
Fig. 2 Privacy protection comparison on LAUC with different percentages of sensitive links图2 随着隐私链路数目变化的隐私保护LAUC比较
5.2 隐私保护效果对比
链路预测的过程中,由于用户i的敏感特征Yisen仅需要在本地参与θi的计算,而不会泄露给服务商或其他用户,所以仅需要考虑对敏感链路的隐私保护效果.由于BPR没有提供隐私保护,所以服务器端能够直接得到Dtrain中的所有数据,并可以根据训练出的变量值预测Dtest中的敏感链路.对于PPLR,所有的参数都存在于每个用户本地,所以仅利用Dtrain中的Xnon,Ynon进行训练,并将学习出的变量用于预测Dtest中的敏感链路.最后,对于PrivLP,由于每个用户的特征选择数目和种类都各不相同,所以攻击者对模型的重构不考虑fij,θi,通过利用共享的V以及训练集中的非敏感数据Xnon重新训练模型
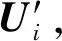
从图2可以看出,PrivLP的隐私保护效果始终处于领先地位.同时,结合图1和图2的结果,我们可以得出结论:我们的方法能够在维持较高链路预测效果的同时有效保护用户隐私.
5.3 参数ε的影响
为了衡量PrivLP随参数ε的变化,我们将x固定为10,β固定为0.01.观察随着ε={0.001,0.05,0.01,0.1,0.5,1,10}的变化对PrivLP效果的影响.从理论来说,隐私预算ε越低,数据干扰强度越高,隐私保护效果越好.从图3可见,随着ε的增长,链路预测和隐私保护的LAUC值处于增长趋势,实验验证了ε的增长能提高链路预测效果,降低隐私保护效果.
