EasiDARM:基于分布式的物联网设备自适应注册方法
2019-03-22施亚虎石海龙
施亚虎 石海龙 崔 莉
1(中国科学院计算技术研究所 北京 100190) 2 (中国科学院大学 北京 100049) (shiyahu@ict.ac.cn)
随着物联网[1]水平化[2]接入协议(如CoAP[3],MQTT[4],LwM2M[5],EBHTTP[6]等)的逐步成熟与实用化,将设备接入云平台(如Xively[7],Waston IoT[8],OneNET[9],YeeLink[10]等)以对设备进行实时访问逐步成为一种主流架构[11].这种云+端的模式使得物联网设备数量急剧增加,据Gartner估计[12],到2020年接入到互联网的物联网设备将达到260亿,到2050年物联网设备数量将进一步增长至万亿级别,有呈指数级增长的趋势.
由于现有互联网基础设施的限制(如IP地址和端口资源有限),绝大多数物联网设备通常位于企业局域网或家庭局域网中,没有独立的公网IP.因而物联网设备通常采用网络地址转换(network address translation, NAT)的方式与外部云平台进行交互.NAT协议要求物联网设备主动到云平台注册以进行IP及端口映射,只有注册过的设备才能被云平台访问.而基于安全考虑,企业网络或者小区网络往往设有防火墙,这些防火墙会定期剔除不常用的映射信息.另一方面,由于许多物联网设备存在动态性[13],如可穿戴设备或车联网设备,使得设备接入网络经常发生变化.这种物联网设备或其所处网络环境的动态性使得设备在云平台中的注册信息(包括IP和端口)失效,导致云平台无法实时访问设备.
因此为了保证物联网云平台与设备之间的双向实时访问,设备往往需要到云平台进行周期注册,以维持注册信息的有效性.现有多数物联网系统[7-10,14-16]采用固定周期的注册方法(static period register method, STRM),使用统一且固定的周期进行注册(如使用TCP长连接,采用固定周期的心跳机制来维持长连接),为保证对不同网络环境的适应性,一般将注册周期设置成一个较小的时间,以保证注册信息不会失效.采用这种注册方式的物联网系统,在设备数较少的物联网发展初期,能够提供稳定的物联网服务.随着物联网设备快速增长,这种注册方式将占用大量云平台资源(服务器内存、CPU时间、Internet带宽等),进而影响云平台的其他服务功能.
因而Ajitomi等人[17]提出了一种自适应注册方法,该方法可以探测物联网设备当前所处网络环境的注册信息失效周期,并根据该周期动态调整设备注册周期,使得设备注册开销最小.然而,该方法的周期探测过程所耗费的时间很长,开销很大,而且当局域网中大量设备同时进行周期探测时,如停电后恢复供电、平台故障重启等,会给网络和平台带来很大的瞬时负载,造成网络拥塞或平台崩溃.因此,该方法难以应对具有海量设备的未来物联网场景.
本文提出了基于分布式的物联网设备自适应注册方法(distributed based adaptive register method, EasiDARM),通过同一网络下不同设备间协同合作来完成复杂且耗时的周期探测过程,并通过参数同步实现结果实时共享,能极大地加快周期探测和设备自适应过程.方法将周期探测过程分为“快更新”和“快收敛”前后2个阶段,“快更新”阶段采用指数增长方式进行任务分配及周期探测,使注册周期快速增长,“快收敛”阶段采用线性增长方式进行任务分配及周期探测,使周期探测过程快速收敛.
本文的主要贡献包括2个方面:
1) 提出了一种基于“快更新”与“快收敛”两阶段相结合的分布式周期探测任务分配机制.“快更新”阶段设备采用指数增长方式进行任务分配及周期探测,加快注册周期增长速度,“快收敛”阶段采用线性增长方式进行任务分配及周期探测,加快分布式周期探测收敛速度.该方法在大幅减少周期探测过程耗时的同时大幅降低了物端、网端和云端开销.
2) 设计并实现了一套物联网设备管理框架,集成了本文提出的EasiDARM,验证了方法的可行性与有效性.并针对物联网设备存在资源受限和网络带宽受限的特点,采用“自适应精度”和“竞争限制”优化了分布式周期探测任务分配机制,进一步降低开销和避免广播风暴.当失效周期较大时,降低自适应精度,从而减少分布式周期探测耗时,且不会明显增加注册开销;当设备数较多时,限制参与分布式周期探测的最大设备数,从而有效降低由竞争带来广播通信开销.
1 相关工作
目前国内外已有大量的物联网云平台[11],大致可以分为3类:
1) 云平台为数据服务平台,如Thingspeak[18],SensorCloud[19],Everyware[20],EvryThng[21]等.各种感知设备通过Internet接入到平台,采用平台规定的数据上传协议和规则,周期地上传对物理世界所感知的数据,如温度、湿度、光照[22]等,平台对数据进行处理加工后,再通过适当的形式展示或交付给用户.此类云平台仅提供数据收集及处理的服务,无法对物联网设备进行反向访问.
2) 云平台在提供上述数据服务的基础上,还提供基于轮询的设备反向访问服务,如Nimbits[23]等.用户通过客户端将执行命令发至云平台,或者提前将执行规则存储在云平台,设备周期地与平台进行通信,查询是否有执行命令需要执行,若有则执行,从而实现了对设备的反向访问.此类平台受轮询周期的影响,其设备访问具有较高的延迟,难以应用于对实时性要求较高的物联网场景,适用范围较局限.
