降低相似度碰撞的证据融合方法
2018-11-22张志勇乔阔远
王 剑,张志勇,乔阔远
(1.郑州大学 信息工程学院,郑州 450001; 2.河南科技大学 信息工程学院,河南 洛阳 471003)(*通信作者电子邮箱iejwang @zzu.edu.cn)
0 引言
证据理论是由Dempster[1]和Shafer[2]提出的一种有效的不确定性推理方法[3],被广泛用于最优决策[4-6]、可靠分析[7-9]、关系度量[10]、最优计算[11-13]等领域。然而在现实环境中,由于传感器的故障或信任函数模型的不准确会导致证据之间互相冲突,进而会引起融合结果的反直观现象[14]。
为了能在冲突证据存在的情况下依然获得正确的融合结果,证据的融合公式必须能适应冲突证据的存在[15-16]。Dubois等[17]提出了一种新的证据融合方法,它将证据的交集部分转化为并集部分,以降低证据冲突程度;但该方法在冲突程度高时表现较差[14]。Murphy[18]将所有待融合的证据求平均得出平均证据,然后将平均证据使用Dempster融合方法融合自身n-1次得到组合结果。然而,文献[14]指出:不同证据对融合结果的影响不同,应为不同证据分配不同的权重。为了获得证据权重,一些学者提出了证据之间的相似度,并将相似度转化为证据权重[19]。Cuzzlion[20]通过将证据体映射成几何空间中特殊线段的方式解释了证据距离的几何意义,为证据距离和证据相似度奠定了理论基础。Jousselme等[21]提出了一种基于证据距离的证据相似度计算方法,但没有提出将证据相似度转化为证据权重的方案。Wen等[22]提出了一种简化的、基于向量余弦值的证据相似度计算方法,却忽略了证据中焦元个数对相似度计算结果的影响。Wang等[23]通过修正证据权重改进了Murphy[18]的融合规则,但存在相似度碰撞的缺陷。文献[24]中提出了一种降低相似度碰撞的方法,但是没有提出与之相适应的证据融合方法。
证据的权重除了受到冲突程度的影响之外,还受到证据不确定程度的影响。证据理论中对证据不确定性程度的计算过程被称为不确定性度量(Ambiguity Measurement, AM)[25]。
陈金广等[26]提出一种基于经验值α和多义度的不确定性度量方法,Wang等[27]提出了一种基于置信区间的证据不确定性测度方法,Kilr等[28]提出了一种基于证据中基本信任分配函数数值分布的不确定性度量方法,韩德强等[29]、Deng等[30]分别提出了两种基于证据距离和证据不确定性的证据权重确定方法,Wang等[31]提出一种基于不确定性度量和软集合的证据决策方法。
以上研究都是在冲突证据被正确识别的前提下,基于证据的不确定性程度完成对证据权重的修正。虽然AM在一定程度上能获得更优的融合结果,但其依赖的冲突证据识别本身就存在相似度碰撞的缺陷,即证据的冲突强度无法被证据相似度正确识别。而无法识别的原因是由于相似度计算的缺陷导致两组不同的证据相似度计算结果相同,进而使高冲突证据被误认为是低冲突证据,引起证据支持度的错误。
1 预备知识
1.1 证据体和基本信任分配函数
在证据理论中,用基本概率赋值函数(Basic Probability Assignment, BPA)来表示初始信任度分配,用信任函数来表示每个命题的信任度。基本概率赋值函数也被称为基本信任分配函数(Basic Belief Assignment, BBA)。对于辨识框架θ,问题域中任意命题A都应属于幂集2θ, 即A是2θ的子集。若用m(A)代表命题A的基本概率赋值函数,当m(A)>0 时,称A为证据的焦元。信任函数bel(A)表示证据完全支持A的程度,似真函数pl(A) 表示证据不反对命题A的程度,区间[bel(A),pl(A)] 构成证据的不确定区间,如图1所示。
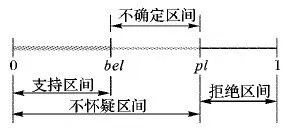
图1 信任概率范围Fig. 1 Trust probabilistic scope in evidence
图1中,函数bel(A)是当前证据对焦元A的信任函数,而pl(A)被称为焦元A的似真函数。一般地,对于任意一个焦元B,bel(B)和pl(B)之间有以下性质:
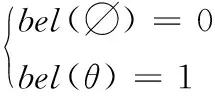
(1)
bel(B)+bel(B′)≤1; ∀B⊆θ
(2)
bel(B)≤pl(B)
(3)


