移动云中可模块并行应用的计算迁移算法研究
2019-02-15疏官胜刘炜清
疏官胜,刘炜清,李 京
(中国科学技术大学 计算机科学与技术学院,合肥 230026)
1 引 言
近年来,随着智能移动设备的广泛普及,一大批移动应用也涌现出来,深入到人们生活的方方面面.这些移动应用强大的功能和丰富的体验对设备的处理能力提出了越来越高的要求,进而刺激着智能移动设备的快速升级换代.然而, 移动设备上有限的资源仍越来越明显地成为了限制移动应用体验及其适用场景的瓶颈.随着移动网络的持续升级和云计算技术的逐渐成熟,研究者们尝试将移动应用中计算复杂的部分通过无线网络迁移到云端运行,从而突破智能移动设备的资源瓶颈、提升应用的服务体验.随着相关的研究成果逐渐积累,人们将这一新兴领域称为移动云计算.其中,针对移动云环境中应用种类繁多、网络状况复杂多变等特点,如何实时地为各类应用决策出适宜当前环境状况的计算迁移方案成为了研究者们关注的热点.
移动云计算中的计算迁移技术能极大地缩减应用的响应时间,这主要得益于以下两点优势:
1)相较于资源匮乏的移动终端,云数据中心强大的计算资源能够极大地加速被迁移模块的执行;
2)一个应用中的多模块间的并行执行能进一步缩短响应时间.
现有的研究工作都在不同程度上利用了这两点优势.例如, Odessa[1]将每一帧图像切分成很多小的图片(tiles),而后对这些切分后的小图片并行地进行人脸识别,从而缩短处理每一帧图像所需的时间,这里所采用的就是数据并行的方式.除数据并行外,流水线并行(pipeline)以及任务并行则是另外两种常见的并行加速方式.流水线并行在针对基于数据流的移动云计算工作中得到了广泛的运用.而任务并行加速在多线程/进程的移动应用中就已经得到了运用,但在移动云环境中部分应用模块已经迁移到云端的场景下进行任务并行的特殊之处并没有得到研究者们的充分重视.
在移动云环境下的应用,与单纯在移动设备上执行时的最大不同在于分布于移动端和云端的应用模块需要通过无线网络进行数据交互,而移动环境中动态变化且受限的无线网络条件使得这一特性对缩短应用的响应时间有着不可忽视的作用.由于在移动云计算中计算迁移常以应用的模块为最小粒度,故在本文接下来的描述中用"模块并行"特指在移动云环境中的任务并行.对于可模块并行的应用而言,常常会出现多对模块同时进行跨网络的数据传输,而现有的移动云计算研究往往都采取简单的"即时发送、网络公平竞争"或"先来先服务、网络独占"两种方式,并未考虑不同网络传输策略对应用响应时间的影响.
本文针对移动云环境的特性,将模块间跨网络的数据传输策略集成到传统只包含各模块执行地点的计算迁移方案中,并为可模块并行的移动应用设计了高效的贪心算法从而在不同环境下实时地决策出其扩展的计算迁移方案.在扩展的计算迁移方案中,移动应用中不涉及移动设备上传感器及输入输出组件的模块(即可迁移模块)可在移动设备或云中任意一端执行.对所有需要在移动端和云端间通过网络传输数据的模块对而言,其数据传输的时机都由底层的移动云计算支撑平台依据本文所设计的算法进行全局控制.而多对模块同时传输时也不再拘泥于上述的两种传统策略,而采用更为灵活的混合策略.
为可模块并行的应用决策上述扩展的计算迁移方案的算法是本文的主要工作.算法设计过程中的主要挑战来源于两个方面:
1)扩展的计算迁移方案的可行域是随着模块数目及模块间数据传输边的数目指数爆炸的;
2)由于移动环境的动态变化,算法需要快速决策出适合于当前环境的迁移方案,即对算法有较高的实时性要求.
为了解决这两方面带来的矛盾,对移动云中应用的特性进行了分析,并针对性地设计了启发式的算法.具体而言,基于前人对于线性拓扑类应用的研究结论[11]上的推广,本文在搜索遍历应用各模块执行地点时进行大量的剪枝,从而降低算法的执行时间.其次,本文设计了多种贪心算法决策固定模块执行地点时各数据依赖的模块对间的数据传输策略.
在实验中,仿真验证了多种网络条件、多种应用拓扑结构下算法的性能.其结果显示,当移动应用各模块间的数据依赖越复杂,模块间数据传输量较大时,本文所设计的算法能得到显著的性能提升.
2 相关工作
首先对现有的相关工作进行简要介绍.其中主要包括移动云系统的通用框架以及几类现有的典型计算迁移方案决策算法.
2.1 移动云计算架构
在移动云计算的众多研究工作中,一个基本的共识便是这些应用需要为终端用户提供与未使用计算迁移技术时并无二致的功能,但在迁移后能提供更好的用户体验,即计算迁移对用户透明.为了实现这一目标,研究者们提出了综合移动设备、网络传输以及云中心的分布式移动云计算架构.传统的移动云计算架构中的"云"值得是远端的云中心[2-4],而针对时延敏感型的移动应用,有研究者提出利用移动设备周围的空闲服务器(微云[5],cloudlet)就近为承接从移动终端上迁移出来的计算.图1展示了一个结合了微云和云中心的典型移动云计算架构.本文所考虑的场景及所设计的算法也适用于这一典型架构.