3) 云平台不仅提供上述服务,还提供设备的实时访问服务,如Xively[7]、Waston IoT[8]、OneNET[9]、YeeLink[10]、百度天工[14]、乐联网[15]、阿里智能[16]等,通过TCP,MQTT(基于TCP)等协议与设备建立长连接,从而实现平台与设备间的实时通信,进一步实现对设备的实时访问.为维持平台与设备间的长连接,需采用该长连接周期地进行通信如TCP的心跳机制和MQTT的心跳机制,此心跳机制即为本文所讨论的设备注册的一种具体实现.上述平台采用的是固定的心跳周期来维持长连接,随着物联网设备的增多,由设备注册带来的网端通信开销及云平台处理开销将急剧增多,进而造成网络拥塞或影响云平台的其他服务功能.
围绕减少物联网设备注册的开销,目前国内外已有部分研究成果.Ajitomi等人[17]针对实时访问类型的物联网设备的工作特点,通过定量分析,揭示了在所有通信成本中,用于维持设备连接的周期通信(即设备注册)占很大比重:当注册周期为50 s时,设备注册带来的云端成本保守估计占总的云端成本的45%.Ajitomi等人[17]通过建立一条额外的连接用于失效周期探测,因此用于设备访问的连接能够持续有效,不会影响设备的访问,其用于网络探测的探测值是固定的,虽然能将探测次数控制在固定次数以内,且能对探测耗时进行控制,但其所探测出的失效周期误差太大,由此所得的注册周期往往不是最优的.温彬民[24]通过对MQTT使用的心跳策略进行研究,提出了自适应心跳机制.该机制使用二分法快速查找最优的心跳值来维持网络长连接,能够在不同的网络环境下自适应找到最优的心跳值来维持网络连接,然而其网络探测的探测次数较多,且所耗费时间也较长,并且由于没有采用额外的连接用于自适应,还会影响设备的访问.上述自适应注册方法为设备独立进行自适应的注册方法(independent adaptive register method, IARM),其中每个设备均需独立进行周期探测,探测过程所耗费的时间很长,开销很大,当大量设备同时进行周期探测时,会给网络和平台带来很大的突发性负载,造成网络拥塞或平台崩溃,难以应对具有海量设备的未来物联网场景.
自适应注册涉及到对网络过期时间(即失效周期)的探测,在这个方面已有很多研究成果,均集中在传统互联网通信和P2P通信上,此类研究[25-30]所提出的周期探测方法并不能很好地适用本文所面向的实时访问的物联网应用,如Wang等人提出的NetPicule[30]方法采用多个TCP连接来探测失效周期,能够较快地完成探测,但此方法开销较大,无法用于接入了大量物联网设备的云平台,也无法运行在资源受限的物联网设备上.本文借鉴了NetPicule[30]方法的思想,采用多个设备进行周期探测,在减少周期探测耗时的同时,降低了周期探测的物端、网端、云端开销.
2 分布式周期探测的任务分配机制
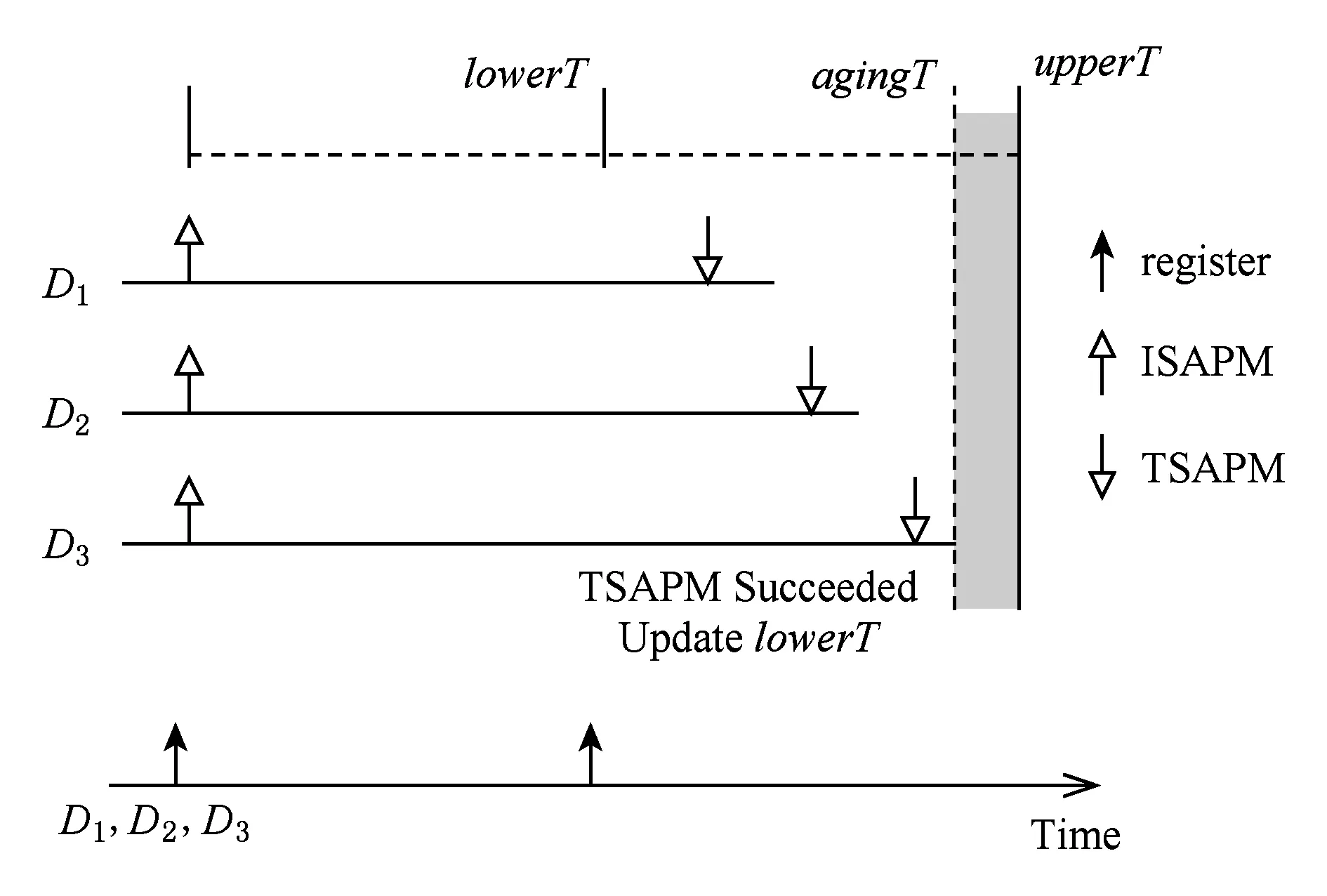
自适应注册的关键是对失效周期的探测,周期探测的过程是:对1个探测值testT进行探测,设备首先建立对自适应端口(self-adapting port)的NAT映射(init self-adapting port mapping, ISAPM),并在testT不再使用该端口进行通信.经过testT时间后,对自适应端口的NAT映射进行测试(test self-adapting port mapping, TSAPM),从平台发送请求至该端口,若设备能收到请求,则testT小于失效周期,否则大于失效周期,通过对不同探测值进行探测,最终能收敛出失效周期的近似值.
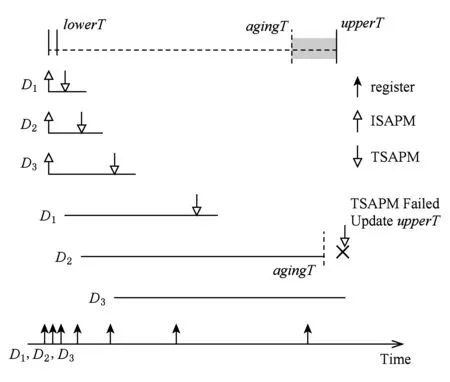
图1是局域网(local area network, LAN)中设备独立周期探测(independent measurement)和分布式周期探测(distributed measurement)的示意图,现有的自适应注册方法中每个设备均需独立完成整个周期探测过程(Task表示),整个过程需对多个探测值(t1,t2,…,tk)进行探测,且不同探测需顺序执行,其耗时长,开销大.考虑到同一网络中的所有设备的失效周期是相同的,分布式周期探测通过设备间协作共同完成周期探测过程,将整个探测过程划分成多个子任务并分配到多个设备执行,可同时对不同探测值进行探测,并将探测结果共享,不仅能加快周期探测的速度,而且能减少总的探测次数,减少物端、网端和云端开销.
