一种基于知识粒度的关键词提取方法
2019-04-19杨淑棉刘剑
杨淑棉,刘剑
(1. 齐鲁工业大学(山东省科学院),山东省计算中心(国家超级计算济南中心),山东省计算机网络重点实验室,山东 济南 250014; 2. 济南高新区齐鲁软件园发展中心,山东 济南 250101)
互联网的出现使得网上的信息呈爆炸式增长,人们越来越难以查找到有用的信息,网上日益丰富的信息资源靠人工处理和分类更是不太可能,因此如何方便、快捷、准确地获取所需信息,对各类文本自动处理并进行自动分类成为一个迫切需要解决的问题。关键词是从报告、论文中选取出来用以表示全文主题的词语,高度概括了文本的主要内容与主题,使不同的读者很容易判断文本是否是自己需要的内容。关键词自动提取技术是文本分类中的一个重点,国内外专家对其做了大量的研究,并在提高获取准确率方面提出了很多的方法,但是关键词的获取准确率和效率仍然不高,仍存在许多需要解决的问题。目前,最经典的关键词提取算法是利用词的统计信息,主要判断词的权重,并设定阈值,选出权重较大的、超过一定阈值的词作为最终的关键词。现有中文分词和词频统计相结合的方法、词库匹配法、基于N-gram频率统计的方法需要依赖于语料库的规模和数量以及词典和专门的分词技术[1]等,汉语词汇量的编制和维护也是一件很烦琐的事情,并且使用训练语料库导致工作量迅猛增加,代价相对高昂,因而局限性大[2]。
信息粒是对现实的抽象,由一系列元素组成,元素之间满足某种程度上的相似性和不可分辨关系。本文从信息粒分类的角度对知识进行研究,目前关于粒度计算已出现在很多领域,如粗集理论、区间分析、机器学习聚类分析等。国内外学者已提出了粒度计算的一些重要模型,这些模型表明粒度计算与粗糙集理论有密切的联系。罗燕等[3]提出了基于词频统计的文本关键词提取方法;廖洪建[4]提出一种基于知识粒度的决策系统属性约简算法;陈玉明等[5]提出基于相对知识粒度的决策表约简;景运革等[6]提出基于知识粒度的增量约简算法; Yao[7]提出利用信息粒度,给出了粗糙集逼近。从现有的成果看,知识粒度已经被广泛应用于不完备属性约简领域,是粗糙集理论中有效进行属性约简的一个重要方法。但是现有的方法由于计算知识粒度浪费了大量的时间,算法效率有待于提高。本文用粗糙集中的等价关系来刻划粒,通过计算知识粒的属性重要度作为一种启发式信息,使用Tabu局部搜索算法,提出一种关键词获取方法,此方法大大降低了算法的时间复杂度,提高了算法的效率,而且克服了张雪英[8]提出的基于GF/GL权重法的局限。
1 信息粒度的相关概念
1.1 知识粒概念
知识粒的定义:设S=(U,R)是一个信息系统,其中U是对象的非空有限集,称为论域,R是属性的有限集,U/IND(R)={[x]R|x∈U}表示不可分辨关系IND(R)在U上导出的划分,也称为R的划分或信息粒度,其中[x]R={y∈U|(x,y)∈IND(R)}记为R的等价类或R知识粒。

定理1[9]:设S=(U,R)是一个信息系统,P⊆R,若U/IND(R)
定理2:设S=(U,R)是一个信息系统,P⊆R,则U/IND(R)=U/IND(P)的充要条件是gk(R)=gk(P)。
约束1:关键词长度是不确定的,存在一定范围限制。为尽可能减少系统的计算时间,中英文粒度的最大抽取长度分别是15和5。英文的每个单词都被看作是一个汉字[4]。
1.2 知识粒重要度的计算(kgImp)
利用知识粒度,可以分析信息系统中每一个属性的重要性,主要方法:信息系统S=(U,R)中,设r∈R是一属性,用从R中去掉r后引起的知识粒度变化的大小来衡量r对于R的重要度,变化越大,认为r对于R越重要。这里主要计算粒的重要度来衡量词在文献中的重要程度,重要度用Imp来表示,知识粒度用gk来表示。
