基于功能磁共振成像的立体图像分辨
2019-04-13郑宏娜龙志颖侯春萍
李 元,郑宏娜,姚 力,龙志颖,侯春萍
基于功能磁共振成像的立体图像分辨
李 元1,郑宏娜2,姚 力2, 3,龙志颖3,侯春萍1
(1. 天津大学电气自动化与信息工程学院,天津 300072;2. 北京师范大学信息科学与技术学院,北京 100875; 3. 北京师范大学认知神经科学与学习国家重点实验室,北京 100875)
视觉是人与外界互动获取信息的主要手段,而双目视差信息是人脑估计外界环境深度结构的重要视觉线索之一.因此,研究人脑处理双目视差的神经机制对了解人类的视觉系统意义重大.功能磁共振成像(fMRI)技术为双目视差研究提供了有效手段.目前在fMRI研究中,虽然已经有很多研究利用fMRI技术深入探究了人脑处理双目视差信息的神经机制,但是利用该技术采集的人脑信号如何分辨包含双目视差信息的立体图像依然有待研究.针对这一问题,设计了一种基于fMRI的实验,该实验选用随机点图生成人造立体视图像作为实验刺激;相较于自然立体图像,该种立体图像可以更加方便地提取出立体图像中包含的图像特征.结合实验特性提出了一种基于lasso回归算法的体素编码模型,该模型利用了视觉感受野的稀疏特性,可以较好地借助立体图像中的二维特征并对fMRI数据进行编码分析和解码分析.其编码分析结果表明利用体素编码模型可以较好预测人脑接收立体图像的脑信号的体素广泛分布在人脑的各个视觉区中,并且大部分体素分布在初级视区V1、V2d和V3d中.解码分析结果表明,初级视觉区V1可以利用立体图像中的二维特征实现立体图像的识别,并且背侧视觉区V3d、V7和hMT+/V5可以与V1协同工作进行立体图像的识别.
功能磁共振成像;体素编码模型;解码;立体视觉
视觉信息占人类依靠五官所获得信息总量的80%,是人类从客观世界获得信息的主要来源[1].通过视觉信息产生的深度知觉对人类至关重要,它可以帮助人类判断物体间的相对距离,实现对物体的抓取和躲避等各种动作,是人类与外界进行交互的一种十分重要的视觉特性.而双目视差信息则是人眼产生深度知觉的重要线索之一.因此,人脑如何加工双目视差信息一直都是认知神经科学领域的研究热点.
针对双目视差神经机制的研究,最早可以追溯到20世纪60年代.最初,研究人员在猫的大脑中发现了对双目视差敏感的神经元[2],而后在猴子大脑中的多个视觉区陆续发现了与处理双目视差相关的神经元[3-7].类似地,在针对人类的研究中,已经有诸多学者通过功能磁共振成像(fMRI)技术证明了人脑对双目视差的处理并非集中于某个特定的视觉区,而是广泛分布于视觉区的腹背侧通路中[8-13],甚至一些顶叶区域和前运动皮层也参与了双目视差的加工[14-15].
虽然探究人脑处理双目视差神经机制的fMRI研究已经比较广泛,但上述研究从立体视觉刺激中所提取的双目视差特征较为单一;人脑实际接收到的立体视觉刺激却含有更丰富的特征;这些特征分布在一个立体空间中,它们含有的视差等级信息和空间位置信息均不相同,人脑通过处理这些特征从而识别出外界的场景并进一步与外界进行交互.因此,利用fMRI技术探究人脑如何利用立体图像中含有的特征进行立体图像的识别是一项很有意义的工作,而该项工作的核心在于能否找到立体图像特征与fMRI数据间的映射关系.Gallent组首次提出了体素编码模型的概念,并通过该模型成功使用fMRI数据实现了二维自然图像的识别[16].该种模型具有很强的泛化性,通过改变刺激特征和特征与fMRI数据间的映射关系可以将其应用到各种视觉领域的研究中.而后,该研究小组使用该种模型实现了自然场景的语义识别、自然图片的重构等工作[17-18].除该组外,其他研究者也通过使用这种体素编码模型实现了基于fMRI数据的二维图像识别和重构等工作[19-20].然而针对立体图像的识别工作目前还鲜有人涉及.
综上所述,本研究旨在考察能否利用图像的二维视觉特征实现对立体图像刺激的识别.本研究设计了一种fMRI实验,并提出一种体素编码模型,通过该模型实现基于fMRI数据的立体图像刺激的识别.
1 研究材料与实验设计
1.1 被试
两名北京师范大学的硕士研究生作为被试参加了本次fMRI实验.两名被试的性别以及参加实验时的年龄分别为被试1(男性,24岁),被试2(男性,26岁).所有被试身体健康,视力或矫正视力正常,均通过了实验前进行的立体图片测试,拥有正常的立体视觉.所有被试在实验前均已了解实验内容并在签署知情同意书后参加实验.本次实验通过了北京师范大学伦理委员会的同意.
