复杂产品协同设计中数据建模与驱动方法
2018-11-22殷学梅周军华朱耀琴
殷学梅,周军华,朱耀琴
(1.南京理工大学 计算机科学与工程学院,南京 210094;2.复杂产品智能制造系统技术国家重点实验室(北京电子工程总体研究所),北京 100854)(*通信作者电子邮箱15705273163@163.com)
0 引言
协同设计系统在网络技术的支持下,使得拥有不同专业知识的空间上分布的设计者能充分利用分布式资源,在同一时间参与到同一个设计任务中,提高产品的设计质量,缩短开发周期,减少不必要的人、物资源浪费[1]。复杂产品协同设计的实质在于:通过交换、共享关于复杂产品设计的信息和知识,提高复杂产品设计过程中决策的正确率,加速决策的过程,提高设计的效率[2]。
经过多年的探索,国内外产生了一些比较著名的协同设计系统。国外著名的项目包括:Stanford大学的Pack系统、PACT(Palo Alto Collaborative Testbed)项目[3]、DICE(DRAPA Initiative in CE)项目之后的Share项目、DARPA资助的Coconut项目、波音公司的Fly Thru项目[4]等。国内在计算机支持的协同设计开发环境方面的研究也早已起步[5-7],如基于工作流管理技术的航天领域复杂产品的协同设计、嵌入式系统软/硬件协同设计、企业BIM(Building Information Modeling)协同设计云平台建设等。目前,国内也有不少学者基于Agent展开协同设计研究[8-9],如杨亢亢等[10]对协同设计中的冲突检测问题进行了研究。但在这些基于工作流管理的协同设计方式中,后继设计任务必须等先序设计任务完成才可以开始,这在多变的复杂产品协同设计这一业务环境下,尤其在并行工程理念下,大幅降低了产品的设计效率。
协同设计中的数据建模和驱动方面在国内外的研究也有了突破性的进展。有学者根据数据驱动控制的理论提出以数据驱动工作流运行的概念[11-13]。在寻求数据驱动工作流的领域里,比较有影响的是van der Aalst等[14]提出的Case handing思想。目前国内有很多学者对以数据驱动的企业协同创新模式进行了研究[15-17];陈冰[18]提出统一模型驱动下的协同研制已经成为航空产品智能制造技术的未来发展模式,但在产品数据模型建立方面仍有不足。由于复杂产品数据模型必须覆盖协同设计周期各个阶段,传统的基于元模型建模技术[19]建立的复杂产品数据模型在对产品信息分类以及产品不同设计阶段数据类型复杂多变等问题考虑不全,这将不利于不同专业设计人员在协同设计过程中的交互和任务协调。
本文针对复杂产品协同设计过程中不同专业设计人员交流困难、任务协调复杂、产品设计效率低下、传统元模型建模技术的弊端等问题,提出了复杂产品“一元三层”数据模型和基于数据驱动的复杂产品协同设计技术。对复杂产品协同设计中的数据建模以及驱动方法进行了研究,解决了传统协同设计过程中人员交流困难、任务协调复杂等问题导致的产品设计效率低下等问题。
1 基于数据驱动的协同设计技术总框架
在传统的复杂产品协同设计中,一般采用工作流技术来管理各个主体之间的协同设计,即流程内的控制信息决定了流程的走向,这对于简单的企业业务调度能发挥较好的作用,但是在多变的复杂产品协同设计这一业务环境下,尤其在并行工程理念下,后继设计任务的驱动不必等先序任务完成后才开始,一般先序任务产生某些数据后,后继设计任务就可先行开展,因此传统的协同设计方式在柔性方面体现出明显不足。为此本文提出了基于数据驱动的复杂产品协同设计技术,该项技术的总体框架如图1所示。
