基于网络节点聚类的目标IP城市级定位方法
2019-03-22李明月罗向阳柴理想袁福祥
李明月 罗向阳 柴理想 袁福祥 甘 勇
1(中国人民解放军战略支援部队信息工程大学 郑州 450001)2(数学工程与先进计算国家重点实验室(中国人民解放军战略支援部队信息工程大学) 郑州 450001)3(郑州轻工业大学计算机与通信工程学院 郑州 450001) (lmypretty@163.com)
IP定位的目的是确定目标IP在某个粒度上的地理位置.定位结果往往包括目标IP对应的用户或设备所在的国家名、地区名、经纬度和时区等[1].IP定位技术能为用户提供IP地址的地理位置,作为提供位置服务的基础,具有相当广泛的应用前景和市场需求[2],例如商业公司可以利用IP定位推广定向商业广告[3-6];移动APP可以为用户提供基于位置的服务(location based service, LBS),谷歌、高德地图导航、大众点评等[7-9]利用IP定位可向指定区域的用户推送用户所在地的天气预报、新闻和定向广告等;IP定位也可为区域版权保护提供支持,例如为电视节目与数字音像等提供区域限制(只在法律允许的网络区域内复制、传播和下载);IP定位还可为网络治理与国家反恐维稳提供技术支持,如实施区域性网络管控、识别垃圾邮件、发现与改善网络节点性能、判定网络欺诈及追踪网络攻击源头、定位网络敏感目标等.因此,开展IP定位技术研究具有重要意义.
现有IP定位方法主要分为2类:基于数据库查询的定位方法和基于网络测量的定位方法.
基于数据库查询的IP定位方法是目前常用的定位方法,主要通过查询数据库来获取目标IP地理位置信息,这种方法的特点是简单快捷.主流的IP数据库有IP138[10],QQWry[11],IPcn[12],IP2Location[13],MaxMind[14],Whois[15]等.其中,IP2location声称其在半径50 km范围内的定位准确率平均为77%[16].现有文献对上述部分数据库研究后发现,对于实际的互联网目标,单个数据库声明的定位准确度并不可靠,不同数据库中的IP城市级位置信息存在较大偏差,最大可达800 km[17].因此,现有方法往往将2个以上数据库查询一致的结果视为目标IP的地理位置.基于网络测量的IP定位方法是当前研究的主要方向,其主要思想是通过测量网络时延或拓扑信息来估计目标IP的地理位置,因此主要包括基于网络时延测量和基于网络拓扑信息等方法.基于网络时延测量的IP定位经典方法有CBG(constraint-based geolocation)[18],SLG(street-level geolocation)[19],Octant[20],其中Gueye等人[18]提出的CBG方法是用3个以上的探测源同时探测一个目标,依据探测源位置及探测时延信息确定可能的地理区域,该方法能够定位目标IP所在的大致区域或城市.这类城市级定位方法是进行更高精度定位方法的前提.Octant是在CBG基础上进行的改进,但是需要大量的地标作为辅助.Wang等人[19]提出的SLG方法的主要思想是基于相对时延越短对应的距离越近的规律,找到与探测源到目标IP的相对时延最近的地标,将该地标的位置作为目标IP的地理位置估计.上述方法尽管具有一定的定位能力,但都容易受探测源部署和测量时延误差的影响.
Tian等人[21]首次将基于数据库查询和网络测量的2类IP定位方法结合,针对查询IP数据库返回错误或空信息的问题,创造性地提出了一种基于网络拓扑启发式聚类的IP定位方法(HC-Based).该方法对现有IP位置数据库,利用Traceroute探测得到多条拓扑路径并构建网络拓扑图,分析网络拓扑中骨干网、非骨干网以及它们之间的通连关系,采用启发式聚类方法对IP节点进行聚类,得到不同的集群,根据同一集群内部的IP节点地理位置往往相同的特点,确定目标IP所属集群,最终根据集群的地理位置确定目标IP的地理位置.然而,该方法得到的集群往往节点数太少,且采用的简单投票规则可能会因为用于投票的相邻节点在IP位置数据库中查询的地理位置存在错误,导致基于投票结果的定位出现错误.
针对HC-Based定位方法存在的上述不足,本文提出一种基于网络节点聚类的IP定位方法(network node clustering based IP geolocation,NNC).将网络拓扑视为一种典型的复杂网络结构,将HC-Based定位方法中的集群与复杂网络理论中的社区对应起来,采用模块度衡量社区结构的强度,利用Louvain社区发现算法对网络拓扑中的节点进行聚类,将网络拓扑划分为不同的社区,最终利用投票确定社区及目标IP的地理位置.与经典的基于网络测量的IP定位方法相比,本文提出的NNC定位方法不再简单地依赖单个时延或相对时延和网络路径,而是利用网络拓扑的结构特性,将目标IP定位与网络拓扑中的网络社区有机结合起来,基于对网络社区的分析实现对目标IP的定位,从而克服了传统基于网络测量的定位方法对探测路径的依赖.而且,与HC-Based定位方法相比,NNC方法避免使用人工划分得到的小集群和简单投票规则,采用社区投票方法,可有效容忍地标数据的地理位置错误对定位结果精度的影响,从而显著提高了定位准确性.
