一种Spark GraphX框架下的关键词抽取方法
2019-02-15程传鹏
程 传 鹏
(中原工学院 计算机学院,郑州 450007)
1 引 言
关键词指的是文档中比较能够体现文档的重要信息和核心内容的词语,主要应用在搜索引擎搜索结果的展示、自动文摘、推荐系统、自动问答等方面[1].目前对关键词抽取的研究主要分为四类,一种是基于词频的方法,比如词语共现、TFIDF,在这类研究中主要应用的是TF*IDF的方法来计算关键词的权重,然后根据句子中候选关键词的权重来选择出主题句,该方法的程序实现简单,原理较为直观,应用也最为广泛,但该方法在计算关键词的权重时只是简单的考虑了词语共现的关系,没有考虑到词语之间的联系,第二类方法是利用文档的篇章结构来抽取关键词,文献[2]利用段落和句子的不同位置,分别给出了初始权重,接下来根据主题单词与前后相邻单词之间的相关性进行词组筛选合并,形成备选关键词组集合.最后综合考虑数字、大小写、单词数、平均单词长度和主题单词选取顺序5个因素,对备选关键词进行评分,并选取得分高的关键词作为最后的结果.第三类方法是利用机器学习的方法来抽取关键词[3-5],该方法利用大量的训练语料来学习出关键词模型的特征,通过大量训练集所得出的学习模型来选择关键词,比较适合多文档关键词的抽取,关键词抽取的好坏依赖于所选择机器学习训练语料质量的优劣.第四类方法是基于语义理解的方法[6-9],该类方法利用同义词词典对候选词语进行过滤或者利用语义词典(HowNet或WordNet)将词语用词义替代,从而提高了关键词提取的准确度.
本文利用词语之间的联系来构造词语联系图,基于TextRank算法,在Spark平台上利用GraphX图计算框架,快速高效的计算出候选关键词的权重.文章主要由三部分组成,第一部分分析了候选关键词权重的计算原理;第二部分介绍了基于Spark Graph X的关键词抽取算法的具体实现步骤.第三部分利用真实的语料,根据本文所提出的方法进行实验论证,并对实验结果做出了合理的评价和分析;第四部分,对文中方法进行了总结,并指出了不足的地方以及未来研究的方向.
2 基本理论介绍
1998年,斯坦福大学两个博士生Sergey Brin(谢尔盖·布林 )和Lawrence Page(拉里·佩奇)提出了一种名为PageRank算法,该算法根据网页之间相互的链接关系计算网页排名,算法采用递归的定义,不论初始值如何选取,这种算法都保证了网页排名的估计值能收敛到它们的真实值[10].2004年Rada Mihalcea and Paul Tarau应用图的排序算法,在谷歌的 PageRank算法思想的基础上提出了TextRank 算法[11],TextRank 算法综合考虑了单词间的位置关系和出现频率,其算法的核心思想和 PageRank 相同,即在文本网络中节点(词)的重要程度取决于与它相连的单词的分给它的票数,其计算公式如公式(1)所示.
(1)
其中,W(Wordi)为候选关键词的权重,In(Wordi)为Wordi与相连的词语,Out(wordj)为与wordj相连的词语个数,d取值一般为0.85,文献里称之为阻尼系数[13].
使用TextRank对文本提取关键字的一般需要经过文本预处理、词语过滤、构造文本图、迭代计算候选词权重、关键词输出五个步骤,在文本文本预处理阶段,将文本按照完整句子进行切分并进行词性标注处理;在词语过滤阶段,过滤掉停用词,只保留指定词性的单词,如名词、动词、等能够体现文本中心思想,具有丰富语意的词;构造文本图的主要操作是根据设定的词语选择窗口截取文本的分词结果,将每个词语作为候选关键词图的节点,截取的每一段文本中的词语作为相邻的边,以此构建候选关键词图;循环迭代计算候选关键词权重, 每个节点的权重初始化化为1.0,通过设定的迭代次数达到稳定后;对节点权重进行倒序排序,从而得到最重要的一些词语,作为候选关键词.下面以一段具体的文本,给出关键词的选择过程.
长期以来,判定医疗质量的指标多是以出院病人的终末结果为依据,这是从医务人员角度设计的判断标准.随着医疗作为一种服务业进入市场,越来越多的病人将以自己对医疗质量的理解和观念来评选医院和医师,参与医疗质量的评价.
