面向深度学习加速器的安全加密方法
2019-06-26左鹏飞谢新锋
左鹏飞 华 宇 谢新锋 胡 杏 谢 源 冯 丹
1(武汉光电国家研究中心(华中科技大学) 武汉 430074) >2(华中科技大学计算机学院 武汉 430074)3(加州大学圣芭芭拉分校 加利福利亚圣芭芭拉 美国 93106)
在过去的10年里,机器学习和边缘计算是2个被广泛关注的领域.一方面,机器学习特别是深度学习技术[1]最近取得了巨大的突破,在图片识别[2-3]、语音识别[4-5]、游戏[6]等领域实现了比人类更高的准确率和效率.另一方面,随着边缘设备计算能力和存储容量的不断提升,和不需要向云端远程传输数据等优势,边缘计算[7]也非常受欢迎.因此,越来越多的应用和产品开始探索和结合机器学习和边缘计算两者的优势,最典型的应用是无人驾驶汽车[8]和智能手机[9].通过在其上部署深度学习加速器,无人驾驶汽车可以进行本地计算来实时地对当前路况做出反应,而不用连接到高延迟的远程控制中心.
在深度学习中,深度学习模型是其核心,被认为是需要重点保护的机密信息[10].这是因为深度学习模型是由模型提供商花费大量财力训练出来的,是他们知识产权的重要组成部分和他们业务的核心竞争力来源.另外,深度学习模型通常是使用用户的隐私数据训练出来的,深度学习模型的泄露还会披露训练数据的相关隐私信息.更重要的是,当恶意的敌手获取到深度学习模型后,他可以有针对性地实施对该深度学习应用的对抗攻击[11].
然而我们发现相对于云计算,边缘计算上的机器学习系统产生了新的安全问题.这是因为边缘计算设备上的机器学习系统更容易地被物理访问.因此,边缘设备上的机器学习系统会受到基于物理访问的攻击,例如总线监听攻击(bus snooping attack)[12-13].攻击者通过监听深度学习加速器和内存之间总线上传输的数据,就很容易地获取到该机器学习系统中的深度学习模型.所以加密深度学习加速器的内存总线中传输的数据非常重要.一种直接的方法是,在深度学习加速器的片上加入加密(如AES)逻辑电路[12].当加速器需要写数据到内存中时,先加密该数据再将密文写入;当加速器需要从内存中读数据时,先读密文数据到片上再解密.然而,这种直接加密的方法极大地降低了深度学习加速器的性能.主要是因为深度学习加速器(如GPU)通过高并发来获得高的性能,其性能对内存访问吞吐量极其敏感.内存总线的吞吐量在160 GBps左右[14],但目前最好的硬件实现的加密电路吞吐量只有10 GBps左右[15],从而大大限制了数据访问的吞吐量和降低了加速器性能.
为了解决这个问题,本文提出一个高效的安全机器学习加速器架构COSA,其利用计数器模式加密把解密操作从内存访问的关键路径中移走.具体地,当加速器在内存中读取密文数据的同时,COSA使用一个秘钥、内存行地址和该行的计数器通过AES电路计算出一个临时数据.当密文数据从内存中读取出来后,COSA把密文数据和这个临时数据进行异或操作就解密出了明文数据.可见.加密操作和内存读操作并行地执行了,只有一个异或操作在内存访问的关键路径上,大大提升了加速器性能.本文的主要贡献包括3方面:
1) 发现了边缘设备上深度学习加速器易受基于物理访问攻击的安全问题,并分析了加密对加速器性能的影响.
2) 提出了一个高效的安全深度学习加速器架构COSA,通过把解密操作从内存访问的关键路径中移走来提升加速器性能.
3) 在GPGPU-Sim上实现了提出的COSA架构,并使用公开的神经网络负载进行测试,验证了本文提出方法的有效性.
1 背景及动机
本节首先介绍深度学习加速器的相关背景,然后介绍边缘设备上深度学习加速器的安全性问题,最后讨论一个保证深度学习加速器安全性的直接加密方法.
1.1 边缘计算
由于位于网络边缘的设备上产生的数据越来越多,数据的传输速度成为了云计算模式的瓶颈.巨大的带宽开销和高的响应延时极大地降低了云计算的效率.例如一辆自动驾驶汽车每秒产生的数据高达1 GB[16],其很难通过云计算来处理数据做实时的决策.为了解决这个问题,边缘计算的概念被提出[7,17].边缘计算利用边缘设备上的硬件资源来直接在本地进行计算,这将大大减少了数据处理延时和边缘设备的能耗开销.
1.2 深度学习加速器
深度学习技术在许多领域得到了广泛地应用,如图片识别、语音识别、自然语言处理、游戏等,甚至可以实现比人类更高的准确率和效率.但是,深度学习的高效性依赖于极大的计算开销.深度学习加速器的出现提高了边缘设备的算力,使得深度学习在边缘计算中的使用成为了可能.
