基于不均匀空间划分和R树的时空索引
2019-03-22赵馨逸黄向东乔嘉林王建民
赵馨逸 黄向东,2 乔嘉林 康 荣 李 娜 王建民,2
1(清华大学软件学院 北京 100084)2 (工业大数据系统与应用北京市重点实验室 北京 100084) (stefanie_xin@163.com)
时空数据是指包含时间和空间经纬度信息的时空对象[1].它的特点是数据量大、更新频率快、数据分布不均匀、在时间和空间维度具有自己的时空特性(在时间维度具有连续性和单调递增性,在空间维度具有区域临近性).
随着时空数据体量的急剧增加,对其进行有效的存储、查询、分析等操作的需求愈发明显.时空索引便是解决时空数据存储与查询的有效手段.解决此问题时,时空索引需要面临3个核心问题:1)如何在利用时空数据特性的同时快速构建索引;2)如何进行快速的时空对象查询;3)如何使其支持更为多样的查询种类(如切片查询、轨迹查询等).在数据量巨大、数据分布不均衡的情况下如何构造一种合适的索引使得其解决上文提出的问题,是目前面临的挑战.
从20世纪80年代至今,时空索引已有了长足的发展和进步.普度大学计算机科学系Mokbel教授在2010年对时空索引的方法进行了详细的调查[2]并根据查询时间范围将时空索引技术分为3类:
1) 历史数据索引TB-Tree(trajectory-bundle Tree)[3],3D R-Tree[4],HR-Tree(historical R-Tree)[5]等.
2) 实时数据索引2-3TR-Tree(2-3 trajectory R-Tree)[6]等.
3) 未来数据索引TPR-Tree[7]等.
本文主要研究历史数据的时空索引,尚不支持对于实时数据和未来数据的索引.
现有的时空数据管理系统和索引存在3方面的问题:
1) 没有充分利用时空数据的特性,如Spatial-Hadoop[8],PostGIS,Geospark[9]不能同时索引带有空间和时间维度的数据;TB-Tree[10],3DR-Tree[4]不能保持时空数据在空间上或时间上的邻近性.
2) 无法随数据的密集程度动态调整,在数据不均匀的情况下导致时间开销增大,如SETI[11].
3) 无法提供多种类型的查询处理,辅助使用者进行数据的分析,如CloST[12].
为了解决以上诸多问题,本文提出了一种新型2层时空索引GRIST(Geohash and R-Tree based index for spatio-temporal data).它在空间上采用Geohash编码进行空间划分,在时间上采用R-Tree索引.为了适应不均匀的数据分布,GRIST在空间上改进了原有Geohash的编码及映射算法,设计了根据数据分布自适应分裂的方法;在时间上GRIST改进了一维R-Tree,增加节点合并策略,以减少R-Tree的规模、提升查询效率.同时,GRIST还针对自身的索引结构设计了时空数据查询方法,提供多种类型的查询,较好地解决了上文提到的现有系统的3个问题.除此之外,本文还基于Cassandra底层存储实现了索引构建和查询算法,使用Spark实现分布式查询,解决大规模数据的存储与查询问题.
1 相关工作
1.1 空间索引方法
R-Tree[13]是高度平衡的多叉树,通常它会被用来索引高维空间数据且不需要预知数据的整体分布,因为它会随着数据更新动态地调整数据组织的方式.
Quad-Tree[14]按照空间划分数据,可以使用有序的线性表实现.它的优点是内存开销小、查询效率高、维护简单.但它需要预知数据的分布,灵活性比较差.
Geohash是在2008年被提出的,它的思想是把二维经纬度编码为一维的字符串.这种编码可以保证空间的邻近性,编码相同前缀位数越多,空间距离越近.目前,Geohash已被广泛应用于需要使用一维索引处理空间数据的情况,如HBase[15]等.
1.2 时空索引方法
常见的索引历史数据的时空索引方法主要分为3类:
1) 构建包含时间维度的三维R-Tree.该类方法时空共用1棵R-Tree,将时间信息作为一个新的维度加入到R-Tree的创建过程中.代表索引有3DR-Tree[4]等.它的优点是应答基于坐标的查询效率较高;缺点是作为树结构,引入过多多余空间且基于轨迹的查询效率不高.
2) 为每个时间戳构建一个二维R-Tree.常见的有HR-Tree[5],MV3R-Tree(multiversion 3D R-Trees)[16]等.它的优点是对时间点查询十分有效;缺点是时间段查询效率非常低.
3) 面向轨迹的索引.该类方法主要供轨迹查询,代表有TB-TreSe[3],SEB-Tree(start/end time stamp B-Tree)[17]等.它的优点是维持了“轨迹”的概念,同一个轨迹的节点被链接在一起;缺点是破坏了空间邻近性,不利于空间近邻查询.
1.3 现有时空系统
GeoMesa基于空间填充曲线技术(z-order-curve)降维,然后将一维空间进行Geohash编码,将空间编码和时间区间进行交叉组合对数据进行分区存储[18].该系统支持空间、时间、属性过滤查询.但是由于空间划分和时间划分粒度大小固定,它不能适应数据分布和查询条件的变化.
PostGIS是关系型数据库PostgreSQL的扩展系统,主要用于处理空间数据.它采用R-Tree的空间索引结构,支持快速查询的空间索引.PostGIS提供了强大的空间数据分析方法,可以支持海量数据的存储与管理,但是对时间维度的处理较为欠缺.
TrajStore[19]是一个自适应存储轨迹数据的系统,采用Quad-Tree的空间索引结构.它提出了空间网格的分裂和合并等动态操作,以适应数据的增加或查询框大小的变化.但是,该系统不是分布式的,难以应对GB级甚至TB级的数据.
2 问题定义
2.1 时空数据定义
时空数据由多个时空数据点构成.时空数据点为一个四元组(Stringdeviceid,longtimestamp,floatlon,floatlat).其中deviceid为时空数据所属设备的唯一标识(设备号),timestamp为时空数据产生时刻的时间戳,lon和lat分别为数据空间信息的地理经纬度.
