CAWOA-ELM混合模型的锅炉NOx排放量预测
2018-12-17陈国彬牛培峰
赖 敏, 陈国彬, 刘 超, 牛培峰
(1.重庆工程学院 软件学院,重庆 400056;2.重庆工商大学 融智学院,重庆 400033; 3. 燕山大学 电气工程学院,河北秦皇岛 066004)
随着经济发展和工业化进程的加速,我国大气污染的形势日益严峻。电厂是大气污染物NOx的主要排放源[1]。因此,建立有效的NOx排放量预测模型不仅能优化电站锅炉燃烧,而且对减少大气污染至关重要。然而,锅炉燃烧系统中NOx的形成是一个复杂的物理、化学过程,受煤种和配风方式等多种因素的影响[2],这些变量相互耦合,难以用机理模型描述这些复杂过程,机器学习技术的出现为锅炉燃烧优化模型的建立提供了一条有效途径[3-4]。
极限学习机(ELM)是依据Moore-Penrose(MP)广义逆矩阵理论产生的一种新型有效的机器学习技术[5]。在ELM中,神经元权值中的输入权值和隐层阈值随机给定,然后通过正则化原则计算输出权值,ELM网络依然能逼近任意连续系统。与神经网络和支持向量机相比,ELM优势在于极大地提高了网络的学习速度,已经受到越来越多的关注[6-7],因此可以采用ELM进行锅炉NOx排放量的回归预测。
ELM回归方法的输入权值和隐层阈值随机给定,无任何先验经验可寻,往往容易造成回归模型的泛化能力与稳定性不理想等问题。在实际应用过程中,为了达到理想的误差精度,ELM通常需要调整输入权值和隐层阈值,其调整过程可以转化为最优化问题。因此,提出一种Sin混沌自适应鲸鱼优化算法(CAWOA) 来优化ELM模型的参数,以改善该模型的稳定性和泛化能力,并进一步提出CAWOA-ELM的NOx排放量软测量模型(以下简称CAWOA-ELM模型)。笔者以某330 MW煤粉锅炉为研究对象,利用集散控制系统(DCS)中稳态样本训练集建立NOx排放量离线预测模型,利用该模型对未来稳态工况进行仿真预测,并验证了CAWOA-ELM模型的有效性,为NOx排放量的精确预测以及热电厂燃烧优化的推广提供了一种有效手段。