1 HC-Based定位方法原理简介及分析
针对基于数据库查询结果不可靠的不足,Tian等人[21]提出了一种基于启发式聚类的定位方法(HC-Based定位方法),将网络测量与数据库查询相结合,在网络拓扑基础上,对网络节点进行启发式聚类,获得多个社区,对社区利用数据库查询方法进行定位,为网络IP定位提供了一种新的途径.HC-Based定位方法主要包括5个步骤:预处理、单集群识别、非骨干网节点聚类、骨干网节点聚类和集群合并.其中,预处理过程需要去除一些探测路径中的匿名路由器,为排除探测源对路径的干扰去掉探测源到骨干网之间的路径,并利用IP地址数据库标识骨干网节点与非骨干网节点;单集群识别从网络拓扑的边缘节点开始,依据特定规则找出符合构成单集群条件的节点或节点对;非骨干网聚类从单集群出发,利用邻居投票规则逐步对其他节点进行合并,到骨干网节点停止;骨干网聚类在骨干网节点中进行,方法与非骨干网聚类一致;集群合并对网络拓扑中的所有集群进行统一处理,设定最小集群节点个数阈值,将较小的集群向周围的大集群合并.最终,得到网络拓扑中的所有集群划分的结果.方法的主要流程如图1所示,图1①到②找出单集群,其中,红色节点是单集群;图1②到③是非骨干网聚类过程;图1③到④是骨干网聚类过程;图1④到⑤是聚类后各个集群进行合并.依照上述步骤最终聚类成多个集群.
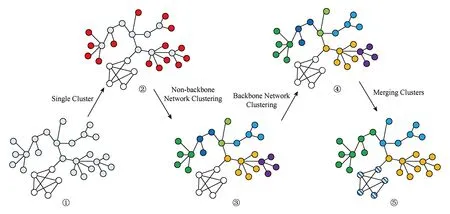
Fig. 1 Steps and processes of the HC-Based图1 HC-Based定位方法的步骤与流程
相比单一的数据库查询或基于网络测量的IP定位方法,HC-Based定位方法将两者结合,通过网络拓扑聚类得到集群,将IP定位问题转换为对IP节点聚类到特定集群的问题,并采用投票方法确定目标IP的地理位置.该方法既解决了IP地址数据库中有部分错误数据的问题,又在一定程度上解决了此前网络测量方法中对探测源和地标的过度依赖问题.
但是,该方法也存在2点不足:
1) 依赖简单投票规则时容易导致错误
HC-Based定位方法在寻找单集群的过程中将网络拓扑中到其他节点没有连接的节点作为一个单集群或者将任意2个节点之间形成回路并且到其他节点没有连接的2个节点分别作为单集群.尽管利用这2个简单的规则,能够较好地解决网络拓扑边缘单集群发现的问题,但是在非骨干网聚类与骨干网聚类的过程中,由于处理的节点之间结构较为复杂,简单的投票规则不能覆盖所有情况,如果集群中一些节点通过查询IP位置数据库得到的位置有误,可能导致基于投票得到的其他节点的位置出现错误.如图2中①到②所示,若节点2,3,4属于同一个集群,利用节点2,3,4的地理位置投票决定节点1所处地理位置.若节点2,3,4能够在IP地址数据库查询到城市级信息,则利用该信息投票确定节点1所属地理位置;否则,使用集群信息对节点1进行投票.若节点2,3,4,5中超过一半的节点认为节点1属于A集群,即投票比例超过0.5,则认为节点1属于A集群.若节点2,3,4位置信息正确将得到正确的集群化分,反之可能出现投票结果错误,如图2中③到④所示,若节点2,3,4信息错误,投票所得的节点1位置很可能出错.
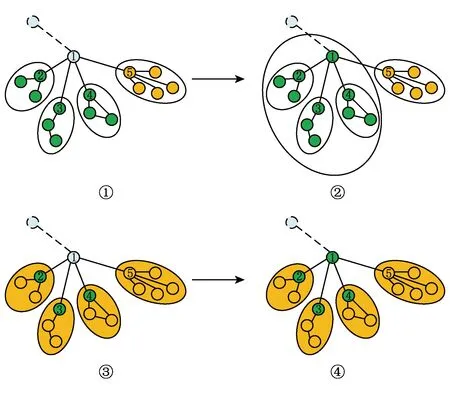
Fig. 2 Voting error problem of the HC-Based图2 HC-Based定位方法投票出错问题
2) 集群合并的阈值设定缺乏依据
HC-Based定位方法在非骨干网聚类和集群合并过程中,简单地将节点数小于阈值的集群合并到与其相连的大集群中,默认的阈值为5,但遗憾的是文献[21]并没有说明阈值设定为5的依据.
从实际情况看,一些集群节点数量大于5的集群也符合合并的条件,但受阈值设定的影响,最终导致网络拓扑中存在大量小集群,而小集群中任意一个节点的位置发生变化或出现错误将会对该集群所处位置产生较大影响,因此大量小集群的产生会影响定位的最终结果.
如图3所示,红色节点和浅蓝色节点表示不同的2个地理位置,节点6是与骨干网相连的第1个路由器,作为标识路由器[22](该路由器代表一个城市的网络入口),因此与节点6相连的节点理论上处于同一集群,假设基于节点2,3,4对节点1投票,则通过投票得到的节点1的位置将会与节点2,3,4一致,由于节点2,3,4的位置与节点6不同,所以通过投票得到的节点1的位置会与节点6不一致,从而出现错误,这种错误在集群合并阶段不能有效解决,因为若节点1与其周围若干个节点构成的集群大小为5或者大于5,启发示聚类方法并不会将该集群与其他集群进行合并,从而使得节点1与节点6处于不同集群.

Fig. 3 Cluster consolidation problem of the HC-Based图3 HC-Based定位方法集群合并问题
3) 需要多次循环遍历网络拓扑
HC-Based定位方法从寻找单集群开始,每一步都需要多次循环遍历整个目标网络拓扑.原因在于该方法依赖人工设定参数和规则,而基于规则的方法需要逐个节点判断执行,难以进行高效的优化处理,从而导致HC-Based定位方法整体效率较低.
