基于3D忆阻器阵列的神经网络内存计算架构
2019-06-26毛海宇舒继武
毛海宇 舒继武
(清华大学计算机科学与技术系 北京 100084)
近年来,基于忆阻器的神经网络内存计算加速器倍受学术研究者和工业界的关注[1-4].研究表明,数据在CPU和片外存储之间的传输消耗的能量比一个浮点运算所消耗的能量高2个数量级[5].基于忆阻器的内存加速器将计算与存储紧密结合,从而省去传统的冯·诺依曼体系结构的中心处理器和内存之间的数据传输,进而提升整体系统的性能并节省大部分的系统能耗[6].此类加速器通过在忆阻器阵列外部加入一些功能单元,使忆阻器阵列能在几乎一个读操作的延迟内完成一次向量乘矩阵操作(matrix-vector-multiplication, MVM)[7],它是神经网络计算中的主要操作.
虽然基于忆阻器的神经网络内存计算加速器有着很高的性能和很低的能耗,但是当它用于神经网络训练任务时,忆阻器阵列的外围电路利用率很低.这是因为:1)当执行前向传播时,用于反向传播的忆阻器阵列的外围功能单元都处于空闲状态; 2)当训练的批大小(batch_size)较小时,无论是在前向还是反向的传播过程中,都有一些忆阻器阵列的外围功能单元处于空闲状态.不仅如此,忆阻器阵列的外围功能单元还占据了极大的面积.例如一个8-bit ADC(模拟转数字的原件)的面积就是一个128×128的忆阻器阵列的面积的48倍[2].由于目前的基于忆阻器的神经网络内存计算加速器的外围电路存在上述2个问题,使得整个芯片的面积大且利用率低.
因此,本文针对上述问题提出了一种基于3D忆阻器阵列的神经网络内存计算架构:基于功能单元池的忆阻器立方体(function-pool based memristor cube, FMC)通过提供一个功能单元池给多个堆叠在其上的忆阻器阵列共享,而不是为每一个忆阻器阵列配备所有的功能单元电路,从而达到减小芯片面积并提高功能单元利用率的目的.这种通过3D堆叠的方式进行功能单元共享的结构不仅减小了所有功能单元的占用面积,还极大地缩短了互联线,使得整体的互联面积减小.与此同时,由于互联线路的缩短,FMC还减少了数据的传输,从而使得整体加速器结构的性能提高且能耗降低.
为了更好地利用FMC,本文用软硬件协同设计的方式,进一步提出了基于FMC的计算数据排布策略——功能单元池感知的数据排布(function-pool aware data mapping, FDM).FDM通过配合FMC工作,使得数据移动更少,功能单元的利用率更高,进而提高整体架构的性能.
实验结果表明:在单个训练任务的情况下,我们提出的FMC能使功能单元的利用率提升43.33倍,在多个任务的情况下能提升高达58.51倍.同时,和有相同数目的Compute Array及Storage Array的2D-PIM比较,FMC所占空间仅为2D-PIM的42.89%.而且,FMC相比于2D-PIM有1.5倍的性能提升,且有1.7倍的能耗节约.
本文的主要贡献有3个方面:
1) 分析并发现基于忆阻器的神经网络内存计算加速器的外围电路存在占用面积大且在神经网络的训练过程中外围电路存在利用率极低的问题.
2) 提出了一种基于3D忆阻器阵列的神经网络内存计算架构,通过将忆阻器阵列3D堆叠在根据系统结构配置设计的功能单元池上来共享外围功能电路资源,从而达到减小芯片面积的占用、提高资源利用率的目的.
3) 提出了一种基于3D忆阻器阵列的计算数据排布策略,通过设计基于3D忆阻器阵列的硬件架构的数据排布策略来更好地利用此架构,使得数据移动尽可能少且资源利用率尽可能高.
1 相关工作
由于神经网络的计算(推理和训练)受限于传统的冯·诺依曼体系结构中片上处理器到片外的存储之间有限的带宽,研究者们提出了内存计算,即将计算单元和存储单元相结合,从而避免两者间大量的数据传输.现在的内存计算可分为两大类:基于忆阻器的内存计算(processing in memory, PIM)[1-4,8-10]和基于DRAM的内存计算——近数据计算(near data computing, NDC)[11-16].PIM通过直接利用忆阻器的特性,将存储资源直接用于做计算,取得计算存储相融合的效果.而NDC则是通过将计算资源靠近存储单元摆放,并通过一些高带宽的连接使得计算资源能快速地访问存储资源,例如混合记忆立方体(hybrid memory cube, HMC).
图1描述了基于忆阻器的PIM的基本电路结构和计算原理[2].如图1(a)所示,每个忆阻器单元的阻值代表一个数值,每个电压代表一个输入值,根据Kirchoff定律,通过模拟电路域的电流加,能得到一个代表输出的电流值,如图1(a)中公式所示.因此,在忆阻器阵列外围加上一些功能单元,如图1(b)所示,一个4×4的忆阻器阵列能够用来存储一个4×4的矩阵,然后加上代表4个1×4的向量的输入电压,就能在几乎一个读延迟内完成一次向量乘矩阵的运算.而向量乘矩阵的运算是神经网络计算中的主要运算,因此,基于忆阻器的PIM加速器能极大地提升神经网络计算的性能.
NDC最常用的硬件结构就是HMC.HMC通过在逻辑晶粒(计算单元)上堆叠一些DRAM晶粒(存储单元),然后用一些垂直贯穿DRAM的穿过硅片通道(through silicon vias, TSV)使它们相连,从而使得计算单元到存储单元拥有很高的访存带宽.但是其本质上还是计算和存储相分离的,不同于基于忆阻器的PIM,NDC中用于存储的DRAM晶粒并不能直接用来做计算.因此,PIM的性能通常优于NDC.
目前对于PIM的研究更多地针对推理,因为推理的计算以及数据流要比训练简单得多,但是它们所用到的硬件功能单元基本一样.文献[1]提出了用具有高存储密度、低读写延迟、相比于其余NVM有较长寿命的ReRAM[17-20]来作为PIM的基础硬件单元,并设计ReRAM阵列可被配置为3种模式:计算、存储和缓存,再通过加上支持其余神经网络计算的硬件单元来做神经网络的推理计算.文献[2]通过使用ReRAM阵列做向量乘矩阵的计算单元,并利用eDRAM作为其存储单元,再通过设计推理的流水线计算,从而提高用PIM来做神经网络推理的效率.文献[3]通过复制多份计算单元,减少当PIM用来做神经网络训练时流水线计算中的空闲,从而提升PIM用来做神经网络训练任务的效率.文献[4]使用比ReRAM有更接近于线性电阻值更新的PCM[21-23]加上CMOS作为PIM的基础硬件单元[24],在同一个阵列中完成神经网络训练时的前向传播和反向传播操作.但是文献[4]只能支持仅有全连接层的神经网络的训练,不能够支持卷积神经网络的训练,而文献[3]可以支持.文献[7]提出了一种用来支持生成对抗网络的基于ReRAM的PIM,它通过软硬件结合的设计,省去生成对抗网络中的冗余计算和存储,并通过运行时可重配的互联提升PIM支持复杂训练数据流时的性能.
