主题和时间特征融合下的服务消亡预测
2018-12-19陈曙辉范玉顺
陈曙辉,范玉顺
(清华大学 自动化系,北京 100084)
0 引言
近年来,随着信息技术的飞速发展,电子商务[1]进入一个迅猛发展的阶段。商业服务和信息支撑技术不断融合,软件即服务(Software as a Service, SaaS)[2]和面向服务的体系结构(Service-Oriented Architecture, SOA)[3]的普及,使得商业服务系统的开发不再是个难题。以某一订餐平台为例,订餐平台的开发者无需再去重复开发地图显示和定位功能、餐馆名称和菜品管理、天气信息获取、送餐员管理等功能模块,而是通过调用互联网上的各类Web服务,将其组合在一起,就能轻松快捷地完成订餐平台所需要的各种功能。在这种环境的驱动下,互联网上Web服务的种类和数量与日俱增。
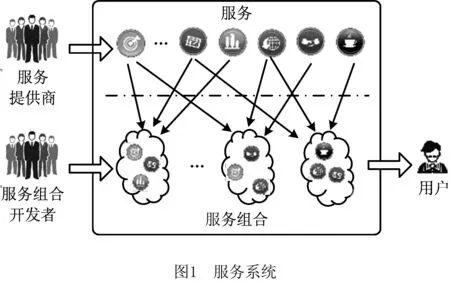
在一个服务系统中,单一的服务个体(service)由于功能性单一,很难满足用户复杂多变的需求,更多的情况是将多个服务集成为一个服务组合(service composition),以服务组合的形式为用户提供服务[4]。服务组合的产生与使用为用户提供了更为便利的使用方式,但也带来一些新的问题。Web服务的数量与日俱增,如Web服务生态系统[5]描述的那样,相似功能的Web服务之间相互竞争,失利的Web服务会走向消亡。在上述应用场景下,消亡的Web服务会对使用它的服务组合带来巨大损失和影响。例如上例中,构成订餐平台的地图显示和定位、餐馆管理和菜品管理、天气信息服务中,无论哪一个出现问题,都会使订餐平台出现系统崩溃。再以ProgrammableWeb[www.programmableWeb.com]为例,截止到2016年8月,ProgrammableWeb提供了15 368个应用程序编程接口(,Application Programing Interface, API)和7 822个Mashup。其中:API可以为用户提供较为单一的功能,可视为单个服务;Mashup则综合了多个API,能够满足用户较为复杂的需求,可视为服务组合。统计表明,平台中282个API失效导致1 527个Mashup失效,给Mashup的开发者造成了极大的损失。因此,服务组合开发者在选择服务时,必须考虑服务的可靠性,避免因单个服务个体失效造成整体崩溃,从根基上提高服务组合的持久可用性。
在研究Web服务可靠性的相关问题中,Web服务失效问题[6-9]的研究热度更高。Web服务失效与本文研究的Web服务消亡问题存在一定的相似性,二者都是研究因Web服务不能正常工作而对整个服务系统造成的影响。前者Web服务本身并没有问题,通常是由于网络环境或者网络节点等原因导致服务失效。在这类Web服务失效中,随着网络环境的改善、受损网络节点的修复或网络节点的调整,很快又可以恢复使用,从长远角度来说并不对服务组合和整个服务系统造成太大影响。Web服务消亡是Web服务在当前服务系统中永久失效。因为Web服务本身退出服务系统不再继续提供服务,所以无法通过调整网络等手段恢复,必然导致相关的服务组合彻底崩溃,如果大量的服务组合出现问题则会威胁到整个服务系统的稳定。
