面向阻变存储器的长短期记忆网络加速器的训练和软件仿真
2019-06-26韩建辉张悠慧郑纬民
刘 鹤 季 宇 韩建辉 张悠慧 郑纬民
1(清华大学计算机科学与技术系 北京 100084)2(清华大学微电子学研究所 北京 100084)
长短期记忆(long short-term memory, LSTM)神经网络擅长处理和预测时间序列中间隔和延迟很长的事件,因此多用于语音识别、机器翻译、控制机器人、合成音乐等领域.LSTM的推断计算大概占用了谷歌数据中心的30%的工作负载[1].然而,LSTM网络在传统的神经网络加速器上的计算效率却很低.举例来说,对于TPU[1]而言,相较于卷积神经网络(convolutional neural network, CNN)的86 Topss的速度,LSTM神经网络的速度只能达到2.8Topss.其主要原因在于LSTM的访存更为密集,因此其计算性能受到内存带宽的严格限制.对于GPU[2]和FPGA[3-4]等加速器件,也有类似的结论.
为了解决内存瓶颈对计算性能的影响,用ReRAM器件可作为神经网络加速器件的计算核心.非易失性阻变存储器(resistive random-access memory, ReRAM)是新一代的存储器件,其阻值可动态设置.利用此器件的物理特性,可以将ReRAM制作成交叉开关阵列(Crossbar)进行神经网络所需的矩阵向量乘法计算.其计算原理是基尔霍夫定律,计算速度快、功耗低,并且避免了一般神经网络加速器计算期间的权重数据移动,很大程度上削弱了内存带宽对计算效率的限制.
由于ReRAM Crossbar本身是模拟电路,相对于一般的数字电路设计有更多的约束条件,为此本文提出了定制化的训练算法,使得LSTM网络在训练时就充分考虑了相应的硬件约束,能够更好地反映推断计算的真实运行环境.同时本文还完成了一个针对ReRAM器件的System-C模拟器,采用行为级电路模拟技术避免了现有的基于SPICE的ReRAM电路仿真的复杂计算,可以大幅度提高模拟运行速度.相对于SPICE仿真,该模拟器引入的误差不超过2.68%[注]与真实芯片的电路设计作对比得出该结论.;且核心计算部分实现了GPU加速,大幅提高了模拟速度,为探索设计空间提供了便利.
1 背景与相关工作
1.1 ReRAM
ReRAM是新一代非易失性存储器件,其具有非易失性、高密度、低功耗、存算合一、易于3D堆叠等特点.在神经网络计算中可以利用其阻值可调的特点作为突触器件,并利用其存算合一的优点以Crossbar形式完成高速向量矩阵乘运算.
具体的计算方式为: ReRAM是一种多级(multi-level)内存设备,理论上可以将ReRAM的电导值设为其取值范围中的任意值.我们可以将ReRAM在Crossbar交叉点的阻值设置为神经网络权重矩阵的对应值,这样就可以用一个ReRAM Crossbar来表示一个神经网络的权重矩阵,并且根据其物理特性就地(in-situ)完成矩阵向量乘操作.对于理想的Crossbar器件,将输入电压Vi加到每一行字线(word-line),电压与每一交叉点的电导值Gij相乘,根据基尔霍夫定律I=GV,每一列的输出电流I可累加得到.该计算过程能达到很高的并行度和速度,过程如图1所示:
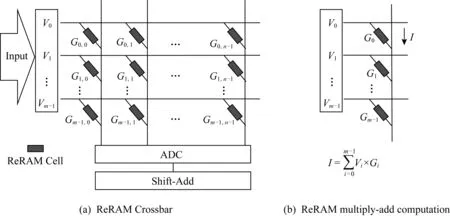
Fig. 1 ReRAM Crossbar图1 ReRAM 交叉开关阵列
但实际上基于ReRAM Crossbar的计算并不像上文提到的理想情况那样,主要包含2种非理想因素,分别是设备Variation和周期Variation.设备Variation主要反映在多个ReRAM单元之间的参数变动,即当我们设置多个ReRAM单元的电导值至某一个给定值时,其实际设置的结果值并不准确地等于预期值,而是服从预期值附近的一个数值分布.周期级的Variation则表示单个ReRAM单元的不同次操作之间的电导值并不完全一致.
具体地,在设置ReRAM电导值的过程中,一个单元的电导值的变化受极性、磁性和输入电压等的影响.同时一些非理想情况,如电导值突变和波动会在反复循环设置电导的过程中出现,因此需要写验证电路来验证所设置的电导值是否符合要求.通常的设置过程如下:将电压脉冲加到ReRAM单元上来增大(或减小)单元的电导值,直到该电导值大于(或小于)期望的电导值.如果实际电导值与期望的电导值相差过大,则需要进行相反的操作来减小(或增大)电导值.同时由于器件不完美特性和设置过程开销(用于验证电路的参考电压数量有限),实际可用的电导取值通常是离散值.这是当前很多基于ReRAM进行神经网络计算加速的研究工作使用离散电导值的一个原因.另一个原因在于,使用离散的权重值有利于提升神经网络的抗噪能力.