2 网络拓扑中社区与城域网的关系分析
钱学森先生指出:具有自组织、自相似、吸引子、小世界、无标度中部分或全部性质的网络称为复杂网络[23].现实世界的网络大部分都不是随机网络,少数的节点往往拥有大量的连接,而大部分节点却拥有很少连接,节点的度数分布符合幂律分布,而这种特点被称为网络的无标度特性(scale-free),研究者将度分布符合幂律分布的复杂网络称为无标度网络.对于分层结构的网络拓扑,骨干网结点的度非常高,非骨干网节点的度较低.骨干网节点主要分布在若干个大城市,数量较少,其他非骨干网节点数量多,符合复杂网络中的无标度特性.骨干网与城市、城市与城市之间的网络拓扑呈现高度的集群化特征[23].网络拓扑的集群化特征可理解为网络拓扑具有社区特性.
2.1 城域网结构与地理位置特性
考虑到网络拓扑结构具有的社区特性,本文提出一种假设:社区与所处城市可能存在相关性,并且属于同一社区的节点往往位于同一个城市.若这个假设成立,则可基于该假设进行基于社区位置的目标IP定位.
事实上,在实际网络环境中,多级分层架构的网络运营商网络通常包括省(或州)际和省内骨干网络,省内又包含许多城域网等,这种结构将运营商网络划分成等级不同的区域网络如省网、城域网等.骨干网与非骨干网(包括省网和城域网)之间的关系如图4所示:

Fig. 4 The relation between backbone network and non-backbone network图4 骨干网与非骨干网之间的关系
城域网是承载城市与骨干网连接的网络,其作用是为降低同一个城市内部节点之间的网络时延.由于城域网的存在,实际网络的拓扑结构除满足复杂网络中的无标度特性外,还存在着显著的社区结构特性,处于同一社区内部的网络实体之间的连接较为紧密.反过来看,我们可通过分析网络拓扑中的社区结构特性,对目标IP进行定位.定位的基本思路是:对目标IP进行多次探测,将探测得到的拓扑路径集合进行网络社区结构划分,依据社区位置投票的结果实现对目标IP的定位.
2.2 社区与城域网关系分析
本文利用1台主机作为探测源,随机抽取了河南省7个城市内部的3 000个IP作为探测目标,并基于探测得到的网络拓扑图分析社区结构的存在性.图5是河南省内部部分网络节点和部分骨干网节点构成的网络拓扑图.在该网络拓扑中,可通过统计同一城市内部和不同城市之间节点的连接数,更细粒度地分析城域网条件下网络拓扑结构的社区特性.

Fig. 5 Internal network node and some backbone network nodes in Henan province图5 河南省内部网络节点与部分骨干网络节点拓扑图
表1列出了本文随机抽取的河南省7个城市的IP分布情况和该网络拓扑中城市内部与城市之间的连接数.由表1统计结果可以看出,社区结构满足如下特征:属于同一社区的节点之间连接数较多,而属于不同社区的节点之间连接数较少.
从表1中还可以看出,在河南省网络拓扑中,城市内部的连接数占总连接数的比重较高.例如郑州市内部IP节点之间连接数为818,占其总连接数的86%.需要说明的是,表1中去除了骨干网节点与这些城市的连接,原因是骨干网节点的具体位置信息往往不够明确,并且骨干网节点在复杂网络中属于数量较少而度又较高的节点,容易对统计城市之间的连接数量造成较大干扰;与非骨干网节点的通连关系,会对社区划分造成影响,从而影响目标IP定位的准确性.
表1结果表明:在互联网分层架构以及城域网的综合影响下,城市内节点的网络连接数要远高于城市之间节点的连接数,城市与城市之间的社区结构较为明显,从一定程度上证明了网络拓扑中社区结构的存在性.为此,我们可以推断:同一社区内的IP地址位于同一城市的可能性较高.需要指出的是,在同一城市内部的网络拓扑也有可能存在更小的社区结构,这些IP可能分布于政府部门、企业或某个网络中.只是由于本文所抽取的IP数量限制,尚不足以形成更细粒度的小社区结构.
上述探测分析结果表明:城域网与网络拓扑中的社区分布的确有着较强的关联,属于同一社区的节点往往位于同一个城市,这验证了我们2.1节提出的假设.