Web服务消亡最直观的原因是因Web服务在同类服务激烈的竞争中处于劣势,Web服务的开发者从战略的角度停止了对Web服务的继续支持。在相关研究中,夏博飞等[10]使用服务标签标注同类服务,利用加权服务网络分析法分析竞争失利的Web服务,从而为服务组合开发者提供有效的参考。这类方法存在的问题是标签的准确性问题,大多数服务系统中的标签由开发者填写,出于竞争和宣传的原因可能不会如实填写,影响了分类的准确性;另外,标签为手工标注,存在标签种类太多、标签格式不统一、维护困难等问题。Web服务消亡另外一个容易理解的动机是,实力欠缺的供应商在Web服务处于竞争劣势时更容易放弃坚持,相反实力强劲的供应商则因为品牌和信誉等原因坚持得更长久。Xia等[11]引入Web服务供应商的信息,并依此建立了服务特征融合建模(,Service Comprehensive Feature Modeling, SCFM)算法,得到了很好的预测效果,但是供应商信息等个性化数据受限于服务系统,甚至受限于当前服务系统的版本更新。
近年来,随着机器学习的兴起,用机器学习方法提取文本特征的方法[12-17]得到了广泛应用,从Web服务的描述、用户的反馈文本中提取Web服务的主题特征成为可能。而在这些主题中,随着社会流行趋势的变化,有一些主题随着时间的发展必然整体走向没落,以这些主题特征为主要功能点开发的Web服务退出服务系统的原理机制其实与Web服务之间的竞争因素并不相同。另外,从实验数据中可以观察到,一个新的服务,如果在产生的若干时间段内未能及时得到调用和认可,就很容易淹没在新生的Web服务大潮中,从而使被调用的几率大大降低,实验表明长时间未被调用的服务出现服务消亡的几率大为增加。本文从主题消亡的角度,结合时间敏感的因素,对Web服务消亡进行了预测。在ProgrammableWeb数据集上的实验验证表明,该方法能有效地从服务系统中筛选出消亡的服务,从而为服务的使用者提供有效的参考。
1 问题提出
本文工作是在服务系统环境下进行服务失效研究。对服务系统的描述如图1所示,一个服务系统包括服务和服务组合两种类型,服务提供商开发单一功能的服务,服务组合开发者则利用这些服务组合出功能丰富多彩的服务组合,用户更倾向于使用满足复杂需求的服务组合而非功能单一的服务个体。从这个角度给出研究环境和研究问题的定义如下:
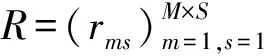
定义2服务消亡预测。在服务系统G中,定义服务消亡向量P=[p1,p2,…,pj],其中pj∈[0,1]为第j个服务出现服务消亡的概率值。pj值越大,其服务退出的可能性越大。
通过上述定义将较为抽象的服务消亡现象转化为以概率值度量出现服务消亡可能性的研究方法,在进行特征分析、建立模型并解决问题前,首先介绍使用到的一些数学模型。
1.1 泊松分解
在用于推荐的机器学习算法中,使用文本主题特征提取的有很多,常见的有隐狄利克雷分布—主题模型(Latent Dirichlet Allocation, LDA)[12-13]、泊松分解[14-15]和深度学习[16-17]等。LDA通过模拟人们的写作过程,从语料库中挑选词汇构成文本来训练模型,但是LDA认为文本中的词汇是从词袋中随机挑选而得,忽视了一篇文章中词汇间存在的内在关系,并不完全符合实际情况;深度学习通过构建多层神经网络,抽象出较为准确的主题特征,然而深度学习在学习代价上,特别是学习矩阵维数较大、中间层设置较多的情况下,需要较大的计算量;泊松分解认为文档的词汇使用情况满足某一特定参数下的泊松分布模型,通过EM算法不断调整参数,使预设模型逐渐逼近文档的真实模型,其缺点是对模型参数要求较高,但对于稀疏矩阵,通过使用独特的训练方法,可以大大降低模型的训练成本。与前两种算法相比泊松分解有极大的优势,而服务系统中的服务主题特征提取恰好满足这种情况。