知识粒重要度计算:设S=(U,R)是一个信息系统,属性r在R中的重要度表示为ImpR-r(r)=gk(R-{r})-gk(R),特别地,当R={r}时,ImpR-r(r)=Imp∅(r)=gk(∅)-gk(r)=1-gk(r),其中U/IND(∅)={U},gk(∅)=1。由以上公式可以知道:U/IND(∅)={U}
性质1:属性r∈R在R中是必要的等价条件是当且仅当ImpR-r(r)>0。
性质2:0≪ImpR-r(r)≪1-1/U。
属性重要度值:设S=(U,R)是一个信息系统,P⊆R是属性集,任意属性a∈R-P对于R的重要度为ImpR(a)=Impp∪a-{a}(a)=gk(p)-gk(p∪{a}),由定义知:
性质3:属性a∈R在R中的必要条件必满足ImpR(a)>0。
基于以上知识粒度的概念和知识粒的重要性,本文提出了一种新的关键词的获取方法。
2 文本预处理方法
大规模文本分类和文本信息检索之前最基本前提是收集数据,收集数据的方法一般是使用别人做好的语料库和自己用爬虫爬取需要的语料数据,本实验使用现有的语料库。另一个环节是文本的预处理,目标是将文本转变成结构化的数据形式,一般使用向量空间模型、语义网络、框架模型等来表示文本。本文采用一种基于粒度重要性的文本表示方法,使用决策信息表和粒表示文本,首先我们需要对文本进行预处理,主要包括:
(1)建立停用词表,包括缺乏检索意义的词、频繁出现在文本中但分词不正确、语义不明确的词等。(2)文本预处理:对文本进行扫描,把标点、数字、非汉字字符、助词、连词、感叹词等都用空格替代;把缺乏检索意义的词比如就是、很、非常等用空格替代;把语义不明确的词用空格替代。(3)用二元语法(2-gram)抽取任意长度的词,按照李秀红等[10]的方法提取所有满足限制条件的字符串。(4)词的表示:使用信息决策表知识表达系统表示以上生成的任意长度的字符串。(5)根据知识粒定义的概念、原理和所提供的性质,计算每一个属性的重要度值,根据重要度值的大小,获取文献的关键词。流程如图1所示。

图1 文本关键词获取方法流程Fig.1 Keyword acquisition process of text documents
3 关键词提取算法
3.1 算法思想
知识粒度度量了知识的粗细程度,利用知识粒度的概念、原理、性质,当一些属性增加到决策表后,可以使原有的决策表的知识粒度发生变化,我们利用了决策表中任一属性的增加对知识粒变化的大小来衡量属性的重要程度,可计算出信息系统中每一个属性的重要度值,并以重要度值的大小确定此属性对文本的重要程度,用此种思路来提取文本中的关键词。首先,根据知识粒的定义,计算决策系统中所有属性核的大小Core,然后增加任一属性之后对属性内核影响程度,计算出属性重要度值,由知识重要度(KgImp)的计算公式ImpR-r(r)=gk(R-{r})-gk(R),根据性质1、性质2和性质3,可以从信息决策系统中提取文本文献中的关键词,增加属性后,对于核的重要度值变化越大,说明属性a对于内核Core(R)越重要,最后根据求出的重要度值的大小,进行排序,取重要度值大的作为要提取的关键词。
3.2 算法描述
依据上述知识粒度、原理及性质,基于知识粒度重要性的关键词提取算法具体描述如下:
输入:信息系统S=(U,P),其中,P是文本文献预处理之后得到的词条。
输出:文献所提取的最小的属性约简。
步骤1:输入预处理之后的所有词条P,建立信息决策系统列表Gklist。
步骤2:计算列表Gklist属性的核Core(P),/*组成核的所有属性记为P*/。
步骤3: 判断属性核Core(P)是否为空。
如果Core(P)为空,转步骤6
否则,转步骤4 /*核为空说明这组文献是特殊文献,如新闻稿,需要单独处理论域中的每一个对象,根据权重提取关键词*/。
步骤4:计算列表Gklist中任一a∈R-P,此步使用基于Tabu算法,搜索空间的a,计算这一属性对核core(P)的重要度值ImpP(a),重要度值大于0的词组成关键词集合