2.2 时空数据类型定义
按照时空数据的查询需求,时空数据可以分为二维空间点、二维空间区域(矩形空间区域与圆形空间区域)、轨迹点、轨迹5种主要类型,定义如下:
1) GPSData,二维空间点.由经度值与纬度值构成,表示为(lon,lat).
2) GEOCircle,二维圆形空间区域.在二维空间中的圆形区域,由一个GPSData类型的圆心和一个浮点型半径组成,表示为(GPSDatacenter,floatradius).
3) GEORect,二维矩形空间区域.在二维空间中的矩形区域,由2个GPSData类型的点组成(分别代表矩形左下角与矩形右上角的点),表示为(GPSDatabl,GPSDatatr).
4) TrajPoint,轨迹点.带有时间信息的GPSData点,由一个GPSData类型的点与时间戳组成,表示为(GPSDatalocation,longtimestamp).
5) Traj,轨迹.一系列相同deviceid的轨迹点集合.由一组按时间升序排列的TrajPoint组成,一组拥有N个TrajPoint的轨迹表示为[TrajPointtji]N(i=1,2,…,N).
2.3 查询模式定义
时空数据的查询需求种类繁多,本文算法主要讨论面向时空的查询,涉及的查询种类有3种:
1) GEORectregion,longt→[GPSDatap]n.根据空间范围与时间点,查询所有的相关数据点(个数为n).
2) GEORectregion,[longt1,longt2]→[GPSDatap]n.根据空间范围与时间段,查询所有的相关数据点(个数为n).
3) GEORectregion,[longt1,longt2]→[TrajPointtp]n.根据空间范围与时间段,查询所有的相关数据点(个数为n).
其中,region表示空间范围,t表示时间点,[t1,t2]表示时间范围,p表示空间点,tp表示轨迹点,[]n表示元素个数为n的集合.
2.4 本文涉及的相关参数
本文GRIST索引涉及的相关参数如下:
1) 数据包包含的数据个数(packageSize).每个包中二位空间点的个数,由用户指定.
2) 最大编码长度(Lmax).空间索引的最大编码长度,由用户指定.
3) 最小编码长度(Lmin).空间索引的最小编码长度,由用户指定.
4) 时间和空间分裂阈值(maxRTreeSize).R-Tree分裂为4个子树时所需达到的数据量,由用户指定.
3 GRIST索引的构建
本节主要介绍GRIST索引的结构与构建过程.GRIST索引结构为2层时空索引:第1层为空间索引;第2层为时间索引.在构建时,GRIST会首先根据用户设置对数据进行打包,并建立数据包的摘要,随后以数据包为单位进行索引的构建.
3.1 数据包与数据摘要
数据包是GRIST时空索引所处理的基本单元,在索引构建时会将同设备号、一定数目(packageSize)的GPSData类型的数据按照时间升序排列构成数据包,这样的设计可以减少索引构建时由于数据插入所带来的索引更新次数.
为了减小索引体积,GRIST中仅存储数据包的摘要而非数据包中的原始数据.摘要是数据包中所有点构成的矩形,它的表示形式为GEORect (GPSDatabl,GPSDatatr),其中bl为数据包中空间位置位于左下角的点,tr为右上角的点.摘要结构如图1所示,其中黑色点代表一个GPSData,矩形框表示摘要.
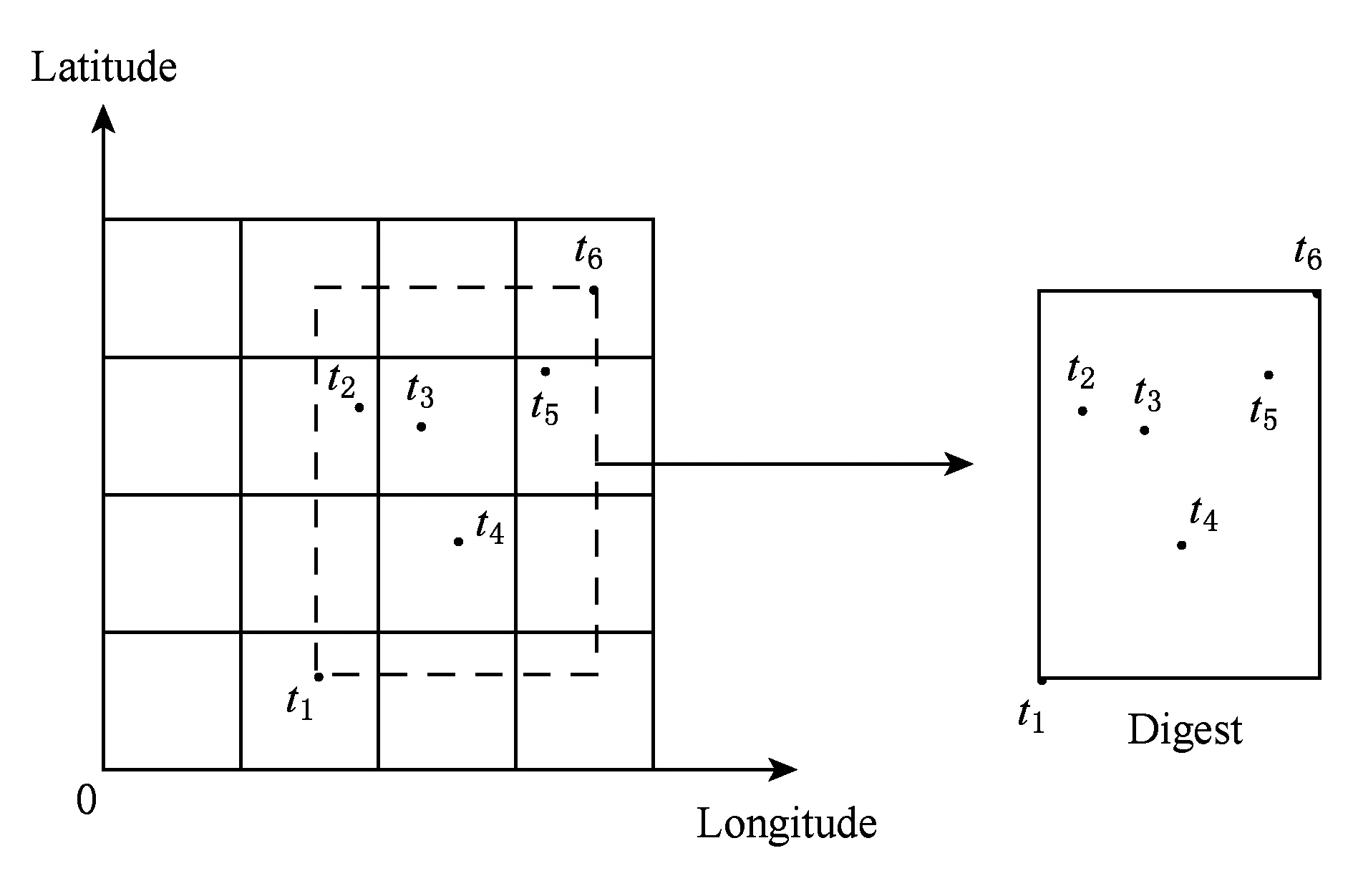
Fig. 1 Digest of packet图1 摘要结构示意图