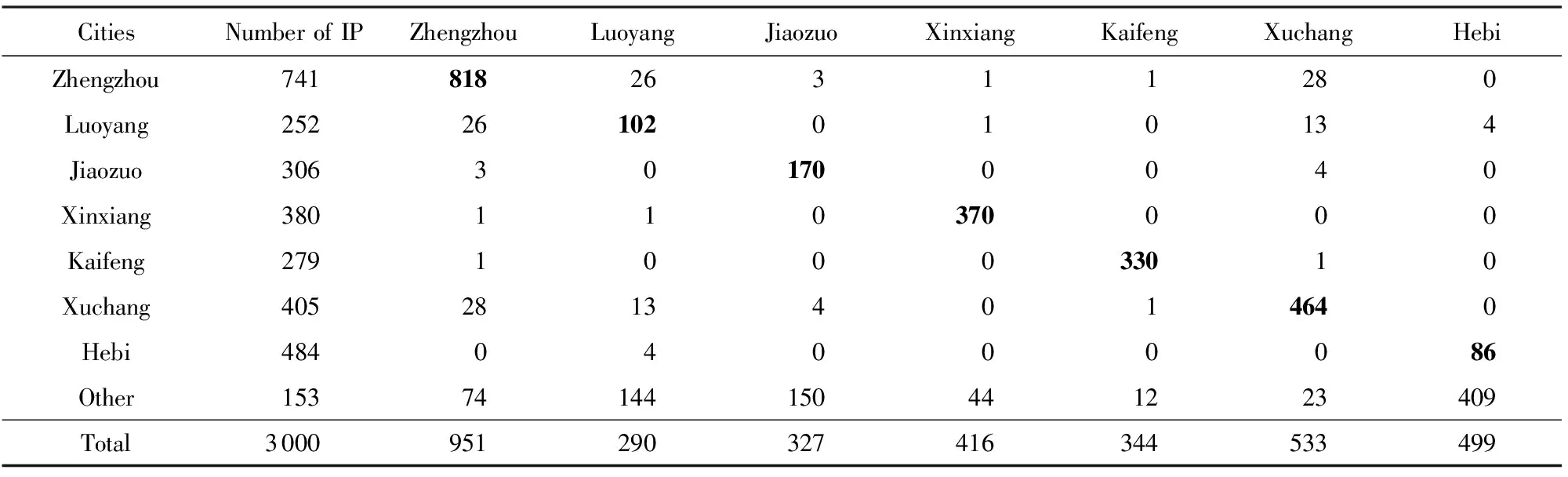
Table 1 The Number of IP Connections Inside the Cities and Between Cities in Henan Province表1 河南省城市内部与城市之间IP连接数统计
Note: The results highlighted in bold denote that IP addresses in the same network community are more likely to be located in the same city.

Fig. 6 Steps of the NNC 图6 步骤流程示意图
网络拓扑本身就是一种典型的复杂网络,而网络拓扑中任意2个节点之间的网络路径也能通过有限的几跳互相连接,符合复杂网络的小世界特性[24],因此,可利用复杂网络理论中的社区发现算法,将全局网络拓扑中具有社区特性的集群按照紧密程度进行聚类,而模块度能够很好地反映一个社区的聚合程度,因此,可基于模块度最优化进行网络社区发现,并在此基础上通过分析社区结构特性对网络拓扑进行研究.
3 NNC定位方法原理及主要步骤
为了改进HC-Based定位方法存在的不足,本文通过分析社区结构特性与网络拓扑的关系,提出一种基于网络节点聚类的IP城市级定位方法(NNC定位方法),其主要思想是利用社区发现算法对网络拓扑社区进行聚类,结合投票机制定位社区所在地理位置,根据所处社区确定目标IP地理位置.定位方法原理框架如图6所示,主要包括预处理、社区发现和社区投票3个阶段,其中预处理阶段包括选定探测源、目标路径、构建网络拓扑图和分离骨干网与非骨干网等;社区发现是核心模块,包含最大化局部模块度和合并超点2个迭代循环的过程;社区投票根据社区发现的结果对目标IP进行投票估计其位置,完成定位.
NNC定位方法的主要步骤如下:
步骤1. 根据探测目标位置分布与特性,从探测源到目标的所有路径中,尽量选择与目标IP路径较长的探测源,充分遍历经过的骨干网与非骨干网信息,得到较为完整的路径信息.
步骤2. 构建网络拓扑.在步骤1获取的完整路径信息中,去除探测源到骨干网之前的路径.不考虑节点权重,将网络拓扑图中所有边的权值赋为1.
步骤3. 分离骨干网与非骨干网.利用IP数据库查询网络拓扑图中所有IP节点的(Internet server provider, ISP)信息,依据ISP信息将网络拓扑初步划分为骨干网与非骨干网,并将两者分离.
步骤4. 社区发现.该步骤包括2个阶段,最大化模块度和合并超点,这是一个迭代循环的过程.首先,最大化局部模块度.在分离得到的非骨干网上,将所有节点视为独立社区并计算模块度,在此基础上尝试将每个节点向周围社区迁移,使模块度尽可能增大,直至模块度达到局部最优.其次,合并超点.在模块度达到局部最优的网络拓扑上合并超点.最后,判断当前模块度是否为全局最优,若是则进入社区投票阶段,否则返回循环步骤4.
步骤5. 基于投票机制的社区位置定位.根据步骤4得到的社区划分的结果,每个社区内部的节点通过IP地理位置数据库对其城市级地理位置进行查询,根据自身位置对该社区所处位置进行投票,将社区内多数节点一致的位置作为社区的地理位置,通过此次投票更正社区内节点错误的位置信息.
步骤6. 确定目标IP位置.将从探测源到待定位的目标IP的探测路径加入步骤2中构建的网络拓扑中,判断其所属社区并将对应社区的地理位置作为待定IP的地理位置.
在上述步骤中,社区发现和确定目标IP位置是关键,下面分别进行具体阐述.
3.1 网络社区发现
本文在对网络进行社区发现时采用了Blondel等人[25]于2008年提出的Louvain社区发现算法,该算法是一种贪心的基于模块度优化的非重叠社区发现算法.
模块度也称模块化度量值,是目前常用的一种衡量网络社区结构强度的方法,模块度的定义为
(1)
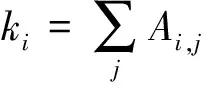
Louvain社区发现算法由最大化模块度和合并超点2个阶段组成,是一个迭代循环的过程.
1) 最大化模块度.在分离得到的非骨干网上,将所有节点视为独立社区并计算模块度.对任意节点,扫描其所有邻接节点,在此基础上尝试将每个节点向周围社区迁移,使模块度尽可能增大,若模块度达到局部最优,则将其加入邻接社区.
2) 合并超点.在模块度达到局部最优的网络拓扑上合并超点.合并超点的基本思路是将原网络拓扑中的社区各自合并为1个节点,进一步寻找深层社区结构特性.具体来说有3条规则:①合并得到的节点的权值不变;②合并后的节点增加1条自连边,边的权值为原社区中所有节点权值之和的2倍;③合并后节点之间边的权值为原2社区之间边权值总和.