1.2 实验设计
1.2.1 实验刺激
本实验的刺激分为两类,分别是用于训练体素编码模型的棋盘格刺激(checkerboard)和进行立体图像刺激识别的图形刺激(graph).
对于棋盘格刺激,首先在灰色背景的中央区域划分出10×10个棋盘格,每个棋盘格的视角尺寸为1.11°×1.11°.每张棋盘格刺激图片中包含了4种不同的棋盘格,分别为带有交叉视差信息(-10′)的随机点棋盘格、带有非交叉视差信息(10′)的随机点棋盘格、带有零视差信息(0′)的随机点棋盘格以及灰色背景棋盘格.660种棋盘格刺激图片被制作,图片间4种棋盘格的位置随机分布.
对于图形刺激,依然在灰色背景的中央区域划分出10×10个棋盘格,每个棋盘格的视角尺寸为1.11°×1.11°.与棋盘格刺激图片不同,每张图形刺激图片中只包含两种棋盘格,分别为带有视差信息的随机点棋盘格以及灰色背景棋盘格,其中随机点棋盘格中包含的视差信息应该为3种视差信息(交叉视差、非交叉视差和零视差)中的一种.通过将特定位置的棋盘格定义为随机点棋盘格的方法,本文研究制作了两类图形刺激,即5种字母图形刺激和5种形状图形刺激.图1(a)、(b)分别展示了本实验所用的一种棋盘格刺激和全部10种图形刺激的实际形态以及它们所包含的视差信息分布情况.
所有刺激的中心均有一个十字形的注视点,注视点覆盖的视角为0.6°×0.6°.所有实验刺激通过3D液晶显示器呈现,显示器型号为LG D2343p,分辨率为1080p.被试在扫描过程中佩戴3D偏振眼镜观看实验刺激,观看距离为110cm.
1.2.2 双目视差实验
本文实验包含两种实验刺激序列(run),分别为拟合体素编码模型的模型拟合序列和用来测试模型性能的模型测试序列.两种实验刺激序列均采用组块(block)设计.
每个被试需要执行30个模型拟合序列.每个序列中包含22个棋盘格刺激组块和23个注视点组块,每种棋盘格刺激图片对应1个棋盘格刺激组块,并且该刺激中的随机点以6Hz的频率闪烁,组块时长6s.注视点组块只包含了含有注视点的灰色背景,时长同为6s.两种组块交替出现,并且实验的开始和结束均为注视点组块.每个序列中的棋盘格刺激组块不会重复,即在执行所有模型拟合序列期间,每种棋盘格刺激组块只会出现一次.
每个被试需要执行两类(字母组和形状组)模型测试序列,两类模型测试序列分别包含5种字母图形刺激和5种形状图形刺激.对于每一组,每个被试执行5个序列,每个序列中包含10个图形刺激组块和11个注视点组块,每种图形刺激对应2个图形刺激组块,组块时长12s且只包含一种图形刺激,并且该刺激中的随机点以6Hz的频率闪烁.注视点组块只包含了含有注视点的灰色背景,时长同为12s.两种组块交替出现,并且实验开始和结束均为注视点组块.每组5个序列中包含的图形刺激均相同,但是呈现顺序有所不同.整体实验范式如图1(c)所示.同时,为了保证被试的注意力一直处在一个较高水平上,屏幕中心的注视点颜色会随机产生变化.