(4)
式(4)中的共性函数描述了一个证据中的所有基本信任分配函数对一个指定的焦元的支持程度。基本信任函数、似然函数和共性函数为证据计算的基石,三者具有以下关系:
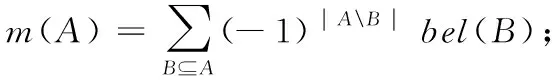
(5)

(6)

(7)
1.2 证据的相似度和支持度
文献[24]基于用于描述证据差别的证据距离,提出了证据相似度函数应满足的三个条件:非负性、无序性和三角性。其中:非负性代表相似度结果永远为正;无序性代表计算结果应与参数顺序无关;三角性代表间接相似度需要大于直接相似度,以满足值域的紧凑性。
基于以上的性质,许多学者提出了证据之间的相似度计算公式,其中由文献[21]和文献[22]的方法应用最为广泛。文献[22]中提出的相似度计算公式是基于两个证据之间的余弦值,具有运算快的特点。文献[21]中提出的相似度计算公式中,将每个焦元中的元素个数进行了计算,相对于文献[22]方法,考虑因素更加全面。本文使用的相似度计算方法是文献[21]中提出的相似度方法,其定义如下:
sim(mi,mj)=1-di, j=
(8)

(9)
其中:ms为参与融合的证据集合,ms中的所有证据必须和mi处于同一个辨识框架之下。证据的支持度是证据相似性的整体体现,一个证据与其他证据的相似度之和越高,其支持度越大。
1.3 证据的信息熵
相似度可以完成证据的冲突检测,而冲突检测还不足以确定证据权重,因为每个证据的不确定性程度不同,无论一个证据冲突程度的大小,如果其不确定性程度很大,就应该削弱其在融合过程中的权重。
由于Deng等[30]提出的方法具有计算简便和适应性强的优点,本文采用该方法完成证据的不确定性度量,其定义为:
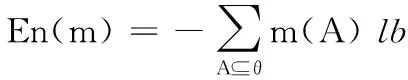
(10)
其中:θ代表当前证据处于的辨识框架;|A|代表焦元A的一阶范式。
1.4 基本融合公式
假设在辨识框架θ中证据的基本信任分配函数分别为bel1,bel2,…,beln,其融合形式为bel⨁=bel1⨁bel2⨁…⨁beln,融合结果bel⨁被称为是其他基本信任分配函数的直和[14]。证据的基本融合公式如下:
m⨁(∅)=0
(11)
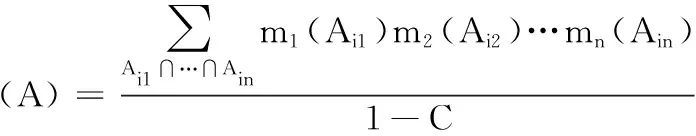
(12)
(13)
其中C被称为冲突程度。根据式(11)~(13)可证明基本的融合公式符合交换律和结合律[4]。融合结果的共性函数Q⨁(A)为:

(14)
2 抗相似度碰撞融合算法
2.1 信任转移模型
在已有的证据融合算法中,融合模型主要分为两部分:信任转移模型和决策模型。在信任转移模型中,为每个证据确定其在融合过程中的权重,每个证据的权重表示其可信程度。而可信程度的度量主要是基于证据之间的相似度和有用性的度量,其架构如图2所示。

图2 传统的证据融合架构Fig. 2 Traditional combination scheme for evidence
在图2所示的架构中,证据的权重建立在证据的相似度计算之上,如果相似度不能把证据之间的差异正确地映射为相似度数值的差异,将导致证据支持度的偏差,进而影响最终的融合结果。而在最近关于证据理论的研究[14]中,已经发现证据相似度存在相似度碰撞的缺陷。为了应对以上碰撞,本文使用排序矩阵修正证据支持度,图3为本文算法的架构。