3) 判断当前模块度是否为全局最优,若是则进入社区投票阶段,否则返回循环1)和2)这2个阶段.
Louvain社区发现算法中单轮执行过程如图7所示.阶段1以最大化局部模块度为目标,合并社区直到模块度不再增加为止;阶段2将前一阶段所得的每个社区视作1个新的节点,合并成新的社区.
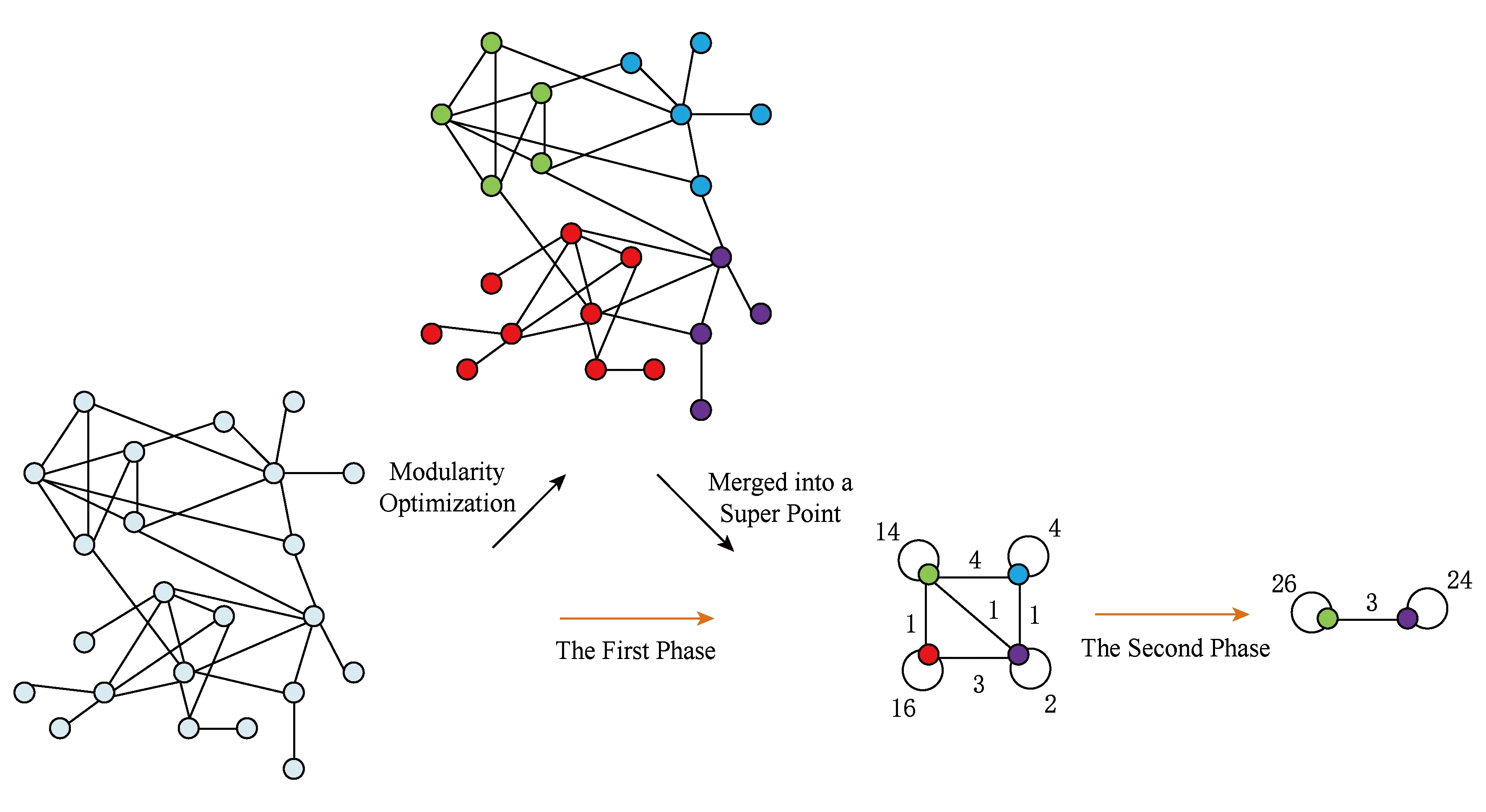
Fig. 7 The single round of the implementation process of the Louvain algorithm图7 Louvain社区发现算法的单轮执行过程
我们采用Louvain算法来进行网络社区发现,有两大好处:1)效率高.表现在通过模块度计算公式能够快速计算模块度的增加值,且在每一轮合并超点时能够大大减小网络的节点数,这使得算法的大部分时间开销集中在第1轮迭代中,而算法的时间复杂度为O(|E|),其中|E|为网络拓扑中的节点个数;2)算法整个执行过程中,社区结构的粒度逐渐增大,可以得到不同层次的社区结构,因而能够发现不同层次的社区.Louvain社区发现算法的不足是:阶段1的输入结果可能跟节点处理的顺序有关,文献[26]指出节点处理的顺序对最终结果模块度的数值影响不大,但会影响到计算的时间开销.