由于整个加速芯片系统的主要部分仍是数字电路,因此数模转换(模数转换),即DACADC,是很大的硬件开销.在配置DACADC的时候,需要综合考虑神经网络的准确率和硬件开销的均衡.
数模转换器(digital analog converter, DAC)的作用是将Crossbar每一行的数字输入向量转换成模拟信号.其重要参数是转换分辨率d,即每次可转换的信号位数.在电路模块中,DAC要占用不小的硬件面积,因此很多设计(如ISAAC[5]等)将S-bit宽度的数字输入信号先转换成一系列低精度的数字信号(通常精度是宽度为1,即d=1),再经过DAC;这也意味着Crossbar要进行(Sd)次的顺序操作,这是一种用时间换空间的优化策略.DAC的个数设为2r×C.
模数转换器(analog digital converter, ADC)的作用是将Crossbar的每一列电流输出转换成数字信号,其传感分辨率为a.为了减小硬件开销,通常使用时分复用的方式,即每个Crossbar列的输出依次进入到ADC中,ADC将其逐个转换成输出信号.每个Crossbar的ADC的数量是A.
1.2 LSTM神经网络
LSTM[6]网络是一种带门结构的循环神经网络(recurrent neural network, RNN),适合于处理和预测时间序列中间隔和延迟较长的重要事件.
LSTM网络引入了判断旧有信息是否有用的单元(cell).Cell的构成如图2所示:
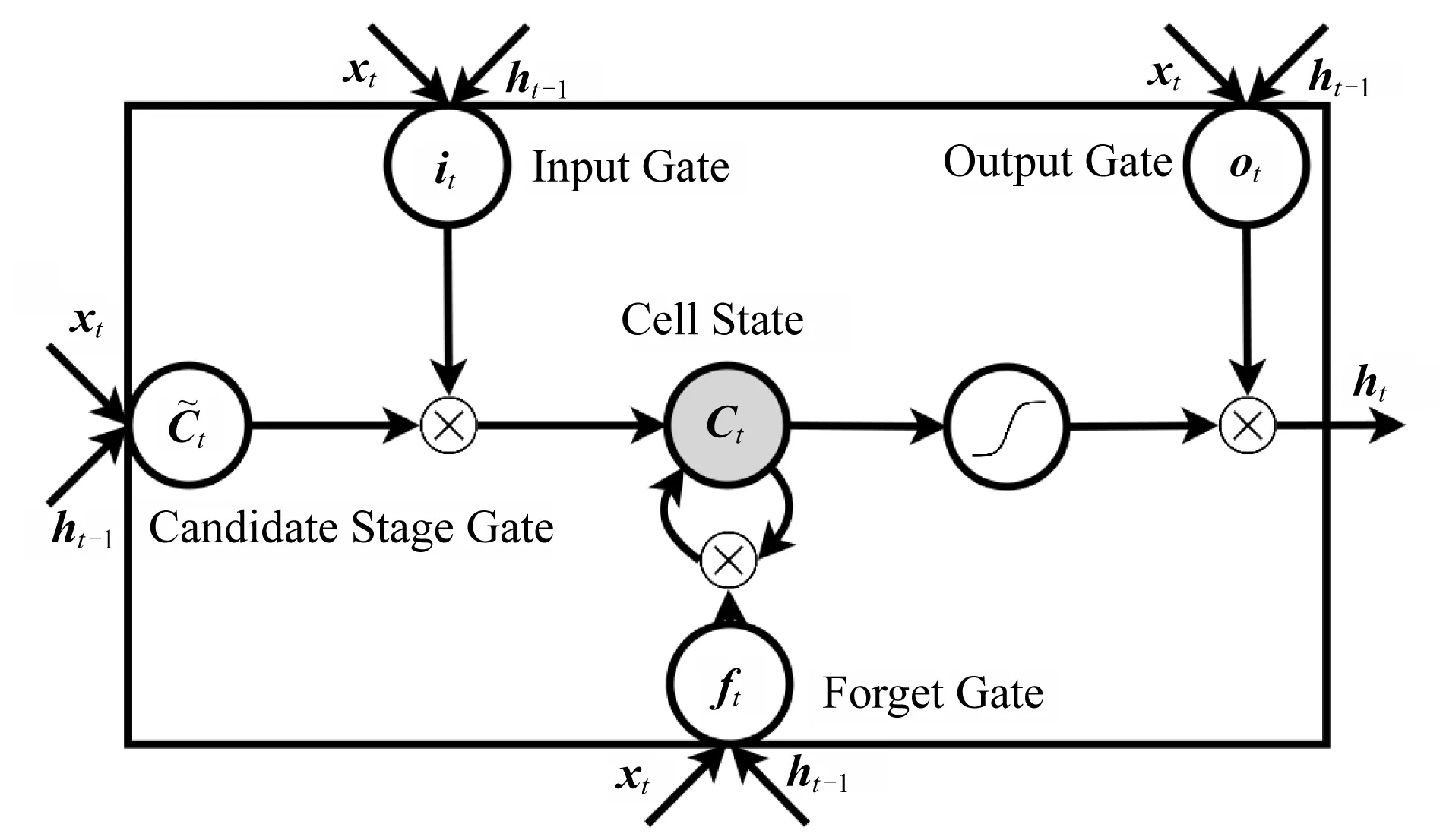
Fig. 2 LSTM Cell[7]图2 LSTM计算单元[7]
遗忘门(forget gate)控制当前输入xt对来自之前Cell状态删除信息的影响程度:
ft=σ(Wfor·xt+Rfor·ht-1+bfor).