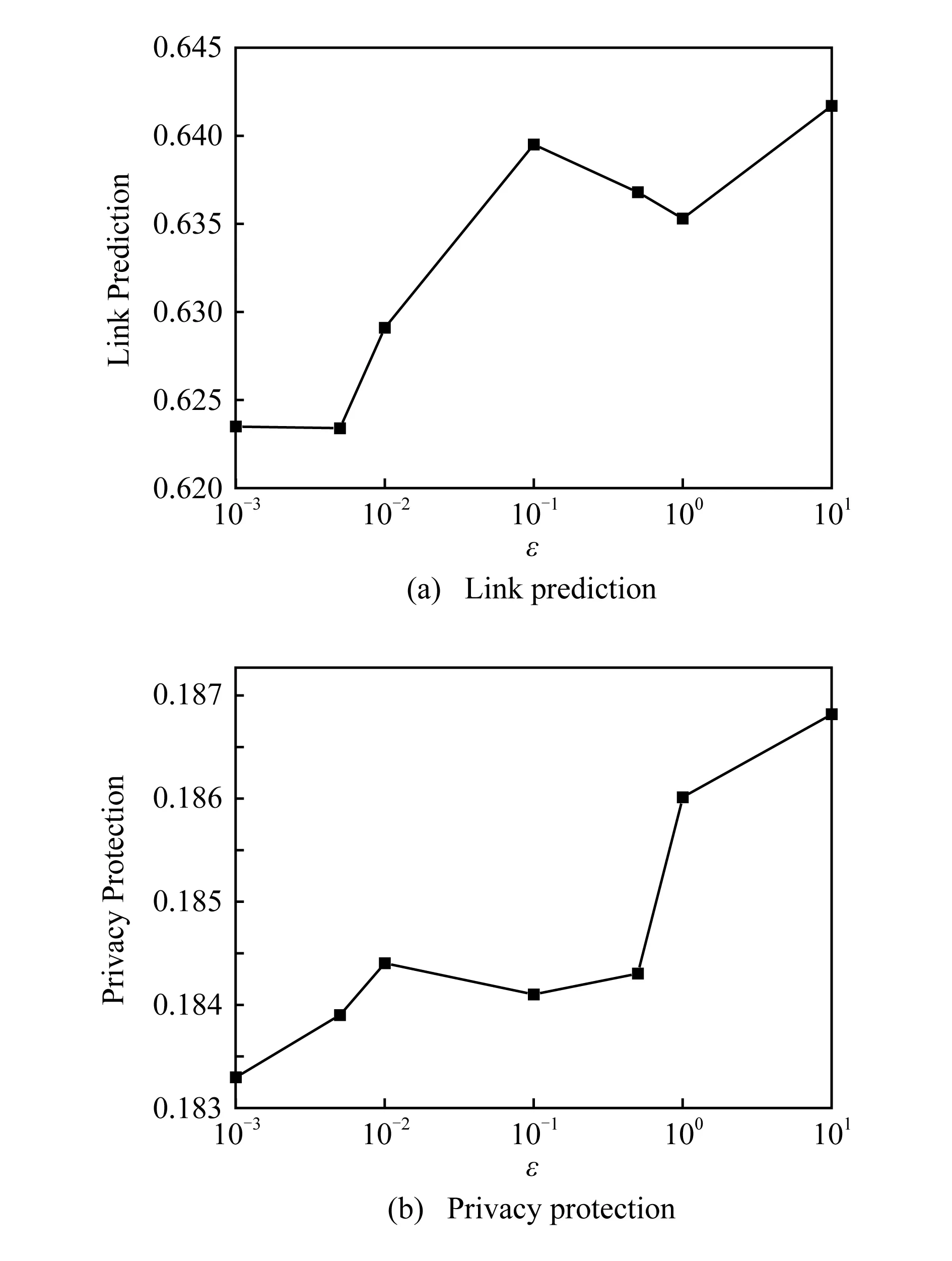
Fig. 3 The impact of ε图3 ε的影响
5.4 参数β的影响
为了衡量PrivLP随参数ε的变化,我们将x固定为10,ε固定为0.01.由于β∈(0,1),所以我们观察随着β={0.001,0.05,0.01,0.1,0.5,1}的变化对PrivLP效果的影响.从理论来说,敏感预算与非敏感预算的比例β越高,对于敏感链路数据干扰强度越高,隐私保护效果越好.从图4可见,随着β的增长,链路预测和隐私保护的LAUC值都处于下降趋势,实验验证了β的增长将降低链路预测效果,提高隐私保护效果.
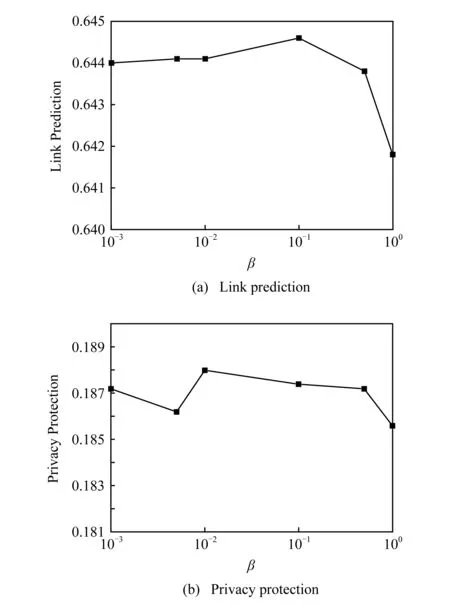
Fig. 4 The impact of β图4 β的影响
6 总 结
为了打消用户隐私泄露的顾虑,我们提出了一种社交网络链路预测的个性化隐私保护方法.摆脱对服务商的完全依赖,让用户和服务商共同合作来完成链路预测;并为敏感信息和非敏感信息添加不同强度的噪声干扰,保护敏感链路不被泄露的同时维持较好的链路预测效果;根据用户个性化的隐私设置,为用户提供个性化的隐私保护.最后,理论证明了提出的方法满足ε-差分隐私,并在真实数据集上验证了隐私保护和链路预测准确性之间的有效平衡.下一步工作将研究如何在动态的链路预测中实现隐私保护.