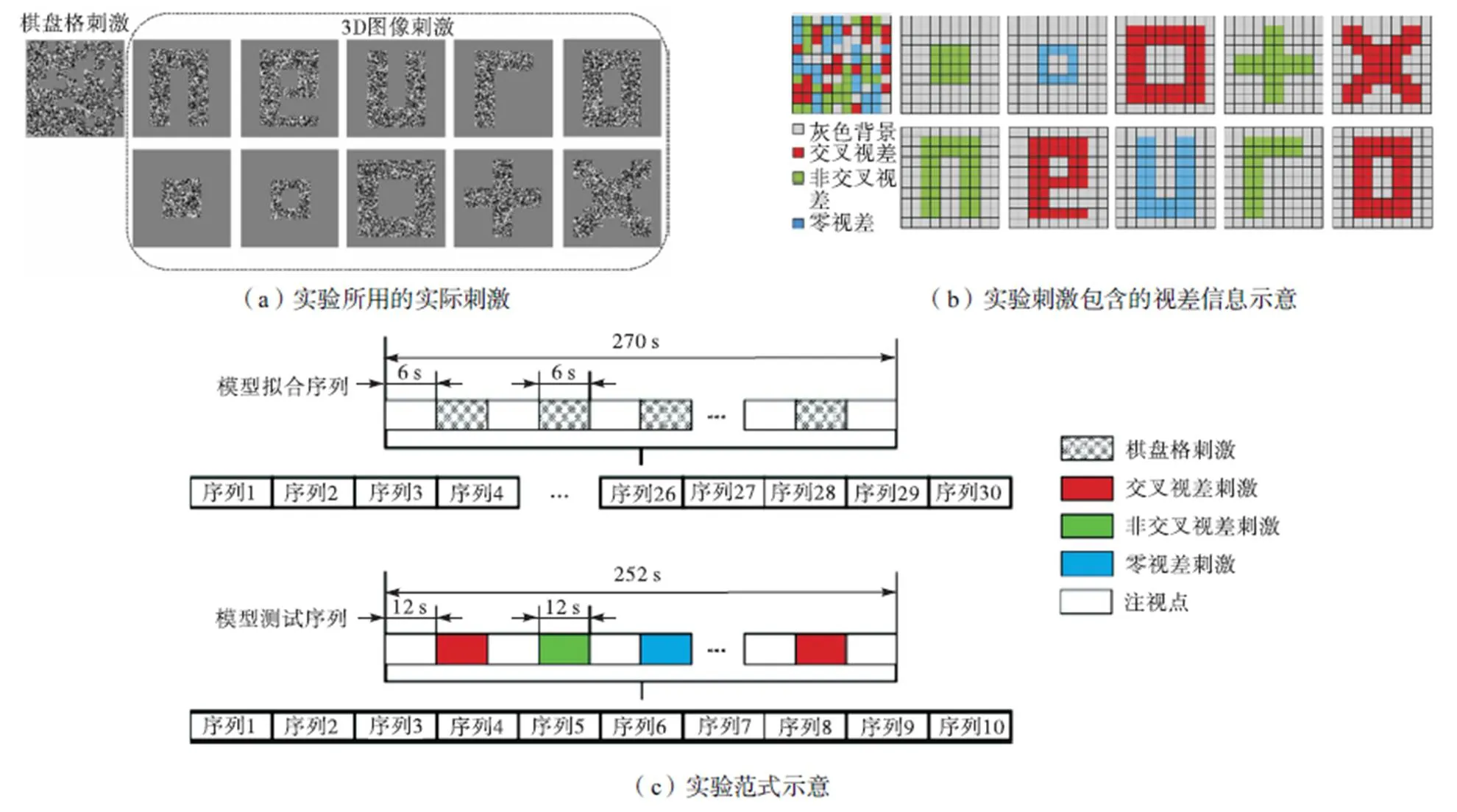
图1 实验设计示意
1.2.3 视觉区定位实验

1.2.4 实验顺序安排
两个被试采集的所有fMRI数据需要通过4次实验(session)完成.对于被试1,前两次实验中各包含15个模型拟合序列,时长约为1.5h.第3次实验包含10个模型测试序列,时长约为1.0h.第4次实验用于收集被试脑区定位的实验数据,其实验顺序为①被试高分辨率结构像扫描;②ROI定位实验(4个视网膜映射区域定位实验,2个LOC定位实验以及2个hMT+/V5定位实验),时长约为50min.该被试在第1天完成了前3次实验的数据采集,并在第2天完成了第4次实验的数据采集.
对于被试2,其实验的整体顺序与被试1的相同.唯一不同的是,该被试在第1天完成了前3次实验的数据采集,并在一周后完成了第4次实验的数据采集.
1.3 实验扫描参数
实验中所有fMRI数据均使用北京师范大学脑成像中心的西门子3.0T磁共振扫描仪进行采集.功能像采用平面回波成像(echo planar imaging,EPI)序列.所有实验中功能像采集参数包括:30slices,TR/TE/flip angle=2000ms/30ms/90°,FOV=192mm× 192mm,matrix=64×64,slice thick=3mm,gap thick=0mm.结构像的全脑分辨率为1.33mm×1mm×1mm.
2 体素编码模型在实验中的构建与应用
2.1 数据预处理
采集到的所有fMRI数据通过BrainVoyager QX软件进行预处理.预处理的步骤包含头动矫正(realignment)、时间层矫正(slice timing)、时域高通滤波(high pass filter).并将经过上述预处理的数据标准化至Talairach空间[27-28].
2.2 体素编码模型的构建
体素编码模型的构建可以分为3步,即实验刺激的特征提取、定义体素激活响应以及构建特征与体素激活响应间的映射关系.本文将分节依次对这3个步骤进行描述.
2.2.1 实验刺激的特征提取
从图1(b)可以看出,本文使用的实验刺激均通过一个10×10棋盘进行表示.基于这种特性,本文对实验刺激中的每个棋盘格进行了二值化操作,并将二值化后得到的图像作为特征.具体操作方法如下.
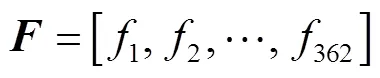
2.2.2 定义体素激活响应
本文将通过GLM分析得到的值作为体素对不同棋盘格刺激的真实激活响应.对每个被试的30个模型拟合序列分别进行GLM分析,每个序列中包含的22种棋盘格刺激对应22个条件(conditon),作为GLM中的22个回归因子.通过GLM分析得到每个体素对应的660个棋盘格刺激的660个回归权重值.
