一种基于多核DSP的Turbo译码实现方法
2019-02-15王华华
王华华,马 昶,亢 成
(重庆邮电大学 重庆市移动通信技术重点实验室,重庆 400065)
1 引 言
Turbo码在低信噪比下所表现出的近Shannon限的性能使其在移动通信领域中有着广阔的应用前景[1].由于Turbo码编码方式灵活、译码算法复杂,不适合在传统硬件电路上实现,并且在LTE-A的PDSCH(Physical downlink shared channel,物理下行共享信道)接收端实现模块中,Turbo译码耗时最多.所以本文使用TI公司TMS320C6670多核DSP[2](Digital Signal Processor,数字信号处理器)对Turbo译码进行实现.该型号DSP的应用可以提高无线通信系统在接收端的效率,并且它能适应WCDMA,FDD/TDD LTE-A,Wi-MAX三种标准[3].
2 Turbo译码算法
Turbo译码最常用就是迭代思想,其主要采用的译码算法有MAP(Max-imum A Posteriori,最大后验概率),Log-MAP和降低复杂度的Max-Log-MAP三种[4].
MAP算法是基于码字格图的SISO译码算法,目的是使译码输出比特错误概率最小.译码器的输入序列设为y=yN=(y1,y2…yN),uk的对数似然比[5](logLikelihood ratio)L(uk)定义如下:
(1)
译码结果需按照以下规则判决:
(2)
最优的SISO算法是MAP算法,但它的计算复杂度高,根据贝叶斯与全概率公式,每个信息比特的L(uk)计算式[6]如下:
(3)
为了降低MAP算法运算的复杂度,后来提出了Log-MAP算法,该算法是在对数域中对MAP算法运算,将乘法转换为加法,所以要比实现MAP算法简单,降低了复杂度,适用于硬件实现.Log-MAP算法用定义的式(4)的近似算法来消除对数和指数的运算.
(4)
该方法虽然简化了算法复杂度但也引入了误差,因此不是最优算法.Max-Log-MAP算法消除了Log-MAP算法中雅可比公式的修正函数,可得[7]:
ln(ex+ey) =max(x,y)+ln(1+e-|x-y|)
=max(x,y)+f(|x-y|)
(5)
如果再简化,使f(|x-y|)=0,得出
ln(ex+ey)=max(x,y)
(6)
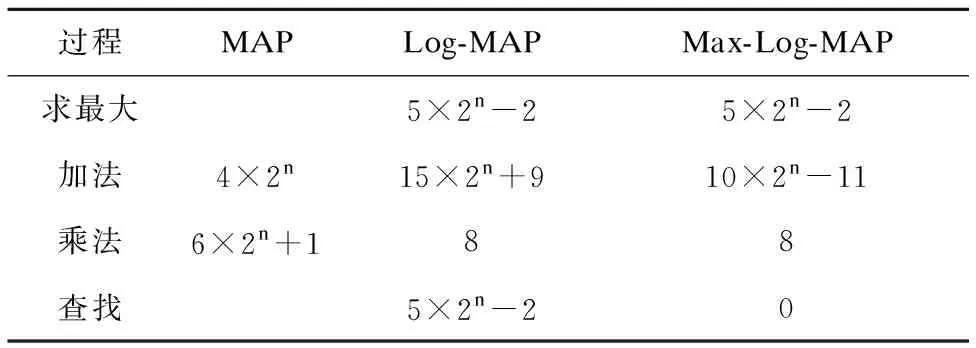
表1 几种译码算法的复杂性比较Table 1 Comparing the complexity of several decoding algorithms
表1是MAP算法及其简化算法复杂度的比较,编码记忆长度定义为n.由上表可知,MAP乘法运算量在3种算法中最大,因此复杂度是最高的;Log-MAP算法次之,Max-Log-MAP算法最小.

图1 算法性能比较Fig.1 Algorithm performance comparison
MAP算法的计算过程中包含着复杂的乘法和指数运算,硬件实现难度大,所以仿真不予考虑MAP算法,只对Log-MAP和Max-Log-MAP两种算法进行了性能对比.仿真采用了3GPP标准交织器,码率为1/3,1024交织长度以及5次迭代.从图1性能曲线可以发现,Log-MAP算法性能较Max-Log-MAP算法更优.在10-3~10-4误码率时,两种算法性能差异大约在0.1dB(0.2dB之间.这是因为Max-Log-MAP简化了修正项函数,所以性能上有所下降,但是该算法误比特率在可接受的范围之内并且便于硬件实现,所以实际应用中采用Max-Log-MAP算法.