3.2 基于社区位置定位目标IP
社区投票定位建立在社区发现的基础之上,是整个方法的最后一个步骤,用于最终确定目标IP的城市级地理位置.具体来说,利用社区投票对目标IP进行定位包含2种情况:1)目标IP已包含在当前网络拓扑中;2)目标IP不包含在当前网络拓扑中.下面分别对这2种情况进行讨论:
1) 目标IP已包含在当前网络拓扑中
目标IP已包含在当前网络拓扑中,那么在社区发现阶段应该确定了所属社区.利用该社区中所有节点对社区所属位置进行投票,若某城市所得票数的比例超过一半,则认为该社区中所有节点均处于该城市.若无一个城市所得票数超过一半,说明当前网络拓扑中的节点数量过少,不足以形成有城域网特征的社区结构,应当适当增加地标数量和探测次数,直到整个网络拓扑中所有社区均能确定地理位置信息.
得到所有社区的地理位置后,再对目标IP的定位时只需要确定其所属社区,即可完成城市级定位.
2) 目标IP不包含在当前网络拓扑中
目标IP不包含在当前网络拓扑中,为了利用社区信息对该目标进行定位,需要与当前网络拓扑建立关联,可通过增加探测次数,必要时可增加探测源数量,尽可能获得更完整的拓扑路径,保证与当前网络拓扑有重合路径.在该前提下,可不用重新对整个网络拓扑进行社区发现,而采用社区增量的方式确定目标IP及其探测路径上IP所属社区.具体来说,类似Louvain社区发现算法中第1阶段优化模块度的过程,尝试将目标IP及其探测路径上的IP向与之连通的社区迁移并计算模块度增量,然后将目标IP及其探测路径上的IP并入使模块度增量最大的社区.此时目标IP已经增加至当前网络拓扑中,可采用与第1种情况相同的方法确定目标IP的城市级地理位置.
4 NNC定位方法的性能分析
本节将主要对本文提出的基于NNC的城市级IP方法的性能进行分析.
4.1 方法可行性分析
本文方法利用社区发现算法对网络节点进行聚类,将多个网络节点根据计算其模块度,将模块度最优情况下的社区划分结果作为最终的网络节点聚类结果,相比经典的HC-Based算法,该算法利用模块度衡量社区划分的好坏,而不是设定经验值,因此能够得到更为有效的节点聚类结果,从而有效减少了由于社区划分错误导致目标节点的地理位置定位错误.
经典的Louvain算法是一种社区划分算法,该算法根据社区结构特性,利用模块度得到社区的最优划分,本文查询多个IP节点的ISP信息,并利用Louvain算法将这些IP节点划分为多个社区,能够得到最优的社区划分结果,社区的位置可通过社区内多个IP节点的位置确定,当目标IP需要定位时,只需要确定其属于哪个社区即可确定其城市级地理位置.由于该方法利用经典的社区算法能够得到最优的社区划分,从而得到合理的社区地理位置,而目标IP是根据社区位置确定其所在城市级位置,因此,该方法结合社区划分算法将网络节点聚类,从而确定目标IP地理位置从原理上是可行的.
4.2 分离骨干网与非骨干网对定位结果的影响
基于社区发现的网络拓扑聚类算法中,将骨干网与非骨干网分离是重要的一步,尤其在连通性较弱的分层网络环境中.通过分离骨干网和非骨干网络,能够使网络拓扑的社区结构特性更加明显,提高目标IP的定位精度.以河南省内的网络拓扑为例,如图8所示.
图8是分离骨干网与非骨干网之后的网络拓扑结构,图8(a)为骨干网节点,社区结构的非常明显,对目标IP的社区定位更加精准和高效,甚至可用肉眼区分不同的社区.
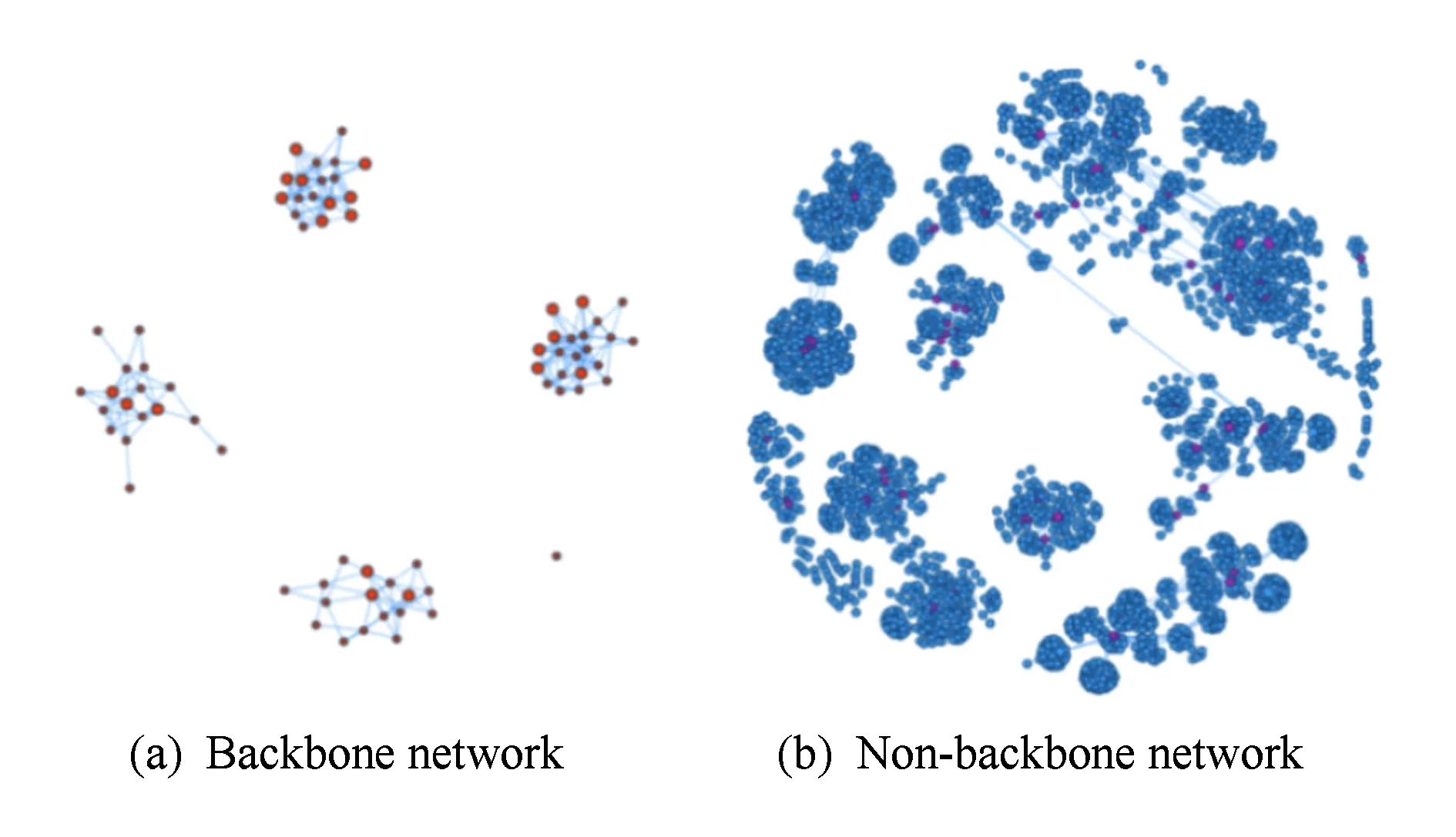
Fig. 8 Separation of backbone and non-backbone network图8 骨干网与非骨干网分离示意图
从复杂网络理论的角度来看,骨干网节点属于少量但却拥有大量连接的节点.对社区发现算法而言,这样的节点往往与多个社区有着很强的关联,容易引入较多初始噪声.因此,本文通过分离骨干网与非骨干网,不仅可以强化骨干网与非骨干网中的社区结构强度,还可以提高社区发现的效率.