3.2 GRIST时空索引概述
GRIST为2层时空索引.第1层为空间索引,它将空间划分为没有交叠且可根据网格里的数据量自适应调整的网格.每个网格使用本文提出的不均匀Geohash映射算法计算得到.第2层为时间索引,利用一维R-Tree进行构建,不同R-Tree索引第1层空间的不同网格中的数据,其中MBR为一维时间段,叶子节点为存储设备的deviceid.在使用中,本文对R-Tree进行了一些改进,当同一个设备的2个MBR时间段连续时,将会对其进行合并.同时,为了自动适应时空数据的不均匀分布,当某一个区域的数据点个数达到某个阈值(maxRTreeSize)时,GRIST会分别在时间和空间层索引上进行分裂.下面详细介绍2层索引的具体内容和分裂策略.
2层索引的组合方式如图2所示,第1层索引的每一个空间网格都会有一个第2层索引的R-Tree与之对应,为了更清晰地表达,图2中仅给出1种空间网格与R-Tree的对应关系.

Fig. 2 Correspondence between spatial grid and R-Tree图2 空间网格与R-Tree的对应关系
选择先空间索引后时间索引的原因,一方面是由于空间是固定不变的而时间是无限增长的,因而空间对数据的划分较于时间更为明显;另一方面则是因为这样的划分可以同时保障数据在空间上的邻近性以及在一定空间内时间上的连续性和邻近性.
3.3 第1层空间索引
由于Geohash编码可以将二维坐标数据映射成一维空间并保证空间的临近性,GRIST的第1层空间索引选取了Geohash作为编码算法的基础.但是,传统的Geohash编码是将整个空间均匀划分,会产生某个区域的数据过度密集的情况.一方面,当新的数据到来的时候,更新这个区域的索引会带来很大的I/O负担;另一方面,查询的时候也会增加I/O成本和查询候选集的大小,降低查询效率.因此,GRIST的空间索引在Geohash均匀编码的基础上根据区域内的数据量多少自动进行空间分裂,以达到平衡每个区域中数据量的目的.
3.3.1 空间索引的分裂策略
GRIST的空间分裂策略是当1个区域内的数量达到分裂阈值后,该区域自动分裂为4个等大的子区域,原始编码同时被删除.
如图3所示,当1100区域中数据超过分裂阈值后,该区域将由1100编分裂为{110000,110001,110010,110011}编码的4个区域.0011区域分裂情况同理.
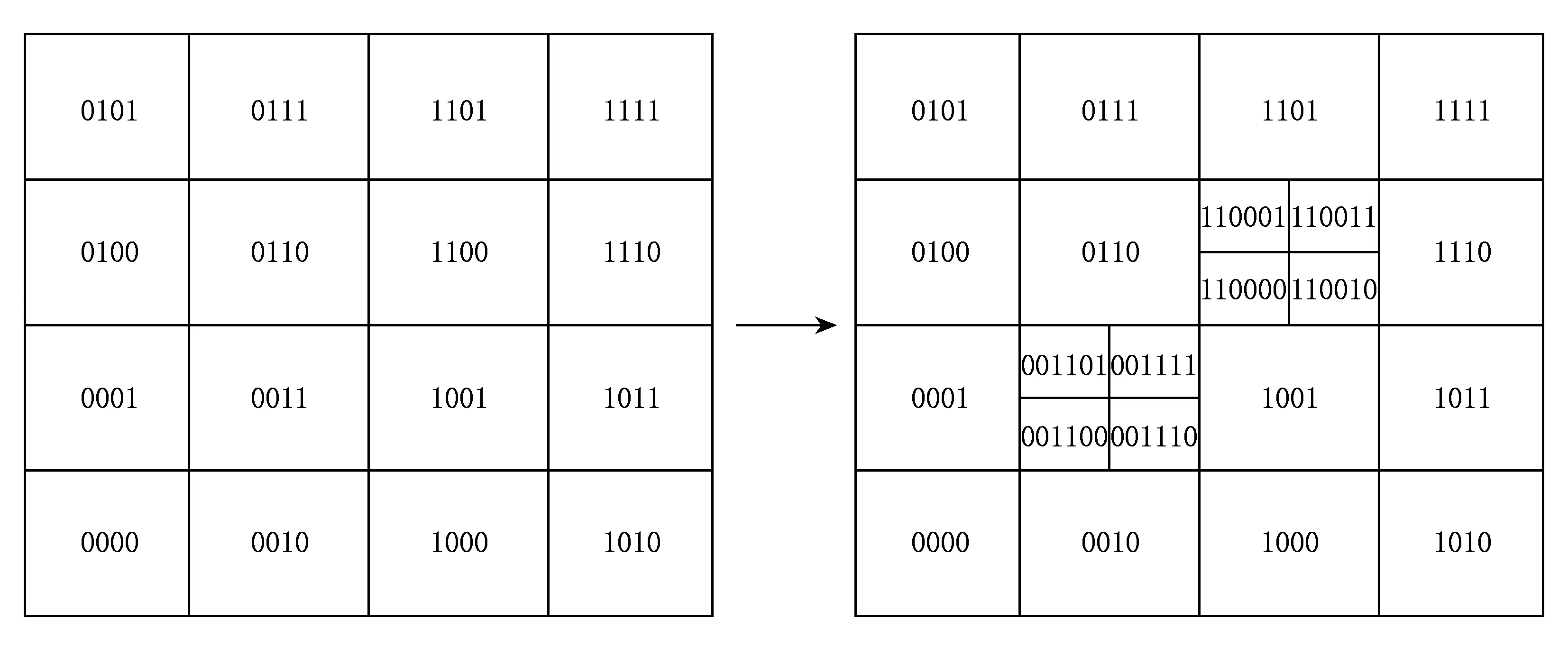
Fig. 3 Example of GRIST geometry split图3 区域分裂示意图
自动空间分裂会造成空间中各部分的Geohash的编码长度不等(称之为不均匀编码),在传统的均匀编码下,可以使用Geohash编码、解码算法完成空间到编码集合的映射.但是在不均匀编码时,传统方式无法完成.同时,空间划分的集合也更加不易维护,需要动态更新.因此GRIST提出了针对不均匀编码的编码存储与索引集维护方法,并针对不均匀空间给出了编码和映射算法.
3.3.2 不均匀Geohash编码存储与索引集维护
由于不均匀编码,空间中不同区域对应的Geohash编码长度不一,使得搜索难度增大.因此,GRIST设计了一种统一的64 b长整型的编码,对不均匀的Geohash进行存储.
编码的转换规则如图4所示.假设Geohash编码长度为L,位置0~7位为L,位置8~61-L位为0,位置62-L~61位为Geohash编码本身,下标62~63位为0.