在指定滑动窗口为2的时候,构造的文本图如图1所示.
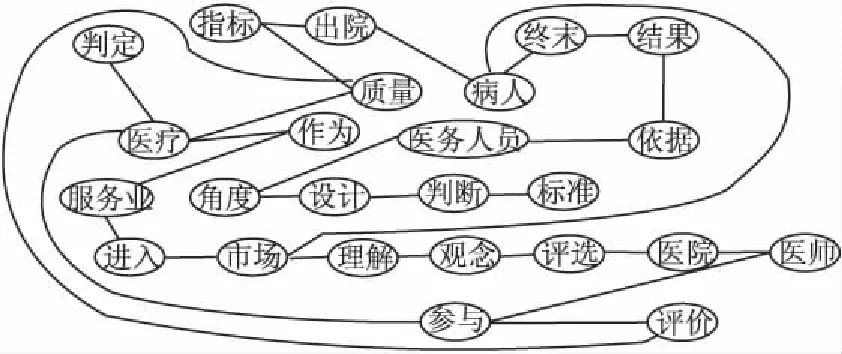
图1 文本网络Fig.1 Text network
根据前面的公式(1),“医疗”词语的权重,由公式(2)给出,其它词语的权重计算方法类似.
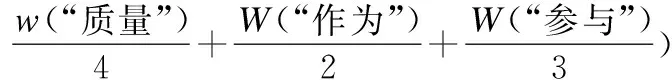
(2)
经过迭代20次以后,权重趋于收敛,文本图中每个词语的权重如表1所示.
3 基于Spark GraphX的候选关键词权重计算
GraphX是构建在Spark之上的图计算框架,它将图数据以RDD分布式地存储在集群的节点上,使用顶点RDD(VertexRDD)、边RDD(EdgeRDD)存储顶点集合和边集合,高效地实现了图的分布式存储和处理,并提供了属性操作、结构操作、关联操作、聚合操作、缓存操作等实用的图操作方法.除此之外,目前最新版本GraphX已支持PageRank、数三角形、最大连通图和最短路径等6种经典的图算法.GraphX对Spark RDD进行了封装,采用了Pregel的编程模型,他们自定义了sendMessage函数,vertexProgram函数,和mergeMessage函数,然后交给Pregel去运行,而在Pregel中,他的核心函数是图的mapReduceTriplets,通过一定的规则不断迭代,直到产生的activeMessage为0或者满足预先指定的迭代次数,最后计算得到相应的结果.GraphX在图顶点信息和边信息存储上做了优化,使得图计算框架性能相对于原生RDD实现得以较大提升,接近或达到GraphLab等专业图计算平台的性能,可以方便且高效地完成图计算的一整套流水作业,其架构如图2所示.
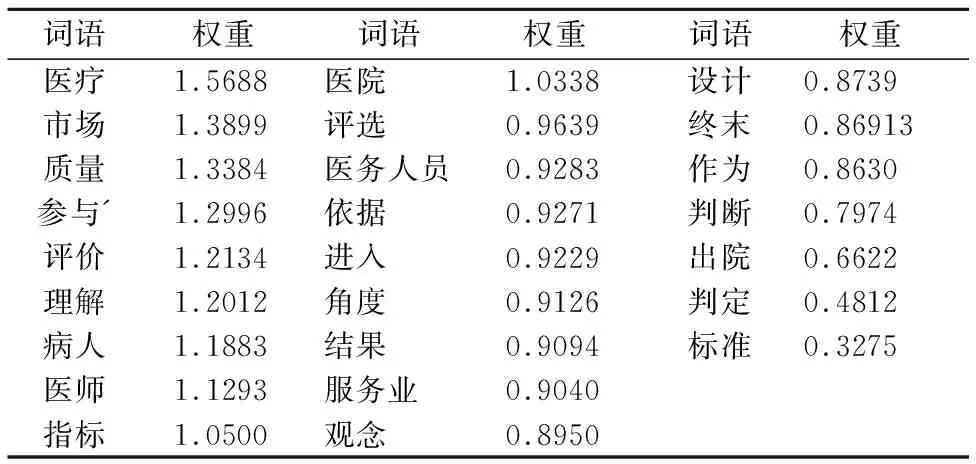
表1 词语权重Table 1 Word weight
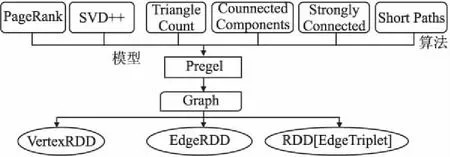
图2 Spark GraphX 框架结构图Fig.2 Spark GraphX frame structure
GraphX综合了Pregel和GAS两者的优点,即接口相对简单,又保证性能,可以应对点分割的图存储模式,胜任符合幂律分布的自然图的大型计算.基于Spark GraphX图计算框架的特点,本文给出关键词抽取步骤主要有以下5个步骤:
第1步. 程序运行环境的配置
首先在程序的开始,导入Spark运行环境配置包,Spark GraphX图计算框架包,控制程序输出信息包以及分词所需要的包.