同样地,对于每个被试的两组共10个模型测试序列,同样对每个序列进行GLM分析,每个序列中包含的5种图形刺激对应5个条件,作为GLM的5个回归因子.通过GLM分析得到每个体素对应的10种图形刺激的50个回归权重值.
2.2.3 Lasso体素编码模型的构建
虽然没有任何相关研究表明外界刺激特征与fMRI体素响应存在线性映射关系.但不可否认的是,目前大多数相关研究中依然使用了线性模型去构建体素编码模型并取得了较好的研究成果[16-29].前人的研究已经证明神经元编码本身具有稀疏性,即神经元应该只对外界刺激中的某个区域有响应[30-31].因此在构建特征与体素响应的线性映射时应该考虑引入这种稀疏特性.基于这种考虑,本文在构建线性体素编码模型时,使用了加入L1限制的lasso线性回归算法.通过L1限制进行回归时可以将部分特征的权重置为0,从而保证体素的激活响应只与所有特征中的一部分产生关联,达到了将特征稀疏化的目的.线性回归的基本公式为
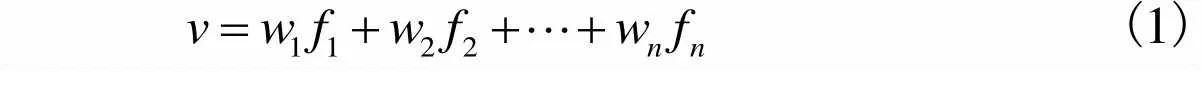
(1)

(2)

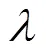
对于每个体素,利用所有棋盘格刺激的特征以及对应的执行上述步骤,最终可以分别估计出权重.从而构建出基于lasso的体素编码模型.
2.3 基于体素编码模型的解码分析
本文研究使用的解码方法可以得到每个ROI识别立体图像刺激的识别准确率,从而定位出人脑对处理立体图像刺激有帮助的脑区.该方法的基本思路与之前的研究相似[16].为了消除筛选体素数量对最终结果的影响,对于每个ROI,本文选出了数量各异的体素集群,并通过每个集群分别进行立体图像刺激的识别并计算识别准确率,而后将所有体素集群对应 的识别准确率进行平均作为该ROI最终的识别准 确率.
前人的研究已经表明人脑处理不同外界刺激时并非将这些刺激交由单一脑区进行处理;相对地,不同脑区处理的外界刺激种类会有交集[13-32].因此,在对本文研究所用实验刺激进行解码时,单独的ROI可能并不能充分地利用从实验刺激中所提取的特征进行解码.基于这种考虑,本文在进行基于ROI的解码分析时,除了预先定义的10个ROI,也考虑使用不同ROI合并形成的组合ROI去进行解码分析.在所有ROI中V1作为处理视觉信息最基础的脑区已被证明可以处理多种视觉特征,并且已经有研究表明该脑区会接收来自于高级脑区的信息反馈[33].因此,本文将V1与其他9个ROI依次合并组成新的9个组合ROI——V1+V2d,V1+V3d,V1+V3A,V1+V7,V1+V5,V1+V2v,V1+V3v,V1+hV4和V1+LOC.因此,本文要依次对10个ROI和9个组合ROI进行解码分析.
本文采集到的模型测试序列的数据中,每种图形刺激对应了不同时间点下的5种不同的脑状态激活模式.由于fMRI数据本身包含很大的噪声,因此这5种激活模式中可能有的激活模式已经被噪声影响以致于无法准确地反映人脑接收对应立体图像刺激时的真实激活模式.为了防范这种问题,本文在识别模型测试序列中的10种图形刺激时并没有将该识别问题转化成一个简单的多分类问题,而是通过如下方法进行计算.
(1) 提取每个ROI的体素集群.对于每个ROI中的每个体素,首先将模型测试序列中的10种图形刺激输入到体素编码模型中得到10种预测激活响应,并按照图形刺激的类别(字母图形和形状图形)分为两类各5种.同时每个体素共有50种真实激活响应,这些激活响应分别对应了10种图形刺激,即每种图形刺激对应了5种真实激活响应,计算每5种真实激活响应的平均值即可得到10种平均真实激活响应.将得到10种平均真实激活响应按照图形刺激的类别分为两类各5种.分别计算每类5种真实激活响应与对应的5种预测激活响应的皮尔逊相关系数,得到两类各1个相关性系数;并将其分别作为预测字母图形刺激和形状图形刺激的模型预测准确率.分别按照这两种预测准确率的高低对ROI中的体素进行排序,从而构建出两种新的体素排序序列,即字母排序序列和形状排序序列.对于后续的解码分析,在识别字母图形刺激时,选取形状排序序列中预测准确率最高的前个体素构成一个体素集群并进行后续的解码分析.同理,在识别形状图形刺激时,选取字母排序序列中预测准确率最高的前个体素构成一个体素集群并进行后续的解码分析.的变化范围为10到对应ROI的体素数量,变化间隔为5个体素.