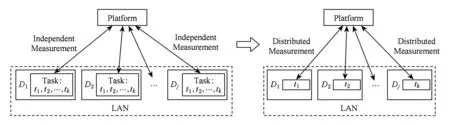
Fig. 1 Independent measurement and distributed measurement图1 独立周期探测与分布式周期探测示意图
分布式周期探测的关键是探测任务的分配,因此,设计高效的任务分配机制是本研究的重点.通过对周期探测过程的不同时期的特点进行分析,本文设计了“快更新”和“快收敛”机制分别用于周期探测的前期和后期进行探测任务的分配.
2.1 “快更新”机制

t1,1=2×lowerT,
t1,2=2×t1,1,
ti,j=2×ti,(j-1),
其中,i>0,j>0,ti,0=t(i-1),m.
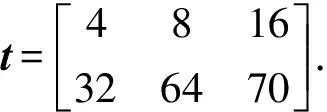
若设备Dj对ti,j的探测结果为有效时,则更新lowerT和T,并为Dj分配探测值为t(i+1),j的探测任务(如果有的话);若Dj对ti,j的探测结果为失效时,则提前结束所有未完成的探测任务,“快更新”执行结束并更新upperT.假设失效周期的真实值为agingT,“快更新”执行结束时,总的探测次数为test_num,探测轮数为loop_num,则:
当agingT≥upperT时,
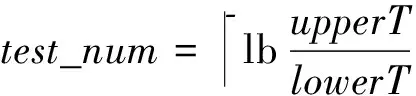
(1)

(2)
T=upperT;
(3)
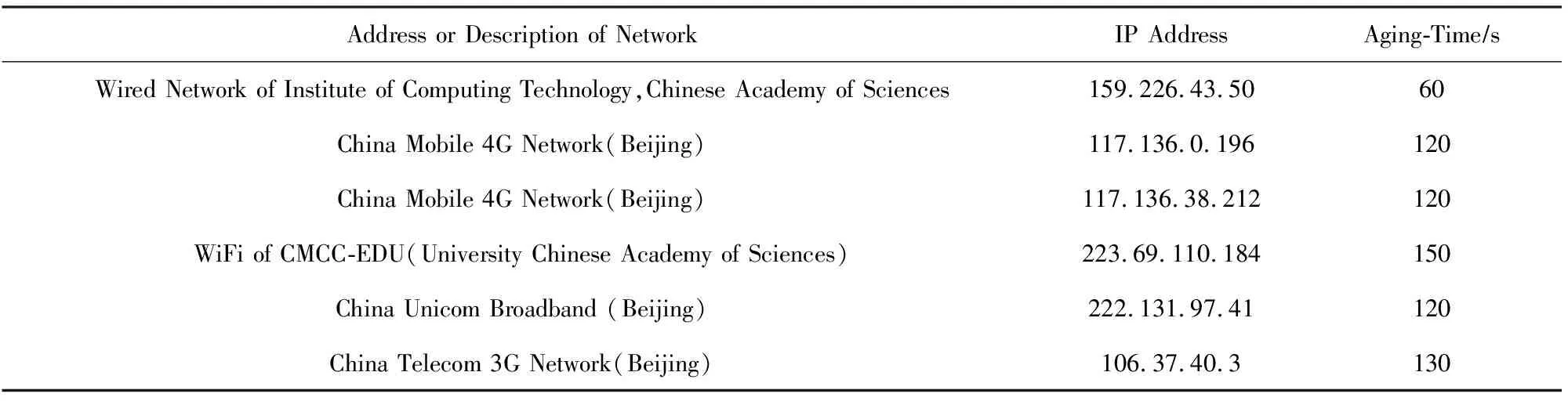
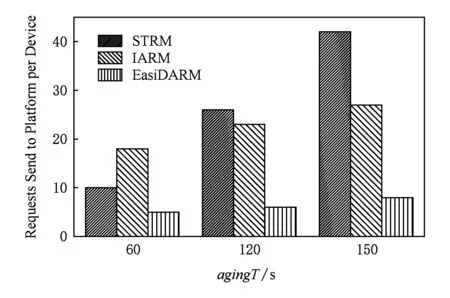
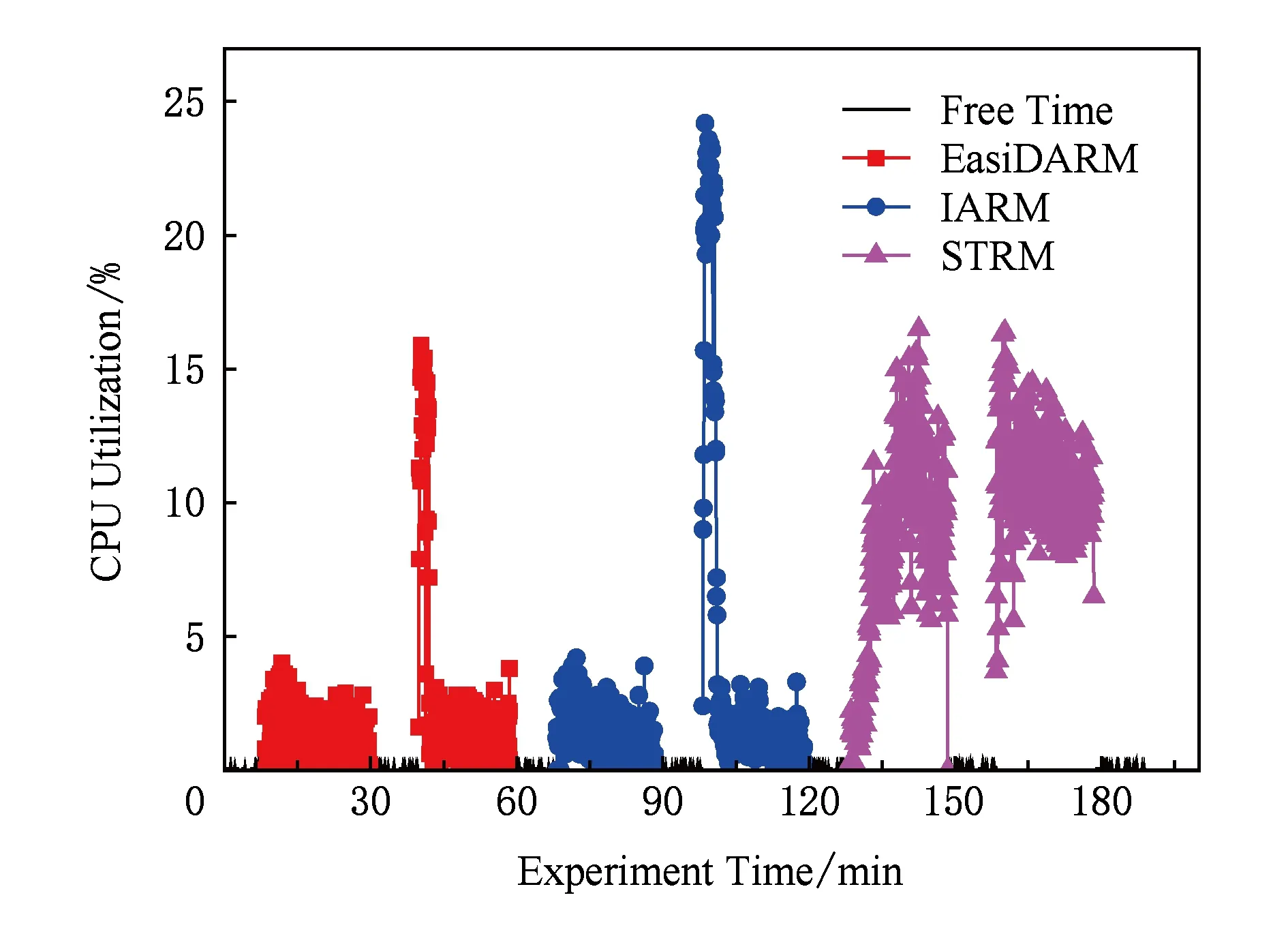
当agingT (4) (5) (6) 在“快更新”执行过程中,每个设备有1次ISAPM,因此映射请求总数ISAPM_num=m;每次探测有1次TSAPM,因此映射测试请求总数TSAPM_num=test_num. 图2是m=3,lowerT=2,agingT=59,upperT=70时,“快更新”机制的一个执行过程.使用“快更新”机制进行探测任务分配所得的任务矩阵t为 Fig. 2 Example of FU stage图2 “快更新”机制执行实例 设备D1,D2,D3第1轮探测的探测值分别为t1,1=4,t1,2=8,t1,3=16,D1对t1,1的探测结果为有效,则更新lowerT和T为t1,1,设备D1继续选择探测值t2,1的探测任务执行;同理,当D2,D3完成了对t1,2,t1,3的探测时更新lowerT和T,选择相应的探测值t2,2,t2,3;当D1完成了对t2,1的探测时,已无探测任务可分配给D1;当D2完成了对t2,2的探测时,由于探测结果为失效,因此提前结束D3对t2,3的探测,D3不再发送TSAPM,“快更新”执行结束并更新upperT=t2,2=64,此时T=lowerT=t2,1=32.可以看出test_num,loop_num,register_total,ISAPM_num,TSAPM_num的值分别为5,2,6,3,5,均符合上述分析. 当首次探测到了失效值testT_failed时,分布式周期探测进入了后期,此时T和testT均比较大,1轮探测耗时较长,若探测轮次较多,则分布式周期探测的收敛速度较慢.采用“快收敛”机制,每轮探测尽量缩小探测区间,减少探测轮次,快速的结束探测.第i轮探测开始时的探测区间为(lowerT,upperT),区间宽度testSizei=upperT-lowerT,假设agingT服从(lowerT,upperT)上的均匀分布,设备Dj所探测的时间为ti,j,前后2次探测的时间间隔ΔTi,j=ti,j-ti,(j-1)(其中ti,0=loweT).则本轮探测结束后,收敛的探测区间宽度为testSizei+1,其数学期望为 图3是图2中“快更新”机制执行结束后,“快收敛”机制的1个执行过程.