(1)
输入门(input gate)控制当前输入xt对当前Cell状态中新信息的增量的影响程度:
it=σ(Win·xt+Rin·ht-1+bin).
(2)
输出门(output gate)控制当前输入xt对当前网络输出的直接影响:
ot=σ(Wout·xt+Rout·ht-1+bout).
(3)
候选阶段门(candidate stage gate)代表当前输入xt所创建的新的信息:
(4)
当前细胞状态(current cell state)是需要被遗忘和需要被吸收的内容的组合,其计算模式⊗表示逐点乘:
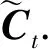
(5)
网络输出(network output)是输入xt与当前细胞状态的组合,其计算模式为逐点乘:
ht=ot⊗tanh(Ct).
(6)
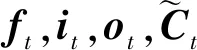
1.3 相关工作
在训练层面,文献[8]提出了一种通过补偿设备变动的方式来增强鲁棒性的训练方案.文献[9]使用二值网络训练来降低ReRAM表示能力的需求.在基于ReRAM的神经网络加速器设计方面也有一些相关工作.ISAAC[5]是一个使用Crossbar的CNN加速器,提出了流水线化的微体系结构和新的数据编码技术.PipeLayer[10]是一个面向CNN的基于ReRAM的内存计算(processing in memory, PIM)加速器,可以支持训练和推断计算.
在模拟器层面,尚未有研究提出一个开放的模拟框架.NVSim[11]对器件面积、时序、动态能量等非易失性存储技术进行建模,但不是针对神经网络加速计算.PIMSim[12]是一个内存计算的模拟器,用于传统的内存技术而不支持内存和计算的本地化.NeuroSim[13]是一个面向神经网络的基于非易失性存储阵列结构的集成模拟框架,但是其目标用户是希望利用自身的模拟突触设备快速评估系统级性能的设备工程师.该模拟架构结构简单(仅支持针对MNIST手写体识别数据集的2层MLP)并且缺乏相应的训练和映射软件.MNSIM[14]是一个针对基于ReRAM的神经形态系统的仿真平台,包括一个层次化的神经形态计算加速器结构和可以灵活定制的接口,以及一个行为级的计算准确度模型.但是MNSIM只实现了仿真功能而不支持实际神经网络应用的评估.因此,本文是第1个开源的针对LSTM的基于ReRAM的神经网络加速的训练和仿真平台.
2 针对ReRAM特性与加速器结构的LSTM神经网络训练
2.1 神经网络权重量化
神经网络权重量化(quantization)是神经网络的常用压缩算法.一般认为,神经网络参数过多、计算过于密集,因此需要通过压缩算法以降低神经网络的有效权重数量,这样既可以减少参数,又能简化计算;同时也能够降低数值表示精度,即用低精度计算来代替高精度浮点数计算,达到降低开销的目的.本文采用神经网络权重量化的出发点,主要是从ReRAM器件特性的角度来考虑.
正如1.1节介绍的,ReRAM器件的优势在于速度快、功耗低、并行性非常好,但是由于当前工艺不够成熟以及器件本身的不完美特性,其数值表示精度低(每个单元所能表示的权重的离散值范围与个数都有限)且受器件噪声的影响较大,因此需要在训练阶段对神经网络权重进行量化,使得神经网络能够符合实际器件的约束.其主要思想是将原有的权重进行放缩至器件精度范围如28,然后四舍五入为整数,并用该整数来表示权重值.
2.2 层间IO精度限制
在层间数据的传输时,数据的精度也常常受到硬件开销的限制.若该层间传输的精度限制为S-bit,权重精度为b-bit,输入的行数有2c行,则在Crossbar中计算时,其结果数据的数值范围为2S×2b×2c=2S+b+c,即输出的结果精度为(S+b+c)-bit,该结果需要被截取到层间数据传输的限制S-bit.截取策略一般有2种,最直接的方法是对输出结果等比例放缩到S-bit.这种方法的弊端是,当结果分布不均匀的时候会有较大的精度损失.另一种策略是截取结果中连续的S-bit作为最终结果,截取的起始位置则由数据分布来确定.