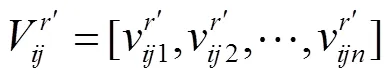
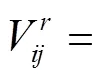

(3)
其中

(4)

2.4 基于体素编码模型的编码分析
解码分析的结果可以直接衡量不同ROI间识别准确率的差异,从而定位识别立体图形刺激能力最强的脑区.然而,对于体素级的分析,使用解码分析方法很难做到.因此,为了更全面地分析数据,编码分析也是一种必要的分析手段.在编码分析中,本文研究目的旨在可以直观看出人脑各个脑区中具有较高模型预测准确率的体素分布.基于此目的,本文首先将在解码分析中为每个体素定义的预测字母图形刺激和预测形状图形刺激时的两个模型预测准确率进行平均,并将该平均值作为每个体素预测全部图形刺激的模型预测准确率.而后,本文将0.2设为阈值,将预测准确率高于该阈值的体素映射到人脑皮层上,该阈值的设定参考了前人的研究[29-34].
3 实验结果
3.1 解码分析结果
图2展示了2个被试10个ROI的识别准确率.本文分别将10个ROI的体素集群作为样本使用SPSS软件(版本20.0)进行了单样本T检验,从而检验各个ROI的识别准确率是否显著高于随机水平,单样本T检验结果如表1所示.表1中“#”表示对应ROI的识别准确率不显著高于随机水平.结果表明,被试1的V1、V2d、V2v、V3v和hV4的识别准确率显著高于随机水平且<0.0005.被试2的V3d和V7的识别准确率显著高于随机水平且<0.0005.
表1 ROI的单样本T检验结果

Tab.1 One-sample T test results of ROIs

图2 ROI的识别准确率
图3和图4展示了2个被试V1中体素集群的识别准确率变化曲线,纵坐标表示体素集群的识别准确率,横坐标表示体素集群含有的体素数量.图右上方的数字表示了图2中V1的准确率,该准确率通过平均V1中所有体素集群识别准确率来得到.从图中可以看出,如果把体素集群数量限定在固定的范围内(体素数量大于400),两个被试的V1均可以获得稳定且较高的识别准确率.

图3 被试1的V1中体素集群的识别准确率变化曲线

图4 被试2的V1中体素集群的识别准确率变化曲线
图5展示了2个被试9个组合ROI的识别准确率.本文分别将9个组合ROI的体素集群作为样本使用SPSS软件(版本20.0)进行了单样本T检验,从而检验各个组合ROI的识别准确率是否显著高于随机水平,单样本T检验结果如表2所示.表2中“#”表示对应组合ROI的识别准确率不显著高于随机水平.单样本T检验结果表明,被试1的所有组合ROI的识别准确率均显著高于随机水平且<0.0005.被试2的V1+V3d和V1+V5的识别准确率显著高于随机水平(V1+V3d:<0.0005;V1+V5:<0.001),V1+V7的识别准确率边缘显著高于随机水平且=0.053.
表2 组合ROI的单样本T检验结果

Tab.2 One-sample T test results of combine ROIs