图3 本文的证据融合架构Fig. 3 Proposed combination scheme for evidence
在图3所示的本文架构中,证据焦元序列被转化为排序矩阵,通过检测每个矩阵焦元序列的差来检测易产生碰撞的证据,同时基于信息熵和排序矩阵的差完成证据权重的确定,并获得融合结果。
2.2 相似度碰撞和支持度修正
假设ms={m1,m2,m3,m4}是处于同一辨识框架下的四个证据,每个证据的证据体如表1所示。
根据式(8),证据m1和m2之间的相似度为:
(15)
同样根据式(8),证据m3和m2之间的相似度为:
(16)
通过式(15)~(16)可以看出,sim(m1,m2)=sim(m2,m3),但m1≠m3。在本文中,将这种证据不相同但是相似度相同的情况称为相似度碰撞。基于证据的相似度,证据m1、m2、m3、m4的支持度分别为:
(17)
(18)
(19)
(20)
根据式(13),算出证据m1、m2、m3、m4两两之间的冲突程度如表2所示。
基于表2中的数据,统计出一个证据对其他证据冲突程度的和,如表3所示。
参照表1中证据m1和m3,由于m1和m3的区别仅仅在于焦元A和焦元C的BPA互换,而BPA的大小未发生变化,导致式(15)和式(16)计算获得的相似度相同。由于证据的支持度是相似度的和,相似度未发生改变导致了证据m1和证据m3的支持度相同(式(17)、式(19))。参照表2,由于证据m3与其他证据的冲突程度之和最大,支持度应该尽可能小,说明相似度的碰撞影响了证据的支持度确定。

表1 证据的证据体Tab. 1 Body of each evidence
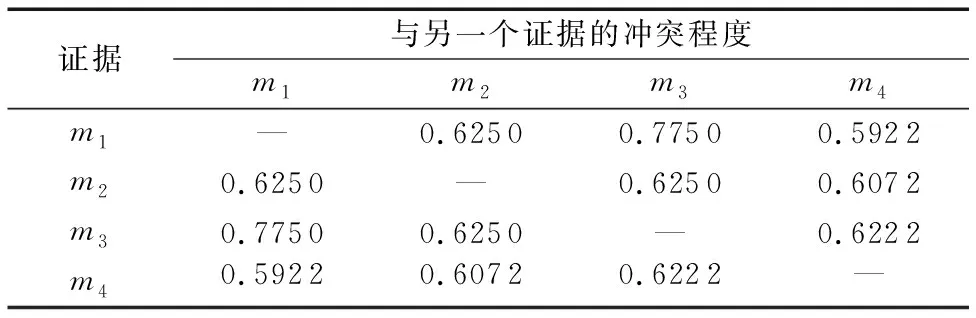
表2 证据之间的冲突程度Tab. 2 Conflict degrees between evidence

表3 每个证据对其他证据的冲突程度和Tab. 3 Summation of conflict degrees of each evidence with other evidence
参考式(8),证据的相似度仅仅计算了证据中BPA的大小区别,而不关心证据中BPA的大小关系。由于每个证据中所有BPA的和一定为1,则每个证据中的所有BPA必定存在一个大小关系且大小关系不同的证据一定不同。以表1中的证据m1为例,其大小关系为m1(A)>m1(B)≥m1(AB)>
m1(C),而证据m3中BPA的大小关系为m3(C)>m3(B)≥m3(AB)>m3(A)。将证据的证据体看作是一个单列矩阵M,同时指定一个有序矩阵(Ordered Matrix,OM),可以找到排序矩阵(Sort Matrix, SM),使得该证据对应的单列矩阵M和SM的积为OM。对于给定的证据m,获得其排序矩阵的过程如算法1所示。
算法1 计算证据的排序矩阵。
输入 证据m。
输出 证据m的排序矩阵SM。
定义证据m′=m,定义有序集合F=∅,J=∅
for ∀f∈P=2θ:
iff∉F: 将f添加到F的最后
end for
for ∃m′(α)≠0(α∈P):
将m′中基本信任分配函数最大的焦元记为f
将m′(f)添加到J的结尾,并令m′(f)=0
end for
定义矩阵SM,其维度为|P|×|P|
for ∀f∈P:
将f在F中的序号记为i
将f在J中的序号记为j
将SMi, j的值设为1
end for
将矩阵SM的其他元素赋值为0
返回矩阵SM作为证据m的排序矩阵
通过算法1,每个证据被映射为一个排序矩阵,多个排序矩阵之间的差异可以映射为另一个矩阵差值矩阵(Difference Matrix, DM),其计算方式为:
(21)
证据的差值矩阵DM描述了一个证据在所有参与融合的证据中焦元序列的一致程度,而通过指数曲线可以将差值矩阵映射为一个值域为[0,n] 的排序因子F。排序因子的定义为:
定义1 假设m1,m2,…,mn是处于同一辨识框架下的n个证据,并且DM1,DM2,…,DMn是证据m1,m2,…,mn的差值矩阵,则mi的排序因子Fi为:
(22)
基于式(22)中的排序因子,式(9)处的证据支持度被修正为:
(23)
2.3 融合结果
假设m1,m2,…,mn是处于同一辨识框架下的n个证据,En(mi)是证据mi的信息熵,则证据mi的综合支持度为:

