基于多尺度特征融合的Faster-RCNN道路目标检测
2019-01-18章东平
陈 飞,章东平
(中国计量大学 信息工程学院,浙江 杭州 310018)
目标检测作为计算机领域的一个重要分支,在自动驾驶、智能视频监控、安防领域都有广泛的应用.目标检测主要解决的是图片或视频帧中目标的what与where问题,即是否存在目标,并对已判断出的目标给定对应的边界框.目标检测对人类来说并不困难,人眼对图片的不同目标的颜色模块,人眼能很容易的进行定位并给出相应类别.但对于计算机而言,由于图片的目标物体都是RGB像素矩阵,很难直接得到目标物体的确切位置,再加上有时是多个物体的混叠以及一些背景信息的干扰,以致增大了目标检测难度.传统机器学习通过对目标提取人工选择特征.如HOG[1](histogram of oriented gradient)、SIFT[2](scale invariant feature transform)等方法,然后将提取特征输入到分类器,如SVM[3](support vector machine)、AdaBoost[4]等进行分类识别[5].人工特征构造复杂且泛化性差而滑动窗口又有检测速度慢等缺点.近年来卷积神经网络在图像识别目标检测等领域取得了突破性进展,掀起了新的研究热潮[6].
1 相关工作
物体结构能很好的反映出目标信息,因此,将目标结构作为目标特征用于检测,可以较为准确的实现目标检测目的.TRIGGS和DALAR[7]采用梯度方向直方图HOG特征描述算子在行人检测目标任务中取得了较好的结果,FELZENSZWALB[8]等人在目标识别中使用了part-based模型来表示目标,并在TRIGGS和DALAR等人基础上采用了混合多模板模型,每个模板含有可移动变形部分,并结合Latent SVM分类器进行训练.实验证明该模板比单一模板具有更好效果.但由于基于滑动模板的目标检测大多采用密集采用方法,这种方法严重影响了目标检测速度.Dollar[9]等人在2014年提出了一种新的快速特征金字塔计算方法,首先对原始图像进行稀疏采用,然后给出特征金字塔相邻层间的幂指运算,并使用统计方法进行运算.
随着计算机硬件技术的快速发展,特别是GPU计算性能的开发和提升以及数据量的几何式增长,促进了深度学习领域的蓬勃发展.2014年Ross Girshick[10]首先把深度学习方法RCNN(区域卷积神经网络)应用于目标检测,由于采用了Selective Search(选择性搜索方法),直接对原图像提出2 000多个候选框,并直接对2 000个候选框输入CNN(卷积神经网络)提取相应的特征,然后通过SVM(支持向量机)对目标进行分类,并采用边框回归(Bounding Box Regression)确定和校准目标位置.由于每张图片要做2 000多次的前向传播,导致检测速度过慢.鉴于此,Ross Girshick 团队提出了其改进版Fast-RCNN,Fast-RCNN采用了直接对整张图片做CNN特征提取,并采用了深度学习常见的Soft-max分类器来替代SVM分类器,以提升其检测速度.由于Fast-RCNN仍旧采用Selective Search方法来提取候选框,影响了检测速度.所以在Fast-RCNN改进版Faster-RCNN提出了RPN(区域提议网络),改进了之前的Selective Search方法,通过在RPN生成候选框,并在RPN中对相关边框做出是背景还是目标的初步过滤处理,从而改进了原始Selective Search生成提议窗口过慢的缺点.
YOLO[11]算法的解决办法是通过把目标检测问题转化为回归问题求解,采用一个卷积神经网络来直接获得要预测的bounding box及对应的类别概率.算法首先把输入图像均等划分为S×S个grid cell(框格),然后对划分的每个框格预测N个bounding box,而预测取得的每个bounding box将包含5个预测值:x、y、w、h以及confidence(置信度分数).其中x、y是bounding box的中心坐标点,而w、h指的是bounding box的宽高值.每个bounding box对应一个置信度分数,若检测到的框格中没有待检目标物体,其置信度值设为0,若有,其值就是预测bounding box与ground truth的IOU(交并比)值.至于判断框格是否有目标物体,若一个物体的ground truth的中心点坐标在一个框格中,那么由该框格负责这个目标检测.
SSD[12]方法为了避免利用太低层特征,SSD从后的conv4_3开始,又往后增加了几层,分别抽取每层特征,并在每层特征上分别使用了Soft-max做背景和目标类别分类处理,并采用边框回归对目标进行定位.由于SSD对高分辨率的底层特征没有再利用,可是这些底层特征对小目标的检测具有重要作用.
FPN利用CNN的金字塔层次结构性质(从低到高的语义特征)构建从低到高的语义特征金字塔.CNN前馈计算是从下到上的,特征图通过CNN,一般特征图是越来越小的,也存在同样大小的,此时称为相同网络阶段(same network stage).在FPN中,每个阶段定义一个金字塔级别,由于每个阶段最深层具有最强的表示特征,所以选择每个阶段的最后一个输出层作为参考层.并实现特征融合效果.