2.3 DAC与ADC及移位相加
在训练阶段还需要考虑ReRAM加速器所需的DAC和ADC以及移位相加(shift-add)对神经网络的影响.因此在训练的每次矩阵向量乘计算之前,需要将原有的输入值按位进行拆分,即将原有的1个8-bit输入向量拆分为8个1-bit输入向量,并将其合并成新的输入矩阵(训练阶段以此来加速训练过程),以此操作模拟DAC的转换过程.
在训练阶段的矩阵向量乘计算之后,首先需要统计该层所有输出结果的最大值,并根据此最大值确定ADC的参考电流(该参考电流值也将用于模拟器的ADC模块).在确定了该层ADC的参考电流之后,再将输出结果按照DAC的顺序,每8个行向量移位相加成1个行向量(即将扩展了8倍大小的输出矩阵还原成DAC拆分之前的同一层输出大小).
2.4 ReRAM噪声分布
ReRAM器件的噪声是指每个单元的噪声,其大小与单元的电导值(即神经网络权重)有关.每个单元的实际电导值为均值为单元目标电导值的正态分布,则每个单元的噪音为均值为0、标准差受电导值影响的正态分布:Gnoise=N(0,δ2).本文采用的ReRAM器件标准差δ符合(由实际测量值拟合得出[15]):
δ=-0.000 603 4x2+0.061 84x+0.724 0,
(7)
其中,x是ReRAM单元的电导值.在Crossbar计算的过程中,由于每次读取权重都会有偏差(ReRAM特性),因此在以上正态分布的约束下,每次计算都需要重新生成Gnoise值,并将其加在ReRAM单元的原有电导值上,作为新的读出值.
2.5 针对ReRAM特性的神经网络训练算法
在神经网络训练时,为了快速收敛,首先按照经典神经网络训练方法进行训练,得到高精度模型,在此基础上,使用本文提出的定制化的训练算法,训练得到符合ReRAM约束的神经网络模型.综合上文提到的ReRAM特性,本文提出的神经网络训练算法如下:
1) 前向过程(forward pass)
步骤1. 神经网络权重8-bit量化.针对各神经网络层,分别选取各层的最大值max(W);保存现有权重为Wold;计算Wnew:
Wnew=round(Woldmax(W)×
(27-1))(27-1)×max(W).
(8)
步骤3. DAC转换.将步骤2中获得的inputnew进行按位拆分,生成新的1-bit向量.工作流程如图3所示.
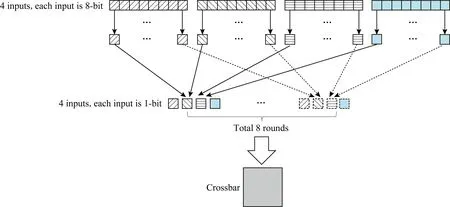
Fig. 3 DAC Workflow图3 DAC工作流程图
步骤4. 计算并添加噪音.首先生成标准正态分布噪音normal,进一步根据式(7)得到标准差为δ的Vnoise;将Vnoise加到现有Wnew上,得到带噪音的权重值Wnoise.将DAC生成的1-bit向量与Wnoise相乘,得到输出output.
步骤5. ADC与shift-add.首先确定各层参考电压AD_V,其值为每层output的最大值,即AD_V=max(output) .将每个output值转换成8-bit向量:outputt=round(outputAD_V×(27-1)).按照DAC拆分的顺序,每8个outputti进行移位相加:为最终输出结果向量.
2) 反向过程(backward pass)
步骤1. 将现有网络权重值Wnoise恢复为Wold.
步骤2. 使用反向传播算法(backpropagation)更新权重值.
以上为本文提出的针对ReRAM特性的神经网络训练算法.利用此算法可以训练得到符合ReRAM约束的神经网络模型.
3 模拟器架构
3.1 整体架构
模拟器的主要计算模块为LSTM模块和Linear模块,分别负责LSTM网络和全连接网络的计算.除了计算模块,还有数据输入和输出模块,以及相应的数据缓冲区模块(LSTM模块的缓冲区与全连接模块的缓冲区结构相似,仅有规模参数不同,因此视为同类模块).如图4所示,Linear模块中包括DAC、若干ReRAM计算阵列、ADC和shift-add以及激活函数,其输出值将发送给下一层数据缓冲区(或者作为模拟器的输出结果).LSTM模块的特殊性在于,其激活函数为非线性函数Sigmoid和tanh(而非Linear和CNN中常用的ReLU),并且需要引入新的控制和计算功能——向量拼接和逐点乘.