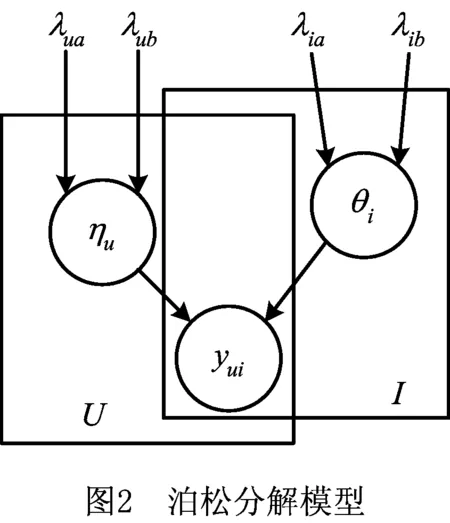
泊松分解在2013年由Prem Gopalan提出[14],作为机器学习中比较新的研究成果,泊松分解属于产生式概率模型,如图2所示。泊松分解本质上仍然是一种非负的矩阵分解算法,与传统的非负矩阵分解(Nonnegative Matrix Factorization, NMF)[18]不同的是,对于一个满足泊松分布的系数矩阵,泊松分解在非负矩阵分解的基础上,通过调整系数使分解后得到的两个矩阵都满足Gamma分布,即
ηu~Gamma(λua,λub);
θi~Gamma(λia,λib);
(1)
式中(λ·a,λ·b)表示Gamma分布的形状参数和尺度参数。
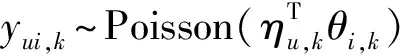
ηu,k~Gamma(λua,k,λub,k);
θi,k~Gamma(λia,k,λib,k);
(2)
式(2)的联合概率公式可以表示为
(3)
使用变分推断的前提假设是各个Gamma分布之间相互独立。对于式(3)中的每个ηu,k(∀k∈K),从中抽取与其相关的部分,得到
p(ηu,k|yui,k,λua,k,λub,k)
(4)
由此得到迭代公式
(5)
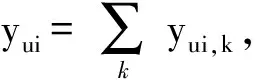
=exp(Eq[log(ηu,kθi,k)])∝log(ηu,k)+log(θi,k)。
(6)
式中Eq(·)表示在分布q下的期望。因为log(ηu,k)=Ψ(λua,k)-log(λub,k),所以φui,k的迭代公式为
φui,k←exp{Ψ(λua,k)-log(λub,k)+Ψ(λia,k)-
log(λib,k)}。
(7)
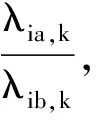
(8)
可以看出,当yui=0时无需计算φui,k,对于稀疏矩阵而言,泊松分解的这个特性可以节省很大一部分计算量。现实生活的大多数服务系统在海量的Web服务队列中,其服务组合调用的往往只有其中少数几个,因此对于服务系统的特征提取,使用泊松分解构建模型是非常适宜的一种方法。
1.2 极限学习机ELM
预测服务消亡与否在本质上属于分类问题,目前常见的可用于分类的算法有Logistic回归、支持向量机(Support Vector Machine, SVM)、极限学习机(Extreme Learning Machine, ELM)。依据摩尔—彭罗斯广义逆理论提出的ELM[19]算法,在保证较优的训练结果的前提下,具有更快的训练速度。
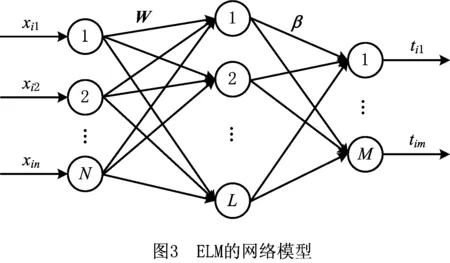
ELM在结构上是一种单隐层神经网络,通过一步计算就可以求出网络的输出权值,其模型结构如图3所示。对于一个有N个样本点的数据集(Xi,Ti),i=1,…,N,其中Xi=[xi1,xi2,…,xin]T∈Rn,Ti=[ti1,ti2,…,tim]T∈Rm。设置一个有L个隐层节点的单隐层神经网络,公式为
(9)
式中:g(x)为激活函数,对于第j个隐层节点,Wj=[w1j,w2j,…,wnj]T为输入权重,βj=[βj1,βj2,…,βjm]T为输出权重,bj为偏置量。
ELM的训练目标是使输入Xi通过网络训练后与输出Ti之间的误差最小,即
(10)
将式(9)代入后得到
(11)
H(W1,…,WL,b1,…bL,X1,…,XN)=
则
(12)