GPU是一种最常用的神经网络加速器[18],由于其强大的并行处理能力非常适用于神经网络中的大量矩阵向量乘运算和浮点运算.FPGA也常被用作神经网络加速器[19],由于其可编程的特性可支持灵活地设计新的硬件结构来匹配神经网络算法.另外还有一些专用的深度学习加速器产品,如Google的TPU[20]、寒武纪的Diannao[21]、麻省理工学院(MIT)提出的Eyeriss[22]等.
大部分神经网络推理加速器都可以抽象为如图1所示的硬件架构.加速器片上会集成很多支持高并发计算的处理单元(processing element, PE),一块cache用来存储最近经常被访问的热数据.由于cache的容量很小,其不能存储全部的深度学习模型.整个的深度学习模型会存储在片外的大容量DRAM内存中,加速器需要通过GDDR总线连接片外的DRAM.GDDR总线是一种针对GPU等加速器专门设计的总线,其具有比传统CPU的DDR总线更高的带宽,从而可以支持更高的内存访问吞吐量.
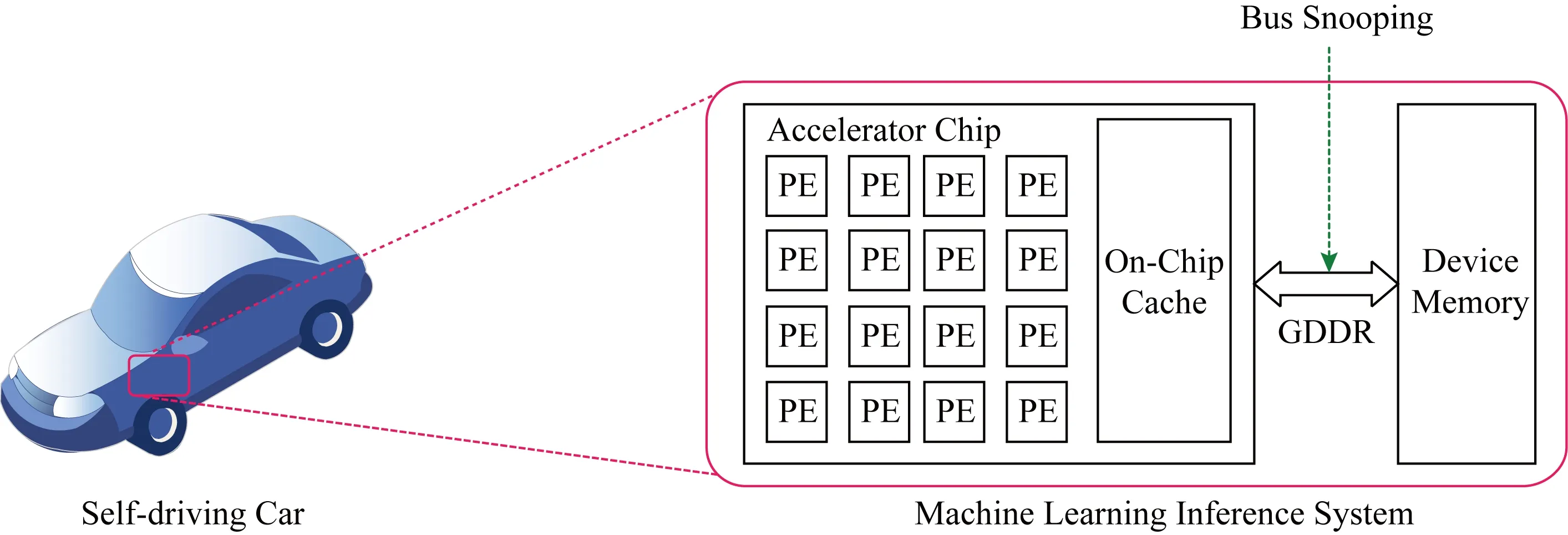
Fig. 1 The architecture of the deep learning inference accelerator on edge devices图1 边缘设备上深度学习推理加速器架构
1.3 安全问题和攻击模型
在深度学习中,深度学习模型作为模型提供商的知识产权是非常重要的数据.我们发现部署在边缘计算设备上的深度学习加速器有泄露其上存储的深度学习模型的风险.与云计算不同,边缘计算中的设备(如无人驾驶汽车)很容易被物理地访问.所以,边缘设备上的深度学习加速器就很容易受到基于物理访问攻击,如总线监听攻击[12].如图1所示,攻击者可以在GDDR内存总线上安装一个探听器,来截获片外内存与片上加速器之间传输的数据,进而获取到整个深度学习模型.另外,本文不考虑总线篡改攻击,其可以通过完整性校验技术抵御[23],与本文的研究工作是正交的.