4.3 与HC-Based定位方法的原理对比
相比HC-Based定位方法,本文提出NNC定位方法,主要有4点优势:
1) 不依赖固定的规则、通用性较好
HC-Based定位方法提出的规则大多基于作者对网络拓扑结构的直观认识,本质上是一种规则化的方法,缺乏很好的理论支持.在实际应用中,能解决一些问题,而在另一些规则中未定义的或例外场景的条件下,往往不能发挥作用.若要适应这些例外场景,必须人工额外定义新规则,添加进规则库才能保证算法正确运行.而本文提出的NNC定位方法,通过引入社区模块度的概念并以此作为评价社区结构强度的标准,不依赖固定的规则,实质是将复杂网络理论作为理论基础,有着较好的通用性.
2) 有明确的社区结构强度衡量标准、不需要设置阈值
HC-Based定位方法中将若干有一定通连关系的节点构成的集合称为集群(cluster),与社区发现中的社区有一定相似性,但由于采用的是规则化的划分方法,因此缺少一个科学的衡量社区结构强度的标准.例如HC-Based定位方法中集群最小节点个数设定为5,但并未给出一个合理的解释,而基于社区发现的网络拓扑聚类定位算法使用模块度衡量社区结构强度.模块度的定义是在概率论基础上通过随机图中节点的度以及它们之间的连接关系推导而来,既符合人们的直观理解,又有严密的数学推导.因此,使用模块度衡量社区结构强度更加科学合理.
3) NNC定位方法对地标准确性要求低、具有很好的容错性
在传统的IP定位方法中,对目标IP进行测量往往离不开准确的地标信息作为辅助.因此,地标挖掘在IP定位中是非常重要的一个步骤,地标的可靠性直接决定着IP定位的准确度.从现有研究来看,最可靠的地标挖掘方式是实地勘察,但是其成本和代价较为高昂,而通过其他方式(如基于网络数据挖掘获取地标)又难以保证获取到的地标具有高可靠性.本文提出的NNC定位方法不依赖于准确的地标数据,而是利用位置查询结果可靠性较为一般的IP地址数据库,在社区划分的基础之上利用社区投票估计目标IP的地理位置.这样做的依据是:IP地理位置数据库中的大多数IP,其城市级地理位置信息是准确的,只要大部分IP的城市级位置信息是准确的,即可保证最后的社区投票结果是可信的.而现有研究[16]指出IP地理位置数据库其城市级信息准确率大约为77%,因此该算法的大部分投票结果是可信的.
4) NNC方法采用了层次化的社区发现算法、遍历次数大大降低、时间复杂度较低
文献[21]中所提出的HC-Based定位方法需要反复循环遍历网络拓扑图,时间复杂度较高.本文提出的NNC定位方法采用Louvain算法进行网络节点聚类,Louvain算法作为一种层次化的社区聚类算法,通过合并超点将社区发现的过程逐步简化,每次合并超点之后,下一轮迭代的效率均有大幅提升.已有分析表明,Louvain算法的时间复杂度接近O(nlogn),其中,n为节点个数[25].因此,与现有HC-Based定位方法相比,本文采用Louvain算法,能有效提高网络节点聚类的效率.
5 实验结果与分析
为了验证本文提出的NNC定位方法的性能,我们在实际互联网环境下,进行了大量目标IP定位实验.
5.1 实验设置
1) 实验数据
为测试验证本文方法的有效性,利用阿里云内部的1台主机作为探测源,选取了河南省内7个城市、山东省内6个城市、广东省6个城市、浙江省6个城市和陕西省内6个城市的IP作为探测目标,从每个省份内随机抽取3 000个IP,共计15 000个待探测目标IP.实验部分IP地址数据是从2015年12月20日纯真IP地址数据库[11]发布的数据中抽取的,该数据库给出了IP地址的城市级位置信息和运营商信息,实验中用的数据库包括纯真数据库、IPcn,IP138.