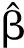
2 特征分析
2.1 主题特征分析
采用机器学习算法从服务系统中提取主题特征的方法通常用于寻找服务系统中使用频繁或者热门的Web服务和服务主题,以便对服务系统中的热门服务进行分类、聚类、推荐等。服务消亡需要搜寻服务系统中容易退出系统的服务,这类服务通常是不常使用或者冷门的,传统算法模型并不适用。本文的主题分析侧重于通过服务系统的主题特征分析,寻找其对服务消亡的潜在因素和影响,从而提高服务系统的整体稳定性。
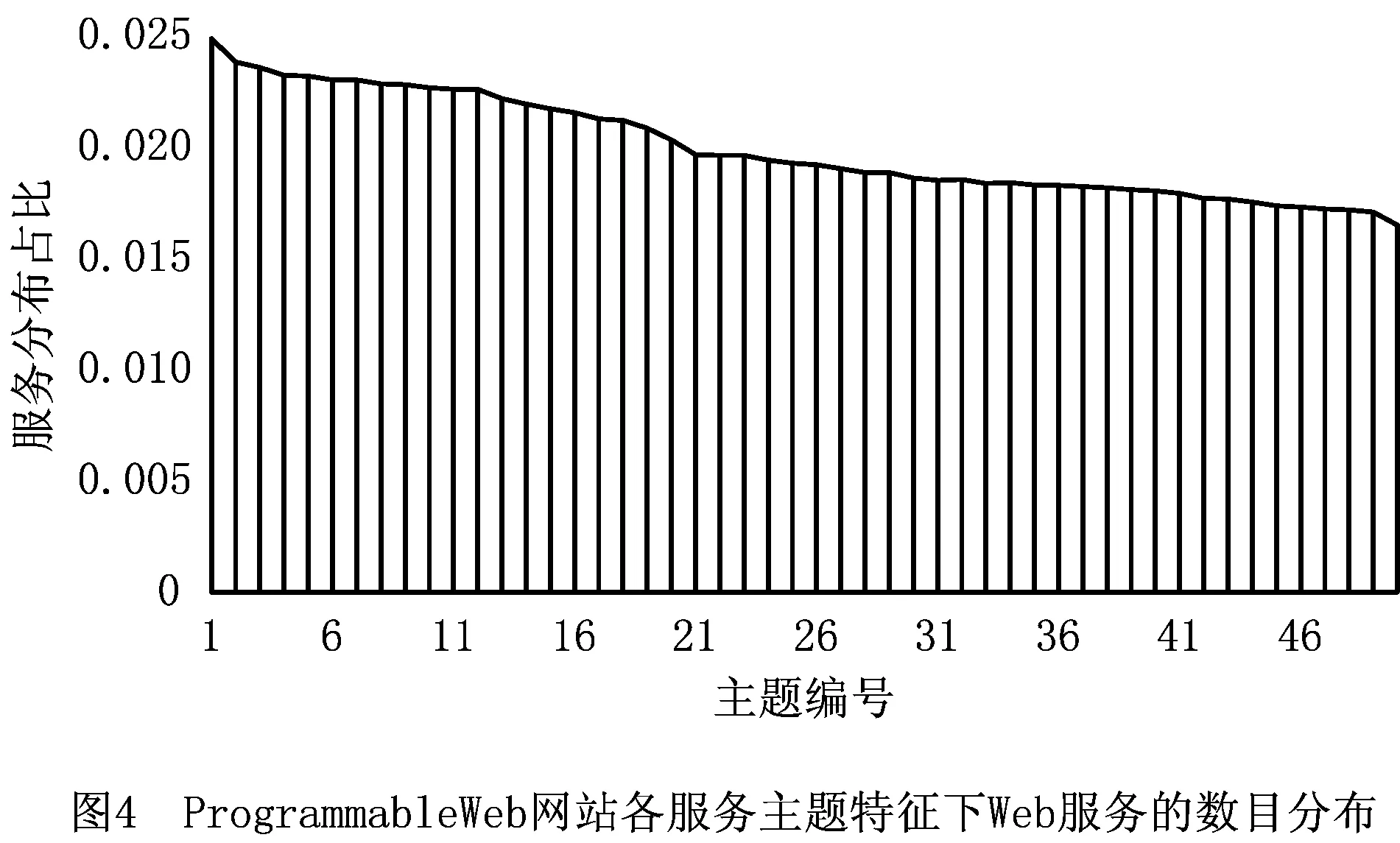
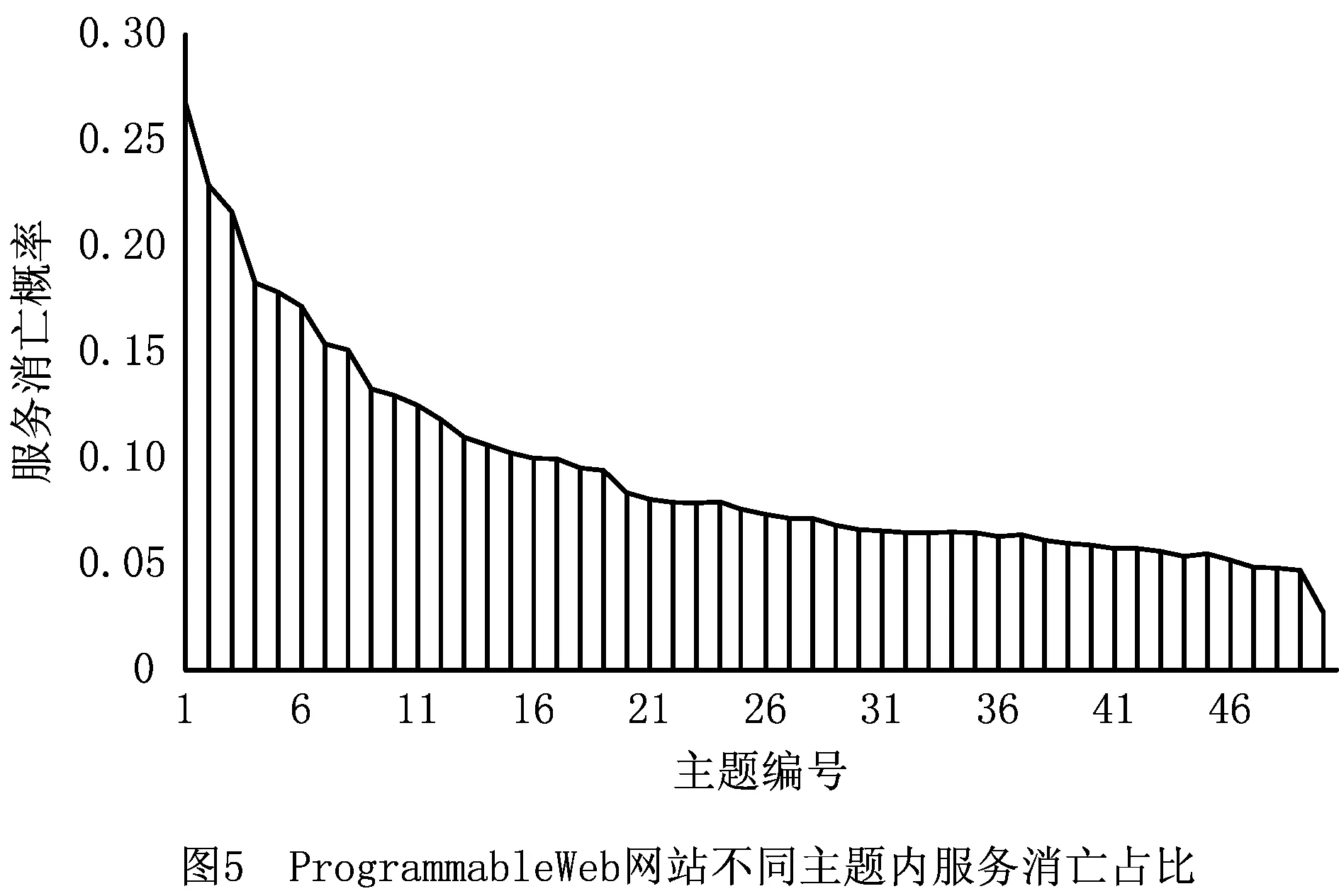
主题特征分析的定性分析以ProgrammableWeb为背景,本文使用LDA提取了2005~2016年间的所有Web服务在不同主题下的分布情况,其中主题数目设置为50,图4所示为所提取的Web服务主题分布排序后的结果。分析认为,虽然当前时期下的Web服务主题有冷热之分,但从长远角度看,Web服务的一个主题总是经历从产生、热门到最终冷却没落的过程。图4统计的结果表明,在主题更替过程中围绕这个主题而产生的Web服务总数相差不多,占比大致在2%上下浮动。另外一方面,以已经或者正在走向没落的主题为中心开发的Web服务必然会更多地退出服务系统。循此思路,本文统计在不同主题中已经退出系统的Web服务占所有Web服务的比例,将结果从高到低排序,如图5所示。由图可以看出,数据呈现明显的规律性特征,某些主题内的Web服务较多产生了消亡现象。服务系统内的Web服务会因为主题分布的不同而呈现不同的服务消亡趋势,从这个角度出发,本文将服务主题分布数据引入服务消亡预测。
2.2 时间特征分析
在研究服务组合失效问题时,一个比较容易推断出的结论是,那些不能得到用户认可的Web服务通常会最先退出服务系统,时间因素是检验Web服务是否活跃的一个重要判别特征。本文通过服务从创建到第一次被调用的时间间隔来研究时间因素对服务退出的影响。
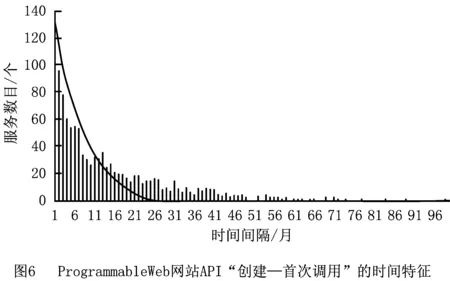
在服务数量和种类都飞速增长的今天,如果某一服务在发布后的若干时间段未能得到调用,则很容易淹没在海量的服务中,其被调用的可能性大大降低。以ProgrammableWeb数据为例,本文抓取应用程序接口(Application Programming Interface,API)的创建时间和Mashup的发布时间,以月为单位计算API的首次调用时间和创建时间的差值。图6中柱状图为统计结果,曲线为拟合曲线,曲线方程为y=max(A)×e-i/10,其中A为统计结果向量,i为月份。从图中可见,从发布后至下个月开始前获得调用的API有144个,在创建18个月内得到首次调用的服务数目占所有被调用服务数目的50%,随着时间的增长,服务被调用的可能性降低。
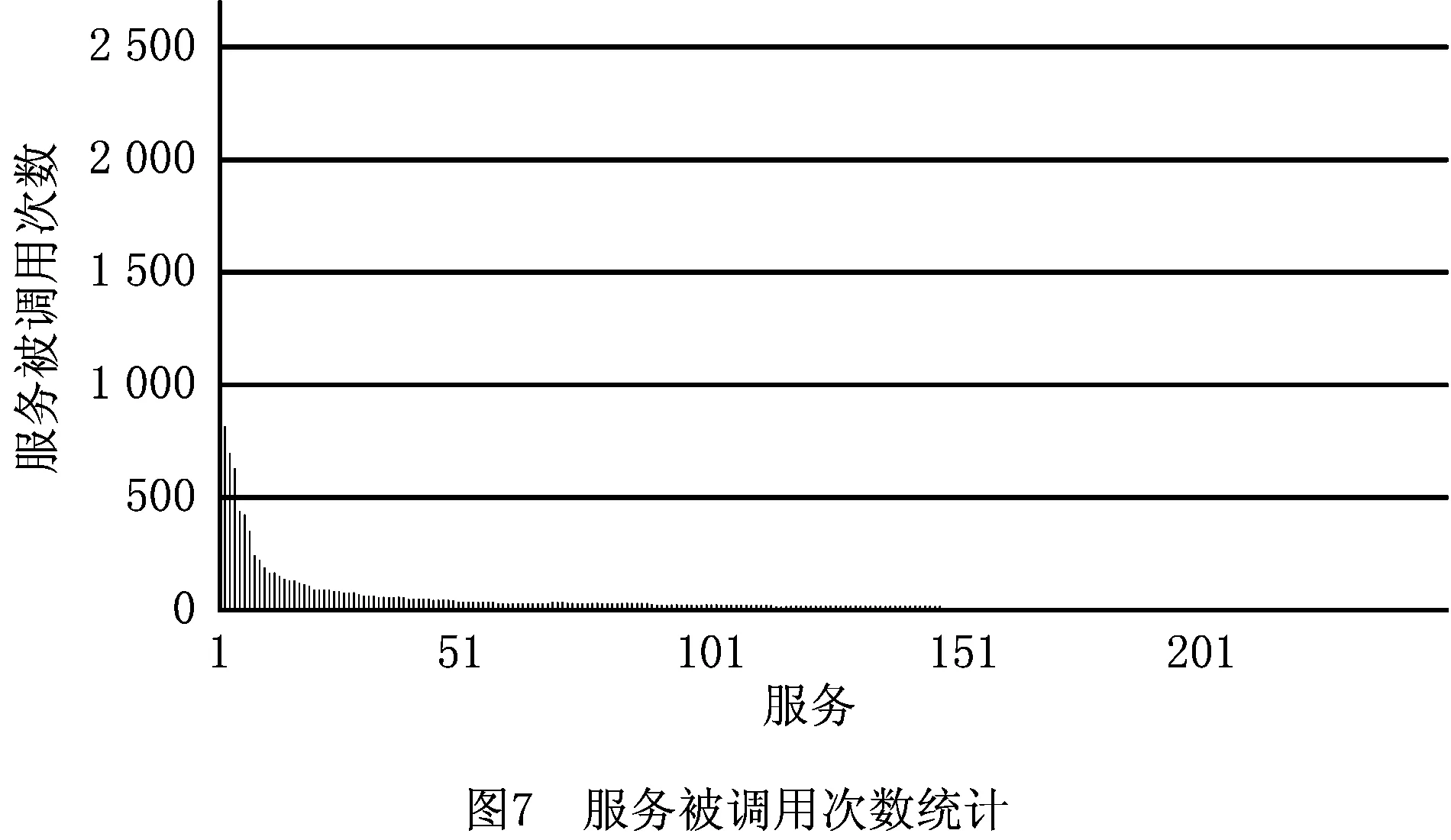
服务在得到调用后,会得到一种类似“再激活”的属性,即重新进入服务组合开发者的视野,从而大大增加再次被调用的几率。从另一个角度观察ProgrammableWeb的数据,统计服务被调用的总次数。图7所示为统计被调用最多的前200个服务调用次数,与图6相比,服务被调用次数迅速下降。分析表明,服务调用次数与服务创建—首次调用时间差呈现大致的对应关系,可能由于从众心理,人们更容易相信已经被别人认可的服务,体现在数据上就是越是经常被使用的服务,被调用的次数越多。相对而言,对于一个服务,“创建—首次调用”时间指标越大,被调用的总次数越少。