(24)
(25)
证据的综合支持度是对每个证据在冲突检测和不确定性度量两个方面的信任度衡量,冲突证据的权重通过支持度的计算被削弱,相似度的碰撞被排序矩阵的计算削弱,最后通过证据的信息熵完成证据不确定性度量。由于证据的综合支持度的值域并非[0,1],需要将其转化为更适合作为权重的另一个参数综合信誉度w,可以通过证据的综合支持度的归一化完成:
(26)
而基于证据的权重,定义归一化证据(Modified Average Evidence, MAE),该证据将代表原始的所有证据和每个证据的冲突强度以及信息量。证据MAE的定义如下:
定义2 假设m1,m2,…,mn是处于同一辨识框架下的n个证据,并且w(m)是证据m的权重,那么证据MAE为:
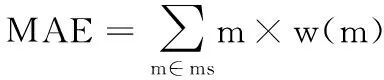
(27)
MAE是原始证据体和冲突检测的综合结果,最终的融合结果可以通过将MAE使用基本公式融合n-1次得到,其流程如图4所示。

图4 MAE转化为融合结果流程Fig. 4 Flow chart of converting MAE into combination result
在图4中,首先定义变量RST,并将其赋值为MAE,通过n-1循环融合MAE自身获得融合结果。
3 实验
在实验部分,分别模拟了文献[18,22-23,29]中提出的融合算法,并设计了两组实验检测本文方法的有效性。在第一组实验中,使用文献[18,22-23,29]共同的比较方法,即通过随机选取一组证据并比较融合结果中正确焦元的基本信任分配函数大小。在第二组实验中,使用在线数据集Iris(http://archive.ics.uci.edu/ml/datasets/iris)作为输入,使用文献[32]中提出的方法将每条记录转化为4条证据,分别使用文献[18,22-23,29]中提出的融合算法和本文提出的融合算法将四条证据融合为融合结果并对鸢尾花类型作出判断,通过统计准确率和召回率来判断本文方法的有效性。
3.1 比较融合结果中BPA大小
在一个由6个传感器组成的目标识别系统中,已知总共有三种可能的目标类型A、B、C。随机抽取一个时刻传感器S1、S2、S3、S4、S5、S6对同一目标的识别证据信息m1、m2、m3、m4、m5、m6,其中:m1代表传感器S1返回的证据1,m2代表传感器S2返回的证据2,以此类推。每个证据如表4所示。
基于表4的数据,证据之间的相似度如表5所示,每个证据的排序因子和信息熵如表6所示。
根据表5和表6中的数据和式(26),每个证据被不同方法确定的权重如表7 所示。
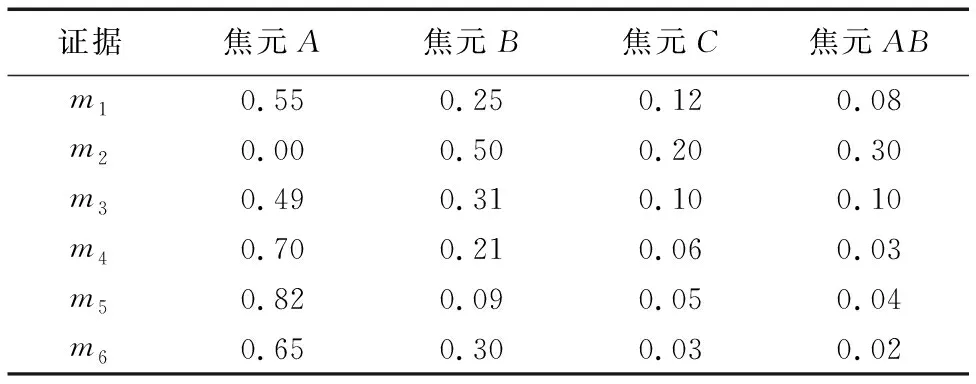
表4 传感器返回证据Tab. 4 List of evidence sent back by sensors
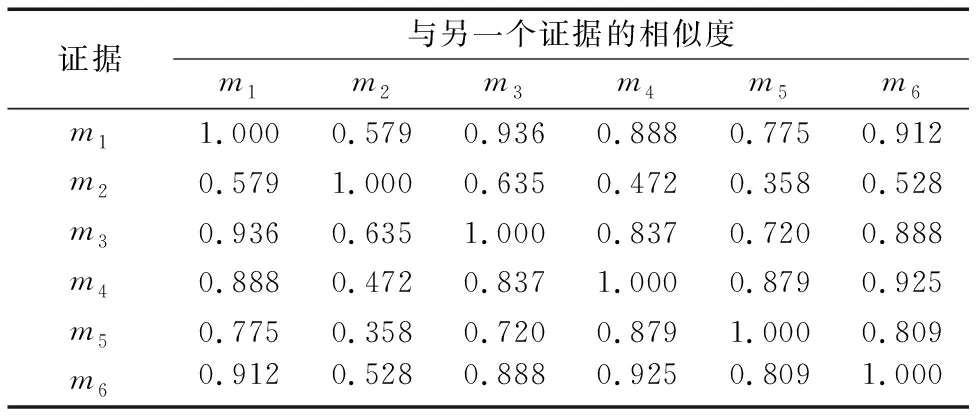
表5 证据之间的相似度(基于表4)Tab. 5 Similarity between evidence corresponding to Tab. 4
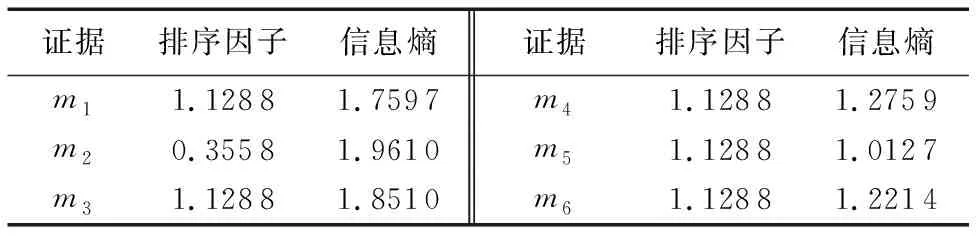
表6 证据的排序因子和信息熵(基于表4)Tab. 6 Sort factor and entropy of each evidence corresponding to Tab. 4