注:表中的值为单样本T检验后得到的值.
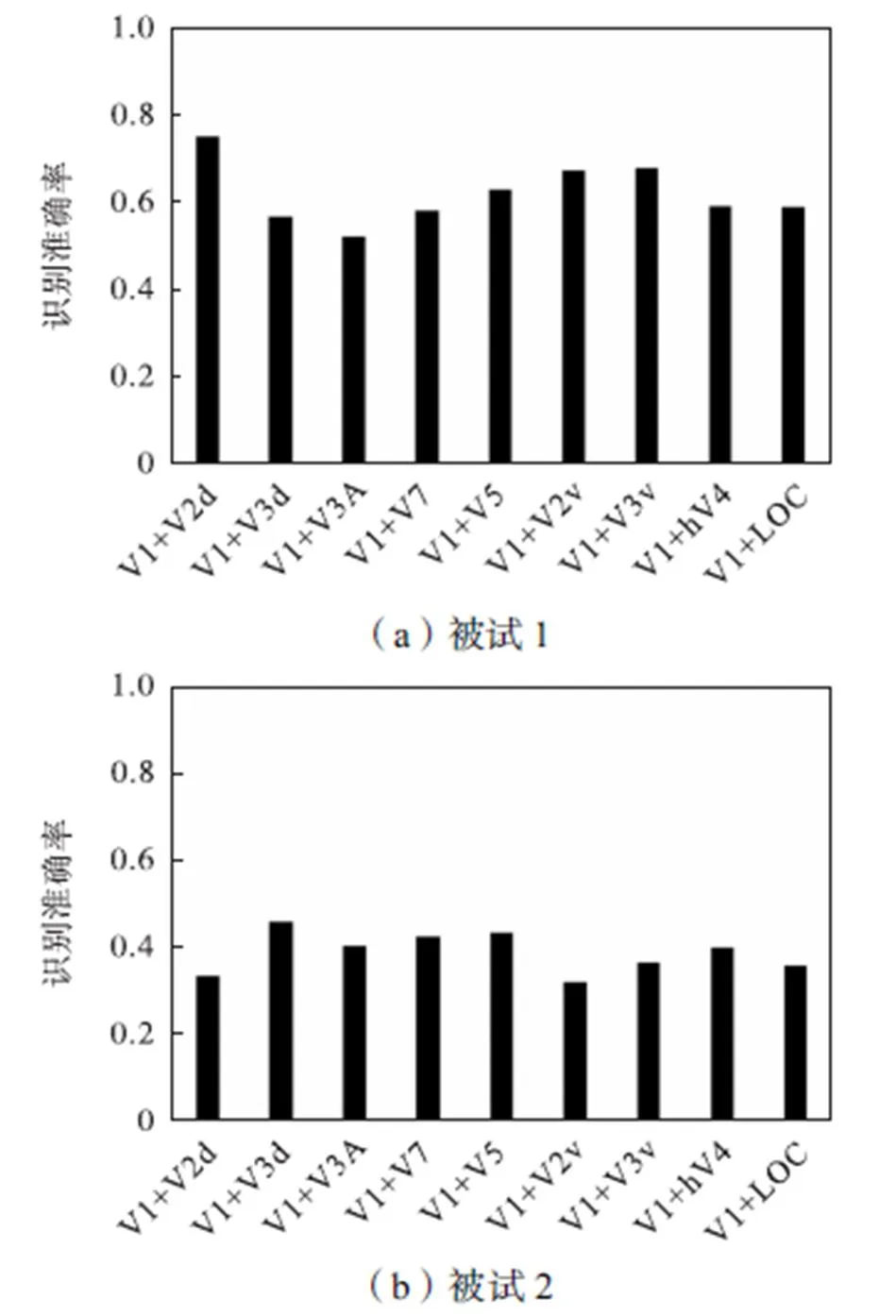
图5 组合ROI的识别准确率
3.2 编码分析结果
图6展示了两个被试模型预测准确率的大脑皮层映射.图中橘黄色区域表示预测准确率高于0.2的区域.可以看出两个被试模型预测准确率较高的体素均主要分布在初级视觉区(V1,V2d和V3d)中,但同时其他脑区也存在具有较高预测准确率的体素.

图6 两个被试的模型预测准确率的大脑皮层映射
4 讨 论
本文研究旨在设计出一种fMRI实验,并提出一种可以应用于该实验数据分析的体素编码模型.基于感受野的特性,本文提取了立体图像的二维特征构建出基于lasso的体素编码模型,实现了对立体图像的识别.
基于10个ROI的解码分析结果表明被试1识别准确率显著高于随机水平的脑区为V1、V2d、V2v、V3v和hV4;而被试2识别准确率显著高于随机水平的脑区为V3d和V7(见图2).这些脑区均已被证明参与了立体视觉的加工[35-36].虽然两个被试10个ROI的解码分析结果没有表现出很好的一致性,但是通过图3和图4的结果可以看出两个被试V1脑区的立体图像识别准确率虽然随体素集群包含的体素数量变化有一定的波动,但当体素数量大于400时,均能获得稳定且较高的识别准确率.该结果表明V1在利用二维特征对立体视觉刺激解码的过程中起到了关键作用.而两个被试基于9个组合ROI的解码分析结果也进一步证明了V1对于人脑识别立体图像的重要性(见图5).从图中可以看出,两个被试组合ROI识别准确率结果的一致性有明显提高.V1+V3d、V1+V7和V1+V5均获得了一致高于随机水平的识别准确率.表明了V3d、V7和hMT+/V5在识别立体图像时可以与V1协同工作并获得较高的识别准确率.值得注意的是,这3个脑区均位于背侧视觉通路,而背侧通路被认为与处理视差信息有关[12].这也进一步加强了本文研究结论的说服力.
编码分析结果表明模型预测能力强的体素主要分布在初级视觉区的背侧部分(V1、V2d和V3d).该结果与解码分析结果比较相符,表明初级视觉皮层对于人脑通过二维特征去识别三维图片具有重要作用.前人的研究也已经证实初级视觉区与多种初级视觉特征的处理有关[33-38],这也间接证明了本文构建模型的合理性.
前人的研究已经证明通过初级视觉皮层能够利用二维特征构建体素编码模型解码二维图像[16].本文研究则使用二维特征构建体素编码模型去解码立体图像.虽然受此影响,其识别准确率低于前人对二维图像识别准确率,但是本文研究的结果进一步证明了二维视觉特征对于分辨立体图像同样起到非常重要的作用.在将来的研究中,探究如何从立体图像中合理地提取三维特征并将其用来进行立体图像的识别是本文笔者未来的研究方向.
5 结 语
本文研究提取了立体图像刺激中的二维特征,并通过lasso线性回归算法构建了体素编码模型,从而对fMRI数据进行编码和解码分析.分析结果表明初级视觉皮层中的体素拥有较强的解码能力;并且V1和背侧高级视觉区具有识别立体图像的能力.