2 多特征融合的特征金字塔结构
本文针对原FPN(图1)的特征提取融合结构上进行改进(图2),原有特征结构进行增加,以实现丰富语义特征的融合.特征融合的路径自下向上,通过卷积核运算,对每一次卷积核的输出构成一个特征金字塔.并对每一特征金字塔同一网络阶段做特征激活输出,确保获得每个阶段的最强特征.对相关模块分别作相对原图像大小的2,4,8,16像素步长.对自上至下路径,则将原本获得的特征输出做1×1的卷积操作实现横向连接.相邻网络特征层的特征大小成2倍比例.
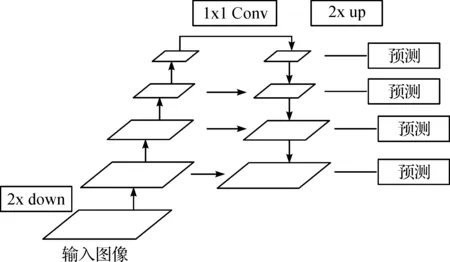
图1 特征金字塔结构Figure 1 Feature pyramid architecture
3 特征融合目标检测网络结构描述
本文提出的多特征融合目标检测算法在原有检测算法中增加了FPN层,实现多层特征融合,充分利用各个卷积层的特征图取得的不同特性.低卷积层的高分辨率有利于检测小物体目标,而高卷积层拥有较大感受野,可以用来检测大目标物体.本文主网络结构采用Faster-RCNN,Faster-RCNN在原Fast-RCNN目标检测方法上增加了RPN,对每个像素点生成锚框,并对每个锚框做出背景与目标的判断,过滤掉背景锚框,并对锚框做边框回归处理,然后再把选择有目标锚框输入到ROI Pooling层以减小物体检测的区域敏感性.其中锚框的生成大小满足以下要求:{(w×h),(αw×αh),(wγ,h/γ)}.(其中锚框的大小w,h表示初始边框的宽高,α,γ表示边框缩放比例,且α∈(0,1],γ>0,当生成n个大小,m个比例时,则共产生有m×n个锚框).由特征融合的网络结构图描述,将输入的RGB三通道彩色图片做四次卷积运算,构成自下到上的特征金字塔结构Conv1_1至Conv4_1,然后从Conv4_2至Conv1_2构成自上到下的特征金字塔结构.按特征金字塔结构图描述,由原来的自下到上的同一网络阶段做1×1卷积核操作实现特征融合,并对同一网络阶段的融合特征在做2×2卷积核操作以解决上采样造成的混叠效应.Conv4_2,Conv3_2,Conv2_2,Conv1_2的输出结果分别输入到RPN.虽然看上去较为复杂,但由于RPN思想更为直观.首先提议预先配置好的一些区域.然后通过神经网络来判断这些提议区域是否是感兴趣的,是的话,则在最后输出时再进行预测,得到一个更加准确的边框,这样我们能有效降低搜索边框的代价.
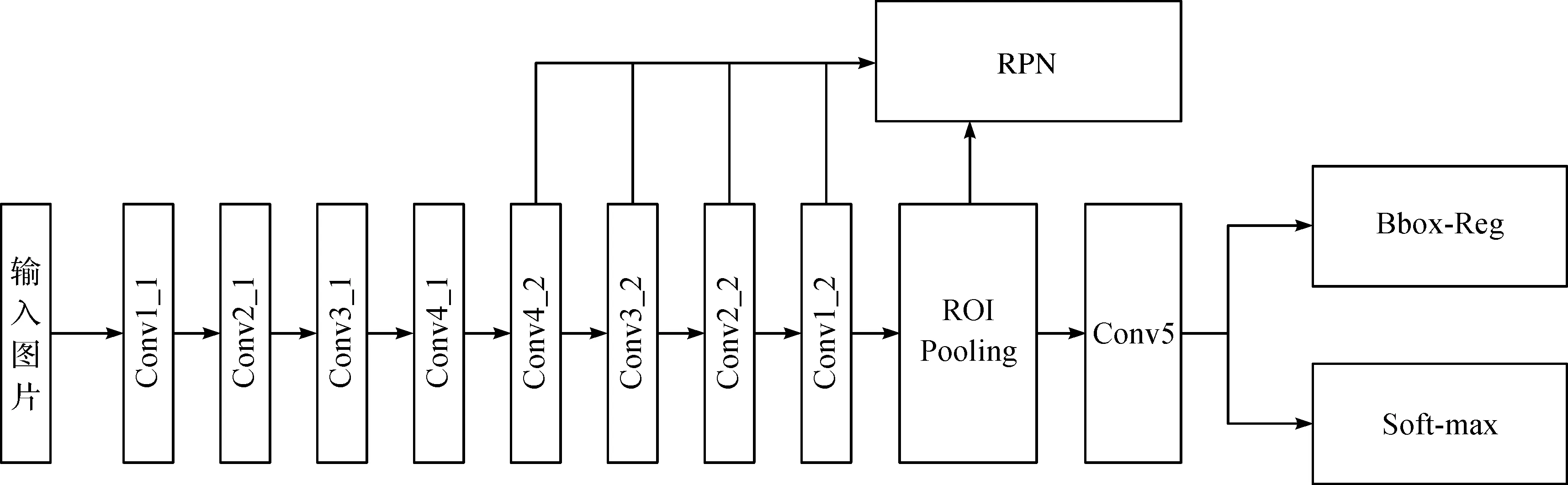
图2 特征融合网络结构图Figure 2 Feature merged network architecture
4 训练方法
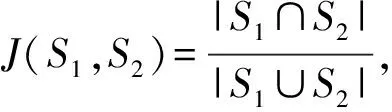
Losscls=-γ(1-pi)λlog(pi)
(1)
常见边框回归损失函数一般使用平方损失函数Loss=x2.但该损失函数对较大的误差惩罚过高,可以通过采用绝对损失函数来降低惩罚Loss=|x|.由于零点处左右导数不相等[15].通过增加平方项使其变得更为平滑.