1.4 直接加密
加密深度学习加速器的内存总线中传输的数据非常重要.如图2所示,一种直接的方法是,在深度学习加速器片上的内存控制器中加入加密逻辑电路,如高级加密标准(advanced encryption standard, AES)[24]逻辑电路.当内存控制器需要将一个内存行写回到片外DRAM内存中时,先将该内存行的数据加密再将密文写入;当加速器需要从内存中读数据时,先读密文数据到片上再解密出明文.
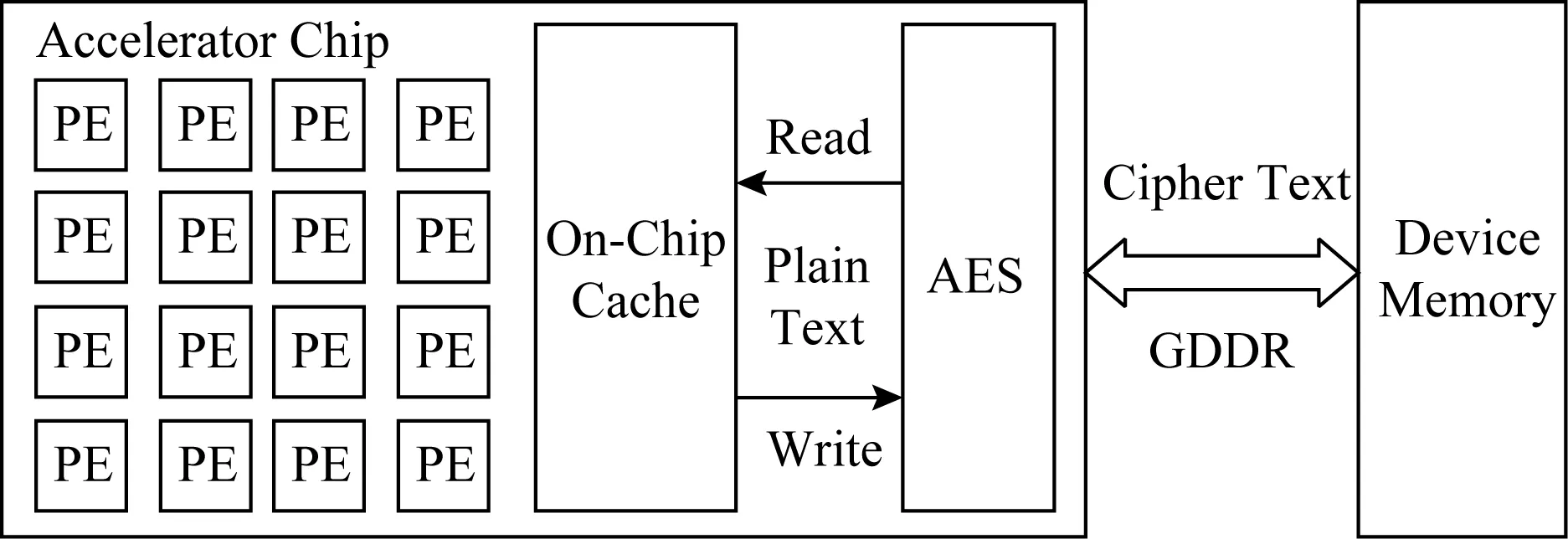
Fig.2 A secure accelerator architecture using direct encryption图2 一个使用直接加密的安全加速器架构
在这种直接加密(direct encryption)的架构中,每次内存读写都需要通过AES做加密或解密,并且加解密操作是在内存访问的关键路径上.然而,目前最好的硬件实现的加密电路吞吐量在10 GBps左右[15],其远低于内存总线的吞吐量(160 GBps左右[14]).使得大量的读写请求在等待AES电路来做加解密,大大增加了计算单元的等待周期从而降低了加速器的性能,如3.2节的实验评估所示.
2 COSA安全加速器设计
本文提出一个高效的安全深度学习加速器架构(COunter mode Secure Accelerator for deep learning, COSA),其利用计数器模式加密(counter mode encryption)[23,25],把解密操作从内存访问的关键路径中移走来极大地提高安全加速器的性能,并且可以实现更高的安全性.本节首先介绍计数器模式加密方法,接着介绍如何在安全的深度学习加速器中有效地使用计数器模式加密,最后介绍COSA的实现细节.