以1111为例,转换后的64 b为:00 1111 00…000 00000100.这种转换有2个明显的好处:一方面是节省空间索引编码的空间消耗,将字符串转为整型进行存储;另一方面,该编码保留了空间上的邻近性,空间上越邻近转换后的数值大小越接近.同时,可以保证一个Geohash编码的所有前缀编码对应的整型值都小于等于该Geohash对应的整型值,这个优点对下文中提到的空间映射前缀查找很有帮助.

Fig. 4 Spatio code图4 编码转换规则示意图
通过不均匀Geohash编码,整个空间可以表示为一系列长整形Geohash编码的集合,称之为空间索引集.初始的空间索引集为整个空间(GEORect(GPSData(-180,-90),GPSData(180,90)))在编码长度为最小编码长度(用户设定)时的均匀Geohash编码集合.在索引的构建过程中,随着数据的不断加入,空间索引集也在动态变化.
3.3.3 不均匀Geohash空间编码和映射方法
对于时空索引,给定空间在索引集上的映射是索引构建和查询的关键环节,主要分为2个步骤:1)将给定的空间编码为Geohash值的集合;2)在空间索引集中寻找相应的编码集合(称为空间映射).在GRIST中主要涉及2种空间类型:点和区域,而区域均可转化为其外接矩形,因此以下主要讨论点和矩形的编码和映射算法.点的编码方法为传统Geohash编码,在此不再阐述.我们在此给出在不均匀Geohash空间编码下矩形编码算法(算法1)、点映射算法(算法2)、矩形映射算法(算法3).
算法1. 不均匀空间矩形编码算法.
输入:GEORectr、编码长度L(偶数);
输出:编码集合C.
① 计算r.bl和r.tr长度为L的Geohash编码g1,g2;
② 分别使用Geohash解码g1,g2,得到矩形r1和r2;
③ 使用r1.bl和r2.tr构成矩形rc;
④ 计算经度间隔:l1=360lbL;
⑤ 计算纬度间隔:l2=180lbL;
⑥ 以l1和l2均匀划分rc,得到矩形集合R;
⑦ 计算R中每个矩形的中心点,得到点集合P;
⑧ 对P中每个点计算长度为L的Geohash编码,得到编码集合C;
⑨ RETURNC.
矩形编码算法的主要思路是:首先将原始矩形的左下角和右上角进行Geohash编码、解码得到新的矩形rc,如图5中左1图、左2图所示,之后按照编码长度L将矩形划分成小矩形空间,如图5中右2图所示,此时划分过的矩形即为矩形对应的Geohash区域.计算这些区域中心点的Geohash值即可得到最终的编码集合,如图5中右1图所示.

Fig. 5 A example of rectangle encoding图5 矩形编码算法示意图
算法2. 不均匀空间点映射算法.
输入:空间点p、空间索引集S、最大编码长度Lmax(用户预设);
输出:点编码Cp.
① 计算点p长度为Lmax的空间点编码g;
② 在S中搜索g的前缀编码Cp;
③ RETURNCp.
因为使用最大编码长度映射出的编码未必存在于真实的空间索引集中,所以需要在空间索引集中找到与该编码最为接近(即前缀匹配个数最多的编码),我们称之为前缀编码.由于GRIST将Geohash编码转化成了64 b整数类型,前缀查找的方法就变为在空间索引集中进行二分查找,找到比待查找编码小的编码中最大的编码,即为待查找的前缀编码.这样的操作降低了原有字符串前缀匹配的时间复杂度.
算法3. 不均匀空间矩形映射算法.
输入:矩形r、空间索引集S、最大编码长度Lmax(用户预设);
输出:映射编码集合Cr.