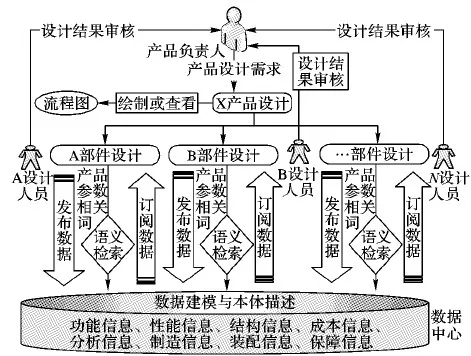
图1 基于数据驱动的复杂产品协同设计框架Fig. 1 Data-driven collaborative design framework for complex products
某项复杂产品设计的具体步骤如下:
步骤一 产品负责人提出产品设计需求,确定自己要设计的复杂产品X,再绘制出复杂产品设计的整体流程图。
步骤二 产品负责人根据流程图将复杂产品X的设计切分为多个部件设计,并为每个部件指定部件负责人。同理,部件负责人在接到任务后,根据需要把任务再细分成多个子任务,分配子任务负责人。
步骤三 部件负责人接收到自己的任务后,设计该部件的参数,向数据中心发布数据,表示该项任务启动。
步骤四 部件负责人设计任务参数时,可以向数据中心订阅需要参考的数据。输入订阅参数相关词,经语义检索后返回所有相关的订阅列表,以供部件负责人订阅。
步骤五 部件负责人完成自己的部件设计后,提交给产品负责人。
步骤六 产品负责人审核部件负责人提交的任务,审核通过,任务完成,此时任务处于完成状态;否则,任务将退回给任务负责人并给出反馈意见。
步骤七 所有部件设计完成后,产品负责人进行产品的整体测试与验证,测试通过,产品设计完成;否则将有问题的部件退回给部件负责人重新设计,直至产品的完成。
根据基于数据驱动的协同设计技术总框架,首先需要对复杂产品建立数据模型,然后实现基于语义检索的协同设计任务数据订阅技术以及基于数据订阅/发布的复杂产品任务协同技术,最后实现基于数据驱动的复杂产品协同设计系统。
2 复杂产品“一元三层”数据模型
复杂产品的协同设计过程分为多个不同的设计阶段,每个设计阶段具有数据类型复杂、不同专业设计人员协同设计等特点。为此本文提出了由任务数据描述层、语义订阅层和数据驱动层组成的复杂产品“一元三层”(A Meta-model with Three Levels, AMTL)数据模型技术。
AMTL模型的特点是以任务数据描述层为基础,集模型语义订阅层和数据驱动层于统一模型中,用于对产品设计所需要的各阶段的数据信息,以及这些数据信息之间的相互关系进行建模,为开发基于数据驱动的复杂产品协同设计系统提供基础。
1)任务数据描述层(task data describe level),是AMTL模型的数据建模层,位于最底层。基于多维多粒度数据建模及本体的任务数据描述,它是AMTL模型的数据源,决定了AMTL模型数据集成的基本粒度,保证了模型的多维多粒度性。
2)语义订阅层(semantic subscription level),是AMTL模型的中间连接层,主要包括数据推荐订阅和语义检索订阅两种数据订阅方式。在任务数据描述层的基础上,采用基于本体的语义检索技术实现数据推荐订阅和数据语义检索订阅的两种数据订阅方式。
3)数据驱动层(data driver level),是AMTL模型的数据订阅/发布层,也是AMTL模型的核心层。在任务数据描述层和语义订阅层的基础上,实现基于数据订阅/发布的复杂产品任务协同技术,从而实现数据驱动下螺旋式上升的协同设计。