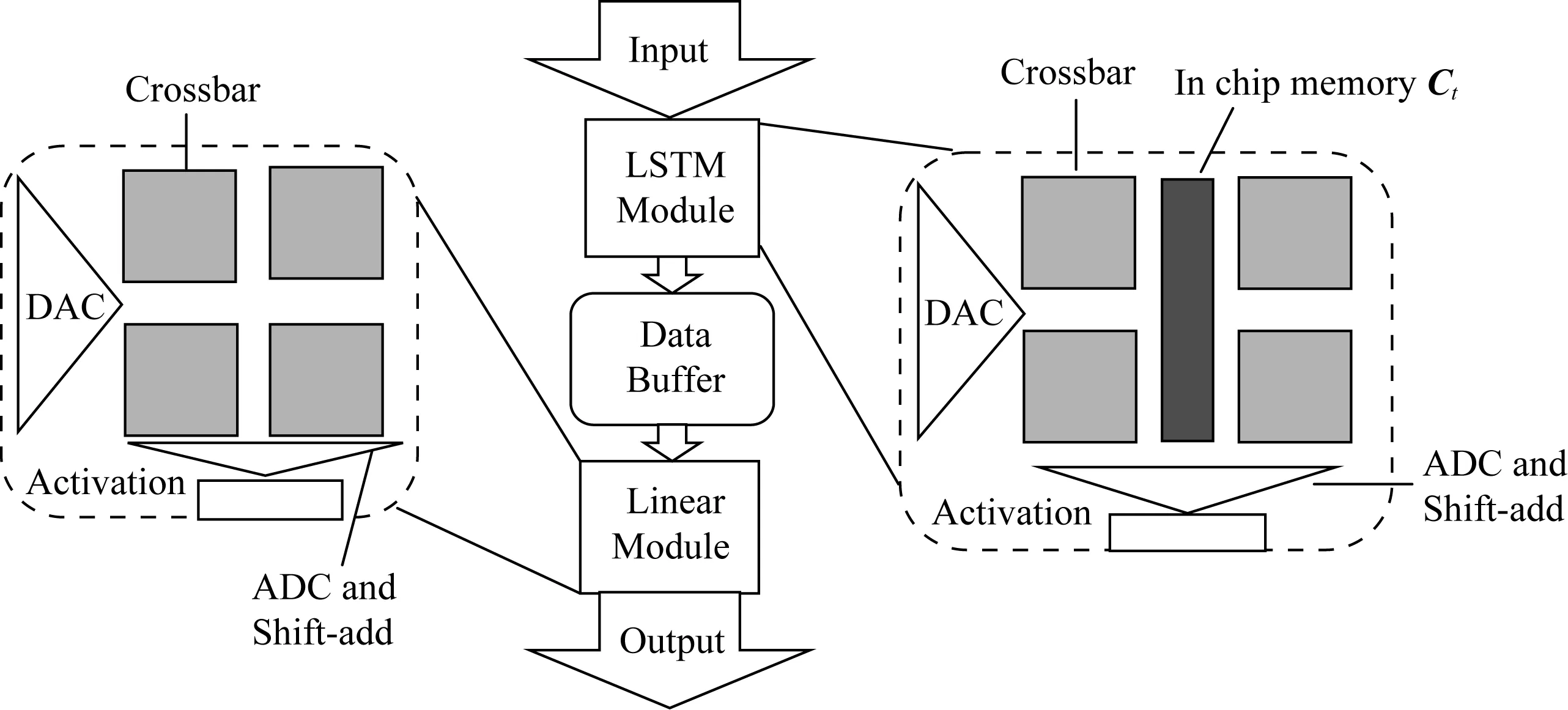
Fig. 4 Overall architecture图4 整体架构
3.2 处理单元
1) DAC模块
DAC模块的主要作用是将输入数据(8-bit)逐位转换成1-bit数据,即将一个8-bit向量转换成8个1-bit向量,依次输送给Crossbar模块进行计算.如图4所示,对于4个8-bit(层间IO限制)输入数据,对其bit位进行拆分,每个8-bit输入数据按照从高位到低位拆分成8个1-bit数据;再按照高低位次序,分8次输入到ReRAM Crossbar中进行计算,因此Crossbar中的计算需要8个时间步完成.
2) Crossbar模块
如图1所示,将一列输入电压与ReRAM单元的电导值(权重值)相乘加得到输出电流.在此过程中,同时需考虑2.4节提到的ReRAM单元的噪音,即对每一个ReRAM单元,其计算电流值为Iij=Vi×(Gij+noiseij).Crossbar中的权重值经预先训练和转换得到,在模拟器运行启动时读入.Crossbar模块的大小预先设置为1 152×128,其参数也是可调的.
3) ADC与shift-add模块
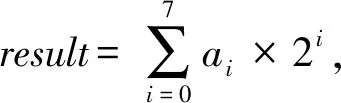
4) LSTM模块
在LSTM模块中,集成了从上层获取数据、DAC转换、Crossbar的计算、ADC转换这4部分.除此之外,由于LSTM网络计算的特殊性,还需要引入逐点乘操作和非线性(激活)函数.另外还需要在模拟器中开辟专门的存储空间来存放本模块循环输入给下一个时间步的结果Ct.
经过激活函数的计算后得出的结果ht作为下一时刻本层的输入,Ct作为当前细胞状态值用于计算下一时刻的细胞状态,因此需要在本层中存入相应的数据缓冲区,待下一时刻本层计算Ct+1时使用.