然而目前针对PIM的研究都以提高PIM的计算效率为目的,并没有关注PIM的芯片面积以及其中的资源利用率.本文考虑了PIM芯片中的功能单元的面积占用问题及其利用率问题.还需说明的是:本文提出的基于忆阻器的3D结构不同于HMC的结构,其存储本身能够用来做计算,且最下层的逻辑晶粒(本文中的资源池)不仅仅是计算资源,还有用来支撑忆阻器做计算的功能单元(例如图1中的DAC和ADC).
下文首先介绍设计的FMC架构,然后介绍基于FMC的数据映射,再后给出FMC的功能单元资源利用率、空间占用情况和FMC+FDM的性能和能耗等实验结果及相应的分析,最后给出本文总结.
2 FMC架构设计
在本节中,我们首先给出了FMC的架构概要图,如图2所示,然后我们分别介绍FMC的忆阻器阵列、互联结构、共享资源池.
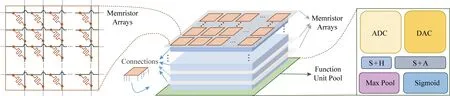
Fig. 2 Outline of the function-pool based memristor cube图2 基于功能池的忆阻器立方体的概要图
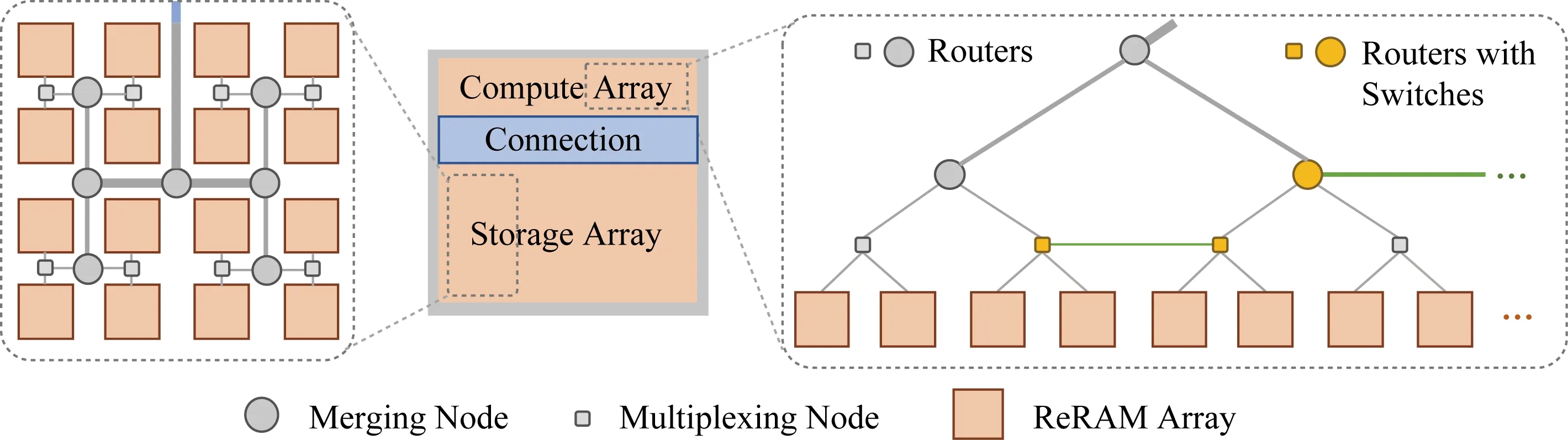
Fig. 3 Intra-connections of 2D memristors图3 忆阻器阵列的平面互联
2.1 FMC架构
FMC架构主要分成3个部分:忆阻器阵列、3D互联结构和共享资源池(如图2的中部所示).共享功能单元池放置于最下方,其上堆叠若干个忆阻器阵列晶粒层.每一层有若干个忆阻器阵列晶粒,一部分用来做普通的存储(本文中称为Storage Array),一部分既可以通过配置用来做存储也可以设置其用来做计算(本文中称为Compute Array).每一层均通过垂直的连接和共享资源层相连.其层数以及每层忆阻器阵列的数目受限于工艺大小以及资源池的资源多少.
2.2 FMC的忆阻器阵列
FMC使用cross-bar结构的ReRAM作为其基础硬件单元,如图2左部所示,保留了作为存储器时的外围电路单元,例如写驱动(未在图2中标出).每一个正方形表示一个ReRAM cell.当这个忆阻器阵列被配置成Compute Array时,每个ReRAM cell用来存储一个神经网络中权重的值或者存储值的一部分(即用多个cell存储一个值,每个cell存储多个位);当这个忆阻器阵列被配置成Storage Array时,整个阵列就被当做普通存储器使用,一个cell存储一个位.
2.3 FMC的互联结构
FMC中的每层忆阻器阵列Storage Array中的忆阻器阵列通过H-tree的方式进行连接,Compute Array中的忆阻器阵列通过基于H-tree的可重配的连接方式进行连接(与文献[7]的平面连接方式相同).Storage Array和Compute Array之间通过一个高速的共享线路进行连接.
图3给出了忆阻器阵列的平面互联结构.左边是Storage Array的互联结构.和普通存储一样,Storage Array用H-tree的连接方式:灰色圆圈代表merging node,连接的父节点的线路宽是连接子节点线路宽的2倍;灰色方块代表multiplexing node,连接的父节点的线路宽和连接子节点线路宽一样.右边是Compute Array的连接方式:我们保留原来的H-tree的连接方式(图3中灰色线条),并在同一层连接节点中不共父节点的节点(如图3中黄色节点所示)之间加上一条电路线(如图3中绿色线条所示).新加的这条电路线的宽度与其连接其父节点的线路宽度相同.由于接口有限,图3中每个黄色节点被增加了一个转换接口,使得它们能选择连到它们的父节点或者相邻节点.这种能够在网络训练时的动态配置的连接方式不仅能够支持快速的Compute Array之间的数据传输(开关拨到横向连接线上,跨过H-tree结构进行通信),还能支持快速的权重更新,即Compute Array的读写(开关配置成H-tree的连接方式).图3中间蓝色部分表示的是Compute Array和Storage Array之间的共享高速连接,这部分并不是将它们直接相连,而是经由共享资源池将它们相连(如图2中蓝色部分所示).