2.1 计数器模式加密
加密内存行的一种简单的方法是用一个全局的秘钥(key)加密所有的内存行,如图3(a)所示.但是,相同的内存行使用相同的秘钥总是生成相同的密文,那么攻击者简单地对比密文数据就可以知道哪些内存行的明文数据是一样的.因此,这种加密方法很容易受到字典攻击(dictionary attacks)和重播攻击(retry attacks)[26-27].一种改进的方法是,使用一个全局秘钥联合该内存行的地址(line addr)来加密该内存行的数据,如图3(b)所示.那么,位于不同内存行地址的相同数据会被加密成不同的密文,可以避免不同内存行之间的字典攻击和重播攻击.但是,在相同行地址先后写入的相同数据的密文却是相同的.因此,这种加密方法会有对同一行地址的字典攻击和重播攻击的风险.
一种更安全的方法是计数器模式加密[25],其给每个内存行分配一个计数器(counter),并使用一个全局的秘钥、该内存行的地址和该内存行的计数器加密该内存行的数据,如图3(c)所示.对于每次写,该内存行的计数器加一.那么,即使在相同行地址先后写入相同的明文数据,其产生的密文也是不同的,从而实现了高的安全性.
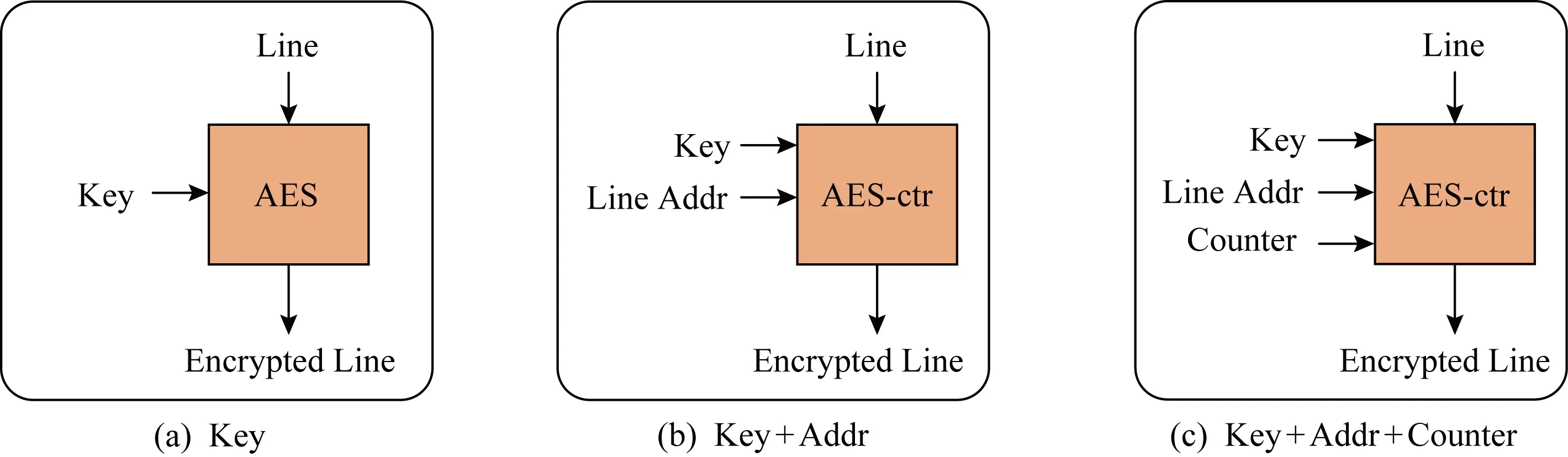
Fig. 3 Different encryption methods图3 不同的加密方法
2.2 COSA安全加速器架构
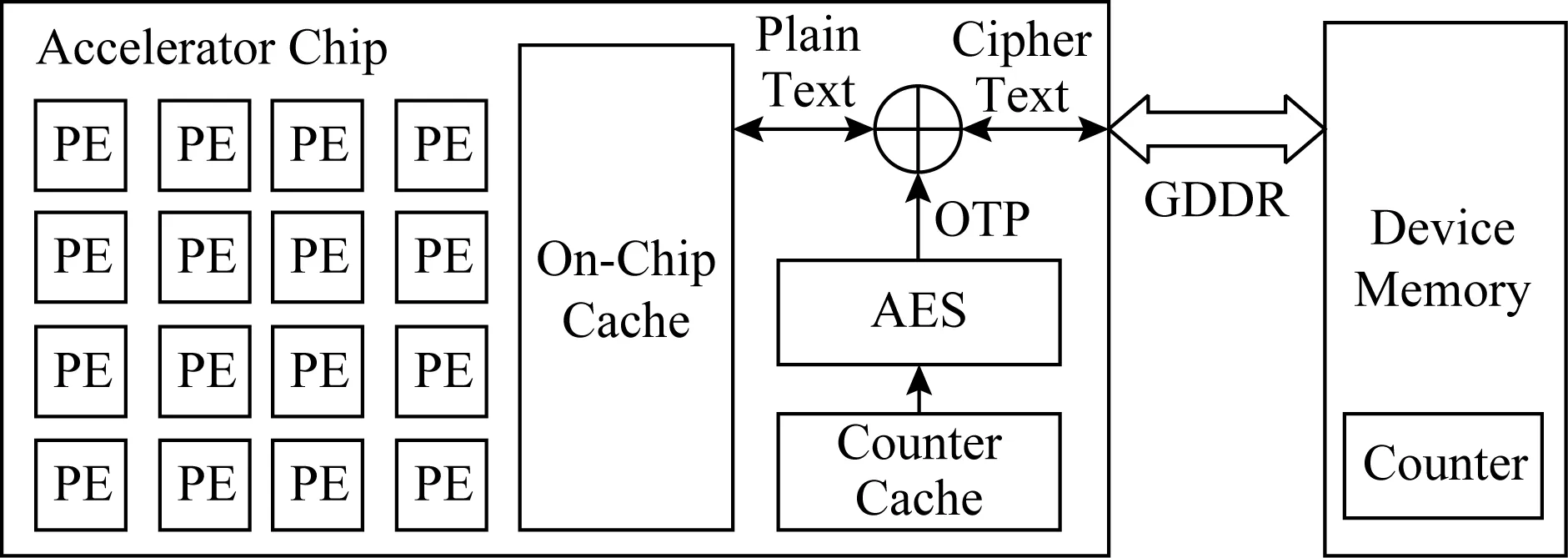
Fig. 4 The COSA hardware architecture图4 COSA安全深度学习加速器硬件架构