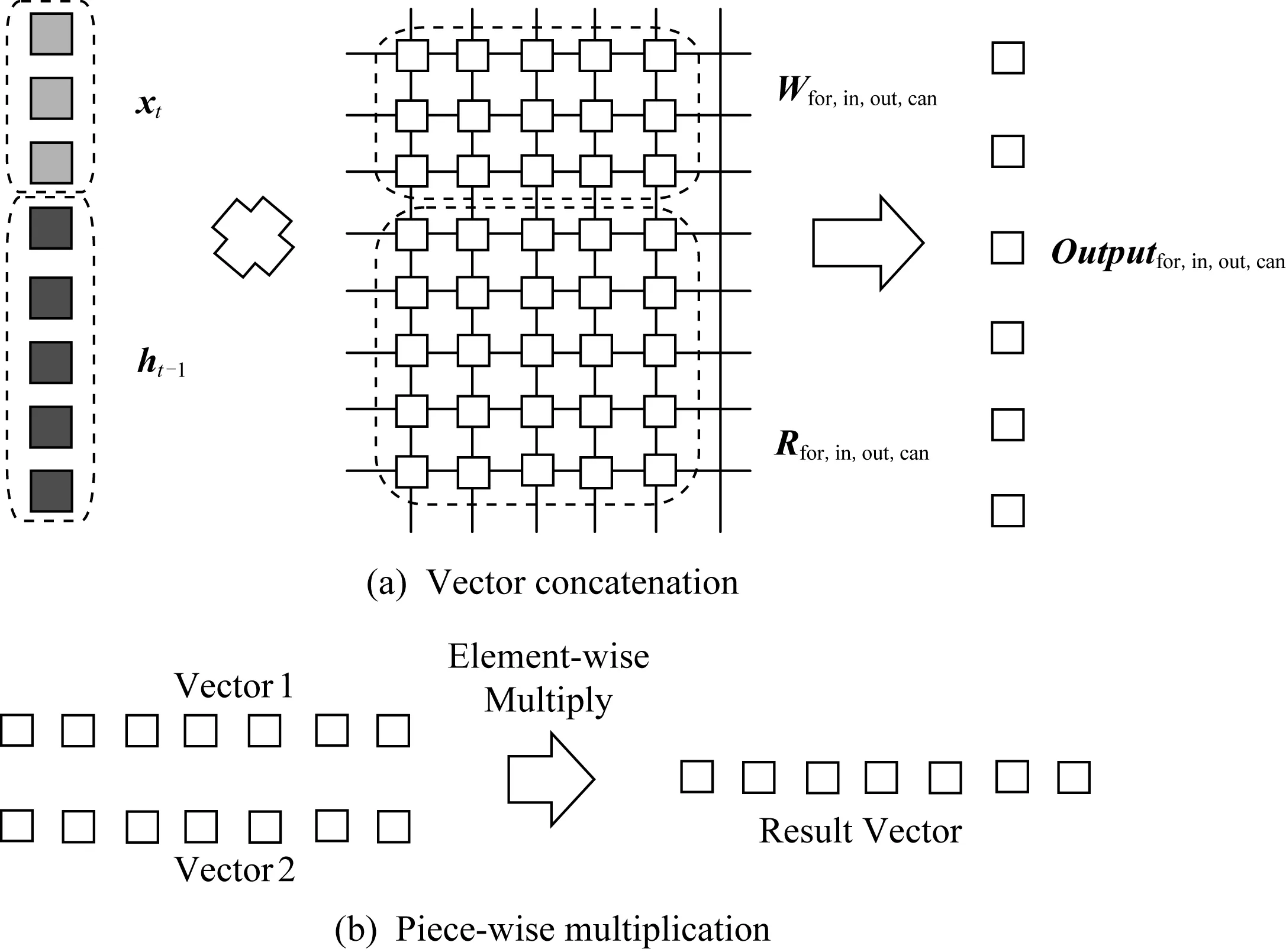
Fig. 5 Computation Mode in LSTM module图5 LSTM模块的计算模式
3.3 GPU加速计算
模拟器的主要计算部分为矩阵向量乘,同时还要在每次进行Crossbar计算时生成满足高斯分布的噪音(需要生成随机数),所以使用CPU进行计算时其时间开销很大.而GPU作为SIMD硬件,其计算并行性很高,适合做矩阵相乘的操作,目前也多用于神经网络计算,具有良好的加速效果.因此我们考虑使用GPU来加速模拟器,即将Crossbar的主要计算部分由GPU来完成,包括ReRAM单元噪音的生成.在GPU计算时,通过编写cuda代码,调用用于生成随机数的curand库生成符合条件的高斯分布噪声,并将其加到对应的ReRAM单元的电导值上.加速算法的步骤如下:
步骤1. 初始化权重W.将所有层Crossbar的权重加载到GPU内存中,并根据权重值计算该层权重对应的噪音标准差δ.
步骤2. 在System-C模拟器中,将每层输入拼接成1个大输入向量input,将input发送给GPU.