① 将矩形r,最大编码长度Lmax输入到算法1,得到矩形编码集合C;
② 在S中搜索C中每个编码c的前缀,将前缀加入映射编码集合Cr中;
③ RETURNCr.
3.4 第2层时间索引
GRIST第2层索引为时间索引,采用一维R-TREE来索引时间段,每个空间分区内的数据使用一维R-Tree建立时间索引.R-Tree内部节点是一维的时间段,叶子节点是设备ID.它的特性使得时间上邻近的对象会存在同一个节点.
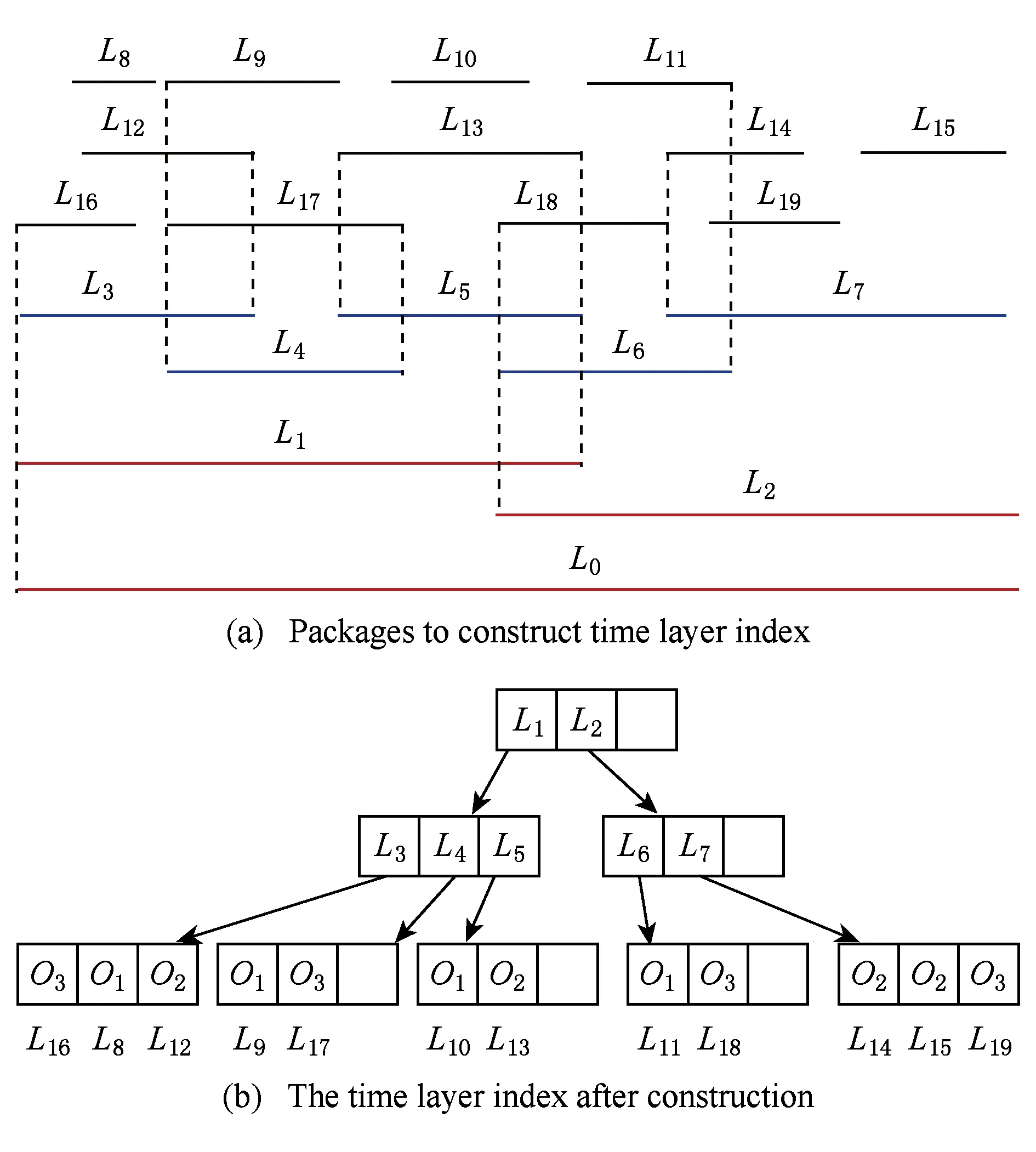
Fig. 6 An example of temporal index building图6 时间层索引构建过程
3.4.1 R-Tree时间索引的构建
R-Tree构建时同样以数据包为单位,对于每个数据包,都对应一段带有时间信息的数据,如图6(a)所示.我们可将在时间上定频、连续的数据归为一段.之后,会按照这些时间段数据的起始时间构建R-Tree.时间层索引构建的过程如图6(b)所示.
其中,O1,O2,O3表示3个设备的ID,L8,L9,L10,L11为O1的4个时间段数据,L12,L13,L14,L15为O2的4个时间段数据,L16,L17,L18,L19为O3的4个时间段数据.这些时间段数据到达的顺序为L16,L8,L12,L9,L17,L10,L13,L18,L11,L14,L19,L15.
在使用过程中,为了减小R-Tree本身的大小、提升查询效率,本文对它的插入做了一些改进,增加了同一设备连续时间段的合并功能.假设R-Tree中已有时间段[t1,t2]以周期T到达,新来一个时间段[t3,t4]也以周期T到达,且t3与t2之间的间隔刚好为T,那么2个时间段则可以合并,合并后的时间段为[t1,t4].此时R-Tree会删除[t1,t2]节点,插入[t1,t4].这样不仅减小了R-Tree的大小而且便于查询.
3.4.2 时间索引的分裂策略
当一个空间中的数据达到分裂阈值时,空间将进行分裂.伴随空间层的分裂,时间层也会分裂.空间区域的分裂在前文已经说明.R-Tree的分裂是将该R-Tree索引的数据重新按照新的空间划分分为4部分,然后重新构建R-Tree索引.
