基于卷积神经网络的自然场景门牌多数字识别研究
2019-01-22钟菊萍高静李军
钟菊萍,高静,李军
(1.广东技术师范学院计算机科学学院,广州 510665;2.广东恒电信息科技股份有限公司,广州 510635)
0 引言
图像中的字符识别如扫描文档和书籍已经在过去的几十年中被广泛研究[1],手写体识别也已被学术界和工业界广泛应用[2]。但从真实场景的图片中读取字符仍是一个困难的计算机视觉问题,因为它不像扫描文档那样背景干净,识别起来方便,真实场景中的字符图像本身极易受到自然环境的影响而出现细节模糊、视角变化、扭曲形变、背景掺杂、光照不均和类内差异等困难,使得计算机对真实场景中的数字识别仍是一个巨大的挑战,然而这对于一系列真实世界的应用来说却又非常重要。自然场景中的街景已经成为在线地图中的一部分,定位到街道,从中读取门牌号,和所在的地理位置进行比对,是现代地图制作的重要组成部分,建立更精准的地图,为智慧城市的智能交通、无人驾驶等提供精准服务。
从自然场景图像中分类字符的传统方法通常是使用手动特征提取[3]和模板匹配[4]。张帅等人[5]为了识别走廊环境的门牌号码,利用Robert边缘检测与形态学运算相结合的方法定位出门牌号图像的位置,再经过水平和垂直投影法、倾斜校正等操作分割门牌号,最后运用模式识别的方法识别出门牌号码。马立玲等人[6]利用正交判别的线性局部切空间排列算法(ODLLTSA)和支持向量机(SVM)方法相结合对门牌进行识别,用提取的特征来训练SVM分类器,用SVM分类器对新的门牌进行分类。
1 卷积神经网络
随着计算能力的提升,实验数据量的扩大,深度学习[7]的研究广泛地应用于图像识别、目标检测、语音识别等领域,并取得了很好的效果[8,9]。卷积神经网络是一种比较流行的深度学习网络,与传统的网络结构不同,它包含有非常特殊的卷积层和降采样层,其中卷积层和前一层采用局部连接和权值共享的方式进行连接,从而大大降低了参数数量。降采样层可以大幅降低输入的维度,从而降低网络的复杂度,使网络具有更高的鲁棒性,同时能够有效地防止过拟合。卷积网络主要用来识别缩放、位移以及其他形式扭曲不变的二维图形,并且可以直接以原始图片作为输入,无需进行复杂的预处理工作。与传统机器学习算法最大的不同,卷积神经网络是自动特征提取。
Yuval Netzer等人[10]提出使用K-means等无监督学习模型自动提取图像中的特征,用于街景数字识别,其效果远大于手工提取特征的方法。韩鹏承等[11]在AlexNet网络改进,马苗等[12]在LeNet-5上改进,均在SVHN数据集进行识别,对单数字门牌号码的识别率获得较高的识别率。
在多数字门牌号码的识别方面,谷歌公司的Ian J.Goodfellow等人[13]用深度卷积神经网络在SVHN数据集上训练了六天,在特定的阈值操作下,精确度达到了96.03%。国内的周成伟[14]利用Faster R-CNN框架实现对字符区域的定位,在获取字符区域的准确位置之后,利用循环神经网络(RNN)对该区域包含的字符串进行识别,并在SVHN数据集上进行验证,但是其识别率并不高。
我们用端到端的方法,构建单个数字识别网络,在不分割数据情况下,构建另一深度神经网络,同时识别多个数字,从而对自然场景中的门牌号码进行序列识别。在LeNet-5的基础上对算法进行改进,提高自然场景中门牌号码的识别速度与识别率。