图1 用户设备-微云-云数据中心架构Fig.1 Devices-cloudlet-cloud datacenter hierarchy
然而在移动云计算的典型架构下,不同的研究工作对于分布在移动端和云端的模块间的通信有着不同的处理模式.早期的研究者们通过采用远程过程调用(RPC)的方式实现模块间的远程通信[6],后来基于跨平台执行框架的移动云计算平台逐渐成为主流(如基于OSGi Service Platform[7]的Cuckoo[8]、基于Microsoft .NET CLR[6]的MAUI[9]、基于Sprout[10]的Odessa[1]).运行于这些平台上的移动应用中的跨网络传输都交由底层的平台处理.本文所提出的扩展的计算迁移方案正是为了这种能全局控制网络传输的移动云计算平台而设计.
2.2 典型计算迁移方案决策算法
现有的研究工作针对不同类型移动应用的特性,分别设计了相应的计算迁移决策算法.如Moo-Ryong Ra[1]等人针对基于数据流的应用设计了以同时提升应用吞吐率和响应时间为目标的决策算法;Zhang Weiwen[11]等人则根据线性拓扑应用的特性分析设计了同时优化移动设备能耗以及完成时间的计算迁移决策算法;J Flinn[12]等人为延迟敏感的交互式应用提出了基于微云(cloudlet)的扩展移动云计算架构并在此基础上设计了一系列的算法在保障响应时间的前提下提高应用的质量(即保真度,fidelity).在这些工作中,研究者们都将应用的响应时间做为应用性能的重要衡量指标,本文也采用响应时间作为衡量指标.
而在算法的选择上,有的着重保证算法实时性而设计相应的贪心算法(如Odessa[1])、有的着眼于缩小可行解搜索范围的剪枝或启发式方法[13,14]、还有的通过求解最优化问题为特殊场景下的应用求解最优计算迁移方案[11].本文结合了搜索剪枝及贪心两类算法,以期在算法实时性及得出的迁移方案效率之间获取平衡.
3 问题建模
接下来分别从设备及网络建模、应用的建模及问题描述三方面来阐述本文的研究目标.
3.1 设备及网络
由于本文着眼于算法的设计,故将不同设备间的差异及特性进行简化.在本文中,统一用每秒处理的百万指令条数(MIPS)作为移动终端及云中服务器的计算能力的衡量指标.设移动设备的处理能力为Pmobi,云服务器的处理能力为Pserv.考虑到移动应用的模块间往往有着较为可观的数据传输量(如传感器数据或中间结果),用带宽B来衡量移动端与云端之间的网络状况.
此外,不论是计算资源或是网络带宽资源,本文都不考虑多用户多应用之间的竞争.这一假设主要基于以下两点考量:
1)由于云服务器的计算能力远远强于移动终端,故而假设单个移动设备只将计算迁移到一台其专属的云中虚拟机上;
2)在移动端与云端的网络通路可简单分为靠近云数据中心的固定网络以及接入移动设备的无线网络.
相较稳定高速的固定网络而言,移动设备接入的无线网络往往会成为移动端与云端之间网络带宽的瓶颈.
3.2 可模块并行的移动应用
在大部分的移动云计算模型中,应用的模块拓扑信息能够通过源码扫描或者开发者描述而获得[10,15,16].在移动云计算中,应用常常可以被刻画为一个有向无环图G(V,E)(Directed Acyclic Graph,缩写为 DAG),其中每个顶点代表应用的一个功能模块,每条边(f,g)表示模块g依赖于模块f.考虑到绝大部分移动应用都会和终端用户进行交互(比如接受用户输入和展示结果)或者依赖移动设备上的传感器数据,假定有向无环图中的源节点(source nodes)和汇节点(sink nodes)都是只能在移动设备上执行的不可迁移模块,而其他的模块都设为可迁移模块.