3 模型建立
算法模型主要使用主题特征和时间特征预测Web服务消亡,模型的流程图如图8所示。流程分为线下和线上两部分:线下部分为图8的左半部分,对于目标服务系统,算法使用泊松分解从Web服务的自然语言描述信息中提炼Web服务的主题分布特征和时间特征并将其融合,然后使用机器学习算法计算出服务消亡的概率模型提供给线上部分调用;当用户输入希望调用的某个Web服务或者某类型的Web服务进行查询时,线上部分通过在线算法则提供对应的Web服务消亡的概率值作为建议。
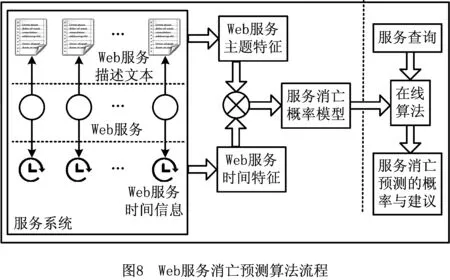
算法流程中的几个关键步骤分别为主题特征提取、时间信息处理、综合两类特征算出概率模型和在线算法部分。下文对这几个步骤分别进行说明。
3.1 特征提取
3.1.1 主题特征提取
Web服务的主题特征采用泊松分解算法从Web服务描述文本中提取,在正式处理前需要将服务系统内的所有Web服务描述文本进行预处理,包括去除分类无关用词、词性转换等工作,最终将其转化为“服务—词”矩阵,具体过程不再赘述。
设获得的“服务—词”矩阵为Y,使用泊松分解求解服务的主题分布,即
ηs~Gamma(λua,λub);
θw~Gamma(λia,λib);
(13)
后续的求解步骤如1.1节,最终获取的参数迭代公式如表1所示。

表1 泊松分解迭代公式
依据参数迭代公式,设计主题特征提取的算法流程如下:
算法1Web服务主题特征提取算法。
输入:“Web服务—词”使用关系矩阵Msw、主题数目K、Web服务的Gamma分布参数(λsa,λsb)、词的Gamma分布参数(λwa,λwb)。
输出:Web服务的主题特征分布μs。
算法:
1.for(k=1:K){
2. 由(λsa,λsb)计算出μs,k初值;
3. 由(λwa,λwb)计算出βw,k初值;}
4.repeat{
5. 对于矩阵Msw中每一个元素msw>0,根据表1中公式,更新φsw,k;
6. for(k=1:K){msw,k=mswφsw,k};
7. 由表1中公式,更新μs,k和βw,k;
8.}until(convergence)
因为泊松分解是非负分解,所以很容易推断出当msw=0时φsw,k=0,因此在算法步骤5和6中可以忽略矩阵Msw中非零元素的各项计算,当矩阵Msw为稀疏矩阵时可以节约大量计算时间,这也是泊松分解在计算速度上相对于其他机器学习算法的优势所在。
3.1.2 时间特征提取
Web服务的“创建—初次使用”与Web服务的活跃程度呈现一种负指数的对应关系,对于服务消亡而言,无论创建—首次调用特征还是调用次数特征,消亡的服务都位于数据的长尾部分,而服务系统中数据量庞大的长尾部分使得消亡服务的特征并不十分明显,因此对时间因素作对应的线性化处理,突出其时间因素与服务退出的对应关系,以提高服务消亡预测的准确度。基于上述原因,在实验中将采集到的时间特征做如下处理:
tr=log(t1-t0)。
(14)
式中:t1为服务得到首次调用的时间,t0为服务的创建时间。再将处理过的tr作归一化处理:
(15)
3.2 服务消亡概率模型
在进行线下部分训练前,通过3.1节和3.2节已经得到集合{μs,ts},其中μs为服务的主题特征,ts为服务的时间特征。训练时设置
τs=[λ1μsλ2ts]。
(16)