Compute Array中每一个忆阻器阵列(橘黄色方块)都配备有一个转换接口,能控制每个忆阻器阵列是垂直连接(连向共享资源池或者不同平面的忆阻器阵列)还是平面连接(连向同平面的忆阻器阵列).如果一个忆阻器阵列连接到下一个忆阻器阵列,那么我们称这2个忆阻器阵列是在同一个模拟电路域的,反之则不是.我们把一个模拟域内的所有连向共享资源池的阵列连接叫做这个模拟域的出入口,入口连接共享资源池的DAC分池,出口连接S+H池.
当有多个FMC时,各个FMC之间通过C-mesh的连接方式进行互联,每个FMC的共享资源层能够访问其他FMC的Storage Array,但是不能使用其他FMC的Compute Array,即FMC之间只在数字域进行通信而不用模拟信号通信,这样确保了模拟信号的稳定性和计算的准确性.
2.4 FMC的共享资源池
共享资源池由六大部分组成(如图2右部所示):DAC池、S+H池、ADC池、S+A池、MP(Max Pool)池和激活函数单元池.每个分池由若干个功能单元组成.表1给出了这些功能单元的名称及其对应的释义.
图4给出了各个分池之间的互联结构.DAC池连接模拟电路域的入口,S+H池连接其出口.S+H池和ADC池相连接,ADC池可选择连接S+A池、MP池、激活函数单元池和Storage Array部分.S+A池可选择连接MP池、激活函数单元池、DAC池和Storage Array部分.激活函数单元池可选择连接MP池、DAC池和Storage Array部分.MP池可选择连接DAC池和Storage Array部分.每个分池内的计算资源通过C-mesh进行连接,分池之间通过高速共享线路进行连接.

Table 1 Notations of Function Units表1 功能单元的参数表示
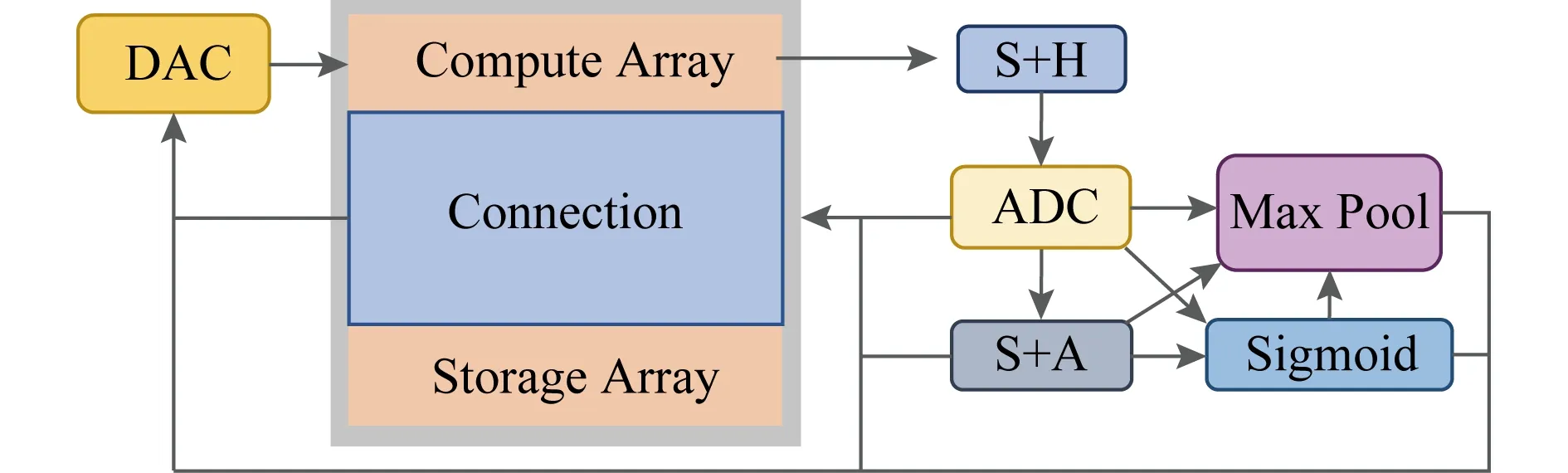
Fig. 4 Intra-connection of sub-pools in function unit pool图4 共享资源池各个分池之间的互联结构
表2提供了共享资源池中功能单元的各个配置参数表示,我们将使用这些配置参数来介绍共享资源池的具体设计方法.
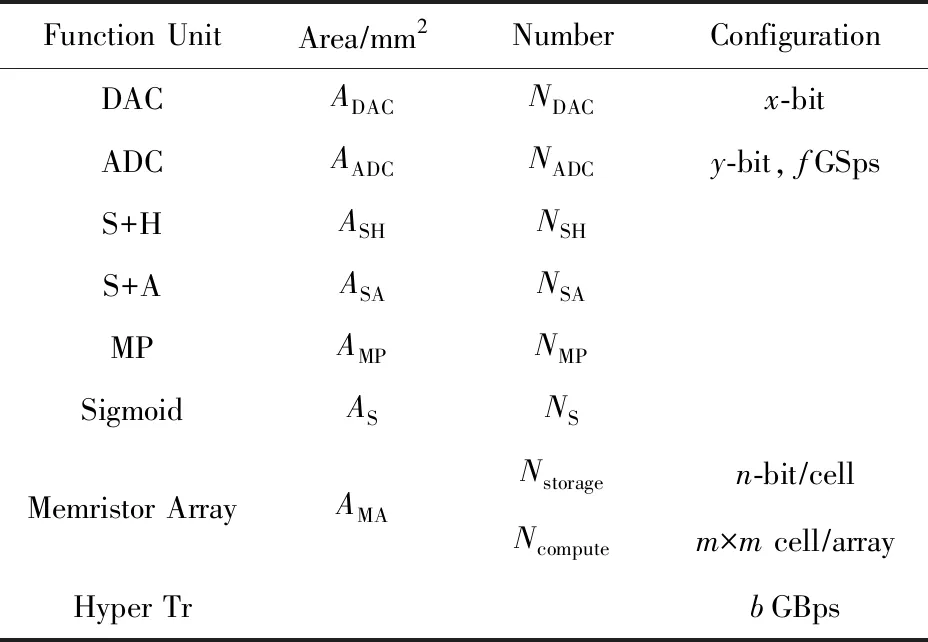
Table 2 Configurations of Function Units表2 功能单元的配置参数
表2是各个单元的相关配置参数表示,FMC的功能单元池的面积AFUP可表示为
AFUP=ADACNDAC+AADCNADC+ASHNSH+
ASANSA+AMPNMP+ASNS,
即功能单元池的总面积等于各个功能分池的面积和,各个分池的面积又取决于单个功能单元的面积以及其个数.为了节省FMC总体占用空间,其功能单元池的面积AFUP需满足:
其中,0≤θ≤0.1.即功能单元池的面积既不能小于其上堆叠的ReRAM阵列的面积,否则无法充分利用功能单元池的空间;也不能过分大于ReRAM阵列的面积,否则会导致3D堆叠时的连接线路过长,不高效.同时,为了使得模拟电路域到数字电路域的顺畅转换,ADC和DAC单元的参数需满足:
x×NDAC=n×m
(1)
(2)
其中,latencyPIM是每个忆阻器阵列一次模拟域向量乘矩阵运算的延迟,单位是ns;NSubCom是在一个共享线路上的所有用于计算工作的忆阻器阵列的数目.式(1)主要使得DAC转换的位数和一个阵列中一行的位数相等,避免计算延迟.式(2)主要使得ADC转换的位数不能小于计算速度,防止计算出来的数据阻塞在ADC之前;且ADC转换速率不能大于传输速度,否则算出的数据会被阻塞在ADC之后.