图2 假想中最简单的可模块并行的应用Fig.2 Simplest imaginary module-concurrent MCC application
本文所关注的可模块并行的移动应用的直观体现为,有两个或以上的模块依赖于同一模块的数据,即在图中至少有一个节点f有两条或以上的出边(f,g1)、(f,g2).图中每个节点都有u∈V都有一个权重Wnode(u)表征完成这一模块所需执行的百万指令条数.图中每条边(u,v)∈E都有一个权重Wedge(u,v)用以表示模块间所需传输的数据量.图2展示了一个假想中最简单的可模块并行的移动云应用.
3.3 应用的局部时间消耗
应用的响应时间是由应用的各模块执行时间及模块间的数据传输时间所决定的.而在不同的网络条件、移动终端和迁移方案下,同一个应用的模块执行时间及数据传输时间都不尽相同.

简述其构造过程如下:
1) 将图G中的任意节点u∈V分割为两个节点u和u′放入图G′,并增加一条边 (u,u′), 其边权等于此模块独占所处设备的一个CPU核时所需的执行时间,即W(u,u′)=Wnode(u)/(|αu-1|*Pmobi+αu*Pserv);
2) 对图G中的任意边(u,v)∈E,在图G′中添加边(u′,v),其边权等于此连接独占所有网络带宽时所需的数据传输时间.由于同一设备上的不同模块可共享存储,所以假定其间的通信时间为0.因而有,
3) 增加一个虚拟的源节点s并以权重为0的边指向所有入度为0的节点,从所有出度为0的节点连出一条权重为0的边指向一个新增加的虚拟汇节点t.
图3展示了在特定迁移方案图2中假想应用的AOE图.

图3 生成应用AOE图的过程
Fig.3 Process of generating the AOE graph for an application
考虑到现有的移动设备往往都配备了4至8核的处理器,而一个移动应用往往仅有为数不多的若干个功能模块,故而假定所有的模块都可互不冲突地执行,即边权W(u,u′)就代表了实际的模块执行时间.
而由于多对跨网络的模块间数据传输需要竞争有限的网络带宽,边权W(u′,v)并不一定反映真实的网络传输时间.若在某时间段有k条连接同时传输数据,则这k条边都需加大其边权以抵消网络竞争带来的影响.具体而言,对图G′中任意一条传输边(u′,v)∈E′,假定其数据传输过程由m个连续的时间片(t1,t2),(t2,t3),…,(tm-1,tm)组成,第i个时间片中固定有ki条连接同时传输数据,需要从i=1开始对其边权进行如下更新W(u′,v)=W(u′,v)+(ti+1-ti)*(k-1)/k.由于这些传输边的先后顺序除被应用的模块拓扑所约束外,还可被算法人为地设定.所以需要综合结合下一小节所介绍的数据传输策略及应用的模块拓扑两方面的信息,在确定每条数据传输边的开始时机之后对这些边权进行统一调整,进而代表真实的数据传输时间.
3.4 数据传输策略
对于可模块并行的移动应用而言,其部分模块迁移到云端之后,常常会出现多对模块间同时进行数据传输的情况,且开始时刻、持续的时间都不同.这也使得对于真实传输时间的估计和优化变得复杂.由于底层的移动云计算平台都能对模块间的数据传输进行集中控制和规划,本文假定模块间的数据传输的开始顺序可由底层平台控制,而一旦传输开始则不能中断或暂停,同时在传输的多条连接平均地共享网络带宽.