前人的研究已经证明通过初级视觉皮层能够利用二维特征构建体素编码模型解码二维图像[16].本文研究则使用二维特征构建体素编码模型去解码立体图像.其研究结果进一步证明了二维视觉特征对于分辨立体图像同样起到非常重要的作用.在将来的研究中,探究如何从立体图像中合理的提取三维特征并将其用来进行立体图像的识别是本文作者未来的研究方向.
[1] Kolster H,Mandeville J B,Arsenault J T,et al. Visual field map clusters in macaque extrastriate visual cortex[J]. Journal of Neuroscience,2009,29(21):7031-7039.
[2] Barlow H B,Blakemore C,Pettigrew J D. The neural mechanism of binocular depth discrimination[J]. The Journal of Physiology,1967,193(2):327-342.
[3] Poggio G F,Gonzalez F,Krause F. Stereoscopic mechanisms in monkey visual cortex:Binocular correlation and disparity selectivity[J]. The Journal of Neuroscience,1988,8(12):4531-4550.
[4] Hinkle D A,Connor C E. Disparity tuning in macaque area V4[J]. Neuroreport,2001,12(2):365-369.
[5] Burkhalter A,Van Essen D C. Processing of color,form and disparity information in visual areas VP and V2 of ventral extrastriate cortex in the macaque monkey[J]. The Journal of Neuroscience,1986,6(8):2327-2351.
[6] Deangelis G C,Newsome W T. Organization of disparity-selective neurons in macaque area MT[J]. The Journal of Neuroscience,1999,19(4):1398-1415.
[7] Roy J P,Komatsu H,Wurtz R H. Disparity sensitivity of neurons in monkey extrastriate area MST[J]. The Journal of Neuroscience,1992,12(7):2478-2492.
[8] Minini L,Parker A J,Bridge H. Neural modulation by binocular disparity greatest in human dorsal visual stream[J]. Journal of Neurophysiology,2010,104(1):169-178.
[9] Li Y,Zhang C,Hou C,et al. Stereoscopic processing of crossed and uncrossed disparities in the human visual cortex[J]. BMC Neuroscience,2017,18(1):80-1-15.
[10] Sun H C,Luca M D,Ban H,et al. Differential processing of binocular and monocular gloss cues in human visual cortex[J]. Journal of Neurophysiology,2016,115(6):2779-2790.
[11] Finlayson N J,Zhang X,Golomb J D. Differential patterns of 2D location versus depth decoding along the visual hierarchy[J]. NeuroImage,2017,147:507-516.
[12] Goncalves N R,Ban H,Sánchez-Panchuelo R M,et al. 7 Tesla fMRI reveals systematic functional organization for binocular disparity in dorsal visual cortex[J]. The Journal of Neuroscience,2015,35(7):3056-3072.
[13] Preston T J,Li S,Kourtzi Z,et al. Multivoxel pattern selectivity for perceptually relevant binocular disparities in the human brain[J]. The Journal of Neuroscience,2008,28(44):11315-11327.
[14] Georgieva S,Peeters R,Kolster H,et al. The processing of three-dimensional shape from disparity in the human brain[J]. The Journal of Neuroscience,2009,29(3):727-742.
[15] Patten M L,Welchman A E. fMRI activity in posterior parietal cortex relates to the perceptual use of binocular disparity for both signal-in-noise and feature difference tasks[J]. PloS One,2015,10(11):e0140696-1-22.
[16] Kay K N,Naselaris T,Prenger R J,et al. Identifying natural images from human brain activity[J]. Nature,2008,452(7185):352-355.
[17] Stansbury D E,Naselaris T,Gallant J L. Natural scene statistics account for the representation of scene categories in human visual cortex[J]. Neuron,2013,79(5):1025-1034.
[18] Naselaris T,Prenger R J,Kay K N,et al. Bayesian reconstruction of natural images from human brain activity[J]. Neuron,2009,63(6):902-915.
[19] Zuiderbaan W,Harvey B M,Dumoulin S O. Image identification from brain activity using the population receptive field model[J]. PloS One,2017,12(9):e0183295-1-17.
[20] Wen H,Shi J,Zhang Y,et al. Neural encoding and decoding with deep learning for dynamic natural vision[J]. Cerebral Cortex,2016,28(12),4136-4160.
[21] Warnking J,Dojat M,Guérin-Dugué A,et al. fMRI retinotopic mapping:Step by step[J]. NeuroImage,2002,17(4):1665-1683.
[22] Tyler C W,Likova L T,Chen CC,et al. Extended concepts of occipital retinotopy[J]. Current Medical Imaging Reviews,2005,1(3):319-329.
[23] Tootell R B,Hadjikhani N,Hall E K,et al. The retinotopy of visual spatial attention[J]. Neuron,1998,21(6):1409-1422.
[24] Tootell R B,Hadjikhani N. Where is ‘dorsal V4’in human visual cortex? Retinotopic,topographic and functional evidence[J]. Cerebral Cortex,2001,11(4):298-311.