式中λ=[λ1λ2]为系数。因为ELM算法需要求矩阵广义逆运算,设置系统λ的目的是使合并后的矩阵元素在数量级上保持基本一致,以避免不必要的计算误差。在此使用rs标志采集到的服务退出信息,其中rs=1表示服务退出服务系统,rs=0表示服务仍在提供服务。
使用ELM算法训练模型,模型的输入为ts,输出为rs,训练目标为
(17)
训练过程如1.2节所示。利用{τs,rs}训练出ELM模型的隐层参数,至此完成模型的线下训练。
3.3 在线算法
对于线上部分,当一个新的服务sk被用户输入模型时,利用特征提取训练完成的参数,容易算出新服务对应的{μsk,tsk}并生成出对应的τsk,通过τsk和训练好的服务退出概率模型,最终计算出rsk。rsk为一个[0,1]间的概率值,用来表示该服务退出服务系统的可能性,其提供给用户作为是否使用该服务的参考建议,值越大,该服务越有可能出现消亡现象。
4 实验
4.1 实验数据
ProgrammableWeb网站提供API(Web服务)和Mashup(服务组合)两种在线服务功能,其中API仅提供单一功能的服务,例如Google Maps提供地图服务,Zillow提供在线房屋估值、挂售功能。Mashup则通过调用一个多个API,提供功能众多、能满足用户复杂需求的服务。例如BetterHome通过调用Zillow, Walk Score, Google Maps等多个API,根据用户的各种喜好(如环境、位置等信息)为用户提供个性化房屋购买、租赁建议;Globebop则通过调用Google Maps, Wikipedia等API,为用户提供旅游地点路线、景点介绍、推荐等服务。
截止2017年5月10日,ProgrammableWeb网站提供了17 455个API和7 877个Mashup(包括已退出的API和Mashup)。实验中抓取了网站2005~2016年间的所有API数据,放弃了从2016年12月底至今时长约半年的API数据,原因是这部分API属于新生服务,其退出服务系统的可能性几乎为0,实际观测也是如此。在实验数据中加入这部分数据无疑会增加算法结果的准确度(全为负样本),但对算法性能测试并无实际意义。
使用数据前通过服务组合的使用情况对Web服务进行了一次过滤,剔除了从未被调用过的API。这样的数据处理出发点是,被调用的Web服务退出系统会对整个服务系统的稳定性造成更大危害,如果算法能针对这些Web服务给出可靠的消亡预测,则将更具实际应用价值。通过上述处理后实验数据集如表2所示。

表2 处理后的ProgrammableWeb.com数据
4.2 评价指标
对于一个给定的区分阈值,如果计算得到的服务消亡概率值大于这个阈值,则认为该服务在未来一段时间内并不稳定;小于这个阈值,则表示该服务能在服务系统内更稳定地提供服务。因此服务消亡预测问题本质上还是一个二分类问题,阈值调整需要根据不同的服务系统或用户的使用需求而定。在这种情况下,曲线下面积(Area Under Curve,AUC)指标值是非常适合的一种评价方法。
二分类问题样本的观察结果常表示为正类(positive)和负类(negative),分类结果有正确分类(true)和错误分类(false)两种情况,综合起来有TP,FP,TN,FN4种指标,这4种指标能更好地体现分类的准确性。定义真正类率TPR和负正类率FPR分别为:
(18)
在[0,1]间逐渐改变分类阈值,可以得到逐渐变化的多组分类结果,以FPR为横坐标,TPR为纵坐标,绘制受试者工作特性(Receiver Operating Characteristic, ROC)曲线,曲线与X轴之间的面积即为AUC值。ROC曲线越接近(0,1)越好,曲线拱起的弧顶使视觉判断更为直观。在多种算法曲线相近的情况下,AUC值越接近1,分类算法的效果越好。