2 构建网络结构
2.1 数据集简介
SVHN(Street View House Number)数据集来源于谷歌街景门牌号码,是一个真实世界的图像数据集,主要用于开发机器学习和图象识别算法。SVHN数据集有两种格式,分别包含训练集、额外集和测试集三个子集:
(1)裁剪后的数字,由600000多张32×32像素分辨率的图像组成,是从原始数据集中裁剪出来的单个街景数字。
(2)原始数据集,包含33401张图片用于训练,13068张图片用于测试,另有一组额外的202353张图片。
我们对两种数据集分别构建两种不同的网络结构,分别是单数字识别网络结构和多数字识别网络结构。
2.2 单数字识别网络结构
该模型是一个6层的网络结构,包括2个卷积层、2个下采样层、1个全连接层和1个输出层。输入图像是32×32的门牌街景图像,设置Padding为1,第一层的卷积层使用大小为5×5的卷积滤波器,卷积步幅为1,该层共有32个卷积滤波器,输出32个32×32的特征图。获得第一层卷积层的输出后,使用ReLU作为非线性激活函数,最后连接一个窗口大小为2×2,步幅为2的Max pooling层,得到32个16×16的特征图。第二层的卷积层使用大小为5×5的卷积滤波器,设置Padding为1,卷积步幅为1,该层使用64个卷积滤波器,输出64个16×16的特征图,随后采用和第一层一样的处理策略,得到64个8×8的特征图。全连接层的参数为256,在进行全连接时,先对上一层输出的参数加入Dropout,参数设置为0.6。最后用Softmax进行分类。模型结构如图1所示。
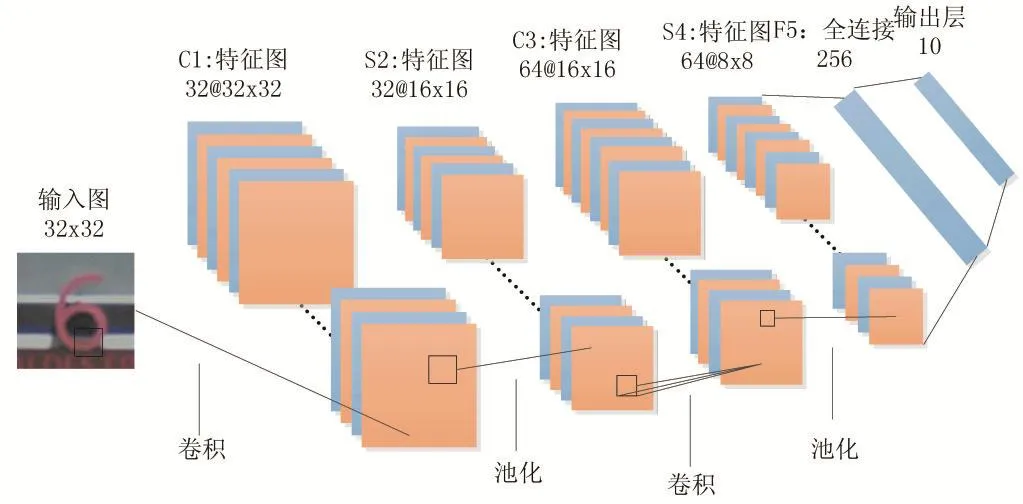
图1 单数字识别网络结构图
2.3 多数字识别网络结构
对于多数字,我们识别的长度是有限的,一般门牌号码都不会超过5位数字,所以我们把长度限定在5位。给定一个图像X,任务是识别图像中的数字,要识别的数字是一个多数字,S=s1,s2,s3,...,sn。我们要做的是训练每个数字的概率模型P,然后将它们组合成一个序列。并行用5个Softmax分类器进行分类。在实验中,我们引用公式[13]:
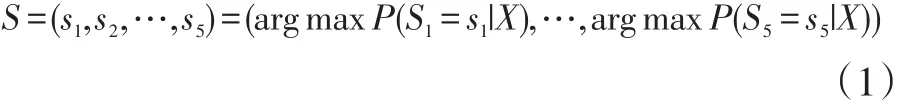
该分类器接受从卷积神经网络X中输出的特征。其中,S表示给定图像X中的序列,si是序列中的第i位。每个数字变量si都有10个可能的值。并且每个元素si都要被正确预测才算识别正确,因为只有全部号码被正确识别,才能在地图上找到精确的位置。每个字符的argmax是独立计算的。
多数字模型是一个11层的网络结构如图2所示,包括5个卷积层,3个下采样层,2个全连接层和1个输出层。所有的卷积核大小都是5×5,步幅为1。第一个卷积层输出32个32×32的特征面,第二第三个卷积层输出64个16×16的特征面。第四第五个卷积层输出128个8×8的特征面。所有的卷积层在输入上都使用Padding为1的零填充,以保持大小不变。所有的最大池化窗口大小都是2×2,步幅为2。两个完全连接层包含456个节点。第二个完全连接的层进入并行的5个Softmax分类器,每个分类器有0-10这11个类别,其中0-9表示数字0到9,10表示当前位置没有数字。这之前还按照以下方法进行数据预处理,首先在原始的SVHN图像上找到包含单个字符边界框的小矩形边界框,通过最小和最大边框坐标将其合并成一个边框,然后我们将这个框向四周扩展30%,最后裁剪包含边框的图像,并将其调整为32×32像素。由于图像中数字位数的不同,这就引入了一些比例变化。