3.5 GRIST索引构建过程
基于3.3节空间索引和3.4节时空索引,GRIST时空索引的构建流程主要是:
1) 将整个空间(GEORect((-180,-90),(180,90)))构建为一个矩形Rspace,将Rspace以及最小编码长度输入算法1,得到空间对应的矩形编码,作为整个空间的初始化空间索引集.
2) 计算输入的数据包集合的摘要集合.
3) 对于每一个数据包的摘要,使用算法3计算相应的矩形映射编码集合.然后将数据包插入编码集合对应空间的R-Tree中.
4) 若R-Tree达到分裂阈值则分裂相应空间和时间索引;否则结束.
算法伪码如算法4.
算法4. GRIST索引构建算法.
输入:整个空间矩形Rspace、数据包集合packages、最小编码长度Lmin(用户预设)、最大编码长度Lmax(用户预设).
① 将Rspace,Lmin输入算法1得到空间索引集S;
② 计算packages的摘要集合digests;
③ for eachdigestindigests
④ 将digest,S,Lmax输入算法3得到矩形映射编码集合Cr;
⑤ 将digest对应的package插入Cr中每一个编码C的R-Tree中;
⑥ 如果R-Tree达到分裂阈值则分裂相应空间和时间索引;否则RETURN;
⑦ end for
4 GRIST索引的查询
GRIST索引支持本文提到的所有面向时空的查询,同时支持面向时间的查询和面向空间的查询.其中,面向空间的查询可以看作面向时空查询的特殊情况(即时间取全集);面向时间的查询则是通过对数据包在系统存储层中的排序组织方法予以支持的[20].因而,在此只重点讨论面向时空的查询.
面向时空的查询均是基于时空索引所做的查询,其中比较重要的是时空范围查询.时空范围查询包含设备查询(本文2.3节查询1和查询2)与轨迹查询(本文2.3节查询3).在GRIST索引中,面向时空的查询需要经过空间层查询、时间层查询2层索引查询得到所需结果.
时空范围查询见算法5,基本流程如下:
1) 空间层查询.将查询区域映射为索引区域.
2) 时间层查询.将每个索引区域对应的R-Tree读到内存,进行时间点/段查询,得到满足时间条件的包的集合.
3) 时空过滤.遍历所有的包中的数据进行时空过滤,得到结果设备集合.
4) 若为设备查询,则直接返回结果集.若为轨迹查询,则将相同deviceid的设备分入一组,每组数据按照时间升序排列,形成轨迹并返回.
算法5. GRIST时空范围查询算法.
输入:时间查询范围Qtime、空间查询范围Qspatial、空间索引集S、最大编码长度Lmax(用户预设);
输出:空间点集合[S]n、轨迹集合T.
① 空间层查询.将Qspatial,S,Lmax输入算法3得到矩形映射编码集合Crectangle;
② 时间层查询.在Crectangle中每个编码C的R-Tree中查询满足Qtime的包集合P;
③ 根据Qtime和Qspatial对P中每一个数据进行时空过滤.若为设备查询,则直接返回结果点集.若为轨迹查询,则将相同deviceid的设备分入一组,每组数据按照时间升序排列,形成轨迹并返回.
5 索引性能实验
5.1 实验说明
为了测试GRIST索引的性能,本文基于NoSQL的K-V数据库Cassandra实现了索引和数据的持久化,并使用Spark实现GRIST的分布式查询.实验主要分为2部分:
1) GRIST相关参数对比实验;
2) GRIST,GeoMesa,PostGIS系统导入与查询对比实验.
5.2 实验准备
5.2.1 实验环境
本节的实验环境分为单机和集群2种条件,单机节点系统为Ubuntu14,i7处理器、30 GB内存.集群采用6节点集群,其中每个节点配置和单机节点相同.开发语言使用Java(JDK1.8),Cassandra版本为3.3,Spark版本为2.0.
5.2.2 实验数据
本文实验使用的数据来源如表1所示,实验采用了Uber开源的真实数据,但是由于数据量较少,本文在Uber数据基础上开发了随机数据生成器,模拟设备移动产生的更多数据.这些随机数据分布不均匀,产生频率为一个设备每分钟1个数据点,每个设备共产生10万或100万个数据点.为体现GRIST在大数据量下的表现,下文实验主要使用随机数据,同时也会在必要地方使用Uber数据进行分析.

Table 1 Data Size of Performance Experiments表1 索引性能实验数据规模
5.3 GRIST相关参数实验
在GRIST系统中,包大小、R-Tree分裂阈值对GRIST系统的数据导入和查询表现产生一定影响.所以本节实验主要围绕以上2个因素对GRIST索引进行参数实验,实验均使用随机生成的数据(5 000万条数据),在集群条件下进行实验.