2.1 集于多维多粒度数据建模及本体的任务数据描述
2.1.1 复杂产品设计任务的多维多粒度的数据建模
复杂产品设计的过程分为多个设计阶段,由于每个设计阶段数据需求的差异性,数据具有类型复杂及动态多变的特点,然而不同设计阶段产品数据需要保持一致性,因此复杂产品的设计信息需要采用多维数据模型。同时,复杂产品的数据空间又可分为多个层次,可见复杂产品的设计信息也是一个多操作粒度数据模型。故本文采取多维多粒度的数据描述方法来定义复杂产品设计任务之间的交互。如图2所示。
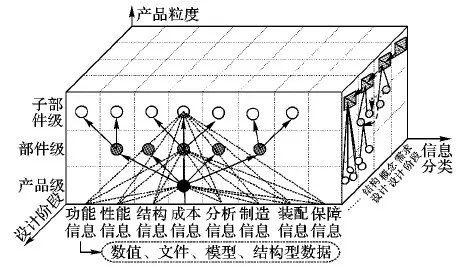
图2 复杂产品的多维多粒度数据建模Fig. 2 Multi-dimensional and multi-granular data modeling for complex products
1)设计阶段。
从设计阶段上看,复杂产品全生命周期分为需求分析、概念设计、详细设计、工艺设计、检验检测几个阶段。不同设计阶段数据需求的差异性导致数据类型复杂及数据动态多变,并要保证每个设计阶段产品数据一致性。
2)产品粒度。
从产品粒度上看,产品数据空间可分为产品、部件、子部件等多层。如图2所示,在复杂产品的不同设计阶段需要不同产品粒度上的数据支持。例如,在需求分析设计阶段,仅需要产品层次上的数据,而在详细设计阶段,则需要产品、部件等两个层次以上的数据。
3)信息分类。
正确合理的信息分类是建立复杂产品数据模型的关键。因此在对复杂产品设计任务进行数据建模之前,需要对产品的信息进行合理的分类。按产品制造流程可以划分为如下8种:功能信息、性能信息、结构信息、成本信息、分析信息、制造信息、装配信息、保障信息。
4)数学表示。
根据以上对复杂产品设计任务的多维多粒度的数据描述,定义复杂产品设计任务数据模型的数学表示形式为:
PIM(PG,DP,IC)
其中:PIM表示复杂产品设计任务数据模型;PG表示产品粒度;DP表示设计阶段;IC表示信息分类。
产品粒度PG的数学表示形式为:
PG(P,C,Sub_C)
其中:P表示产品级;C表示部件级;Sub_C表示子部件级。
设计阶段DP的数学表示形式为:
DP(DA,CD,DD,TD,TT)
其中:DA表示需求分析阶段;CA表示概念设计阶段;DD表示详细设计阶段;TD表示工艺设计阶段、TT表示检验检测阶段。
信息分类IC的数学表示形式为:
IC(FI,PI,SI,CI,AI,MI,ASI,GI)
其中:FI表示功能信息;PI表示性能信息;SI表示结构信息;CI表示成本信息;AI表示分析信息;MI表示制造信息;ASI表示装配信息;GI表示保障信息。
复杂产品的每个产品级、部件级乃至原子部件的设计都包含8种信息分类。每个信息由具体的数据组成,本模型中共有4种数据类型,包括数值、文件、结构型数据、文件。
2.1.2 复杂产品设计任务数据的本体描述
在基于数据订阅/发布的复杂产品任务协同技术中。为了实现数据订阅过程中的语义检索功能,需要对该领域的复杂产品建立本体。因为本体不仅可以作为概念建模的工具,还能实现知识共享,是实现复杂产品任务协同设计过程中基于语义检索订阅技术的基础。因此,本文需要对某一领域的复杂产品建立本体。