步骤3. 调用curand库,生成标准差为δ的噪音Vnoise,并将该Vnoise与W相加,得到Wnoise.GPU调用cublas库进行input和Wnoise的矩阵乘计算,得到输出向量output.
步骤4. 将输出向量output进行转置(GPU中显存的存储方式为列优先,而CPU内存中的存储方式为行有限).将结果拷贝回CPU内存.
在具体实现上,使用CMake进行编译,其中System-C相关代码需要调用System-C 2.3.2库,而Crossbar计算部分则单独拆分出来,使用NVCC进行编译.在程序链接时,将2部分代码生成一个可执行文件.
本项目所用的GPU为NVIDIA Tesla P100,其显存大小为12 GB.加速效果如表1所示:
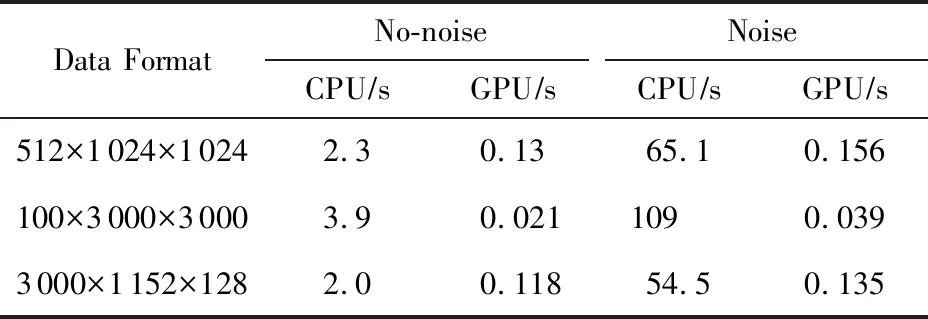
Table 1 GPU Acceleration Result表1 使用GPU计算的加速效果
由表1所示,“数据规格”为所设置的Crossbar大小,其中第1维表示Crossbar个数,后两维表示单个Crossbar的长和宽.在表1中,第1,2行分别列出了中等矩阵规模(1 024×1 024)和较大矩阵规模(3 000×3 000)的加速数据.由于当前ReRAM工艺所限,其Crossbar阵列规模亦有限,因此在最后一行给出了Crossbar尺寸为1 152×128的计算加速数据.表1中的第2列和第3列首先使用无噪音的随机生成数据作为权重验证计算准确性,可以看出,在无噪音情况下,当阵列规模较小的时候(第1行和第3行)使用GPU进行计算可以达到16~17×左右的加速比,在阵列规模较大的时候(第2行)更是能够发挥GPU的并行优势,达到185×的加速比.之后再用有噪音的随机生成数据评估性能,在使用GPU进行加速计算的情况下,当阵列规模较小时(第1行和第3行)加速比可达到400×左右,而当阵列规模较大时(第2行)其加速比更可达2 794×.由以上数据可以看出加速效果十分显著.
4 案例研究与结果评估
作为案例研究,我们实现了如第3节架构的一个模拟器,并据此评估我们的训练算法.
4.1 模拟器的实现
我们实现了一个ReRAM Crossbar仿真框架,并给出了基于Pytorch的定制化训练算法,包含第3节中提到的诸多模拟电路特性;模拟器仿真部分基于System-C实现,ReRAM设备模型来自文献[15],默认的IO和权重精度均为8-bit(可以配置).
在具体的仿真实现上有诸多参数可以设置,包括电路参数和神经网络参数,如表2和表3所示:

Table 2 Circuit Parameters for Simulator表2 模拟器所需电路参数

Table 3 Neural Network Parameters for Simulator表3 模拟器所需神经网络参数
基于表2和表3所列参数,针对所需的仿真模型,通过提前设置LSTM模块数、Linear模块数、数据缓冲区模块数,并通过System-C中的信号将相关模块串联,即可生成特定的模拟器,且该流程可通过代码脚本自动生成.
对ReRAM神经网络加速器而言,面积和功耗是重要指标之一,因此本项目模拟器对此进行了32 nm尺寸下的参考设计,具体参数如表4所示.
其中,缓冲区(buffer)相关的模型参数来自CACTI[16],Crossbar面积参数来源于文献[17],其他参数采用了ISAAC[5]的参数.

Table 4 Hardware Parameters for Simulator表4 模拟器所需硬件参数
4.2 仿真结果的评估
4.2.1 仿真算法评估
我们实现的LSTM网络为应用在一个在TIMIT数据集上进行语音识别的网络.该数据集的训练集、验证集和测试集大小分别为3 696,400和192.其中每条测试集语音帧数为619,因此总计有118 848帧测试数据.其神经网络输入维度为39(经过MFCC预处理后的语音数据,即每一帧的向量长度),输出维度为61(语素分类数),包含一个LSTM层(隐层大小128)和一个全连接层.表5为仿真算法评估结果.