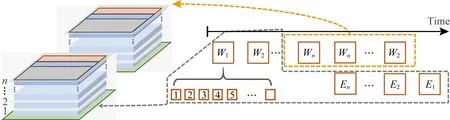
Fig. 6 An example of FDM图6 FDM策略的一个示例
有了这些公式的限制,我们就能根据实际系统情况的限制以及任务的需求,很好地制定出我们所需的功能单元池中每个功能单元的数目,从而设计高效的功能单元池.
3 FDM策略设计
在本节我们介绍FDM策略,配合FMC的硬件结构,使得存储与计算资源分配合理、数据传输尽可能少、共享资源池的资源利用率尽可能高.由于FMC中有多层PIM阵列层,每层只有有限个PIM阵列,所以在神经网络的训练过程中可能需要多个PIM层的多个阵列.每一层中PIM阵列的数据传输要比每层间的数据传输延迟小,并且神经网络的每个层之内、每个层之间已经训练的不同阶段都会有数据依赖.因此FDM的核心思想是将有数据依赖的数据块尽量存在一个PIM阵列层上,将没有数据依赖的计算块放置于不同PIM层以方便它们共享资源池中的资源.图5给出了在PIM中训练一个神经网络的数据存储和数据流图.正方形表示数据存储在Compute Array中,直接用来做计算;圆角矩形表示数据存储在Storage Array中,用来暂存数据供给Compute Array做计算.图5中的W表示Weight,E表示Error,O表示Output.训练时的前向传播和反向传播是串行的,而反向传播包含2部分:误差传播和权值计算,二者是并行的.因此,当只有一个训练任务时(训练一个网络),我们尽量把串行的部分切割排布到同一个FMC中,使得它们能够时分复用共享资源池;把并行的部分排布到不同的FMC中,避免它们对资源池的访问造成冲突.
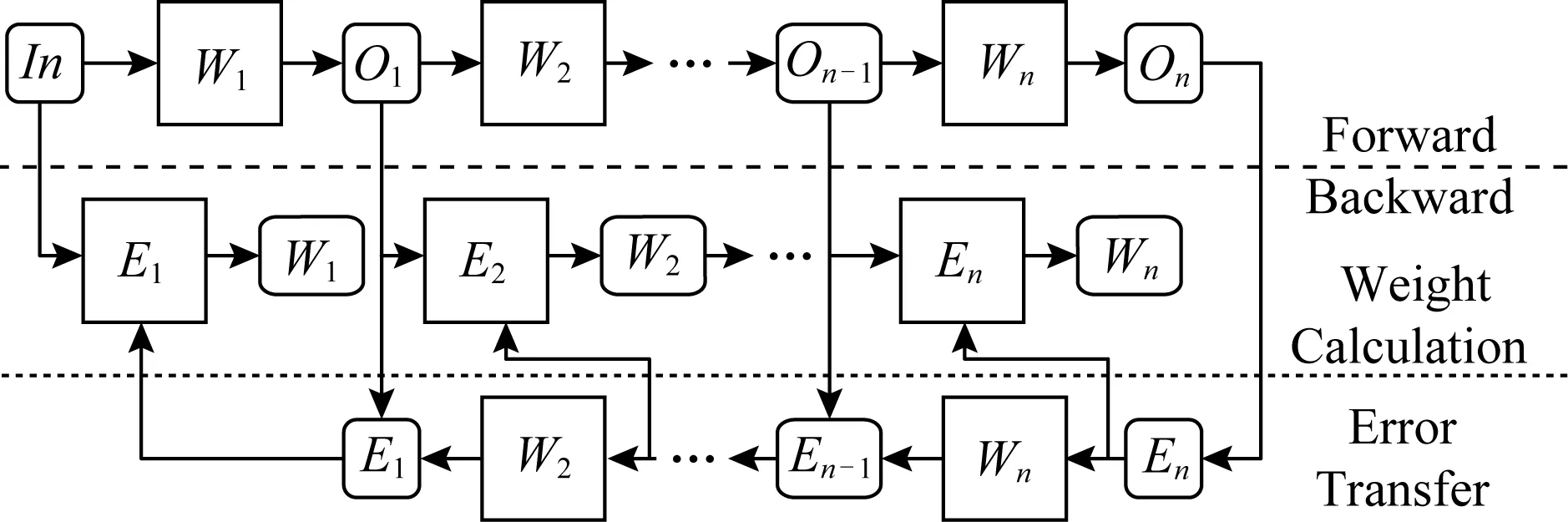
Fig. 5 Data graph of training a neural network图5 训练一个神经网络的数据图

如果一层的权值需要多个忆阻器阵列进行存储,那么我们把它们均匀地分布到一个FMC中的所有忆阻器阵列层上(图6中从第1层到第n层进行循环分配,直到分配结束),因为它们之间不需要进行通信,所以不必在同一个平面层中,其余各层按照这个方式进行分配.这样做还为了使得所有神经网络层能有几乎一样的计算效率,能够有几乎相等的访问共享资源池的延迟(避免如将第1层神经网络权值分配到FMC的第1层忆阻器阵列、最后一层神经网络分配到FMC的最后一层忆阻器阵列,从而导致因最后一层访问共享资源池的延迟大而造成性能差的问题).当有多个训练任务时,我们将多个训练任务均匀分配到所有的FMC中.
FDM的整体流程如图7所示.首先将多个网络分配到多个FMC中,每个网络可能在一个或多个FMC里;然后将每个网络的不同层部分分配到FMC中;最后把网络每个层的各个部分分配到FMC的各个PIM阵列层中.