3 DSP芯片配置
3.1 硬件
目前DSP广泛应用于软基站、小型基站以及无线电的基带处理[8].因此,DSP处理器性能直接成为一个制约系统的重要因素.TMS320C6670是TI公司推出的一款每个核的主频达到1.2GHz的四核定点/浮点DSP,是一块专用于通信的DSP芯片[9].
DSP内核及二级内存单元与TCP3d数据交换的结构如图2.TCP3d控制寄存器控制整个状态,其中包括总线传输能力、相关编码信息、译码性能等.同步事件产生模块控制EDMA的读/写同步事件;译码处理单元与内存存储模块负责译码和存储.
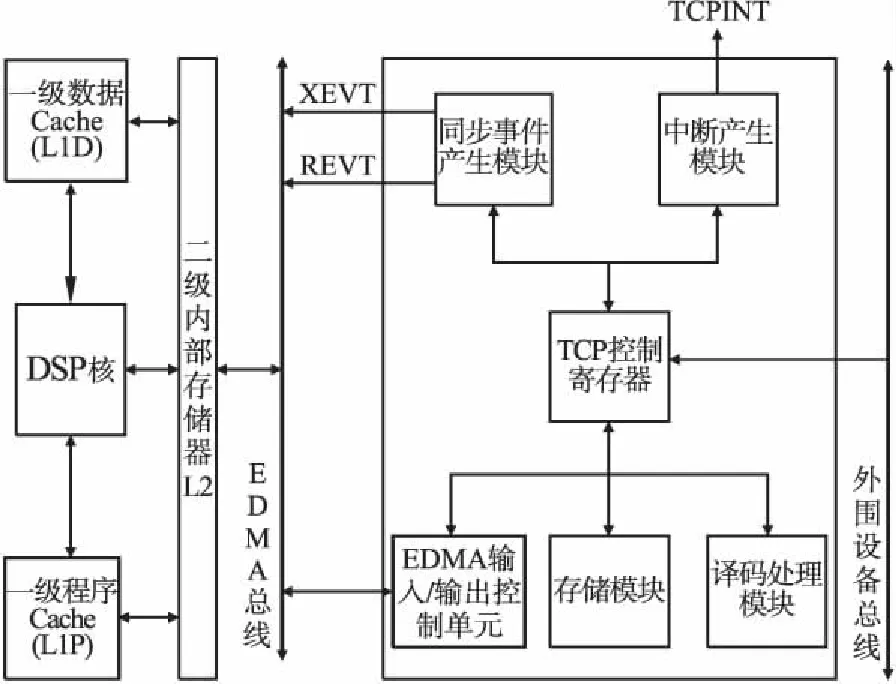
图2 数据处理与交换结构图Fig.2 Data processing and exchange structure diagram
3.2 EDMA配置
EDMA[10](Enhanced Direct Memory Access,增强型直接内存存取)完成参数配置并启动后,EDMA通道将进入使能状态并等待触发.EDMA通道被触发后,会根据PaRAM(Parameter RAM,参数RAM)将数据和控制信息传输到相应内存空间,接着触发译码模块.译码完成后,通过写同步事件触发EDMA通道把处理后的数据搬到DSP内核中.图3显示了Turbo译码过程基本触发过程.

图3 译码触发过程Fig.3 Decoding triggering process
3.3 参数配置
本文主要用于实现PDSCH接收端的Turbo译码,多核DSP处理Turbo译码时先要进行一些硬件初始化,主要包括复位、清零、EDMA的初始化和通道配置等,另外还要配置一些PDSCH处理的参数,TCP3d协处理器的主要参数配置见表2所示.
4 Turbo译码算法的DSP实现
为了进一步提高Turbo译码的效率使用了滑窗译码算法,该算法是将接收码块序列分割成子块,然后将子块送入到多个结构相同并行的译码器进行处理.滑窗译码算法如图4所示,每个子块通过多个滑动窗分别使用Max-Log-MAP算法实现译码.