表7 不同方法确定的证据权重(基于表4)Tab. 7 Evidence weight determined by different methods corresponding to Tab. 4

图5 各方法确定的MAE中焦元的基本信任分配函数Fig. 5 BPA of focal-element in MAE determined by each method

图6 各方法的融合结果Fig. 6 Combination result of each method
表7中w(mi)表示证据mi的权重,为了检测每种方法确定证据权重的合理性,通过式(13)计算出每个证据与其他证据的冲突强度之和如表8所示。

表8 每个证据对其他证据的冲突程度和(基于表4)Tab. 8 Summation of conflict degrees of each evidence corresponding to Tab. 4
从表8可知,由于m2与其他证据的冲突程度最大,为m2分配的权重应该尽可能小。在表7中,证据m2被文献[18,22-23,29]和本文方法确定的权重分别为0.166 6、0.105 8、0.105 8、0.078 2和0.031 2。其中本文方法确定的证据权重是最小的。通过证据的权重和信息熵,可以确定代表着原始证据体和证据权重的归一化证据MAE。每个方法确定的MAE中各个焦元的基本信任分配函数如图5所示。
从图5可看出:本文方法确定的MAE中焦元A的基本信任分配函数值最大,同时其他几个焦元的基本信任分配函数最小。说明本文方法获得的MAE更加合理。
在获得MAE之后,融合结果中焦元的基本信任分配函数如图6所示。
由于焦元A在绝大多数证据的基本信任分配函数是最大的,融合结果中焦元A的基本信任分配函数越大越好;并且由于焦点元素B、C、AB,不是最后的融合结果,它们的基本信任分配函数应该越小越好。从图6(a)可以看出,无论证据数据是多少,本文方法中确定焦元A的基本信任分配函数始终是最大的;从图6(b)~(d)可以看出,由本文方法确定的其他几个焦元的基本信任分配函数始终是最小的。由此可得出:本文方法确定的基本信任分配函数更加合理,同时在证据数目较少时能更快地作出决策。
3.2 比较决策准确率
实验中使用鸢尾花植物数据集作为实验数据,数据集中每条记录包含四个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度和植物类型。通过文献[32]方法将一条记录转化为代表四个特征的证据,然后通过证据的融合完成植物类型的决策。随机挑选一条在不同融合公式下表现不同的记录,该记录为:
type=Vi
features=[6.3, 2.5, 5.0, 1.9]
该记录代表着当前植物的真实类型为Vi,同时萼片长度、萼片宽度、花瓣长度、花瓣宽度分别为6.3、2.5、5.0、1.9。将其四个属性转化为四条证据,如表9所示。
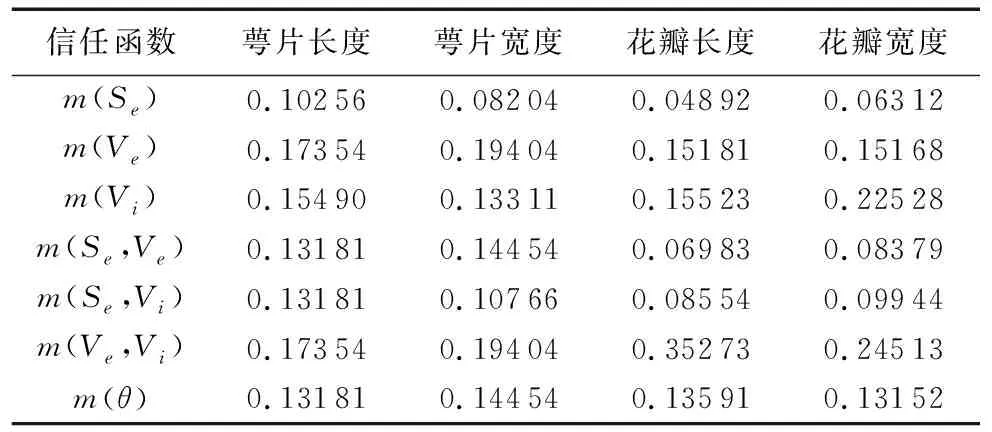
表9 转化获得的证据Tab. 9 Evidence converted by plant features
基于表9中的证据,使用参与比较的几种方法进行融合,其融合结果如表10所示。