此时探测精度P=1,m=3,T=32,lowerT=32,agingT=59,upperT=64,testSize=32.此时为第3轮探测,使用“快收敛”机制进行探测任务分配,探测值按等差数列规律线性增长,分布在探测区间(lowerT,upperT)内,所得的任务向量为t3=(40,48,56).可以看出,D1,D2,D3对t3,1,t3,2,t3,3的探测结果都为有效,该轮探测结束时,T=56,lowerT=56,upperT=64,testSize=8,探测区间缩小至原来的14,同时该轮探测期间设备注册的次数也较少,仅为1次.同理第4轮、第5轮探测的任务向量分别为t4=(58,60,62)和t5=(59). Fig. 3 Example of FC stage图3 “快收敛”机制执行实例 在第5轮探测开始前,T=58,lowerT=58,upperT=60,testSize=2,lowerT与upperT间仅有1个探测值59,因此任务向量t5仅为1维,仅需给D1分配探测任务,探测值t5,1=59.虽然agingT=59,考虑到网络延迟等因素,D1对t5,1的探测结果应为失效,因此第5轮探测结束后,T=58,lowerT=58,upperT=59,由于testSize=1,达到探测精度P,无需再进行探测,“快收敛”机制执行结束,完成了收敛,且收敛的区间(lowerT,upperT)=(58,59),agingT的探测值agingT′=58. 本文设计并实现了一套物联网设备管理框架,集成了本文所提出的EasiDARM.本节首先介绍该框架的系统架构,然后介绍设备注册部分的具体实现,最后再介绍分布式自适应的具体实现. 系统架构如图4所示,由物联网云平台、物联网设备和客户端组成,包含用户管理模块、设备管理模块、设备访问模块,而分布式自适应模块和设备注册模块共同构成了EasiDARM(灰色部分).系统采用CoAP协议作为平台和设备的通信协议,平台运行CSoP(CoAP server on platform),设备运行CSoD(CoAP server on device). Fig. 4 Architecture of IoT devices management system图4 物联网设备管理系统架构图 用户管理模块主要用于处理用户的注册、登录、注销等.设备管理模块用于用户管理其所拥有的设备,当用户购买了新设备,需在客户端中添加该设备(以序列号serialNumber作为设备身份信息),平台收到添加请求后再将设备与用户绑定;当用户不再使用某设备时,可在客户端将该设备删除,平台收到删除请求则将设备与用户解绑;用户还可以查看设备信息,平台从数据库中获取设备信息并返回给客户端. 设备访问模块中,平台为客户端访问设备提供API,客户端调用API发送访问请求给平台,平台经过API解析获取请求的内容,再从数据库中获取设备的注册信息,通过请求封装将请求内容、设备的IP地址和端口号封装成能访问具体的设备资源的资源请求.设备资源收到资源请求时,经过解析后根据解析的结果调用设备的相应的功能,并将调用结果封装成资源响应,通过资源返回给平台.平台解析出资源响应的内容,通过API封装之后作为API调用的结果返回给客户端,客户端再以适当的方式展示给用户. 设备的注册模块以周期T生成注册请求并发送到云平台,设备的注册信息(rInfo)分为2类:1)静态注册信息(sInfo),包括设备标识(id)、设备名称(deviceName)、设备序列号(serialNumber)、设备描述信息(description);2)动态注册信息(dInfo),包括IP地址(ip)、端口号(port)、注册时间(time)、注册周期(T).设备注册时sInfo和T显式指定,装成json串携带在注册请求的数据部分(payload字段).而ip,port,time则通过注册请求解析动态获取:从注册请求的IP数据报的首部获取ip,从UDP数据报的首部获取port,平台收到注册请求的当前时间为time.注册验证主要是对ip和port做验证,看是否与该设备之前的注册请求的相同,若不同则说明设备的网络情况发生变化,设备需要重新进行自适应.经过注册验证后将设备注册信息更新到数据库.