5.3.1 包大小对导入和查询的影响
本节的实验环境中包大小从100~1 000等间隔取值,间隔为100.编码长度最小为6,最大为10.R-Tree分裂阈值为1 000.查询范围为编码长度为2,4,6,8,10,12对应的空间区域,时间长度为1年,随机生成.实验结果如图7所示:
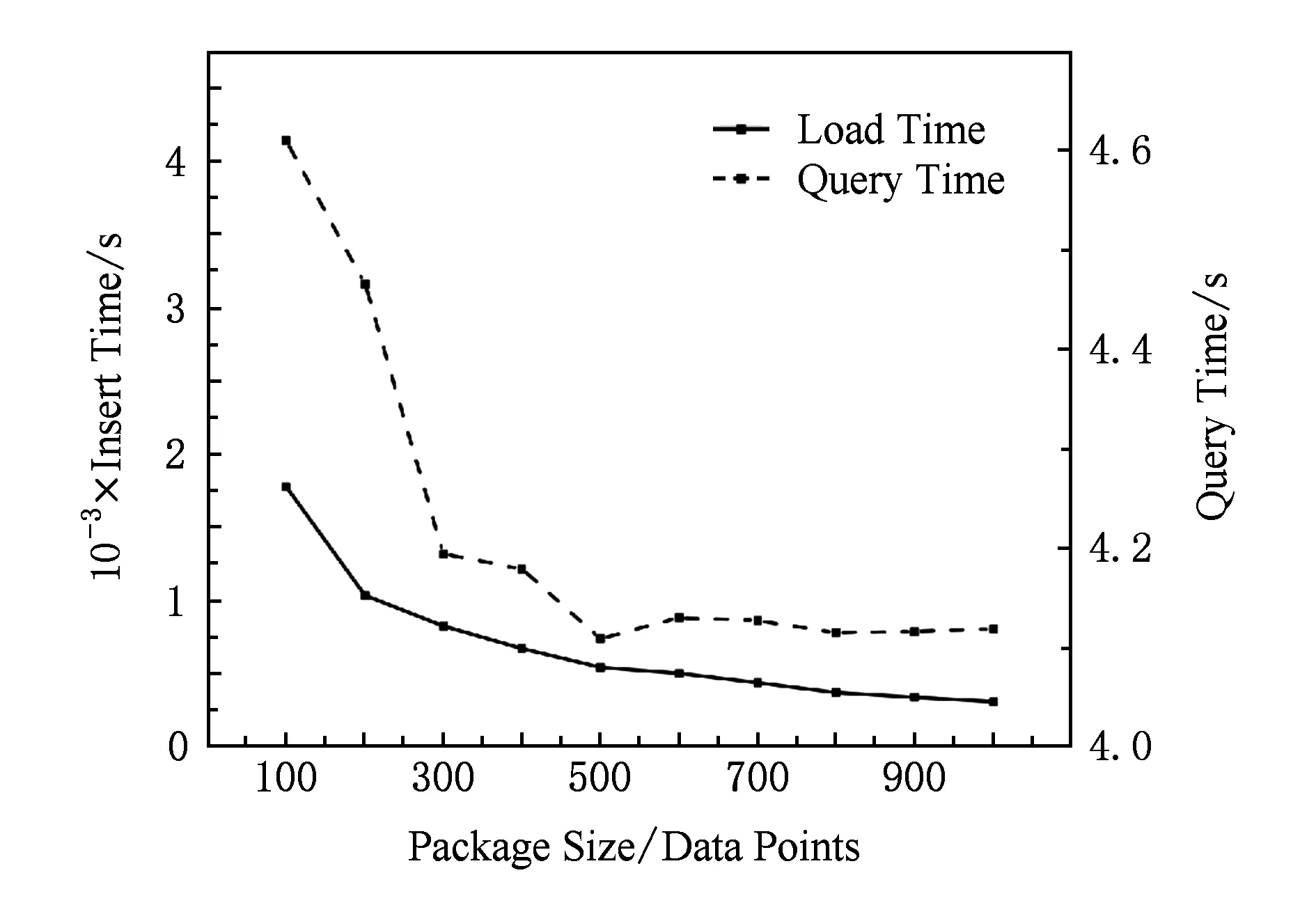
Fig. 7 Result of package size experiment图7 包大小对导入和查询的影响实验结果
由图7可以看出,随着包大小数值的增大,时空索引数据导入时间逐渐减小,且和包大小呈反比关系.其主要原因是,包的大小越大包的数量越少,同一批次写入Cassandra中的数据点数越多.在Cassandra批量写入的承受阈值内,写入的执行速度会随包大小(包中数据点的数量)而减小.
在查询效率方面,随着包大小数值的增大,查询时间逐渐减小.其主要原因是随着包大小增大,系统中维护的包数量减少,在做相同区域的查询时获取的GRIST数据包减少,数据包的序列化、反序列化总时间减小.
5.3.2 R-Tree分裂阈值对导入和查询的影响
本实验中包大小采用500,编码长度最小为6、最大为10.R-Tree分裂阈值200~1 000等间隔取值,间隔为100.查询范围为编码长度为2,4,6,8,10,12对应的空间区域,时间长度为1年,随机生成.实验结果如图8所示.
由图8可以看出:R-Tree分裂的阈值越小,数据插入时间越短,主要原因是R-Tree分裂次数增多,数量增长,单个R-Tree规模下降,将其序列化到磁盘的时间缩短.
同时还可以看出:R-Tree分裂的阈值对查询耗时影响不大.这是因为在包大小不变时,查询时间主要由查询结果集的大小决定.
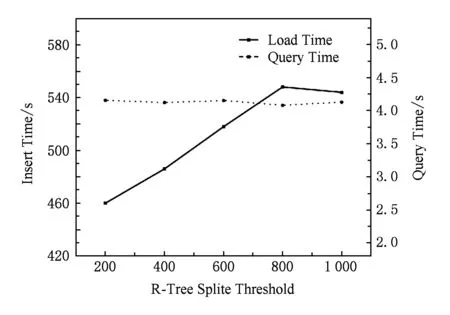
Fig. 8 Result of R-Tree splite threshold experiment图8 R-Tree分裂阈值对导入和查询的影响实验结果
5.4 现有系统对比
与现有系统对比的实验主要在单机和分布式2种环境下进行.单机实验主要以千万级以下数据为数据集,分布式实验主要以千万级以上数据为数据集.
5.4.1 单机环境系统对比实验
在本实验中PostGIS系统选用2.1版本,对Geometry类型的数据点构建GIST索引.GeoMesa系统选用底层为Cassandra存储的版本,版本号为1.3.1.实验结果为10次实验的平均值.