3.5 问题描述
4 算法设计
4.1 模块执行地点:限制搜索范围
在第3.2节对移动应用的建模中一个重要的特性便是,应用模块拓扑图中的源节点和汇节点都是不可迁移的模块,以此代表移动应用与用户及所处环境进行交互的特性.在前人在针对线性拓扑的计算迁移方案研究[11]中,发现在起、止模块都在移动设备上执行时,若迁移部分模块至云端能提升应用性能,则最优的迁移方案一定是线性拓扑中有且仅有一段连续的若干模块同时迁移到云端.也就是说,移动端和云端之间只会依次有一次上行和下行的数据传输.这一结论稍作转换则可得到:若模块u和模块v都被决策为在云上执行,则这两模块之间的其他模块都应在云上执行.在直观上也很好理解,由于云服务器的计算能力远强于移动终端,若模块u和模块v之间的某模块被决策于移动端执行,通过网络来回传输数据的耗时以及移动设备上有限的计算能力都将延长应用总体的响应时间.
算法1. DFS遍历不同模块部署方案

//最初调用时可迁移模块都在云端

//最终的扩展计算迁移方案
function:DFSExecLoc
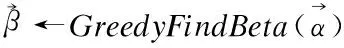
//记录探索到的最优迁移方案

then

endif
αi←0


endif
endforeach
endfunction
4.2 数据传输策略:贪心算法
然而,如图2所示,可模块并行的应用的一个典型特征就是:一个模块执行完毕后需要将相应的中间数据发送个多个后续模块.上述两种传统的贪心策略在这种常出现多条传输连接的数据同时准备完毕的场景下,要么多条链接同时发送互相竞争,要么随机选择一条连接进行发送.本文在这两种传统的贪心策略之外,尝试为可模块并行的应用设计更为合理高效的贪心策略.
通过借鉴AOE图中关键路径算法的思想,将同一个模块发出的多条跨网络的数据传输连接的最晚开始时间lst都计算出来并进行比较,每次选择最晚开始时间lst最早的一条连接进行数据传输.每次按照最晚开始时间lst最早选出来的传输边是最为紧要的一条边,有理由期待优先传送这一条边上的数据会比随机选择一条边传输或将带宽均匀分配得到更短的应用响应时间.
进一步思考会发现,上述简单直接的贪心策略还有进一步提升的空间.如图4所示的特殊情况,虽然两条边的最迟开始时间相同,但显然优先启动边(u′,v1)是更为明智的选择.这里的贪心思路在于优先传送有着更少数据量的边,从而使得后续能够充分并行的模块执行尽早执行.因此,将贪心算法改进为以下形式:对从同一个模块发出的多条传输边,分别计算其作为下一条传输边时(其他传输边都等待其传输结束后才开始),应用响应时间的缩短量,并选用能最大缩短应用响应时间的一条边作为下一条传输边.
然而在具体实现时,由于AOE图中各传输边的权值需要与这些边的先后次序进行同步的更新,这将使得上述算法中每枚举一条传输就需要有额外O(m)的边权更新复杂度,这显然是不可接受的.因此,在实际实现中,选用固定当前AOE边权,将带来最少响应时间增加的边作为下一条发起传输的边.假设这一模块的所有出边序列为R,(ui′,vi)和(uj′,vj)分别代表R中的第i和第j条数据传输边,可以根据下式来计算出应该首先传输的边:
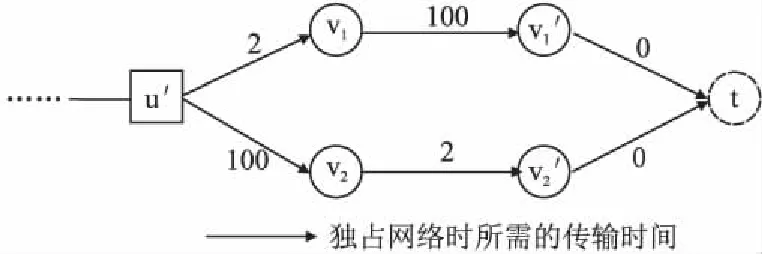
图4 并行数据传输的极端情况Fig.4 Extreme case of concurrent data transmission
按照此式则可轻松得出图4所示的例子中,边(u′,v1)相较边(u′,v2)有着更高的优先级.算法2展示了这一贪心算法的主要逻辑.
算法2.贪心算法求得数据传输时机