1 混沌自适应鲸鱼优化算法
1.1 鲸鱼优化算法
鲸鱼优化算法(WOA)是受鲸鱼泡泡网觅食行为启发,在2016年提出的一种新型群智能优化算法[8],并受到众多研究者的关注[9-10]。为了从数学上描述鲸鱼的泡泡网觅食行为,在WOA算法中设计了2种不同方式:收缩包围机制和螺旋更新位置。
(1)收缩包围机制。
设WOA算法种群个数为N,第i只鲸鱼表示为Xi=(xi1,xi2,…,xid),i=1,2,…,N,其中d表示优化空间的维度。假设猎物位置Xp为当前种群中最优解,鲸鱼个体X(t)均向最优解包围,数学模型描述如下:
X(t+1)=Xp(t)-A·|CXp(t)-X(t)|
(1)
A=2a×r1-a
(2)
C=2×r2
(3)
a=2-2×t/Tmax
(4)
式中:t为当前迭代次数;A和C为系数向量;r1和r2为[0,1]内的随机数;a为控制参数;Tmax为最大迭代次数。
收缩包围机制通过式(1)和式(4)随着控制参数a的减小而实现。
(2)螺旋更新位置。
鲸鱼螺旋式运动捕获食物的数学模型如下:
X(t+1)=Xp(t)+D′·ebl·cos(2πl)
(5)
式中:D′=|Xp(t)-X(t)|,为鲸鱼与猎物之间的距离;b为一个常数,用来定义对数螺线的形状;l为[-1,1]内的随机数。
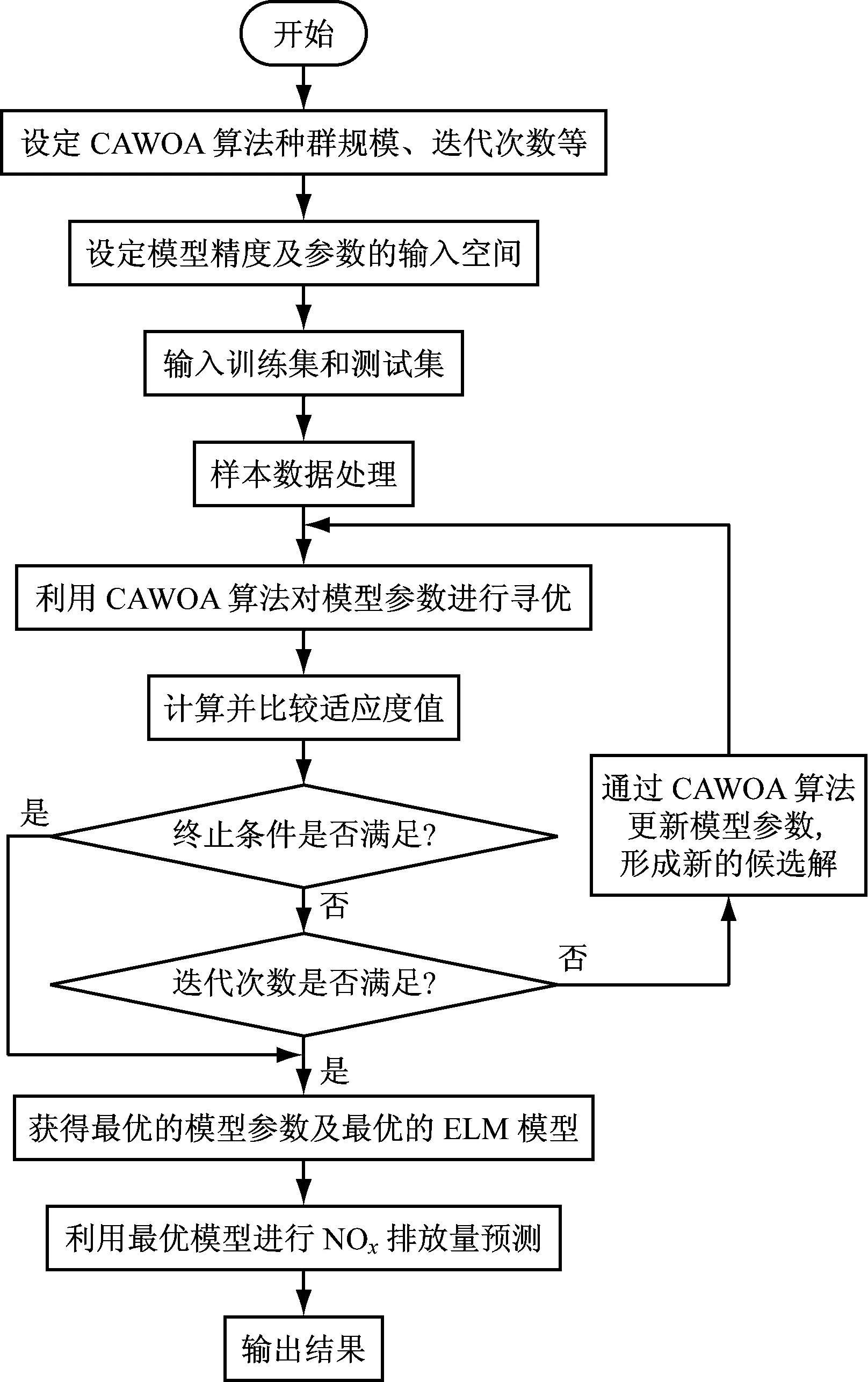
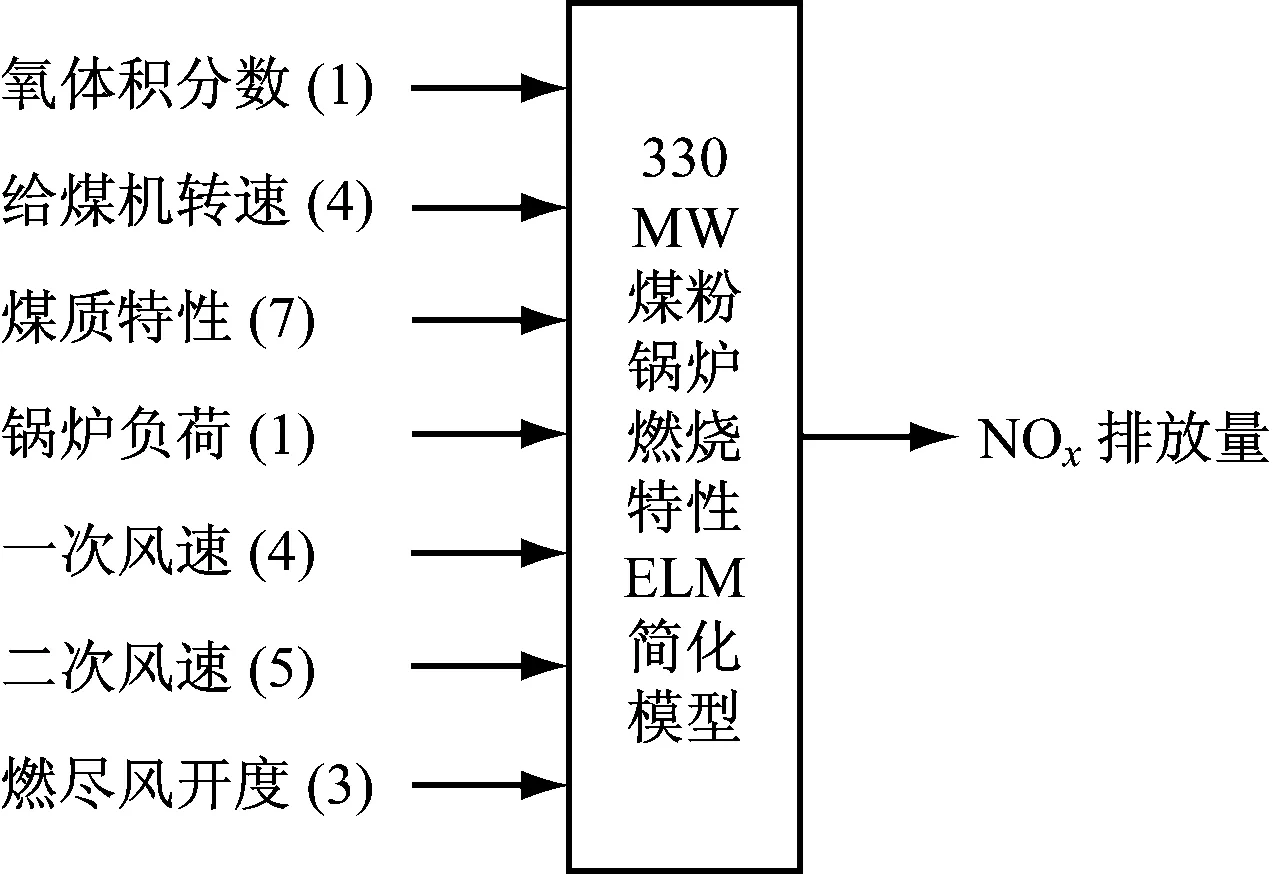
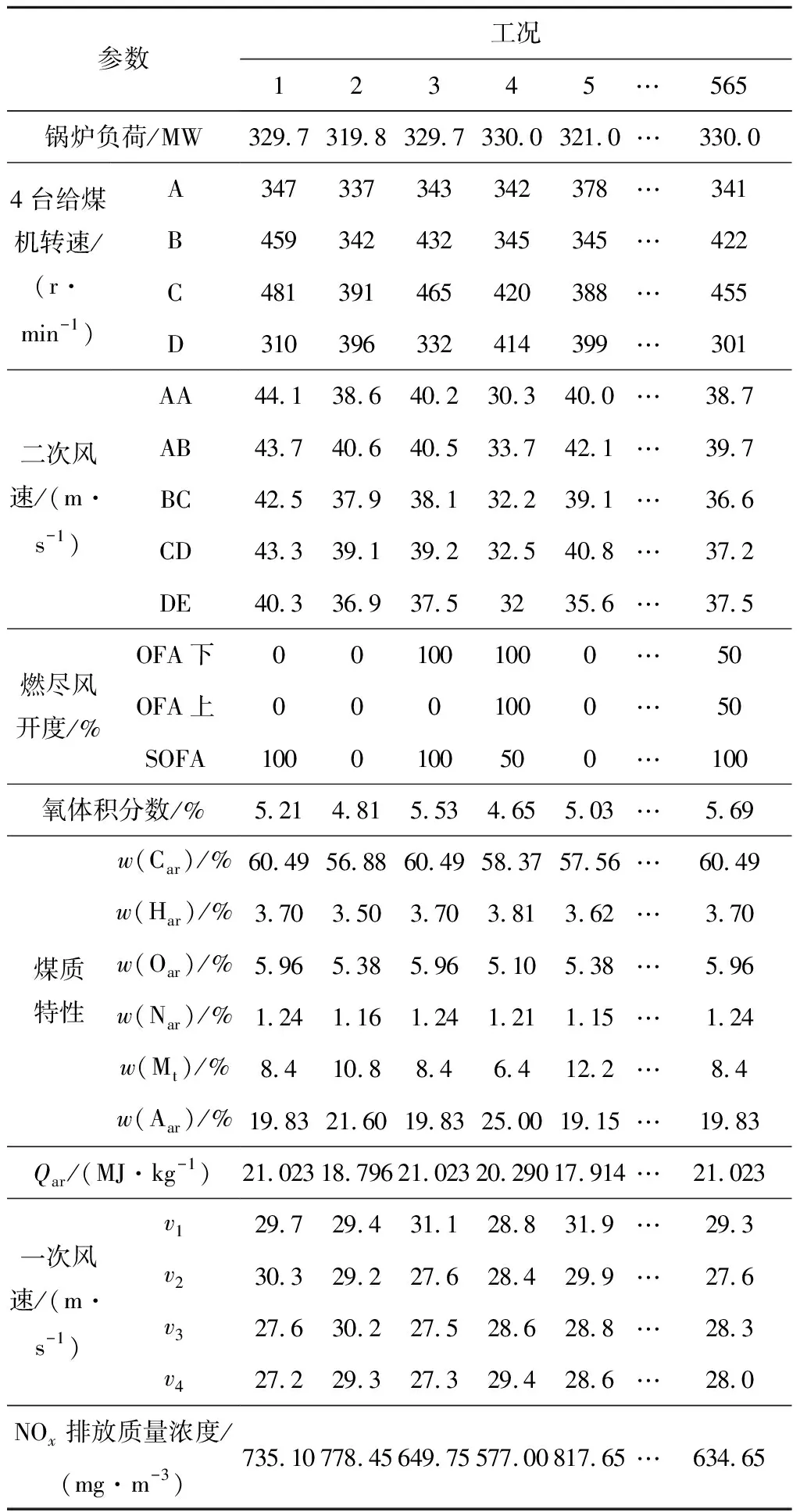
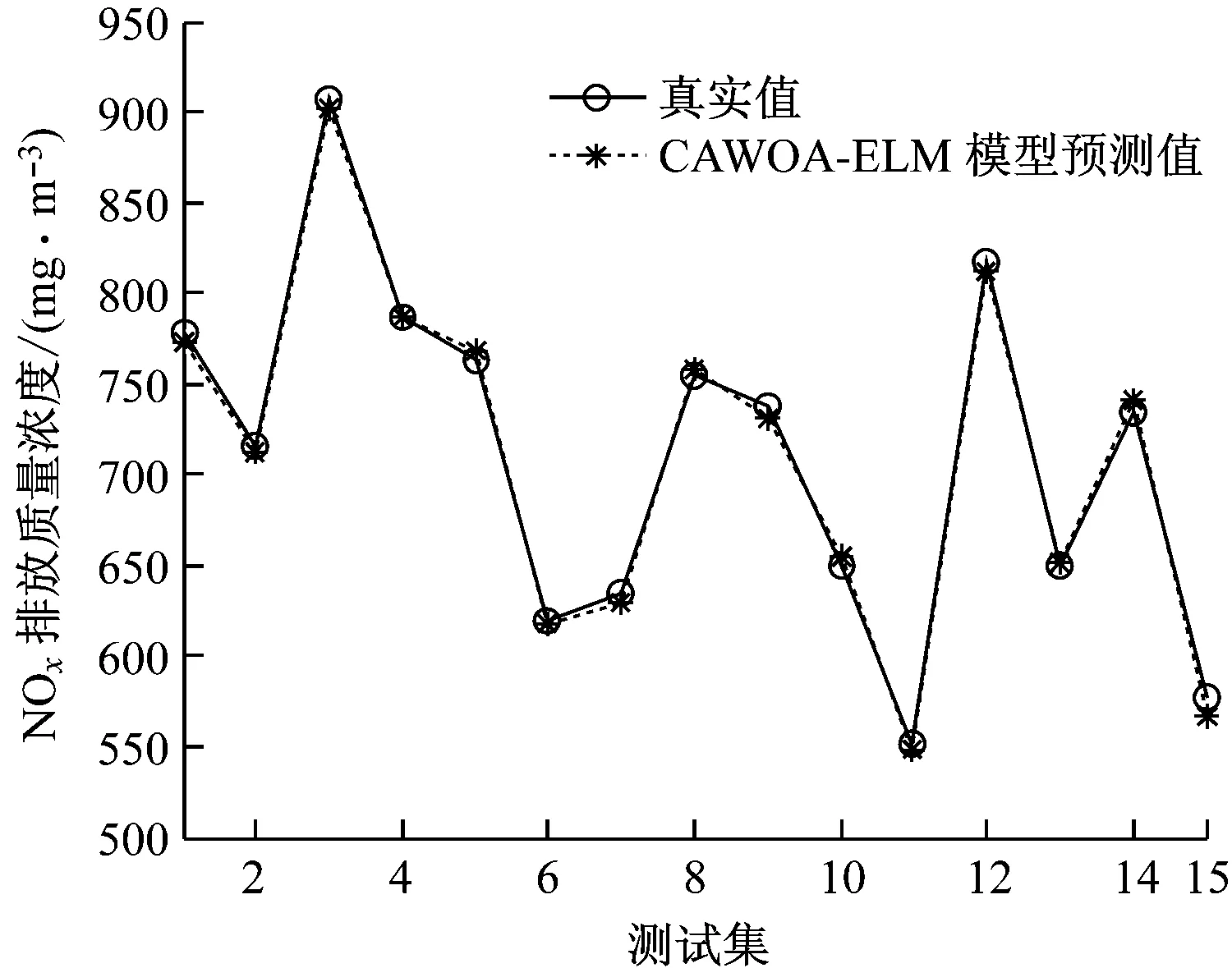