在设备注册过程中,设备通过分布式自适应模块动态调整注册周期,并最终获取网络的失效周期作为最优的注册周期. Fig. 5 Example of device register图5 设备注册示意图 周期注册采用PUT请求实现,注册请求指定id字段作为设备的身份信息,其他字段仅在需要更新时包含.平台收到该注册请求时,首先进行注册验证,将ip,port与registerMap保存的ip,port作比较,若比较结果为不同,则设置Code为UNAUTHORIZED,并在registerMap中更新ip,port,time;然后将其他需要更新的字段(如第2次周期注册中“T:60”)更新到registerMap或数据库中,若更新成功(且注册验证为相同)则设置Code为CHANGE. 其他注册成功的情况Code设置为CONTINUE.最后将注册验证结果和更新结果携带在注册响应中.设备收到注册响应后,若Code为UNAUTHORIZED,即注册验证结果为ip或port发生改变,比如图例中网关重启(reboot)引起port发生改变,说明设备的网络环境发生改变或者网络过期,需要重新启动分布式自适应;若Code为CHANGE,即需要更新的字段更新成功,则之后的注册请求不再携带更新字段;若Code为CONTINUE,则在下次注册周期到来时再进行相同的注册;若Code为其他失败信息,则根据失败的原因做相应的处理. 分布式自适应过程AS(adaption stage)分为未开始(not start, NS)、快更新(fast update, FU)、快收敛(fast converge, FC)和已完成(complete, CP)4个阶段,其中FU和FC阶段需进行分布式周期探测.最小注册周期minT为30 s,最大注册周期maxT为3 600 s.因此,当AS=FU时,探测任务的探测值向量t为 t=(60,120,240,480,960,1920,3600). AS=FU时最多7个设备同时进行探测即可,t将AS=FC时的探测区间分成7个区间:[30,60),[60,120),[120,240),[240,480),[480,960),[960,1920),[1920,3600). 当失效周期agingT较小时,自适应完成后注册周期较小,由注册带来的开销较大,应尽量提高自适应精度(P),获取最大的注册周期以降低注册开销;当失效周期较大时,自适应完成后注册周期较大,由注册带来的开销较小,自适应精度如果较高,则“快收敛”过程耗费的时间较长,适当的减小自适应精度能大幅缩短探测完成时间,并且不会对注册开销造成明显增加.综上,可以将7个探测区间对应的自适应精度分别取为(1,2,4,8,16,32,64).本方法中定义了维度为8的“自适应精度”数组P,第2~8个元素分别用于“快收敛”阶段的上述7个探测区间,作为相应的自适应精度.其中: P=(1,1,2,4,8,16,32,64). MaxM=(7,7,15,29,29,29,29,26). P和MaxM下标从1开始,其中P和MaxM的第1个元素用于AS=FU阶段;后面的7个元素用于AS=FC阶段的7个不同区间.因此本方法中定义了1个下标变量q用于指示探测过程中所应选取的P和MaxM中的元素.分布式自适应的实现可由算法1表示. 算法1. 分布式自适应算法AdaptTogether(). 输入:minT,maxT,P,MaxM,t;*下标从1开始* 输出:agingT. ①lowerT=minT; ②upperT=maxT; ③q=0; ④m=0; ⑤AS=NS; ⑥s=0; ⑦sn=0;*sn(sequence number)为设备的分布式编号* ⑧requestParams(); ⑨ ifAS=NS或AS=FU then ⑩fastUpdate(); 算法1首先对部分自适应参数(Params)进行初始化,Params包括:lowerT,upperT,q,m,AS,CD(count down),其中CD为“快收敛”阶段的1轮探测中最后1个探测任务执行完成的倒计时时间.然后发送自适应参数同步请求requestParams()与网络中的其他设备进行同步.