Fig. 7 Flow chart of FMC图7 FMC的流程总体流程
4 实验与分析
本节首先介绍实验环境、参数配置以及实验方法,并简要介绍所用的对比实验的结构和参数配置;接着给出实验结果和相应的分析,包括FMC的功能单元资源利用率、空间占用情况和FMC+FDM在训练各个神经网络时的性能和能耗比较.
4.1 实验方法
表3给出了实验环境和具体的基于ReRAM的主存参数配置.整个系统将CPU作为中心任务处理器,统计好训练任务的数量以及每个任务所占空间大小后,按照FMD的策略将训练任务发布到整个PIM中.发布完任务后CPU不再参与整个训练工作,所有的训练工作包括计算和数据存取都在基于ReRAM的主存中进行.本系统不考虑DRAM和ReRAM的混合主存,所有用来支持训练的数据都存放在基于ReRAM的主存中.
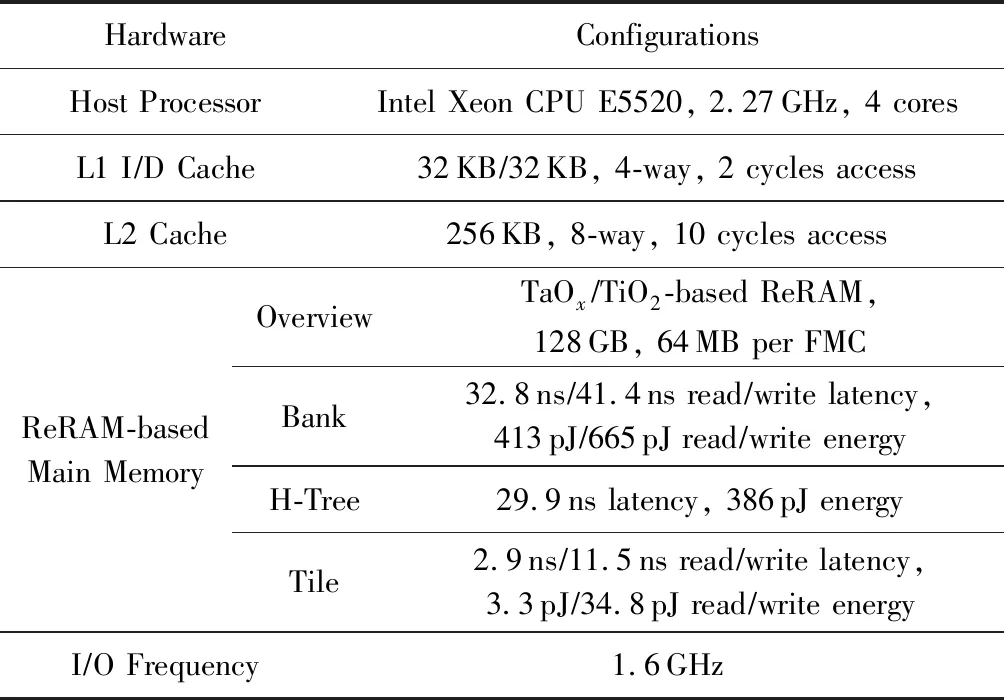
Table 3 Hardware Configurations表3 硬件配置
我们使用CACTI 6.5[25]对所有FMC中的连接进行建模;使用CACTI-IO[26]来对FMC之间的连接进行建模.关于ReRAM的参数配置,我们使用DESTINY[27]进行模拟获取.需要说明的是,我们的模拟系统中使用的基于忆阻器的主存包含2个chip;每个chip包含16个tile,通过H-tree方式连接;每个tile包含16个FMC.
如2.4节所述,FMC的资源池里各个资源的数目在不同的系统限制下会有不同的取值;同时,在同一个系统配置下,FMC的资源池的配置也可能会有多种可能.该实验部分测试了在表3的系统配置情况下的所有配置可能,并选取了FMC的资源池的资源利用率最高的一种配置来做性能和能耗的相关实验.
表4给出了FMC的单元配置参数,其中忆阻器阵列给出的参数是一层的配置,每个FMC有4层忆阻器阵列(考虑到传输线路长度和共享资源池的资源利用率).共享资源池中每个单元的占用面积直接使用ISAAC中的配置[2];每个单元的数目根据2.4节中的限制条件给出.
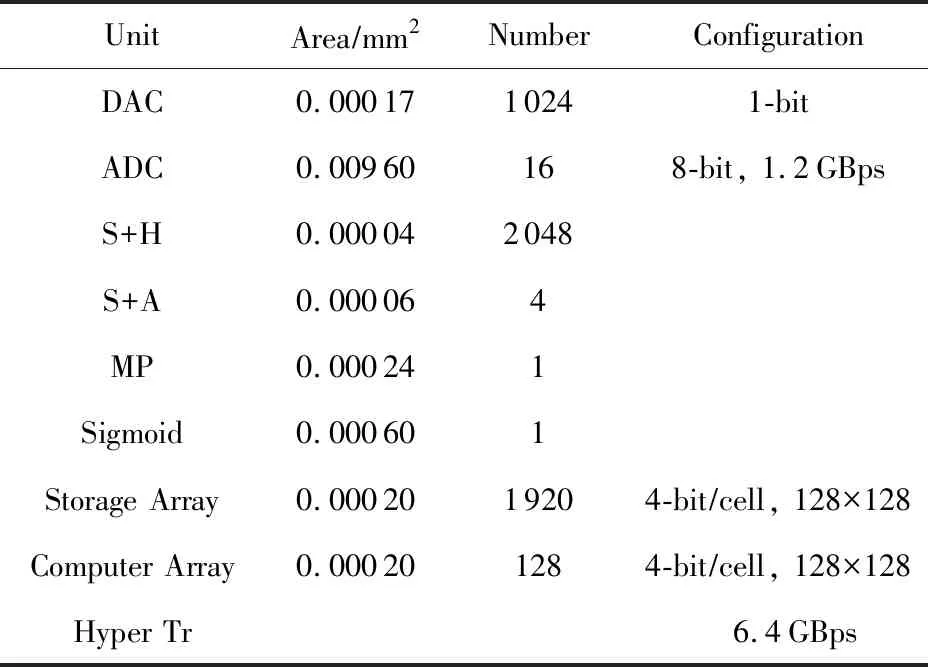
Table 4 Parameters of Units in FMC表4 FMC单元的实验配置参数
我们将配备如表4所示的FMC结构和2D的PIM进行实验比较,用PipeLayer[3]的结构.即一个PIM由多个PIM阵列组成,它们之间采用H-tree的连接方式进行连接,并且每个PIM阵列周围都配备有表4中的功能单元,这些功能单元之间互相不能共享,属于每个阵列私有.我们使用LeNet[28],ConvNet[29]和Caffe Model Zoo[30]中的6个流行的网络来作为实验的测试网络,包含: AlexNet,NiN,GoogLeNet,VGG_M,VGG_S和VGG_19.它们中既有大网络也有小网络,既有全连接层也有卷积层,数据集也涵盖了用来做图像分类的黑白MNIST手写数字集[31]和著名的用来做图像分类、目标定位和检测、场景分类的彩色图片集ImageNet[32].我们使用1,8,16,32,64和128六种batch_size来训练测试网络集,每个单独的网络分别执行1 000次训练迭代(用来测试单个任务时的架构性能),并将所有网络同时执行1 000次训练迭代(用来测试多个任务时的架构性能).