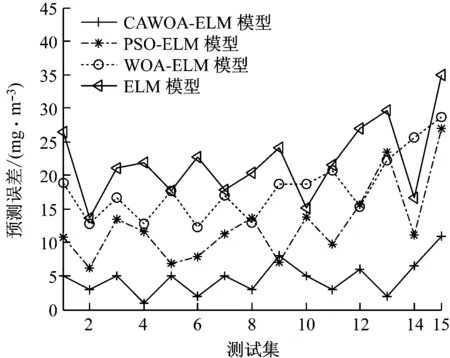
鲸鱼的收缩包围机制与螺旋更新位置是一种同步行为,通常按照概率值Pi=0.5选择更新方式:若p WOA算法在处理复杂优化问题时存在收敛精度较低且易陷入局部最优的不足。为解决上述不足,提出CAWOA算法来改善WOA算法的全局优化能力。在WOA算法的基础上,引入Logistic混沌搜索策略,通过对当前最优解进行混沌扰动以解决局部收敛的问题;此外,在位置更新中引入自适应惯性权值,通过平衡开发与探索能力解决算法收敛精度低的问题。 1.2.1 Sin混沌搜索策略 混沌映射是由确定性方程得到的具有随机性的运动状态,具有相空间的遍历性和内在的随机性,结合混沌变量进行优化搜索能有效跳出局部最优,实现全局优化。杨海东等[11]验证了Sin混沌比Logistic混沌具有更明显的混沌特性,针对WOA算法处理复杂函数优化问题陷入局部最优的不足,采用Sin混沌搜索对WOA算法每一代种群的最优个体(精英个体)进行M次混沌搜索,如果搜索到更优个体则进行取代,使其跳出局部最优,有效地避免了WOA算法陷入局部最优。Sin混沌映射模型定义如下: Zt+1=sin(2/Zt),t=0,1,…,N -1≤Zt≤1,Zt≠0 (6) 混沌映射的迭代计数器用t来计数,进行M次混沌迭代,系统输出将遍历整个解空间。 假设WOA算法种群中最优个体为Xi,在可行域内混沌优化过程为: (7) 假设WOA算法第i代的精英解是Xi=(xi1,xi2,…,xiD),Sin混沌搜索步骤如下。 (1)利用式(8)对Xi进行归一化: i=1,2,…,N;j=1,2,…,D (8) 式中:Xjmax和Xjmin分别为可行域中第j维的最大值和最小值。 (2)生成混沌序列。随机生成Z0,根据式(6)迭代生成M个混沌序列。 (9) (5)计算适应度值f(uij),并与Xi的适应度值f(Xi)进行比较,保留最好解。 