2) 评价标准
本文选择了2种评价指标对算法的效果进行评估:1)模块度.模块度是复杂网络领域中一个经典的评价指标,可用于衡量网络拓扑中社区结构的强度,反映算法对网络拓扑中复杂关系的解析能力.模块度的计算方法如式(1).2)准确率、召回率和F1值(准确率和召回率的调和平均值).该评价指标反映了算法对目标IP的定位能力和对IP地址数据库的纠错能力.对目标IP的定位问题可视为对IP地址数据库的纠错问题,只是在定位完成之后无需与数据库中的地理位置信息进行比对.在计算准确率和召回率时,需要先统计真阳、假阳等值.
实验通过上述聚类算法得到的L个IP地址的地理位置与通过查询纯真数据库得到的IP地址的地理位置作比较,若比较结果不一致则认为IP地址修改,修改的IP地址个数为A;与IPcn和IP138查询结果一致的IP有TP(true positive)个;与IPcn和IP138查询结果不一致的IP有FP(false positive)个,FP=A-TP.
若比较结果一致则认为IP地址未修改,未修改的IP地址个数为B;未修改的数据B(B=L-A)中,与IPcn和IP138数据库查询结果一致的IP有TN(true negative)个;与IPcn和IP138查询结果不一致的IP有FN(false negative)个,FN=B-TN.
在统计得到上述4个值后,设准确率(accuracy ratio)为P,召回率(recall ratio)为R,则准确率为
P=TP(TP+FP),
(2)
召回率为
R=TP(TP+FN),
(3)
则有:
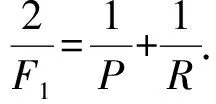
(4)
5.2 定位结果实验
本节将对本文提出的NNC定位方法与现有的HC-Based定位方法[21]进行比较.HC-Based定位方法通过人工定义规则对目标网络拓扑进行聚类,采用启发式聚类的方式确定目标IP所属集群(即社区),根据集群特性估计目标IP的城市级地理位置.在实现HC-Based定位方法时,采用其默认的参数设定:邻居投票阈值为0.5,集群内最小IP数量为5.在上文所述的数据集和参数的设定条件下,对HC-Based定位方法和本文方法聚类划分的社区结构模块度进行实验,基于河南省、山东省、和陕西省9 000个网络节点的结果如表2所示:

Table 2 Comparison of the Proposed Method withHC-Based Method

Fig. 9 Cluster result display图9 聚类结果展示图
从表2可以看出,本文方法对网络拓扑聚类划分得到的社区结构模块度均在0.9左右,具有较高的社区结构强度.而使用HC-Based定位方法得到的社区结构模块度均在0.7以下,社区结构强度较弱,这主要是因为在HC-Based定位方法中,存在大量分散的小集群.相比而言,本文方法以模块度为优化社区结构的指标,不需要指定社区内最小IP数量,而是通过算法自适应调整社区大小,因此得到的社区结构更加科学合理.实验对河南省网络拓扑采用上述2种方法的聚类结果可视化如9所示,图中相同颜色的点处于同一集群.图9(a)是使用HC-Based定位方法对河南省的网络拓扑进行聚类的结果示意图,由图中可以看出共划分了117个集群,小集群较多,模块度较低.图9(b)是使用本文提出的方法对其进行聚类的结果,从图中可以看出共得到56个集群,模块度较高,能更好地展示各个IP节点之间的关系,为下一步定位提供了更加准确的网络结构信息.
5.3 对IP位置数据库的纠错能力实验
本文还针对2种方法对IP位置数据库的纠错能力进行了实验比较.基于NNC定位方法和HC-Based定位对IP位置数据库中的IP进行地理位置定位和修正,分别统计出HC-Based定位方法和本文方法在纠错能力上的准确率、召回率和F1值.结果如表3所示.从表3中可以看出,本文方法在准确率、召回率、和调和值等各项指标上均优于HC-Based定位方法.这表明本文方法能够有效利用划分好的社区信息,从社区内部大量IP地址信息的统计特征估计出目标IP的地理位置,并对异常的位置进行纠正.

Table 3 Accuracy, Recall Ratio and F1 Value of Error Correction for IP Database表3 对IP数据库进行纠错的准确率、召回率和F1值比较
6 结束语
本文从复杂网络理论出发分析了现有HC-Based定位方法中存在的不足,提出了一种基于网络节点聚类的目标IP城市级定位方法.该方法以模块度作为衡量社区结构强度的标准,采用高效Louvain社区发现算法实现对网络拓扑的聚类,得到不同的社区划分,最终利用社区投票确定目标IP的地理位置.实验结果表明:与HC-Based定位方法相比,本文方法划分得到的社区结构在模块度上有较大提升,在对网络拓扑的社区结构划分上更加合理准确;利用该方法对国内常用的IP地址数据库进行纠错,无论是在准确率、召回率或是F1值上,本文方法均高于HC-Based定位方法.
然而,尽管本文获得了较好的定位结果,但仍存在2点不足:1)在构建网络拓扑时仅考虑节点之间的连接关系,未考虑路径时延信息,如能在路径信息的基础上充分利用时延信息,可能能够得到更好的网络节点聚类效果;2)网络拓扑中的社区结构可能存在重叠社区现象[27],重叠社区中的IP节点与2个甚至多个社区均有较多连接关系,因此其地理位置信息归属较为模糊.在下一步研究中,将针对上述问题开展进一步的研究.