3.2 实验结果与分析
3 实验
3.1 实验预处理
卷积神经网络的工作原理是自动提取分类器所需要的特征,因此本身不需要进行太多的预处理工作来增强数据特征。单数字识别的预处理只是进行了简单的去均值和灰度化处理,没有对图像进行图像增强或对比度增强等操作。灰度化公式如下:

其中Y′表示处理后的灰度图像,a、b、c分别表示R、G、B分量的数值比重,因为SVHN数据集中的背景偏蓝色,所以为了抑制蓝色背景信息会适当降低B所占比重,实验中,我们设置a=0.299、b=0.587、c=0.114。
多数字进行了同样的去均值和灰度化处理,但在
本文实验的环境为Windows Server 2008 R2 Enter⁃prise 64位操作系统,浪潮E5-2407CU,主频2.4GHz,16GB内存,使用TensorFlow开源库,Python编程语言。单数字识别我们构建的是一个6层的神经网络,2个卷积层,2个池化层,1个全连接层和输出层的训练模型。多数字识别构建的是11层的神经网络,5个卷积层,3个池化层,2个全连接层和1个输出层。实验总共迭代了50000次,单数字的训练时间3.5个小时左右,多数字的网络结构比较复杂,所以训练了27.5个小时左右。表1是调整单数字识别的一些参数和测试的准确率。
在表1中,C1和C3分别表示第一层和第三层的卷积核大小,从表中可以可知,当卷积核大小都为5×5的时候,Dropout=1.0也就是没有加入随机失活(Drop⁃out)这项超参数时,准确率是94.22%,比Dropout=0.6准确率是95.72%时降低了1.5个百分点,说明加入正则化后能够适当地提高准确率。我们试着改变卷积核的大小或者是全连接层节点的大小,准确率都会有所降低。我们与 HOG、K-means、LeNet5-SVM、PCA-CNN等方法的准确率进行对比,如表2所示。
我们用混淆矩阵来检测单数字识别的各个类别精度,如图3所示,横坐标的0-9表示实验预测分类,纵坐标的0-9表示真实分类。

图3 单个数字类别识别率
我们得到在单数字识别达到95.72%的识别率,多数字识别达到89.14%的识别率,多数字的识别如图4所示,我们从测试集中随机抽取10张图片进行测试,其中有9张能够正确识别,1张错误识别,发现图片比较模糊,背景颜色和数字之间的对比特征不明显,我们的模型难以正确识别。

图4 随机抽取10张测试图片的真实分类和预测分类
4 结语
本文提出了两种卷积网络模型,一种是单数字识别模型,训练3.5个小时,识别率为95.72%,表明该模型具有较高的识别率。在构建单个数字识别网络的基础上,构建多数字识别的深度神经网络模型,同时识别多个数字,自然场景门牌号码的多数字识别率达到89.14%,比单个数字识别低了6.58%,我们根据给定的边界信息裁剪图像,用数字边界来删除冗余信息,然后将它们规范化。我们设计的多数字识别模型限定了长度,假定最长只有5位数字,每个的数字分类器都需要自己的单独的权重矩阵,如果加大长度,会占用太多的内存导致程序无法运行。因此,在改进模型和实现其他识别技术方面还有很大的改进空间。