根据《航天科学技术叙词表》中术语的编制规则,寻找叙词表中术语之间的语义关系,从而确定叙词表到本体转换的映射规则。通过这种映射规则编写算法实现叙词表向本体的转换。以复杂产品航天科学领域为例,根据《航天科学技术叙词表》建立关于航天科学领域的本体库。最终构建的复杂产品航天领域的“推进部分”设计本体包括2 730个类、1 800个属性、345个实例。如图3为“涡轮喷气发动机”构建的本体示例图。

图3 “涡轮喷气发动机”本体构建图Fig. 3 Ontology construction diagram for “turbojet engines”
2.2 基于语义检索的协同设计任务数据订阅技术
传统的数据订阅方式有两个特性:一是订阅数据必须是已经存在的;二是对数据的订阅方式是精确匹配的。然而在实际应用中任务设计人员订阅的数据可以是数据中心还没有上传的数据。另外任务设计人员对数据的订阅往往是模糊的,需要订阅的是某一概念的相关数据。任务设计人员只需输入订阅数据的参数相关词,就可以检索出所有与之相关的数据以供订阅。因此本文提出了基于语义检索的协同设计任务数据订阅技术,该方法能够克服传统数据订阅的缺点。
复杂产品协同设计任务数据订阅时,本文提出的基于本体的语义检索技术,能够准确地捕捉到任务设计人员所输入语句后面的真正意图,并以此来进行检索,从而更准确地向任务设计人员返回最符合其需求的搜索结果。最终实现了数据订阅过程的语义化订阅,有助于任务设计人员快速且准确地订阅到所需的数据。
2.2.1 基于本体的语义检索算法
基于本体的语义检索算法的核心是计算本体概念之间的相似度[20-23]。在对本体概念相似度计算的算法进行了比较之后。本文采用了蔚醒醒[24]提出的算法,主要考虑了语义距离、语义重合度、属性重合度等因素。该算法能够很好地计算出航天科学领域本体概念之间的语义相似度。
由于复杂产品建立的本体规模大,导致时间复杂度高、检索速度慢。为提高检索速度、降低时间复杂度,本文引入了领域本体的剪枝算法,目前很多学者对本体剪枝算法提出了研究[25-26],本文采用了文献[27]中提出的剪枝算法。经实际验证该算法能够提高语义检索的速度。
本文以2.1.2节建立的复杂产品航天科学领域的“推进技术”部分的本体O,语义检索“涡轮喷气发动机” 为例,详细说明本体之间概念相似度计算过程。
步骤一 对本体树O采用剪枝算法:从领域本体中概念节点相对抽象的部分开始进行剪枝,舍弃掉完全不可能的分支,最后在可能的分支上使用多层次子本体的映射算法进行映射,从而降低了映射的本体规模,剪枝后形成新的本体O1。
步骤二 遍历本体树O1,获得第一个概念C1,计算概念“涡轮喷气发动机”与概念C1的语义相似度,包括语义距离、语义重合度和属性重合度,最后计算其综合加权语义相似度。其计算方法如下:
a)计算C与C1的语义距离。
语义距离指本体层次结构中连通C和C1的最短距离,记为Dist(C,C1)。计算方法如式(1)所示:
(1)
其中:Maxlen表示本体层次结构的最大深度;Dist(C,C1)表示概念C到概念C1的最短路径上的所有有向边的语义距离之和。
b)计算C与C1的语义重合度。
语义重合度是指C和C1拥有的相同上层概念的个数,计算方法如式(2)所示:
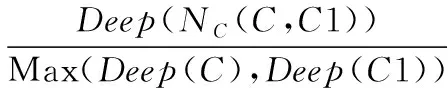

(2)
其中:Deep(NC(C,C1))表示概念C和C1的最近公共祖先节点的深度;r和ε为参数,实验中分别取0.5和0.4。
c)计算C与C1的属性重合度。