4.3 参数设置
实验中需要设置的参数主要为泊松分解算法参数和ELM算法部分参数。泊松分解算法中,Gamma分布参数λsa=0.14,λwa=0.16,λsb和λwb并未单独设置,而是采用文献[20]介绍的方法,其中
(19)
主题数目K=150。ELM算法中设置λ=[10 1]。
另外,本文在实验中采用LDA作为泊松分解的比较算法,采用朴素贝叶斯分类算法作为ELM的对比算法。LDA的参数设置中,主题数目同样设置为150,迭代次数设置为2 000次;朴素贝叶斯算法中无参数设置。
4.4 实验结果
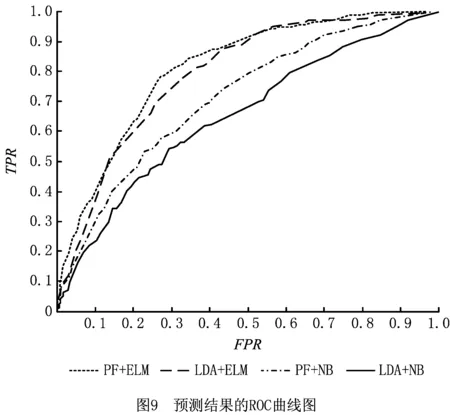
实验将4种算法交叉应用,最终的实验结果如图9所示。当主题特征提取采用泊松分解,分类算法采用ELM时取得了最好的实验结果,即图中的PF+ELM曲线,AUC面积为0.800 3;采用LDA提取主题特征、ELM分类时的AUC面积为0.780 8,效果次之;再次的为使用PF算法提取主题特征、使用朴素贝叶斯分类,其AUC面积为0.698;效果最差为采用LDA和朴素贝叶斯组合的算法,其AUC面积为0.652 7。综合考虑得出结论为:对于主题特征提取,泊松分解略优于LDA算法,而分类算法中的ELM分类效果明显优于朴素贝叶斯算法。
使用训练完成的PF+ELM算法对数据集中最后150个服务进行预测,预测结果如表3所示。

表3 预测结果
在实际的服务系统中,产生服务消亡现象的仍然为少数服务,在本组数据中,真正失效的只有Yahoo Image Search一个服务。对于其他几个服务,由于受Yahoo search服务消亡的影响,导致Google的类似服务迅速占据了绝对领先地位,Yahoo Local Search和Yahoo Travel也因此处于长期无人问津的尴尬地位。预测中的第4位Wolfram Alpha是一个计算类服务,在其介绍中有“computational knowledge engine”和“make it possible to compute whatever can be computed about anything”等,在ProgrammableWeb网站上计算类服务并非热门的类别,过度夸张的宣传或许会使用户敬而远之。Wookmark是一个社交类网站,用户可以在上面发布照片和视频以及交友等。Facebook基本涵盖其所有功能,不能获得用户青睐也比较容易理解。
4.5 特征组合意义和特征选择标准
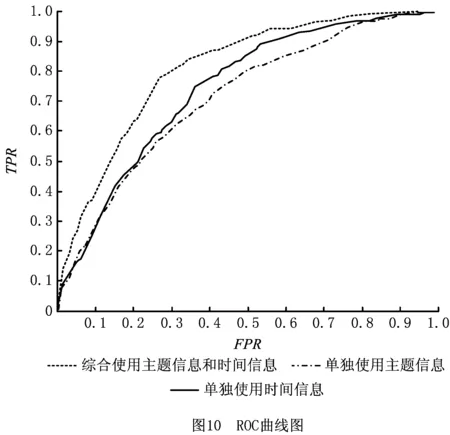
为观察仅使用单特征情况下的预测效果,单独采用主题特征和时间特征分别进行预测。从图10可以看到,当单独使用主题信息进行服务消亡预测时,AUC面积为0.703;当单独使用时间信息进行预测时,AUC面积为0.732 7;而当将二者结合使用后,预测效果则有了一个较大的提升。从算法上来说,增加一个参数,最坏的情况仍然是保持之前的结果,即这部分参数的隐层参数全为0。相反,如果能采用更多可用的特征信息,则可以进一步提高服务退出预测的整体精确度。