通过使用计数器模式加密,本文提出了一种高效的安全深度学习加速器架构COSA,如图4所示.COSA在片外内存中分配了一块空间用来存储所有内存行对应的计数器值,并在加速器片上增加了一个计数器cache(counter cache)来存储最近经常被访问的内存行的计数器值.COSA并不是用AES电路逻辑直接对内存行的数据进行加解密,而是使用一个全局秘钥、内存行地址和内存行计数器通过AES电路逻辑计算出一个一次性的填充数据(one-time pad, OTP).该填充数据和内存行的密文数据进行简单的异或操作就生成了明文数据;同样地,该填充数据和内存行的明文数据进行异或操作就生成了密文数据[12].
这样做的好处是可以并行地执行AES计算和数据读操作.具体地,当一个读请求到DRAM内存中取数据的同时,COSA使用该内存行的地址、计数器值和全局秘钥通过AES电路逻辑计算出一个一次性填充数据(OTP).等密文内存行被读取到片上时,COSA直接将该填充数据(OTP)和密文内存行异或就解密出了明文数据.可见,AES计算步骤被成功地从读操作的关键路径上移走,只有异或操作的延迟被加在了读操作的关键路径上,如图5所示:
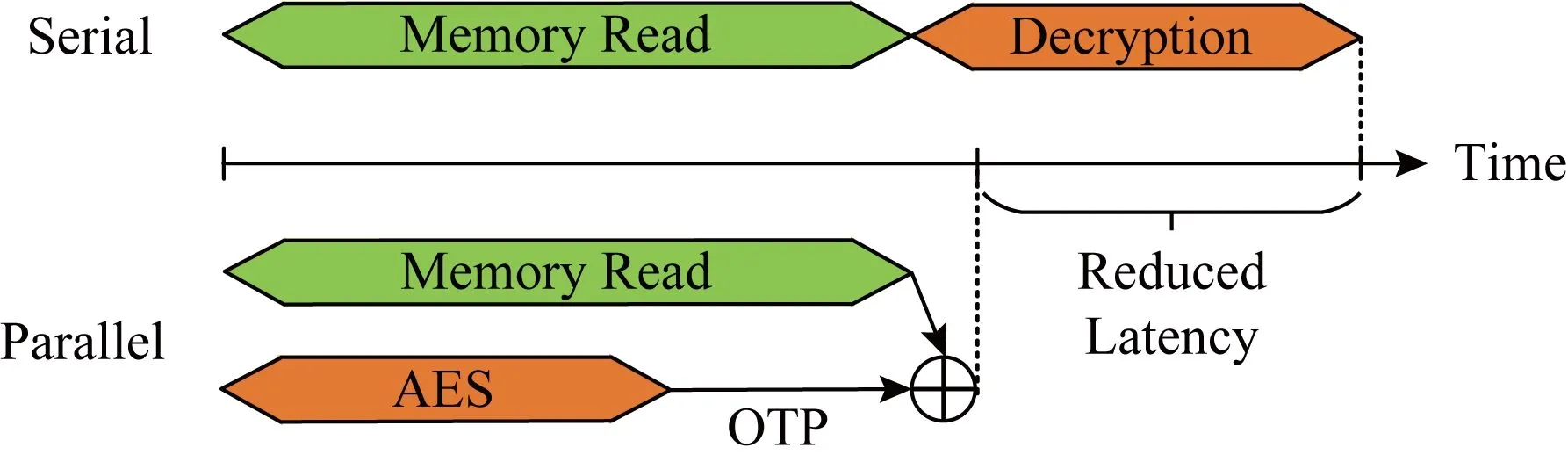
Fig. 5 The parallel encryption in COSA图5 COSA中的并行加密操作
需要注意的是,只有当读请求将要访问的内存行所对应的计数器缓存在片上计数器cache中时,AES计算才能和DRAM内存中的读操作并行执行.如果其所对应的计数器没有缓存在计数器cache中,COSA必须到内存中先读取计数器来形成OTP,再异或数据密文来解密.这样的话,AES计算延迟依然在读请求的关键路径上.