//当前探索的应用模块部署方案
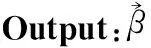

function:GreedyFindBeta
//将所有跨网络数据传输边按est排序
L←GetSortedTransEdges(G′)
whileL!= NULLdo
//获得一个模块的多条出边序列R
whileL[i].est=L[0].estdo
ifL[i].src=L[0].srcthen
R.insert(L[i])
endif
i←i+1
endwhile
ifR=NULLthen
L.deleteFirst()
else
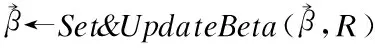

L.deleteList(R)
endif
endwhile

endfunction
5 实验评估
为了验证所设计的算法的有效性,设计了一系列的仿真实验对其进行测试.
5.1 实验设置
在仿真试验中,固定应用的可迁移模块数为10,足以覆盖大部分的移动应用.而其他的各种参数,如应用的模块拓扑、各模块的计算量、模块间的数据传输量、移动设备及云服务器的处理能力和移动端于云端之间的可用带宽等,都是由脚本自动随机产生的.而在生成这些随机参数的过程中,选取了两个有代表性的变量进行控制,以此测试算法在不同场景下的性能表现,其分别是:应用各模块间数据传输的疏密程度、模块计算时间与模块间数据传输时间的比值.其具体的定义将在随后各小节详细介绍.在所有的试验中,每组实验都会对的同样配置下随机生成的100个应用进行测试,并取其平均值作为其结果.
在各组实验中,主要比较本文所涉及的贪心算法和传统的两种贪心算法,即"即时发送、网络公平竞争"和"先来先服务、网络独占".算法的结果都以比值的形式呈现,具体而言是当前算法得出的应用响应时间除以"即时发送、网络公平竞争"算法得出的响应时间.这一比值越小则表明算法的结果越好.由于上述三种贪心方式都可能不同情况下获得更短的响应时间,所以在实际应用中可将这三种贪心算法所得的迁移方案进行比较后,选取有着最短响应时间的迁移方案进行部署.将这一算法的结果也列入实验对比之中.
此外,还根据应用的模块拓扑及网络带宽、设备处理能力等,为每组实验计算其响应时间比值的松弛下界.这一松弛下界的取值等于放松两种不同的约束得到的两个松弛下界中较大的一个.具体而言,这两个简单的松弛下界是通过:
1)假设移动端到云端之间有无穷多条带宽为B的网络通路,模块间的任一数据传输都可独占一条通路进行数据传输,从而得到一个简单的松弛下界.
2)假设迁移到云端的模块执行时间都为零,故这一响应时间的松弛下界等于网络传输的总时间(总数据量/带宽B)与不可迁移模块中计算量最小的两个模块的执行时间总和.
通过取这两个松弛下界中较大的一个作为响应时间的松弛下界,可以大致估计各贪心算法的结果距最优解的差距.
5.2 模块间依赖程度对性能的影响
采用模块间数据传输边的数量除以全连通图中边的总数量的比值LinkRate来衡量应用各模块间的依赖程度.图5显示了在不同LinkRate下,各贪心算法的所得响应时间与"即时发送、网络公平竞争"算法所得响应时间的比值RespTimeRate.由于"即时发送、网络公平竞争"算法是目前移动云计算的研究工作中最为广泛运用的数据传输策略,故而可认为(1-RespTimeRate)就代表了比现行通用方法性能提升的比例.