表2 TCP3d主要参数配置Table 2 TCP3d main parameter configuration
滑动窗大小规定了6种不同的取法,其中包括16,32,48,64,96或128比特.另外还可以从图4中看到头延伸部分,可信部分和尾延伸部分.这是因为Turbo码在编码时,编码器的状态转换关系是连续的马尔科夫过程.在译码时,需要确定编码器的初始状态和终止状态以及状态之间的转换关系.把接收序列分割为多个子块后,就破坏了状态的连续性.头延伸初始状态和尾延伸终止状态都被设定为等概率,然后根据接收序列以及编码器状态转换规律逐步对可信部分进行计算.在可信部分、起始时刻值和终止时刻近似调整为分割前的状态时,头延伸和尾延伸为冗余重叠的部分,此时计算译码输出时只需考虑可信部分,所以虽然算法不会提升Turbo译码性能,但会减少处理的时延.
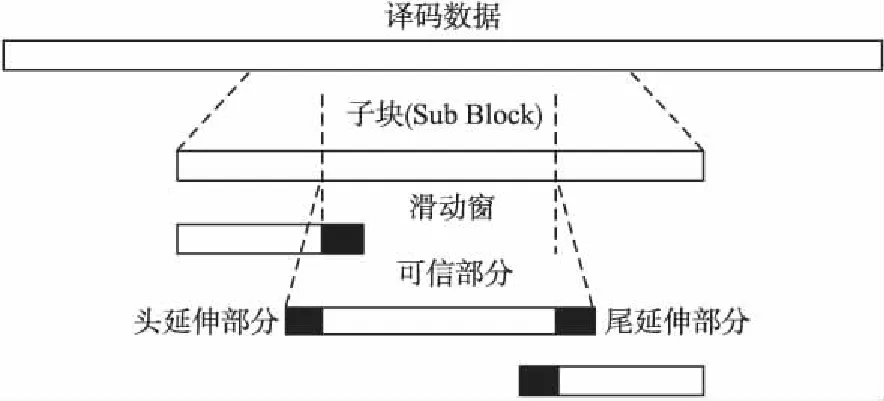
图4 滑窗译码算法Fig.4 Sliding window decoding algorithm
根据芯片特性及工作原理,本文设计的Turbo译码的基本流程由以下步骤组成:
1)DSP硬件初始化,包括清零、复位、选择大小端等.
2)输入数据的量化与配置控制信息.输入数据的量化主要是调整尾比特数据格式.配置控制信息有工作模式选择、滑动窗口、码块大小等.
3)EDMA的初始化与通道配置.初始化后.将输入的数据、控制信息、交织表等搬移到对应的内存中.
4)EDMA搬移完成后,触发TCP3d进行Turbo译码.
5)译码完成后,EDMA接受到完成中断,将状态信息与判决数据搬移到DSP核内,整个过程结束.
5 性能分析
5.1 译码性能比较
使用多核DSP与单核DSP分别对符合3GPP协议码率为1/3的Turbo编码数据进行译码.考虑误帧率为10-4,块大小在40-6144之间,滑窗大小为16、64或128比特,迭代为8(71/2)得到的译码性能分别如图5和图6所示.

图5 多核DSP Turbo译码性能Fig.5 Decoding performance of multi core DSP Turbo
图5和图6分别为多核DSP与单核DSP达到特定的误帧率目标与码块大小所需的信噪比的关系图.从图5和图6中都可以看出滑动窗口长度对Turbo译码性能有一定的影响,从16比特长度增加到64比特长度对Turbo译码性能有一定地提升.滑动窗口长度超过64比特之后,性能提升可以忽略不计.通过图5与图6的对比发现,码块长度为101~103时,多核DSP随着码块长度的增加,信噪比变化幅度比单核DSP大;码块长度为103~104时,多核DSP随着码块长度的变长,信噪比变化幅度与单核DSP相似.但是在相同的码块长度情况下,多核DSP的信噪比性能优于单核DSP.