为了解决这个问题,COSA增强DRAM内存中计数器存储的空间局部性并通过预取来提高计数器cache的命中率.具体地,每个内存行对应的计数器是个8 B的值,而加速器(如GPU)的内存行大小通常是128 B.COSA把连续的16个物理地址所对应内存行的计数器存储在一个128 B的内存行中.那么,当一个计数器被访问时,连续的16个内存行的计数器会在一次内存访问中被预取到计数器cache中.接下来如果有对剩余15个计数器的访问,都会命中cache,从而提升了计时器cache的命中率.
由于每个128 B的内存行需要8 B的计数器,COSA只需要6.25%(=8 B128 B)的内存空间来存储全部的计数器.
2.3 实现细节
本节介绍安全深度学习加速器COSA的实现细节,如图6所示. 位于片上的加速器会对片外的DRAM内存发送读写操作请求,这些读写请求都会先放入如图6中下半部分所示的L2到DRAM队列(L2→DRAM Queue)中.另一方面,片外的DRAM内存会返回读请求的数据到片上加速器(图6中的上半部分所示).
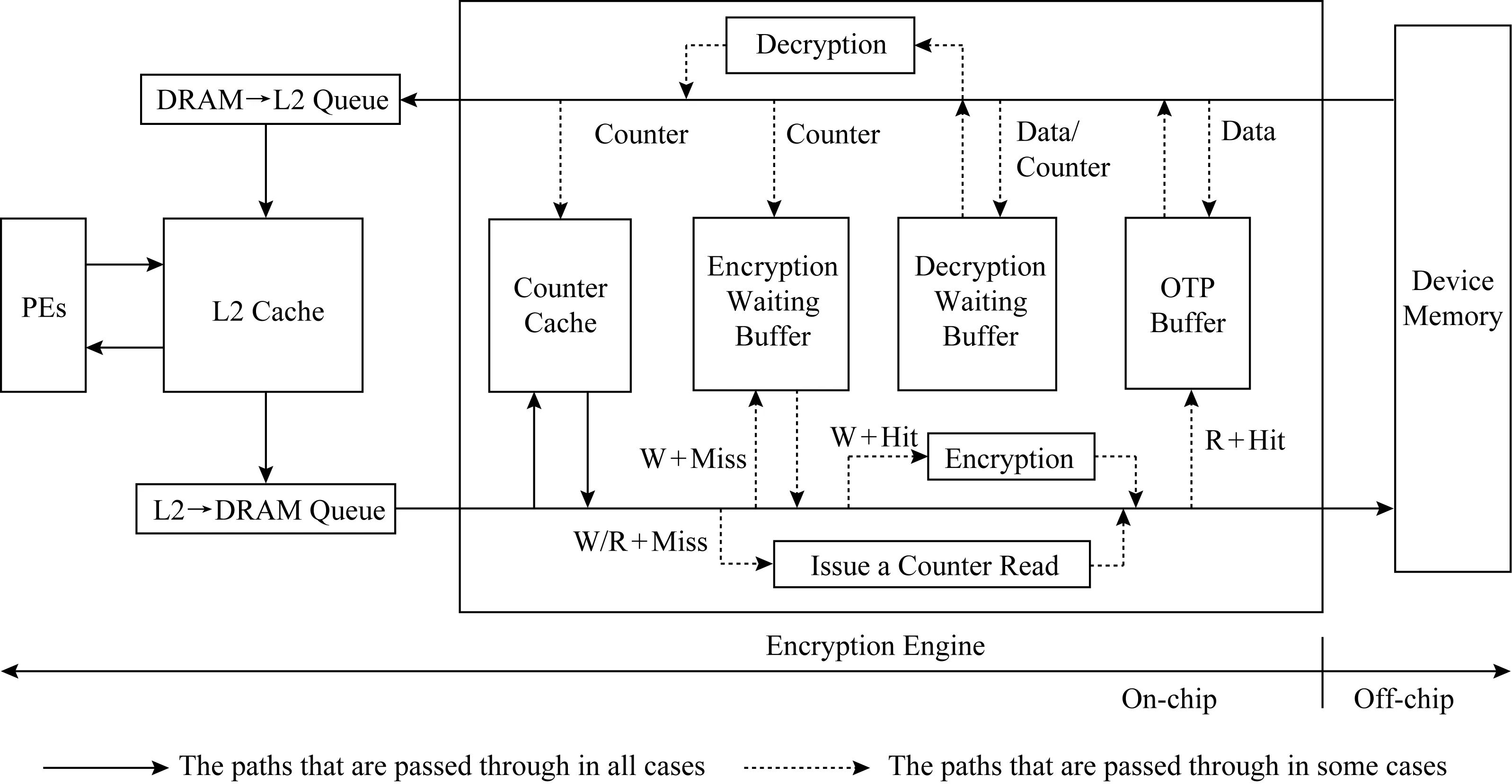
Fig. 6 The workflow of counter mode encryption in COSA图6 COSA中计数器模式加密工作流程
首先介绍片上加速器向片外内存发送请求的流程.发送的请求包括读(R)和写(W)两种请求,不管是读请求还是写请求都需要先查询计数器cache.这是因为写请求需要获取对应的计数器值来加密写入的数据,读请求需要获取对应的计数器值来并行地执行AES计算作解密.根据请求的类型和计数器cache是否命中,COSA需要分别处理4种情况:
1) 写请求+cache不命中(W+Miss).当一个内存写请求对应的计数器值不在计数器cache中时,COSA生成一个对该计数器值的读请求到片外内存,并把该写请求加到解密等待缓存(encryption waiting buffer)中.如果解密等待缓存已满的话,该写请求会等待,直到解密等待缓存非满时再被加入.
2) 写请求+cache命中(W+Hit).当一个内存写请求对应的计数器值在计数器cache中时,COSA使用该计数器通过AES计算出一个OTP来加密该写请求,然后把该写请求发送到片外内存.
3) 读请求+cache不命中(R+Miss).当一个读请求对应的计数器值不在计数器cache中时,COSA生成一个对该计数器值的读请求到片外内存,然后继续把该读请求发送到片外内存.
4) 读请求+cache命中(R+Hit).当一个读请求对应的计数器在计数器cache中时,COSA把该读请求发送到片外内存,同时,使用它的计数器通过AES计算出一个OTP,并把该OTP放到OTP缓存中.