4.2 FMC的功能单元资源利用率
我们首先将2D的PIM的外围电路资源利用率和FMC的共享资源池中的功能单元利用率在训练单个神经网络的情况下进行比较,结果如图8所示.我们将训练8个测试网络时2D-PIM的外围电路资源利用率归一化成1,给出在每个测试网络下FMC的资源利用率与2D-PIM的倍数比较.图8中FMC-x的x表示训练时所用的batch_size,所有网络测试结果呈现按照名称首字母降序排序.
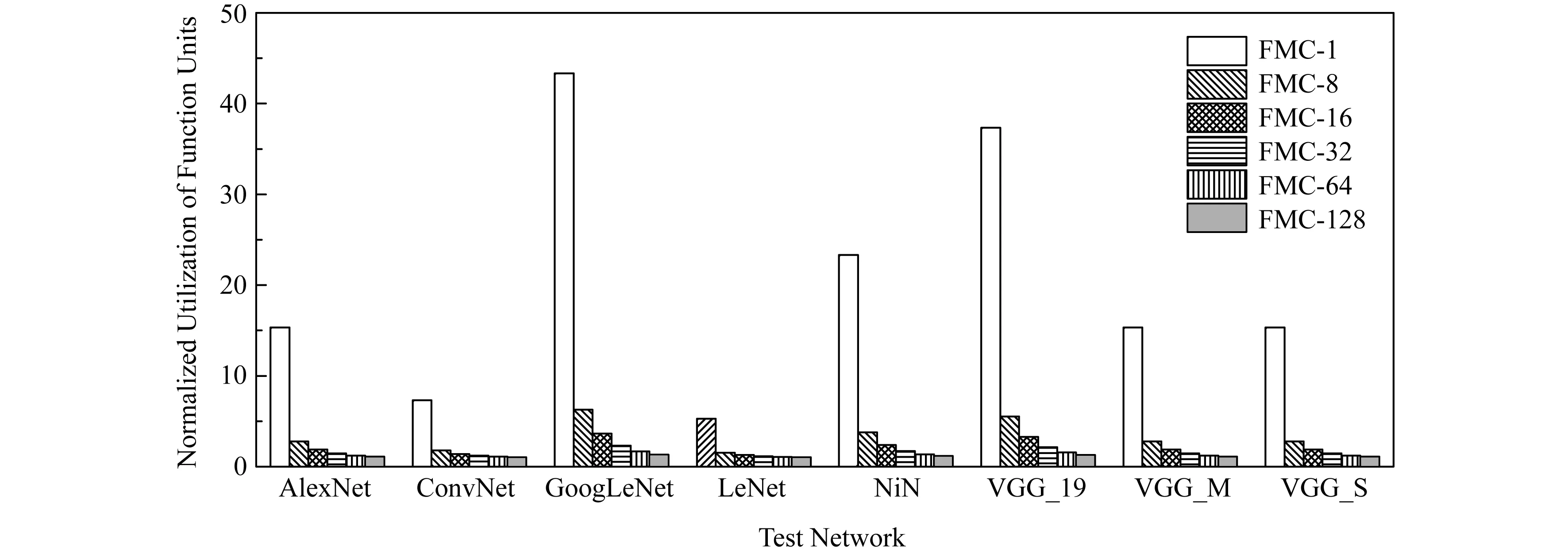
Fig. 8 Utilization of function units in FMC compared with 2D-PIM when training a single network图8 单个网络训练时FMC中功能单元的资源利用率和2D-PIM的比较
我们可以从图8中看到,FMC的资源利用率要比2D-PIM的高(所有的资源利用率的提升均在1倍以上),且在batch_size=1时有非常显著的利用率提升(如图8中FMC-1的柱形所示),最高能达到43.33倍(训练GoogLeNet时).另外FMC的资源利用率随batch_size增大而减小.这是因为当batch_size增大时,2D-PIM中整个传播过程可以很好地利用管道并行(pipeline)起来,从而提高功能单元的资源利用率.因此FMC在batch_size较大时,资源利用率的提升相比于2D-PIM不是很明显,但仍然有一定提升.例如用batch_size=128来训练GoogLeNet时,资源利用率有1.33倍的提升.这样的提升来源于pipeline时候的气泡部分以及前向传播和反向传播的中断部分.图8还显示出训练不同深度的网络时FMC资源利用率提升的差别:当训练深度大的网络(GoogLeNet,VGG_19)时,FMC的资源率提升相对大;当训练深度小的网络(LeNet,ConvNet)时,FMC的资源利用率提升较小.这是因为网络的深度越大,处理后面的网络层需要等待的时间就越长,进而导致处理后面网络层的2D-PIM的功能单元空闲时间过长,最终使得2D-PIM的资源利用率低,而FMC通过使前后层共享功能单元的方式提高了资源利用率,因此FMC的资源利用率相比较于2D-PIM的提升会随着网络层数的增大而更高,反之亦然.
图9展示了多个神经网络同时训练时在FMC中的资源利用率和在2D-PIM中的资源利用率的比较结果.其中,L代表LeNet,C代表ConvNet,G代表GoogLeNet,V19代表VGG_19,ALL代表所有8个测试网络的组合.