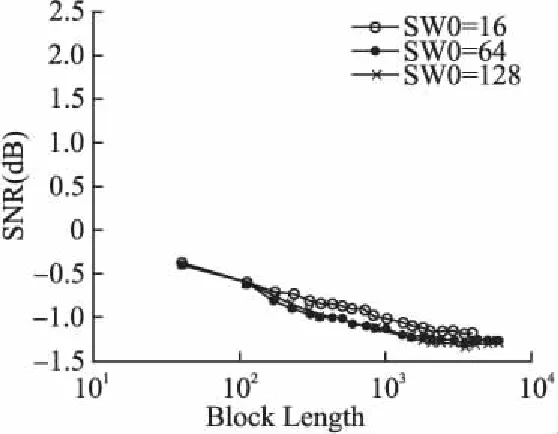
图6 单核DSP Turbo译码性能Fig.6 Decode performance of mononuclear DSP Turbo
5.2 时间性能对比
为检验基于多核DSP的Turbo译码处理性能,本文与单核DSP的实现进行对比.如表3所示,在码块个数和迭代次数不同的情况下,对比了Turbo译码算法在单核DSP下的实现时间与多核DSP中TCP3d的处理时间.
从表3中可以发现:第一是对于Turbo译码,单核DSP处理时间性能远低于TCP3d的处理时间性能,并且随着码块数的增加,两者处理的差距越来越明显;第二是随着迭代次数从1次变为2次,单核DSP处理的时间也变为了大约原来的2倍,而TCP3d的处理时间略微增加,这是由于TCP3d对数据处理时,处理时间分为了相关配置时间和数据处理时间两部分.
5.3 误比特率性能比较
对随机二进制信源经过两种DSP的Turbo编码后,再进行BPSK映射,之后经过高斯白噪声,最后经过两种DSP的如图7性能图形能够看出,单核DSP与多核DSP测试的误比特率都随着信噪比的增加而降低.从图中还可以发现多核DSP的性能比单核DSP的性能好,这是因为多核DSP应用了TCP3d协处理器,协处理器的使用可以极大地提升多核DSP误比特率的性能.
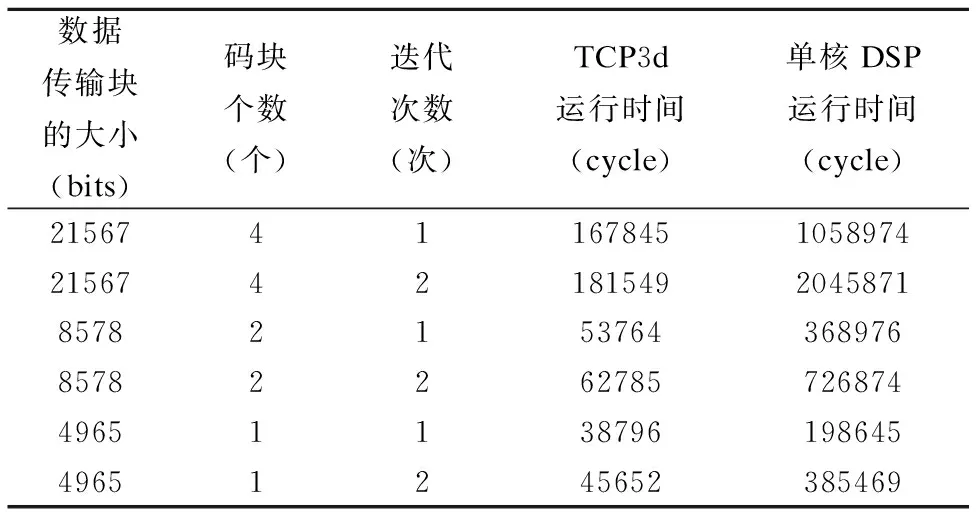
表3 不同码块和迭代次数下多核DSP与单核DSP处理时间对比Table 3 Comparison of multi-core DSP and single-core DSP processing time under different code blocks and iterations译码模块.最终对比信源和译码结果进而得出误比特率.图7为单核DSP与多核DSP测试后误比特率性能对比曲线.

图7 单核DSP与多核DSP误比特率对比Fig.7 Comparison of bit error rate between mononuclear DSP and multi-core DSP
6 结 论
本文对TI C66系列DSP中的TCP3d基本原理进行了详细的介绍,并对不同的译码算法进行了分析,着重分析了数据在多核DSP与单核DSP中的译码性能、译码时间开销和误比特率性能,通过比较发现单核DSP处理性能远低于TCP3d协处理器.本文将Turbo译码实现方法有效减少开发难度以及提高数据处理速度,大幅提升了LTE-A 数字基带系统处理性能,也为其他多核DSP的应用开发提供参考.