再介绍COSA处理片外内存返回到片上的读请求的流程.返回的读请求可能是数据行或计数器行,所以分为2种情况:
1) 数据行(data).当读请求返回的是数据行时,COSA首先查询OTP缓存中是否有其对应的OTP.如果有,则直接解密该数据行,并删除OTP缓存中对应的该数据的OTP;如果没有,继续查询计数器cache中是否存在其对应的计数器.如果计数器cache命中,则解密该数据行;如果cache不命中,COSA将该数据行放入解密等待缓存(decryption waiting buffer)中.
2) 计数器行(counter).当读请求返回的是计数器行时,COSA先查询解密等待队列中是否有其对应的数据行.如果有,则解密该数据行并将解密后的数据发送到DRAM→L2队列.COSA继续查询加密等待队列中是否有其对应的数据行.如果有,则加密该数据行,并将该被加密的数据行写入到内存.最后,COSA将该计数器写入到计数器cache中.
3 性能评测
为了不失一般性,本文使用GPU一种最常用的深度学习加速器来实现提出的COSA方案.然而,本文提出的安全加密方法COSA实现在深度学习加速器的内存控制器中,从而也适用于其他的深度学习加速器,如基于FPGA和ASIC的加速器.
3.1 实验配置
1) GPU配置.通过使用GPGPU-Sim[28],实现了本文提出的安全深度学习加速器方案COSA.GPGPU-Sim是一个被广泛使用的周期级的商用GPU性能模拟器,其可以支持运行CUDA[29]和OpenCL[30]程序.在测试中,使用GPGPU-Sim模拟的GPU的配置如表1所示.在GPU中的每个内存控制器中加入了一个16阶流水线的AES电路,其加密块大小是128 bit,对一个内存行(128 B)的加解密延迟是40 cycles[31].COSA中encryption waiting buffer,decryption waiting buffer和OTP buffer的大小都为16.

Table 1 Configuration Parameters of the Simulated GPU表1 GPU硬件配置参数
2) 数据集.使用SPASS2009-Benchmarks[28]中的神经网络负载(neural network, NN)来评估COSA的性能.该NN负载使用卷积神经网络(convolutional neural network)来识别手写数字.已经训练好的神经网络权重数据和待识别的手写数字输入已经预先放在片外DRAM内存中.该NN负载允许同时识别多个手写数字来提高并行性,总共识别来自美国国家标准技术局(National Institute of Standards Technology, NIST)数据库的28个手写数字.