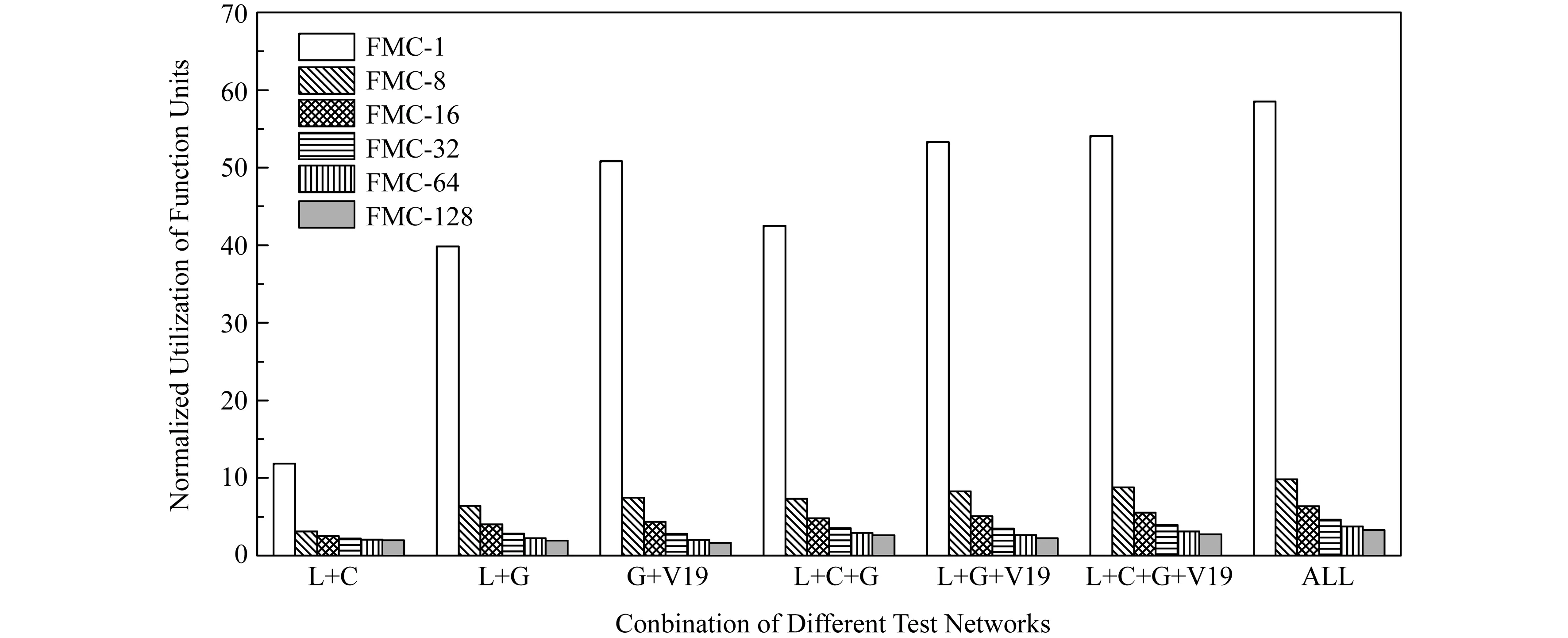
Fig. 9 Utilization of function units in FMC compared with 2D-PIM when training multiple networks图9 多个网络训练时FMC中功能单元的资源利用率和2D-PIM的比较
从图9中我们可以看出,当同时训练的网络越多且网络深度越大时,FMC相比较于2D-PIM的资源利用率提升更大.这是因为,当同时训练多个网络时,2D-PIM的资源利用率取决于最小网络训练时的资源利用率,而FMC因为能够使得多个网络共享功能单元,从而在训练网络任务多时,由于各个网络之间不存在依赖关系可以并行,因此它们可以通过pipeline的方式共享功能单元,从而提升FMC的资源利用率,进而使得FMC相比较于2D-PIM的资源利用率的提升更为明显.但是这样的提升速率并不会随着网络大小和网络深度的增长速率而增长,这是因为,当网络的大小和数目大到一定程度时,共享资源池的资源利用率趋近于100%(不能到达100%,因为训练起步时会有一定的气泡).
4.3 FMC空间占用
图10给出了FMC中的各个功能单元和一层忆阻器的面积占用的比较.其中,一层忆阻器的面积占用为总共面积占用的49.97%,也就意味着一层忆阻器的面积稍稍小于功能单元池的面积.在功能单元池中,DAC和ADC是占主要面积的分单元池,分别为21.24%和18.74%.
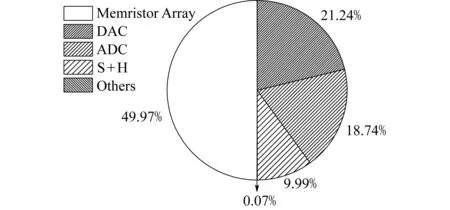
Fig. 10 Area breakdown of FMC(one layer of memristor) 图10 FMC中各个单元的空间占用比率(包含一层忆阻器阵列)
FMC中新加的开关和连接线占总空间的6.79%,而一个FMC所占空间仅是具有同等数目的Compute Array及Storage Array的2D-PIM所占空间的42.89%.
4.4 FMC+FDM性能和能耗
由于batch_size对FMC的性能和能耗与2D-PIM的比较几乎没有影响,因此我们选取batch_size=64(常用的batch_size)作为FMC的性能和能耗测试结果呈现,具体如图11和图12所示.
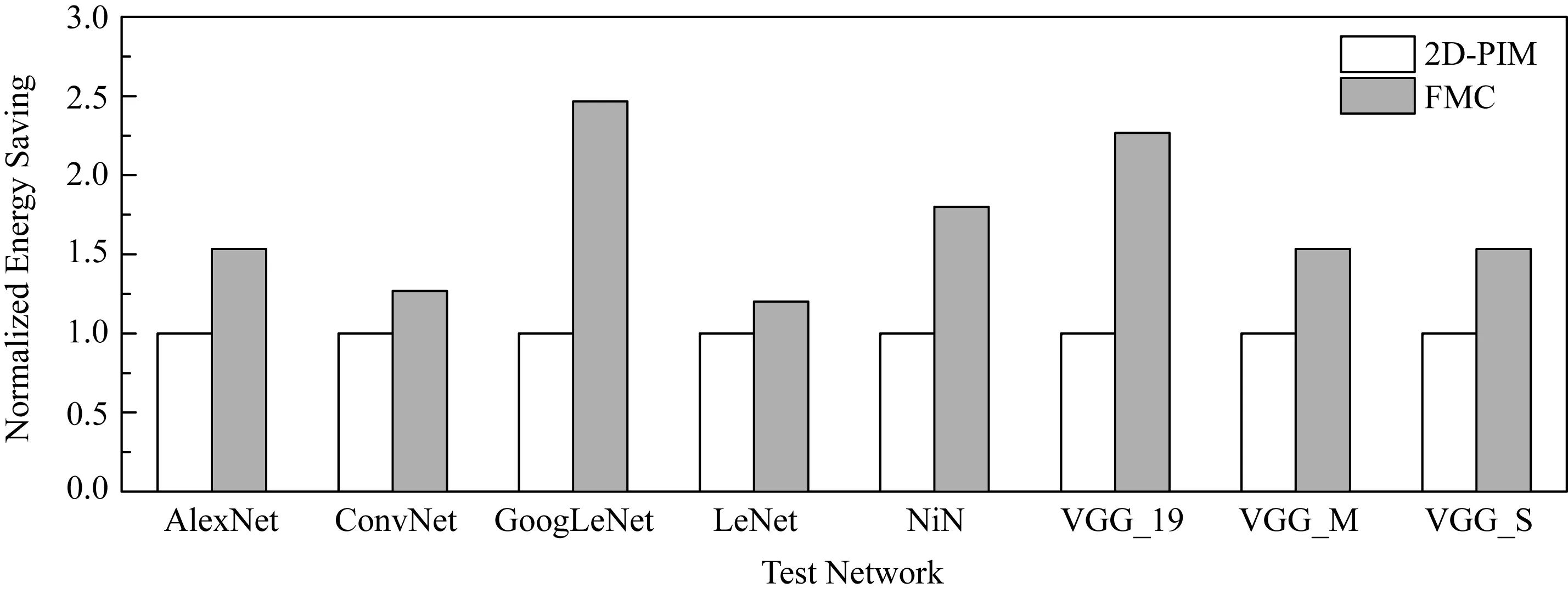