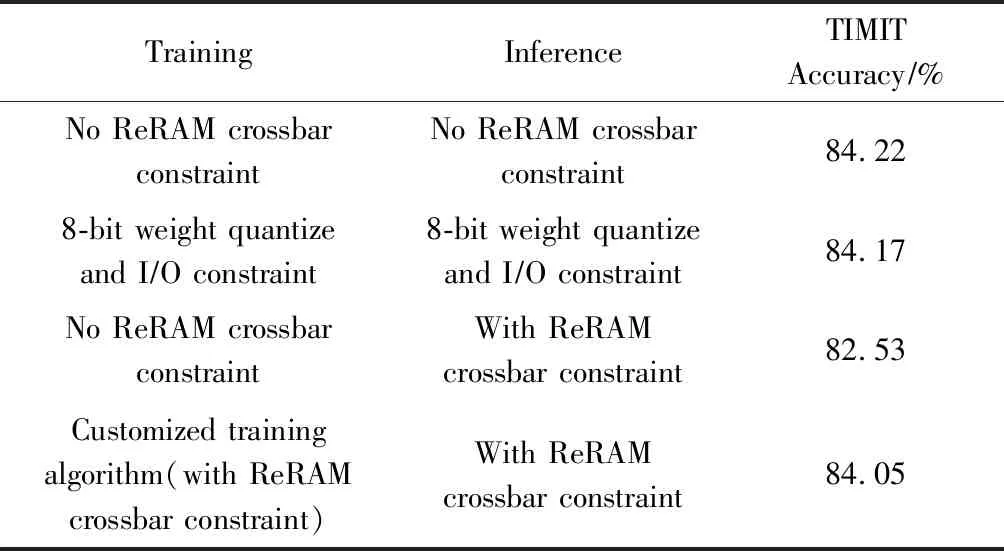
Table 5 Evaluation Result for Training Algorithm表5 训练算法评估结果
我们使用通用的神经网络训练算法作为基准,经过30个周期的训练,其分类准确度可以达到84.22%,此网络模型称为基准模型.在此基础上,我们在训练中引入了神经网络8-bit的权重量化和IO限制,结果显示其准确度为84.17%,即有轻微的下降.接下来将基准模型直接部署模拟器上(后者在模拟过程中引入了所有的限制因素,包括权重量化、IO限制、ReRAM的非理想因素等),结果显示由于权重量化、器件噪音以及DAAD等的影响,识别准确度下降为82.53%.最后我们将基准模型在ReRAM约束下进行微调(fine-tune),引入了所有限制因素,在网络收敛后,可以得到其识别准确度84.05%,这个数据与将该网络部署到模拟器上获得的精度一样.
表5表明:传统的训练算法在应用到ReRAM的推断过程中,权重的量化和IO精度限制对神经网络的表达结果影响很小,但是由于器件噪音以及DAAD等的约束,会导致性能下降.而我们的定制化训练算法将以上因素考虑到训练过程中,再将训练好的模型应用到ReRAM Crossbar的计算之上,可以有效减小器件因素带来的性能下降.
4.2.2 模拟器的仿真准确度评估
在模拟器本身的准确性方面,我们做了基于SPICE模拟的评估.这是因为模拟器本身需要能够满足实际器件的物理特性和约束.现有的基于SPICE的ReRAM模拟工作,其电路方程非常复杂(对于一个2r×2c的Crossbar,需要求解2r×2c+2r×(2c-1)个电压参数和3×2r×2c个电流参数,且方程是非线性的),因此求解难度很高,模拟仿真速度慢.
本项目模拟器在计算速度和仿真准确性上做了权衡:1)Crossbar的输入电压为1-bit的值(只有高低电压之分),以此来消除非线性的影响;2)考虑到Crossbar阵列中连线上的电容和电感对于计算影响很小[18],因此将其忽略;3)每当读取电导值时,都要引入ReRAM variation[19].
在此基础上,我们将结果与实际芯片的电路级仿真进行了比较.在阵列大小为1 152×128规模下,ReRAM单元高阻和低阻分别为800 KΩ和50 KΩ,导线电阻(bit-line,source-line,work-line)分别为87 mΩ,100 mΩ,1.16 Ω(130 nm工艺下的CMOS电路).在此条件下,我们得到的行为级模型计算的结果电流值与电路仿真的结果电流值其误差不超过2.68%.
5 结束语
本文提出了基于ReRAM的长短期记忆网络加速器训练和仿真框架,包括针对ReRAM器件特性的定制训练算法、时钟驱动的行为级模拟器及其GPU加速.验证结果显示训练算法能够有效降低模拟器件带来的噪音和数值精度损失等不利因素的影响,而该模拟器与SPICE仿真的计算结果误差在2.68%以内,并且避免了SPICE对电路仿真耗时过长的缺点.与现有的工作相比,本文提出的模拟器项目完成了端到端的训练和仿真,并将一个实际应用于TIMIT数据集语音分类的LSTM网络部署并运行.未来我们会继续完善该模拟器,增强各模块的可配置性,为相关的加速器硬件设计提供探索方案.
致谢感谢北京市未来芯片技术高精尖创新中心的支持!