3) 实验对比.实验对比了一个没安全保证的神经网络加速器(Un-encr),和一个如1.3节描述的采用直接加密(direct encryption)的神经网络加速器.
3.2 实验结果
实验测试了不同架构的深度学习加速器的每周期执行指令数(instructions per cycle, IPC),如图7所示.由于本文提出的安全深度学习加速器COSA的片上部署了一个计数器cache,不同的计数器cache大小会影响其性能.所以实验也评估了COSA在不同计数器cache大小情况下的性能.
从实验结果中发现,相对于一个没有加密的加速器(Un-encryption),使用直接加密(direct encryption)的加速器性能大大地降低了,其IPC降低高达80%,如图7所示.这是因为在使用直接加密的加速器中加密操作是在内存访问的关键路径上,加密电路逻辑相对非常低的吞吐量严重影响了加速器的性能.本文提出的COSA,相对于直接加密方法极大地提高了加速器的性能.随着每个内存控制器中计数器cache的大小从8 KB增加到64 KB,COSA相对于直接加密方法实现了3.1倍到5.0倍的性能提升.当计数器cache的大小为64 KB,COSA只比不加密的安全加速器慢13%左右.这是因为COSA利用计数器模式加密把很多读请求的解密步骤从内存访问的关键路径中移走了.COSA会产生一些额外的内存访问来读取计数器,但是这不会显著影响性能,因为内存有足够高的带宽.另外,更大的片上计数器cache容量可以实现更高的性能提升,这是由于更大的计数器cache有更高的cache 命中率,如图8所示.

Fig. 7 IPCs of accelerators with different encryption schemes图7 不同加密方法的加速器IPCs
4 相关研究工作
本节首先从算法和架构层面讨论机器学习模型安全性相关的研究工作,然后讨论内存加密相关的研究工作.
1) 模型提取攻击.①算法层面.现有的一些工作把机器学习模型看做为一个黑盒子,然后提出一些算法通过观察该黑盒子的输入和输出数据来提取或推测模型相关的信息.Tramer等人[32]假设机器学习系统输出的分类标签的置信分数(confidence scores)和模型结构(model architecture)是已知的,并证实可以通过置信分数来推测模型参数相关的信息.Oh等人[33]假设模型结构是未知的,然后提出一个元模型(metamodel)方法来获取模型结构相关的信息.Wang等人[34]提出了一个获取机器学习模型的超参数(hyperparameter)的方法.超参数一般被用于平衡目标函数中的正则项和损失函数,知道超参数可以进一步帮助攻击者获取模型参数.②系统和架构层面.现有的一些方法通过利用操作系统或体系架构的一些信息来推测机器学习模型的相关信息.Naghibijouybari等人[35]提出利用操作系统中的侧信道信息,如内存分配API、GPU硬件的性能计数器和时序等,来推测神经网络模型的相关信息如神经元的个数.Hua等人[36]提出利用机器学习加速器体系架构中的侧信道信息如内存访问模式,来推测神经网络的结构信息.
与这些现有的攻击相比,本文关注的是一个更加危险的攻击也就是总线监听攻击.通过总线监听攻击,攻击者不用推测就可以直接获取到机器学习模型的所有数据,包括网络结构和权重参数等.为了抵御这种攻击,本文提出了一个有效的安全加速器架构COSA.
2) 内存加密.内存加密被广泛地应用在安全CPU系统中[12-13,23,26-27].由于CPU系统中的DDR内存总线带宽(10~30 GBps)和AES加密逻辑的带宽(10 GBps)差不多,所以在CPU系统中使用内存加密并不会带来太大的性能损失.然而,机器学习加速器系统如GPU的GDDR总线带宽远高于AES加密逻辑的带宽,并且加速器的性能是带宽敏感的,内存加密会极大地影响加速器的性能.本文提出了COSA安全加速器架构来有效地解决这个问题.
5 总 结
我们发现部署在边缘计算设备上的深度学习加速器有泄露其上存储的深度学习模型的风险.攻击者通过监听深度学习加速器和设备内存之间的总线就能很容易地截获到模型数据.为了解决这个问题,本文提出了一个有效的安全深度学习加速器架构称作COSA.COSA通过利用计数器模式加密不仅提高了加速器的安全性,并且能够把解密操作从内存访问的关键路径中移走来极大地提高加速器性能.我们在GPGPU-Sim上实现了提出的COSA架构,并使用神经网络负载测试了其性能.实验结果显示COSA相对于直接加密的架构提升了3倍以上的性能,相对于一个不加密的加速器性能只下降了13%左右.