Fig. 11 Performance of FMC compared with 2D-PIM图11 FMC与2D-PIM的性能比较
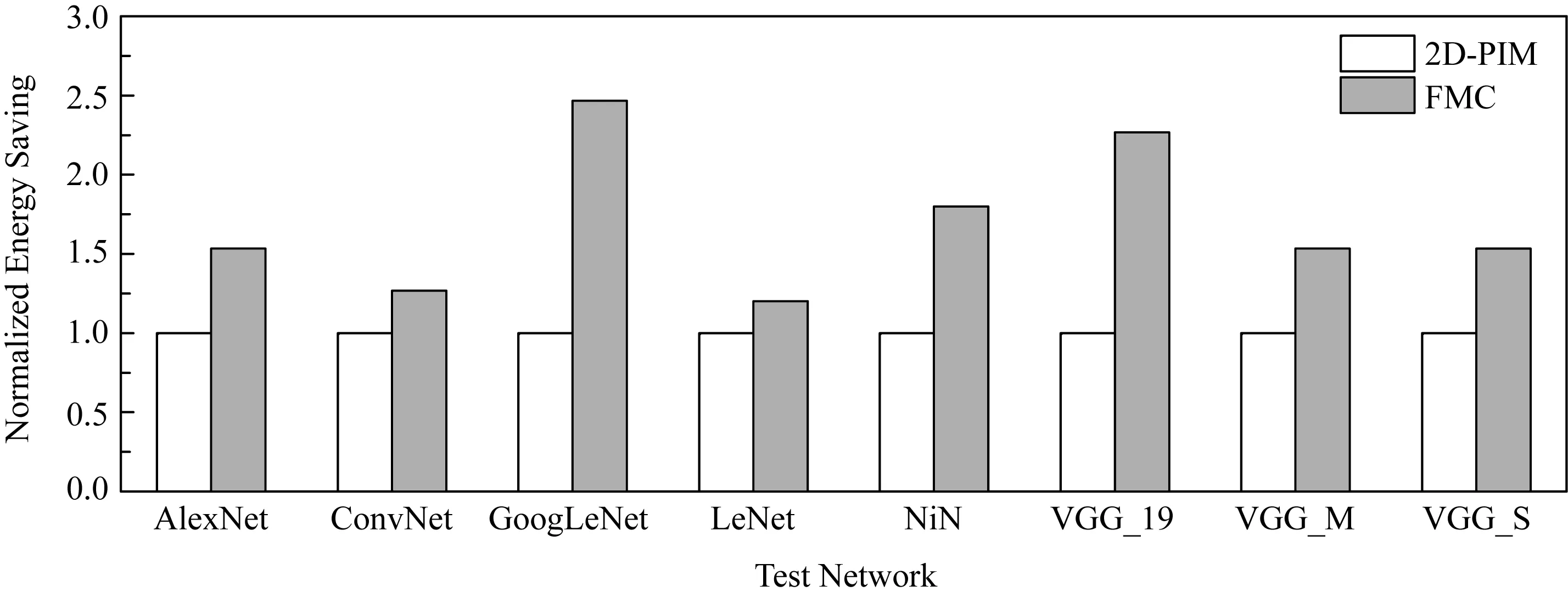
Fig. 12 Energy consumption of FMC compared with 2D-PIM图12 FMC与2D-PIM的能耗比较
从图11中我们可以看出,相比于2D-PIM,使用FMC训练越大的神经网络取得的性能加速要大.这是因为FMC各层忆阻器阵列之间是3D堆叠的,并通过3D堆叠的方式共享资源池.这使得忆阻器阵列之间的连接充分缩短,而网络越大需要的忆阻器阵列就越多,因此FMC相比于2D-PIM的优势就更为明显.而用FMC训练LeNet时几乎没有性能上的提升,这是因为LeNet很小,从而使得FMC的3D堆叠的连接方式相比较于2D-PIM的优势小,且数据传输的延迟被计算的延迟隐藏.总体来看,FMC相比于2D-PIM有1.5倍的性能提升.
图12展示了用FMC和2D-PIM训练单个神经网络时能耗比较.FMC在训练神经网络时能比2D-PIM有明显的能耗节省,也是因为FMC的3D堆叠的结构比2D-PIM的平面结构大大减少数据传输的线路长度.因此,所训练的神经网络越大,FMC相比于2D-PIM的能耗节省就更加明显.当训练GoogLeNet时,能耗节省能达到2.47倍.而当训练LeNet时,FMC也比2D-PIM有1.2倍的能耗节省.总的来看,FMC平均比2D-PIM节省1.7倍的能耗.
5 总 结
现如今,基于忆阻器的内存计算(PIM)如火如荼,但是它存在着除忆阻器阵列之外的电路单元面积过大且利用率低的问题.本文提出了一种基于3D忆阻器阵列的神经网络内存计算架构,将功能单元抽取出来形成一个资源池提供给忆阻器阵列共享,并通过3D堆叠的方式缩短各个忆阻器阵列的连接以及忆阻器阵列和功能单元池之间的连接.同时,我们还提出了一种基于3D忆阻器阵列的计算数据排布策略,配合上3D忆阻器阵列的结构,使得训练神经网络时的数据移动尽可能小.实验结果显示,我们提出的基于3D忆阻器阵列加共享资源池的架构能使功能单元的利用率在单个训练任务的情况下提升43.33倍,在多个任务的情况下最高提升58.51倍.同时,我们提出3D架构所占空间是有相同数目的Compute Array及Storage Array的2D-PIM所占空间的42.89%.此外,我们提出3D架构相比于2D-PIM有平均1.5倍的性能提升,且有平均1.7倍的能耗节约.