第2步. 文本预处理阶段
结合语料的性质,可以增加切分度更高的自定义词典,自定义词典文本中每一行存放一个词,逐行读入文本文件,将其添加到自定义词典中.在添加完用户自定义字典和停用词词典后,用SparkContext对象sc读入要分词的文件,将文本转换为弹性分布式数据集(RDD),其中停止词过滤字符串为("w",null,"ns","r","u","e","","uj","a","c","p","d","j","q").
第3步. 文本图的构建
为了在Spark GraphX中运行程序,需要构造文本图,分为两个部分,一个是构造图的顶点,由词语组成,第二部分是构造图的边,由滑动窗口内的词对组成图的边.对文本进行分词,从分词结果中去掉词性为方位词、标点符号、助词、介词等词语,并对每个词进行标号,顶点列表vertexList=List((1L,WordType(word1)),(2L,WordType(word2)),(3L,WordType(word3)),……(iL,WordType(wordi)),……(nL,WordType(wordn))),边列表edgeList= List(Edge(WordNo(wordi),NextWordNo(wordi),iniWeight)),WordNo(wordi)意思是第i个词语的词标号,NextWordNo(wordi)意思是第i个词语的邻接词语的词标号,iniWeight是初始权重,在程序中设置为1.在构造完顶点列表和边列表后,将它们RDD化,并利用Spark graphX提供的Graph方法构造图.
第4步. 并行化计算候选关键词的权重
将上一步所构造的图的顶点数据更新为出度,设置边界的值为出度数目的倒数,顶点数据设置为1.所有顶点的消息初始化为0 ,遍历每个triplet,将顶点的出度数发射给目标对象,目标对象合并所有的出度数后,将顶点数据进行更新.最终处理具体代码如下:
val outWordDegreesGraph=wordsGraph.outerJoinVertices(outDegrees){
(vId,vData,OptOutDegree) =>
OptOutDegree.getOrElse(0)
}
val weightWordEdgesGraph=outWordDegreesGraph .mapTriplets { EdgeTriplet=>
1.0/EdgeTriplet.srcAttr
}
val inputGraph=weightWordEdgesGraph .mapVertices((id,vData) => 1.0)
val firstMessage=0.0
val itr=25
val edgeDirection=EdgeDirection.Out
val updateWordVertex=(vId: Long,vData: Double,msgSum:Double)=>0.15+0.85*msgSum
val sendMsg=(triplet:EdgeTriplet[Double,Double])=>Iterator((triplet.dstId,triplet.srcAttr * triplet.attr))
val aggregateMsgs=(x: Double,y: Double)=>x+y
val influenceGraph=inputGraph.pregel(firstMessage,itr,edgeDirection)(updateWordVertex ,sendMsg,aggregateMsgs)
第5步. 候选关键词词语权重的输出
对计算所得到的候选关键词的权重按从大到小进行排序,输出一定数量(程序中输出10个关键词)候选关键词以及相应的权重值.
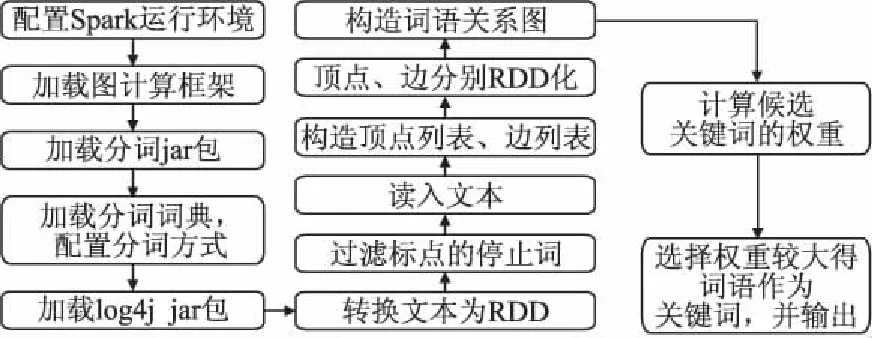
图3 关键词抽取算法流程Fig.3 Flow chart of keyword extraction algorithm
候选关键词权重计算流程如图3所示.