(2)
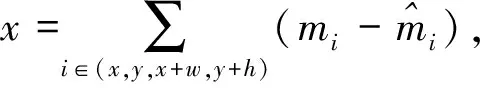
5 结果分析
本文相关实验采用的服务器CPU配置为Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20 GHz,GPU配置为NVIDIA TITAN X所采用深度学习框架为mxnet.训练使用的KITTI数据集共有7 481张训练图片,7 581张测试图片,采用分离验证方法,将数据分成训练集7 481张,验证集3 800张和测试集3 781张图片.首先用训练集获得训练模型,再用验证集评估模型性能,如图3、图4,并用测试集获得目标检测的测试性能,如表1[16].

图3 基于特征融合的Faster-RCNN检测效果实例Figure 3 Detection performance based on merged feature Faster-RCNN

图4 基于Faster-RCNN的检测效果实例Figure 4 Detection performance based on original Faster-RCNN architecture
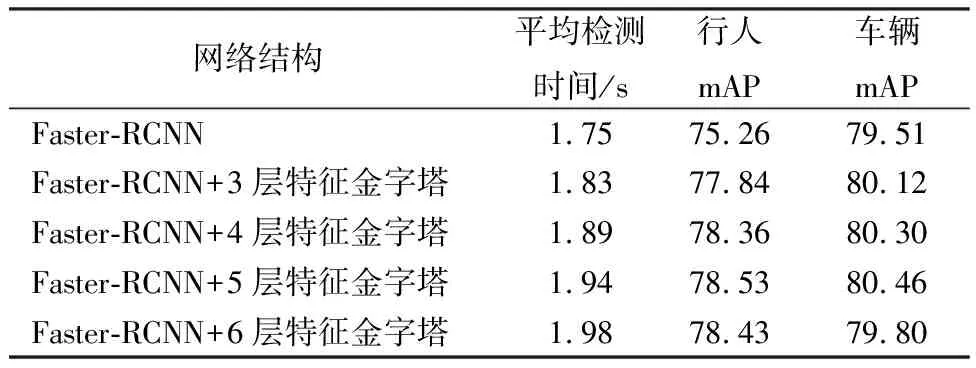
表1 不同网络结构对分类性能对比Table 1 Comparation of various network structures on classification performance
观察上述实验验证结果,当增加卷积特征层层数,Faster-RCNN的检测结果有相应的提高,当特征层选择为5时,在此次实验中能取到较好的结果.在卷积特征层的的特征融合部分增强了局部和全局的特征信息,获得检测目标更为丰富的语义信息,从而提升了检测精度.但更多的特征融合层可能会增加过拟合风险,导致后续的结果检测率下降.而从最终的检测效果可以看到,改进的算法能检测到较小的目标物体,更具有实用性.
6 结语
本文提出了一种基于特征融合的神经网络目标检测方法,根据在原Faster-RCNN的结构基础上结合能实现丰富语义特征的特征金字塔网络结构.在公开KITTI数据集上的对比实验结果表明增加特征金字塔后对目标检测率能有一定程度的提高,特别是对小目标物体的检测效果有一定的提升.同时,采用关注损失函数替代之前的深度学习的交叉熵损失函数.最后的实验结果表明对原有的Faster-RCNN对比效果有一定的提升.由于对遮蔽面积较大的目标车辆检测效果还不明显.后续工作还需要对上述的算法缺陷进行针对性的改进和优化.