虽然更多的特征加入会提高服务消亡预测的精度,但是本文在算法中仅考虑了时间特征和主题特征两种参数。一个服务系统中必然包括很多特征,有些是属于所有服务系统共有的特征,而有些则是该服务系统特有的个性化参数。在算法的可用特征的选择上,应该尽可能选择那些通用的、普适性的参数,而不仅是某个服务系统所独有的属性,否则必然降低算法在不同服务系统间的通用性,甚至受限于服务系统的更新而导致算法失效。例如文献[11]使用的供应商信息,由于ProgrammableWeb网站改版的原因,新增加的Web服务中大部分已经不再提供该项数据,导致该算法的可用性大大降低。本文仅选择时间特征和主题特征正是出于这方面的考虑,所选取的特征均为各类服务系统具备的通用属性。
5 相关工作
近年来,随着服务系统在人们日常生活中的日益普及,对服务系统的研究逐渐引起了学者们的重视。目前的研究问题多数集中在从用户使用的角度出发所作的服务推荐工作,如文献[5,12-14]。但对服务系统来说,Web服务消亡也是一个必然的现象,目前有关服务系统内Web服务退出服务系统的机制和影响的研究还比较少。服务消亡不等同于服务失效,服务消亡和服务失效的最大区别在于,导致服务失效的往往是因为网络异常等原因,在故障排除后Web服务依然能够继续提供服务,从长远的角度看对服务系统的影响并不严重,对服务失效的研究多聚焦于研究失效的原因及处理方法[6-9]。服务消亡则是Web服务彻底退出了服务系统,不再提供任何服务支持,解决这类问题更侧重于预防以及相似Web服务的备选工作。目前,有关Web服务消亡问题的研究尚处于起步阶段,文献[21]研究了服务消亡的产生机制,依此提出一个研究框架并给出了一套度量指标,但目前Web服务正处于蓬勃发展的上升期,对应的框架和指标也应该随着服务系统的日趋成熟而不断修改和变化;文献[10]使用服务标签对Web服务进行分类,使用二部图度量同类Web服务间的竞争关系来进行服务消亡预测,然而服务标签为人工生成,难免存在一些分类误差或者遗漏;文献[11]加入供应商信息,通过判别供应商实力来进行服务消亡预测,分类算法取得了不错的效果,但供应商信息受限于服务系统,非通用性的参数限制了算法的可移植性和通用性。本文通过使用主题信息和时间信息两类特征数据,有效地对Web服务消亡进行了预测。本文采用机器学习方法减少了人工干预可能带来的误差,特征数据的通用性则保证了预测算法在不同服务系统间的可移植性。
6 结束语
近年来,随着Web服务的迅猛发展,服务计算及其相关研究得到了极大关注。从软件生命周期[22]的角度分析,Web服务必然包括产生、提供服务和最终消亡的过程。目前,学者们的研究往往集中在从用户的角度解决Web服务中出现的各种问题,以及面向用户做各种类型的服务推荐等,有关Web服务生命周期中服务消亡现象的研究还比较少。研究服务消亡问题,是通过检测服务系统中存在不稳定因素的相关服务,提醒服务组合开发者和服务系统开发与研究人员加以重视,从而提高服务系统的稳定性。一个健康稳定的服务系统才能更好地满足用户的各种需求,持续吸引用户的关注并得到更好的发展。
社会流行元素的更替必然影响Web服务主题分布,不合时宜的Web服务会逐渐退出服务系统,时间特征则是所有Web服务共有的因素。本文提出的Web服务消亡预测方法利用机器学习算法有效提取了服务系统中服务消亡个体的特点,基于ProgrammableWeb上的实验表明,该方法能有效预测服务消亡,为服务的使用者特别是服务组合开发者提供可靠的建议。
引入更多的可用指标必然会增加预测的准确性,后续研究计划增强这方面的研究和探索,以发现和利用更多的通用性指标。另外,算法中有一部分需要线下计算,而服务系统在运行一段时间后必然会有新服务加入或已有服务消亡,导致线下部分必须在模型运行一段时间后重新计算,以保持与当前系统的一致性,后续研究将致力于完成对应的增量改进算法,从而更好地提供在线服务。