[25] Zeki S,Watson J,Lueck C,et al. A direct demonstration of functional specialization in human visual cortex[J]. The Journal of Neuroscience,1991,11(3):641-649.
[26] Kourtzi Z,Kanwisher N. Cortical regions involved in perceiving object shape[J]. The Journal of Neuroscience,2000,20(9):3310-3318.
[27] Lancaster J L,Rainey L H,Summerlin J L,et al. Automated labeling of the human brain:A preliminary report on the development and evaluation of a forward-transform method[J]. Human Brain Mapping,2015,5(4):238-242.
[28] Lancaster J L,Woldorff M G,Parsons L M,et al. Automated talairach atlas labels for functional brain mapping[J]. Human Brain Mapping,2015,10(3):120-131.
[29] Naselaris T,Olman C A,Stansbury D E,et al. A voxel-wise encoding model for early visual areas decodes mental images of remembered scenes[J]. NeuroImage,2015,105:215-228.
[30] Hubel D H,Wiesel T N. Receptive fields,binocular interaction and functional architecture in the cat’s visual cortex[J]. The Journal of Physiology,1962,160(1):106-154.
[31] Hubel D H,Wiesel T N. Receptive fields and functional architecture of monkey striate cortex[J]. Journal of Physiology,1968,195(1):215-243.
[32] Huth A G,Nishimoto S,Vu A T,et al. A continuous semantic space describes the representation of thousands of object and action categories across the human brain[J]. Neuron,2012,76(6):1210-1224.
[33] Murray S O,Boyaci H,Kersten D. The representation of perceived angular size in human primary visual cortex[J]. Nature Neuroscience,2006,9(3):429-434.
[34] St-Yves G,Naselaris T. The feature-weighted receptive field:An interpretable encoding model for complex feature spaces[J]. NeuroImage,2018,180(10):188-202.
[35] Orban G A,Sunaert S,Todd J T,et al. Human cortical regions involved in extracting depth from motion[J]. Neuron,1999,24(4):929-940.
[36] Buckthought A,Mendola J D. Neural Mechanisms for Binocular Depth,Rivalry and Multistability[M]. London:INTECH Open Access Publisher,2012.
[37] Nasr S,Polimeni J R,Tootell R B. Interdigitated color-and disparity-selective columns within human visual cortical areas V2 and V3[J]. The Journal of Neuroscience,2016,36(6):1841-1857.
[38] Nasr S,Tootell R B. Visual field biases for near and far stimuli in disparity selective columns in human visual cortex[J]. NeuroImage,2016,168:358-365.
Discrimination of Stereo Images by the Human Brain Based on fMRI
Li Yuan1,Zheng Hongna2,Yao Li2, 3,Long Zhiying3,Hou Chunping1
(1. School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China; 2. College of Information Science and Technology,Beijing Normal University,Beijing 100875,China; 3. State Key Laboratory of Cognitive Neuroscience and Learning,Beijing Normal University,Beijing 100875,China)
Vision is a main pathway for human understanding of the physical world. Binocular disparity is an important visual cue in the human brain’s estimation of depth structure in the environment. Therefore,exploring the neural mechanism of disparity processing is essential for understanding the human visual system. Functional magnetic resonance imaging(fMRI)technology provides an effective method for the study of binocular disparity in humans. Although some fMRI studies have explored the neural mechanism of binocular disparity processing,it has remained unclear as to how to discriminate stereo images from the observed fMRI data. In this study,an fMRI experiment was designed and the artificial stereo images by random dot stereograms were used as experimental stimuli. Compared with the natural stereo image,the image features in the artificial stereo image can be extracted more easily. Considering the characteristics of the experiment designed,a voxel-wise encoding model based on lasso was proposed. The model with the sparsity of the visual receptive field can utilize the 2D visual features of stereo images to perform encoding and decoding analyses from fMRI data. The encoding analysis results indicated that the voxels were distributed in various visual areas,which could accurately predict the human brain signals from stereo images by voxel-wise encoding models. Most of these voxels were distributed in the primary visual areas V1,V2d and V3d. The decoding analysis results indicated that primary visual area V1 had higher discriminative power to stereo image by using 2D features of stereo images. Moreover,the dorsal visual areas V3d,V7 and hMT+/V5 could work with V1 to discriminate stereo images.
functional magnetic resonance imaging(fMRI);voxel-wise encoding model;decoding;stereo vision
10.11784/tdxbz201808004
TP3-05
A
0493-2137(2019)06-0608-10
2018-08-01;
2018-09-20.
李 元(1987—),男,博士研究生,liyuan06024209@hotmail.com.
侯春萍,hcp@tju.edu.cn.
国家自然科学基金资助项目(61520106002,61471262);国家自然科学基金重点资助项目(61731003).
the National Natural Science Foundation of China(No.61520106002,No.61471262),the Key Program of the National Natural Science Foundation of China(No.61731003).
(责任编辑:王晓燕)
