Apriori算法在个性化学习中的应用研究
2019-01-22周显春肖衡高华玲
周显春,肖衡,高华玲
(三亚学院信息与智能工程学院,三亚 572022)
0 引言
随着大数据技术、人工智能、互联网技术和教育信息化技术的飞速发展,学习资源也呈现爆发式增长,造成学习者很难从浩如烟海的资料不能快速有效地找到适合自己个性化学习资源,甚至会出现认知超载、网络迷航[1]等异常现象。于是,个性化学习顺势而生,并已经成为教育技术领域的研究热点[2-3]。然而,在近两年的新媒体联盟地平线报告(高等教育版)[4]中,个性化学习被定义为是一项“了解但解决方案尚不清晰的困难挑战”,并且认为目前个性化学习最大的障碍就是如何把纷繁复杂的方法和技术转变成一套精简的策略,开发出有教学理论指导的个性化网络学习系统。
现在是大数据、人工智能时代,一切以数据为基础,用数据说话。通过获取学生个性特征、学习行为轨迹数据,利用机器学习算法能够精准识别学习中的个性化特征、推荐优秀的学习资源、学习路径,预测未来的学习行为、学习结果。对于预测结果欠佳的学习,需要尽早给予个性化学习强制干预、有效指导,让学习者能克服时空的限制实现自我导航,避免认知过载,提高学习者的学习兴趣,激化学习中潜在的学习潜能,最终达到最优的学习效果。
当前,国内外利用机器学习算法对个性化学习研究多集中在个性化学习路径推荐、个性化学习系统、个性化教学方法、个性化学习评价模型等几个方面。姜强等[5]基于大数据背景下以AprioriAll算法分析并通过实验验证群体信息挖掘个性化的学习路径。周海波[6]提出根据学生个性特征推送个性化的学习资源。牟智佳[7]为了对学习效果有效评价,采用基于聚类的层次性个性化化评价体系,有助于个性化评价系统的实现。以上研究都忽视一个关键内容,即学生的学习特征,包括学习风格,与知识点内容之间是有本质区别的。学生特征没有时序性,而知识点之间大多数是有时序性的。根据学生风格、特征使用Apriori进行聚类,都不能产生符合时间序列的资源或者学习路径推荐。
在海量的教育教学数据环境下,为了更好改善个性化学习效果,本研究主要从两个方面对以前的研究成果进行改进。一是对Apriori算法在Spark分布式计算框架并行化,改善算法的实时性;二是利用学习目标和知识点修改Apriori方法推荐的知识点序列,让学习内容或路径更有针对性,改善个性化学习的质量。
1 Apriori算法研究
Apriori算法是R.Agrawal用于解决关联规则问题的数据挖掘方法[8],得到广泛的应用。随着数据规模、维度的不断增大,造成该算法在实际场景运用中也存在时间延长、内存不足的问题。为了改善其挖掘的效率,利用分布式架构Hadoop、Spark,大量的学者并行化Apriori算法研究,可以大幅度提升数据挖掘的效率。对比Hadoop平台,Spark的效率更高[9-10]。