表10 融合结果中的基本信任分配函数Tab. 10 BPAs in combination result
从表10可以看出:文献[18,22-23,29]中融合算法作出了错误的决策,本文方法作出了正确决策。每种方法对数据集中每条记录的决策统计如表11所示。表11的中间三列中每个元素由三个数值构成:第一个数值代表由当前方法正确召回的个数,第二数据代表当前方法认为正确的召回个数,第三数据代表当前数据集中的当前类型的数据个数。最后一列的数据是统计每种方法对不同类型的F-Score的平均值,可以发现本文方法的F-Score的最高。
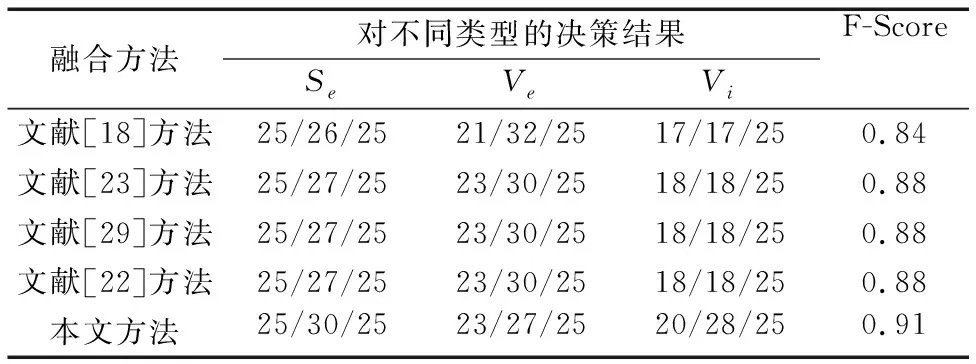
表11 每种方法的决策表现Tab. 11 Decision performance of each method
4 结语
本文针对相似度易产生相似度碰撞产生证据权重失衡并引发融合结果错误的问题,提出了一种新的抗相似度碰撞的证据融合方法。该方法首先将证据中焦元的序列特征量化为矩阵,然后将证据支持度和焦元序列特征转化为证据权重,最后使用Dempster证据融合算法将归一化证据融合n-1次获得融合结果。通过两组实验检测本文方法的有效性:与文献[18,22-23,29]方法相比,第一组实验中,正确焦元的基本信任分配函数从0.964、0.981、0.981、0.986提高到0.992;第二组实验中,对在线数据集鸢尾花的类型决策的F-Score从0.84、0.88、0.88、0.88提升到0.91。实验结果表明本文提出的证据融合方法在分类决策方面取得了出色的表现,能够为证据融合提供更加准确、有效的融合方法,获得更加可靠的融合结果,为人工智能中分类决策、目标识别等问题提供新的解决方案。