同步过后,若AS=CP,则快速自适应完毕,返回失效周期agingT=lowerT;若AS为NS或FU,则执行“快更新”算法;若AS=FC,则执行“快收敛”算法. 算法2. 快更新算法fastUpdate(). 输入:Params(自适应参数)、minT,MaxM,t; 输出:Params. ①AS=FU; ②s=MaxM1; ③sn=compete(m,s); ④ ifsn>0 then ⑥ ifq=0 then ⑦q=sn; ⑧ else ⑨q=q+m; ⑩ end if “快收敛”机制的整体过程通过算法3实现.“快收敛”阶段每轮探测开始时均重新进行分布式竞争(sn=compete(m,maxM)),能减少设备移出网络导致本轮的某些探测任务不执行的情况,也能充分利用新加入网络的设备参与本轮探测,执行探测任务.maxM为1轮探测所需的最多设备数,由upperT,lowerT,Pq,MaxMq确定,通过分布式竞争,每轮探测选取出m个设备参与探测,m不超过maxM. 算法3. 快收敛算法fastConverge(). 输入:Params,P,MaxM; 输出:Params. ①AS=FC; ②sleep(CD); ③ while (upperT-lowerT)>Pdo ④maxM=(upperT-lowerT-1)Pq; ⑤maxM=min(maxM,MaxMq); ⑥sn=compete(m,maxM); ⑦testT=lowerT; ⑨ ΔT=max(ΔT,Pq); ⑩s=(upperT-lowerT-1)ΔT; 设备进入“快收敛”阶段,通过sleep(CD)等待本轮探测执行完成再开始下一轮探测.ΔT为相邻探测任务间的时间增量(公差),s为探测区间所划分的探测任务数,即有s个设备实际参与此轮探测.每轮探测开始前,每个设备均需建立倒计时CD,当倒计时结束或者有探测任务的探测结果为失效时,本轮探测结束.当探测结果为未失效时更新lowerT和注册周期并进行自适应参数同步;当探测结果为失效时,更新upperT并将倒计时CD置为0,然后通过自适应参数同步提前结束其他设备的探测任务,结束本轮探测,进入到下一轮探测. Fig. 6 Example of measurement图6 探测任务执行实例 设备Dj根据分布式周期探测任务分配机制(“快更新”阶段,执行算法2)决策出要执行的探测任务,探测值为testT(图6中图例为60 s),Dj需对testT进行探测,首先应为自适应端口建立映射(ISAPM),即通过自适应端口发送映射请求(采用GET实现)给平台,使上层网络建立对设备的自适应端口的映射,图例中为9084,平台将映射端口9084响应给设备.经过testT后,设备通过注册端口向平台发送映射测试请求(TSAPM,采用PUT实现),映射测试请求需携带映射端口9084,平台将映射测试请求转发给映射端口,并收到了响应,说明映射端口是有效的,将映射测试结果响应给设备,设备收到Code为VALID的映射测试响应则更新自适应参数lowerT并将自适应参数同步,同时更新注册周期T;设备再次决策出要执行的探测任务及增大了的探测值testT(图6中图例为120 s),Dj继续对新的testT进行探测.在等待120 s后,设备再次对映射端口9084进行映射测试,由于失效周期小于120 s,映射端口已经失效,平台无法收到对转发的映射测试请求的响应,因此发送Code为NOT_FOUND的映射测试响应给设备,设备收到响应后更新自适应参数upperT并将自适应参数同步;然后再继续上述过程,直至自适应过程结束;设备第3次决策(“快收敛”阶段,执行算法3)出要执行的探测任务及减小了的testT(图6中图例为100 s),Dj重新发送映射请求为自适应端口建立映射(ISAPM),继续对新的testT进行映射测试,重复上述步骤直至自适应过程结束.通过对多个探测值进行探测,确定每个探测值与失效周期的大小关系,可以收敛出失效周期,实现对其的探测. Fig. 7 Implement of experiment to compare register methods图7 注册方法对比实验示意图 本文通过实验和分析比较了3种不同的设备注册方法在不同的情况下的性能与开销,3种注册方法为:1)STRM,注册周期为30 s;2)EasiDARM;3)IARM,其中探测值在周期探测的开始阶段以指数为2的方式增长,当首次探测到了失效值testT_failed时,探测值为探测上限与探测下限的中值,直至达到自适应精度(与EasiDARM相同).