1.1 基于Spark的Apriori算法优化
Spark引入弹性分布式数据集RDD数据模型,集成了节点集群内存,适合迭代计算,不需要访问磁盘。相对于Hadoop,Spark更适合分布式处理场景。Trans⁃actions、Action是Apriori算法并行化迭代计算实现的核心[8]。Apriori在Spark上实现分为两个阶段,第一阶段迭代求出每个项集,第二阶段针在第j个项集前提下求出第i+1项集的候选集。
输入:数据源 DataSet,最小支持度阈值Count_min_sup。
输出:K-项频繁集。
#频繁集合生成伪代码
(1)采用并行化得到分区的RDD,分发给worker;#每个worker节点可以独立工作;
(2)flatMap()作用于数据集中的 Transaction,读取每个中的Item;
(3)map()转换 Item 成键值对(Item,1);
(4)reduceByKey()用于计算每个Item的出现的次数,filter()对于Item的次数小于Count_min_sup的进行剪枝;
(5)最后,把剪枝后的Item转换成Set中保存。#规则生成伪代码
(1)转换Item的Set为候选项集Set(T);
(2)频繁集合的元素进行自连接,产生K+1候选集;
(3)重复频繁集生成过程。
1.2 基于学习目标和知识点的Spark的Apriori算法优化
经典或并行化的Apriori算法首先要从Transaction中获得Item出现的次数,再根据次数阈值过滤、自连接生成规则。基于学习目标的并行化Apriori,针对学习目标,先过滤Transaction,即Transaction的Item不包含学习目标的关键词(知识点关键词)直接删除,可以大幅提升其推荐的效率。
相对于其1.1并行化Apriori伪代码,需要修改两句一是频繁集生成的第二句为:flatMap()作用于数据集中的Transaction,filter读取每个中的Item,过滤掉没有学习目标关键词的Transaction;二是把规则生成伪代码的第二句修改为:频繁集合的元素进行自连接,然后根据知识点、知识点的关系排列Item顺序,产生有序Item的K+1候选集。
1.3 基于Spark的Apriori算法性能比较
目前,Spark支持四种运行模式。本地单机模式、集群模式,而集群模式又分为基于Mesos、基于YARN、基于EC模式。本文的Spark分布式集群基于YARN,即Hadoop2[11]。
(1)实验条件