图5 不同的LinkRate下算法的性能Fig.5 Performance of greedy algorithms under various LinkRate
由图5可知,本文设计的算法要优于传统通用的贪心算法,当综合比较多种贪心算法的结果后选择最优的迁移方案,则在一定条件下能缩短5%左右的响应时间.当LinkRate很小,即模块间的数据传输边非常少时,各贪心算法的性能与平均分配带宽的方案相差不大,这是因为在数据传输很稀疏的情况下,同时有多条连接同时传输的概率也大大降低,因而难以体现出不同算法之间的的差异.随着模块间数据传输的比例增大,可模块并行的程度也相应增加,本文所设计算法的优势开始逐渐体现.直到近乎任意两模块之间都有数据依赖关系时(LinkRate=1),为数据传输的开始时机进行优化的积极影响才开始削弱.
值得注意的是,综合了三种贪心策略的算法在LinkRate较小和较大时都与算法所能达到的松弛下界逼近,说明在这些情况下,这一算法几乎能够获得最优的性能.而在LinkRate处于适中的位置时,由于松弛下界的RespTimeRate显著降低,这是因为所采用的松弛下界是由两组简单的松弛下界中取较大得来的,LinkRate较小时,"无穷多条网络通路"这一松弛下界距下确界较近,而LinkRate较大时,则是"忽略云端模块执行开销"的松弛下界距下确界较近.而当LinkRate大小适中时,这两种简单松弛下界距下确界都较远,故而使得图中的松弛下界快速下降,并不意味着本文所设计的算法在这一场景下距最优解有更大的差距.
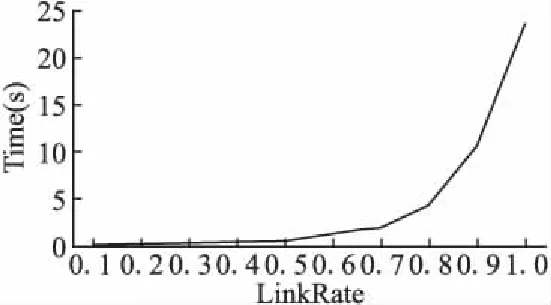
图6 不同的LinkRate下所有算法的执行时间和Fig.6 Total execution time of all three greedy algorithms under various LinkRate
另一方面,比值LinkRate的增大等价于应用AOE图中的边数m的增多,这显然会带来算法执行时间的增长.图6展示了在不同LinkRate下,综合的贪心算法在个人PC机(Intel Core i7-3770)上所消耗的时间.由于扩展的迁移方案常常是在云端进行决策的,且实际的应用中模块间的依赖都较低(互相紧密依赖的功能/函数往往都被打包进一个模块中),故而可以相信这一算法能够满足移动云环境下的实时性需求(几秒内返回结果).
5.3 计算或通信密集对性能的影响
采用一对模块间的数据传输在独占网络带宽场景下的期望时间除以在移动设备上独占一个CPU核计算一个模块所花的期望时间的比值TransCompRate来衡量应用对通信资源和计算资源的侧重.图7显示了在不同TransCompRate下,各贪心算法的RespTimeRate.由图7可知,当应用是典型的通信密集型应用时(与网络状况不佳的情况等价),各决策算法都倾向于不迁移任何应用模块以避免高昂的通信开销,这时各算法之间的差距很小(TransCompRate很小时).而随着应用中计算所占比重的增加(或网络状况的好转),本文所设计算法的优势开始逐渐体现出来(TransCompRate适中).直到应用逐渐体现出计算密集型应用的特征(或网络状况极好),数据传输在应用整体的响应时间中所占的比重越来越低,这时各个贪心算法之间的差距开始缓慢的缩小(TransCompRate较大).但不论在何种情况,本文所设计的算法以及综合多种贪心算法后的综合算法都能显著地降低应用的响应时间.
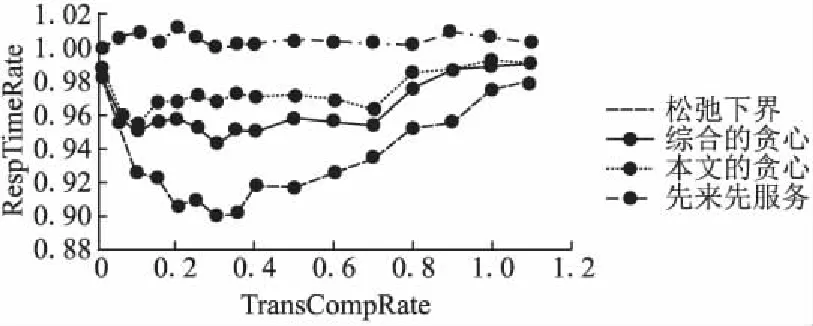
图7 不同TransComRate下各算法的性能Fig.7 Performance of greedy algorithms under varous TransCompRate
6 结 论
本文针对移动云计算中可模块并行的移动应用,探讨了其特性并提出在对应用进行计算迁移时,不光决策应用各模块的执行地点,还同时优化各跨网络数据传输的顺序,从而进一步降低可模块并行应用的响应时间.为了应对移动环境快速多变的特性,本文设计了高效的贪心决策算法,在满足实时性需求的前提下显著降低应用的响应时间.通过一系列的仿真实验验证,本文设计的贪心算法相较传统的公平竞争及先来先服务的数据传输方案,能缩短约5%的响应时间.