每个本体概念拥有很多的数据属性和对象属性,两个概念在属性上的重合度反映出两概念之间的相似性,因此属性重合度用C和C1拥有的相同属性的个数来描述,计算方法如式(3)所示:
Sim(Pro)=Max(ProDi(C,C1),ProIndi(C,C1))
(3)
其中:ProDi(C,C1)表示概念C和C1的直接属性重合度;ProIndi(C,C1)是概念C与C1间接的属性重合度,取两者中较大的作为两概念的最终属性相似度。
d)计算C与C1的综合加权语义相似度。
为了从多个方面衡量概念的相似度,本文对这三种相似度进行加权得到综合的相似度Sim(C,C1):
Sim(C,C1)=λ1·Sim(Dist)+λ2·Sim(Con)+
λ3·Sim(Pro)
(4)
其中:λ1、λ2、λ3权重调节因子,且λ1+λ2+λ3=1。本文λ1、λ2、λ3分别取0.3、0.4、0.3。
步骤三 遍历本体树O1的下一个节点C2,计算“涡轮喷气发动机”与C2的语义相似度,重复步骤二,直至计算出“涡轮喷气发动机”与本体树O1所有节点的语义相似度。
步骤四 将概念“涡轮喷气发动机”与本体树O1所有节点的综合加权语义相似度按降序排列,获得相似概念集。
本文选取相似度值前18个概念为例,如表1所示。
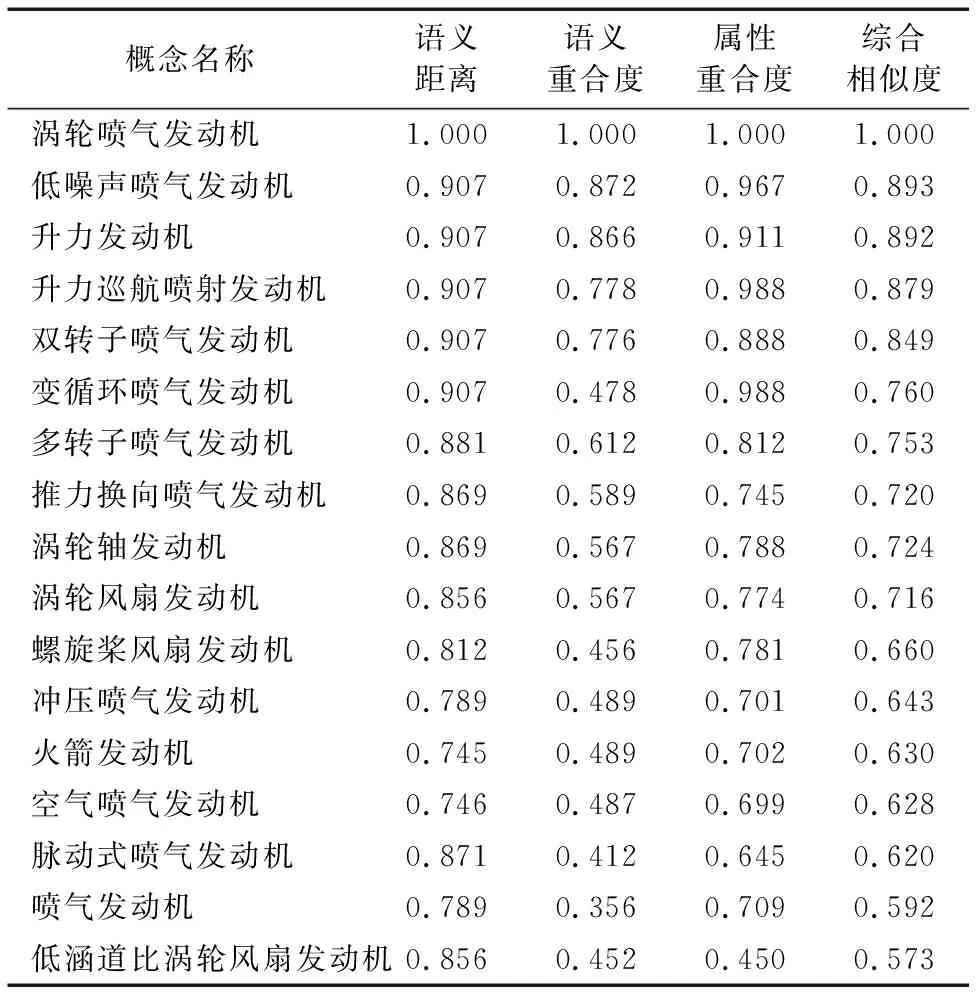
表1 与“涡轮喷气发动机”相似概念列表Tab. 1 List of similar concepts with “turbojet engines”
从表1可知:“涡轮喷气发动机”与自身的概念相似度为1;除此以外,其概念与“低噪声喷气发动机”“升力发动机”“升力巡航喷射发动机”等都有着极高的相似度。
上述算法和自然语言处理领域的Word2Vec算法都能解决协同设计数据订阅过程中的语义检索功能问题。本文算法是基于本体概念的,通过计算本体概念间的相似度实现语义检索,可用于协同设计中基于任务数据关键词描述和基于文档名的数据订阅;Word2Vec是基于语料库的,通过将语料库中的所有词向量化来度量词与词间的关系[28],可用于协同设计中基于文本文档的数据订阅。然而协同设计过程中涉及的是大量设计图纸类文档,文本类文档较少,故本文暂时只考虑基于本体相似度的数据订阅技术。
2.2.2 基于语义检索的数据订阅流程
根据2.1节集于多维多粒度数据建模及本体的任务数据描述,结合协同设计任务数据订阅的实际情况,本文设计了任务数据在数据库中的存储结构,即TaskData(数据id、数据名称、数据类型、所属任务名称、信息分类、设计阶段、产品粒度、……、版本号)。在协同设计数据订阅过程的实际应用中,任务设计人员可以根据系统推荐订阅数据或者自己语义检索需要订阅的数据,因此本文给出语义检索订阅和推荐订阅两种数据订阅方式。
方法一:推荐订阅,根据任务名称及任务信息描述,系统根据语义检索算法给出推荐订阅列表,任务设计人员通过推荐列表订阅数据。
方法二:语义检索订阅。步骤如下:
步骤一 任务设计人员可先选定信息分类、产品设计阶段以及数据版本,其中数据版本分所有版和最新版,再输入要检索的内容。如选定“成本信息”“概念设计”阶段和最新版,输入要语义检索的内容为“涡轮喷气发动机”。
步骤二 在数据库中查询出信息分类为“成本信息”、设计阶段为“概念设计”且数据版本为最新版的所有数据,形成初始数据集。