软件:Ubuntu Server 17.10,Hadoop 2.7,JDK 1.8。硬件:6台联想商用机,CPU是主频3.4GHz的Intel酷睿i5,硬盘容量512G,内存8GB。
实验数据:数据量大小为2G,Transaction平均长度为38MB,共120个Item项集,包括约500万条Trans⁃action记录。
实验计划:首先,采用经典Apriori算法以及保持10个节点的集群环境下的并行化MapReduce-Apriori、Spark-Apriori算法,在处理不同数据集的情况下,不同的算法运行时间关系如图1所示;其次,采用200万条数据集,从一台机器开始,以2的倍数递增机器数、节点数。MapReduce-Apriori、Spark-Apriori算法分别在1、2、4、8节点时完成任务的运行时间结果如图2所示。基于学习目标和知识点的Spark-Apriori简称为改进的Spark-Apriori。
由图 1可知,无论是 MapReduce-Apriori还是Spark-Apriori算法都比经典Apriori算法的完成相同任务执行时间短、效率高。随着数据量的增加,分布式算法优势更加明显,而且Spark-Apriori比MapReduce-Apriori更适合大数据环境,原因是Spark-Apriori算法是基于内存进行迭代计算,大大减少数据需要I/O读取时间,而且因为简化运算,改进的Spark-Apriori比Spark-Apriori的运行时间更短。由图2可知,随着worker节点数增多,改进 Spark-Apriori、Spark-Apriori、MapReduce-Apriori算法执行时间越来越短,说明计算节点worker节点越多越能提高算法效率。
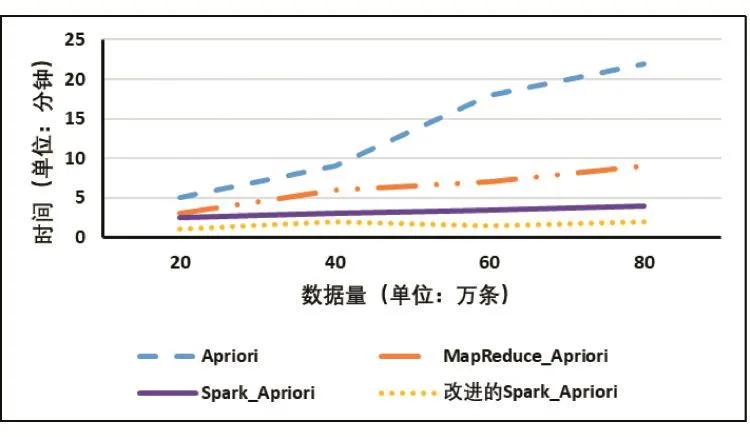
图1 三种算法不同数据量的运行时间图
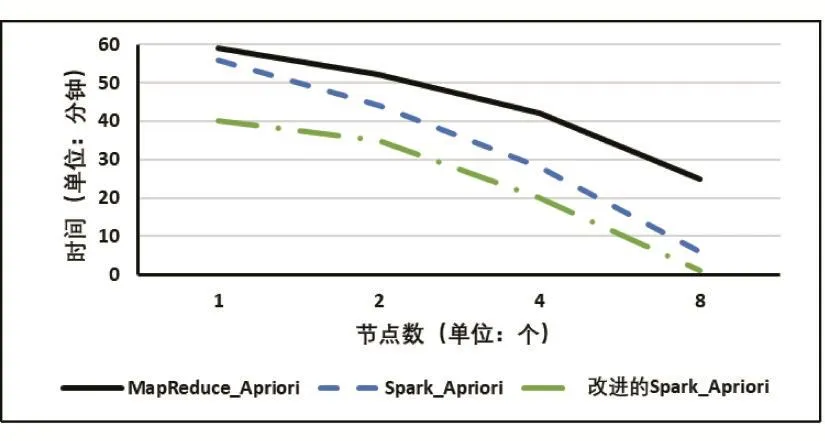
图2 两种算法在不同节点数的运行时间
2 基于Spark并行化Apriori的学习规则分析与挖掘
Apriori可以不仅应用在学生的成绩分析上[12],如知识点与学生能力[13]之间的相关性,而且还可以与学生风格相结合。本研究在个性化学习的应用中最大的创新点是根据学习目标,即需要掌握的知识逆推学习过程。如果要完成该学习目标,需要掌握那些知识点序列。知识点之间不仅有时间顺序,而且还可以根据学生的风格和学习能力可以动态调整,以最优的路径掌握知识点。
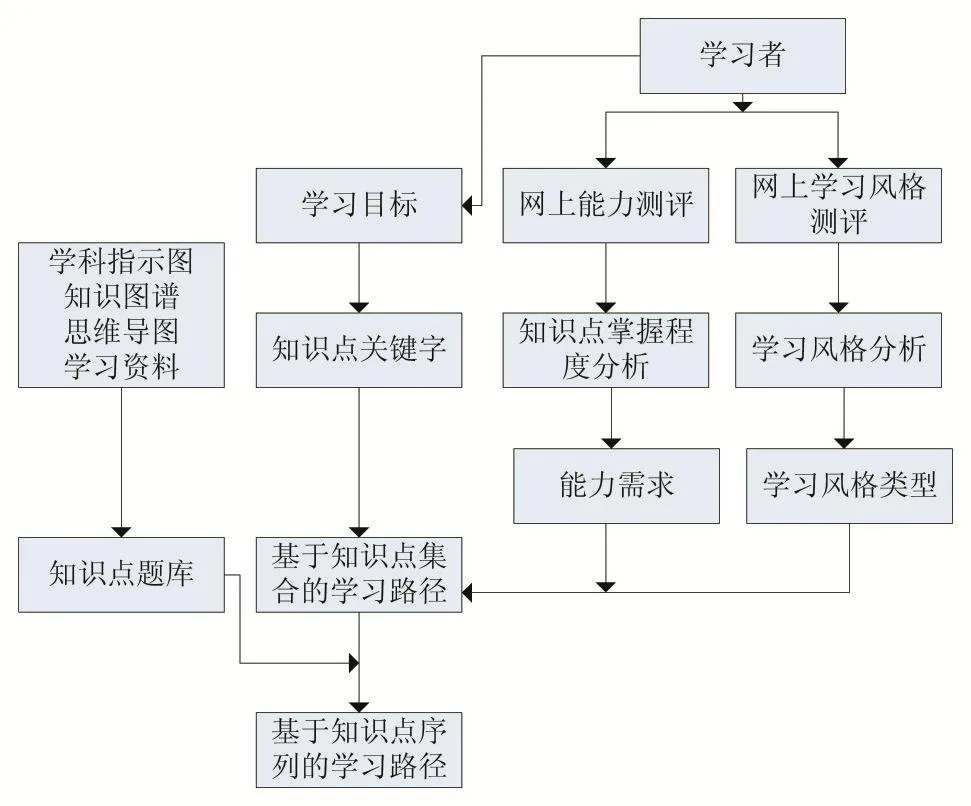
图3 基于学习目标的个性化学习推荐路径生成架构
2.1 基于并行化Apriori的知识点题库系统构建