1.2.2 自适应惯性权值 惯性权值是WOA算法中的一个重要参数,式(1)和式(5)中保持较大的惯性权值1,恒定不变的惯性权值将降低算法效率,不利于算法的全局寻优。Zhang等[12]指出较大的惯性权值有利于全局优化,较小的惯性权值有利于局部挖掘。基于此,提出一种基于适应度值的自适应惯性权值,以保证算法在迭代初期随适应度值的不同而具有较大的非线性权值,在迭代后期具有较小的非线性权值策略。 在式(1)和式(5)中引入自适应惯性权值ω: (10) 式中:ffit(X)是个体X的适应度值;u为在第一次迭代计算中鲸鱼种群中最佳的适应度值。 改进后的更新公式如下: X(t+1)= (11) 利用ω的动态非线性特性提高WOA算法的收敛精度和收敛速度。 ELM是一种新的单隐层前向神经网络学习算法,与传统神经网络训练学习的不同在于ELM隐层无需迭代,输入权值和隐层节点偏置是随机选择设定的,以最小训练误差为目标,最终确定隐层输出权值,该算法描述如下。 设m、M、n分别为网络输入层、隐层和输出层的节点数,g(X)为隐层神经元的激活函数,bi为隐层阈值。n个样本为(Xi,Y),其中Xi=[xi1,xi2,…,xim]T∈Rm,为网络输入向量,Y=[y1,y2,…,yj,…,yn]T∈Rn,为目标输出向量。 ELM模型描述如下: (12) 式中:ωi=(ω1i,ω2i,…,ωmi),为连接网络输入层节点与第i个隐层节点的输入权值向量;βi=[βi1,βi2,…,βin]T,为连接第i个隐层节点与网络输出层节点的输出权值向量;O=[o1,o2,…,oj,…,on]T,为网络输出值。 ELM的代价函数E可表示为: (13) 式中:S=(ωi,bi),i=1,2,…,M,包含了网络输入权值及隐层阈值;β为输出权值矩阵。 ELM的训练目标是寻求最优S和β。