本实验中包大小为500,编码长度最小为6、最大为10,R-Tree分裂阈值为50.Uber数据查询条件为数据集所在全部区域,时间为6个月,随机生成.Random数据查询条件为编码为2,4,6,8,10,12对应的空间区域,时间为1个月,随机生成.实验结果如图9所示:

Fig. 9 Result of comparative experiment in single node environment图9 单机系统对比实验结果
5.4.2 分布式环境系统对比实验
在本实验中,由于PostGIS系统为单机系统,所以不对PostGIS进行实验.GeoMesa系统选用底层为Cassandra存储的版本,版本号为1.3.1.由于GeoMesa在亿级别以上数据集上数据插入时间超过1 d,所以GeoMesa实验仅在5 000万条Random数据集上进行实验.同时,为验证GRIST系统在大数据集的运行效果,GRIST实验将在千万及以上级别数据集(如表1所示)上进行实验.实验结果为10次实验的平均值.
本实验中导入参数与查询条件与5.4.1节中相同,不在此赘述.实验结果如图10所示.
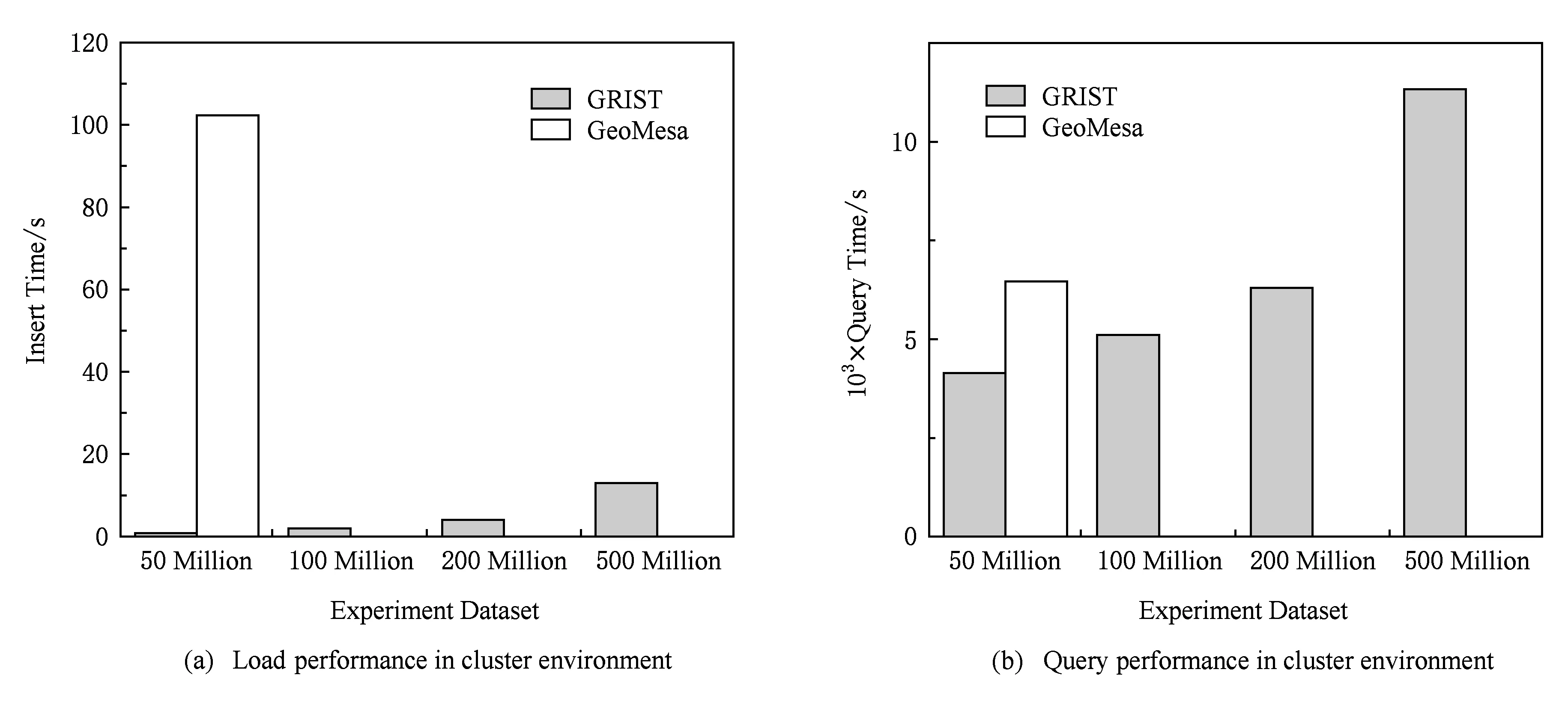
Fig. 10 Result of comparative experiment in cluster environment图10 分布式系统对比实验结果
5.4.3 实验分析
由图9和图10可以看出:相比GeoMesa和PostGIS,GRIST在单机与分布式版本的导入速度上优势明显,单机版本快10~45倍,集群版本可以达到200倍以上.这主要是因为GRIST首先对数据进行了打包,充分利用了Cassandra在批量插入上的优势,且在R-Tree索引中也按照时间进行了聚集,导致索引更新次数急剧下降,速度带来显著提升.
在查询性能上,查询区域大小相同的情况下,GRIST比GeoMesa和PostGIS快2~4倍.这主要是因为数据的打包减小了时间索引的个数,查询时索引操作次数降低,查询速度增快.
6 总 结
本文针对海量时空数据的高效查询提出了一种新型的索引结构GRIST,并介绍了该索引的构建和查询算法.
2层的时空索引GRIST可以支持海量的、未知分布的数据索引;支持多种类型的时空查询;支持分布式的查询.同时,本文使用Cassandra和Spark对GRIST实现了索引持久化以及分布式查询,并针对该系统的参数对数据导入和查询性能做了实验分析.与PostGIS和GeoMesa系统对比,GRIST具有很强的数据导入性能(10~45倍)以及较强的查询性能(2~4倍).
未来GRIST还将在以下方面继续改进:支持更丰富轨迹查询的种类,如轨迹相似性、进/出等;支持实时数据写入与查询操作;支持对未来的预测查询;支持时空数据分析,如:先将数据进行采样分析数据的分布,在数据导入前进行数据分区,减少导入的负担.