4 实验及评价
4.1 实验环境的配置
本实验采用了8台计算机组成局域网,在每台计算机上安装的操作系统为Centos 6.5,JDK的版本为64位的jdk1.8.0_144,Hadoop的版本为2.7.4,Spark的版本为spark-2.1.2-bin-hadoop2.7.Master机的IP为192.168.80.121,hostname名称为master,7台slaves机的IP为:192.168.80.122~ 192.168.80.128,hostname名称分别为:slave1~slave7.并确保每台计算机之间可以两两ping通,8台计算机的防火墙都为关闭状态,确保通讯顺畅.IDE采用了linux平台的Intelli IDEA UTLIMATE 2017.2,在IDEA的Project Structure界面分别添加JDK、Spark、Scala 等工程依赖库,其中Scala SDK的版本为2.11.0.
4.2 实验过程及结果分析
利用网络爬虫从人民网上爬取的时政要闻作为实验语料,从中筛选出7357条新闻,提取出每条新闻的标题和新闻的正文部分,使用hadoop fs-put命令将新闻语料存储到HDFS文件系统,采用ansj所提供的分词jar包对每条新闻进行分词并进行词性标注.本文的实验分为4个,第一个实验将实验语料集分为不同的四组,第一组、第二组和第三组分别有1800条新闻,第四组为剩余的1957条新闻.分别用本文中所提到的方法与应用最广泛的TFIDF算法以及基于文档结构的方法进行比较,文档结构方法中权值取值如表2所示.

表2 文档结构权重取值Table2 Weight of document structure
本文采用召回率(Recall)来衡量各个算法的优劣,其计算公式如公式(3)所示.
(3)
其中NumManual指的是由人工选择出的关键词数量,并假设人工选择的关键词完全正确,NumManual指的是有计算机选择出同等数量的关键词中和人工选择关键词一致的词语数量,经过实验形成如图4所示的实验数据.
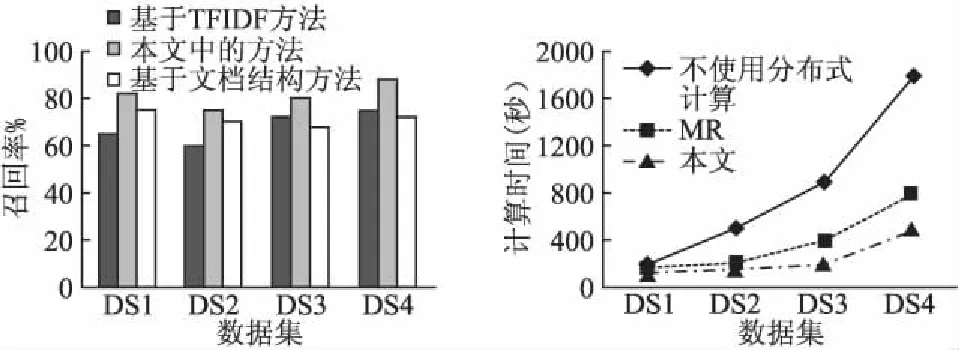

从图4中的实验数据,可以看出本文中的方法在数据集1、数据集2、数据3上都有较好的表现,在数据集4上测试的结果,本文中的方法和TFIDF的方法都没有基于文档结构的测试结果好,究其原因TextRank和TFIDF的方法都和词频有关,而测试集4中有很多同义词在简单的进行词频统计时,被当成了不同的词语来对待,在构造文本图顶点或者词频统计时理应对这些同义词进行合并处理,这也是我们下一步工作的需要改进的地方.
第二个实验是时间效率的比较,主要用本文中所提到的方法和不使用分布式计算以及h andoop平台上的MapReduce并行分布式式计算进行比较,其中数据集DS1共有130条新闻,DS2共有500条新闻,DS3共有2500条新闻,DS4共有7000条新闻,比较结果如图5所示.
从图中可以看出在小数据集的情况下,三种算法计算时间差别很小,但随着数据量的增大,使用MapReduce的方法要优于不使用分布式计算的方法,而本文中使用Spark 平台的算法在时间效率上,随着数据量的增大有着更为明显的提高.