min(E(S,β))可进一步描述为: (14) 式中:H为网络关于样本的隐层输出矩阵。 其中, H(ω,b,X)= (15) (16) (17) 式中:H†为隐层输出矩阵H的MP广义逆。 ELM学习算法在回归问题的计算性能和准确率等方面具有一定的优势,在缺乏先验知识情况下,ELM的输入权值和隐层阈值通常随机确定,并求出网络的输出权值。假如输入权值和隐层阈值选择不当,将会影响ELM的预测精度和泛化能力。针对该问题,采用CAWOA算法优化ELM模型,其核心思想是将样本数据作为ELM模型的输入,通过CAWOA算法搜索调整得到最佳输入权值和隐层阈值,在隐层节点尽可能少的情况下使ELM算法的回归效果最好,输出权值矩阵β则通过解析MP广义逆求得。图1给出了CAWOA算法优化ELM模型参数的流程,具体步骤如下: (1)种群初始化。随机产生由N个鲸鱼个体组成的种群,鲸鱼个体Xi按输入权值和隐层阈值编码,如Xi=(ω11,…,ω1m,…,ωM1,…,ωMm,b1,b2,…,bM)所示。 (2)变量选择与数据采集。在进行NOx排放量预测建模时,选择合理的输入、输出模式;并从燃烧系统采集、处理与建模相关的运行数据,将其分为训练集和测试集。 (3)确定适应度函数J: (18) (4)模型选择。根据初始种群建立NOx排放量预测模型并计算适应度值,如果适应度值不满足要求,则采用CAWOA算法优化、选择ELM的模型参数,直到得到满意的结果为止,并建立CAWOA-ELM模型。 图1 CAWOA算法优化ELM模型参数的流程 (5)模型验证。利用测试集验证CAWOA-ELM模型的性能。 锅炉燃烧生成NOx的途径主要有燃料型NOx、热力型NOx和快速型NOx,其燃烧过程非常复杂,NOx的生成量与排放量受燃烧方式、燃烧器结构形式、运行风量、负荷和煤质特性等因素的影响,这些影响因素之间具有非线性、强耦合特性,常规的机理建模方法难以描述锅炉燃烧过程。