步骤三 对输入的内容“涡轮喷气发动机”通过2.2.1节的本体的语义检索算法进行语义扩展,如表1所示,本文选取与“涡轮喷气发动机”概念相似度大于0.5以上的概念形成扩展集。
步骤四 在初始数据集中模糊查询出所有任务名称包含扩展集的所有数据,并按相似度大小排序。
步骤五 根据数据的相似度,任务设计人员选择需要订阅的数据。
2.3 基于数据订阅/发布的复杂产品任务协同技术
基于工作流技术的传统复杂产品协同设计中有很多缺点,比如不同专业设计人员在协同设计过程中的交流困难和协调复杂等问题,这些问题容易导致产品设计效率低下以及产品质量得不到保证。为了克服传统协同设计中的弊端,本文提出了基于数据订阅/发布的复杂产品任务协同技术。
2.3.1 数据订阅/发布机制概念
数据订阅/发布机制是不同设计人员之间互换信息的一种通信机制,根据2.1节本文将复杂产品信息共分为8种信息类型,4种数据形式。该机制分为数据的发布者(Data Publisher)和数据的订阅者(Data Subscriber)。数据的发布者将要发布的数据分为不同的信息类别及数据形式,然后选择需要发布的数据到数据中心而无需知道订阅者的任何信息。而数据的订阅者可以从数据中心订阅一种或多种类型的数据,而不需要知道发布者信息。数据订阅/发布机制的信息交换模式是一种灵活有效的信息交换方式,将其应用于协同设计,可将大规模的协同设计应用中的各个设计人员联系起来,能以松耦合的方式进行联系,从而提高了设计效率。
2.3.2 基于数据订阅/发布的复杂产品任务协同设计过程
1)基于数据订阅/发布的任务协同设计过程。
本文选取2个专业设计人员,来描述他们基于语义检索的数据订阅/发布驱动复杂产品的协同设计过程。如图4所示:其中,专业设计人员A与专业设计人员B工作步骤相似,以专业设计人员A为例说明其数据订阅/发布的流程。
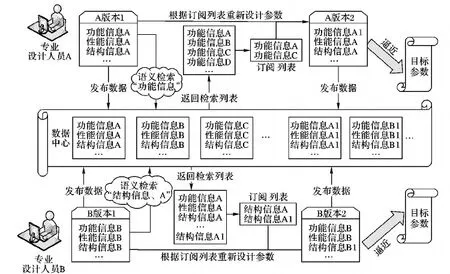
图4 基于数据订阅/发布的任务协同设计过程Fig. 4 Collaborative design process based on data subscription/publishing
步骤一 专业设计人员A接到设计任务后,初步设计所需的所有任务参数数据,即任务版本1;
步骤二 专业设计人员A将自己的任务数据选择发布到数据中心,发布到数据中心的数据可以供其他任务设计人员订阅;
步骤三 专业设计人员A同时向数据中心通过语义检索订阅数据,如检索“功能信息”,然后系统会把所有与“功能信息”相关的数据从数据库中检索出来再返回给用户订阅列表,此时专业设计人员A从可供订阅列表中选择所要订阅的数据;
步骤四 专业设计人员A根据订阅的数据重新设计自己的任务参数,形成新的任务版本2;
步骤五 重复操作步骤二~四,直至所设计的参数越来越逼近目标参数。
2)数据驱动下螺旋式上升的协同设计。
在复杂产品协同设计过程中,专业设计人员在数据订阅/发布的过程中,可能会产生某个任务的多个版本的设计数据,而这些版本的任务数据可能被其他专业设计人员订阅,因此存在不同版本的任务数据的保存、融和、删除等操作。复杂产品任务设计在多个版本的迭代后最终实现数据驱动下的螺旋式上升。
以复杂产品参数设计为例,在经历数据的多次发布/订阅后形成新的数据版本,其参数设计也在版本迭代过程中得到不断的优化,最终实现参数协同设计过程的螺旋式上升。如图5所示。