以教育教学的布鲁姆认知目标为依据,构建学科知识点模型、知识思维导图,然后利用jieba+Apriori方法完成知识点、知识点关系的提取和集成。例如,利用闵宇锋[14]等提出方法可以生成进制二和字符表示知识点及关系如图4。
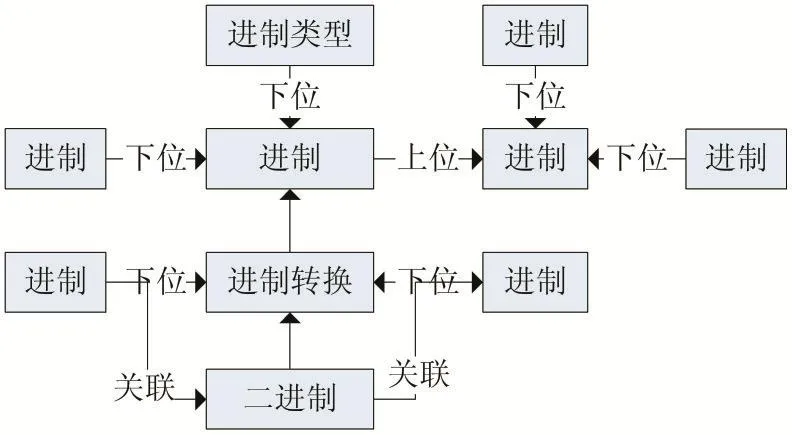
图4 进制、字符表示知识点及关系图
2.2 基于并行化Apriori的知识点与能力、学习风格之间规则的分析
(1)收集数据
在学生确定学生目标之后,要求学生填写基本特征的调查表,涉及内容有学生姓名、性别、学号、学习风格、学习时间等内容,接着学生参加基于学习目标的知识点题目测试,测试结果能够动态调整学习路径。
(2)基于学习目标和知识点的Spark的Apriori算法的知识点推荐
在基于学习目标的并行化Apriori算法完成学习路径推荐后,使用知识点对学习路径进行修正。例如,中文字符表示知识点的学习。
①根据学习风格、学生特征[4]可以获取Transac⁃tion,但是通过中文字符、汉字、字符表示等关键词筛选后剩下少量的 Transaction;如:{进制,字符表示},{进制,西文,汉字},{十进制,二进制,西文,汉字输入,汉字存储,汉字输出},……
2.3 基于学习目标和知识点的个性化学习推荐路径学习绩效评测
为了体现本研究的效果,以物流专业50名学生作为研究对象,讲授《计算机应用基础》课程。按照学号计算机随机均等分组,每组25人,一组自主学习,另外一组按照推荐学习路径学习,采用灵活的在线和翻转课堂方式开展一个学期的学习。期末考试后,随机挑选4位学生,从网上平台提取学习数据和学习成绩对已完成学习绩效进行客观分析,如图5、6所示。
由图5知,自选学习路径的学生所花费学习时间要多于按照个性化推荐路径学习的学生;由图6知,使用个性化推荐路径学习的学生成绩要好于自选学习路径的学生。因此,学生按照个性化学习路径学习时,无论花费的学习时间还是产生的学习效果的效率都自选学习路径要好。
3 结语
在海量的教育教学数据环境下,为了更加改善个性化学习的效果,本研究以学习目标为核心,利用在Spark平台上并行化Apriori方法逆向推荐基于有序知识点的学习内容或学习路径。经过教学实践验证,基于学习目标的个性化学习推荐路径能够大幅提升学习者学习效率,可以解决认知超载、网络迷航等问题,也为该类平台的实现提供研究思路。
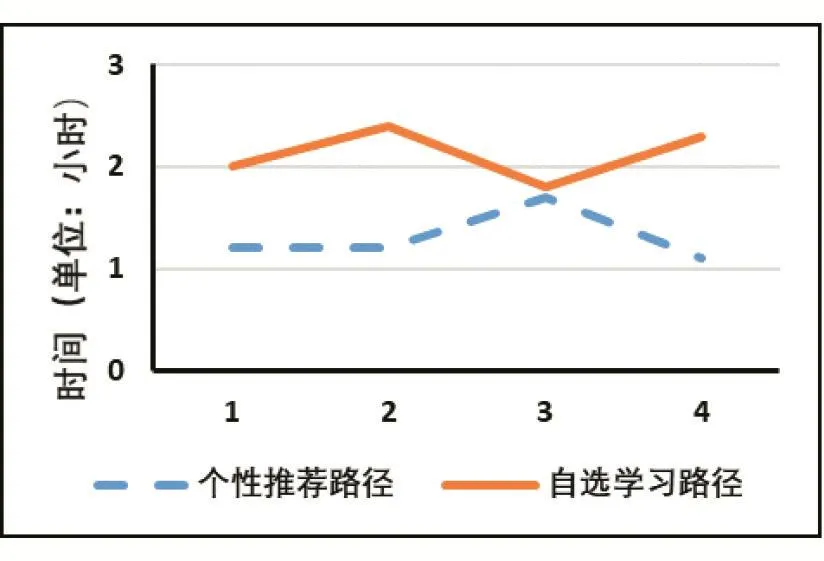
图5 不同学习组的学习时间比较
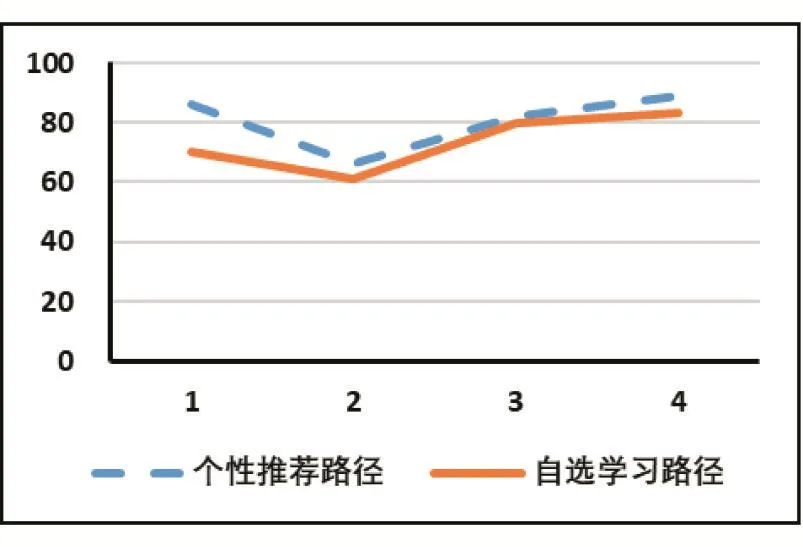
图6 不同学习组的学习成绩比较