然而,NOx的精确计算是发电企业实现节能减排、环境保护的必要环节之一。ELM黑箱模型的出现为解决上述难题提供了一条有效途径。 采用ELM建立锅炉NOx排放量预测模型需要确立输入、输出参数。依据强相关性原则采用25个操作参数作为输入参数,具体如下:锅炉负荷;省煤器出口烟气含氧体积分数;4个一次风速(v1、v2、v3和v4);4台给煤机转速,给煤机编号为A、B、C、D;二次风速,二次风共投入5层,同层联动,各层编号为AA、AB、BC、CD、DE;燃尽风开度,燃尽风分别位于OFA上、OFA下、SOFA层;煤质特性w(Car)、w(Har)、w(Oar)、w(Nar)、w(Mt)、w(Aar)和发热量Qar共7个参数用于描述煤质对NOx排放质量浓度的影响因素。预测NOx排放量的ELM简化模型如图2所示,选择ELM模型的输入节点数为25,输出节点数为1,根据文献[13]确定ELM模型的隐层节点数为8,构成25-8-1的ELM的NOx排放量预测模型。 图2 锅炉燃烧特性ELM简化模型 以某330 MW煤粉锅炉为研究对象,从其DCS系统中采集565组稳态运行样本,如表1所示。在565组数据中,随机选取550组稳态样本训练ELM模型,并建立基于CAWOA-ELM的NOx排放量预测模型;其余15组作为测试集,用来验证模型的准确度和泛化能力。CAWOA-ELM模型对测试集的预测结果见图3。为验证CAWOA-ELM模型的性能,将其与粒子群算法(PSO)优化的ELM模型(PSO-ELM)、WOA-ELM和标准ELM 3种模型进行仿真对比,各方法预测误差的绝对值见图4。 从图3可以看出,CAWOA-ELM模型的预测趋势与真实值的趋势相同,15个测试集虽存在一定估计误差,但从热工过程可接受误差范围来看,CAWOA-ELM模型能够对测试集进行正确估计。 