第三个实验是自身参数的调节,分别调节的迭代次数,滑窗的大小,程序运行界面如图6所示.
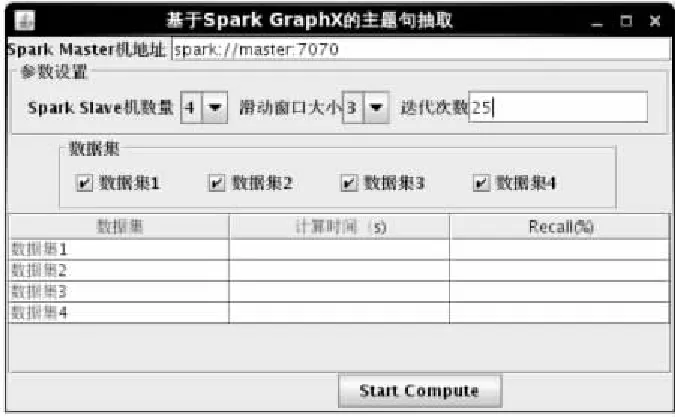
图6 程序运行界面Fig.6 Program interface
在程序主界面上设置Spark Maserter机的地址为spark://master:7070,Spark Slave机数量为4,迭代次数为25,分别设置滑动窗口的大小为2、3、4、5时,本文中的方法在四个测试数据集上所得出的实验结果如图7所示.
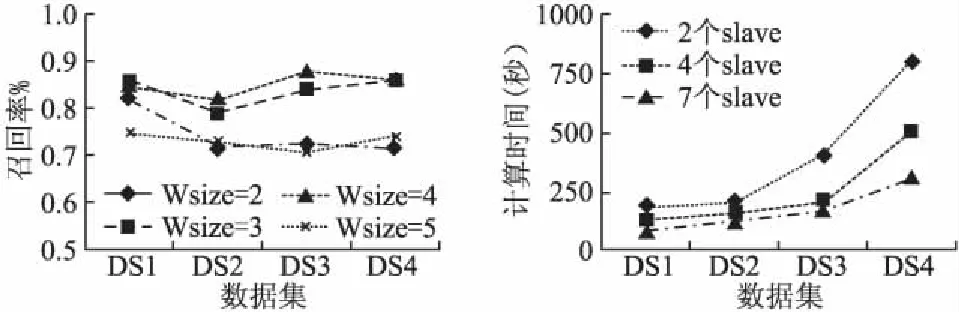
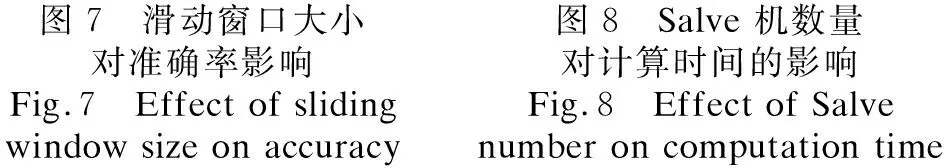
滑动窗口的大小为2、3,迭代次数为25,分别设置Spark Slave机数量为2、4、8时,本文中的方法在四个测试数据集上所得出的实验结果如图8所示.
从图7中可以看出滑动窗口取值为3和4时,所抽取的关键词,要好于滑动窗口取值为2和5的时候,这说明滑动窗口的取值大小对实验结果的准确率有较大的影响,滑动窗口取值过小或者过大,实验的效果并不理想.从图8中可以看出在数据量较小的情况下,从机的数量对时间效率并没有多大的影响,但随着实验数据量的增大,从机数量越大,那么时间效率就越好.
5 结 语
本文利用大数据技术中的spark平台在迭代计算上的优势,结合TextRank文档关键词抽取算法,实现了大规模文本关键词的快速高效提取.利用词语之间的联系构造文档候选关键词文本图,利用Spark所提供的GraphX图计算框架,计算出每个候选关键词的权重,选择一定数量权重较大的词语作为文本的关键词.实验表明,数据规模较大时,本文中的方法能够大大缩短计算时间,选出的关键词与人工标注的结果非常接近.文本图的构建是本文计算方法的基础,在后续研究中,将采用词法分析的方法,利用词语之间的相似度构建更加合理的文本图,对领域内的文本分词时,将添加专业词典,提高词语切分精度.