图7是实验的示意图,实验基于Californium CoAP框架实现了CSoP平台,运行在阿里云服务器上.基于Erbium CoAP框架在Contiki嵌入式操作系统上实现了CSoD,运行在CC2538开发板上,边界路由采用的是开源项目6LBR,运行在ENC28J60+CC2538上,同时也基于Californium实现了运行在手机上和PC上的CSoD.本文还分别采用上述3种注册方法进行仿真实验来比较3种注册方法的突发性开销. 通过对多个实际网络进行实验,探测出它们的失效周期,其结果如表1所示: Table 1 The Aging-Time of Several Networks表1 多个网络的失效周期的实测值 鉴于该实验结果,本文在失效周期为60 s,120 s,150 s的网络下进行实验和分析来比较3种注册方法的性能与开销.对于STRM和IARM,由于设备单独进行设备注册,其运行模式相对固定,通过计算得出其理论最优值(无丢包、网络延迟等)作为其性能与开销的参考值;而EasiDARM的性能与开销是通过在上述3种网络中运行不同数目的采用EasiDARM进行设备注册的CSoD设备,并记录了每个设备的每个请求和广播,由实际的请求和广播情况来反映. Fig. 8 Time of measurement图8 周期探测耗时 周期探测时间开销对比:图8中虚线为IARM完成周期探测的理论最优的时间;实线为不同EasiDARM设备数完成周期探测所消耗的时间.结果表明,当网络中只有1个EasiDARM设备时,其探测耗时要稍微多于IARM的最优值,这是因为单个EasiDARM设备也会有进行分布式的时间开销,另一原因是实际网络中有网络延迟等因素;而当网络中有多个EasiDARM设备时,其耗时要少于IARM,且随着EasiDARM设备数的增多,耗时有明显下降趋势.当设备数为64时,EasiDARM的周期探测耗时较IARM减少46%. Fig. 9 Consumption on devices of measurement图9 周期探测设备端开销 周期探测设备端开销对比:假定设备发送每个请求所带来的物端开销相同,实验取单个EasiDARM设备完成周期探测的耗时作为对比时长,比较了IARM和EasiDARM进行周期探测的设备端开销.图9中虚线为IARM在对比时长内发送的请求数(包括注册请求、映射建立请求ISAPM、映射测试请求TSAPM)的理论最优值;实线为不同EasiDARM设备数在对比时长内平均每个设备所发送的请求数(包括注册请求、映射建立请求ISAPM、映射测试请求TSAPM、竞争广播、自适应参数同步请求、自适应参数同步广播).结果显示,当设备数较少时,EasiDARM进行探测的设备端开销要多于IARM,因为EasiDARM带了额外的竞争开销及参数同步开销;当设备数多于4时,EasiDARM进行探测的设备端开销要少于IARM,且设备越多,EasiDARM的设备端开销越少,当设备数为64时,EasiDARM进行探测时的设备端开销较IARM减少46%. 周期探测云端及网端开销对比:假设设备发送到云端平台的每个请求所带来的云端处理和网端通信开销相同.图10中虚线为IARM在上述对比时长内发送至平台的云端请求数(包括注册请求、ISAPM、TSAPM);实线为不同EasiDARM设备数在对比时长内平均每个设备所发送至平台的云端请求数(包括注册请求、ISAPM、TSAPM).结果显示,当设备数为1时,EasiDARM进行探测平均每个设备带来的云端和网端开销与IARM相近.而当网络中不止1个设备时,EasiDARM进行探测的云端和网端开销要少于IARM,且设备越多,EasiDARM的云端和网端开销越少.