从图4可以看出,ELM模型的预测误差最大,说明随机初始化输入权值和隐层阈值的ELM模型预测精度不高;比较PSO-ELM、WOA-ELM与ELM模型曲线,前2种模型参数分别在PSO和WOA算法优化的情况下,其NOx排放质量浓度预测精度有明显改善。从图4还可以看出,CAWOA-ELM模型的预测误差曲线最为平稳,且预测误差最小,表明基于CAWOA-ELM模型的NOx排放质量浓度预测效果最好,同时也表明经过Sin混沌搜索策略和自适应惯性权值策略改进的CAWOA算法较WOA算法更能优化搜索到较好的输入权值和隐层阈值。综上所述,输入权值和隐层阈值决定了ELM的泛化能力;CAWOA-ELM模型比PSO-ELM、WOA-ELM和ELM模型具有更优的泛化能力。 表1 锅炉运行试验数据 图3 CAWOA-ELM模型对NOx排放质量浓度的预测结果 图4 4种模型对NOx排放质量浓度的预测误差 为了精确预测煤粉锅炉NOx排放量,提出一种基于混沌自适应鲸鱼优化算法与极限学习机结合的预测模型。采用CAWOA算法来预先选择ELM模型参数以改善模型的预测精度和泛化能力。以某电厂330 MW煤粉锅炉为测试对象,建立CAWOA-ELM的NOx排放量预测模型,通过DCS系统历史运行稳态数据进行模型训练,并利用稳态运行样本对模型进行预测检验,仿真实例表明,CAWOA-ELM模型具有较好的准确性、较强的泛化能力和更高的实用价值。1.2 CAWOA算法
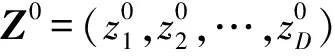
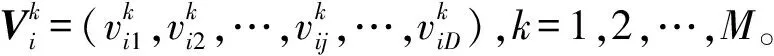
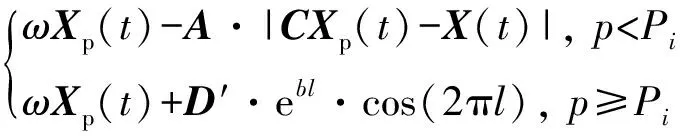
2 极限学习机模型
2.1 极限学习机基本原理
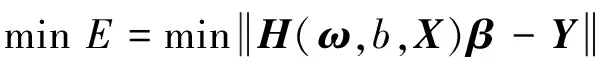
2.2 ELM模型
3 仿真实例
3.1 ELM模型的设计
3.2 仿真实验
4 结 论
