基于彩色分量双重鉴别相似性的人脸特征提取*
2018-12-05谭萍,王兵
谭 萍, 王 兵
(1. 兰州文理学院 数字媒体学院, 兰州 730000; 2. 中国科学院 近代物理研究所,兰州 730000)
人脸识别依托科学技术的快速发展逐渐成为身份验证研究的关键技术,彩色人脸识别近几年也越加受到关注.彩色图像针对传统的灰度图像来说涵盖了相对更多的信息,如何更加充分运用每个彩色分量间的互补信息,剔除冗余信息,从而获得更多有效的特征是目前彩色人脸识别技术亟待解决的问题[1-2].传统的整体正交分析[3](holistic orthogonal analysis,HOA)以及统计正交分析[4](statistically orthogonal analysis,SOA)在提取鉴别特征时分别运用没有监督的正交算法及统计正交约束的算法来剔除三个彩色分量特征间的相似性,并没有考虑三个彩色分量数据集间的相似性,从而把有利及不利于识别的同类及异类样本相似性一并剔除掉,降低了特征的鉴别性能[5].针对传统算法存在的问题,本文研究了基于彩色分量特征层双重鉴别相似性分析的人脸图像鉴别特征提取方法.
1 分量数据集的类内及类间相关性
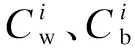
(1)
(2)
(3)
(4)
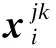
2 图像数据集鉴别特征提取
设计基于相关性度量的双重鉴别相似性分析(CM-DDSA)方法的目标函数为
(5)
式中:wR、wG及wB分别为R、G及B色彩分量的投影变换矩阵;α>0、β>0及γ>0分别为权重系数.
可将式(5)改写为
(6)
式中,
wR、wG及wB可以利用式(7)进行求解,即
Pw=QΛw
(7)
式中:
CM-DDSA方法具体操作流程如下:
1) 依照式(7)运算总体投影变换矩阵w;
2) 经过拆分w获得R、G及B三个彩色分量的投影变换矩阵wR、wG及wB;
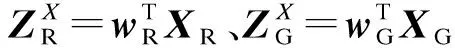
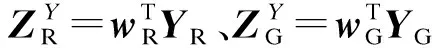
5) 运用基于相关性度量的最近邻分类器完成分类识别.
3 实验分析
为了验证CM-DDSA算法性能,本文采集AR[6]、FRGC-v2[7]和LFW[8]三个彩色人脸图像数据库中图片分别与传统整体正交分析(HOA)及统计正交分析(SOA)方法进行了对比分析.
AR彩色人脸图像数据库拥有126个人的4 000多幅正面彩色人脸图像,个人图像中很大程度上存在表情、光照、遮挡以及采样时间等不同.本文择取该数据库中100个人脸图像,其中每个人包含20幅图像,总计共20×100=2 000幅图像.每幅彩色图像均通过裁剪,仅仅保留人脸及周边区域,经过处理后每幅图像像素是60×60,其中某个人的图像样本如图1所示.

图1 AR 彩色人脸数据库中某人图像样本Fig.1 Image samples for a certain person in AR color face database
FRGC-v2相对来说是一个范围比较大的彩色人脸图像数据库,择取training集合中222个人的图片,每个人均拥有20幅不同的图像.针对每一幅彩色图像完成校正(确保两眼都保持水平)、缩放以及裁剪等处理,最终仅仅保留人脸及周边区域,经过处理后每幅图像像素为60×60,其中某个人的图像样本如图2所示.

图2 FRGC-v2彩色人脸数据库中某人图像样本Fig.2 Image samples for a certain person in FRGC-v2 color face database
LFW彩色人脸图像数据库拥有5 749人的13 233幅彩色人脸图像,其中1 680人具有两张以上图像,图像全都是从网络上运用Viola-Jones人脸探测器采集获得的,并且图像在很大程度上都存在不同.针对择取的原始图像完成缩放以及裁剪等处理,最终仅保留人脸及周边区域,经过处理后每幅图像像素是60×60,其中某个人的图像样本如图3所示.
为了有效设置参数,在每种数据库中每个类别任意择取8个彩色人脸图像样本当做训练样本,其余样本作为测试样本,完成20次随机测试.依照得到的平均识别率确定最优参数,三种数据库在采用CM-DDSA方法时平均识别率随参数ξ的变化情况如图4~6所示.