当设备数为64时,EasiDARM进行探测时的云端及网端开销较IARM降低53%. Fig. 10 Consumption on platform and Internet of measurement图10 周期探测云端、网端开销 设备动态加入开销对比:物联网设备往往具有动态性,当新设备加入到网络中时,STRM采用30 s进行周期注册,IARM需要重新进行周期探测来完成自适应,EasiDARM可以进行通过自适应参数同步进行快速自适应.图11为3种设备新加入到网络中在上述对比时长内所发送的请求数,图12为所发送至平台的云端请求数,其中STRM和IARM均为理论最优值,而EasiDARM新加入的网络中已有设备完成了自适应.结果表明,若设备动态性较高,当失效周期较小时,IARM的物端、网端、云端开销较STRM要高;而EasiDARM在不同的失效周期下的物端、网端、云端开销均要少于STRM和IARM.当设备动态性较高时,EasiDARM的设备端开销为IARM的37%,网端和云端开销为IARM的28%. Fig. 11 Consumption on devices when adding device to the network图11 设备动态加入物端开销 Fig. 12 Consumption on platform and Internet when adding device to the network图12 设备动态加入云端、网端开销 本文比较了在设备数较多的情况下,采用3种注册方法的平台突发性开销,包括CPU占用率和平台的网络访问速率(由于受Java内存管理机制和垃圾回收机制的影响,内存使用量无法反映本平台的实际运行情况).实验在NAT失效时间为120 s的网络中进行,以64个仿真设备为1组模拟1个网络,共80组,仿真设备总数为5 120个,运行在PC机上.图13为实验过程中CSoP平台的CPU占用情况,图14为服务器的网络访问速率.在第1 h内,采用EasiDARM仿真设备进行实验:先让平台稳定运行10 min,再在10~15 min期间逐渐运行5 120个仿真设备,在30 min时切断PC机的网络(模拟小区停电后恢复供电或平台故障重启等突发事件),等待10 min后恢复PC机的网络,在60 min时停止运行所有仿真设备;在第2,3 h内分别采用IARM,STRM仿真设备进行实验,实验步骤与EasiDARM相同. Fig. 13 CPU Utilization of platform图13 平台CPU占用情况 Fig. 14 Net speed of platform图14 平台网络访问情况 实验结果表明:正常情况下,EasiDARM和IARM的云端、网端开销要要远少于STRM,且EasiDARM要少于IARM;当发生突发事件,大量设备恢复注册时,STRM没有明显的突发性开销,而IARM有大量突发性开销,且远多于STRM的开销(多出部分由设备自适应引起),而EasiDARM虽然也有突发性开销,但远少于IARM,仅稍多于STRM的开销(多出部分由分布式自适应引起).经计算,较于IARM,EasiDARM能降低云平台的突发性开销达到36%. 未来物联网将具有海量设备,Internet及物联网云平台将面临巨大的注册开销,本文提出了一种基于分布式自适应的物联网设备注册方法来加快注册周期自适应过程并减少注册开销.考虑到物联网设备存在资源受限和网络带宽受限的特点,本文采用“自适应精度”和“竞争限制”对分布式周期探测进行优化,进一步降低开销和避免广播风暴.实验结果表明,较于现有的方法,本方法能大幅减少周期探测耗时,降低周期探测时的物端、网端和云端开销,当设备动态性较高时的开销也明显减少,并且能大幅降低平台的突发性开销.经理论论证及实验评估得出:本方法能更好地应对具有海量设备的未来物联网场景.
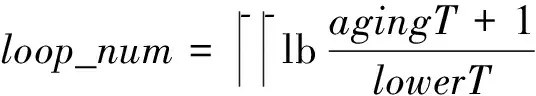
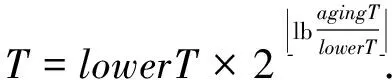
2.2 “快收敛”机制
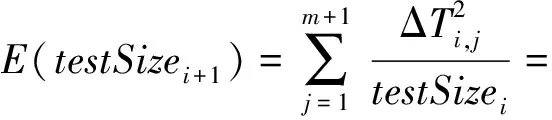
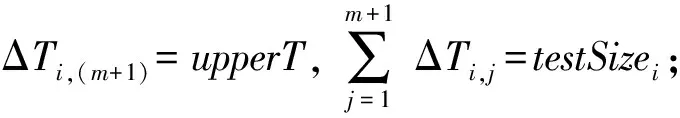

3 物联网设备管理框架
3.1 系统架构

3.2 设备注册

3.3 分布式自适应




4 实 验
4.1 开销分析对比




4.2 突发性开销分析对比

5 总 结