步骤5:根据步骤4计算出来的ImpP(a)的值给所有大于0的词条排序,取重要度值大的作为要提取的关键词。
1)做好顶层设计,助推实验室管理制度体系化。设立由单位领导及各相关部门负责人组成的实验室安全管理委员会,按专业类别下设实验室安全专家咨询组,例如:化学、生物、辐射、环境保护、特种设备、职业健康等安全专家咨询组;为委员会评价和审核各项管理制度、安全手册、规范及细则等提供专业性意见或建议,促进实验室管理制度体系化发展。
步骤6:根据统计方法,从单篇文献中提取关键词,首要考虑关键词的词性、位置、词频、词跨度等因素计算词条的权重,选取权重大的为提取的关键词。
由算法可知,先增减哪个字符串计算的属性重要度值是不一样的,因此下一步的问题是解决怎样克服增减字符串顺序引起的重要度值不同的问题。
4 实验验证
给定一个信息决策系统[11]IS=(U,A,V,f),其中U={X1,X2,X3,X4,X5,X6},A={a,b,c,d}如表1所示。

表1 信息系统
4.1 计算属性的知识粒度和属性重要度
由于论域U中任何一个对象都是不同的,对象在论域U上划分是最细的,则有R的知识粒度达到最小值,即:
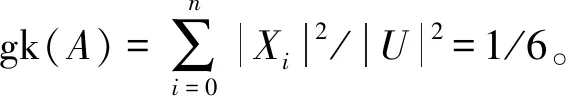
gk(A-{A})=14/36; gk(B-{B})=12/36; gk(C-{C})=12/36;
根据单属性知识粒度和在A属性集上的知识粒度差值计算单属性的重要度值,按降序排序,获取关键词,分别为:
同样的道理:
Imp(b)=18/36-1/6=12/36>0;
Imp(c)=12/36-1/6=6/36>0。
排序之后,单属性递减序列为b,a,c,取前几位作为文本集的关键词,此实验只是验证所有属性的核不为空的情况,特使用了文献[11]中数据进行验证,此结果和文献[11]中结果是一致的。不过一般情况下,最小约简并不是唯一的,本文只是找出不完备信息系统中的一个约简方法。
4.2 算法效率验证
选用决策表1和UCI 机器学习数据库中的4个决策表在Inter(R) Core i5-2500 3.3GHZ CPU,4G 内存,Windows7 机器上进行实验,数据库采用MySql 5.1,与王珏等[12]和刘少辉等[13]的两种算法进行对比,这两种算法简称为算法1、算法2,本文中的算法简称算法3。实验结果如表2所示。从表2三种算法效率比较可知,当决策表实例数小于100时,算法3 与算法1、算法2在约简后执行时间上无明显区别。当决策表的实例数大于300时,算法1比算法2和3的效率低很多,后两种算法在实例数较大时则比较接近,从而我们确认,后两种算法更适用于大型的数据分析。单纯的执行时间上看,算法2又比算法3效率低一些。从表2约简前后属性个数比较可知,约简前,算法2 的中间结果含有较多的无用属性,仍需大量的工作才能得到理想的约简结果,最后算法3中使用Tabu算法和属性重要度的这一启发式策略,算法3 的约简前后的中间结果明显优于算法2,免除了大量的重复工作,进一步验证了Tabu算法与引入属性重要度这一启发式策略的有效性及正确性。

表2 算法效率比较
5 结论
本文利用粗糙集中的等价关系刻划知识粒度,将粒计算理论中的知识粒度概念应用于文本处理中,阐述了知识粒度的概念、原理、性质,给出了属性重要度的计算方法,并利用知识粒的属性重要性为启发式信息给出了信息决策系统的约简算法,最后提出了一种新的关键词获取方法。该方法充分利用了粒计算理论处理不确定数据方面的优势,并在此基础上使用了Tabu局部搜索算法,去除可省属性并减少了可搜索空间,提高了提取效率。本文在关键词提取方面作了探索性的工作,经实例验证,此算法是有效的,能提取出等价类的最小关键词集合。下一步计划根据此算法提取出的关键词集合获取文本分类规则,从而对大文本数据集进行快速有效的分类。