图5 FRGC-v2数据库平均识别率随ξ的变化Fig.5 Change of average recognition rate with ξ in FRGC-v2 database
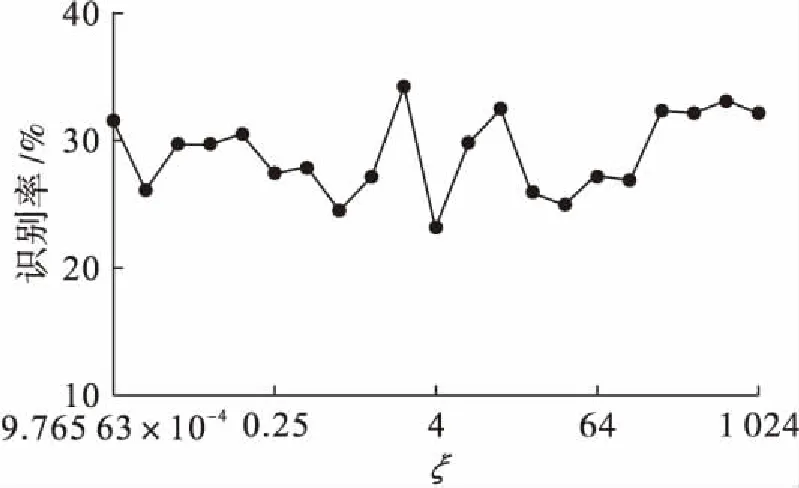
图6 LFW数据库平均识别率随ξ的变化Fig.6 Change of average recognition rate with ξ in LFW database
根据图4~6中应用CM-DDSA方法的结果可知,在AR人脸彩色图像数据库中,人脸图像色彩区域变化较大,故数据保留的信息量不能太少,当信息量数值低于要求数值会降低人脸特征识别能力;相比而言,在FRGC-v2和LFW人脸区域变化较小的数据库上,降维后彩色人脸图像数据保留的信息量适中时效果最好,当信息量增高或降低均会对识别效果有比较明显的不利影响.
在AR、FRGC-v2以及LWF三个数据库内,CM-DDSA方法的平均识别率分别在ξ=64、ξ=0.5以及ξ=0.5的位置获得最大值,所以在数据库内完成实验分析时均择取上述的ξ值.
鉴别能力[9]运算公式为
(8)
式中:Sbi为i彩色分量数据集特征的类间散布矩阵;Swi为i彩色分量数据集特征的类内散布矩阵.
HOA、SOA以及CM-DDSA方法获取的R、G及B彩色分量特征鉴别性能实验结果如表1所示.

表1 平均鉴别性能实验结果Tab.1 Experimental results of average authentication performance
根据表1可知,在HOA和SOA方法中,DC(R)>DC(G)>DC(B),尤其是DC(R)和DC(G)的值在很大程度上存在不同.而CM-DDSA方法中DC(R)、DC(G)及DC(B)的差异相对来说非常小,从而表明CM-DDSA特征提取在很大程度上解决了三个彩色分量特征鉴别性能差异大的问题.
为了量化每个彩色分量间的相似性,设定x及y分别代表维数相同的两个彩色分量图像样本向量,则它们之间相似性[10]为
(9)
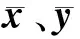
将AR、FRGC-v2以及LWF三个数据库中的图像分别经过HOA、SOA以及CM-DDSA方式处理之后,三个彩色分量特征间的平均相似性值和平均识别率分别见表2~5所示.

表2 AR数据库三个彩色分量特征间的平均相似性Tab.2 Average similarity between three color component features in AR database

表3 FRGC-v2数据库三个彩色分量特征间的平均相似性Tab.3 Average similarity between three color component features in FRGC-v2 database

表4 LWF数据库三个彩色分量特征间的平均相似性Tab.4 Average similarity between three color component features in LWF database

表5 平均识别率Tab.5 Average recognition rate %
根据表2~4可知,CM-DDSA方法的平均相似性值在很大程度上高于HOA以及SOA方法,从而表明该方法在很大程度上保留了三个彩色分量特征之间的平均相似性.根据表5能够获知,CM-DDSA方法保留更多的三个彩色分量特征之间的相似性,其在很大程度上增加了特征的鉴别能力,提升了识别效果.
4 结 论
本文提出了基于彩色分量特征层双重鉴别相似性分析的人脸图像鉴别特征提取方法CM-DDSA,其运用相关性度量各个彩色分量数据集内部以及不同彩色分量数据集之间的相似性.CM-DDSA与HOA、SOA方法相比在很大程度上保留了更多的有利于识别的同类样本相似性,提升了特征的鉴别能力,同时CM-DDSA方法并没有运用串行的特征提取,在很大程度上解决了HOA及SOA方法中三个彩色分量特征的鉴别能力存在很大差异的问题.