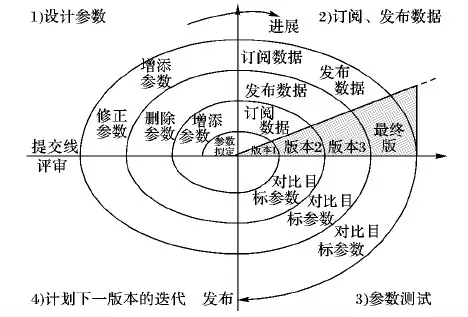
图5 协同设计的螺旋式上升图Fig. 5 Spiral rise of collaborative design
3 系统实现及展示
本文在前端基于JQuery、Bootstrap3、Layui技术,后台基于Spring、SpringMVC、Mybatis框架技术,数据库基于Oracle平台下,实现了基于数据驱动的复杂产品协同设计系统。
本文选取复杂产品航天科学领域的“喷气发动机设计”为例,详细介绍了其基于数据驱动的协同设计过程。
3.1 复杂产品多维多粒度的数据描述
复杂产品设计任务采用了多维多粒度的数据描述方式,如图6所示,复杂产品“喷气发动机设计”可分为很多不同部件的设计,如“超音速冲压喷气发动机设计”“涡轮风扇发动机设计”“亚音速冲压喷气发动机设计”等;同时,每项任务都有不同的优先级及任务状态等信息。而图7中有产品设计阶段和信息分类等信息,这体现了复杂产品信息模型的多维多粒度性。复杂产品采用多维多粒度的数据建模方式可以很好地定义复杂产品设计任务之间的交互。
3.2 基于语义检索的数据订阅/发布机制
本文选取复杂产品“喷气发动机设计”的某一任务“固体火箭发动机设计”为例,来说明其基于语义检索的订阅/发布数据过程。
1)发布数据。
任务设计人员在完成自己的任务参数设计后,可以选择向数据中心发布数据,发布后的数据可以供其他任务设计人员参考订阅。
2)基于语义检索的数据订阅。
如图7(a)是第一种数据订阅方式,即根据任务名称及任务信息描述,系统根据语义检索算法给出推荐订阅列表,任务设计人员通过推荐列表订阅选择需要订阅的数据。
如图7(b)是第二种数据订阅方式,即任务设计人员通过语义检索法选择订阅的数据。如任务设计人员先选定信息类型为“性能信息”,设计阶段为“概念设计”,检索输入“涡轮喷气”,就能语义检索出所有与“涡轮喷气”相关的数据,结果按相似度大小排序,供任务设计人员选择需要订阅的数据。
图6 “喷气发动机设计”多维多粒度的数据描述Fig. 6 Multidimensional and multi-granular data description for “turbojet engines design”

图7 数据的两种订阅方式Fig. 7 Two ways for data-subscription
4 结语
针对传统的基于工作流的协同设计模式效率低下且设计人员之间难以协调问题,本文提出了复杂产品“一元三层”数据模型和基于数据驱动的复杂产品协同设计技术,首先对复杂产品以多维多粒度的方式进行数据建模,接着研究了基于语义检索的协同设计任务数据订阅技术以及基于数据订阅/发布的复杂产品任务协同技术。从而有效解决了协同设计中不同任务设计人员之间的交互困难以及任务之间难以协调等问题,实现了产品协同设计过程的螺旋式上升。
数据驱动模式下的协同设计已经成为复杂产品智能制造技术的一项关键技术。建立复杂产品统一的数据模型是产品协同设计的前提,本文对复杂产品的多维多粒度的数据建模方式还存在一些不足,比如在产品粒度以及产品信息分类问题上还有待完善。此外,本文的数据类型共有四种:数值、模型、文件、结构型数据。在订阅文件类型的数据时,如何实现基于文档内容检索技术,这样任务设计人员可以基于文档内容订阅所需的数据,这也是今后需要改进的地方。
